






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
局部可视对抗扰动生成方法
[周星宇1, 2  , 潘志松
, 潘志松2 , 胡谷雨2 , 段晔鑫2, 3 ]
, 潘志松, 胡谷雨, 段晔鑫]
|
|




周星宇,博士研究生,讲师,主要研究方向为计算机视觉、对抗样本.E-mail:universezhou@sina.cn.

胡谷雨,博士,教授,主要研究方向为计算机网络、通信网络管理、网络智能化技术.E-mail:huguyu@189.com.

段晔鑫,博士研究生,讲师,主要研究方向为对抗样本、图像识别.E-mail:duanyexin0713@163.com.
深度神经网络极易受到局部可视对抗扰动的攻击.文中以生成对抗网络为基础,提出局部可视对抗扰动生成方法.首先,指定被攻击的分类网络作为判别器,并在训练过程中固定参数不变.再构建生成器模型,通过优化欺骗损失、多样性损失和距离损失,使生成器产生局部可视对抗扰动,并叠加在不同输入样本的任意位置上攻击分类网络.最后,提出类别比较法,分析局部可视对抗扰动的有效性.在公开的图像分类数据集上实验表明,文中方法攻击效果较好.
ZHOU Xingyu, Ph.D. candidate, lec-turer. His research interests include computer vision and adversarial examples.
HU Guyu, Ph.D., professor. His research interests include computer network, communication network management and network inte-lligent technology.
DUAN Yexin, Ph.D. candidate, lecturer. His research interests include adversarial exam-ples and image recognition.
Deep neural network is susceptible to the disturbance of adversarial attacks. Based on the generative adversarial networks, a novel model of GAN for generating localized and visible adversarial perturbation(G2LVAP) is proposed. Firstly, the attacked classification network is designated as a discriminator, and its parameters are fixed during the training process. The generator model is constructed to generate localized and visible adversarial perturbations by optimizing fooling loss, diversity loss and distance loss. The generated perturbations can be placed anywhere in different input examples to attack the classification network. Finally, a class comparison method is proposed to analyze the effectiveness of localized and visible adversarial perturbations. Experiments on public image classification datasets indicate that G2LVAP produces a satisfactory attack effect.
本文责任编委 陶卿
Recommended by Associate Editor TAO Qing
目前利用深度神经网络(Deep Neural Network, DNN)构建的分类模型在图像分类任务中已取得显著成果.但研究表明, DNN极易被对抗样本攻击[1, 2].对抗样本是指攻击者通过特定方式修改干净的输入样本, 在不影响人类判断的前提下, 欺骗基于DNN实现的分类模型, 导致分类网络发生错误判断[3, 4].研究对抗样本攻击问题有助于进一步了解深度模型的特性, 并有针对性地提高其鲁棒性.
大多数关于对抗样本的研究致力于生成视觉不易察觉的对抗扰动.当输入图像叠加这些扰动时, 人眼难以发觉样本的改变, 但分类网络却会将其误判为其它类别[5, 6, 7, 8, 9, 10, 11, 12].这些扰动通常是位置相关的, 即使扰动在输入图像上的位置只有细微偏差, 也会使攻击效果急剧下降.
与此同时, Karmon等[13]提出局部可视对抗扰动(Localized and Visible Adversarial Noise, LaVAN), 通过将一小块局部、肉眼可察觉的对抗扰动放置在输入图像上, 使分类网络发生误判.这种扰动具备位置无关性和图像通用性, 可叠加在不同的干净样本任意位置上, 形成对抗样本以攻击分类网络.虽然这些扰动面积很小, 但是极易混淆在自然图像的背景中.即使监控者发现它们, 也很有可能将扰动视为图像中的自然噪声而忽视潜在的攻击性.LaVAN通过迭代更新的方式生成局部可视对抗扰动, 当扰动覆盖输入图像约2%面积时, 可以实现78.9%的攻击成功率.
当前, 已有不少工作分析视觉不可感知的对抗扰动存在的原因[13, 14], 但与局部可视对抗扰动相关的工作还主要集中在如何生成、防御局部可视对抗扰动, 针对有效性的分析还很少.Brown等[15]和Karmon等[13]论述扰动的攻击有效性, 但给出完全相反的意见.Brown等推测局部可视对抗扰动可能是图像中“ 最突出的部分(the most salient item)” , 使网络将扰动视为图中的主要目标, 从而忽视对抗样本中的真实图像部分, 导致错误分类.而Karmon等通过一系列的实验分析发现, DNN通常不会将局部可视对抗扰动视为对抗样本的显著区域, 对抗样本的攻击性与局部可视对抗扰动并无直接关系.因此有必要进一步分析局部可视对抗扰动的有效性.
本文以生成对抗网络(Generative Adversarial Networks, GAN)[16]为基础, 提出局部可视对抗扰动生成模型(GAN for Generating Localized and Visible Adversarial Perturbation, G2LVAP), 生成与图像无关、面积很小、人眼可见的扰动.G2LVAP指定被攻击的分类模型作为判别器并固定参数不变, 通过训练生成器网络参数, 使生成器最终能够将输入的随机变量转换为局部可视对抗扰动.攻击者在确定被攻击分类模型后, 只需调整G2LVAP生成器的部分结构, 就可生成不同大小的局部可视对抗扰动.实验表明, 相比LaVAN, G2LVAP生成的扰动攻击效果更好, 仅需覆盖输入图像1%的面积即可实现约90%的攻击成功率.本文还设计实验方法, 从类别判定的角度分析局部可视对抗扰动的有效性.从实验结果可知, 局部可视对抗扰动吸引分类网络大部分注意力, 导致网络将对抗样本错误分类.
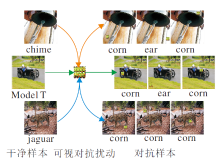
G2LVAP生成的局部可视对抗扰动具有位置无关性和图像通用性, 如图1所示.位置无关性是指将扰动放置在输入样本任意位置上, 都可以形成对抗样本并成功欺骗分类器.图像通用性是指扰动可应用于不同的输入图像, 攻击者只需生成1个扰动并叠加在不同的输入样本上, 就可以攻击分类器.同时, 由于扰动的面积很小, 它们容易隐藏在输入图像的背景中, 即使监控者看到这类扰动, 也很有可能将它们视为图像中的噪声.
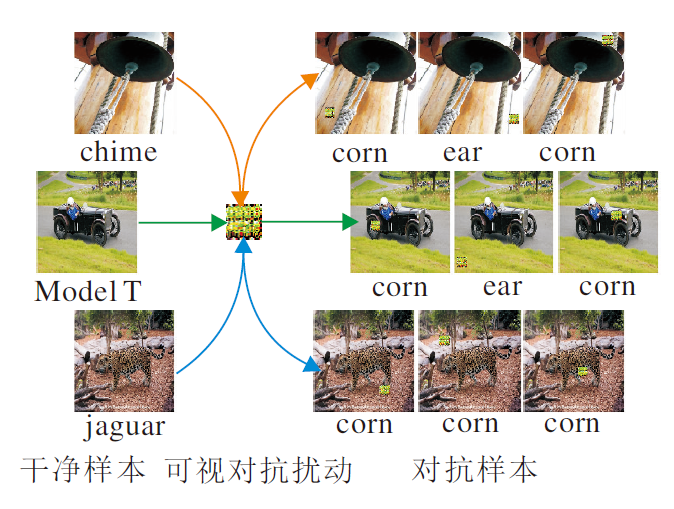 | 图1 局部可视对抗扰动示意图Fig.1 Illustration of localized and visible adversarial perturbation |
首先, 对本文使用的符号进行形式化规范.定义干净的输入样本x服从于分布Χ , 被攻击的分类网络为f, 分类网络最后一个卷积层的输出为fc(x).令y(x)为分类网络的预测类别, P(x)为分类网络最后一层的输出值, Pj(x)为分类网络预测样本为类别j的概率.δ 为生成的局部可视对抗扰动, 将扰动δ 随机放置在x某个位置上得到的对抗样本表示为A(x, δ ).
本文的目标可以形式化表述为寻求产生δ 的方式, 使
y(x)≠ y(A(x, δ ) for x~Χ .(1)
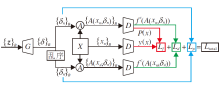
为了实现这个目标, 本文以GAN为基础, 构建G2LVAP, 如图2所示, 输入z为随机变量.不同于GAN框架同时训练生成器G和判决器D, G2LVAP以分类网络f作为判决器D并固定参数不变.在训练模型的过程中, 仅优化生成器G的参数, 直到G能够将输入的随机变量z转换为具备攻击性的局部可视对抗扰动.
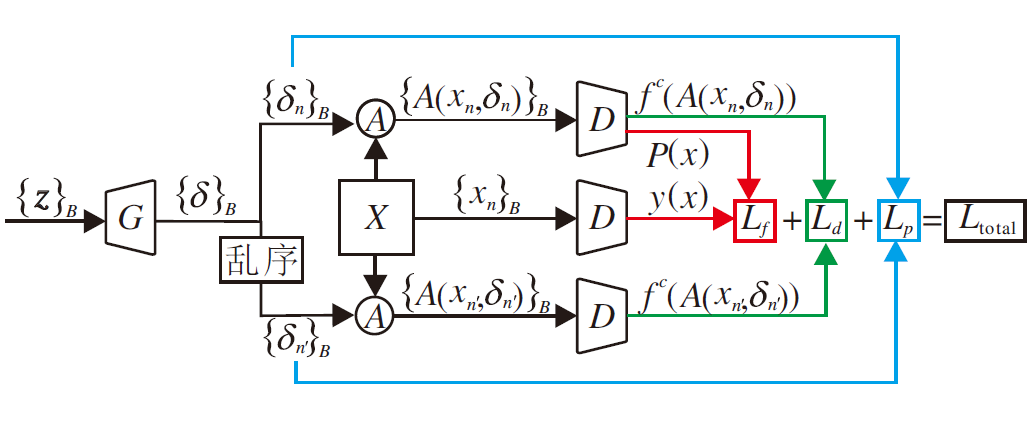 | 图2 G2LVAP框图Fig.2 Flowchart of G2LVAP |
为了欺骗目标分类网络, 需定义合适的损失函数以训练G.y(x)为分类网络对样本x的预测类别, Py(x)(A(x, δ ))表示对抗样本A(x, δ )被目标分类网络判定为类别y(x)的概率, 为实现式(1)目标, 扰动δ 应当尽可能对分类网络造成混淆, 减小Py(x)(A(x, δ ))的值, 直到存在类别j, 使
Py(x)(A(x, δ ))≠ Pj(A(x, δ )) for j≠ y(x). (2)
当式(2)满足时, 目标分类网络将对抗样本A(x, δ )判定为其它类别(如类别j)而非y(x), 扰动攻击目标分类网络成功.因此, 定义欺骗损失:
Lf=-lg(1-Py(x)(A(x, δ ))).(3)
Lf随着Py(x)(A(x, δ ))的减小而减小.通过优化欺骗损失Lf, 使生成器G产生足以攻击目标分类网络的局部可视对抗扰动.
fc(x)为分类网络最后一个卷积层的输出, 通常也可视为网络对输入x提取的特征.对于不同的输入图像, 分类网络f提取的特征也不尽相同.如果2个扰动δ 1和δ 2差异越大, 那么分类网络对其提取的特征fc(A(x, δ 1))和fc(A(x, δ 2))差别也会越明显.因此, 为了增加扰动的多样性, 对同一批次生成的扰动δ n和δ n', 引入多样性损失Ld为
Ld=-
如图2所示, 每批次进入模型的输入样本数量为B, n'∈ [1, B], n'≠ n, xn和δ n分别表示输入生成器的第n个样本和扰动, d(· , · )表示距离函数, 在本文中定义为2范数距离.通过减小多样性损失, 增大fc(A(xn, δ n))与fc(A(xn, δ n'))之间的距离, 可以丰富扰动的多样性.进一步地, 对扰动{δ n}和{δ n'}直接定义距离损失:
Lp=-
Lp越小, 扰动δ n和δ n'之间的距离越大, 扰动之间的差异性越明显.综上所述, 为了实现扰动的攻击性和多样性, 设定调节参数α 、β , 最终损失Ltotal定义为
Ltotal=Lf+α Ld+β Lp.
模型的具体训练过程如算法1描述, 采用Adam算法优化[17].生成器G的参数随着迭代训练逐步优化, 生成的局部可视扰动攻击性也逐渐增强.
算法1 G2LVAP
输入 确定被攻击的分类网络f(即生成器D),
构建生成器G,
确定训练样本集Xtrain, 验证样本集Xvalidation,
Adam算法学习率ρ , 参数α 、 β
输出 生成器网络的权重参数W
设定分类网络的误分类率fr=0, 随机初始化W
while fr not converged do:
for each x∈ Xtrain do:
输入B个随机向量{z}B和干净的输入样本{x}B
{δ }B=G({z}B)
计算Ltotal
更新权重W=W-ρ
end
计算Xvalidation叠加扰动后的fr
end while
在训练过程中, 定义随机变量z为100维向量, 服从[0, 1]一致分布.设定同一批次有B(Batch_size)个变量{z}B={z1, z2, …, zB}进入网络, 经过生成器G转化成一组可视扰动{δ }B={δ 1, δ 2, …, δ B}, 在训练样本集中随机采样B个样本图像{x}B={x1, x2, …, xB}.接下来将扰动一对一地叠加到训练数据上, 形成相应的对抗样本
如图2上侧分支所示.同时, 对这组可视扰动进行随机乱序处理, 形成一组扰动{δ 1', δ 2', …, δ B'}, 对于∀ i有δ i≠ δ i'.以此形成另一组对抗样本
如图2下侧分支所示.在组成对抗样本
由此可知, 在每次迭代训练过程中, 网络都包含3批次数据, 即样本图像{x}B、对抗样本
需要注意的是, 为了生成位置无关的扰动, 在整个训练过程中扰动摆放在样本上的位置都是随机的.因此, 在不同的训练批次中, 即使采用相同训练样本xi和局部可视对抗扰动δ i, 由于扰动δ i摆放在样本xi上的位置是随机的, 它们形成的对抗样本A(xi, δ i)也不一定相同.
实验采用ImageNet项目的ISLVRC2012数据集[18].ImageNet项目是一个用于视觉对象识别软件研究的大型可视化数据库, 是目前世界上最大的图像识别数据库.ImageNet项目每年举办一次大规模视觉识别挑战赛(ILSVRC).ISLVRC2012的训练集包含128 167幅图像及标记, 验证集包含50 000幅图像及标记, 用于最终评分的测试集为100 000幅图像(无标记), 数据包含1 000个不同类别的物体.
从ISLVRC2012训练集1 000类样本中选择20 000幅图像作为实验训练集, 其中每类样本随机选择20幅图像, 并从ISLVRC2012验证集中随机选择10 000幅图像作为实验验证集, 最后从剩下的验证集图像中再随机选择10 000幅图像作为实验测试集.
以预训练好的Inception-V3网络[19]作为攻击目标.Inception-V3是GoogLeNet系列模型之一, 通过堆叠Inception模块形成大规模卷积神经网络.Inception模块通常包含1× 1, 3× 3或5× 5等不同尺寸的卷积核, 以获得输入图像的不同信息.并行处理这些运算并结合所有结果, 获得更好的图像特征信息.Inception-V3网络在简化网络规模、减少训练参数、加快训练速度的同时, 提升图像识别精度, 在ISLVRC2012测试集上可实现96.42%的图像分类精度.
考虑到Inception-V3网络的输入图像大小为299× 299, 尝试生成的局部可视对抗扰动大小分别为15× 15(约占输入图像面积0.25%)、20× 20、25× 25、30× 30(约占输入图像面积1%)的正方形, 4种情况下生成器G的结构如表1所示.
| 表1 生成器结构 Table 1 Structure of generator |
在表1中, FC(Fully Connected Layer)表示全连接层, Batch_Norm表示归一化该层隐藏单元值, Deconv表示反卷积层.由于被攻击的Inception-V3网络需将输入图像的RGB值归一化至[-1, 1]区间, 因此选择tanh函数作为生成器G的最后一层.设定参数ρ =0.001, α =20, β =0.1.
在图像分类任务中, 当生成的局部可视对抗扰动满足式(1)时, 被攻击的分类网络将干净样本和对抗样本判定为不同类别, 此时局部可视对抗扰动攻击成功.
本节采用G2LVAP生成4种面积不同的局部可视对抗扰动, 每种随机选择1个扰动显示在图3(a)中.本文生成的扰动仅用于数字场景下的攻击, 现有的研究仅有LaVAN与本节相似, 因此按照LaVAN同样生成4个面积不同的扰动, 显示在图3(b)中.为了更好地分析扰动的攻击性能, 随机生成4个面积不同的扰动(Random Noise, RN), 如图3(c)所示.
 | 图3 不同方式生成的不同面积局部可视对抗扰动Fig.3 Localized and visible adversarial perturbations of different areas generated by different methods |
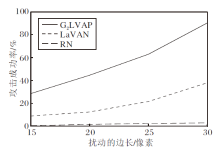
使用这3组扰动进行攻击性能测试, 将扰动分别放置在测试集的10 000幅图像上, 观察对抗样本的攻击成功率fr.由于扰动放置在干净样本上的位置是随机的, 可能会对分类识别网络的判断造成影响, 因此重复测试10次, 结果如图4所示.
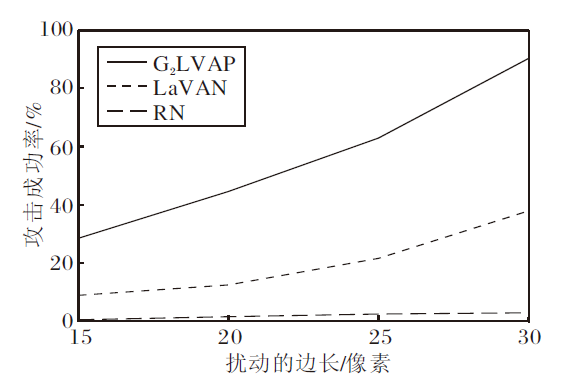 | 图4 局部可视对抗扰动的攻击成功率Fig.4 Attack success rate of localized and visible adversarial perturbations |
由图4可知, 当扰动面积为15× 15(约占输入图像面积0.25%)时, G2LVAP和LaVAN的攻击能力有限, 分别只能实现28.49%± 2.30%和8.90%± 3.42%的攻击成功率.随着扰动面积的增加, G2LVAP和LaVAN的攻击成功率迅速提升, 当扰动大小为30× 30时, 虽然面积仅占干净图像样本的1%, LaVAN的攻击成功率为37.79%± 2.61%, G2LVAP的攻击成功率高达90.23%± 1.91.这意味着采用G2LVAP的攻击者仅需精心构建一个极小的局部可视对抗扰动, 然后叠放在输入图像的任意位置上, 就可以导致绝大部分样本被深度神经网络错误分类.观察随机扰动(RN)的攻击效果可知, 面积的增长并不会提升随机扰动的攻击性, 随机扰动的攻击成功率较低.综合图4的结果可知, 向输入样本中随机添加小范围的扰动无法攻击图像分类网络, 只有精心构造的对抗扰动才能攻击分类器.
由图4还可以观察到, 当扰动的面积相同时, G2LVAP的攻击成功率远高于LaVAN, 这主要是由于两种方法初始目的不同造成的.G2LVAP致力于构造可以欺骗图像识别网络的扰动, 即生成的扰动是无目标的.LaVAN的目的是指定一个类别并产生相应的扰动, 使分类网络将对抗样本识别为目标类别, 是有目标的对抗扰动.因此, 当仅以攻击成功率为考量标准时, G2LVAP的效果优于LaVAN.
为了进一步验证G2LVAP生成的局部可视对抗扰动的图像无关性, 采用G2LVAP生成的一个面积为30× 30的扰动攻击多个输入样本, 如图5所示.在每组图像中, 干净的输入样本能被Inception-V3网络正确分类, 对抗样本都叠加相同的扰动, 扰动放置的位置随机.可以看到, G2LVAP生成的局部可视对抗扰动应用在不同的干净样本时, 都能欺骗图像分类网络.
 | 图5 G2LVAP图像无关性示例Fig.5 Examples of image independence of G2LVAP |
由实验结果可知, G2LVAP生成的局部可视对抗扰动能够实现较高的攻击成功率, 对此作进一步分析.Lei等[20]指出, 从数据中学习隐藏的流形结构和流形上的概率分布是深度神经网络的主要目的和功能之一.根据这个观点, 本文认为局部可视对抗扰动有可能服从某种高维空间分布, G2LVAP在训练生成器的过程中会不断探索并拟合这个高维空间分布, 使生成器将随机变量z转变为欺骗分类网络的局部可视对抗扰动.
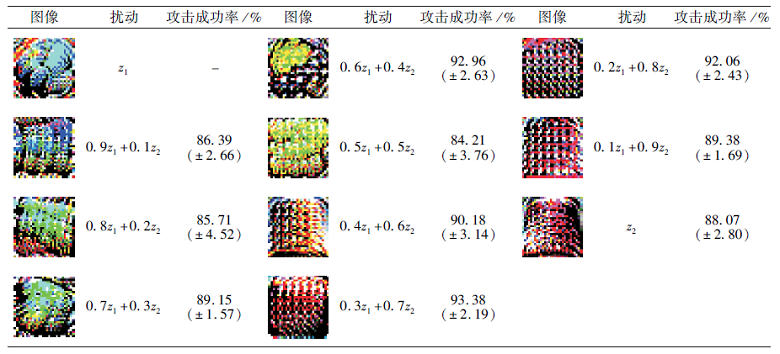
为了验证这个设想, 从随机变量z中随机采样两个点z1和z2, 并考虑z1、z2连接线上的10个插值点, 通过预训练好的生成器G产生与这些中间点对应的局部可视对抗扰动.表2为各点对应生成的扰动及攻击成功率.
通过观察可知, 在z1和z2之间, 随着输入变量的变化, G生成的扰动也逐渐变化, 并且这些扰动的变化显然存在一定的结构性和过渡性.记录扰动对10 000张测试集照片的攻击成功率, 均值都接近90%, 这表明生成器G经过不断训练, 有可能学习可视对抗扰动的数据分布, 使生成的扰动具有很强的攻击能力.
| 表2 z1和z2之间的插值点对应的局部可视对抗扰动 Table 2 Localized and visible adversarial perturbations generated by interpolation points between z1 and z2 |
攻击者通常希望扰动具有一定的差异性, 更难以被防御.本节引入结构相似性(Structural Similarity Index, SSIM)和峰值信噪比(Peak Signal to Noise Ratio, PSNR), 分析局部可视对抗扰动的多样性.SSIM是衡量两幅图像相似度的指标, 从亮度、对比度和结构这3个方面评估两幅图像的相似性, 取值范围为0至1.当两幅图像一模一样时, SSIM的值等于1.PSNR同样是使用最广泛的图像相似性评价指标之一, 利用两个样本图像对应像素点间的误差进行对比, 是基于误差敏感的图像质量评价.PSNR的单位是dB, 数值越大表示两幅图像越相似, 高于40 dB说明两幅图像非常相似, 低于20 dB表示两幅图像差异较大.
随机选择6个G2LVAP生成的局部可视对抗扰动, 大小均为30× 30, 分别编号为A~F, 如图6所示, 计算两两之间SSIM值及PSNR值, 结果分别如表3和表4所示.
 | 图6 G2LVAP生成的6个局部可视对抗扰动Fig.6 Diverse localized and visible adversarial perturbations generated by G2LVAP |
| 表3 局部可视对抗扰动间的SSIM值 Table 3 SSIM between different localized and visible adversarial perturbations |
| 表4 局部可视对抗扰动间的PSNR值 Table 4 PSNR between different localized and visible adversarial perturbations dB |
以SSIMi, j表示扰动i和j的SSIM值, PSNRi, j表示扰动i和j的PSNR值.从表3可知, 仅有SSIMA, C和SSIMC, D之间的SSIM略大于0.1, 而SSIMA, B和SSIMA, F的值甚至小于0.01, 这说明6个用于测试的扰动结构相似性非常小.从表4可知, 只有PSNRA, C和PSNRC, D值略大于5 dB, 大部分扰动之间的峰值信噪比都小于4 dB, 这意味着6个用于测试的局部可视对抗扰动之间相似性极小.这些结果表明G2LVAP生成的扰动符合多样性要求, 可以针对指定的图像分类网络生成多个差异性明显的局部可视对抗扰动.
当前无严格、公认的分析对抗扰动隐蔽性的指标.Moosavi-Dezfooli等[11]在提出视觉不可知的通用对抗扰动时, 也只是根据多次实验经验提出观测性的结论:当对抗扰动的每个像素点RGB值小于10时, 隐蔽效果较好, 不易被人眼感知.因此, 本节对G2LVAP生成的可视对抗扰动隐蔽性不进行数值上的分析, 只是提供一些干净输入样本及对抗样本的对比图进行对比观察.如图7所示, 将大小为30× 30的可视对抗扰动放在自然图像的背景部分, 图像的下侧标明分类网络对图像的分类结果.
 | 图7 G2LVAP隐蔽性示例Fig.7 Examples of covertness of G2LVAP |
从图7可看到, 当图像背景较复杂时, 将扰动放置在图像背景中具有较好的隐蔽效果, 除非刻意仔细观察样本, 监管人员并不一定能注意到这些局部的可视对抗扰动.
研究人员虽然已经实现欺骗分类网络的局部可视对抗扰动, 但在探讨扰动为何能够攻击分类网络时, 却无法达成一致意见.Brown等[15]推测局部可视对抗扰动在分类网络的“ 视界” 非常显著, 吸引分类网络大量的注意力.而Karmon等[13]通过评估对抗样本向指定类别转换时像素点的变化, 定性地得出结论:分类网络虽然会将对抗样本错误分类, 但这些错误并不是由对抗扰动造成的.
本文尝试从类别判定的角度分析局部可视对抗扰动的有效性.对比图8中3幅图像的预测结果, 分类网络能够把(a)中干净样本x正确分类为indigo bunting, 但将(b)中对抗样本xadv错误分类为corn.(c)中存在相应的对比扰动δ c, 表示将可视对抗扰动δ 放置在大小为299× 299、所有像素点RGB=[0, 0, 0]的图像上, 并且δ 放置的位置与对抗样本xadv中位置相同.
 | 图8 x、xadv和δ c的分类结果对比Fig.8 Comparison of predicted labels between xadv and δ c |
为了便于观察, 将对比扰动δ c的背景显示为灰色.分类网络同样将δ c分类为corn, 与中间的对抗样本xadv分类相同, 这表明可视对抗扰动有可能是导致分类网络将对抗样本错误分类的原因.
下面进一步分析扰动的有效性.首先将可视对抗扰动δ 的位置设定为对抗样本xadv的左上角, 重复图8的实验, 然后每次将扰动向右或向下平移2像素再进行对比, 最终进行17 956次对比, 结果如表5所示.在全部实验中, 对比扰动δ c均分类为corn或ear, 表明图8的局部可视对抗扰动δ 在分类网络的感知中呈现为corn或ear.对抗样本xadv成功攻击分类网络15 762次(成功率为87.78%), 说明扰动δ 具有极强的攻击性.在对抗样本攻击成功时, 对抗样本xadv与对比扰动δ c有12 519次(占比69.72%)分为相同类别.在对抗样本xadv与对比扰动δ c分类结果不同的3 243次(占比18.26%)实验中, 对抗样本仍然有3 242次被分类为corn或ear.
| 表5 xadv和δ c在1个干净样本下的分类结果对比 Table 5 Comparison of classification results between xadv and δ c (one clean example) |
图8使用的局部可视对抗扰动δ 在这一组实验中实现87.78%的攻击成功率, 并且在Inception-V3网络的“ 视界” 中, 对比扰动δ c看起来就是corn或ear(在人眼看来无法分辨).考虑到对比扰动中实际发挥作用的只有局部可视对抗扰动δ , 其余的RGB值为0的像素点不会影响被攻击网络的输出, 因此Inception-V3网络本质上是将扰动δ 视为corn或ear.当扰动攻击成功时, 大部分情况下对抗样本xadv会分类为corn或ear(占总实验次数的87.78%), 并且在69.72%的实验中对抗样本xadv与对比扰动δ c都会判定为相同类别.这组实验充分说明, 可视对抗扰动δ 是导致对抗扰动错误分类的主要原因.
从测试集图像中随机挑选100幅图像作为干净样本重复上面的测试, 结果如表6所示.表中符号-表示对抗样本xadv被分类网络判定的类别较多, 不一一列举.攻击成功率为92.95%, 其中对抗样本分类为corn或ear的情况占总次数的92.94%.此结果表明, 当干净样本叠加上被分类网络视为corn或ear的可视对抗扰动后, 大部分情况下分类网络的注意力会被扰动吸引, 忽视样本中自然图像的部分, 从而将形成的对抗样本xadv误判为与对比扰动δ c相同的类别.因此, 可视对抗扰动能够攻击分类网络的原因在于, 它们对于分类网络是极其显著的.
| 表6 xadv和δ c在100个干净样本下的分类结果对比 Table 6 Comparison of classification results between xadv and δ c on 100 clean examples |
进一步扩展此实验, 对比图9所示4幅图像的预测结果.(a)为叠加2个可视对抗扰动的对抗样本, (b)为对比扰动, 同样是将2个扰动叠加在RGB=[0, 0, 0]的图像上, 位置与(a)相同.(c)、(d)分别叠加1个可视对抗扰动的对比扰动.(a)、(b)均被判定为thimble, 与(c)相同, (d)被判定为corn.分析此结果, 认为是因为扰动“ thimble” 比扰动“ corn” 更显著, 当输入图像中存在2个扰动时, 分类网络的注意力都聚集在扰动“ thimble” 上, 导致网络将对抗样本判定为thimble.
 | 图9 不同的对比扰动δ c的分类结果对比Fig.9 Comparison of classification results of different δ c |
综上所述, 大部分情况下模型会将对抗样本错误分类, 并且判定为与对比扰动相同的类别, 这说明对抗样本产生攻击性的关键在于其中的局部可视对抗扰动.局部可视对抗扰动在被攻击模型的“ 视界” 中可能非常显著, 以致于吸引网络的大部分注意力, 使网络忽视输入图像中的自然图像部分, 并将输入图像误判为其它类别.并且, 在被攻击模型看来, 大部分时候对抗样本与对比扰动属于同一类别.因此有理由相信, 局部可视对抗扰动能够攻击分类网络的原因在于它们对于分类网络是极其显著的.
本文以生成对抗网络为基础, 提出局部可视对抗扰动生成方法(G2LVAP).指定被攻击分类网络为判决器, G2LVAP通过不断训练生成器即可产生局部可视对抗扰动.G2LVAP通过优化欺骗损失, 提升扰动的攻击性.为了增加扰动的丰富性, 采用多样性损失和距离损失, 使G2LVAP能够生成不同的局部可视对抗扰动.实验表明, G2LVAP生成的扰动仅需覆盖输入样本非常小的面积, 即可使分类网络出现较高的错误分类率.本文还提出类别对比方法, 分析局部可视对抗扰动的有效性.由实验结果可知, 局部可视对抗扰动吸引分类网络大量的注意力, 使网络忽视对抗样本中自然图像的部分, 从而将样本错误分类.针对局部可视对抗扰动的研究有利于研究者发现深度神经网络的盲点, 构建更鲁棒的模型.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|