{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
知识可编程智能芯片系统:概念、架构与展望
[张俊1, 2, 3  , 王飞跃
, 王飞跃1, 3 ]
, 王飞跃]
|
|




作者简介:王飞跃,博士,研究员,主要研究方向为智能系统和复杂系统的建模、分析与控制.E-mail:feiyue.wang@ia.ac.cn.
本文原创性地提出知识可编程智能芯片系统(KPI-CS)及其理论和工程体系.该系统在当前最先进的异构计算和可重构人工智能(AI)芯片技术的基础上,深度融合复杂系统工程理论、知识工程理论与技术、半导体芯片研发技术、人工智能可重构算法技术,提出基于知识的可重构智能芯片和计算系统平台技术.该系统旨在支持AI应用场景适应性、AI系统重构灵活性、AI算法算力合理性的平行智能AI芯片系统平台和对应的知识服务平台.同时,作为应用展望,KPI-CS与相应的应用平台联动,为平行复杂系统管理与控制、智能交通、智能能源、平行区块链、智能医疗等研究领域和工程实践提供新一代的实时、高效、自适应的计算系统支撑.
About the Author:WANG Fei-Yue, Ph.D., professor. His research interests include modeling, analysis, and control of intelligent systems and complex systems.
:This article proposes the theory and the architecture of Knowledge Programmable Intelligent Chip Systems(KPI-CS). KPI-CS is based on cutting-edge heterogeneous computing and reconfigurable AI chip technologies, fusing complex system computing, knowledge engineering and semiconductor IC design technology. It is aimed at providing adaptability to different application scenarios, flexibility in chip architecture reconfiguration and rationality in AI algorithmic computing capability to support parallel intelligent systems. KPI-CS can provide effective and efficient real-time supporting computing facilities which adapt to different demands in intelligent systems.
20世纪上半叶, 冯· 诺伊曼认为阿隆佐· 邱奇和阿兰· 图灵的研究构成了邱奇-图灵论题(Church-Turing Thesis).这是一个关于可计算性理论的假设, 认为“ 任何在算法上可计算的问题同样可由图灵机计算” .尽管邱奇-图灵论题严格意义上是一种陈述, 不能被数学严格证明, 但是到目前为止它几乎被科学界全面接受.在此信念下, 我们有了计算机的冯· 诺伊曼结构和今天的信息产业.2016年,
在人工智能围棋程序AlphaGo击败世界冠军李世石后, Wang等[1]提出AlphaGo论题, 表述为
The AlphaGo Thesis: A decision problem for intelligence is tractable by a human being with limited resources if and only if it is tractable by an AlphaGo-like program.
其相应的“ 扩展AlphaGo论题” 表述为
The Extended AlphaGo Thesis: A decision problem is tractable by a human being with limited resources if and only if it is tractable by a network-like system with sufficient numbers of adjustable parameters.
从邱奇-图灵论题到AlphaGo论题, 实质是从基于形式逻辑的算法可计算性假设, 到基于复杂网络系统的智能可计算性假设.尽管AlphaGo论题的最终验证甚至证明可能还需要很长的一段历史时期, 但是和该论题对应的计算结构已经在高速发展, 并且可以验证该论题的应用领域、场景、结果也在不断涌现.
和邱奇-图灵论题所陈述的可计算性对应的计算结构为冯· 诺伊曼结构, 是一种实现通用图灵机的计算设备和引用模型, 依该结构设计的计算机又称存储程序计算机, 直到今天, 这仍然是主流计算机结构.
然而, 在应对新一代人工智能问题时, 以中央处理器(Central Processing Unit, CPU)提供主要计算方式的冯· 诺伊曼架构由于遇到计算能力瓶颈, 已经不再适用.当今, 在人工智能计算专业领域, 异构计算架构正在成为主流, 而异构计算架构和AlphaGo论题相互对应.异构计算架构主要是指融合两个或以上不同计算体系架构的计算单元而成的混合增强计算方式, 计算单元架构可能包括CPU、图形处理器(Graphics Processing Unit, GPU)、数字信号处理器(Digital Signal Processor, DSP)、供专门应用的集成电路(Application Specific Integrated Circuit, ASIC)、现场可编程门阵列(Field-Program-mable Gate Array, FPGA)等[2].
在深度学习GPU加速市场NVIDIA、TPU加速市场的Google, 以及云服务器+FPGA芯片模式, 都是当前异构计算代表性架构.这些架构的出现, 使得处理海量的训练数据和复杂的深度神经网络成为可能, 因此出现以深度学习系统为代表的新一代人工智能系统.
虽然异构计算平台为新一代人工智能技术提供新颖的计算架构和强大的算力支撑, 但是异构计算平台并不能解决人工智能(Artificial Intelligence, AI)行业所有计算需求.总体而言, GPU、TPU、FPGA集群主要提供企业级AI研发阶段的训练(Training)市场, 同时也服务云端AI推断(Inference)市场.而AI终端市场, 如智能手机、机器人、自动驾驶、边缘计算等设备则需要在应用终端部署高度定制化、低功耗的人工智能芯片.根据Tractica预测, 深度学习芯片组市场将从2017年的16亿美元增加到2025年的663亿美元, 满足各个方面和层次上AI系统的计算需求[3].
综上所述, 由于架构的原因, CPU架构无法为AI算法提供足够的算力.而GPU、TPU的体积大、高功耗、非实时性和依赖于云等特点, 在众多平行智能支撑的平台应用中逐渐显露其不适用性.另外, 专用AI芯片都是为了满足特定应用和场景而设计的, 芯片架构存在极度的专用性和局限性, 无法满足AI算法在不同的时间、空间、应用场景、时变算力等差异性需求.
为了克服上述各种通用AI计算平台和专用AI芯片各自的缺点, 可重构AI芯片架构应运而生, 旨在支撑可重构的异构计算架构、实现低功耗AI计算, 其特点是包含大量粒度适中的各种可重构和编程单元, 实现高能效、低功耗的AI计算应用, 同时结构可重构、功能自适应、性能可优化.具体而言, 可重构计算芯片技术在其使用过程中不断自我学习、架构不断更新、网络模型不断适应系统计算的要求[4].
尽管可重构AI芯片提供一定的自适应性和灵活性计算能力, 避免高粒度和低粒度AI计算的诸多弊端, 但是, 从系统工程的视角, 仍然有许多问题需要回答:1)用于重构芯片内部结构的知识从何而来?2)已知这些知识后, 如何提取重构方案?3)重构方案如何映射到芯片内部可编程单元的逻辑互联和时序控制?4)有无可能设计一种粒度适中的AI芯片计算系统, 使之能够自适应且通用于较多的AI应用场景和计算需求?对上述问题的解决, 是研发出具有“ 智能” 的芯片系统的关键.
人工智能的应用领域与场景包括智能交通、无人驾驶、智能农业、智能能源、无人系统等, 每个应用与场景对系统功能性、场景差异性、算力自适应性都有不同的要求.在智能系统中不同场景下实时性、设备空间及边缘计算算力等要求和限制也不尽相同.而在抽象综合智能AI算法所需的运算后, 通过芯片级的在线设计和重构以满足上述智能平台的自适应性、重构性、差异性和算力需求就是知识可编程芯片系统的目标.
综合所述, 在平行芯片理念的基础上[5], 本文提出知识可编程智能芯片系统(Knowledge-Programmable-Intelligent Chip System, KPI-CS)可以预见, KPI-CS深度融合复杂系统工程理论、知识工程、半导体芯片设计与研发技术、人工智能可重构算法技术, 而提出基于知识、可重构的智能芯片计算和知识服务系统平台技术.本文旨在初步提出KPI-CS的系统工程概念、科学问题、架构及其应用场景和展望.
知识可编程智能芯片系统(KPI-CS)分成知识可编程智能芯片(下文称知识芯片)和平行芯片知识服务平台系统(下文称知识服务平台), 如图1所示.
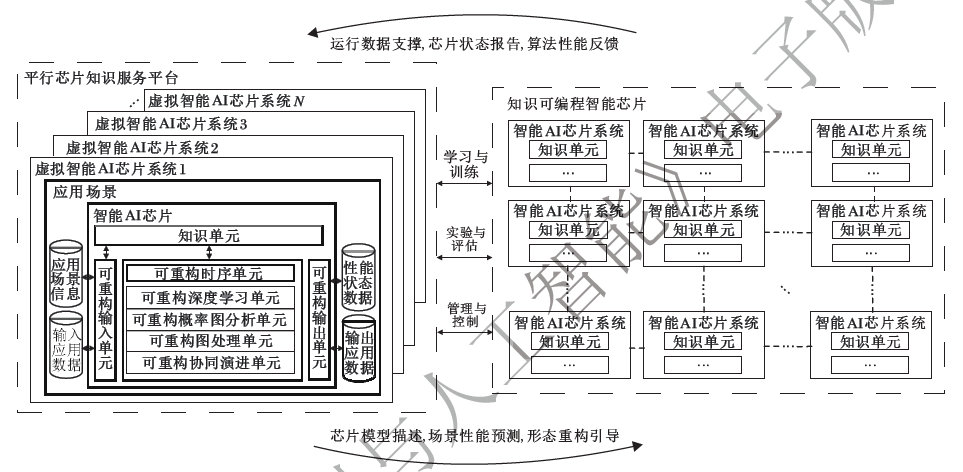 | 图1 知识可编程智能芯片系统Fig.1 Knowledge-programmable-intelligent chip system |
KPI-CS是依据平行智能理论[6]而发展的融合复杂系统理论和知识工程的智能芯片生态系统, 针对依据平行理论发展的平行交通、平行驾驶、智能农业、智能能源、平行无人系统等平行智能平台, 实现对系统重构性、场景差异性、算力自适应性需求提升的情况下自发演变的计算架构和依托平台.
KPI-CS中每个知识芯片内置海量可配置和可编程的AI算法硬件单元(AI Algorithm Hardware Elements, AI-AHE), 以及相应的可重构时序控制系统.知识芯片以此支撑可重构AI算法系统, 如深度学习系统、概率图系统、图论系统、协同演化算法系统等.每个知识芯片具备一个重构“ 知识单元” , 存储海量的关于知识芯片如何进行重构的知识, 知识单元通过识别当前应用场景、数据特性(类型、速率、格式、内容等)、AI问题复杂度(规模、性能要求等), 为知识芯片提供实时的重构方案, 不断根据当前知识芯片的运行环境参数和运行情况变化, 重构芯片, 以期提供最优的自适应性系统和差异性计算架构方案.
知识服务平台是运行在后台的平行智能系统, 通过计算和通信手段为智能AI芯片(群)提供重构知识服务.知识芯片和知识服务平台的具体功能和运行过程为:知识服务平台基于应用场景分析、AI算法计算模型, 以及从知识芯片发回的真实应用和性能数据, 不断针对不同场景、不同数据特性、不同AI问题进行重构方案的学习与训练、实验与评估、管理与控制, 从而产生最优的重构知识, 并将结果不断发送到智能AI芯片, 更新知识库.当知识芯片在实际的系统中运行时, 一方面利用知识服务平台提供的重构知识不断进行自我重构, 另一方面, 将其运行过程的真实数据, 通过网络等通信手段传递到知识服务平台, 为知识服务平台提供来自实际物理系统的数据, 以支持平行系统产生更有效和精确的重构知识.
物理知识芯片提供的是反映物理半导体世界的“ 小数据” .在知识服务平台中, 在对“ 小数据” 进行清洗和预处理后, 再进一步完成描述智能、预测智能(AI算法计算模型、应用场景模型等), 生成更多样化的虚拟现实的“ 大数据” , 进而产生重构知识, 发回知识芯片, 完成引导智能.因而, 在KPI-CS中, 实际知识芯片实现并且提供物理实际数据反馈, 知识服务平台实现知识芯片重构的指导, 两者形成不断迭代升级的平行管控过程.结合物理世界和虚拟世界中知识芯片的运行状态和数据, 可以利用整个KPI-CS设计适应性更强、重构更灵活、算力更合理、实时性更高的平行智能可重构芯片.
知识可编程智能芯片系统(下文称知识芯片)包括包含各种海量AI算法硬件单元(AI-AHE), 如可重构深度学习单元、可重构概率图单元、可重构图处理单元、可重构演化计算单元、可重构输入/输出(I/O)单元等.知识单元是知识芯片系统的特征, 知识单元负责存储知识芯片的重构知识表征, 根据这些知识表征在芯片运行时根据芯片的应用场景、输入输出数据、运行状态等信息, 得出如何重构芯片的知识, 并映射成芯片的新结构和时序控制, 完成对知识芯片进行重构的过程.
典型深度神经网络中的神经层可分为卷积层、全连接层和递归层, 每种神经层都具有不同的特性, 需要不同的计算结构和方法.因此, 深度神经网络需要大量的并行计算和内存访问, 也有必要支持可做多种操作、具有不同位宽、可重构的计算单元, 以加速整个神经网络.其次, 现有的深度学习时序控制采用的基于时间复用的计算方式, 处理效率不高, 因此, 为神经网络算法设计一个高效的计算流程时序控制非常重要.另外, 为卷积计算而设计的存储器存取机制不适用于一般性的深度学习算法需要, 导致存储资源利用率低下.因此, 需要设计一个高效而又自适应的可重构深度学习算法数字设计实现机制.Tu等[4]设计支持位宽自适应计算并涵盖混合神经网络所有基本操作, 支持可重构可编程单元阵列, 从而最大化计算资源利用率; 支持可重构内存分块, 以将任意神经网络配置到芯片资源上.
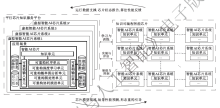
概率图模型(Probabilistic Graphical Model, PGM)是指一种使用图结构描述多元随机变量之间条件独立和相关关系的概率模型[6].概率图已经发展成为一个庞大的领域, 演化出多种模型和算法, 包括众多机器学习模型.图2大致给出概率图模型理论所涵盖的常见内容和常用方法.
 | 图2 概率图模型理论涵盖的常见内容和常用方法Fig.2 Common content and methods covered by probabilistic graphical model theory |
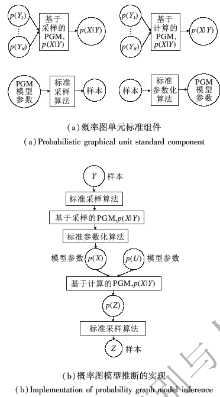
概率图理论虽然包罗万象, 但是根据其基本原理, 对其组件进行简化、标准化和模块化, 可以用于设计可重构概率图单元.原理表述如下.在本文中, 知识芯片中概率图单元只涉及根据已有模型进行推断的功能, 而训练模型和模型参数的获取, 则是离线知识服务平台的功能.将概率图的“ 边” 理解为一对一的概率关系, 即根据在已知输入变量概率分布, 根据已有的标准PGM(如高斯混合模型(Gaussian Mixture Model, GMM)等), 计算输出变量的后验概率分布, 经过标准化和简化, 芯片可实现的方法包括查表法、采样法、计算法等标准方法.然后通过标准组件的组合和重构, 实现任意的概率图模型推断, 如图3所示.
图处理技术是人工智能技术的重要组成部分, 图数据规模不断增长, 大图处理需求越来越多.因此, 在知识芯片中实现可重构图处理技术、甚至是可重构大图处理技术, 实现通用的基于芯片技术的图处理系统也会在未来智能芯片中占有重要的一席之地[8].
 | 图3 概率图单元标准组件及实现的概率图模型推断Fig.3 Probabilistic graph unit standard component and the implementation of probability graph model inference |
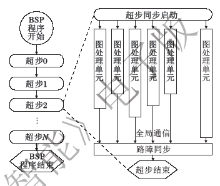
整体同步并行计算模型(Bulk Synchronous Parallel Computing Model, BSP), 是现在广泛应用的大规模图处理计算模型.BSP模型以“ 超步” 为执行单位同步计算过程.在每个超步开始和结束前所有计算节点进行路障同步.节点之间通过消息传输机制进行信息交互.在每个超步中, 所有的节点执行本地计算, 然后进行全局核查, 判断是否所有的节点都已完成超步.如果完成, 进入下一个超步.每个超步的计算输出结果都作为下一个超步的输入, 当计算结果满足终止条件或达到设定的超步数时程序终止.BSP执行过程如图4所示.
结合芯片前端设计原理, BSP模型适合可重构图处理数字逻辑设计.在此, 可将图处理中每个节点设计成一个标准可配置的逻辑单元, 该逻辑单元需要完成的任务包括节点的消息通信功能、超步的同步核查功能等, 当然该逻辑单元也需要完成图处理计算任务, 而对应于人工智能技术, 大多数类型图的节点可使用概率图模型以建模.因此可重构图处理结构, 可以看作在可重构概率图单元的基础上, 继续加入BSP模型功能单元, 最后形成的大规模图和概率图的处理技术.
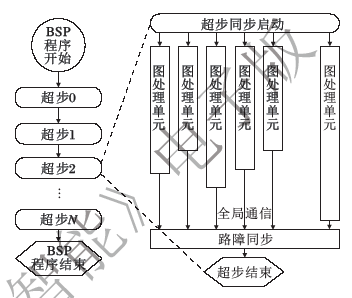 | 图4 BSP执行过程示意图Fig.4 Schematic diagram of BSP execution process |
协同演化算法的原始思想是运用生物协同演化的思想, 通过构造多个个体或种群, 建立它们之间的博弈或协作关系, 通过这些互动, 种群得以适应复杂系统的动态演化环境, 增强种群自身相关的性能, 如强壮性、适应性等[9].
演化计算的数学基础是博弈论, 即通过协同演化最终达到稳定平衡状态, 这个稳定状态即系统最优解.演化博弈论为协同演化复杂动态行为提供理论基础.
从工程的角度上, 演化计算的实现依赖于多智能体工程方法.一个多智能体系统由多个、甚至是海量可以互相交互的可配置计算单元组成.在本芯片系统中, 即可重构演化计算单元.在该系统中, 每个计算单元某种程度上可以按照自己的既定目的自治行动, 而且每个单元可以与其它单元进行交互, 而这种交互以交换数据为前提, 包括竞争、协作、协商等.
因此, 可重构演化计算单元可以看作是上一节所述图处理单元在逻辑和功能上的延伸.而演化计算系统是图论系统的进一步功能扩展.在芯片设计上, 增加博弈论的逻辑设计内容及更丰富的对于演化过程的时序设计内容.
可重构I/O单元根据芯片内知识单元的配置指令, 对输入输出数据的引脚位置、速率、协议、芯片内部数据格式(对芯片内各个模块的数据接口)、芯片外数据格式(对芯片外设备接口)等做出实时智能化配置.
知识单元是知识芯片的“ 大脑” , 知识单元根据芯片的配置信息、外部应用接口提供的信息、芯片内外部数据信息、芯片运行状态信息、芯片输出数据信息、芯片的性能评估信息等, 根据其内部存储的芯片配置知识, 对芯片的内部结构和功能进行实时配置.而芯片的配置知识存储在知识单元内置的存储单元内.最基本的重配置知识固化在芯片内部, 支撑可编程芯片的基本运行.而针对各种应用场景和运行状态的重配置知识由知识芯片的知识服务平台提供, 通过远程通信更新并存储到知识单元.同时, 知识单元也不断把各种芯片内外部数据信息、运行状态、性能评估等发送到知识服务平台, 为知识服务平台提供芯片大数据的输入与支撑, 提供更优质、精准、有效、丰富的芯片重配置信息.
结合当前的深度学习技术、概率图技术、大图技术及协同演化技术, 可以对大规模动态系统的个体微观行为和宏观群体现象进行统一的建模、分析和研究.基于描述智能的建模与表征包括系统中个体的主体行为与心理模式建模、主体间的交互模型、主体活动环境的模型, 并基于此建立巨型多代理系统模型和概率图模型.在上述基于大图的多代理概率图模型中, 联合运用主体模型、环境交互模型、演化模型与传播模型, 对大规模动态网络的个体微观行为和宏观群体现象进行统一建模、分析和研究.根据芯片的信息处理结果, 进一步再运用大图数据挖掘技术, 如聚类、子图发现、网络异常检测、最短路径发现、分类与降维等理论方法, 对复杂社会网络的宏观现象, 如信息传播、舆情演进、舆情影响及特殊宏观现象(如“ 涌现” )的内在机理和动态过程进行数理、科技和系统工程层次上的科学研究.
根据对网络活动与信息进行干预与诱导的目标, 也可以开发基于智能芯片的协同演化的自组织、自优化多代理管控系统, 对网络中个体或其连接关系进行干预与诱导, 即管控代理之间的互相交互、互相竞争、互相消减, 并运用协同演进技术实现计算实验; 运用计算实验的方法, 评估管控策略, 最终达成“ 情景-应对” 自适应管理策略; 通过研究平行系统在线优化, 得出平行系统互动调节和反馈机制, 并最终实现有效的网络活动和信息的管控.
可编程智能芯片的知识服务平台系统是运行在边缘计算端和云端后台的平行智能系统, 通过计算和通信手段为知识芯片(群)提供重构知识服务.知识服务平台运用AI算法计算模型、应用场景分析及从知识芯片发回的真实应用和性能数据, 不断针对不同场景、不同数据特性、不同AI问题进行重构方案的学习与训练、实验与评估、管理与控制, 从而产生最优的重构知识, 并将结果不断发到知识芯片, 更新知识库.所以, 知识服务平台既可以理解成是为可重构知识芯片提供知识的服务机制, 也可以理解成是知识芯片(群)所组成的复杂系统的管控平台[10].
基于平行系统理念, 结合芯片设计的实际特点, 知识服务平台包括基础构建层、数据和知识层、计算实验层和平行执行层等, 如图5所示.该系统可动态模拟知识芯片真实系统复杂运行过程, 实现对芯片数据和过程的状态监测、未知应用情景的智能模拟计算、芯片配置方案的滚动优化分析, 及芯片运行过程的在线推演评估与优化.
 | 图5 知识服务平台主要架构和内容Fig.5 Main structure and content of the knowledge service platform |
系统核心思想为, 通过深度学习、行为分析模型等代理建模方法, 对芯片I/O系统、AI算法参数、系统性能建立模型, 组成同实际系统等价的虚拟系统.在虚拟系统中, 通过计算实验认识实际芯片系统各可重配置要素间的演化规律和相互作用关系, 通过两者(知识服务平台和芯片中的知识单元)的相互连接, 对虚拟知识芯片和实际知识芯片的行为进行对比和分析, 研究对各自未来状态的借鉴和预估, 相应调节知识芯片的配置、控制与管理方式, 最后利用认识的规律, 通过平行控制实现在各种应用场景和具体状态情况下芯片配置和运行, 优化实际系统的控制和管理, 达成知识可编程智能芯片的自适应性与自优化性.
知识服务平台需要实现知识芯片全仿真和重构决策, 可以在采用硬件描述语言的软件仿真和硬件仿真两个层面进行.软件层面仿真是设计必要的步骤, 但运行速度很慢, 特别对于大型系统, 软件全仿真在运行时间上是无法接受的方案.采用硬件描述语言的硬件加速仿真用于在外界输入上可以最大程度地仿真现实环境, 可以对芯片运行状态进行部分查看.在最先进的硬件加速仿真软硬件支撑下, 可以做到快速无缝的硬件调试、硬件/软件协同验证或集成、系统级样机制作、低功耗验证和功耗估计及性能特征提取.另外, 高性能的GPU/TPU服务器等异构计算平台也是支撑知识服务平台的必要设备.
基础构件 在上述平台基础上, 构建具备大规模数据分布式存储与海量数据分布式计算能力的基于面向服务的体系架构(Service-Oriented Architec-ture, SOA)(或云计算)平台, 并开发知识芯片管理系统、分布式目录服务器和芯片通信通道等多代理平台组件, 实现平台内部的芯片生命周期服务和消息通信服务; 开发各种软硬件接口、组件、工具规范; 构建知识芯片本体模型, 以实现知识服务平台内部代理间以及外部与知识芯片之间的语义层次上互操作性.
数据和知识 运用软件级、硬件级芯片仿真技术, 以及基于代理建模方法对知识芯片中的可重构单元、应用环境、规则和机制建模并构建海量场景库和重构模型库.其次, 基于XML语言设计一套形式化表示方法统一描述知识服务中的领域知识, 包括构造应用场景库和知识芯片模型库, 以达到构建领域知识库的目的, 实现知识服务系统的芯片重构领域知识的存储、表达与推理.
计算实验 设计同时支持真实与虚拟实验场景的场景生成器.场景生成器能够模拟特定场景或自动提取场景库中的特定实验场景, 实例化实验场景中的交互机制与管理规则, 并传递给事件驱动引擎完成计算实验仿真; 基于离散事件仿真技术实现事件驱动引擎, 并动态模拟实验场景中芯片内部各个单元交互与通信过程.事件驱动引擎采用仿真时钟模拟实验芯片运行时的特定时刻和时间变化, 按时间顺序存储、分析和确定实验过程中离散事件、事件间的引发关系, 以及由事件所产生的芯片输入数据.通过离散事件的驱动、基于仿真时钟的数据推送以驱动和模拟计算实验的过程.最后, 研制适用于计算实验平台的算法分析工具, 并以模块和组件的形式应用于实验平台中.重点开发各类典型应用场景中定性与定量计算实验研究算法, 以及对各应用领域提供特定支持的专用算法模块.这些工具动态分析、研究和优化计算实验过程及其结果, 并实时更新知识库.
平行管控 对知识芯片的知识单元进行实时交互, 并收集与融合知识芯片的输入/输出、运行和状态数据, 并基于实时监测数据和内置的重构知识, 实时重新配置芯片内AI功能单元.其次, 设计一套完整的硬件描述语言程序库(芯片端)和高层应用程序协议(平台端), 构建知识服务平台与知识芯片之间的通信接口, 使知识芯片能够方便地获取知识、管理和配置芯片内部架构及运行方式.同时通过知识单元, 反馈芯片运行状态和性能评估信息给知识服务平台, 实现反馈调控、计算研究和系统优化.最后, 设计动态可视化的人机交互界面, 以文本、图、表等形式全方位呈现计算实验模拟及其交互管控的全过程.
知识可编程智能芯片系统(KPI-CS)是面向信息物理社会系统(Cyber-Physical-Social Systems, CPSS)的平行智能理论在可重构智能计算方向的平台化延伸.另外, KPI-CS也是众多平行智能平台, 在对基础计算系统各方面需求提升的情况下, 自然演变的计算依托平台, 如平行交通、平行驾驶、智能农业、智能能源、平行无人系统等.因此, 面向CPSS的平行智能理论是KPI-CS的理论指导, KPI-CS是面向CPSS的平行智能理论的计算支撑.
依据平行智能理论发展的平行智能平台对现有智能AI算力的解决方案提出挑战, 研究、设计及生产完全契合上述平行智能平台的芯片级系统是解决算力需求的必要途径.同时, 面向CPSS的平行智能理论的KPI-CS分为知识芯片系统和知识服务平台, 以反馈、迭代升级的模式定义智能芯片, 对解决智能系统算力等研发难题是一个新颖、有效的指导方向, 并与近期提出的智联网概念契合[11].KPI-CS主要涉及平行智能算法芯片系统架构, 可扩展、低延迟计算模块架构, 平行智能算法数据流的优化, 平行智能算法存储优化, 平行智能算法定点化优化及平行智能算法芯片实现的裁剪优化等技术研究.
本文原创性地提出知识可编程智能芯片系统(KPI-CS)及其理论和工程体系.该系统在当前最先进的异构计算和可重构AI芯片技术的基础上, 深度融合复杂系统工程理论、知识工程理论与技术、半导体芯片研发技术、人工智能可重构算法技术, 提出基于知识的可重构智能芯片和计算系统平台技术.
该系统旨在支持AI应用场景适应性、AI系统重构灵活性、AI算法算力合理性、AI应用变化实时性的平行智能AI芯片系统平台和对应的知识服务平台.同时, 作为其应用展望, KPI-CS与相应的应用平台联动, 为平行复杂系统管理与控制、智能交通、智能能源、平行区块链、智能医疗等研究领域和工程实践提供新一代的实时、高效、自适应的计算系统支撑.
KPI-CS以面向CPSS的平行智能理论为核心指导理论, 面向智能芯片设计等技术前沿, 以知识芯片设计开发和知识服务平台为平行智能提供可反馈迭代升级的计算芯片结构.以平行驾驶、平行交通、智能农业、智能能源等新领域的计算升级为需求牵引, 以差异性计算力、高自适应性、高实时性、低功耗和设备小型化的平行虚实知识芯片设计为重点发展方向, 希望KPI-CS能够引领与行业应用结合的平行智能AI算法芯片设计在国内的发展, 并为解决国家在交通、安全驾驶、能源、农业等重大领域的应用需求提供核心技术手段, 做出创新和贡献.
2018年5月, 英特尔智能网联汽车大学合作研究中心在北京设立研究分支, 携手中国科学院自动化研究所和清华大学, 致力于推动和发展自动驾驶、平行驾驶系统相关课题的研究.随着人工智能、大数据、移动互联等新技术的蓬勃发展, 以自动驾驶、平行驾驶、平行交通等为标志的平行智能应用正在步入高速发展的新时代.因此对于一款更强大、高效、充分发挥平行AI算法优势的计算平台的需求愈加迫切.其中, 在抽象综合平行AI算法需要的运算后, 与其紧密结合的平行智能芯片及其知识服务系统是实现上述高性能计算平台的关键核心技术.
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|