



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
目标跟踪算法综述
[卢湖川1  , 李佩霞
, 李佩霞1 , 王栋1 ]
, 李佩霞, 王栋]
|
|



作者简介:卢湖川,博士,教授,主要研究方向为行人再识别、图像显著性检测、在线目标跟踪.E-mail:lhchuan@dlut.edu.cn.

李佩霞,硕士研究生,主要研究方向为视觉跟踪、深度学习.E-mail:pxli@mail.dlut.edu.cn.

王 栋,博士,副教授,主要研究方向为人脸识别、交互式图像分割、目标跟踪.E-mail:wdice@dlut.edu.cn.
作为计算机视觉领域的一个重要课题,在线目标跟踪在导弹制导、视频监控、无人机跟踪等众多领域中具有重要作用.尽管现在已有大量研究,但是仍然存在很多问题亟待解决,如光照变化、尺度变化、形变、遮挡和相机移动等.为了更清楚地梳理现存的算法,文中对典型的目标跟踪算法进行分析总结.首先,简单介绍研究意义及相关工作.然后,从传统算法和深度学习算法两方面对经典算法进行概述和分析.最后,讨论算法目前存在的问题,给出未来的研究趋势.
About the Author:LU Huchuan, Ph.D., professor. His research interests include person re-identification, saliency detection and online visual tracking.
LI Peixia, master student. Her research interests include visual tracking and deep learning.
WANG Dong, Ph.D., associate professor. His research interests include face recognition, interactive image segmentation and object tracking.
Online object tracking is a fundamental problem in computer vision and it is crucial to application in numerous fileds such as guided missile, video surveillance and unmanned aerial vehicle. Despite many studies on visual tracking, there are still many challenges during the tracking process including illumination variation, rotation, scale change, deformation, occlusion and camera motion. To make a clear understanding of visual tracking, visual tracking algorithms are summarized in this paper. Firstly, the meaning and the related work are briefly introduced. Secondly, the typical algorithms are classified, summarized and analyzed from two aspects: traditional algorithms and deep learning algorithms. Finally, the problems and the prediction of the future of visual tracking are discussed.
计算机视觉是研究如何让计算机从图像或视频中获取信息并进行“ 感知” 的科学, 它可以看作是人类视觉和感知的延伸.近二十年来, 随着计算机硬件水平、图像视频处理技术及人工智能技术的迅猛发展, 计算机视觉技术在智能控制(如机器人、无人机等)、决策系统(如监控、检测和识别系统等)、信息检索(如多媒体数据查询、图像搜索引擎等)、人机交互等许多关系到人类活动和生活领域均得到广泛应用.
在计算机视觉领域中, 基于视频的目标跟踪(也称为视觉跟踪)一直都是一个重要课题和研究热点.视觉跟踪通过在连续的视频图像序列中估计跟踪目标的位置、形状或所占区域, 确定目标的运动速度、方向及轨迹等运动信息, 实现对运动目标行为的分析和理解, 以便完成更高级的任务.目标跟踪无论在军事国防还是民用安全方面都具有重要的研究意义和广阔的应用前景.具体研究和应用包括:
1)智能视频监控.目前, 视频监控是目标跟踪技术最活跃的应用领域[1, 2, 3, 4, 5, 6].视频监控系统通过对视频中的目标进行自动识别、跟踪及更高级的语义分析处理, 从而实现对特定场所(如军事部门、政府机关、车站、机场、银行、校园、住宅区等)进行监控和预警.通过对视频的分析和理解, 智能视频监控能自动提取对监控和预警有用的关键信息, 尽可能地减少人为干预, 提高监控效率, 同时减轻人的工作负担.作为智能视频监控的关键技术, 视觉跟踪算法的研究具有巨大的产业价值.
2)现代化军事.视觉跟踪技术是当今以及未来现代化军事的研究热点[7, 8], 主要集中在精确制导、飞行控制、无人机侦察、靶场测量及武器观测瞄准等方面.如在精确制导方面, 早在20世纪70年代之前, 美国就开始研制视频制导导弹和炸弹, 并在越南战争和第四次中东战争中用于实战, 取得引人注目的作战效果.现在大多数制导导弹均采用可见光、红外线及其它射线等相结合的视觉跟踪技术.因此, 对于应对现代化局部战争, 视觉跟踪技术的研究也具有重要意义.
3)基于视频的人机交互.基于视频的人机交互技术通过对由摄像头或其它采集设备拍摄的视频进行分析, 实现人与计算机之间的“ 对话” .计算机软件可以对人的眼神[9]、表情[10, 11]、手势[12, 13]、姿态及身体动作[14, 15]等进行分析和理解, 从而完成目标跟踪.一个完整的目标跟踪系统通常包括目标的检测、提取、识别和跟踪4个环节.计算机想要获得如表情、手势、姿态等高级语义信息, 必须首先实现对人脸、人眼及人体的定位和跟踪.因此, 视觉跟踪也是人机交互的重要环节之一.
4)智能交通系统.随着目前城市机动车辆的逐渐增多和车流密度的逐渐增大, 智能交通系统成为辅助交通调度不可或缺的工具.智能交通系统利用目标检测和跟踪技术[16, 17, 18], 对车辆进行实时检测和跟踪, 进一步自动获取车辆的流量、车速、车流密度、道路拥塞状况等信息, 辅助交通调度.所以, 在视频中快速定位和跟踪目标是智能交通的关键.
5)智能视觉导航.随着摄像机硬件设备和视频处理技术的快速发展, 基于计算机视觉的智能导航技术具有较广泛的应用(如智能机器人、无人驾驶汽车及无人驾驶飞机等).智能导航技术利用摄像头或其它传感器对周围环境和运动物体进行检测和跟踪[19, 20], 使机器能安全运转及获取有用信息进行特殊的作业或任务.如何在摄像机运动时快速精确地实现检测和跟踪是智能视觉导航的关键.
6)三维重建.基于视频图像序列的三维重建(如人体三维运动和姿态重构[21, 22]、 城市建模[23, 24]等)一直是计算机视觉领域的一个研究热点, 是数字博物馆、智能导航、计算机动画、人机交互等诸多应用的关键技术.视觉跟踪技术能够计算摄像头或人体各个关键部分的运动参数, 为后续的三维重构提供支持.除此之外, 视觉跟踪技术还在航空航天[25]、医疗诊断[26, 27]、虚拟现实[28]、增强现实[29]等方面应用广泛.
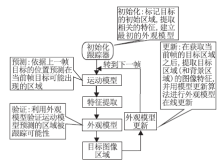
在线视觉跟踪的基本框架如图1所示.一般在线视觉跟踪具有4个基本组成部分:特征提取、运动模型、外观模型、在线更新机制.
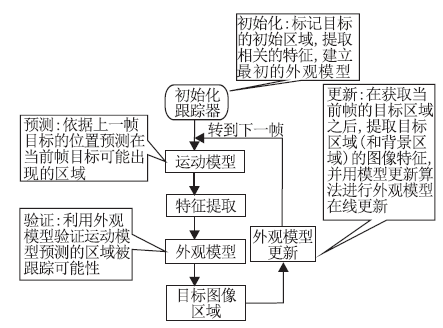 | 图1 在线视觉跟踪的基本框架图Fig.1 Basic framework of online visual tracking |
特征提取.在线视觉跟踪算法要求提取的视觉特征既能较好地描述跟踪目标又能快速计算.常见的图像特征有灰度特征[30]、颜色特征[31]、纹理特征[32]、Haar-like矩形特征[33]、兴趣点特征[34]、超像素特征[35]等.
运动模型(Motion Model).运动模型旨在描述帧与帧目标运动状态之间的关系, 显式或隐式地在视频帧中预测目标图像区域, 并给出一组可能的候选区域.经典的运动模型有卡尔曼滤波(Kalman Filtering)[36]、粒子滤波(Particle Filtering)[37, 38]等.
外观模型.外观模型的作用是在当前帧中判决候选图像区域是被跟踪目标的可能性.提取图像区域的视觉特征, 输入外观模型进行匹配或决策, 最终确定被跟踪目标的空间位置.在视觉跟踪的4个基本组成中, 外观模型处于核心地位, 如何设计一个鲁棒的外观模型是在线视觉跟踪算法的关键.
在线更新机制.为了捕捉目标(和背景)在跟踪过程中的变化, 在线视觉跟踪需要包含一个在线更新机制, 在跟踪过程中不断更新外观模型.常见的外观模型更新方式有模板更新、增量子空间学习算法及在线分类器等.如何设计一个合理的在线更新机制, 既能捕捉目标(和背景)的变化又不会导致模型退化, 也是在线视觉跟踪研究的一个关键问题.
以前目标跟踪的研究更多局限于在可控条件(如静态背景、光照均匀等)下对特定目标(如人脸、行人、车辆等)实施跟踪, 而在线视觉跟踪旨在对现实场景中的任意目标进行跟踪.由于现实场景的复杂性和目标物的不确定性, 实现在线视觉跟踪存在诸多挑战, 部分在线视觉跟踪的挑战如图2所示.
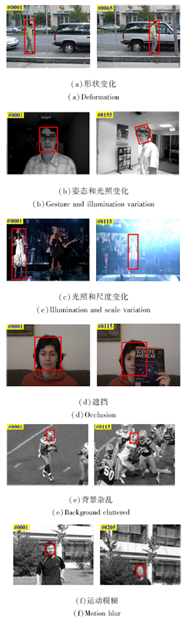 | 图2 在线视觉跟踪的挑战Fig.2 Challenge for online visual tracking |
这些挑战主要可分为由目标内在变化引发的挑战(如姿态变化、形状变化等)和由外在因素引发的挑战(如光照变化、运动模糊、遮挡、背景杂乱等), 它们为实现在线视觉跟踪造成很多困难:如姿态和形状变化会造成被跟踪目标外观在不同帧之间存在较大的差异; 光照通常会引起被跟踪目标外观的明暗变化并带来不可预知的阴影; 遮挡会造成目标外观的不完整或给目标区域引入背景干扰; 目标的快速运动会造成运动模糊, 使被跟踪目标变得不易分辨; 在杂乱的背景中, 跟踪算法难以较好地鉴别目标和周围的背景, 容易发生跟踪漂移.
在线目标跟踪算法一般由人工设计特征和浅层外观模型构成, 旨在利用简单有效的视觉特征和浅层匹配或分类模型设计快速鲁棒的跟踪算法, 如早期均值偏移算法、子块跟踪算法、子空间算法等.这些算法能在有效计算资源情况下取得一定的跟踪效果和速度, 但通常不够鲁棒.稀疏表示理论在计算机视觉方面的成果应用使研究学者不断尝试利用稀疏表示模型和稀疏特征编码解决在线目标跟踪问题, 取得非常卓越的效果.但稀疏表示模型计算复杂度较高, 难以实时处理.鉴于外观模型在传统视觉跟踪的核心地位, 下面从外观模型建立和决策过程的角度对传统视觉跟踪算法进行概述.
作为一种典型的非参数统计工具, 均值偏移(Mean Shift)[39]算法本质上是基于梯度上升的局部寻优算法, 广泛应用于模式识别、数字图像处理和计算机视觉等领域.Mean Shift 跟踪算法一直是目标跟踪领域研究的一个热点, 很多研究学者不断进行改进, 使其更加稳定和鲁棒.Comaniciu等[31, 36] 最先将Mean Shift算法用于跟踪领域, 实现简单, 速度较快, 对目标的非刚性变化、旋转等挑战都具有较好的鲁棒性, 但是不能较好地解决遮挡、背景杂乱、尺度变化等挑战.为了解决局部遮挡问题, Wang等[44] 提出基于分块Mean Shift的跟踪算法, 通过不同分块对中心位置的加权投票, 降低被遮挡的目标区域对跟踪结果的影响.Collins等[40] 结合尺度空间(Scale Space)理论和Mean Shift算法, 在一定程度上提升Mean Shift算法对目标尺度变化的稳定性.考虑到Mean Shift是一个局部寻优算法, 容易陷入局部最小值, Hager等[41] 通过在多个尺度上选择最稳定的核宽, 减少局部最小值的影响.此外, 也有学者结合局部寻优的Mean Shift算法和全局寻优的粒子滤波(Particle Filtering)算法[42], 快速寻找全局最优值.
基于 Mean Shift 的跟踪算法属于基于模板匹配的跟踪算法, 主要通过Mean Shift非参数局部寻优工具搜索和目标模板相似度最大的候选区域.在目标跟踪领域, 基于模板匹配的跟踪算法在当前仍较活跃, 如何设计有效的目标描述机制和鲁棒的相似度函数或距离函数是此类算法的关键.
早期的目标跟踪算法常采用简单有效的全局直方图, 但这会丢失特征的空间位置信息, 导致跟踪算法在遮挡或背景杂乱等情况下容易失败.Adam等[43] 提出子块跟踪(Frag Track), 利用分块-联合机制克服传统模板跟踪算法(如Mean Shift)对遮挡敏感的问题.受到子块跟踪算法的启发, 在视频跟踪领域, 越来越多的学者考虑采用分块的方式, 引入特征的空间位置信息.Wang等[44] 将分块的思想引入Mean Shift跟踪框架, 提出基于分块 Mean Shift的跟踪算法.通过不同分块对中心位置的加权投票降低被遮挡的目标区域对跟踪结果的影响.Jia等[45] 提出基于分块多核学习的跟踪算法, 利用多个分块灰度直方图描述目标, 并利用在线多核学习选择具有判决性的分块.Yang 等[46] 采用由随机分块组成的词包(Bag-of-Words)描述被跟踪目标, 提出基于词包学习的视觉跟踪算法.除此之外, 基于局部图像块稀疏编码特征的跟踪算法[47, 48]目前也取得较好的效果.在具体跟踪算法设计中, 如何选择分块的方式和分块的大小仍需研究和探索.
线性子空间学习(简称子空间学习)算法是模式识别和机器学习领域的一个研究热点, 基于线性子空间的目标跟踪可看作是子空间学习算法在视觉跟踪领域的延伸和扩展.通过学习一组线性投影, 实现高维特征空间到低维空间的映射, 保持或获得某种属性(如保留整体或局部距离、提取判决性的特征等).子空间学习算法有基于重构准则的主成分分析(Principal Component Analysis, PCA)[49] 、基于判决准则的线性判决分析(Linear Discriminant Analysis, LDA)[50] 、具有流形和图论背景的局部保持映射(Local Preserving Projection, LPP)[51] 、基于向量子空间算法的图嵌入(Graph Embedding, GE)框架[52] .由于子空间学习算法的输入特征都是向量形式, 所以称其为一维(1D)子空间算法.除此之外, 子空间算法还包括多维子空间算法.
目标在跟踪过程中可能出现较大的变化, 单一PCA子空间可能不足以描述所有的变化.为此, Yu等[53] 提出增量多流形子空间模型, 相比增量视觉跟踪器(Incremental Visual Tracking, IVT)中仅使用一个PCA子空间在线学习外观模型, 该算法可利用若干个 PCA子空间, 用于分段线性近似跟踪过程中目标的非线性变化.尽管该模型在处理目标的非线性变化上具有一定的优势, 但由于算法复杂, 导致跟踪的速度较慢.
通常子空间算法都会假设数据服从高斯分布或局部高斯分布, 但在跟踪问题中背景分布较混乱, 难以满足子空间算法的假设.所以基于判决性子空间的跟踪算法往往结果不稳定, 未达到很好的效果.
未来基于子空间的跟踪算法的研究主要集中在如下2个方面:如何构造一个子空间使之能更好地描述被跟踪目标的外观变化; 如何处理遮挡等异常噪声情况.
自Donoho等[54]完成较严密的理论工作后, 压缩感知和稀疏表示算法在很多计算机视觉应用领域都得到广泛研究, 包括图像去噪、图像修复、图像去模糊、超分辨重建等[55].
Mei等[56]提出基于 l1 最小化的目标跟踪算法, 首次将稀疏表示理论用于解决跟踪问题.假设被跟踪的目标能由目标模板和遮挡模板组成的字典稀疏表示, 其中目标模板动态更新以捕捉目标在跟踪过程中的变化, 而遮挡模板用于描述目标可能遭遇的遮挡, 如图3所示, 其中遮挡模板由正负琐碎模板组成.(b)为好的和差的跟踪候选的稀疏表示系数的差别, 左侧显示当前视频帧的图像, 紫红色曲线框内显示当前存储的目标模板, 红色和蓝色框分别表示一个好的和一个差的目标候选, 右侧显示好的和差的候选图像区域的稀疏表示系数.可看出, 好的候选表示系数明显稀疏于差的候选表示系数, 这说明稀疏限制有利于定位好的目标候选, 获取精确的跟踪结果.
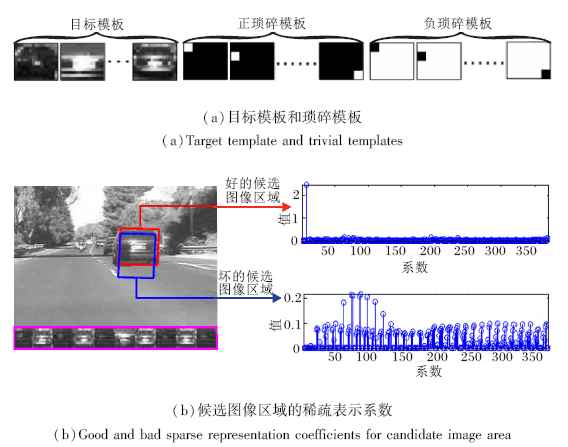 | 图3 好的和差的候选图像的区别Fig.3 Differences between good and bad candidate images |
Yang等[57]开始探索基于稀疏表示的目标跟踪算法, 最常用的是利用稀疏表示建模目标的外观.如何合理地选择目标模板和遮挡模板建模跟踪目标及如何设计快速有效的跟踪算法是这类算法的关键.
在视觉跟踪中, 稀疏表示算法还用于特征提取[48] 、特征选择[47] 及运动状态建模[58] 等方面.
基于稀疏表示的跟踪算法是未来在线视觉跟踪领域的一个研究热点, 如何更好地结合稀疏表示等理论与跟踪问题的先验知识仍是未来研究趋势.
基于判别学习的目标跟踪算法将目标跟踪看作一个二分类问题, 试图从周围的背景中鉴别跟踪目标, 因此目标跟踪的准确性和稳定性很大程度依赖于在特征空间上目标与背景的可分性.在跟踪过程中, 被跟踪的目标和周围背景的外观一般都会发生变化, 导致判别性的特征集合也会发生变化.因此, 在线建立能适应目标和背景外观变化的判别模型是这类算法的关键.基于判别学习的目标跟踪算法基本包含基于像素或超像素级分类的跟踪和基于检测的目标跟踪这两大类.
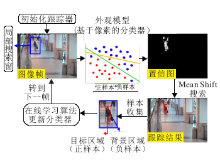
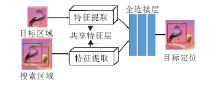
基于像素或超像素级分类的跟踪算法通过分类当前图像帧中搜索区域内的像素或超像素, 形成一个关于跟踪目标的置信图, 然后利用Mean Shift等模态搜索算法精确定位目标.基于像素分类的跟踪算法的流程图如图4所示.基于像素分类的跟踪算法速度较快, 可以提供对目标的软分割(Soft Segmen-tation), 但是不能处理遮挡和背景杂乱的情况.
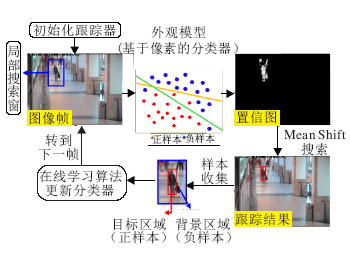 | 图4 基于像素分类的跟踪算法流程图Fig.4 Flowchart of tracking algorithm based on pixel classification |
基于检测的目标跟踪算法将目标跟踪当作一个局部搜索区域内的检测问题, 通过在线学习分类器实现目标跟踪.受到人脸检测和使用检测实现跟踪的启发, 学者们开始使用Boosting算法建立外观模型, 用于视觉跟踪.Grabner等[59]提出在线的Adaboost算法( Online Adaboost, OAB)用于视觉跟踪.随后又将半监督学习(Semi-supervised Learning)算法与 OAB相结合, 提出Semi-Boost 跟踪算法[60] , 极大地提高跟踪算法的鲁棒性和适应性.
总体上, 基于检测的跟踪算法和机器学习的分类器算法联系紧密.未来基于判决学习的目标跟踪算法将是在线视觉跟踪研究的一个热点方向.机器学习算法的发展仍会成为该方向发展的重要推动力.
除此之外, 比较活跃的在线视觉跟踪算法研究方向还有:基于主动轮廓(Active Contour)或水平集(Level Set)的目标跟踪[61] 、基于图割(Graph Cuts)的目标跟踪[62] 、基于兴趣点(Interest Point) 的目标跟踪[63] 、基于度量学习(Metric Learning)的目标跟踪[64] 等.
目标跟踪运用各种方法根据已知观测图像估计当前图像中目标物体的位置.使用目标图像训练的滤波器对图像进行滤波处理, 在响应图像中寻找最大值位置, 即图像中对应的目标位置.在这种情况下可把目标跟踪的过程近似地看成对搜索区域图像进行相关滤波(Correlation Filter)的过程, 寻找目标位置也就是寻找滤波器响应图像的最大值位置.下面从基础算法以及对基础算法改进的角度概述相关滤波算法, 并给出简要分析.
Bolme等[65]提出相关滤波(Correlation Filter)用于目标跟踪.基于输出结果的最小均方误差训练滤波器, 作用于搜索区域, 可以得到响应图像, 值越大说明该位置处的图像与初始化目标相关性越大, 提高滤波器的准确度和稳定性.与此同时, 算法采用灰度特征, 速度超过600帧/s.这种相关滤波跟踪算法即是常说的平方误差最小滤波器(Minimum Output Sum of Squared Error, MOSSE)[65], 可以算得上最早关于相关滤波的算法.
随着基于检测跟踪算法(Tracking by Detection)的广泛应用, 相关滤波得到进一步发展.在相关滤波跟踪算法中, 关键部分是训练一个具有判别性的相关滤波器, 用于区分前景和背景.Henriques等[66]针对相关滤波中样本数量不足对分类器结果的影响, 创新循环密集采样方法.利用中心图像块循环移位近似窗口移位, 如图5所示.
图5(a)中间为中心图像块, 位于它左右的图像块是中心图像块沿x轴分别左右移动10个像素得到的图像块, 位于它上下的图像块是中心图像块沿y轴分别移动10个像素得到的图像块.(b)是中心矩阵循环移位后对应的图像相应地上下左右偏移, 循环采样粒子可组成循环矩阵.在训练滤波器时, 利用循环矩阵时域和频域的特殊性质, 将优化求解中的复杂矩阵求逆转变为简单矩阵点除.在进行目标跟踪时, 将滤波器与粒子的相关性操作变成频域内的点乘操作, 大幅减少计算量, 显著提高训练速度.算法采用单通道灰度特征, 可以实现简单跟踪, 但当遇到目标遮挡、背景复杂、目标旋转及尺度变化等情况时, 容易发生跟踪漂移.
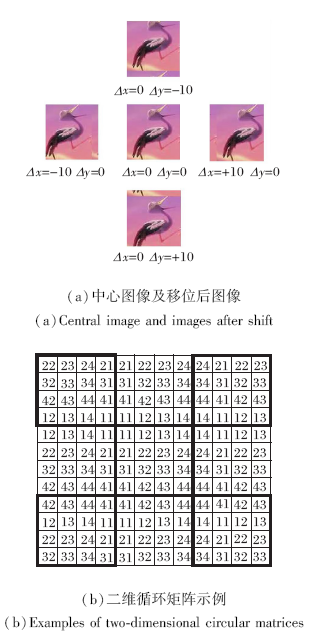 | 图5 循环样本及循环矩阵示例Fig.5 Examples of circulate samples and circulate matrices |
为了提升算法性能, Henriques等优化CSK[66]的特征部分, 提出基于颜色空间的算法(Color Name, CN)[67] .对RGB 颜色空间进行扩展, 提出CN空间, 该空间通道数为11(包括黑、蓝、棕、灰、绿、橙、粉、紫、红、白和黄).将CN空间内提取的图像特征代入原训练公式, 对每个通道进行快速傅里叶变换, 并进行特征加和.虽然对算法精度有所帮助, 但多通道特征使运算量加大, 影响算法速度.为了降低运算量, 作者提出使用PCA降维的方法提取更有效的特征.除了对颜色空间进行改进之外, Henriques 等[68] 在相关滤波中引入核空间, 同时提出将多通道特征融入相关滤波的方法.采用方向梯度直方图(Histogram of Oriented Gradient, HOG)特征, 通过核函数将原来线性空间中的脊回归映射到非线性空间, 在非线性空间中求解一个对偶问题和某些常见的约束, 同样可以利用循环矩阵傅里叶空间对角化简化计算.
HOG特征对运动模糊、光照变化及颜色变化等很鲁棒, 但对形变的鲁棒性较差.颜色特征对形变鲁棒性较好, 但对光照变化不够鲁棒.如果将2种特征进行有效结合, 将会提升跟踪算法的精度.Bertinetto等[69]提出STAPLE(Complementary Learners for Real-Time Tracking), 从特征融合方面入手, 改进跟踪算法.利用HOG特征训练相关滤波器, 得到跟踪得分, 并融合使用颜色直方图得到的统计得分进行, 得到最后的响应图像并估计目标位置.两种特征的融合提高跟踪算法的准确度, 但也使得计算略微复杂.
除了采用多种颜色特征之外, 还有一些算法将多核方法(Multi-kernel)应用到相关滤波中, 取得不错的效果.核函数可以将原本线性空间内不可分的样本映射到高维空间, 增加样本的可分性.单核学习中, 核函数的选择通常根据经验人为设定, 这样的核函数不一定最优, 而多核学习旨在通过多个核函数按权重融合或自适应的选择解决人工设定带来的不合理性.Tang等[70]提出多核相关滤波器(Multi Kernelized Correlation Filter, MKCF), 在核化相关滤波器(Kernelized Correlation Filter, KCF)[68] 中引入多核, 并提出优化求解方法.Zhang等[71] 融合多特征与多核, 将多个滤波器进行有效整合, 并通过最后的跟踪结果判断特征与核的权重, 使算法具有自适应选择特征及核的能力.继而, Choi等[72] 对其进行改进, 提出注意力机制相关滤波网络(Attentional Correlation Filter Network, ACFN), 使用注意力网络(Attention Network)选择合适的相关滤波器, 使算法能根据跟踪情况自适应调整选用的特征与核函数.同特征改进相同, 单一特征或单一的核函数很难适应所有的跟踪情况, 因此多特征及多核之间的联合作用通常起到较好的效果.
尺度变化是目标跟踪中一个较常见的问题, 但前述算法中都无法进行尺度估计.当目标尺度缩小时, 会造成选取图像块中包含大量背景信息, 当目标尺度扩大时, 会造成选取图像块中只包含目标的局部信息, 这两种情况都会引起跟踪漂移.为了解决尺度变化对跟踪的影响, 自适应尺度变化的相关滤波跟踪器(Scale Adaptive Kernel Correlation Filter Tra-cker, SAMF)[73] 和判断尺度空间跟踪器(Discrimi-native Scale Space Tracker, DSST)[74] 在KCF[68] 的基础上引入尺度估计.SAMF使用7个较粗的尺度, 使用平移滤波器在多尺度图像块上进行检测, 选取响应值最大处对应的平移位置和目标尺度.DSST分别训练平移滤波器和尺度滤波器, 使用33个较精细的尺度, 先使用平移滤波器进行位置估计, 然后在该位置处使用尺度滤波器进行尺度估计.以后的算法中经常使用这两种尺度估计的算法.
此外, 跟踪过程中的物体通常使用一个矩形框选取, 由于跟踪的物体一般不为矩形, 目标图像块不可避免地引入背景信息, 导致跟踪不准确.为了解决这一问题, 可以采用分割算法(Segmentation)或关键点算法(Key Point)表示目标.基于分割的物体表示虽然能较好地表示目标形状, 但计算量过大, 影响跟踪算法的速度.而基于关键点的目标表示难以获取跟踪目标的整体特征, 也不是一个很好的方法.为了解决这一问题, Li等[75]提出选取有效局部图像块表示物体结构, 利用每个局部图像块的响应图像计算其置信度.如图6所示, 这些响应图像按一定方法组合后可大致表示图中物体的形状.算法采用霍夫投票的方法融合多个响应图像, 估计目标位置和尺度.
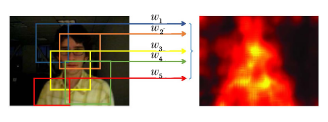 | 图6 RPT局部图像块表示目标物体示意图Fig.6 Schematic diagram of representing target object via PRT local image block |
Liu等[76] 提出使用分块的相关滤波算法增强跟踪器对遮挡的鲁棒性.将目标区域分为5部分, 每部分分别训练相关滤波器, 将得到的响应图像(Response Map)按权重加和, 得到最终的响应图, 由此估计目标状态.根据每个滤波器的权重判断跟踪好坏, 决定是否进行模板更新.Fan等[77]将整体与局部相结合进行目标跟踪, 提出局部全局相结合的相关滤波器(Local-Global Correlation Filter, LGCF).将整个目标区域平分成2× 2的图像块, 在相关滤波优化方程中加入整体和局部的优化方程, 使用交替方向乘子算法(Alternating Direction Method of Multi-pliers, ADMM)进行优化求解.Lukež i
在相关滤波算法中, 通过样本循环移位构造密集采样, 这样样本对应的二分类标签一般采用高斯分布的标签.当上一帧目标跟踪不准时, 由于当前帧的标签是以上一帧中心点为中心产生, 会导致错误的累积, 发生跟踪漂移现象.其次, 这种标签帧间独立, 忽略跟踪过程中物体时间上的关联, 并不可靠.为了克服上述问题, Bibi等[79]提出目标响应自适应相关滤波跟踪算法(Target Response Adaptation for Correlation Filter Tracking, CF+AT), 将原来固定的高斯型标签变为自适应的样本标签, 在KCF[68]的优化方程中同时加入滤波器学习和样本标签先验的学习, 根据样本标签先验信息, 计算每帧的自适应标签, 并提出快速求解的方法.这种自适应样本标签用于相关滤波算法中, 可以提升算法的抗干扰能力, 具有理论上的合理性和实践上的有效性.相同的思想也出现在鲁棒相关滤波器(Robust Correlation Filter, RCF)[80]中, 但做法有所不同.RCF提出现有的相关滤波优化方程中的L2损失项对应的响应为各向同性, 较易受遮挡或光照等因素的影响, 通过引入稀疏性的损失项探索各向异性的响应对跟踪结果的影响, 算法也通过实验证明这种响应更准确鲁棒.
边界效应也是影响滤波器性能提升的一个主要原因.在训练阶段, 由于密集样本是经过中心图像块循环移位得到, 如图5所示, 只有中心样本准确, 其它的样本都会存在位移边界, 导致训练的分类器在物体快速移动时不能准确跟踪.大部分算法的解决方案是在图像上加上余弦窗, 弱化图像边界对结果的影响, 这样只要保证移位后图像中心部分合理即可.虽然增加合理样本的数量, 但仍不能保证所有训练样本的有效性.另外, 加入余弦窗也会使跟踪器屏蔽背景信息, 只接受部分有效信息, 降低分类器的判别能力.在目标检测阶段, 当物体处于搜索区域的边界时, 余弦窗的加入使物体信息弱化甚至清除, 导致跟踪失败.为了克服边界效应, Galoogahi等[81] 采用较大尺寸的检测图像块和较小尺寸的滤波器, 提高真实样本的比例, 并采用ADMM迭代求解.Danell-jan等[82]提出空间约束相关滤波器(Spatially Regu-larized Correlation Filter, SRDCF), 采用更大的检测区域, 在滤波器系数上加入权重约束, 越靠近边缘权重越大, 越靠近中心权重越小, 使滤波器系数主要集中在中心区域.由于滤波器在整个搜索区域内移动检测图像块的相关性, 因此在克服边界效应的同时不会忽略边缘物体的检测.
在SRDCF的基础上, Danelljan等[83]提出连续域卷积相关滤波算法(Continuous Convolution Opera-tors for Visual Tracking, CCOT).将原来时域离散的位置估计转换为时域连续的位置估计, 使位置估计更准确.此外, 算法还在相关滤波算法中融合分辨率不同的图像特征, 将多种传统特征与深度特征相结合, 提升算法精度.CCOT中对待高维特征的方法是每个通道训练一个相关滤波器, 使算法存在大量的冗余, 也影响算法速度.继而, Danelljan等[84]改进CCOT, 从训练样本、滤波器系数和模板更新3个方面去除冗余, 提出高效卷积操作(Efficient Convolu-tion Operators, ECO).算法指出, 相邻帧之间的样本具有很多冗余信息, 影响样本多样性, 限制分类器性能.使用高斯混合模型对样本建模, 可以有效增强算法性能.同时, 训练代表性滤波器, 并用线性组合表示其它滤波器, 每隔6帧更新一次, 大幅降低计算量.Lukež i
一些算法结合循环矩阵与其它方法, 提高速度和精度.支持向量机(Support Vector Machine, SVM)能准确区分目标和背景, 但粒子滤波(Particle Filter)的框架导致算法速度较慢.相关滤波算法得益于循环矩阵的特殊性质, 能将运算转换到频域进行简化.Zuo等[87]结合SVM与循环矩阵, 提出支持相关滤波器(Support Correlation Filter, SCF), 并给出优化方程在频域中的简化计算方法.Wang等[88]结合结构化SVM与相关滤波算法, 提出LMCF(Large Margin Object Tracking with Circulant Feature Maps), 分类器使用结构化SVM, 循环采样目标框作为训练样本.对响应图像进行多峰检测, 并自适应进行模板更新, 提高定位精度.此外, Zhang等[89]结合粒子滤波与相关滤波算法, 提出多任务相关粒子滤波器(Multi-task Correlation Particle Filter, MCPF), 利用相关滤波的响应图像引导采样粒子趋近于样本的真实分布, 同时利用循环密集采样减少粒子个数, 提升算法速度.随着深度学习的流行, 有些算法也结合相关滤波与深度学习.
在现阶段, 相关滤波算法凭借良好的精度与速度综合性能得到广泛应用, 也发展出一系列基于相关滤波改进的目标跟踪方法, 从特征、核、尺度、分块、样本标签、边界效应及结合其它算法等方面进行改进, 使算法精度得到大幅度提升, 但仍存在一些问题需要解决.
现存的算法大部分是取一定面积的搜索区域用于图像滤波操作.如果搜索区域过小, 在目标快速移动时会检测不到目标.如果搜索区域过大, 引入过多背景信息, 当背景复杂时, 容易造成跟踪漂移, 大部分算法一般取目标大小的2~3倍作为搜索区域.这种限定区域的搜索方法具有一定的局限性, 不能保证完全准确的跟踪.同时, 用于训练分类器的负样本均为中心样本循环移位得到, 负样本的局限性不能保证分类器的判别性能.
近些年, 深度学习方法(Deep Learning)借助其优秀的特征建模能力, 在目标跟踪领域取得巨大成功.在基础测试数据库(OTB, VOT等)上, 准确度排名前几的算法都是基于深度学习的目标跟踪算法.采用粒子滤波的深度目标跟踪算法一般需要上百个粒子训练分类器或匹配器, 每个粒子都要经过复杂的卷积层以提取特征, 增加算法复杂度, 限制算法速度的提升.为了同时保证算法精度与速度, 很多算法结合深度学习方法与相关滤波算法, 取得不错效果.
相关滤波算法的核心思想是将目标模板与搜索区域内滑动窗口取得的图像块进行相关性匹配, 响应最大位置处对应的图像块为目标图像块.为了加快相关性对比的速度, 利用中心样本循环移位, 近似滑动窗口取出的图像块, 并利用循环样本构建二维循环矩阵, 将计算转换至频域加速.相比传统特征, 深度神经网络提取的图像卷积特征具有良好的抗干扰能力, 在大规模图像分类比赛中取得巨大的成功.但是, 多层卷积计算使特征提取部分耗时较多, 对多粒子图像块的算法不利.因此, 相关滤波在深度目标跟踪中具备很好的应用前景.
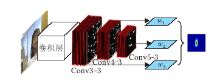
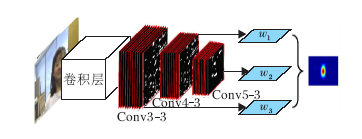
Ma等[90]提出基于多层卷积特征的跟踪器(Hierarchical Convolutional Features for Visual Tracking, HCFT), 结合深度特征与相关滤波算法, 取得很好的效果.算法指出深度神经网络不同层的特征具有不同的特点, 浅层特征包含更多的位置信息, 但语义信息不明显.深层特征包含更多的语义信息, 抗干扰能力较强, 但位置信息弱化, 因此不同层特征结合有助于效果的提升.如图7所示, 使用VGG16分别提取Conv3-4, Conv4-4和Conv5-4层的输出特征, 训练各自的相关滤波器.在目标检测时, 将搜索区域的三层特征输入对应的相关滤波器, 得到响应图像, 按权重相加得到最终响应图像, 通过最大值位置定位目标.实验表明, 相比传统特征, 深度特征具有良好的鲁棒性, 相关滤波算法使得多层特征的利用变得可行.
与HCFT[90] 类似, 强化深度跟踪(Hedged Deep Tracking, HDT)[91] 也采用多层深度特征与相关滤波相结合的方法.由原来的三层深度特征变为六层深度特征, 将原来固定权重相加的方法变为自适应权重相加.Danelljan等[82]在SRDCF 的基础上引入深度特征, 构成DeepSRDCF(Deep Features for SRDCF), 与文献[90] 和文献[91] 不同, DeepSRDCF提出使用VGG网络的第一层卷积特征效果优于深层特征, 同时浅层特征提取速度更快, 有利于算法速度提升.CCOT[83] 在特征融合上进行改进, 创建时域连续的相关滤波器进行更精确的定位, 使滤波器输入可以是不同分辨率的特征图, 实现传统特征与深度特征的融合, 高维特征训练多个滤波器, 增加算法复杂度, 算法速度较慢.为了加快算法速度, ECO[84] 从滤波器系数、样本和模板更新3个方面进行去冗余操作.除了采用大规模图像分类网络提取的特征之外, 基于深度运动特征的SRDCF(Deep Motion Features for SRDCF, DMSRDCF)[92] 采用深度运动特征进行目标跟踪.
现今深度学习与相关滤波的结合不仅局限于使用深度网络提取特征, 一些算法结合特征提取与分类器, 使用神经网络模拟相关滤波的整个过程.在相关滤波中, 需要保存模板信息并提取搜索区域特征, 因此基于相关滤波思想的网络一般都采用孪生网络(Siamese Network)结构, 其中一条支路保存目标模板信息, 另一条支路用于搜索区域特征提取, 最后将两部分特征进行相关操作, 得到响应图像(Response Map), 根据响应图像最大值位置判断目标状态.Bertinetto等[93] 提出Siamese-FC, 构造孪生网络结构, 分别提取目标特征和搜索区域特征进行相关操作, 使用大规模视觉图像识别比赛(ImageNet Large Scale Visual Recognition Competition, ILSVRC)中的视频对网络进行训练.使用模板支路信息引导跟踪, 取代网络的在线更新, 算法精度与速度都能得以保障.基于相关滤波的网络(Correlation Filter Based Network, CFNet)[94] 和判别相关滤波网络(Discriminant Correlation Filter Based Network, DCFNet)[95] 将滤波器系数转换为神经网络的一层, 推导前向与后向传播的公式, 实现网络的端到端训练, 算法速度可达每秒几十帧甚至上百帧.
神经网络功能多种多样, 除负责相关滤波跟踪算法中的特征提取和相关性操作之外, 还可以作为辅助网络进行特定区域显著性增强或自适应选择.Cui等[96]提出循环目标强化跟踪算法(Recurrently Target-Attending Tracking, RTT), 使用RNN网络提取显著性图, 显著性图在目标部分具有较高的值, 将它加到相关滤波器系数上, 增强相关滤波器对于背景噪声信息的抗干扰能力, 也使得滤波器能更好地关注对结果有帮助的部分.注意力机制相关滤波网络(Attentional Correlation Filter Network, ACFN)[72]训练注意力机制的神经网络(Attention Network), 对多个特征及滤波器核进行选择, 主体部分由不同特征和核函数组成的多个相关滤波器构成, 将多个滤波器的输出送到注意力机制的神经网络中, 判断结果可靠部分, 引导下一帧目标定位及相应的滤波器更新, 取得不错的效果.神经网络灵活多样, 相信在未来的相关滤波算法中能够得到更广泛的应用.
目前, 大部分深度学习算法都使用CNN网络结构, 小部分使用RNN或自己设计的网络结构.与传统算法类似, 也可分为判别式算法与生成式算法.判别式算法基于粒子滤波或相关滤波框架(上面已讨论基于相关滤波的深度目标跟踪算法, 这里不重复讨论), 通过训练分类器区分前景和背景.生成式算法运用生成模型描述目标的表观特征, 之后搜索候选目标最小化重构误差, 采用孪生网络结构.
Wang等[97]提出深度目标跟踪(Deep Learning Tracking, DLT), 使用4个堆叠的栈式降噪自编码器(Stacked Denoising Autoencoder, SDAE)在大规模自然图像数据集上进行无监督训练, 获得物体表征能力, 然后在解码器后面加入sigmoid分类层用于区分目标和背景图像块.根据分类最高得分判断是否进行模型更新, 当得分高于一定阈值时进行模型更新.由于训练数据不足, 网络并没有获得很好的表征能力, 算法精度不高, 但它提出的“ 离线预训练+在线微调” 的方法为深度学习在目标跟踪中的应用提供一个可行的方向, 之后很多算法都采用这种方法进行目标跟踪.
特征强化深度目标跟踪(Transferring Rich Feature Hierarchies for Robust Visual Tracking, SO-D-LT)[98] 延续DLT[97] “ 离线预训练+在线微调” 的方法, 将原来的全连接网络(Fully Connected Network)变为卷积神经网络(Convolutional Network), 在最后一层卷积后面连接不同尺度的池化层, 输出特征经过全连接层得到目标位置概率图, 用于目标定位.为了解决训练样本不足的问题, 在网络离线训练中使用ImageNet 2014检测数据集.模型更新采用长期与短期CNN相结合的方式, 使算法既能适应目标外观的变化, 又能具备一定的抗干扰能力.该算法成为大规模图像数据集训练CNN模型在目标跟踪领域的一次成功应用.
近几年, 随着大规模图像分类比赛的流行, 很多典型卷积网络被应用到图像处理领域, 如AlexNet[99] , VGGNet[100] , GoogleNet[101] 和残差网络(Residual Network, ResNet)[102] 等, 也出现很多基于这些网络的目标跟踪算法.Wang等[103]提出基于全卷积网络的跟踪算法(Fully Convolutional Network Based Tracking, FCNT), 利用VGG-16网络, 提出深度神经网络不同层的特征具有不同的特点, 浅层特征含有较多位置信息, 深层特征含有更多语义信息, 而且深度特征存在大量冗余.因此, 算法针对Conv4-3和Conv5-3两层输出的特征图谱, 训练特征选择网络分别提取有效的特征, 降低特征维度.然后将选好的特征输送到各自的定位网络中, 得到热力图, 综合2个定位网络的热力图得到最终的热力图, 用于目标定位.算法利用不同层特征相互补充, 达到有效抑制跟踪器漂移, 同时对目标本身形变更鲁棒的效果.多特征补充可以弥补单一特征的不足, 多分类器也能弥补单一分类器的不足.基于序列训练卷积网络的跟踪算法(Sequentially Training Convo-lutional Networks for Visual Tracking, STCT)[104] 在特征提取网络的后面连接多个卷积层训练弱分类器, 综合弱分类器结果得到强分类器, 提升算法精度.
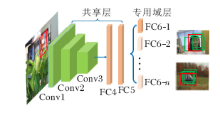
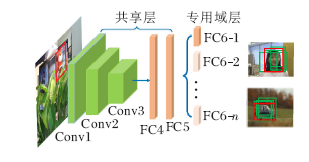
图像分类中的图像分辨率较高, 主要目的是判断图像中物体所属类别.目标跟踪中图像分辨率一般较低, 只要目的是对图像中的目标进行定位, 可能会遇到背景杂乱和目标太小等情况.虽然在大规模图像分类比赛中训练的网络在目标跟踪任务中的成绩不错, 但仍不能完全适用于目标跟踪任务.目标跟踪中可能出现图像分类任务中未包含的物体种类, 随着网络的深入, 目标位置信息的削弱不利于目标定位.为了扩展CNN在目标跟踪领域的能力, 需要大量的训练数据, 但这在目标跟踪中很难做到.Nam等[105] 提出多域网络(Multi-domain Network, MDNe-t), 解决上述问题.如图8所示, 算法采用在图像分类任务中预训练的模型VGG-M作为网络初始化模型, 后接多个全连接层用于分类器.训练时, 每个跟踪视频对应一个全连接层, 用于学习普遍的特征表示跟踪.跟踪时, 去掉训练时的全连接层, 使用第一帧样本初始化一个全连接层, 新的全连接层在跟踪过程中继续微调, 适应新的目标变化.这种方法使特征更适合于目标跟踪, 效果大幅提升.由此可看出, 通过视频训练的网络更适合目标跟踪这一任务.后来, 结构关注网络(Structure-Aware Network, SANe-t)[106] 针对MDNet[105] 进行改进, 将RNN网络得到的目标显著性图融入到原网络中, 使网络能更关注对结果有用的部分.树状卷积神经网络(CNNs in a Tree Structure, TCNN)[107] 采用未经视频训练的VGG-M网络提取特征, 改进后面全连接层结构为树状结构, 采用多个可信度高的全连接层共同决定最终结果.
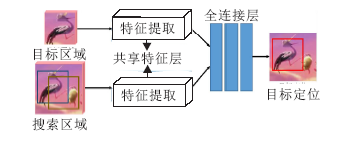
基于粒子滤波框架的深度学习算法由于需要提取多个图像块的深度特征, 速度难以达到实时性要求.为了提升算法速度, Held等[108]提出利用回归网络的通用目标跟踪框架(Generic Object Tracking Using Regression Networks, GOTURN).如图9所示, 将上一帧的目标和当前帧的搜索区域同时经过CNN的卷积层, 级联特征输出通过全连接层, 回归当前帧目标的位置, 由于没有模板更新, 算法速度可超过100帧/s.Redmon等[109]提出YOLO, 构建孪生网络输出目标概率图, 得到目标状态.这种基于模板匹配的目标跟踪算法使用一条支路保存模板信息, 为目标跟踪提供先验信息, 取代全连接层在线更新, 算法速度一般较快.
与分类图像不同, 视频图像的帧与帧之间具有很强的时间及空间连续性, 这种视频信息对于跟踪结果的准确性及算法速度的提升都有较大帮助.虽然CNN网络的特征提取能力很好, 但没有办法建立视频帧之间的时间连续性.循环YOLO(Recurrent YOLO, ROLO)[110] 采用YOLO进行候选样本检测, 将检测图像块输送到长短期记忆模块(Long Short-Term Memory, LSTM)输出目标框信息, 利用LSTM保存帧间连续性信息.循环神经网络在文本和语义等方面得到广泛应用, 能建模前后文之间的关系, 在目标跟踪领域具有广阔的发展前景.
近几年, 强化学习(Reinforcement Learning)受到广泛关注, 作为一种介于半监督与无监督之间的训练方法, 适用于目标跟踪这种缺乏训练样本的领域.动作决策网络(Action-Decision Network, AD-Net)[111]是强化学习在目标跟踪领域的一个成功应用.通过强化学习得到一个智能体(Agent), 预测目标框的移动方位及尺度变化, 在当前帧中, 以前一帧的目标位置为初始点, 经过多次方位估计、位移和尺度变化, 得到最后的目标位置.与此不同, Choi等[112]提出强化决策跟踪算法(Reinforcement Deci-sion Making Tracker, RDMT), 利用策略学习(Policy Gradient)得到智能体用于模板选择.无监督或弱监督学习是目标跟踪领域的一个新兴方向, 具有巨大的潜力.
综合现存深度目标跟踪算法的结果, 判别式模型的效果优于生成式模型.在判别式模型中, 训练分类器区分目标物体和背景; 而在生成式模型中, 训练匹配器用于模板匹配.由于目标跟踪任务中训练数据的缺乏, 很难训练一个代表性的网络模型, 因此很多跟踪算法采用已有的网络模型作为算法预训练模型, 这些网络在大规模图像分类数据集上训练, 更适合进行分类任务, 所以在判别式网络模型中表现更优.在目标跟踪领域, 分类任务只是单纯的二分类, 当样本分值达到阈值后就可作为正样本, 而在回归任务中, 只有当输出结果与标签完全吻合时, 输出损失才为0, 因此相比回归任务, 区分前景与背景对于网络来说是一个更简单的任务.
特征好坏是影响跟踪器效果的一个重要因素.目标跟踪任务中的视频图像不同于图像分类和目标检测, 像素值较低.随着网络深度的增加, 会对图像信息造成较大的损失.很多优秀的目标跟踪算法采用小型神经网络(如VGG-M)进行特征提取, 可以有效防止信息损失.除此之外, 这种小型网络提取特征时间较短, 有助于算法速度的提升.浅层特征可适用于大部分跟踪情况, 但当目标发生较严重形变或外界环境变化较复杂时, 抗干扰能力不够.将浅层特征与深层特征进行结合往往对算法精度具有较大帮助, 但同时深度特征的提取也会影响算法速度.根据不同层特征特点, 自适应选择特征是一种同时保证算法精度和速度的好方法.
发展至今, 目标跟踪算法已取得很大的进步, 特别是深度神经网络的引入, 使算法精度得到大幅提升, 但仍存在一些需要解决的问题.
速度是评价在线目标跟踪算法的一个重要指标.由于深度神经网络复杂的计算及模型更新时繁琐的系数, 现存大部分深度目标跟踪算法速度都较慢.目标跟踪中大部分为低像素图像, 不适合使用层数太多的卷积网络, 是因为信息损失严重, 也影响计算速度.很多深度目标跟踪算法采用小型神经网络(如VGG-M)提取特征.另外, 跟踪中只给定第一帧目标位置, 缺少跟踪物体先验信息, 这就要求模型实时更新以确保跟踪精度, 而这在深度目标跟踪算法中非常耗时.一些算法采用孪生网络结构保存先验信息, 代替模型在线更新, 算法速度得以提高.深度特征的高维度也会影响跟踪算法的速度, 如果能提出有效的特征压缩方法, 不管对算法速度还是精度都会有所帮助.只有高速且有效的算法才具有实际的应用价值.
影响深度神经网络效果的两个主要因素是网络结构和训练数据.现存大部分深度目标跟踪算法均采用CNN结构, 虽然CNN结构的特征提取能力很好, 但是难以建模视频帧中的时间连续性信息.一些算法采用RNN结构构建目标跟踪模型, 但效果并不是很突出, 仍需探索发展.还有一些新型的网络架构(如ResNet和DenseNet等)在图像分类领域取得很好的效果, 这些网络架构是否能在目标跟踪领域成功应用也是令人期待.另外, 限制深度目标跟踪算法发展的一个主要原因是训练样本的缺乏, 没有如同图像分类任务那样的大规模训练样本, 在线跟踪时只能给定第一帧的信息, 难以训练一个适合当前跟踪物体的网络模型.近几年, 无监督或弱监督方法受到人们的广泛关注.也有一些算法开始尝试将强化学习应用到目标跟踪领域.对抗网络可以生成迷惑机器的负样本, 增强分类器判别能力.这些无监督和弱监督的方法可有效解决目标跟踪领域样本不足的问题.
除此之外, 将视觉注意力机制引入目标跟踪的方向也很有前途.在原来的跟踪模型中加入特定网络生成目标区域显著性图, 弱化背景突出前景.也可将注意力机制融入网络内部结构, 引导跟踪器关注对结果有帮助的部分.现在已有一些方法将相关滤波当作特定层嵌入到网络实现端到端训练, 但只是简单的核化相关滤波器, 如何能将传统算法中的一些方法嵌入到深度神经网络中也值得研究.
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|
| [44] |
|
| [45] |
|
| [46] |
|
| [47] |
|
| [48] |
|
| [49] |
|
| [50] |
|
| [51] |
|
| [52] |
|
| [53] |
|
| [54] |
|
| [55] |
|
| [56] |
|
| [57] |
|
| [58] |
|
| [59] |
|
| [60] |
|
| [61] |
|
| [62] |
|
| [63] |
|
| [64] |
|
| [65] |
|
| [66] |
|
| [67] |
|
| [68] |
|
| [69] |
|
| [70] |
|
| [71] |
|
| [72] |
|
| [73] |
|
| [74] |
|
| [75] |
|
| [76] |
|
| [77] |
|
| [78] |
|
| [79] |
|
| [80] |
|
| [81] |
|
| [82] |
|
| [83] |
|
| [84] |
|
| [85] |
|
| [86] |
|
| [87] |
|
| [88] |
|
| [89] |
|
| [90] |
|
| [91] |
|
| [92] |
|
| [93] |
|
| [94] |
|
| [95] |
|
| [96] |
|
| [97] |
|
| [98] |
|
| [99] |
|
| [100] |
|
| [101] |
|
| [102] |
|
| [103] |
|
| [104] |
|
| [105] |
|
| [106] |
|
| [107] |
|
| [108] |
|
| [109] |
|
| [110] |
|
| [111] |
|
| [112] |
|