
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
时空嵌入式生成对抗网络的地点预测方法*
[孔德江1  , 汤斯亮
, 汤斯亮1 , 吴飞1 ]
, 汤斯亮, 吴飞]
|
|




作者简介:孔德江,博士研究生,主要研究方向为深度学习、推荐系统.E-mail:kdjysss@gmail.com.

汤斯亮,博士,副教授,主要研究方向为多媒体分析、文本挖掘、统计学习.E-mail:siliang@cs.zju.edu.cn.
定位技术的广泛使用可以积累大量的用户轨迹信息,为挖掘用户的行为轨迹提供便利.地点预测任务是众多基于位置服务的基础,学者们更关注如何有效利用这些轨迹数据进行地点预测.已有的方法或关注对长期模式(数天或数月)的预测,或致力于实时轨迹预测.文中研究的问题基于上述两者之间,即对弱实时条件下(数分钟或数小时)用户下一步的访问行为进行预测.为此,提出时空嵌入式的生成对抗网络模型(ST-GAN),在序列生成对抗网络的基础上,提出时空嵌入式长短时记忆生成模型(ST-LSTM)和时空嵌入式卷积神经网络判别模型(ST-CNN).ST-LSTM利用时空信息引导LSTM训练门机制,缓解数据的稀疏性.ST-CNN利用时空信息增强判别真伪访问序列的能力.此外,ST-GAN的训练优化机制使模型可以生成更多逼近真实的数据以引导模型学习,从而得到更好的预测效果.最后在真实的轨迹数据集上的实验验证ST-GAN的有效性.
The wide use of positioning technology makes the mining of the people movements easy and plenty of trajectory data are recorded. How to efficiently handle these data for location prediction is a popular research topic as it is fundamental to location-based services(LBS). The existing methods focus either on long time (days or months) visit prediction(i.e. point of interest recommendation) or on real time location prediction(i.e. trajectory prediction). In this paper, the location prediction problem in weak real time conditions is discussed to predict users' movement in next minutes or hours. A spatial-temporal long-short term memory model(ST-LSTM) combining spatial-temporal influence into LSTM model naturally is proposed to mitigate the data sparse problem. Furthermore, following the idea of generative adversarial network(GAN) for seq2seq learning, the ST-GAN model is proposed, and it takes the proposed ST-LSTM as the generator and the proposed spatial-temporal convolutional neural network(ST-CNN) as the discriminator. The minimax game of ST-GAN can produce more real enough data to train a better prediction model. The proposed ST-GAN is evaluated on a real world trajectory dataset and the results demonstrate the effectiveness of the proposed model.
导航定位技术的广泛运用使研究行动轨迹规律成为可能.每当用户使用数字地图应用(如百度地图、高德地图等)或其它接入地图服务的应用进行定位时, 会记录当前位置.如果用户每天多次使用定位服务, 就可以描述其一天的行动轨迹模式.这些轨迹日志数据打开用户运动行为研究的大门, 而用户运动行为的研究又能够进一步为基于位置的服务(Location-Based Services, LBS)提供帮助, 如导航服务、交通管理、基于位置的推荐和广告推送等.
自从定位技术广泛使用以来, 地点预测也成为重要的研究主题.许多工作致力于提高地点预测的准确度, 一部分工作[1, 2, 3, 4, 5, 6, 7, 8]关注实时地点预测, 通常使用机动车辆在导航时产生的轨迹数据研究车辆的实时动向, 为交通拥堵预测和路径规划等任务提供帮助.另外一部分工作[9, 10, 11, 12, 13, 14, 15, 16]着重于长期、非实时的地点预测, 如兴趣地点(Point of Interest, POI)推荐.目的是研究用户的喜好并预测未来可能的地点访问, 为推荐和广告服务带来便利.
随着当今社会城市化进程的快速发展, 如何有效管理城市、发展智慧城市已经成为热门话题.研究发现[17, 18], 现代城市由一些带有特定功能的区域组合而成, 如住宅区、商业区、工业区和教育区等, 人们在这些功能区之间的转移反映一定的社会活动模式, 如工作、购物和娱乐等.如果能够有效地挖掘用户在这些功能区域的访问规律, 可在一定程度上提高城市管理的效率.对于个体用户而言, 如果能有效预测出访目的地, 可对其进行个性化的服务推送, 如交通方式(直达车站、共享单车等).对于群体而言, 准确预测出访目的地可为智能交通管理提供便利.本文研究的地点预测问题为介于实时和非实时之间的一种弱实时预测, 即根据用户当前的运动轨迹, 预测用户下一时刻(从几分钟到几小时内)可能的到访功能区域.
众所周知, 时间和空间信息是研究地点预测问题需要考虑的重要因素.例如, 某人当前在工作区工作, 如果要预测其十五分钟后的到访区域, 那么办公室附近的咖啡馆有很大可能, 因为其可能稍作休息; 如果预测其两个小时后的到访区域, 那么更可能是相隔距离较远的另一个办公区域或住宅区, 因为其可能去其它公司开会或已下班回家.这只是一个简单的例子, 真实的情况更复杂.
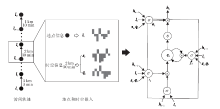
图1展示基于真实访问数据统计的结果, 列出人们在访问区域22后, 在接下来的连续四小时内所访问区域的分时段统计.
 | 图1 在连续4个时间块内区域22的下一访问区域的分布情况Fig.1 Distributions of next visit location of location 22 for 4 time bins |
由图1可以看出, 每个时间块内访问区域的分布完全不一样, 如区域10和957仅出现在前两个时间块内, 而区域678和1028只出现在后续的时间块内.由此可见时空信息隐含的模式对地点预测的影响.近年来, 很多工作尝试利用时空因素提高地点预测的性能.部分工作[12, 13, 19]将时空信息引入到约束项中, 训练更好的预测模型.Liu等[16]使用嵌入模型, 将时空信息表达为张量形式, 并将其与地点的表达相乘, 构造带有时空信息的地点表达.上述时空模型都取得不错的预测效果.
随着人工智能技术的发展, 深度模型, 例如反馈神经网络(Recurrent Neural Network, RNN)和卷积神经网络(Convolutional Neural Network, CNN), 运用到越来越多的领域, 并展现良好的性能.长短时记忆模型(Long-Short Term Memory, LSTM)[20]是一种改进的反馈神经网络, 它通过引入门机制以协调信息的传递, 在时序数据建模上展现良好的效果.但是很多深度预测模型仅考虑序列节点间的依赖关系, 忽略时空信息的影响.此外, 深度模型往往会遇到数据稀疏的问题.地点访问轨迹数据包含时间和空间这些额外信息, 可辅助模型进行训练, 缓解数据稀疏性的问题.
最近, 生成对抗网络(Generative Adversarial Net- work, GAN)在自然图像生成领域取得重要突破.Yu等[21]克服生成对抗网络处理序列数据的限制, 利用强化学习传递梯度, 提出面向序列数据的生成对抗网络.在文献[21]的基础上, 学者们提出许多序列模型的生成对抗模型, 并在机器翻译[22]、对话生成[23]等领域取得较好结果.本文基于生成对抗网络的思路, 提出时空嵌入的序列生成对抗网络, 利用其优化机制以训练更好的地点预测模型.
综上所述, 本文提出时空嵌入式的生成对抗网络模型(Spatial-Temporal GAN, ST-GAN).以序列生成对抗网络为基础设计时空嵌入的长短时记忆模型(Spatial-Temporal LSTM, ST-LSTM), 用于对地点序列进行建模, 利用时空信息引导门机制的学习, 提高预测效果.运用生成对抗网络研究地点预测问题, 提出时空嵌入式卷积神经网络(Spatial Temporal CNN, ST-CNN), 增强模型判别真伪地点访问序列的能力.在真实的轨迹数据上进行大量实验, 并通过与已有方法的对比验证文中模型的有效性.
与本文相关的研究内容主要包括3方面:地点预测任务、深度模型、序列数据的生成对抗网络.
地点预测是长期以来的研究热点.对于实时轨迹预测而言, 主要可分为2种不同的策略:第1种是基于个体数据的挖掘[1, 2, 3, 24], 该策略注重研究个体的运行规律, 却忽略群体运动规律的共性.由于个体数据通常不足, 容易遭遇数据稀疏问题.第2种为基于群体数据的挖掘[4, 5, 6], 该策略在考虑个体运动规律的同时还考虑群体的运动共性, 通常能取得比第1种策略更好的效果.上述2种策略的算法的设计通常是基于马尔科夫模型及其变种.本文的地点预测模型使用第2种策略, 即研究群体在功能区域间的运动规律.
不同于实时地点预测, 兴趣点预测的目的是为用户推荐未来其最可能访问的地点.传统方法通常是基于协同过滤(Collaborative Filtering, CF)算法, 最常用的为基于用户的协同过滤[9, 10, 11], 利用相似用户进行地点推荐.另外一种是基于矩阵分解(Matrix Factorization, MF)的方法[12, 13], 通过矩阵分解学习用户-地点的偏好矩阵, 进行地点推荐.
上述方法都只考虑用户对于地点的偏好, 忽略用户历史访问地点构成的时序信息.基于分解个性化马尔可夫链(Factorizing Personalized Markov Chain, FPMC)的一些方法[14, 15, 25]虽考虑时序信息, 但只对短程时序关系进行建模, 限制这些方法的预测能力.内嵌技术的出现推动这一领域的研究.个性化排序度量嵌入(Personalized Ranking Metric Embe- dding, PRME)[19]是最具代表性的地点预测嵌入算法, 将用户和地点嵌入到隐空间, 发掘相似关系, 更好地进行地点推荐, 但是其仍然只能建模访问序列的短程依赖关系.本文提出的ST-LSTM 模型可以挖掘用户长程的访问关系, 提高预测效果.
深度学习是近年来的研究热点.卷积神经网络在图像分类[26]、目标检测[27]、视频分类[28]等视觉领域取得显著进展.同时, 基于卷积神经网络的判别模型[29, 30, 31]也在复杂序列的分类上取得明显效果.反馈神经网络作为一种深度模型, 能够较好地建模序列数据之间的时序依赖关系, 广泛运用到如机器翻译、语音识别和语言建模[32]等领域.最近, 反馈神经网络也运用到地点预测任务, Liu等[16]提出利用时空信息增强兴趣点推荐效果的时空嵌入式反馈神经网络(Spatial-Temporal RNN, ST-RNN), 将时空信息嵌入到地点的表达中, 并利用RNN挖掘访问序列的时序关系, 取得良好的预测效果.
生成对抗网(GAN)[33]作为一种训练生成模型的方法, 利用判别器引导生成器进行训练, 在生成连续型数据研究上取得进展, 如图像生成[34, 35].但对于离散型序列数据, 由于实数值梯度无法有效地从判别器传递回生成器, 并用于引导生成器进行训练, 因此将生成对抗网络运用于离散序列生成遇到挑战.Yu等[21]克服这一困难, 提出基于序列数据的生成对抗网络(Sequence Generative Adversarial Nets with Policy Gradient, SeqGAN).SeqGAN巧妙引入增强学习, 利用策略梯度来回传递梯度信息以训练生成器, 在文本生成等任务上取得良好的效果.文献[22]、文献[23]基于SeqGAN, 分别提出针对机器翻译和自然对话生成的序列数据的生成对抗网络.
每当用户使用定位服务进行导航时, 所在的当前位置会记录在服务端.那么, 如果用户每天多次使用定位服务, 将会记录运动轨迹.随着互联网的兴起, 大量的应用程序会使用位置信息, 而定位服务的提供商(如百度地图、高德地图等)将会得到大量的用户轨迹数据, 这些数据使研究用户的出行规律成为可能.给定用户u及其对应的轨迹
xu={
其中,
为地点
为地点
| 表1 符号标记及其含义 Table 1 Symbols and their corresponding meanings |
本文以SeqGAN为基础, 将地点预测问题看作地点序列生成问题, 提出的基于地点预测生成对抗网络主要包括如下3部分.
2.2.1 地点序列生成模型
下一个地点预测可看作根据当前状态生成下一个地点的任务.对于真实访问序列{l1, l2, …, lN}, 地点预测模型Gθ 的目标是最大化概率
P(lk+1|l1, l2, …, lk), k=1, 2, …, N-1,
一般可使用最大似然估计优化Gθ .给定通过真实数据优化的模型Gθ , 生成新的访问序列过程如下:首先固定前m个真实访问地点, 然后根据P(lm+1|l1, l2, …, lm) 选择下一个地点, 依次类推, 直到生成与真实序列长度相同的地点序列.在实际训练过程中, m最初设定为序列最大长度的1/2, 并随着训练过程逐渐减小.生成模型Gθ 的目的是生成足够真实的数据, 使得判别模型无法判断真假.
2.2.2 地点序列判别模型
通过生成模型Gθ , 给定真实数据
xreal={l1, …, lm, lm+1, …, lN},
可以生成一个新的访问数据
xgen={l1, …, lm, l'm+1, …, l'N}.
判别模型Dϕ 的目标是判别序列来源于真实数据(为真), 还是由Gθ 生成(为假).如为生成数据, 使P(xgen)的概率越小越好(接近为0); 否则, 使P(xreal)越大越好(接近于1).
2.2.3 策略梯度训练
如文献[21]所述, 由于离散数据无法进行梯度传递, 可以使用强化学习的方法模拟数据生成过程, 并且使用策略梯度优化生成器.对于生成序列
L1∶ N={l1, …, lk, …, lN}, lk∈ L,
其中L为所有地点的集合.在时刻k, 状态s为已生成的序列{l1, l2, …, lk-1}, 动作a为下一个要生成的地点lk, 策略为Gθ (lk|L1∶ k-1), 动作的奖励通过判别模型Dϕ 获得.由文献[21]可知, 对于无法直接获得动作奖励的策略(生成模型)Gθ , 其优化目标为从状态s0开始生成序列并最大化如下最终期望奖励:
J(θ )=
其中,
k的动作价值函数.定义M次蒙特卡洛搜索为
M
其中
其中Dϕ (L1:N)为序列L1∶ N从Dϕ 所获奖励.使用Dϕ 作为奖励函数的优点在于其可与生成模型进行交替优化.每当生成模型能生成更加真实数据时, 可利用如下目标来继续优化判别模型:
每当新的判别模型训练好后, 对优化生成模型再次优化:
Ñ J(θ )=
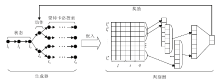
生成器(Generator)和判别器(Discriminator)的具体对抗训练过程如图2所示.对于生成序列, 将已生成的序列作为当前状态, 下一个要生成的地点作为动作, 生成器为生成策略, 动作的价值通过蒙特卡洛搜索进行估计, 即对于动作a, 对后续访问地点序列以策略G进行M次蒙特卡洛搜索.然后对于每个搜索生成的序列, 输入判别器, 并将判别器输出为真的概率作为奖励, 将M个奖励的均值作为动作价值赋予a, 通过此方式, 对生成策略G进行训练.每当生成器训练一定次数后, 利用真实访问数据和生成数据训练判别器.如此反复, 直至模型取得最好的地点预测效果.
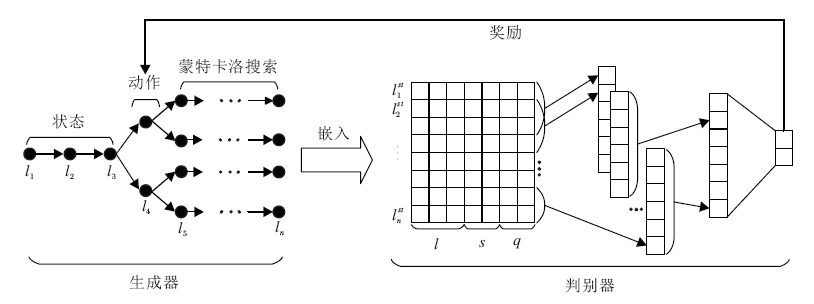 | 图2 生成器和判别器的对抗训练过程Fig.2 Adversarial training between generator and discriminator |
单一的预测模型往往只使用真实数据训练模型, 而真实的数据数量总有限, 因此难以从有限数据中学习得到逼近真实数据分布的模型.使用生成对抗网络进行地点预测的优势在于, 其不仅能够利用全部真实的数据进行模型训练, 而且由于判别器的存在, 还能够利用生成的数据对模型进行微调, 使预测模型表现更好.
反馈神经网络[36]是时序数据处理常用模型.给定时刻k的输入lk, 标准卷积神经网络输出hk计算如下:
sk=σ (Wllk+Wssk-1), (6)
h k=Whsk, (7)
其中sk为时刻k的隐状态.反馈神经网络由于处理长序列时会产生梯度弥散和梯度爆炸[37, 38]等问题, 因此难以建模序列数据中长程依赖关系.长短时记忆模型[20]是一种改进的反馈神经网络, 通过引入门的机制解决梯度弥散和爆炸问题.给定时刻k的输入lk, LSTM的输出hk:
gk=ϕ (Wlglk+Whghk-1+bg), (8)
ik=σ (Wlilk+Whihk-1+bi), (9)
fk=σ (Wlflk+Whfhk-1+bf), (10)
ok=σ (Wlolk+Whohk-1+bo), (11)
ck=fk· ck-1+ik· gk. (12)
hk=okϕ (ck), (13)
其中, h0=0, σ (· )为sigmoid函数, ϕ (· )为双曲正切函数, i为输入门, f为遗忘门, o为输出门, c为记忆单元状态(Cell State).这些门能使LSTM的记忆
单元可以有效地对信息进行更新、遗忘和保持.具体来说, 输入门i控制输入信息是否流入, 遗忘门f控制记忆单元是否忘记历史保存信息, 输出门o控制是否将当前记忆单元信息输出到一个时间片.一般情况下, 这些门的功能完整性需通过大量数据进行训练学习.然而, 缺乏足够的标注数据是深度学习系统面临的一个常见问题, 对于地点预测任务也同样如此.数据稀疏性使常规深度模型不能得到充分训练.但是, 出行的时间间隔和空间间隔与用户出行行为之间具有紧密关系, 这种关系可作为隐含信息以引导LSTM门机制的学习.
因此, 本文提出时空嵌入的长短时记忆模型(ST-LSTM).如图3所示, 模型将连续地点访问的时间间隔和空间距离分别进行嵌入, 并将其引入到输入门、输出门和遗忘门中引导模型训练:
ik=σ (Wlilk+Whihk-1+Wsisk+Wqiqk+bi), (14)
fk=σ (Wlflk+Whfhk-1+Wsfsk+Wqfqk+bf), (15)
ok=σ (Wlolk+Whohk-1+Wsosk+Wqoqk+bo), (16)
其中, s∈ Rd, q∈ Rd, sk为k-1时刻与k时刻连续访问地点空间间隔的向量表达, s1=0. qk为k-1时刻与k时刻连续地点访问时间间隔的向量表达, q1=0.Ws∈ Rd× |c|为时间向量的线性交换, Wq∈ Rd× |c|为空间向量的线性变换, | c | 为记忆单元状态的维度.如果对每个连续可能的时间间隔和空间间隔学习一个向量表达, 所需学习的参数非常大, 加剧数据稀疏问题.为了解决这一问题, 本文首先将时间和空间划分为等距子块(bin), 如以一小时为间隔, 一天可以划分为24个等长时间子块.空间划分同理可得.
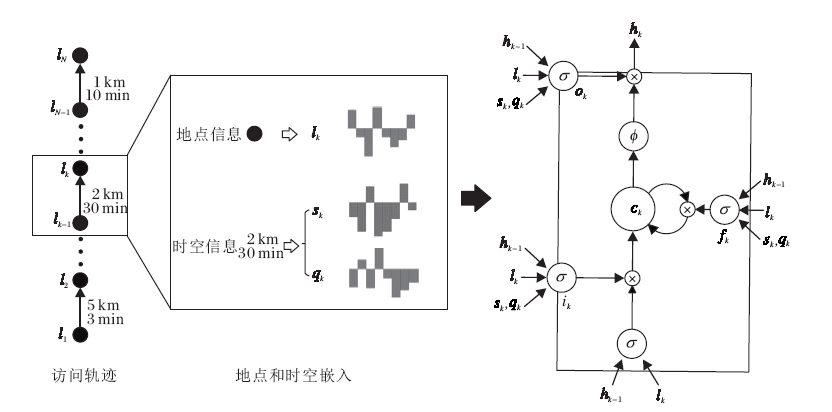 | 图3 时空嵌入的长短时记忆模型Fig.3 Spatial-temporal embedding LSTM |
对于所划分子块, 只对子块边界进行向量嵌入.对于某一时间间隔vq和空间间隔vs, 通过线性插值方式计算对应的时空向量表达q和s:
q=
s=
其中, u(vq)、l(vq)为时间间隔vq所在块的上界和下界, u(vs)、l(vs)为空间间隔vs所在块的上界和下界.Q∈
对于访问序列{l1, l2, …, lN}, 时刻k输出hk:
hk=STLSTM(hk-1, lk, sk, qk), h0=0, k=1, 2, …, N, (19)
其中, STLSTM(· )为时空嵌入长短时记忆模型, 通过k时刻的网络输出hk, 预测或生成下一个访问地点:
P(lk+1|l1, l2, …, lk)=Softmax(Wl· hk+bl), (20)
其中, P(lk+1|l1, …, lk)为预测k+1时刻访问地点的概率分布, 通过该分布可对下一访问地点进行预测或生成, Wl为变换矩阵, bl为对应的偏置.进行模型训练时, 先使用最大似然估计对ST-LSTM模型进行预训练, 然后使用生成对抗网络对模型进行微调.
地点访问序列不是简单的地点序列, 包含的时间间隔和空间间隔也是地点访问序列中的语义描述信息.为了更好地区分真实访问序列和由生成器生成的访问序列, 本文将时空信息引入到卷积神经网络中, 增强判别能力.
给定一个访问序列
x={l1, l2, …, lN},
对于li∈ x, 首先将其转化为带有时空信息的访问节点
其中, ⊕为拼接操作,
xst={
表达为矩阵形式:
ξ 1∶ N=
其中, ξ 1∶ N∈ RN× k, k=|l|+2d.本文使用多个滤波器{w1, w2, …, wM}对ξ 1∶ N 进行特征提取.对于窗口大小为aj、步长为1的滤波器wj∈
其中, ⓧ为逐位相乘求和操作, b为偏置项.wj对应特征图(Feature Map)为
Fj={
不同窗口大小滤波器可抽取不同序列特征.对于所得特征图{F1, F2, …, FM}, 进行时间最大池化(Max-
Pooling Over Time)操作:
得到M维大小特征向量:
F=
然后将特征向量输入到如下分类器中, 求取这一序列为真实访问序列的概率:
在训练过程中, 将ST-LSTM生成的序列数据标记为负样本, 将原始数据标记为正样本, 并保持正负样本数量相等, 对ST-CNN模型进行训练.
每当用户使用百度地图(http://map.baidu.com)或接入百度地图应用进行定位时, 用户位置信息会被保存.本文使用的轨迹数据来源于百度地图定位日志, 选取在北京市9 000个功能区域一周内(从2015年12月2日到2015年12月8日)定位数据, 包含144 320条用户访问轨迹, 1 677 581条定位信息.为了验证模型的鲁棒性, 分别选取20%、40%、60%和80%的轨迹数据作为训练数据, 剩余数据作为测试数据, 用于验证模型.
本文使用如下对比算法.
1)Top.该方法只依据地点热门度(流行度)进行排序推荐.
2)Matrix Factorization(MF)[12].基于矩阵分解算法, 广泛运用到预测推荐领域.本文构建连续访问地点-地点二元关系矩阵, 然后利用矩阵分解进行地点预测.
3)Variable-Order Markov(VOM) Model[7].变阶马尔可夫是一种序列预测模型.通过训练数据学习k-1阶(k为最大地点访问序列长度)条件分布以捕捉不同阶的依赖关系, 并采用最长匹配法则进行预测.
4)FPMC[25].推荐预测领域效果较好的个性化马尔可夫链算法.
5)PRME[19].地点预测嵌入算法, 将用户和地点分别嵌入隐空间, 计算用户-用户、用户-地点和地点-地点两两之间相似度, 增强预测效果.
6)ST-RNN[16].最早结合时空信息和反馈神经网络, 并运用到地点推荐方法, 将时间和空间分别表达为矩阵形式, 并对地点表达进行改进, 达到更好的预测效果.
7)LSTM[20].建模序列数据深度模型, 在挖掘序列数据长程依赖上取得不错效果.本文将其作为地点预测的基准算法.
本文主要使用2种评价标准对地点预测任务进行评价.
1)Accuracy@K, 计算方法为
Accuracy@k=
其中, #hit@k表示预测正确地点排序在前K的总数, #tests表示测试样例总个数.本文选取K=1, 5, 10, 20, 反映地点预测准确性.
2)平均倒数排序(Mean Reciprocal Rank, MRR), 计算方法为
MRR=
其中, N为测试样例总数, Ranki为第i个测试样例正
确预测地点的排序数.本文使用MRR反映地点预测排序的整体效果.
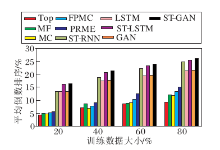
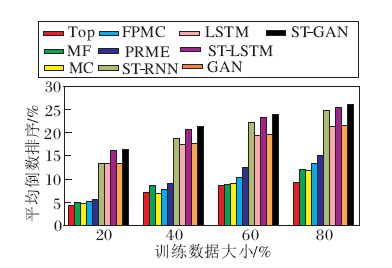
表2为训练数据大小比例分别为20%、40%、60%、80%时各种算法在Acc@1、Acc@5、Acc@10和Acc@20下的结果对比.图4为各种算法在训练数据大小比例分别为20%、40%、60%、80%时整体预测排序情况.
通过实验结果分析, 可得到如下结论.
1)挖掘序列数据中长程依赖的模型(基于深度神经网络的模型, 如LSTM、ST-RNN)效果优于不考虑时序依赖或只考虑短程时序关系的模型(如MF、FPMC、PRME等).从实验结果来看, 基于反馈神经网络预测模型取得的Acc@1值将近是非深度模型的Acc@1值的两倍.整体预测性能指标MRR也得到同样结论.具体来说, 在80%训练数据情况下, 只考虑用户对地点偏好信息的MF, 要比同时考虑用户喜好和访问短时依赖关系的FPMC和PRME所得Acc@1值分别低24.8%和30.4%.VOM虽然能够建模长程依赖, 但是受数据稀疏影响, 也只取得与MF相似的预测效果.LSTM考虑长程时序关系, 在不同训练数据大小的情况下均超越FPMC和PRME.由此可见长程时序关系在地点预测任务中的重要作用.
2)时空信息对提高预测性能帮助很大.对比引入时空信息的ST-LSTM与标准LSTM的预测性能可发现:前者Acc@1指标要比后者在各种训练条件下的净值增加1.47%~3.0%, 整体排序性能MRR也提高约21%, 提升幅度明显.此外, ST-RNN模型使用时空信息提高地点表达能力, 除了在训练数据较少(20%)时性能与LSTM 相当, 当训练数据增加时, 预测性能逐渐超越LSTM.对比本文提出的ST-LSTM和ST-RNN可以发现, ST-LSTM通过使用时空信息引导LSTM门机制的学习, 相比ST-RNN, 更好地利用时空信息, 尤其是当训练数据缺少(20%)时优势更明显.
| 表2 训练数据大小不同时各种算法预测的准确率对比 Table 2 Performance comparison of all prediction methods with 20%, 40%, 60%, 80% training data % |
 | 图4 训练数据大小不同时各种算法的平均倒数排序Fig.4 Mean reciprocal rank of 10 prediction methods with different training data size |
3)使用生成对抗网络对预测模型进行微调, 能进一步提升预测模型性能.表2和图4中GAN模型分别使用标准LSTM和标准CNN作为生成器和判别器.对比ST-GAN和ST-LSTM可看出, 使用生成对抗网络的训练方法对ST-LSTM进行微调, 可在一定程度上提升模型预测性能, 并且随着训练数据增多, 提升幅度也随之增大.另外, 对比ST-GAN和GAN可知, 当生成器和判别器自身效果一般时, 生成对抗网络的微调效果也不明显, 这也从另一个方面验证ST-LSTM模型的有效性.
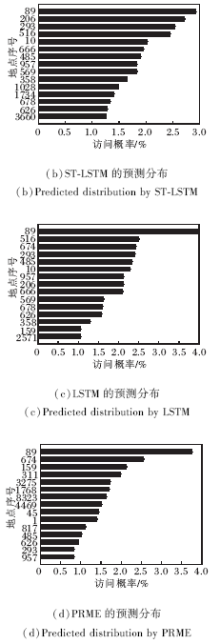
图5为用户访问单个地点22后一阶预测分布, 可明显看到, 相比LSTM和PRME, ST-LSTM整体预测情况与数据集分布更接近, 甚至前5位预测地点与实际情况完全相同, 这说明引入时空信息后, ST-LSTM能更好地拟合数据.
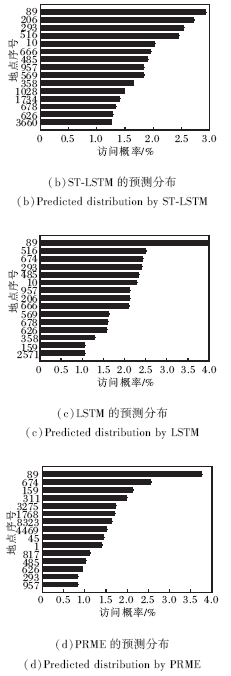 | 图5 用户访问区域22后下一访问区域的预测分布情况Fig.5 Distribution of predicted locations after visiting location 22 |
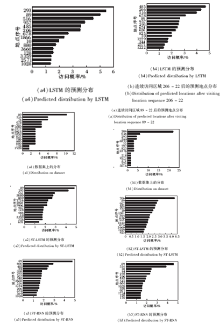
图6为用户连续访问两个地点后二阶预测分布, 从连续访问地点89、22这一例子可知, ST-LSTM和ST-RNN表现优于LSTM, 前者预测最有可能访问下一个地点且总体预测情况也优于后者.而在连续访问地点206、22 例子上, ST-LSTM表现优于ST-RNN, 这在一定程度上说明ST-LSTM对时空信息利用更合理.
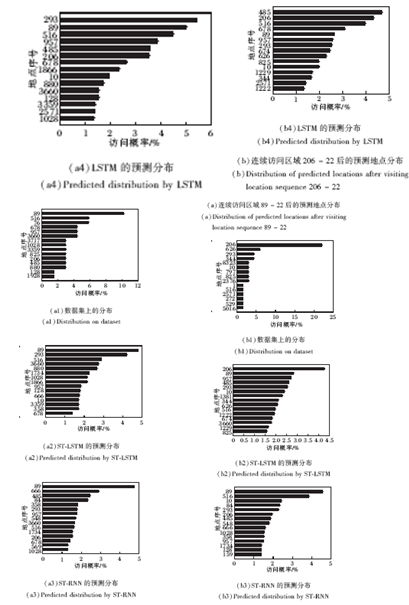 | 图6 用户在连续访问2个区域后下一访问区域的预测 分布情况Fig.6 Distributions of predicted locations after visiting two locations |
对比图5和图6, 还可得出如下结论.
1)在数据集上, 一阶分布更平滑, 在二阶情况下表现为锯齿形状, 反映二阶情况下数据表现更稀疏.各种嵌入模型的二阶预测结果分布都相对平滑, 反映嵌入模型的泛化能力.
2)地点22、89和206是用户倾向于连续访问的地点, 从图6可看出, 它们之间访问顺序存在89-22-89和206-22-206这样形如A-B-A访问模式, 说明用户存在在2个地点间折返这种行为模式, 这与现实情况也较符合.
针对地点预测任务, 本文提出时空嵌入式的生成对抗网络模型(ST-GAN), 以序列生成对抗网络为基础, 设计时空嵌入式长短时记忆生成模型(ST-LSTM)和时空嵌入式卷积神经网络判别模型(ST-CNN), 其中, ST-LSTM利用时空信息引导LSTM训练门机制, 解决数据的稀疏性问题, ST-CNN利用时空信息增强判别真伪访问序列的能力.
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|