
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
二值表示学习及其应用
[鲁继文1  , 段岳圻
, 段岳圻1 , 陈志祥1 , 周杰1 ]
, 段岳圻, 陈志祥, 周杰]
|
|




作者简介:鲁继文,博士,副教授,主要研究方向为计算机视觉、模式识别、机器学习.E-mail:lujiwen@tsinghua.edu.cn.

段岳圻,博士研究生,主要研究方向为计算机视觉.E-mail:duanyq14@mails.tsinghua.edu.cn.

陈志祥,博士,助理研究员,主要研究方向为计算机视觉.E-mail:zxchen@mail.tsinghua.edu.cn.
随着互联网等信息技术的飞速发展,视觉数据呈现爆炸式增长趋势.如何从视觉数据中高效挖掘信息,已成为大数据时代的重要研究课题.二值表示在存储、传输和匹配上表现出高效性,在多项视觉应用中取得初步成效.文中从实际应用出发,对面向视觉搜索和视觉识别的二值表示学习进行总结分析.在方法层面上,主要从图像哈希和视频哈希两个角度进行阐释.在应用层面上,讨论二值表示学习在人脸分析、图像分类、图像匹配和视觉跟踪任务上的成功应用.最后,对二值表示学习的发展趋势进行展望.
About the Author:LU Jiwen, Ph.D., associate professor. His research interests include computer vision, pattern recognition and machine learning.
DUAN Yueqi, Ph.D. candidate. His research interests include computer vision.
CHEN Zhixiang, Ph.D., assistant profe-ssor. His research interests include computer vision.
With the rapid development of internet and other information technologies, the amount of visual data grows explosively. It is an essential research topic for efficient visual data mining in the big data era. In this paper, the technology of binary representation learning and its applications are reviewed. Binary representation shows efficiency in storage, transmission and matching, and it is successfully applied to several visual analysis tasks. The applications on visual search and recognition are summarized, and the future trend of binary representation learning is pointed out. From the aspect of methodology, the image-based hashing and the video-based hashing are illustrated, respectively. From the aspect of applications, the successful applications of binary representation learning on varying tasks are discussed including facial analysis, image categorization, image matching and visual tracking. Finally, the future trend of binary representation learning is introduced.
特征学习是模式识别和人工智能中的一个基础问题, 也是众多计算机视觉应用的重要组成部分, 如检测[1]、识别[2]、跟踪[3]、搜索[4]等.随着信息技术的不断变革发展, 计算机软硬件性能规格不断提升, 电子设备更加普及, 互联网络日益完善, 这些应用需要处理的数据规模更加庞大, 或需要适配于运算能力和存储资源都受限的移动终端.这都对特征学习提出新的需求和挑战, 不仅要求特征有效, 具有鉴别性, 而且要求特征是对象的紧致表达.
在紧致的特征学习上, 已有学者尝试通过对实值特征(如尺度不变特征变换(Scale-Invariant Feature Transform, SIFT))进行压缩以适配大规模或实时的应用场景, 包括数据降维、量化和二值化.相比二值特征, 通过降维和量化得到的特征需要消耗更多的存储空间, 并且无法使用基于汉明距离的快速相似性计算.因此, 本文着重回顾二值特征学习, 并具体阐述二值特征学习在搜索[4]、识别[5]、分类[6]、匹配[7]和跟踪[8]中的应用.其中用于搜索的二值特征学习也称作哈希学习.
按照学习对象不同, 哈希学习可分为图像哈希和视频哈希两种, 下面分别回顾这两方面的进展.
图像哈希方法的基本思想是构建一系列的哈希函数, 将视觉图像映射成二值特征向量.从数据中学习得到哈希码, 只需使用较短的哈希编码就可以达到理想的精度, 进一步提高检索和学习效率, 降低存储和通信开销.应用于快速图像检索的哈希学习算法已被大量研究.下面按非监督方法和监督方法进行讨论.
1.1.1 非监督哈希方法
Gong等[9]提出迭代量化方法, 首先使用主成分分析[10]降维, 然后旋转数据以减小误差.
这种方法欲使v∈ Rc 与sgn(v)∈ {-1, 1}c的欧氏距离最小, 即min
该方法使用B表示二值码, 主成分分析降维后的数据为V=X× W, 其中W为下列目标函数的最优解:
max L(W)=
对于任意的c× c的正交矩阵R, W'=WR也是最优解.而R的几何解释就是旋转矩阵.所以问题转化为如下优化问题:
Q(B, R)=
对于上述优化问题的求解, 采用类似于K-means[11]的迭代量化程序, 寻找量化误差的局部最小值.迭代量化方法的特点就是对基于主成分分析降维后的数据进行旋转, 减少量化误差.同时学习得到旋转矩阵, 较好地降低图像特征在量化这一步的信息损失, 使映射到哈希码时依然保存原来特征的局部结构和相似性, 提高检索精度.同时, 该方法也适用于典型相关分析[12]降维后得到的数据.
He等[13]提出K聚类哈希方法, 结合了汉明距离计算的快速性、数据无关的优点及K均值聚类量化准确的优点.因此该方法使用K均值的方法在原特征空间进行量化, 通过计算聚类后各胞元的下标的汉明距离估计距离:
d(x, y)≅d(q(x), q(y))= d(ci(x), ci(y))≅dh(i(x), i(y)).
该方法显示采用朴素的两步方法后提出新的“ 类同保持量化” 的方法.
谱哈希[14]及其扩展[15-20]表明, 对一个给定的数据集进行哈希编码实际上是一个图分割问题, 并且是一个NP难的问题.通过放松原问题得到一个谱问题.放松后的问题解实际上是一个拉普拉斯图的有阈值的特征向量的子集.此外, 半监督哈希[21-23]将谱哈希扩展到半监督的情况下, 即只有部分图像对被标注.
Liu等[24]提出基于图的方法, 自动提取数据中的内在邻域结构, 学习近似的二值码.为了减小计算复杂度, 采用锚点图获得易于处理的低秩邻接矩阵, 使算法可以在常数时间复杂度下对新的样本点进行哈希编码.Liu等[25]提出的离散图哈希将基于图的哈希问题融入离散优化的框架, 直接得到二值码.
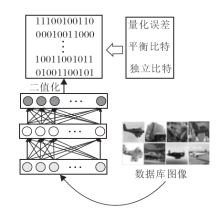
与上述方法不同, 深度哈希[26]使用深度神经网络取代线性投影的方法, 学习二进制编码, 示意图如图1所示.这种方法对于网络层的约束有3个准则:量化误差最小, 向量的每个比特分布均匀即携带的信息对等, 不同比特之间尽可能不相关以防止冗余的编码.在此基础上还可以增加监督信息, 优化性能.
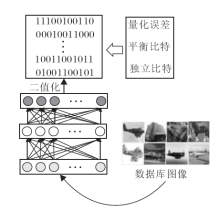 | 图1 深度哈希算法示意图Fig.1 Flowchart of deep Hashing method |
对于深度哈希算法归纳如下.设网络共有M+1层, 除去第一层, 每一层节点有pm个, 对于每个样本xn∈ Rd, 第一层的输出为
hn=s(W1xn+c1)∈
其中, W1∈
以此类推, 第m层的输出是
所以顶层的输出为
gDH(xn)=
最后对
bn=sgn(
这个过程就是学习网络的参数
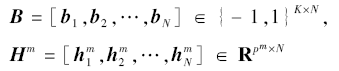
表示N个x数据点得到的哈希code和每个点在第m个网络层的输出.设计如下优化目标进行参数学习:
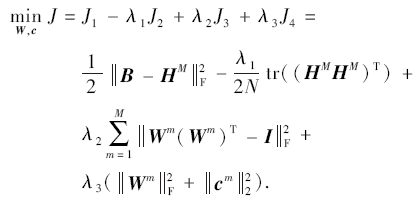
其中:J1项是为了减小量化过程中的误差; J2项是希望最大化方差; 第3项对于W的正交性条件有所放松, 但是为了使投影方向尽可能独立, 这一项应尽可能小; J4项用于控制参数规模.上式的优化采用随机梯度下降求解.
Liong等[26]提出监督的深度哈希方法, 即监督深度哈希方法, 利用训练样本的监督信息, 在上述优化目标中加入tr(Σ B-Σ W), 其中, Σ B表示类内方差, Σ W表示类间方差.
1.1.2 有监督哈希方法
Wang等[21] 提出的算法描述如下.输入数据X, 成对标记的数据Xl, 初始化的相似度矩阵S1, 哈希码长度K, 常数α .对于第k个比特位, 计算
Mk=XlSk
的第一特征向量, 并令wk=e.根据wk更新点对
Sk+1=Sk-α T
计算剩余:
X=X-wk
与监督方法的Boosting框架不同, 这种方法是一种半监督的框架, 目标函数使二值化精准度更大, 平等对待每个哈希函数, 而不是进行加权.同时, 在求完投影方向后, 除去那个方向张成的子空间以减小哈希码之间的冗余度.
Kulis等[27]提出二值重构嵌入方法, 优化目标为最小化输入特征距离和重构后的汉明距离的均方误差最小, 使用坐标下降的方法求解最优:先固定一个权重, 然后迭代更新哈希函数.进而更新一轮哈希b个函数, 直到收敛.
Shen等[28]提出新的监督哈希框架— — 监督离散哈希, 学习目标是得到用于线性分类的优化的二值编码.通过引入一个辅助变量, 重新引入正则化算法, 设计新的目标表达式.关键步骤是求解伴随NP难的二值问题的正则化子问题.文献表明子问题通过循环坐标下降具有解析解.进而在可接受的计算资源消耗的情况下, 得到高品质的离散解.
上述哈希学习的大多数方法都是学习一个单独的投影矩阵, 这种线性方法不能准确描述数据之间的非线性关系, 即使是基于核的方法也受到扩展性的约束.
Chen等[29]提出非线性的离散哈希算法, 用于大规模图像检索.如图2所示, 该方法采用统一的哈希学习框架同时优化非线性映射和离散量化.采用带有非线性映射的多层网络保持数据的局部结构, 从而取代大多数方法采用的单一线性映射.为了避免量化误差的累积, 直接求解离散优化的问题.特别地, 为了更好地保持数据的相似关系, 通过统一的优化目标学习有效的二值码:1)最小化样本点和学习得到二值码的量化误差; 2)保持学习得到的二值码的相似关系; 3)最大化每个比特的信息量; 4)最大化通过二值码预测得到的语义类标的准确率.
Chen等[30]提出对非线性相似性和图像结构编码为二值码的方法.与大多数已有的采用单一线性映射的方法不同, 该方法以多层神经网络的形式进
行非线性映射, 进而得到带有保存局部结构性质的二值码.在训练网络中, 控制量化误差最小并令所有比特的方差最大.除此之外, 为了提高模型对于新样本的泛化能力, 对网络加入稀疏的约束.手动标注的类标作为监督信息加入到学习过程中, 提高二值码的检索性能.
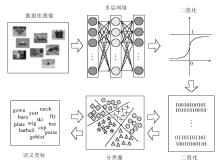 | 图2 非线性离散哈希示意图Fig.2 Flowchart of nonlinear discrete Hashing method |
近年来深度学习取得较大进展[31, 32].深度卷积神经网络可以学习得到鲁棒、有效的特征, 已成功应用在大量的计算机视觉任务中[31, 33].将深度卷积神经网络应用在哈希学习中也成为当前的研究热点[26, 34, 35, 36, 37, 38, 39].
Xia等[33]提出监督哈希学习方法用于图像检索.该方法同时学习得到好的图像表示和哈希函数.方法分为如下两步:1)对于基于点对的相似性矩阵S, 将S分解为HHT, 其中H的每一行是对图像哈希值的估计; 2)通过深度卷积神经网络同时学习得到好的图像表示和哈希函数.
Lai等[40]设计深度网络结构, 用于哈希学习.深度网络的学习过程分为3块:1)使用级联的深度卷积神经子网络学习得到有效的图像特征; 2)使用一个“ 分离编码” 的模块, 将图像特征分离到多个分支, 每个分支对应一个哈希编码; 3)设计一个三元组排序的损失函数作为目标函数指导网络的学习.
Liu等[38]设计一个输入为图像对、输出为离散二值码的网络.在网络顶层设计如下:1)利用类标监督信息使二值码判别能力最大化; 2)同时使实值特征与二值码之间的量化误差最小.在图像检索阶段, 检索的样本通过网络的前传再度二值化, 得到相应的二值码输出.
近年来, 视频检索成为相似性检索领域的研究热点之一[39, 41-50].与图像不同, 视频包含复杂的帧内底层视觉信息和不同帧之间的高层语义相关信息.视频的这一特性使得大规模的视频检索比图像检索更具挑战性.此外, 每个视频的大量帧数会导致计算资源的耗尽.因此, 如何设计学习框架提取视频中的判别信息在检索领域非常重要.
Yu等[45]提出对视频帧进行二值编码的模型.该模型只对视频的关键帧进行编码, 降低计算复杂度, 同时采用点对的监督形式对模型进行约束, 保证检索性能.
Ye等[43]提出基于结构学习技术的监督视频哈希学习方法, 同时提出关于结构正则化误差的最小化问题.结构正则化提取同一语义类标下的视频帧共有的视觉模式, 同时保持统一视频内的时序一致性.
Cao等[44]设计一个全新的视觉框架.与大部分使用单一的哈希值描述视频的方法不同, 作者采用多种哈希编码结合的方式描述视频中多样的视觉内容, 将池化和哈希学习2阶段结合到一个统一的框架中.在池化阶段, 不同的视频帧划分为不同的组件, 在哈希学习阶段, 不同的组件进行哈希编码然后结合.这种方式保存大量的信息, 为了加速检索的速度, 使用基于图的最大影响方法桥接池化和哈希学习两个阶段.
Hao等[22]提出一个随机多视角的哈希算法, 进行近似重复视频检索.通过最大化一族检索准确率和召回率的分数, 系统学习得到从视频帧特征到紧凑的二值码的可靠映射函数.特别地, 采用复合的KL散度随机对齐原特征空间和二值空间的邻域结
构, 估计检索分数.
Dong等[23]提出一个新的深度卷积神经网络, 学习得到具有判别性和紧凑的二值码, 进行人脸视频检索.该方法将特征提取和哈希学习结合到一个统一的框架中, 为了更好地初始化网络, 提出低秩判别哈希, 在训练阶段预先学习哈希函数.
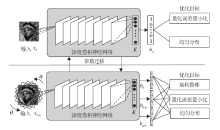
Liong等[47]提出基于深度网络的哈希方法, 用于视频检索.图3给出算法示意图.与大多数现有的对每一帧图像提取特征然后使用传统哈希技术进行编码的方法不同, 该方法通过一个深度学习的框架对整个视频进行二值码以同时利用时域信息和判别信息.特别地, 采用如下2个准则对不同帧的时域信息进行融合:
1)在顶层, 如果图像对是同类, 那么它们的特征距离应该相近, 反之应该尽可能远离;
2)最小化实值特征和二值特征的量化误差.
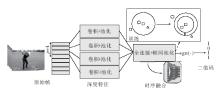 | 图3 深度视频哈希算法示意图Fig.3 Flowchart of deep video Hashing method |
Chen等[48]提出非线性的结构化哈希方法以进行大规模的视频检索.与当前将视频中的帧独立进行学习的方法不同, 该方法采用多层神经网络学习视频帧间的结构信息和不同视频之间的非线性结构关系.特别地, 网络在顶层加入2个限制以学习哈希二值码:
1)在一个视频中属于同一场景的帧的二值表达距离尽可能小;
2)同类的视频对的二值表达距离尽可能小, 不同类的距离尽可能大.
为了更好地从视频中学习得到结构信息, 子空间聚类视频中的帧进入不同的视频场景中.同时, 设计多层神经网络, 保持视频的非线性结构.
8种二值特征学习方法的特点对比如表1所示.
| 表1 哈希学习方法总结及对比 Table 1 Summary and comparison of different hashing methods |
特征学习是视觉分析的重要环节之一, 它的目标是精确、鲁棒地描述图像或视频中的视觉目标, 用于完成下面的分析任务.相比实值特征, 二值特征在匹配、存储方面表现出较强的高效性, 在多项视觉应用中受到广泛关注.
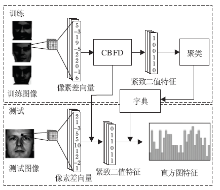
Lu等[5]提出一个紧致二值人脸描述子(Compact Binary Face Descriptor, CBFD), 用于人脸的表征与识别, 流程图如图4所示.通过计算每个像素与其相邻像素之间的差值得到像素差向量(Pixel Difference Vector, PDV), 作为每幅图像的初始特征, 再使用非监督的方法学习一个投影, 将其变为低维二值特征.其中损失函数包含3项, 分别对应最大化训练集二值特征的方差、最小化初始实值特征与二值特征的差别、二值特征均匀分布到每一位.进一步地, 通过减少异质人脸间在特征层次上由模态导致的差别, 使该方法适用于异质脸识别.
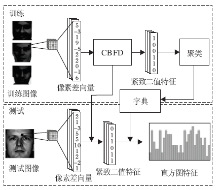 | 图4 紧致二值人脸描述子示意图Fig.4 Flowchart of compact binary face descriptor method |
Lu等[51]提出同时学习和编码局部二值特征的方法(Simultaneously Local Binary Feature Learning and Encoding, SLBFLE), 可以实现同类及异质人脸识别.与文献[5] 不同, 其同时学习局部人脸区域的二值特征及其字典, 只需一个阶段就能从图像的初始像素中提取具有判别力的二值特征信息.与之前的大部分方法不同, 该方法同时利用不同模态人脸样本中共同和特有的信息刻画异质脸的内在关系, 可以更好地实现异质脸识别.Duan等[52]提出具有旋转不变性的局部二值特征描述子(Rotation-Invariant Local Binary Descriptor, RI-LBD), 首先提取每个局部区域的旋转二进制模式(Rotational Binary Pattern, RBP), 再同时学习每种模式的方向及投影矩阵, 得到局部的二值特征描述子.通过在得到的二值特征上聚类以构建字典, 对于每幅图像得到直方图特征, 用作该图像的特征表示.Duan等[53]通过学习上下文联系的局部二值特征进行人脸识别, 通过限制二进制编码中不同位之间的跳变次数, 降低噪声带来的影响, 得到更鲁棒的二值特征.对于每幅图像, 计算得到每个局部区域的像素差向量, 并非监督地学习每个像素差向量到二值特征的投影, 使二值编码中相邻位之间跳变尽可能地接近1.与文献[5] 类似, 通过减少特征层次上的异质脸间包含的模态信息, 将该方法用到异质脸识别中.
除了进行人脸识别外, 二值特征学习方法还可以运用到其它的人脸分析任务中.Lu等[54]提出代价敏感的局部二值特征学习方法, 进行人脸的年龄估计, 通过学习一系列的哈希函数, 将人脸局部区域的原始像素投影为低维的二值特征, 使年龄差距小的样本的二值特征尽可能接近, 而年龄差距大的样本的二值特征尽可能相距较远.使用这些局部二值特征得到的每幅人脸的实值直方图特征作为人脸的表征, 进而通过从不同尺度的人脸图像中提取出的区域同时学习一系列哈希函数, 得到代价敏感的二值特征.Ren等[55]提出基于二值特征学习的回归方法, 实现高效准确的人脸对齐.首先使用回归随机森林独立学习一系列局部特征映射函数, 从人脸的每个特征点提取二值特征.继而使用这些二值特征及特征映射函数学习整体的线性回归矩阵, 通过形状回归实现人脸对齐.由于二值特征的计算简单性, 该方法的运行速度远快于之前的人脸对齐算法.
Gong等[56]使用双线性变换将高维的实值特征转化为二值特征.通过双线性变换可将大的旋转矩阵替换为两个更小的矩阵, 极大地降低空间与时间成本.通过改变双线性变换的两个矩阵的维数可以达到降维的效果, 将符号函数作用在旋转后的特征向量即可得到最后的二值特征.以降低变换后的实值特征与二值特征之间的距离为目标, 使用迭代的方式可学习双线性变换的两个矩阵.Babenko等[57]提出加法量化替代之前的乘积量化, 实现向量的压缩.与乘积量化不同, 加法量化使用的字典中向量长度与原始向量长度相同, 而优化目标为各个编码向量相加得到的和与原始向量尽可能相近.Xia等[58]提出一个学习稀疏投影矩阵的方法, 得到高维二值特征.与文献[56] 、文献[59] 和文献[60] 不同, 该方法不仅对投影矩阵有正交性的正则限制, 还增加稀疏性条件, 使投影矩阵中的非零元个数尽量少, 并迭代地学习这样的矩阵.增加稀疏性条件不仅能减少过拟合的情况, 也极大地降低计算成本.Shen等[61]提出离散近端线性最小化的优化方法, 直接处理优化目标中的离散型约束条件, 应用到一大类二值描述子的学习过程中.具体地, 将离散问题的优化目标看作一个光滑目标函数与不光滑的示性函数之和, 这样该问题可以通过迭代解决, 并且每一步迭代的
解具有解析形式, 极大地提升学习速度.
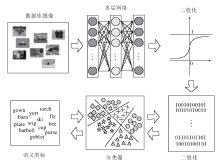
Lin等[6]提出深层网络, 可以非监督地学习紧致而又判别力强的二值特征描述子(DeepBit), 其将符号函数直接作用在网络输出的实值特征上, 得到最后的二值特征.网络结构及优化目标如图5所示.网络优化的目标函数具有三项, 第一项最小化二值特征与原始图像之间的量化误差, 第二项使二值特征尽可能均匀分布到每一位上, 最大化二值特征中能够包含的信息量, 而第三项最小化旋转后图像的二值特征与原始图像二值特征之间的汉明距离, 使得到的二值特征描述子尽可能地做到旋转不变.
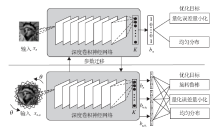 | 图5 深度二值描述子网络结构示意图Fig.5 Flowchart of DeepBit method |
图像匹配是指通过比对不同图像的特征以寻找相似图像的方法.由于二值特征的比对速度非常快, 所以在大规模图像匹配中应用非常广泛[62, 63, 64].但是, 由于描述能力与实值特征差距太大, 所以在使用上受到许多限制.近几年, 随着基于样本学习方法的提出, 二值特征的性能大为改善, 其中具有代表性的方法如下.
Huang等[65]提出基于带权重的鲁棒二值描述子的图像匹配方法.相比亮度, 梯度在图像的各种变换中具有更好的鲁棒性和描述能力, 作者摒弃传统的像素值逐一比对的采样方法, 提出基于圆形邻域的梯度的比对方法.为了保持图像的旋转不变性, 将图像旋转到其主方向后再进行二值描述子的提取.其次, 为了获得大规模二值描述子中最有描述能力的部分以减小二值描述子的规模, 通过计算每一位的得分, 从所有描述子中选择最能区分正负样本的位.同时, 通过最小化不同位之间的相关性, 使描述子整体的描述能力最强.最后, 通过最大化正样本和负样本之间的距离差学习不同位的实值权重, 使描述能力和鲁棒性强的位影响力更强.将带权重的二值描述子再一次二值化便可得到最终的鲁棒的二值描述子.
Balntas等[66] 提出高效的图像匹配的在线算法, 能同时减小类内距离并增大类间距离.算法主要步骤如下:1)在离线环境下找到使类间距离最大的描述子, 获得最有描述力的特征; 2)基于作者提出的相关性评分, 在离线环境下找到使内部相关性最小的描述子; 3)在前两步处理过后的特征的基础上, 找到使类内距离最小的描述子.由于前面两步在离线状态下限制描述子的长度, 所以第3步的复杂度大幅降低, 使其在在线环境下的效率大幅提高.
Trzcinski等[67]针对二值特征鲁棒性差的缺点, 提出高效投影算法.首先通过最小化相似关键点距离且最大化不同关键点距离, 将原始图像块投影到具有更强描述力的子空间, 且该投影由某一字典的元素线性组合而成, 字典的选取可以是箱滤波器、高斯滤波器或矩形滤波器, 运算速度更快.将投影结果二值化拼接后, 得到最终的二值特征.
Fan等[68]提出感受野描述子, 首先在原始图像的8个方向上提取各个方向的梯度信息作为原始的特征, 然后对原始特征采用特定形式的感受野(高斯感受野, 矩形感受野)进行池化, 最后通过对池化特征二值化进行图像匹配.其中, 作者通过选取合适的感受野大小使提取的池化特征既保留较多信息, 也尽可能去除特征内部的相关性.同时, 也通过最大化识别准确率的方式学习二值化的阈值.
Duan等[7]针对二值特征刚性量化时产生巨大量化误差的问题, 提出基于k个自编码器的量化网络.首先将样本输入预训练好的卷积神经网络, 再将提取的特征分别输入k个自编码器, 使用三项损失函数预训练各个自编码器.三项损失函数分别是特征方差最大、自编码器重构误差最小及神经网络权重约束.进行二阶段优化时, 先使用样本训练重构误差最小的自编码器, 再使用所有样本训练卷积神经网络.在测试阶段, 作者将样本的每一位编码成重构误差最小的自编码器的二进制编码, 得到二值特征.
视觉跟踪是指对于连续图像进行目标检测的方法, 旨在将目标和背景分离[69-71].由于检测任务对实时性要求较高, 所以近年来基于二值特征视觉检测方法发展迅速, 具有代表性的方法如下.Li等[72]针对视觉跟踪中准确率与计算效率低下的问题, 提出基于二值码的追踪方法.首先通过随机决策树的生长计算样本之间的相似度, 并基于相似度对提取的特征进行二值化.由于树具有层级结构, 所以能够提取样本中的分层信息, 提高描述能力.同时, 由于基于不同的子数据集进行随机采样, 故可以消除特征内部的相关性.然后, 引入基于最小平方误差的支持向量机, 判断图像中的某一部分是否是目标物体.最后, 作者采用超图传播的方法寻找样本之间的上下文信息, 获得更好的追踪效果.Parkhi等[8]提出使用紧致二值描述子的人脸追踪方法.首先使用Fisher矢量编码图像的原始特征(预处理可使用SIFT等方法), 然后通过度量学习的方式找到最佳投影矩阵, 最后对投影后的结果进行二值化后, 便可使用特征进行人脸跟踪.
6种二值特征学习方法的特点对比如表2所示.
| 表2 二值描述子学习方法总结及对比 Table 2 Summary and comparison of different binary descriptor learning methods |
本文总结面向视觉表示的二值表征学习的最新进展, 给出其在搜索、识别、分类、匹配和跟踪中的应用.面对视觉大数据, 哈希学习和二值特征学习利用二值表征在存储、传输和匹配的高效性, 显著提高系统处理大数据的效率.综上所述, 已有大量工作对二值表征学习进行探索研究, 并已在多项视觉应用中取得初步成效.随着视觉大数据持续爆炸式增长, 视觉表示的高效性将会受到进一步的挑战.因此, 如何将二值表征学习拓展到更多的应用场景, 解决传统方法面对视觉大数据难以克服的问题, 是非常有意义的研究方向.
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|
| [44] |
|
| [45] |
|
| [46] |
|
| [47] |
|
| [48] |
|
| [49] |
|
| [50] |
|
| [51] |
|
| [52] |
|
| [53] |
|
| [54] |
|
| [55] |
|
| [56] |
|
| [57] |
|
| [58] |
|
| [59] |
|
| [60] |
|
| [61] |
|
| [62] |
|
| [63] |
|
| [64] |
|
| [65] |
|
| [66] |
|
| [67] |
|
| [68] |
|
| [69] |
|
| [70] |
|
| [71] |
|
| [72] |
|
| [73] |
|