




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
低秩矩阵近似与优化问题研究进展
[张恒敏1  , 杨健
, 杨健1 , 郑玮1 ]
, 杨健, 郑玮]
|
|




作者简介:张恒敏,博士研究生,主要研究方向为统计机器学习、非凸优化算法.E-mail:zhanghengmin@126.com.

郑 玮,博士,讲师,主要研究方向为机器学习、特征选择.E-mail:zhengwei@jit.edu.cn.
首先以高维数据压缩与恢复为背景,详细阐述由香农采样理论到稀疏表示和压缩感知理论再到低秩矩阵问题的发展历程,引出低秩矩阵近似与优化问题的重要性.然后,从低秩矩阵最小化问题、低秩矩阵分解问题、低秩矩阵的优化与应用三方面对现有方法进行详细的综述.最后对当前研究的不足之处与未来的研究方向提出合理的建议.
About the Author:ZHANG Hengmin, Ph.D.candidate. His research interests include statistical machine learning and nonconvex optimizations.
ZHENG Wei, Ph.D., lecturer. Her research interests include machine learning and feature selection.
Based on the compression and recovery of high-dimensional data, the development process from the theory of Shannon sampling to sparse representation and compression perception and then to low-rank matrix problem is described. Then, the importance of low rank matrix relaxation and optimization problem is discussed. Subsequently, a detailed review of the existing methods is introduced from three aspects of low rank matrix minimization, decomposition, optimization and applications. Finally, some reasonable suggestions on the deficiencies of current research and the future research direction are put forward.
众所周知, 大规模的高维数据在科学、工程及日常生活中日益剧增, 这为许多学科及领域的发展, 如计算机视觉、模式识别、数据挖掘、机器学习和智能优化等, 带来巨大的机遇和严峻的挑战.在这些领域中, 有的数据的维数成千上万甚至高达数亿, 有时样本的个数也达到几乎同样的数量级.在这些大规模的高维数据中, 一方面含有丰富的信息以供挖掘利用, 另一方面也大幅增加学习和研究这些数据带来的成本和困难, 即“ 维度灾难” [1].
在实际的信号、图像或视频采集与处理过程中, 数据的维度越高, 数据的采集和处理的要求与约束更高.归结原因主要包括:1)高维数据内部或相互之间往往存在较多的相关性和冗余性; 2)数据本身信息量的增长通常慢于数据维度的增长, 使数据变得冗余.对于最初的香农采样理论[2], 其核心思想是为了能准确地恢复原始信号, 需要采样频率不小于原始信号频谱中最高频率的两倍.为了满足这种采样方式, 需要对传感器等许多采集设备提出更高要求.其基本流程是需要预先收集大量的数据, 然后通过数据压缩的方式[3]去除数据中存在的大部分冗余信息, 只保留和存储那些重要的信息.然而, 香农采样理论的信息编码过程和解码过程会产生2个不希望得到的结果:1)先采样后舍弃冗余数据的采样方式会导致大量采样数据的浪费; 2)若压缩数据的过程中丢失部分数据会导致重建后的信号失真, 降低信号的编码效率.
为了克服香农理论对信号采样和压缩过程的苛刻要求, 需要充分考虑高维数据处理过程中存在的内在相关性和某些先验信息.如自然界中的信号通常不够稀疏, 但当把它变换到某个域 (如小波域和傅立叶域)时通常会使得到的变换系数呈现稀疏分布[4].换言之, 这些系数中存在大部分为零或接近零的数值, 只存在极少部分较大的系数值, 即非零数值.一个自然的问题是, 如何合理和充分利用这些高维数据中存在的稀疏性, 高效采集、表示和重构这些数据, 发挥稀疏性带来的作用.为了解决这个问题, 学者们提出稀疏表示[5-6]和压缩感知理论[7-8], 为数据采集技术和压缩技术带来革命性的突破和新的研究思路, 引起众多学科领域的广泛关注, 成为信息科学研究领域中的热点问题之一.
简而言之, 稀疏表示理论的核心思想是指有意义的信号在适当选取的一组过完备基(或字典)下, 可以只用其中少数几个基线性表示, 进而通过表示系数向量的稀疏性刻画原始信号.而压缩感知理论的核心思想是指只要信号稀疏, 就可以使用一个与变换基不相关的测量矩阵将高维信号投影到一个低维空间上, 进而通过求解一个最优化问题以较大概率从这些少量的投影中重构原始信号.最主要的是, 无论是稀疏表示理论还是压缩感知理论, 都需要充分利用信号的的稀疏性, 达到降低采样所需的采样率, 从而保证准确地重构原始的信号.特别地, 两种方法都需要信号的稀疏性这个基本假设, 从而产生一个非自适应采样过程, 便于实现对信号的压缩.为了便于解释说明, 给出k-稀疏的定义[9]如下.
定义 1 称某信号是k-稀疏的, 如果有n维的信号y∈ Rn最多只有k个元素不为零, 即‖ y‖ 0≤ k; 或者如果信号y本身不稀疏, 但存在某个变换域A, 使得y=Ax且‖ x‖ 0≤ k.
从数学意义上讲, 稀疏性通常反映向量或矩阵中非零元素的个数, 即由对应向量或矩阵的l0范数 (‖ x‖ 0=
与此不同的是, 稀疏表示理论和压缩感知理论一般是将非凸的l0范数优化问题转化为凸松弛的l1范数优化问题[10], 这里l1范数反映向量或矩阵中所有元素的绝对值之和.现有的理论如矩阵的等距性条件和压缩传感重建条件[17-19]已表明如果信号足够稀疏, 那么l1范数最小化方法就能以较高概率恢复原始信号.
为了进一步求解l1范数的最小化问题, 在凸优化领域也相应提出许多基于l1范数的求解算法, 如l1-ls算法[20]、同伦算法[21]、梯度投影法[22]、Bregman迭代法[23, 24]、收缩阈值算法[25, 26]、NESTA算法[27]及交替方向乘子法[28, 29].另外, 基于这些算法的一系列改进算法及变种也相继提出, 目的是提高稀疏恢复的精度和通过减少迭代次数以提高计算的效率.由于解决的是一类凸优化模型, 这些算法通常会保证得到全局的最优解.
从定义可知, l1范数过分地惩罚向量或矩阵中的每个元素, 而l0范数比较平等地对待每个元素, 因此l1范数作为l0范数的凸松弛会产生一个有偏的估计.然而, 基于l0范数松弛的正则函数只需满足3个基本准则[30]:无偏性、稀疏性和连续性, 才能更好地近似l0范数.不少学者提出一些非凸的近似函数以放松l0范数, 如lp(0< p< 1)范数[31-32]、极大极小凹进函数(Minimax Concave Penalty, MCP)[33]、平滑剪断绝对偏差函数(Smoothly Clipped Absolute Deviation, SCAD)[34]、封顶l1范数[35]、指数型的处罚函数(Exponential-Type Penalty, ETP)[36]、格曼函数[37]和拉普拉斯函数[38] .其具体表示形式可参考文献[39]和文献[40].由上可知, 上述非凸函数满足3个基本准则, 而且在信号恢复、误差更新和图像处理等问题中, 大量的数值实验也显示l0范数的非凸近似函数得到解的质量通常会优于凸的l1范数近似.
为了更好地求解这些非凸的l0范数近似优化问题, 上文提到的许多l1范数的求解算法也被相继推广或改进, 目的是解决此类非凸问题.这里需要注意两点:1)对比凸近似问题, 非凸近似问题会得到更稀疏的解; 2)非凸问题的求解通常只能得到若干局部解, 而全局收敛性也很难得到保证.有学者发现几乎所有的非凸近似函数具有一个共同点, 即满足Kurdyka-Lojasiewicz (KL)性质[41, 42].事实上, 具有KL性质的函数主要分为3类:1)实解析函数, 如最小二乘方函数和逻辑斯谛函数; 2)半代数函数, 如l0范数, lp范数, MCP和SCAD; 3)次解析函数, 如对数求和函数.此外, 有限个半代数函数之和或乘积仍是半代数函数.特别地, KL性质对给出非凸优化算法的收敛性分析的作用极其重要.正是这些高效的优化算法可以解决无论是凸的还是非凸的数学模型, 才使得稀疏表示和压缩感知理论在人脸识别[32, 43, 44]、字典学习[45]、图像处理[46, 47]和深度学习[48, 49]等方向具有成功的应用.
近年来, 稀疏表示和压缩感知理论无论是在数学建模、优化求解还是在实际应用中都取得巨大的成功, 其本质思想是利用信号对应向量或矩阵的稀疏性对信号进行采集和重建.然而要对现实中的信号如图像和视频实现有效压缩, 必须考虑图像和视频在时间或空间上的相关性.如经典的Netflix挑战问题, 必须通过利用用户喜好的相关性和视频类别的相关性推断未知的用户评价.面对诸如此类的数据, 如果按照向量的稀疏性刻画, 就需要把它们按照一定方式拉成向量进行处理, 这势必会破坏数据内在的结构, 导致相关性等信息无法充分利用.于是学者们就自然面对着一个问题:如何度量矩阵的稀疏性?也就是如何充分利用图像或矩阵的行之间或列之间的相关性? 矩阵的秩正好能反映这种相关性, 即二阶矩阵的稀疏性.自然而然地, 向量的稀疏性可成功推广到矩阵的低秩特性上.事实上, 秩早已用于统计学中的减秩回归[50]和三维立体视觉[51]等众多领域与秩相关的数学模型.因此与向量稀疏性密切相关的就是矩阵的相关性, 它本质上就是指其奇异值向量的稀疏性.从数学意义上讲, 矩阵的秩反映矩阵列(行)向量极大无关组的个数.为了便于解释说明, 也给出低秩矩阵[52]的定义如下.
定义 2 称某矩阵是低秩的, 如果矩阵Y∈ Rm× n的秩远小于矩阵的行数或列数.这里对于秩为r的矩阵Y, 奇异值分解可以表示为
Y=
σ i、ui和vi为对应的奇异值和奇异向量.低秩矩阵的集合表示为
Ω ={Y∈ Rm× n∶ r=rank(Y)≤ max(m, n)}.
注意到定义1与定义2在表述上有一定的差异, 但其本质上是一脉相承, 具有紧密的联系.之所以较大篇幅地介绍稀疏表示和压缩感知相关的理论, 是因为基于这些介绍的l0范数的近似问题、优化及其相关应用、关于低秩矩阵的秩最小化问题的相关理论可以从中推广并发展.特别是稀疏表示理论到矩阵秩最小化理论的拓展(如l1范数到核范数).
与l0范数的最小化问题类似, 秩函数不仅具有非凸性和不连续性这2个基本性质, 而且其最小化问题也是NP-难, 直接求解非常困难.不同于使用l1范数近似l0范数, 这里通常使用凸的核范数[52, 54-55]作为秩函数的替代, 并且相关的理论已证明在某些特定的假设条件下求解核范数最小化问题得到的解就是秩函数最小化问题得到的解.之所以选择核范数作为秩函数的替代, 主要是因为核范数是秩函数最紧的凸包, 目的是使NP-难的问题转化成为凸问题, 便于解决, 可以得到全局的最优解.但是当矩阵的奇异值较大时, 从秩函数与核范数的定义看, 后者过分的放松使其不能更准确地估计矩阵的秩.
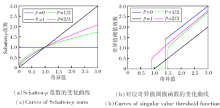
除核范数, 秩函数还有许多其它非凸的近似形式, 以最常用的非凸近似函数Schatten-p范数[44, 56-57]为例, 当p值等于1时, Schatten-p范数就是矩阵的核范数, 因此Schatten-p范数更一般.
从图1(a)可看出, 不同的p值反映Schatten-p范数与秩函数和核范数的逼近程度, 值越小, 越接近秩函数, 产生的偏差越小.反之, 随着p值的变大, 偏差也随之变大.(b)为基于Schatten-p范数奇异值阈值算子[31, 44, 58]得到最终解的变化曲线, 仍然与p值的选取有很大的关系.
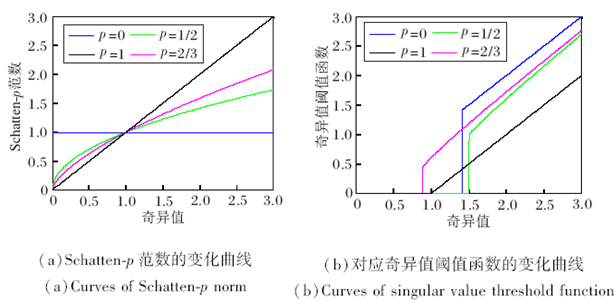 | 图1 Schatten-p(p=0, 1/2, 2/3, 1)范数与对应奇异值阈值函数的变化曲线Fig.1 Curves of both Schatten-p norm and its singular value threshold function with p=0, 1/2, 2/3, 1 |
此外, 除了使用矩阵的奇异值定义Schatten-p范数, 事实上, 它还可以通过矩阵本身定义为tr(
表1列出4种常见的非凸秩近似函数.从截断核范数[62]的表示形式可看出, 定义min(m, n)-r个最小奇异值的和.特别地, 当r=0时, 截断核范数就变成核范数.其核心思想是矩阵的秩在求解过程中主要受较小奇异值变化的影响, 而较大奇异值的变化不会影响矩阵的秩.与前面提到的非凸近似函数类似, 截断核范数同样能更好、更准确地近似秩函数.从封顶核范数[35]的形式可以看出, 如果θ 小于得到的所有奇异值, 那么矩阵的核范数就是矩阵的秩, 与核范数之间存在某种等价关系[63].除了表中提到的核范数, max范数是另一种用到的凸近似函数[64].另外, 秩函数与核范数的关系类似于l0范数和l1范数的关系, 不同之处在于, 前者反映矩阵奇异值向量的稀疏性, 后者反映向量本身的稀疏性.如l0范数的一些非凸近似函数可以进一步推广到近似秩函数中[39-40].
| 表1 几种常见的非凸秩近似函数 |

不同于前述的秩函数的凸近似和非凸近似方法, 本节主要介绍低秩矩阵分解的几种近似方法.这在稀疏表示和压缩感知的常用模型中是没有的.具体做法是把需要求解的低秩矩阵直接分解为2个子矩阵或多个子矩阵的乘积, 这里以2个子矩阵乘积为例, 要求第一个矩阵的列数等于第二个矩阵的行数, 并且是所期望矩阵的秩, 然后再交替迭代第一个子矩阵和第二个子矩阵, 直至不再变化为止.到目前为止, 了解到几个低秩矩阵分解的例子大多都是基于凸的核范数和非凸的Schatten-p范数展开研究, 其中具有代表性的表示形式如下.
1)核范数.对一个尺寸为m× n的低秩矩阵X, 当m≥ n时, 对应奇异值分解的计算复杂度为O(mn2); 当秩为r时, 计算复杂度至少为O(rmn).这里记低秩矩阵X分解为2个子矩阵的形式为f(U, V), 3个子矩阵的形式为 f(U, W, V), 则有
(1)如文献[65]所述,
f(U, V)=UVT, U∈ Rm× d, V∈ Rn× d, d≥ r=rank(X).
如果U为正交的列矩阵, 即UUT=I, 那么
‖ UVT‖ * =‖ V‖ * .
(2)如文献[66]所述,
f(U, V)=UVUT, U∈ Rm× d, V∈ Rd× d, d≥ r=rank(X),
X为低秩对称的正半定矩阵, V为对称的正半定矩阵, U为正交的列矩阵, 那么
‖ UVUT‖ * =‖ V‖ * .
(3)如文献[67]所述,
f(U, W, V)=UWVT, U∈ Rm× d, W∈ Rd× d, V∈ Rd× d, d≥ r=rank(X),
U和V都是正交的列矩阵, 那么
‖ UWVT‖ * =‖ W‖ * .
(4)如文献[68]所述, 对一个秩为r且尺寸为m× n的低秩矩阵X, 如果d≥ r, 定义U∈ Rm× d和V∈ Rn× d, 那么
‖ X‖ * =
2)Schatten-p范数.分解的形式主要包括
(1)如文献[69]所述, 当p=2/3时,
‖ X‖ FN=
(2)如文献[69]所述, 当p=1/2时,
‖ X‖ BiN=
(3)如文献[70]所述, 当p=1/3时,
‖ X‖ TriN=
更一般地, 对任意p值的Schatten-p范数[71], 表示形式如下
‖ X‖
其中, 1≤ i≤ M=(⌊1/p」+1), ⌊1/p」是指不超过1/p的最大整数, ∏ 表示矩阵之间的乘积运算, Mp> 1.注意到这里的子矩阵并没有正交阵的要求, 重点是子矩阵的尺寸要小于原矩阵的尺寸, 从而降低矩阵运算的计算复杂度.但是, 存在的一个基本问题是在求解低秩矩阵问题时需要事先估计低秩矩阵秩的上界d.此外, 凸的max范数[64] 相应的矩阵分解形式如下:
‖ X‖ max=
许多学者运用各种数学工具建立不同的模型(凸或非凸)及其相应求解算法, 大致可以分为:基于低秩矩阵最小化方法的优化算法和基于低秩矩阵分解的优化算法.
类似于l1范数在稀疏表示和压缩感知理论中的角色, 基于核范数的最小化问题在低秩矩阵恢复方面也引起许多学者的研究兴趣.需要指出的是, 在求解秩函数的最小化问题中, 奇异值阈值算子非常重要, 而且可以得到它的闭式解[44, 58], 否则可以通过加权的形式得到加权核范数的阈值算子的闭式解[40, 59].
凸优化已是较成熟的领域, 这里重点介绍加速近邻梯度法(Accelerated Proximal Gradient Method, APG)和交替方向乘子法(Alternating Direction Me-thod of Multipliers, ADMM).APG主要针对无约束凸问题, 要求目标函数可微且梯度Lipschitz连续, 通常设计的梯度下降法的收敛速度只能达到O(k-1), k为迭代次数, 但是通过Nesterov技术[72]可以构造一个加速版本— — 收敛速度为O(k-2)的算法[26].继而有学者将其推广到目标函数为一个凸函数和一个连续函数和的情形, 大幅扩展Nesterov算法的应用范围, 进一步提出使用动态估计的Lipschitz系数, 目的是加速收敛, 也推广到核范数正则化的最小问题求解上[73, 74].对于带线性约束的优化问题, 可以把约束的平方项放到目标函数里作为惩罚项[75], 再应用APG求近似解, 为了加快收敛速度, 惩罚系数应用连续的技术逐渐增加到较大的值.
ADMM针对目标函数可分解(如2个不同变量凸函数的和)、带线性约束和凸集约束的问题, 首先构造问题的增广Lagrangian函数, 然后通过交替极小化增广Lagrangian函数更新2个原始变量, 最后更新Lagrangian乘子, 如此持续迭代, 直至收敛.其优点是更新变量子问题时要比直接求解原问题简单, 甚至有闭式解.特别地, 在子问题不易求解的情况下, 可以考虑线性化的交错方向法(Linearized Alternating Direction Method of Multipliers, LAD-MM)[76].如果线性化增广Lagrangian函数的增广项还不足以导致足够简单的子问题, 还可以进一步把目标函数的光滑成分也线性化.对多变量 (变量数大于2)的凸规划问题, 简单地套用2个变量的ADM不能保证收敛[77] .
目前大量的实验表明, APG和ADMM在解决凸优化问题时取得巨大的成功, 具有全局收敛性的保证[26, 74, 78].然而这些算法却不能直接推广到解决一些非凸优化问题, 主要是因为凸性的缺少导致收敛性很难得到保证.现存的非凸优化算法主要有迭代重加权的算法[40, 59]、极大极小值算法[79]、迭代软阈值算法[80]和DC规划算法[81].这些算法主要思路是先把非凸问题转化为一系列可解凸优化问题以得到最终的解.需要指出的是, 这些算法收敛性分析大多只证明迭代得到的目标函数单调下降或得到的变量序列的子序列收敛到一个鞍点, 并未建立一个全局的收敛性分析结果.由于涉及到矩阵的奇异值分解, 这些算法在解决大规模问题时, 需要较高的计算复杂度和较多的迭代次数.针对此问题, 研究人员已取得一些工作进展, 具体如下.
1)保证算法的全局收敛性.大多数凸及非凸的函数满足KL性质, 这对证明非凸优化算法的全局收敛性的作用极其重要.基本证明思路是先保证目标函数单调下降, 接着证明得到变量序列的子序列收敛到一个极限点(鞍点), 再证明得到的目标函数和变量序列满足一致KL基本假设, 最后证明得到的变量序列是一柯西列.这一基本思路已在许多优化算法中得到广泛应用, 如迭代重加权的算法[82]、加速近端梯度法[83, 84]和交替方向乘子法[85].
2)降低计算复杂度.通过将大尺度矩阵分解为两个或多个子矩阵的乘积, 以便进行较小尺度矩阵的计算, 更好地近似秩函数, 如对核范数及Schatten-p范数的分解.相比秩最小化问题的优化, 会引入更多的变量, 导致收敛性很难得到保证[77].然而, 在给出一些辅助的假设条件下, 可以证明得到的变量序列满足KKT条件, 也能进一步证明变量序列是一个柯西列.另外, 学者们提出一些随机的算法, 如快速随机奇异值阈值算法[86].
3)减少迭代次数.这是另一个提高计算效率的方式, 而且Nesterov'加速策略及其变种对降低迭代次数发挥重要作用.常用的APG算法首次推广到解决非凸的优化问题[83].相继提出相应的改进版本, 如非精确的近段梯度算法[87]、动态近端端梯度法[84]以及一些在线的、随机的梯度优化算法[88-89]的一些相关的变种.
众所周知, 近年来低秩矩阵模型在机器学习和计算机视觉等领域应用广泛, 主要是基于凸核范数及非凸秩近似函数在低秩矩阵恢复问题上的数学建模, 如矩阵回归模型[43-44, 78]在人脸识别与重建中的应用、矩阵补全[55, 59]在图像部分缺失和协同滤波中的应用、稳健主成分分析[63, 90]在背景建模及人脸建模中的应用、低秩矩阵表示[91-92]在子空间分割和聚类中的应用.本节为进一步加强可读性, 结合作者的相关研究工作, 给出上述文献中的部分图例, 表明凸核范数或非凸秩近似函数在一些应用问题上的优越性.
基于l1范数和l2范数的稀疏表示和协同表示模型在人脸识别中取得极大成功, 其中l1范数和l2范数对残差项的刻画主要体现在对稀疏噪声和高斯噪声的度量, 然而它们不能很好地描述残差项的二维结构, 忽略相关性.核范数作为秩函数的近似可以反映残差图像像素间的相关性.为此文献[43]和文献[44]给出基于核范数正则化的矩阵回归模型, 不同点是文献[43]选择使用l1范数作为系数刻画, 而文献[78]选择使用l2范数作为系数刻画.更一般地, 文献[78] 给出基于Schatten-p范数与lq(q=1, 2)范数的矩阵回归模型, 并验证p=2/3, 1/2的情形要比p=1的情形取得更好的识别性能, 特别是受到较大比例块状遮挡和较严重光照污染, 如图2所示.
 | 图2 部分受光照和遮挡污染的人脸图像Fig.2 Some face images corrupted by illuminations and occlusions |
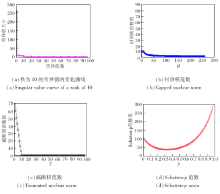
矩阵补全问题是指给定一个只观测到部分元素的矩阵, 然后根据这些已知元素及其在矩阵中的位置推测矩阵中的未知元素.显然, 若对矩阵不加任何约束, 该问题不可解.通常假设矩阵具有低秩特性, 对应的优化问题就是矩阵的秩函数极小化问题.为此基于凸及非凸近似和分解的近似函数和相应优化
算法应运而生.常见的秩函数不同逼近形式(表1)的对比如图3所示.由图可见, 相比截断核范数, 封顶核范数和Schatten-p范数更准确逼近真实矩阵的秩, 而且基于这些近似函数的矩阵补全问题在图像修复、数据降维和推荐系统等方面的应用前景极其广阔.如图像复原, 对于有缺失信息的Tinny图像, 图像补全结果的对比如图4所示.
 | 图3 常见的秩函数逼近形式的对比Fig.3 Comparison of popular rank relaxations |
 | 图4 图像补全结果对比Fig.4 Comparison of image completion |
稳健主成分分析是指将输入数据分为低秩部分和稀疏部分, 这在背景建模和人脸建模中具有重要的应用.通常是将已经对齐的每帧或每幅图像拉成向量, 保证得到具有低秩结构的背景视频或人脸图
像, 而具有稀疏结构的部分可以指视频前景中移动的物体或人脸图像中含有的稀疏噪声, 如光照和阴影.图5和图6分别是对监控视频背景建模和受光照变化得到的部分恢复结果, 这里都是许多数学模型基于低秩假设得到的背景建模结果.
 | 图5 视频监视的背景建模Fig.5 Background modeling for video surveillance |
 | 图6 受光照污染的Extended YaleB 数据集部分图像Fig.6 Illuminated face images of partial Extended YaleB dataset |
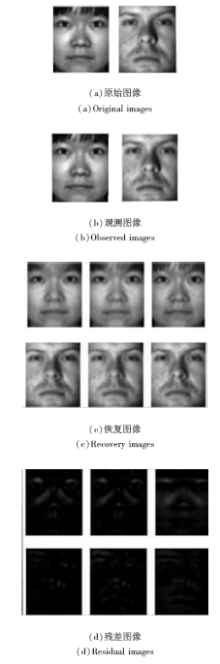
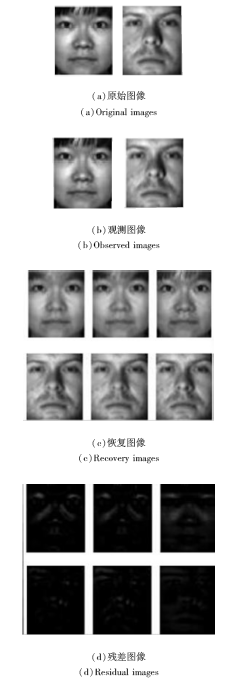
低秩表示模型可看作是将稳健主成分分析从数据中提取一个子空间的情形推广到提取多个子空间情形的常用方法, 认为是稳健主成分分析的更一般形式.具体地, 低秩表示模型需要一个基本假设, 即有充足的数据和相互独立的子空间, 为了增强表示系数矩阵各列之间的相关性以达到提高对不同噪声的抵抗能力, 要求对表达系数进行低秩约束.因此, Chen等[92]提出稳健的低秩表示模型, 其特点是给出对不同残差的一般刻画, 即F-范数诱导的加权形式.与之不同的是, Zhang等[93]选择使用Schatten-p范数刻画表示系数矩阵, 并给出Schatten-p范数的分解形式, 建立基于Schatten-p范数最小化及分解的低秩表示模型.文献[92]和文献[93]是对文献[91]的一般推广, 相比其它方法, 文献[92]在处理如围巾和眼镜等受遮挡及光照变化的图像时, 可以更好地恢复污染图像, 如图7所示.图中包括原始图像、恢复图像、辅助变量产生的图像以及得到的残差图像.文献[93]在扩充YaleB数据集 (选择10类) 上得到的具有块对角结构的表示系数矩阵如图8所示, p=1, 2/3, 1/2.
除上述介绍的应用外, 低秩矩阵恢复问题不仅可以推广到三维张量[94], 而且还可在图像处理和计算机视觉等领域有着其它典型的应用, 如图像去噪、图像分割、运动分割、显著性检测、变换不变低秩纹理等.具体可参考相关文献[63]、文献[95]~文献[97].
 | 图7 恢复受污染的AR数据集部分图像Fig.7 Recovery of corrupted face images of partial AR dataset |
 | 图8 基于Schatten-p范数最小化与分解的低秩表示模型产生的具有块对角结构的相似矩阵Fig.8 Similarity matrices with block-diagonal structures generated by Shatten-p norm minimization and decomposition based low rank representation models |
基于低秩的数学模型是近年来稳健高效处理高维数据的新工具.伴随着稀疏表示和压缩感知, 低秩矩阵恢复的方法已引起越来越多研究者的的重视.关于秩函数的凸和非凸近似函数以及大量有效的优化算法不断被提出, 并被用于解决一些实际的问题.最重要的是, 关于这些算法或模型的理论性分析也取得有意义的成果, 特别是非凸优化算法全局收敛性的分析.同时, 目前一些与秩相关的问题还需进一步的研究.
1)非凸近似问题相关理论.目前的低秩数学模型理论主要基于核范数展开, 相比核范数, 非凸的近似函数可以更好地近似秩函数.此外, 非凸优化问题求解的全局收敛性分析仍是一个急需解决的难题, 这是因为在实际应用中, 往往希望得到更准确的解而不是某个局部解.
2)大规模数据处理问题.受深度学习的推动, 处理大规模数据成为近年较热门的话题.但是在现有的硬件条件下, 如何降低算法的计算复杂度以及加快算法收敛率是对矩阵奇异值分解亟待解决的问题.这就迫使研究人员在保证恢复精度无损失的前提下, 提出一些在线、分布式或随机的优化算法, 解决一些与低秩矩阵数学模型相关的大规模优化问题.
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|
| [44] |
|
| [45] |
|
| [46] |
|
| [47] |
|
| [48] |
|
| [49] |
|
| [50] |
|
| [51] |
|
| [52] |
|
| [53] |
|
| [54] |
|
| [55] |
|
| [56] |
|
| [57] |
|
| [58] |
|
| [59] |
|
| [60] |
|
| [61] |
|
| [62] |
|
| [63] |
|
| [64] |
|
| [65] |
|
| [66] |
|
| [67] |
|
| [68] |
|
| [69] |
|
| [70] |
|
| [71] |
|
| [72] |
|
| [73] |
|
| [74] |
|
| [75] |
|
| [76] |
|
| [77] |
|
| [78] |
|
| [79] |
|
| [80] |
|
| [81] |
|
| [82] |
|
| [83] |
|
| [84] |
|
| [85] |
|
| [86] |
|
| [87] |
|
| [88] |
|
| [89] |
|
| [90] |
|
| [91] |
|
| [92] |
|
| [93] |
|
| [94] |
|
| [95] |
|
| [96] |
|
| [97] |
|
| 98 |
|