





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
机器仿生眼的多任务学习人脸分析
[樊迪1  , HyunwooKim
, HyunwooKim1 , 陈晓鹏1 , 刘云辉2 , 黄强1 ]
, HyunwooKim, 陈晓鹏, 刘云辉, 黄强]
|
|



作者简介:
 樊 迪,博士研究生,主要研究方向为深度学习、计算机视觉.E-mail:fandi0126@126.com
樊 迪,博士研究生,主要研究方向为深度学习、计算机视觉.E-mail:fandi0126@126.com
Hyunwoo Kim,博士,副教授,主要研究方向为深度学习、计算机视觉.E-mail:eugene.hwkim@gmail.com.
 陈晓鹏,博士,副教授,主要研究方向为机器人视觉、机器人控制.E-mail:xpchen@bit.edu.cn
陈晓鹏,博士,副教授,主要研究方向为机器人视觉、机器人控制.E-mail:xpchen@bit.edu.cn
 刘云辉,博士,教授,主要研究方向为机器人学、机电系统、计算机视觉.E-mail:yhliu@mae.cuhk.edu.hk
刘云辉,博士,教授,主要研究方向为机器人学、机电系统、计算机视觉.E-mail:yhliu@mae.cuhk.edu.hk
 黄 强,博士,教授,主要研究方向为仿生技术、机器人.E-mail:qhuang@bit.edu.cn
黄 强,博士,教授,主要研究方向为仿生技术、机器人.E-mail:qhuang@bit.edu.cn
智能机器人中人机交互的性能至关重要,人脸分析可以使人机交互变得更友善.文中提出可以同时进行笑容识别和性别分类的多任务学习卷积神经网络,同时学习存在内在相关性的任务,提升单个任务的性能.在CelebA数据集的测试集上,文中网络在笑容识别任务和性别分类任务中均获取较高准确率.在设计的机器仿生眼上验证文中模型,获得良好的笑容识别效果和性别分类效果.文中对人脸分析进行的研究可以提升与机器仿生眼人机交互的能力.
About the Author: FAN Di, Ph.D.candidate. His research interests include deep learning and computer vision.
CHEN Xiaopeng, Ph.D., associate professor. His research interests include robotic vision and robotic control.
LIU Yunhui, Ph.D., professor. His research interests include robotics,electromechanical system and computer vision.
HUANG Qiang, Ph.D., professor. His research interests include biomimetic techno-logy and robotics.
FAN Di, Ph.D.candidate. His research interests include deep learning and computer vision.
The performance of human-machine interaction is crucial for intelligence robot, and face analysis makes human-machine interaction more friendly. In this paper, a multi-task learning convolutional neural network is proposed. The tasks of smile recognition and gender classification are solved simultaneously. Inherent correlated tasks are learned, and the performance of individual task is improved. On CelebA test dataset, the proposed network achieves high accuracy on a smile recognition task and a gender classification task. The proposed model is tested on the designed machine bionic vision eyes, achieving satisfactory result on smile recognition and gender classification. The research on face analysis in this paper improves the human-machine interaction ability with the machine bionic eyes.
人脸分析包含人脸识别[1]、特征点检测[2]、视线估计[3]、表情识别[4]、性别分类[5]等任务.人脸分析由于表现出重要的实际应用价值, 已成为一个热门并具有挑战性的研究问题.
传统的基于卷积神经网络(Convolutional Neural Network, CNN)的人脸分析通常将人脸识别、特征点检测、视线估计、表情识别、性别分类等任务视为分离的问题[6, 7].实际上, 这些任务之间存在内在的相关性, 对存在相关性的任务进行联合学习可以提升单个任务的性能[8].
Caruana[9]首次详细分析多任务学习(Multi-task Learning, MTL).此后, 学者们开始采用多任务学习解决不同的计算机视觉问题.Eigen等[10]提出通过单幅图像同时预测深度、表面法线、语义标签的多尺度卷积神经网络.UberNet[11]采用相似的概念同时训练低、中、高层级的视觉任务.Zhu等[12]提出对人脸检测、特征点检测和姿态估计进行联合学习的方法.
笑容识别任务和性别分类任务属于人脸分析中人脸属性推断的一部分.传统的笑容识别方法和性别分类方法采用寻找良好的判别特征以分类的方式, 大多数传统方法采用局部二值模式(Local Binary Pattern, LBP)、SURF(Speeded up Robust Features)、方向梯度直方图(Histogram of Gradient, HOG)、尺度不变特征变换(Scale-Invariant Feature Transform, SIFT)等特征中的一种或多种的集合.Zhang等[13]提出基于深度学习特征的人脸笑容检测方法, 同时利用笑容识别和验证信号对表情特征进行监督学习, 在GENKI-4K数据集(http://mplab.ucsd.edu)上取得良好效果.Glauner等[6]提出利用卷积神经网络进行笑容识别, 在DISFA(Denver Intensity of Spontaneous Facial Action)数据集[14]上表现良好, 并提取笑容相关的区域(嘴和脸颊).Chen等[15]提出利用深度卷积神经网络在自然环境下进行笑容识别的方法, 提出的笑容-卷积神经网络(Smile-CNN)在GENKI-4K数据集上取得良好效果.Nian等[16]利用卷积神经网络进行非约束环境下的鲁棒性别分类, 在LFW(Labeled Faces in the Wild)数据集[17]上表现良好.van de Wolfshaar等[18]利用深度卷积神经网络和支持向量机进行性别分类, 在color FERET数据集[19, 20]和Adience数据集[21]上均取得良好效果.Mansanet等[22]利用局部深度神经网络(Local Deep Neural Network, Local-DNN)进行性别分类, 在LFW数据集[17]和Gallagher's数据集[23]上均表现良好.
在传统的双目视觉系统中, 如Kinect、Multisense SL[24], 不能改变两个相机的姿态和视场, 获取的视觉信息非常有限, 然而仿生机器人需获取全场景的视觉信息. HRP-3(Humanoid Robotics Platform-3)[25]、ASIMO(Advanced Step in Innovative Mobility)[26]、PR2(Personal Robot 2)(www.willowgarage.com/pages/prz/overview)等机器人的颈部只有2个自由度(平转、俯仰), 2个相机不能单独运动, 视场也不能改变.然而, 人的双眼能够单独运动, 人类可以通过调整颈部和双眼改变视场范围.因此, 主动式双目仿生视觉更适合应用于仿生机器人.基于上述问题, 本文参考人类颈部和眼睛的仿生数据, 设计九自由度仿生眼, 其中颈部包含3个自由度(俯仰、侧摆和平转), 每个眼睛包含3个自由度(俯仰、平转和自旋).
本文基于ResNet50网络提出可以同时进行笑容识别和性别分类的多任务学习卷积神经网络.对多任务学习卷积神经网络进行训练, 卷积神经网络中笑容识别任务和性别分类任务共享低层数的权重参数, 通过这种方法, 卷积神经网络中低层数的层将对所有任务的通用表达特征进行学习, 而高层数的层针对不同任务的表达特征进行学习, 有效减轻共享层的过拟合问题.本文的多任务卷积神经网络是一个端对端的系统, 它能同时训练多个任务且仅需存储一个单独的卷积神经网络, 而不需要对多个任务分开训练, 分别存储解决对应任务的卷积神经网络, 这样既节省训练时间也节省内存使用空间.在设计的仿生眼上测试本文的多任务学习卷积神经网络.上述对人脸分析的研究可以提升与机器仿生眼人机交互的能力.
人类的颈部是一个由大量肌肉和骨骼组成的复杂系统[27].颈部模型具有3个自由度[28]:颈部俯仰、颈部侧摆和颈部平转.
人类的眼外肌肉控制眼睛的运动.每个人眼有6条眼外肌肉[29], 6条眼外肌肉成对工作.人类的每只眼睛具有3个自由度[30]:眼球俯仰、眼球平转和眼球自旋.
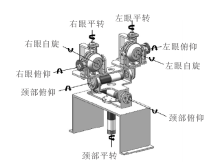
机器仿生眼总共包含9个自由度, 如图1所示.
 | 图1 机器仿生眼自由度示意图Fig.1 Sketch map of freedom degree of machine bionic eyes |
颈部包含3个自由度, 每只眼睛包含3个自由度, 显然机器仿生眼颈部和眼睛的自由度数量与人类的完全一致.机器仿生眼能通过9个自由度的协同运动实现人眼的各种基本运动.设计的机器仿生眼实物图如图2所示.
 | 图2 机器仿生眼实物图Fig.2 Machine bionic eyes |
基于ResNet50网络, 本文提出可以同时执行笑容识别任务和性别分类任务的多任务学习卷积神经网络.对多任务学习卷积神经网络进行训练, 构建不同任务之间的协同作用, 用于提升单个任务的性能.
多任务学习卷积神经网络可在单个卷积神经网络中对多个任务同时进行训练学习, 相比单任务学习, 多任务学习更注重多个任务之间的联系, 而对存在相关性的任务同时进行学习可以提升单个任务的性能.
多任务学习卷积神经网络的框架如图3所示.
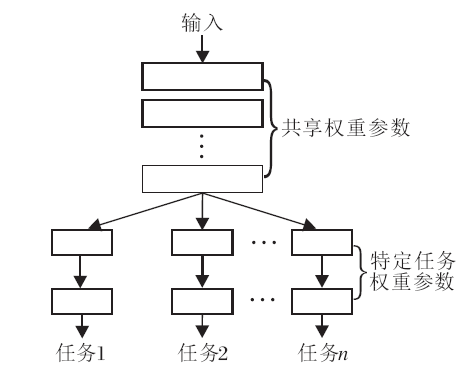 | 图3 多任务学习卷积神经网络框架Fig.3 Framework of multi-task learning convolutional neural network |
低层数的层学习多个任务的通用特征, 高层数的层学习针对不同任务的特征[30].因此, 共享多任务学习卷积神经网络中低层数的层学习人脸通用的表达特征的参数, 随后高层数的层学习针对笑容识别和性别分类表达特征的参数.
2.2.1 ResNet
ResNet(Residual Network)[31]是当前最新的卷积神经网络结构之一, 它与VGG(Visual Geometry Group)网络[32]的结构类似, 但ResNet50具有恒等映射的功能, 如图4所示.
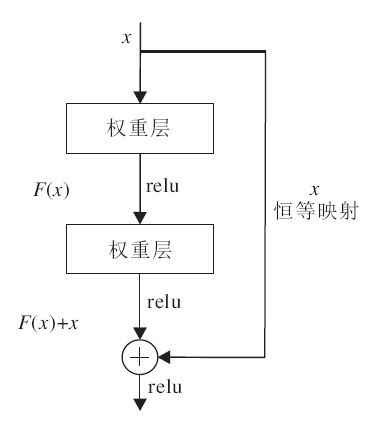 | 图4 具有恒等映射功能的ResNet残差块Fig.4 ResNet residual block with identity mapping function |
在ResNet的残差块中, 输入x, 需拟合的结果为H(x).将输出差分为x+y, 即
H(x)=x+y.
令
y=F(x),
即y由x拟合而来, 拟合的结果为
H(x)=x+F(x),
x为本来的输入, 因此只需拟合F(x).在ResNet的残差块中, 使用两层卷积层拟合函数F(x).
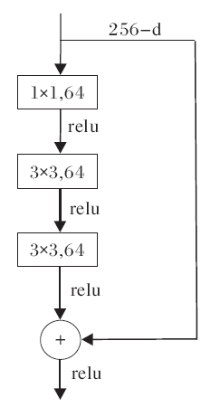
当网络较深(大于50层)时, 考虑使用瓶颈(Bottleneck)(见图5), ResNet的残差块与bottleneck的参数量属于同一个量级, 但bottleneck占用整个网络的三层, 而残差块只占用两层, 由于bottleneck节省大量参数, 因此在大于50层的网络中通常使用bottleneck.
在ResNet网络中, 如果当前层不是必要的层, 恒等映射功能使模型跳过典型的卷积神经网络的权重层, 因此恒等映射功能可以使很深的卷积神经网络模型避免出现过拟合问题.
 | 图5 ResNet瓶颈Fig.5 ResNet bottleneck |
2.2.2 多任务学习卷积神经网络
基于ResNet50网络, 本文提出可以同时执行笑容识别任务和性别分类任务的多任务学习卷积神经网络, 网络结构如表1所示.
| 表1 多任务学习卷积神经网络结构 Table 1 Architecture of multi-task learning convolutional neural network |
多任务学习卷积神经网络共享卷积层1、最大池化层、残差单元1~残差单元4的参数, 用于对笑容识别任务和性别分类任务的通用特征进行学习.随后针对笑容识别任务和性别分类任务各自的特征进行学习, 笑容识别残差单元与性别分类残差单元均与残差单元4相连, 笑容识别残差单元经过平均池化层1池化后与全连接层1进行连接, 最终通过笑容识别softmax层对笑容进行识别, 性别分类残差单元经过平均池化层2池化后与全连接层2进行连接, 最终通过性别分类softmax层对性别进行分类.多任务学习卷积神经网络实现通过单个卷积神经网络同时对笑容识别任务和性别分类任务进行学习, 是一个端对端的系统.
CelebA(CelebFaces Attribute)数据集[33]包含202 599幅人脸图像, 每幅图像都做好特征标记, 包含人脸bbox标注框, 5个人脸特征点及包含笑容、性别及其它38种属性(戴帽子、戴眼镜等)的人脸相关的属性标记.在CelebA数据集中, 训练集包含162 770个样本, 验证集包含19 867个样本, 测试集包含19 962个样本.
由于ResNet要求输入图像的最小尺寸为200Í 200, 利用CelebA数据集提供的人脸bbox标注框选择原始图像中的人脸框, 然后将框选的人脸图像修改成尺寸为224Í 224的图像作为网络输入, 所有输入图像均为224Í 224Í 3的彩色图像.经过数据预处理后的图像如图6所示.
 | 图6 预处理后的CelebA数据集Fig.6 CelebA dataset after pre-processing |
使用交叉熵(Cross-Entropy Loss)损失LS 作为笑容识别训练的损失函数:
LS=-sln ps-(1-s)ln(1-ps),
其中, s=1表示有笑容, s=0表示没有笑容, ps 表示预测输入的人脸有笑容的概率.
同样使用交叉熵损失LG 作为性别分类训练的损失函数:
LG=-gln pg-(1-g)ln(1-pg),
其中, g=1表示男性, g=0表示女性, pg 表示预测输入的人脸为男性的概率.
总的损失函数由笑容识别任务与性别分类任务各自的损失函数加权求和得到:
Ltotal=λ sLS+λ gLG ,
其中, 权重λ s 和λ g 分别决定在总的损失函数中笑容识别和性别分类各自的重要程度.
使用Keras(https://github.com/fchollet/keras)训练多任务学习卷积神经网络, 通过评估CelebA的验证集选择模型的超参数, 将批尺寸(Batch_size)设置为32, 训练30个周期, 初始学习率设置为0.001, 25个周期后, 学习率降为0.000 1, 笑容识别和性别分类的损失函数均选择交叉熵损失(categorical_crossentropy), 选择Adam作为优化器.
为了改善过拟合问题, 使用dropout, 并对训练集进行实时数据增强, 将训练集进行水平翻转和随机旋转.
通过CelebA数据集的测试集对多任务卷积神经网络模型执行笑容识别任务和性别分类任务的性能测试.对比方法包括PANDA-1(Pose Aligned Networks for Deep Attribute modeling-1)[34]、MT-RBM(Multi-task Restricted Boltzmann Machines)[35]、LNet+ANet(Face Localization Network+Attribute Prediction Network)[33]、HyperFace[36], 准确率如表2所示.
| 表2 5种方法在CelebA数据集的测试集上的准确率 Table 2 Accuracy of 5 methods on CelebA test dataset % |
由表2可看出, 在笑容识别任务和性别分类任务中, 本文方法均取得最优结果.多任务卷积神经网络模型执行笑容识别任务和性别分类任务时在CelebA数据集的测试集上的混淆矩阵(Confusion Matrix)如图7所示.
 | 图7 笑容识别和性别分类在CelebA数据集的测试集上的混淆矩阵Fig.7 Confusion matrix of smile recognition and gender classification on CelebA test dataset |
在设计的仿生眼上测试多任务学习卷积神经网络模型.实验证明, 多任务学习卷积神经网络可以实时正确执行笑容识别任务和性别分类任务.实验结果如图8所示.
 | 图8 笑容识别和性别分类平台测试结果Fig.8 Platform test results of smile recognition and gender classification |
本文在ResNet50网络的基础上提出可以同时进行笑容识别和性别分类的多任务学习卷积神经网络.在CelebA数据集的测试集上将本文方法得到的笑容识别和性别分类的准确率与一系列已发表的方法进行对比, 结果表明, 本文方法在笑容识别任务和性别分类任务中均取得最优结果.最后, 在设计的仿生眼上测试本文模型, 实验证明, 本文模型执行笑容识别任务和性别分类任务的效果良好.本文对人脸分析进行的研究可以提升与机器仿生眼人机交互的能力.今后进一步扩展多任务学习卷积神经网络, 使其可以使用单个卷积神经网络同时执行更多人脸分析相关的任务.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|