



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
用于行人重识别的多类型特征网络
[王鹏1  , 宋晓宁
, 宋晓宁1 , 吴小俊1 , 於东军2 ]
, 宋晓宁, 吴小俊, 於东军]
|
|



作者简介:

王 鹏,硕士研究生,主要研究方向为深度学习、计算机视觉.E-mail:614132282@qq.com.

吴小俊,博士,教授,主要研究方向为模式识别、计算机视觉、人工智能、模糊系统、神经网络等.E-mail:wu_xiaojun@jiangnan.edu.cn.

於东军,博士,教授,主要研究方向为机器学习、模式识别、神经网络、生物信息学等.E-mail:njyudj@mail.njust.edu.cn.
近年来,注意机制在行人重识别任务中效果较优,但是不同类型的注意机制(如空间注意、自注意等)联合使用的效果仍然有待提高.因此,文中首先提出改进型的卷积块注意模型(CBAM-Pro),再提出多类型特征网络模型.对CBAM-Pro与自注意机制的集成提取不同关注域的特征,同时引入不同划分粒度的局部特征,联合进行行人重识别.在现有的通用基准数据集上的实验验证文中模型的有效性与可靠性.
AboutAuthor:
WANG Peng, master student. His research interests include deep learning and computer vision.
WU Xiaojun, Ph.D., professor. His research interests include pattern recognition, computer vision, artificial intelligence, fuzzy system and neural network.
YU Dongjun, Ph.D., professor. His research interests include machine learning, pattern recognition, neural networks and bioinformatics.
The attention mechanism is effective in person re-identification. However, the performance of the combined use of different types of attention mechanisms needs to be improved, such as spatial attention and self-attention. An improved convolutional block attention model(CBAM-PRO) is proposed, and then a multi-type features network(MTFN) is proposed. The features of different interested domains are extracted through the integration of CBAM-Pro and self-attention mechanism, and the local features with different granularities are introduced concurrently to perform person re-identification jointly. The validity and reliability of MTFN are verified by the experiments on the existing general benchmark datasets.
本文责任编委 高隽
Recommended by Associate Editor GAO Jun
行人重识别在智能安防领域具有较大需求, 它旨在关联不同时间、地点的相同行人.一般做法是给定一幅行人的待检索图像, 通过已经训练好的模型提取查询图像和图库中图像的特征, 按照特征的相似性排序图库中的图像, 进行行人图像检索.近年来行人重识别任务取得较大进展, 但是由于在开放的户外环境下, 行人图像会由于姿势、遮挡、衣服、背景杂波、相机视角等干扰的存在产生较大差异, 因此行人重识别仍是一项具有挑战的任务.
解决行人重识别任务有2个传统方向:表征学习和度量学习.表征学习的本质是提取携带更多行人鉴别信息的特征, 使用这些较优的特征进行行人识别.随着深度学习的不断发展, 通过深度网络提取的鉴别特征已基本上取代手工设定的描述特征.Li等[1]和Yi等[2]将深度孪生网络(Siamese Network)架构引入行人重识别任务中, 并结合人体部位特征进行学习, 所得结果性能优于同期手工特征方法.Zheng等[3]提出ID判别嵌入方法(ID-Discriminative Embedding, IDE), 进行深度特征提取.目前IDE已成为基于深度学习方法进行行人重识别任务的基础架构.
不同于表征学习, 度量学习的关键在于设计较优的度量损失函数, 将提取的特征映射到一种特定的特征空间中, 在此空间中相似样本之间的特征距离较小, 不相似样本之间的特征距离较大, 达到区分行人身份的效果.常用的度量学习方法包括: 对比损失[4]、三元组损失[5, 6, 7]、四元组损失[8]、难样本采样三元组损失[9]等.此外, 为了进一步提升识别结果的精度, Zhong等[10]提出模型训练后的处理方法— — 重排序方法, 通过k倒排编码(k-Reciprocal Encoding)重新计算特征之间的相似性, 大幅提升行人重识别任务的检索结果.此方法已成为提升精度的通用方法.
除了表征学习与度量学习, 局部特征学习也广泛应用于行人重识别任务.对于局部特征学习, Sun等[11]提出基于分块的卷积基线(Part-Based Convo-lutional Baseline, PCB), 将深度特征图均匀划分成6个相等的局部区域, 并对每个区域分别进行Softmax Loss分类, 大幅提升精确度.受到这项工作的启发, Wang等[12]提出多粒度网络(Multiple Granularity Network, MGN), 结合多粒度特征, 进一步提升识别性能.此外, Zhang等[13]计算两组特征之间的最短距离, 获得相应的局部特征.Huang等[14]使用基于COCO数据集的人体姿态估计方法检测行人的关键点, 用于图像分割和局部特征提取.
近年来, 注意机制已发展成为深度学习中应用广泛的技术之一.Hu等[15]提出挤压激励模块(Squeeze-and-Excitation), 建模通道之间的相互依赖关系, 自适应重新校准通道间的特征响应.Woo等[16]分别建模空间通道的关系, 提出卷积块注意模型(Convolutional Block Attention Model, CBAM).Wang等[17]发现Squeeze-and-Excitation模块中的降维操作是低效的, 为此提出高效通道注意模块(Efficient Channel Attention(ECA) Module), 改进Squeeze-and-Excitation模块.注意机制在行人重识别任务中应用活跃, Si等[18]提出双注意匹配网络(Dual Attention Matching Network, DuATM), 使用类内注意策略进行特征细化, 使用类间注意策略进行特征对齐.Li等[19]提出和谐注意网络(Harmonious Attention CNN, HACNN), 结合空间注意与通道注意, 学习较优的关注特征.
因为卷积块注意模型中的通道注意模块实际上就是Squeeze-and-Excitation模块, 本文发现它存在一定的性能改进空间, 基于此种情况, 本文引入ECANet(ECA Networks)机制, 改进CBAM, 提出改进型的卷积块注意模型(An Improved CBAM, CBAM-Pro).CBAM-Pro的架构与CBAM一样, 都是先进行通道注意, 再进行空间注意.通道注意机制通过建模通道维度之间的关系校准通道之间的响应, 空间注意机制与此类似, 通过卷积与Sigmoid激活建模空间像素之间的关系, 获得相应权值, 自适应校准像素之间的响应.除了CBAM-Pro, 还考虑自注意机制, 即Non-local模型[20], 这种机制实际上也是对空间维度的一种操作, 可捕获空间像素之间的长距离依赖关系, 在相关像素之间建立共同响应的联系.由于空间注意机制与自注意机制实际上都是在对特征图的空间维度进行操作, 分析这两种机制的区别发现, 空间注意机制为乘性操作, 将得到的权重特征乘到原始特征图上, 直接增强网络对特征高鉴别位置的关注.自注意机制为加性操作, 将得到的像素关联特征图加到原始特征图上, 建立相关像素的长距离依赖关系, 增强对相关像素的共同关注.由此可知两种机制虽然都是对空间像素进行注意操作, 但是由于侧重不同, 所以可共同应用于网络中, 提取更丰富的行人特征.
由于多粒度特征被证明对行人重识别任务具有较大提升作用[12], 所以除了提取不同的注意特征之外, 本文的网络架构中还加入多粒度特征提取分支, 用于提取不同粒度的局部特征.因此提出的多类型特征网络模型可提取不同的注意特征, 与局部多粒度特征进行连接, 共同用于行人鉴别.此外本文的网络模型进行端到端训练, 未加入额外监督, 也可取得较优结果.
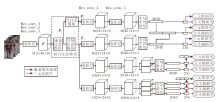
卷积块注意模型(CBAM)[16]结构如图1所示.给定特征图F∈ RC× H× W, 其中, C为特征图的通道数, H× W为特征图的大小.
 | 图1 卷积块注意模型结构图Fig.1 Structure of convolutional block attention module |
首先将F送入通道注意模块, 把得到的结果再交给空间注意模块.相比挤压激励网络(Squeeze-and-Excitation Networks, SENet)[15]仅使用通道注意, CBAM的改进不光引入空间注意, 而且使用最大池化作为特征补充.对于通道注意, 首先将F送入通道注意模块, 通过平均池化和最大池化汇聚每个通道的空间信息, 得到2个信息汇聚向量Cavg∈ RC× 1× 1, Cmax∈ RC× 1× 1.之后将Cavg和Cmax通过共享参数的多层感知机(Multilayer Perceptron, MLP), 包含2个全连接层), 再进行逐元素加操作, 将相加结果通过Sigmoid激活得到通道权重特征向量, 将其与原特征图进行逐元素相乘, 得到通道注意特征图:
Fc=σ (MLP(Cavg)+MLP(Cmax))☉F,
其中, σ 表示Sigmoid激活函数, ☉表示逐元素乘.由于特征图的每个通道被视为一个特征检测器, 用于关注输入图像的“ 什么” 是有意义的[16], 故通道注意力的作用主要在于确定给定输入图像的哪些通道对识别任务更有价值.
对于空间注意, 将给定特征图F送入空间注意模块后, 通过平均池化和最大池化沿通道维度汇聚空间信息, 生成2个2D的空间特征图Savg∈ R1× H× W和Smax∈ R1× H× W.然后将得到的特征图沿通道方向连接后, 通过1× 1的卷积层与Sigmoid激活, 得到空间像素权重特征图, 再与F逐元素乘, 得到空间注意特征图:
Fs=σ (Conv(Cat(Savg, Smax)))☉F,
其中, σ 表示Sigmoid激活函数, Cat表示连接操作, ☉表示逐元素乘.不同于通道注意, 空间注意的作用主要在于把握“ 哪里” 是有意义的信息, 这实际上是对通道注意关注的一种补充.
本节通过改进CBAM提出改进型卷积块注意模型(CBAM-Pro).因为CBAM同时考虑通道与空间的关注, 对其进行改进时, 空间维度的操作仍遵循CBAM.CBAM的通道注意模块中通道注意机制运行方式如图2所示.实际上CBAM在通道注意中使用的多层感知机就是一个Squeeze-and-Excitation模块, 如(a)所示, 图中r为缩放参数, 通过2个全连接层进行注意权重分配.考虑到ECANet[17]证明Squeeze操作会对通道注意的预测带来负面效果, 因此引入ECANet的高效通道注意模块以改进CBAM.
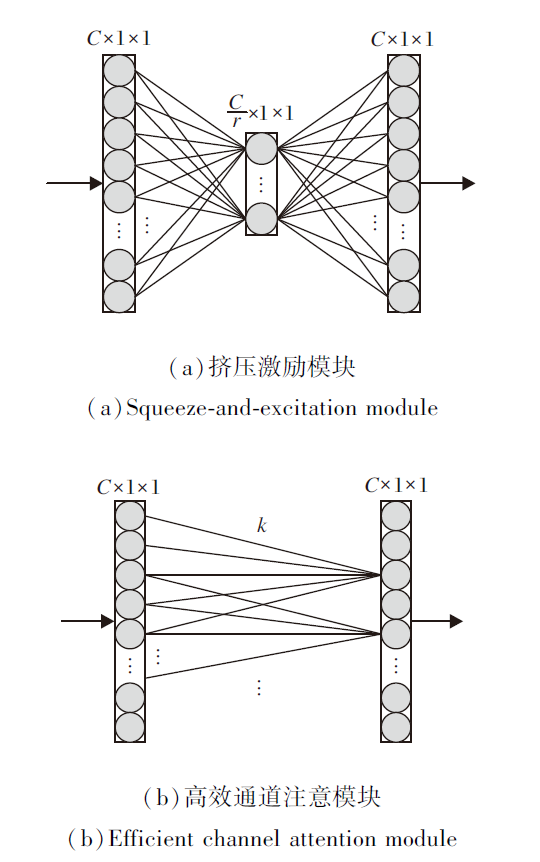 | 图2 通道注意机制的运行方式Fig.2 Operation mode of channel attention mechanism |
首先仍将特征图F分别通过2个池化层, 得到Cavg与Cmax.然后将多层感知机替换为高效通道注意模块, 用于分配注意权重, 如图2(b)所示.高效通道注意模块关注1个通道与其相邻的k(k为邻域大小)个邻居, 用于捕获通道间的信息交互, 以此分配注意权重, 这仅需1个一维卷积就可轻松实现, 并取得相比使用Squeeze操作压缩通道域更优的效果.注意到, 在这里使用高效通道注意模块与CBAM中的多层感知机一样, Cavg与Cmax也共享参数, 之后通过逐元素相加与Sigmoid操作, 获得通道权重特征向量:
w=σ (CIDk(Cavg)+CIDk(Cmax)),
其中, σ 表示Sigmoid激活函数, CIDk为卷积核大小为k的一维卷积操作.CBAM-Pro不仅保留CBAM的优秀特性, 同时引入ECANet对于Squeeze-and-Excitation模块的改进, 性能更优.
本文使用应用于二维图像的Non-local模块对特征图进行自注意关注.对于特征图上某个位置的特征值, 与其它所有位置的值进行加权求和, 相应的权值由特征值之间的相关性决定, 这样无论在空间位置上2个像素位置相距多远, 只要拥有一定的相关性, 就可进行相互促进.如图3所示, 给定特征图F.将F分为双路, 通过1× 1卷积之后计算得到空间特征相关矩阵X∈ RN× N, N=H× W.在此使用运用最广泛的Embedded Gaussian函数计算X:
xij=
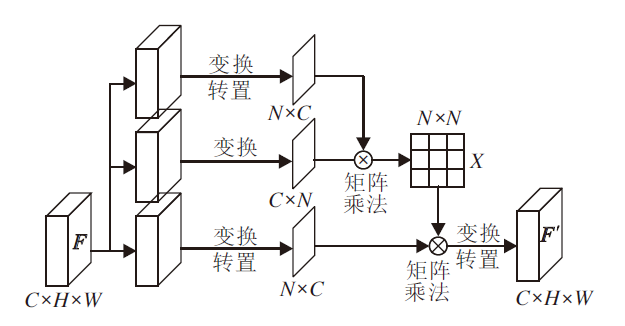 | 图3 自注意模型结构Fig.3 Structure of self-attention module |
其中, xi、xj分别表示空间位置i、 j处的特征值, xij表示空间位置i、 j之间的相关性, Wq、Wk表示1× 1卷积的权重矩阵.将所得的相关矩阵X与F相乘, 得到像素关联特征图F', 将F'与原特征图F逐元素加, 这样F中每个像素位置i都包含它与其它位置的相关性:
Fi=Fi+F'i=Fi+
本文使用的多类型特征网络(Multi-type Fea-tures Network, MTFN)结构如图4所示, 网络的基础架构采用在行人重识别任务中最常被使用的ResNet50.网络训练得到多种类型的行人特征, 包括不同注意的全局特征与不同粒度的局部特征.在提取局部特征时, 采用直接水平划分特征图的方式.在实验过程中, 尝试将网络划分为PCB[11]形式的6分支结构, 及MGN[12]的2、3分支结构.
 | 图4 多类型特征网络结构图Fig.4 Structure of multi-type features network |
对于全局特征分支, 在网络中联合使用CBAM-Pro与自注意模块.由于CBAM-Pro中的空间注意与自注意模块都是对特征图的空间维度进行操作, 将网络通过通道注意模块后划分为2个全局分支, 分别用于提取空间注意特征图与自注意特征图, 如图4虚线部分, 将这样包括多个注意模块的区域称作联合注意模块(Joint Attention Module, JAM).由于自注意模块通常需要一个较大的接收域, 用于捕捉远距离依赖, 将整个联合注意模块加入基础架构的res_conv_3进行注意学习.具体而言, 基础架构在经过res_conv_3后得到特征图F, 将F直接送入CBAM-Pro的通道注意模块, 进行通道注意加权后得到输出特征图Fc.然后网络被划分为2个不同的全局注意分支, 2个分支分别包含空间注意模块与自注意模块, 将Fc送入2个分支后, 得到各自的注意特征图Fs、Fn, 经过余下的卷积层后, 2个分支的特征图再分别使用全局平均池化(Global Average Pooling, GAP)处理后, 经过包含1× 1卷积、批标准化(Batch Normalization)与ReLU激活的降维层, 得到2个256维的独立注意全局特征.除此之外, 在2个特征经过GAP处理后, 将其沿通道维度连接, 再通过相同的降维处理后得到256维的融合注意全局特征.
由于自注意会通过建立每个像素的远程连接以获取注意, 而局部特征划分后成为单独的局部区域, 如果在局部特征的网络构造路径中使用自注意模块, 会在提取特征时丢失注意关联的像素, 因此只在空间注意模块后划分2个局部特征分支, 分别用于提取划分为2、3块的局部特征.同时为了保证局部特征具有适当的接收域, 局部特征分支的res_conv_5未使用下采样操作.当通过res_conv_5并划分各自的局部特征图后, 对每个得到的局部特征图使用全局最大池化(Global Max Pooling, GMP).与全局特征图使用GAP不同, 在局部特征图使用GMP更有利于挖掘最具鉴别性的局部特征.再通过相应的降维层得到各个256维局部特征.最后, 将全局特征及局部特征按照通道维度连接, 得到最终的包含多类型特征的行人鉴别特征.
在网络训练阶段, 使用交叉熵损失与难样本采样三元组损失[9]训练模型.对所有的256维特征使用交叉熵损失优化分类任务, 对于每个批次中的特征fi, 交叉熵损失定义为
Lsoftmax=-
其中, C为数据集中类的数量, W为对应类的权值向量, N为实验批次大小.注意, 类似于MGN[12], 实验中采用的交叉熵损失函数放弃偏置项.
对所有的全局特征使用三元组损失以优化度量.除此之外, 考虑到局部特征也被加入到最终的行人判别特征中用于识别行人, 由于每个局部特征的相似性并不一致, 连接后会导致特征的识别产生一定偏差, 而每个局部特征是由相应的全局特征划分而来, 如果对每个局部特征使用三元组损失进行优化, 不仅会大幅提升优化复杂度, 而且会因为局部的对齐问题使优化得不到理想效果.为了解决这一问题, 将连接从同一个全局特征获得的局部特征, 得到一种新的特征, 称作局部连接特征.对局部连接特征也进行三元组损失优化度量, 有助于在测试阶段汇聚相同身份行人的最终特征.实验中难以实现样本采样三元组损失[9], 每个训练批次随机采样P个行人身份的K幅图像.对于每个批次, 选取相对于锚身份的距离最远的正样本与距离最近的负样本, 构建正负样本对进行训练:
Ltriplet=-
其中, f
L=β 1Lsoftmax+β 2Ltriplet,
其中, Lsoftmax为所有特征的交叉熵损失的和, Ltriplet为三元组损失的和, β 1、 β 2为平衡参数, 实验中分别设置β 1=2, β 2=1.
本文在行人重识别任务常使用的3个数据集, 即Marker-1501数据集[21]、DukeMTMC-reID数据集[22, 23]、CUHK03数据集[1]上进行实验.
Marker-1501数据集包括由6个摄像头拍摄到的1 501个不同身份的行人, 通过可变形部件模型(Deformable Parts Model, DPM)检测器生成包含单独行人的32 668幅图像.划分为不重叠的训练集和测试集.训练集中包含751个身份不同的行人的12 936幅图像, 测试集包含来自750个不同身份行人的3 368幅查询图像与19 732幅图库图像, 查询图像的检测框通过手工绘制, 确保测试结果的准确性.
DukeMTMC-reID数据集为DukeMTMC数据集的行人重识别子集, 使用8个摄像头采集得到, 其中包含1 812个行人身份的3 6411幅图像.图像中有1 404个行人出现在多于2个摄像头下, 通过随机采样将这1 404个行人的图像划分为训练集与测试集, 分别包含702个行人的图像, 其余408个行人只出现在1个摄像头下, 将他们的图像也加入到测试集的图库中作为干扰.训练集包含16 522幅图像, 图库包含1 7661幅图像, 查询集包含2 228幅图像.
CUHK03数据集包括1 467个行人的14 097幅图像, 每个身份由2个不同的摄像头进行采集.其中有767个身份的图像用于训练, 另外700个身份的图像用于测试.数据集提供手工标注与检测器自动标注2种标注方式, 本文在2种标注的数据集上都进行实验.
实验采用首次成功匹配概率(Rank-1)及平均查准率(Mean Average Precision, mAP)评估实验结果.由于在匹配达到一定程度时, Rank-1的标准会达到饱和, 区分度不高, 所以本文更侧重于mAP的评估.
多类型特征网络中采用直接划分的方法, 用于提取局部特征, 所以实验遵循PCB的设置, 在训练阶段将输入图像大小调整为384× 128.再采用随机水平翻转、标准化及随机擦除进行数据增强.测试时也将图像调整为384× 128, 并且只进行标准化处理.
网络的基础架构采用在ImageNet数据集[24]上预训练的ResNet50, res_conv_3之前网络模型共享参数, 之后模型引入联合注意模块, 通过通道注意模块后, 划分为自注意分支与空间注意分支, 经过空间注意模块后又划分为包含1个全局分支和2个局部分支的子分支, 网络中划分的所有分支并行训练.注意到, 模型中res_conv_3后的所有分支都使用ResNet50的res_conv_3之后对应层的预训练权重进行初始化.
实验批次大小设置为32, 随机从训练集中采样P=8个身份, 并从每个身份中采样K=4幅图像.网络使用Adam优化器进行训练, 初始学习率设置为3× 10-4, 一共训练250个周期.当训练进行到150个和230个周期时, 学习率分别下降至3× 10-5与3× 10-6.三元组损失的margin设置为1.2.测试评估时, 遵照MGN, 取原始图像特征与水平翻转图像特征的平均以得到最终特征.
本节将多类型特征网络(MTFN)在3个基准数据集上的结果与近期方法进行对比.具体而言, 将对比方法分为如下3类.
1)使用注意机制的方法:DuATM[18], HACNN[19], 掩膜引导的对比注意模型(Mask-Guided Con-trastive Attention Model, MGCAM)[25], 具有课程式采样的多任务注意网络(A Multi-task Attentional Network with Curriculum Sampling, Mancs)[26], 搜寻局部感知的卷积神经网络(Searching for a Part-Aware ConvNet, Auto-ReID)[27].
2)基于划分局部特征的方法:PCB[11], PCB+精细局部池化(Refined Part Pooling, RPP)[11], MGN[12], 增强对齐网络(Enhancing Alignment Net-work, EANet)[14], 一致注意的孪生网络(Consistent Attentive Siamese Networks, CASN(PCB))[28].
3)其它先进的方法:相似性引导图神经网络(Similarity-Guided Graph Neural Network, SGGNN)[29], 用于行人重识别的人类语义分析(Human Semantic Parsing for Person Re-identification, SPReID)[30], 交互聚合网络(Interaction-and-Aggre-gation Network, IANet)[31], 类激活图增强模型(Class Activation Maps Augmentation, CAMA)[32], 批处理DropBlock模块(Batch DropBlock, BDB)[33].为了保证实验对比的公平性, 各方法都未使用重排序方法.
各方法在Market-1501、DukeMTMC-reID数据集上的性能对比如表1所示.
| 表1 各方法在2个数据集上的性能对比 Table 1 Performance comparison of different methods on 2 datasets % |
由表1可知, 本文方法性能更优.性能优秀的Auto-ReID在2个数据集上的mAP值分别提升2.95%和4.64%, Rank-1值分别提升0.90%, 1.00%.在基于划分局部特征的方法中, MGN仍处于优势地位, 本文方法仅在Market-1501数据集上的Rank-1值略低于MGN, 而在其余指标上都优于MGN, 特别是在mAP值上, 相比MGN, 在2个数据集上分别提升1.15%和1.34%.相比BDB, MTFN在2个数据集上的mAP值分别提升1.35%和3.74%, Rank-1值分别提升0.10%和0.50%.
各方法在CUHK03数据集上的性能对比如表2所示.现有的方法如Auto-ReID、BDB在CUHK03两种标注集上都取得优秀结果.EANet在检测标注集上也有较好性能.在这2种标注集上, MTFN更优.相比性能最优的BDB, MTFN在CUHK03-Labeled数据集上的mAP值和Rank-1值分别提升0.84%和0.10%, 在CUHK03-Detected数据集上, mAP值和Rank-1值分别提升0.67%和0.81%.值得注意的是, MGN在Market-1501、DukeMTMC-reID数据集上表现出色, 但在CUHK03数据集上却表现不佳.相比之下, MTFN在3个数据集上都有良好表现.
| 表2 各方法在CUHK03数据集上的性能对比 Table 2 Performance comparison of different methods on CUHK03 dataset % |
在Market1501数据集上分析CBAM-Pro的邻域参数k.为了消除其它方法带来的影响, 使用单路全局特征模型作为基线(Baseline).实验中分别对比6组设置:基线实验, 基线加上CBAM, 基线加上设置不同邻域参数k的CBAM-Pro, 具体实验结果如表3所示.由表可知, 加入CBAM的Baseline在mAP值和Rank-1值上都有提升.在此基础上, 把设置参数k不同的CBAM-Pro加入Baseline, 可发现无论k值如何变化, 方法结果始终优于只加入CBAM的方法, 这验证CBAM-Pro改进的有效性.
| 表3 k变化时各方法的性能对比 Table 3 Performance comparison of methods with different k % |
除此之外还可看到, 随着k值的变化, mAP值和Rank-1值均在k=7时达到最优结果.由ECANet可知, k值的选取与方法及特征图通道数都有一定的关系, ResNet50对于较大的k值具有更优的性能, 而本文使用此模型的特征图通道数为512, 通过ECANet提出的自动计算k值的方式得到k=5.由此可知, 在2个因素的共同作用下, k=7时模型取得最优结果是合理的.
本文的多类型特征网络中包含提取局部特征的分支.直接水平划分局部特征的典型代表方法有PCB和MGN, 在实验中选取这两种结构的划分方式进行实验.表4为各方法在2个数据集上的第1组实验结果, 实验对比这2种包含不同划分局部特征方法的网络模型.在表中, Baseline1包含1个全局分支与1个局部分支, 局部分支按照PCB的形式划分为6块.Baseline2包含1个全局分支与2个局部分支, 局部分支按照MGN的形式分别划分为2、3块.
| 表4 各方法在2个数据集上的消融实验结果对比 Table 4 Comparison of ablation experiment results of methods on 2 datasets % |
由表4可知, 选用MGN划分为2、3分支的模型架构可得到更优结果.由此可看出单纯的提取全局特征与局部特征, 而没有局部感受野的连续跨度变化对于识别相对而言是不利的, 这也验证连续的多粒度划分结构提取的局部特征用于鉴别行人更具优势.
从本文方法可看到, 网络中使用JAM, 模块中不仅包括CBAM-Pro, 同时也集成自注意机制, 用于提取不同关注的空间特征信息.为了证明JAM的效果, 在2个数据集上进行2组实验.首先在单路全局特征模型Baseline上进行实验, 分别在模型中加入CBAM-Pro与JAM, 这样可在排除局部特征影响的情况下单独验证JAM的效果.再在包含2, 3块局部特征的Baseline2上进行对比, 得到JAM对于最终模型效果提升的验证.表4也给出具体实验结果.由表可看到, 无论在哪个模型上, JAM都具有更优性能.
同时, 为了证明2种注意机制关注的差别, 使用梯度加权类激活图(Gradient-Weighted Class Acti-vation Mapping, Grad-CAM)[34]可视化2种注意机制的热图.使用空间注意机制和自注意机制可视化热图结果如图5所示.由图可看到, 空间注意机制的关注特性是高亮的一整块局部区域, 这也验证空间注意机制使用Sigmoid激活凸显图像最具鉴别力的信息位置的事实.自注意机制的热图凸显受关注的局部像素, 可看到长距离依赖使注意集中在人体中有一定联系的位置, 这些位置都较相似.由直观分析也可看到, 不同注意机制的联合使用是有意义的.
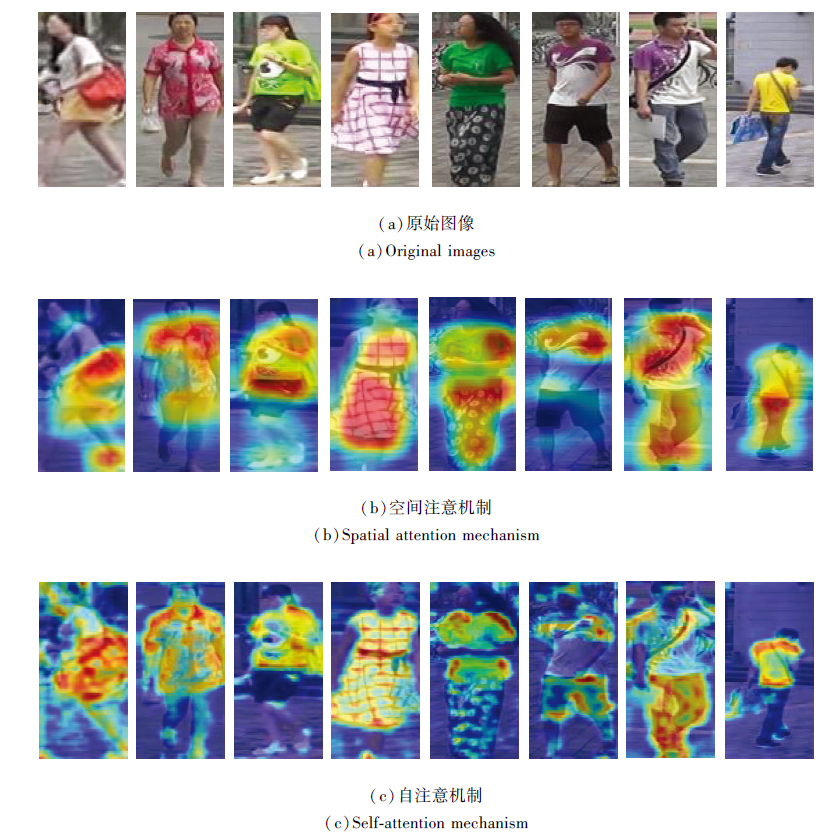 | 图5 注意力机制可视化热图Fig.5 Heatmap of attention mechanism visualization |
本文首先改进卷积块注意模型, 在此基础上结合改进的卷积块注意模型与自注意模型, 得到可提取不同关注特征的联合注意模块.基于此种情况, 针对行人重识别任务, 使用联合注意模块并引入局部分支, 设计可使最终行人鉴别特征包含多类型特征(不同关注的全局特征, 不同粒度的局部特征)的网络架构, 实验结果表明网络模型在行人重识别任务的通用数据集上取得较优性能.当然, 模型也因为划分的多条路径变得相对复杂.下一步的改进方案着眼于精简模型, 尝试以不同的方式引入特征的多粒度性, 在尽量使模型轻量的情况下, 精度得到更好提升.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|