



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
人脸画像合成研究的综述与对比分析
[王楠楠1 , 李洁1  , 高新波
, 高新波1 ]
, 高新波]
|
|




作者简介:李 洁,博士,教授,主要研究方向为模式识别、计算机视觉.E-mail:leejie@mail.xidian.edu.cn.

高新波,博士,教授,主要研究方向为多媒体分析、机器学习、计算机视觉.E-mail:xbgao@mail.xidian.edu.cn.
人脸画像合成通常是在给定一些训练画像-照片的前提下,将一张输入的人脸照片转换为画像的过程.目前并没有一个系统性的实验对比分析揭示当前此过程面临的挑战以及可能的解决思路.文中对具有代表性的各类方法进行综合深入对比与分析.人脸画像合成方法归纳为2类:数据驱动类方法(即基于样本的方法)和模型驱动类方法.数据驱动方法由3类方法组成:基于子空间学习的方法、基于稀疏表示的方法和基于贝叶斯推断的方法.模型驱动方法直接学习照片到画像的映射关系.文中给出一些之前文献中并未发现的有意义的结论和展望.
About the Author:LI Jie, Ph.D., professor. Her research interests include pattern recognition and computer vision.
GAO Xinbo, Ph.D., professor. His research interests include multimedia analysis, machine learning and computer vision.
Face sketch synthesis refers to generating a sketch from an input face photo with some face sketch-photo pairs as the training set. An experimental study on the existing methods is nontrivial. The comprehensive review and the comparative study on representative face sketch synthesis methods are conducted. These methods are grouped into two categories: data-driven methods, also known as exemplar-based methods, and model-driven methods. Generally, data-driven face sketch synthesis consists of three sub-categories: subspace learning-based methods, sparse representation-based methods and Bayesian inference-based methods. Model-driven methods explicitly learn the mapping from face photos to face sketches. Some previously unknown conclusions are drawn as well.
人脸画像合成是指将一幅照片转换为画像的过程, 通常利用事先收集好的人脸画像-照片对作为训练集.它在辅助刑侦追捕[1]及数字娱乐方面具有重要作用.以辅助刑侦追捕为例, 监控视频中得到的人脸往往因为分辨率低、侧面、光照变化、遮挡等原因使获得的人脸图像无法直接用于人脸识别, 有时甚至无法得到监控图像信息.这种情况下法医画家根据有限的视频监控信息或目击者的描述手绘的模拟画像就成为破案的关键线索.人脸画像合成目的是减少画像和公民照片数据库中图像的巨大纹理差异, 即将公民照片数据库中的照片一次性转换为画像(得到公民画像库), 进而可将模拟画像与转换后的公民画像库进行常规的人脸识别.值得一提的是由人脸照片合成人脸画像的逆过程, 即由画像合成照片也成立, 一般而言, 人脸画像合成算法中交换画像和照片的角色即可得到人脸照片合成算法.
早期人脸画像合成集中在使用图像处理方法生成简单的线条画[2]和漫画[3, 4].这些线条画和漫画因独有的个性较容易被人类识别, 但是对于计算机而言可能是一个非常艰巨的任务, 进而基于线条画或漫画进行人脸识别变得非常困难.本文主要探讨素描画像(文中简称为画像)的合成.人脸画像合成引起人们的注意始于2002年香港中文大学汤晓鸥教授课题组[5]利用主成分分析进行人脸画像的构建.该方法将测试照片投影到训练照片集上, 得到投影系数, 然后使用得到的系数对训练画像进行现行组合, 得到最终的合成画像.考虑到主成分分析是对图像整体进行线性投影变换, 难以合成细节信息, 继而相继出现基于“ 分段线性” 和“ 分段非线性” 思想模拟整体非线性的工作.“ 分段线性” 是指将整幅图像分成图像块, 单个图像块的重构仍然是线性的, 但对于整幅图像而言是非线性的, 代表性的工作有基于局部线性嵌入(Locally Linear Embedding, LLE)[6]的合成方法[7]、基于稀疏表示的合成方法[8]、基于线性回归的合成方法[9]等.“ 分段非线性” 是整幅图像分成图像块, 单个图像块的重构是非线性的, 因而对于整幅图像也是非线性的, 代表性的工作有基于马尔科夫随机场 (Markov Random Fields, MRF)的方法[10]和基于卷积神经网络的方法[11]等.
在之前的工作[12, 13]中, 学者们对人脸图像超分辨率重建和人脸画像合成主要从数学模型的角度进行深入分析, 特别地将人脸画像合成方法分为4类:基于贝叶斯推断的方法、基于子空间学习的方法、基于贝叶斯推断和子空间学习结合的方法及基于稀疏表示的方法.文献[1]又将人脸画像合成方法作为异质人脸图像识别的一个子类进行综述.
本文与之前工作的不同在于:1)模型驱动类的方法在之前的工作中并未归为一大类方法, 并且关于人脸画像合成的文献增多, 然而并没有文献对其进行综合对比分析.随着深度学习在计算机视觉各个方向上取得的突破性进展, 基于深度学习的人脸画像合成方法[11, 14]逐渐引起大家重视, 此类方法无法归纳到前面工作中划分的任何一类中.2)之前的综述工作并未从实验角度在不同类方法及同类方法之间进行对比分析, 本文重点对比分析数据驱动类方法和模型驱动类方法之间的异同.
本文中使用t表示测试照片, 待合成画像表示为s, 每幅图像被划分为N块p× p大小的图像块, 例如ti和si分别表示测试照片和待合成画像划分成的第i个图像块.每幅图像块排列成一个d维的向量, d=p2, 相邻图像块之间保持o个像素的覆盖.M表示训练集中人脸照片-画像对数.对于每个测试照片块ti, 使用
表示从训练照片中搜索到的K个近邻中的第i个.对应地,
划分数据驱动类人脸画像合成方法和模型驱动类方法的依据是训练画像-照片对是否参与在线合成过程.对于数据驱动类方法, 首先需要将训练画像-照片对和测试照片划分成很多图像块(规则图像块或不规则图像块), 相邻图像块之间保留一定的覆盖, 照片块可以使用灰度值或其它特征表示.对于每个测试照片块ti, i=1, 2, …, N, 需要从训练照片块中选择K个近邻
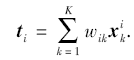
数据驱动类方法假设待合成画像块si与测试照片块ti有相似的流形分布, 即有相同的重构系数wi.故关键是如何得到重构权值, 即权值计算问题: 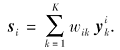
当按照上式得到所有的待合成画像块后, 需要将所有的画像块排列融合, 重新组成一幅画像, 这里的关键是如何计算相邻图像块覆盖区域的像素值.
子空间学习的目的是寻找嵌入在高维空间中的低维子空间.基于子空间学习的人脸画像合成方法的代表性工作如下:假设照片和画像之间的映射关系是全局线性的工作[5]和假设照片和画像之间的映射关系是全局非线性局部线性的工作[7].由于这两个工作在文献[1]中已进行详细介绍, 在此简单总结.
文献[5]利用主成分分析从训练照片中学习得到投影矩阵.在测试阶段, 利用学习得到的投影矩阵将测试照片进行投影, 得到投影系数, 用此投影系数对训练画像进行线性组合, 得到最终的合成画像.后续分别在纹理和形状上进行基于主成分分析的画像转换, 进一步提高合成效果[15, 16].
文献[7]将所有的训练图像对和测试照片分成均匀大小的图像块, 对于每个测试照片块, 首先从训练照片中搜索K个最近邻照片块.使用寻找得到的K个最近邻照片块对测试照片块进行最小二乘重构, 得到重构系数, 继而使用此重构系数对训练画像集中对应于K个最近邻照片块位置的画像块进行线性组合, 得到合成画像块, 待得到所有的合成画像块时, 将它们组合成一整幅画像.
Wang等[17]提出基于随机采样的快速人脸画像合成方法.核心思想是使用离线的局部区域随机采样替代在线的K近邻搜索.在离线随机采样阶段为了进一步提高合成效率, 主成分分析用于对图像块进行降维处理.在测试阶段, 执行类似于文献[7]的步骤即可得到合成画像块, 不同的是在求解重构权值时将不同随机采样块与测试照片块的距离作为对权值的约束, 提高解的准确性.
稀疏表示是指利用过完备字典将输入的信号进行紧致的表达, 这里紧致的表达是指得到的表示系数中非零元素尽量少.由于寻找非零元素个数的稀疏表达是一个非确定性多项式困难(NP -hard)的问题, 故而一般使用稀疏表示系数的L1范数以近似[18].
Chang等[19]利用稀疏编码联合训练得到一对画像和照片块字典, 分别记作
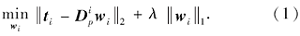
得到稀疏表示系数wi后, 与画像块字典进行相乘即可得到对应的画像块
si=
最后将所有的合成画像块进行组合得到一整幅画像, 其中相邻合成画像块覆盖区域灰度值取平均.
与Chang等利用稀疏编码学习一对照片块和画像块字典不同, Gao等[8]直接使用原始照片块和画像块作为字典中的原子, 借助稀疏表示系数中非零元素个数随着输入测试照片块的不同而自适应决定这一特点, 提出基于稀疏近邻选择的人脸画像合成方法, 在一定程度上缓解固定个数近邻带来的模糊现象, 但并不能完全补偿因为线性组合而过滤的高频细节信息.为此, Wang等[20]受人脸幻象[21]的启发, 提出利用回归技术学习照片到过滤的残差之间的映射, 进而补偿现有人脸画像合成方法过滤的高频细节信息.
考虑到现有的数据驱动方法仅在局部范围内进行近邻搜索, 图像上一些非人脸因素难以合成, 例如人脸特定位置的疤痕、发卡、痣等.此外, 局部搜索策略的前提是测试照片和训练集中的图像提前进行对齐, 限制测试照片的来源范围.Zhang等[22]提出利用稀疏表示系数中非零元素的值和非零系数编码的顺序进行全局图像块的按树搜索, 提高算法的鲁棒性.基于此稀疏贪婪搜索算法, 后续研究分别提出解决方案, 应对训练集中只有一对照片和画像时[23]及只有一幅训练画像时[24]如何进行合成的挑战.
对应于人脸画像合成, 贝叶斯公式可以写为如下最大化后验概率问题: 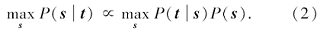
在式(1)中都将已知的训练画像-照片对隐去.此项中的似然项P(t|s)一般约束的是合成的画像需要同输入的照片上内容相似, 先验项P(s)一般用于约束合成画像中相邻图像块之间的相似性(兼容性).
Gao等[25]率先提出利用二维的隐马尔可夫模型[26]— — 嵌入式隐马尔可夫模型[27]进行人脸画像合成.该方法可以看作在最大后验概率(式(2))的基础上进一步引进隐状态变量, 保持画像和照片内容上的一致性, 并建立画像和照片之间的桥梁[1, 12].后续研究进一步将对整张照片和画像建模改进为对每个图像块或部件进行嵌入式隐马尔可夫模型建模[28].
Wang等 [10]利用图像的马尔科夫特性, 提出基于多尺度马尔科夫随机场的方法.马尔科夫特性是指图像中某一位置的变化只与其最近邻相关.对于单层的马尔科夫随机场模型, 可以使用式(2)中的最大后验概率公式表示, 其中似然项和先验项分别定义为
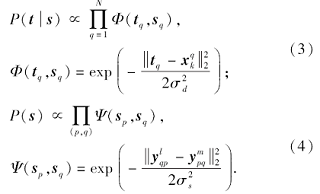
似然项使用测试照片块和其近邻照片块之间的距离表示, 先验项使用相邻画像块覆盖区域的距离表示,
基于MRF的方法最终是从所有的候选画像块中选择一个作为最终的合成画像块.Zhou等[33]发现文献[10]会因为最终的这一策略导致生成的人脸画像存在形变.这是因为训练画像集中画像数量有限, 对于不存在于训练集中的人脸块, 该算法无法合成.因此提出在MRF中引入多个画像块的线性组合, 通过差值合成一些不存在于训练集中的图像块, 从一定程度上缓解人脸变形的影响.此工作可以看作是对式(3)和式(4)中的先验项进行的改善:
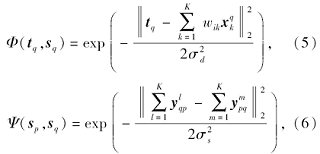
即原来单个候选块之间的距离变为候选块线性组合之间的距离.Peng等[34]受贝叶斯推断思想进行人脸画像合成思想的启发, 提出利用概率图模型推断重构权值作为特征, 直接进行异质人脸图像识别.
Wang等 [35]从直推式学习的角度对人脸画像合成进行建模, 主要思想是画像合成和照片合成均是由共有的中间隐变量— — 重构权值来控制(这里记作W):
P(Y, X, W) = P(Y, X |W)P(W) =P(Y| X, W)P(X |W)P(W),
其中, Y表示所有的画像(训练画像和待合成画像), X表示所有的照片(训练照片和测试照片).最终可以写作2个似然项和1个先验项的乘积, 其中似然项P(X| W)和先验项P(W)的定义与式(3)和式(5)相同.由于假设重构权值W控制画像Y和照片X的生成, 故根据概率图模型知识可知, 当-W已知时, 画像Y和照片X的生成相互独立, 即
P(X, Y|W) = P(X|W)P(Y|W),
因而
P(Y| X, W) = P(Y|W).
因为直推式学习是测试照片和待合成画像一起纳入到学习过程中, 故P(-P(Y|W)亦可看作一种似然函数, 可以使用类似于式(5)中的方式定义.
为了增强基于贝叶斯推断的人脸画像合成方法对于复杂背景、光照变化及种族变化等因素的鲁棒性, Peng等[36]提出对多种鲁棒性较强的特征进行加权融合的方式纳入到贝叶斯推断问题(式(2))中.Zhu等[37]提出对深度网络学习 [38]的深度特征进行加权融入到贝叶斯网络中, 提高人脸画像合成算法的鲁棒性.考虑到矩形分块方式并未考虑人脸的结构特性, Peng等[39]进一步提出利用超像素分割的思想保持图像块的自然结构特性, 将图像分割成若干超像素, 再以超像素为单位进行人脸画像合成.
Wang等[40]从基于贝叶斯推断的人脸画像合成的整个过程出发, 对现有的数据驱动类方法进行概率上的解释, 并通过总结归纳现有算法存在的缺陷, 提出贝叶斯人脸画像合成方法.该方法认为数据驱动类方法由2部分组成:近邻选择模型和权值计算模型, 并给出概率上的解释:
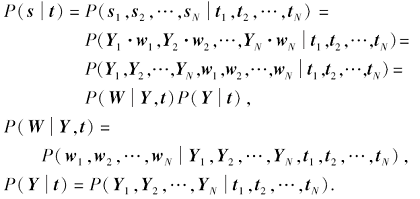
其中
P(Y| t) = P(Y1, Y2, …, YN|t1, t2, …, tN )
可以看作近邻选择模型, P(W|Y, t)可以看作在测试照片块及其近邻已知的情况下, 求解权值即权值计算模型.Wang等认为现有的模型驱动方法或在近邻选择阶段没有考虑邻域约束(除文献[10]之外的工作均可看作没有考虑邻域约束), 或在权值计算阶段没有考虑邻域约束(基于子空间学习的方法、基于稀疏表示的方法以及基于MRF的工作 [10]), 因此提出使用MRF对近邻选择进行建模, 使用基于马尔科夫权重场的方法[33]对权值计算进行建模, 从而将邻域约束都考虑在内.后来Wang等[41]提出在近邻选择阶段应该将训练画像考虑在内, 提出基于锚点近邻索引的近邻选择策略, 可以配合现有的近邻选择方法使用, 提高近邻选择的精准率.
不同于数据驱动类方法需要在测试阶段访问训练样本, 模型驱动类方法在训练阶段学习照片(块)到画像(块)的映射或回归关系(线性或非线性), 然后在测试阶段, 对于任意(位置的)测试照片(块), 只需要利用(对应位置)学习的映射函数进行回归即可.相比数据驱动类方法, 模型驱动类方法合成效率更高[9].
Wang等[9]提出利用线性回归(岭回归)学习照片块到画像块之间的映射, 即将测试照片转换为画像的过程, 划分为N个画像块的合成, 每个画像块的合成均依赖于一个学习得到的回归关系, 该回归关系来自于从对应位置的训练照片块到训练画像块的映射.
Zhang等[11]提出端到端的卷积神经网络结构进行人脸画像合成.该网络结构包含6个卷积层, 利用修正线性单元作为激活函数.端到端的方式是指输入一整张测试照片, 输出一整张测试画像, 无需分割成图像块处理, 从而不需要像前文提到的方法那样将合成画像块组合成整幅画像.本质上, 该方法是学习一种非线性的从整张照片到整张画像的映射关系.
基于生成对抗网络(Generative Adversarial Nets, GAN)[42], Isola等[43]提出基于条件GAN的图
像翻译算法, 能够将一种模态的图像翻译为另外一种模态, 如从人脸照片到人脸画像.该方法通过交替迭代训练判别模型和生成模型, 提高生成图像的质量(判别模型的判别能力也相应地增强).考虑到该方法生成的图像噪声较多, Wang等[44]结合数据驱动类方法提出后处理框架, 能够将GAN生成的画像进行后处理, 得到质量更高的画像.
目前, 公开的人脸画像-照片库主要有香港中文大学(Chinese University of Hong Kong, CUHK)的CUHK Face Sketch(CUFS)数据库和CUHK Face Sketch FERET(CUFSF)数据库.CUFS数据库中的照片分别来自3个子库:CUHK Student数据库、AR数据库和XM2VTS数据库, 分别包括来自188、123和295个人的单张正面中性表情照片.CUFS数据库中每张照片存在一幅画家手绘的画像, 即共有606对人脸画像和照片数据.CUFSF数据库中有1 194对人脸画像-照片, 其中照片来自于FERET数据库[45], 每人有一张照片和一幅画像.相比CUFS数据库, CUFSF数据库中的画像有更多的夸张成分, 因此更具挑战性.图1给出人脸照片-画像对示例.从左到右分别来自CUHK student数据库、AR数据库、XM2VTS数据库和CUFSF数据库(最后3幅).
 | 图1 不同数据库的示例图像对Fig.1 Example image pairs from different databases |
本文从各类方法中选择一些代表性的方法进行对比:基于局部线性嵌入的方法(记作LLE)[7]、基于随机采样的方法(记作RSLCR)[17]、基于稀疏近邻选择的方法(记作SFS)[8]、基于马尔科夫随机场的方法(记作MRF)[10]、基于马尔科夫权重场的方法(记作MWF)[33]、贝叶斯人脸画像合成方法(记作Bayesian)[40]、基于全卷积深度神经网络的方法(记作FCN)[11]、基于生成对抗网络的方法(记作GAN)[43].
实验设置同原文献, 其中MRF方法源代码来源于其它研究者实现的代码(http://www.cs.cityu.edu.hk/~yibisong/eccv14/index.html), 该代码仅实现基于单层MRF的人脸画像合成算法, 故此实现结果差于原文中给出的结果.
LLE和FCN为本文自己实现(文献[40]对比作者对文献[7]的实现和原文中的结果, 表明作者的实现策略优于原文), 其余方法的源代码均来源于作者.
为了进行人脸画像合成, 需要对数据库划分训练集和测试集, 本文采用最新文献中出现较多的划分方式[9, 17, 40-41, 44].图2和图3分别给出8种方法在CUFS和CUFSF数据集上的合成结果.
从图中可以看出, LLE合成效果中存在较多噪声(特别是头发区域)或块状效应, RSLCR合成细节(如眼镜)较好, SFS产生的结果模糊效应较严重, MRF合成结果存在形变, MWF合成结果具有较细粒度的噪声, 在头发区域合成效果不佳, Bayesian合成结果较清晰, 并能从一定程度上合成细节, FCN能够保持合成对象的内容, 但是在风格上与画像差异较大, 模糊效应和噪声比较严重, GAN能够最好地保持画像的纹理特征且细节较完整(如眼镜能够完整的合成), 但是形变较严重(特别是嘴的形状).整体而言, 由于CUFSF数据库中的照片存在变化因素较多(肤色、年龄、拍摄时间、夸张因素等), 在此库上的合成效果差于CUFS数据库中效果.
 | 图2 不同方法在CUFS数据库上的合成画像结果示例Fig.2 Example of synthesized sketches on CUFS database by different face sketch synthesis methods |
 | 图3 不同方法在CUFSF数据库上的合成画像结果示例Fig.3 Example of synthesized sketches on CUFSF database by different face sketch synthesis methods |
模型驱动类方法在离线学习映射关系后, 在线测试阶段只需要将映射关系实施到测试数据, 因此计算复杂度相对较低.综合来看, 由于数据驱动类方法需要遍历整个数据集, 计算复杂度高于模型驱动方法.不同合成算法在不同数据集上平均合成一张画像所用的时间如表1所示.RSLCR由于提前随机采样固定个数的近邻, 解决计算复杂度随数据库数据量增大而线性增加的难题.因为测试阶段不需要重新遍历数据库选择近邻, 因此大幅缩减合成时间.这里将RSLCR归类于数据驱动类方法而不是模型驱动类的主要原因在于, RSLCR未学习照片到画像的映射关系.从表1中可以看出, 基于深度学习的方法速度快于其它方法(数据驱动类方法), 特别是GAN能够做到6 s合成100幅画像, 远超现有算法.
| 表1 不同方法在不同数据集上平均合成一张画像所用时间 Table 1 Average time consuming for synthesizing one sketch by different methods on different databases |
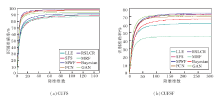
为了评价合成画像的质量, 采用最常用的全参考客观图像质量评价测度— — 结构相似度准则(Structural Similarity, SSIM)[46].图4分别给出在CUFS和CUFSF数据集上的SSIM值.
图4中, SSIM评价分数值越大, 表示合成图像质量越好, 纵轴表示大于等于横轴所示分数的合成画像占全部合成画像的比例.从图4中可以看出, 选择的8种算法在CUFS数据集上的SSIM统计表现相差不大, 但在CUFSF数据集上表现不一.这是因为CUFSF数据库中的照片存在很多变化因素, 导致合成难度较大.
 | 图4 不同方法在2个数据集上的SSIM值Fig.4 SSIM Statistics of synthesized sketches on CUFS and CUFSF databases by different methods |
表2给出不同合成方法在2个数据集上合成画像的平均SSIM值.结合表2和图4可以看出, 数据驱动类方法在质量评价方面表现优于模型驱动类方法, 其中Bayesian和RSLCR取得最佳效果.这也同时说明现有的全参考质量评价方法在评价合成图像质量上与人眼主观感受有所不同.根据图2、图3所示, GAN合成画像纹理效果较好, 虽然存在形变, 但主观视觉上并不会觉得合成效果在8种算法中最差, 而从表2和图4中可以看出, GAN表现最差, 这在文献[47]中也有过相关讨论.
| 表2 不同方法在2个数据集上合成画像的平均SSIM值 Table 2 Average SSIM scores of synthesized sketches by different methods on 2 datasets |
为了进一步测试不同方法合成的人脸画像的质量, 进行人脸识别实验, 选用的人脸识别方法是基于子空间学习的方法— — 零空间线性判别分析(Null-Space Linear Discriminant Analysis, NLDA)[48].图5给出分别在CUFS和CUFSF数据集上不同人脸合成方法合成结果对应的准确率随降维维数的变化情况, 表3给出最佳识别率对比.
从图5和表3的对比可以看出, CUFS数据库挑战性较小, RSLCR能够达到98.43%, Bayesian和FCN识别率超过95%.但在CUFSF数据库上识别率仍然很低, 低于75%.值得一提的是, 跟客观质量评价类似, 基于模型驱动类方法中GAN产生的结果由于存在人脸变形, 识别率并不高.
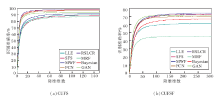 | 图5 不同方法在2种数据集上的人脸识别准确率随降维维数的变化Fig.5 Face recognition accuracies of different methods changing with reduced dimensions on 2 datasets |
| 表3 不同方法在2个数据集上合成画像的NLDA人脸识别率 Table 3 NLDA face recognition accuracies based on synthesized sketches of different methods on 2 datasets % |
本文对现有的人脸画像合成方法从数据驱动和模型驱动角度进行对比分析研究, 发现数据驱动类方法合成速度较慢, 计算复杂度较高, 模型驱动类方法合成速度相对较快.相比模型驱动类方法, 数据驱动类方法能够取得更高的客观质量评价分数.但实验结果表明存在主客观质量评价不一致的情况, 因此合成画像的客观质量评价问题是将来一个有意义的研究问题.
目前, 模型驱动类方法的发展主要依赖于深度学习技术, 但因为训练数据有限, 导致现有的深度学习网络在此问题上的效果并不一定优于数据驱动类方法, 因此设计能够面向小数据量的深度学习网络是一个关键问题.此外, 既然生成对抗网络使合成结果存在形变和噪声, 应考虑能否将对抗方式融于一种更大的协同框架中.此外, 对于人脸识别问题, 如何利用多种合成方法的结果提高异质人脸图像识别的准确率是一个值得研究的课题.
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|
| [44] |
|
| [45] |
|
| [46] |
|
| [47] |
|
| [48] |
|