

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
引入通道注意力和残差学习的目标检测器
[储珺1  , 朱晓阳
, 朱晓阳1 , 冷璐1 , 缪君1 ]
, 朱晓阳, 冷璐, 缪君]
|
|



作者简介:

朱晓阳,硕士研究生,主要研究方向为计算机视觉、目标检测.E-mail:1780139762@qq.com.

冷 璐,博士,副教授,主要研究方向为图像处理、生物特征模板.E-mail:leng@nchu.edu.cn.

缪 君,博士,副教授,主要研究方向为计算机视觉、3D重建、模式识别.E⁃mail:453360695@qq.com.
现有目标检测器特征金字塔无法充分利用不同尺度特征图的特征信息,不适用于低分辨率图像的目标和小目标的检测.针对此问题,文中提出引入通道注意力机制和残差学习块的目标检测器.首先引入通道全局注意力机制,通过网络学习特征图中不同通道特征的权重,增强有效的全局特征信息.然后采用轻量级的残差块,突出特征的微小变化,提高低分辨率图像中小目标的检测性能.最后在用于预测的浅层特征图中融合深层特征,提高小目标的检测精度.在标准测试数据集上的实验表明,文中目标检测器适用于低分辨率图像,对小目标的检测效果较优.
AboutAuthor:
ZHU Xiaoyang, master student. Her research interests include computer vision and target detection.
LENG Lu, Ph.D., associate professor. His research interests include image processing and biometric template.
MIAO Jun, Ph.D., associate professor. His research interests include computer vision, 3D reconstruction and pattern recognition.
The feature information of feature maps of different scales cannot be fully utilized by the existing feature pyramid of target detectors, and these detectors are not suitable for the detection of low-resolution image targets and small targets. To solve this problem, a target detector with channel attention mechanism and residual learning block is proposed. Firstly, the channel global attention mechanism is introduced to learn the weights of different channel features in the feature map through the network and thus the global feature information is enhanced effectively. Then, lightweight residual blocks are exploited to highlight small changes of features and improve the detection performance for small targets in low-resolution images. In addition, deep features are merged into the shallow feature maps for prediction to improve the detection accuracy of small targets. The experimental results on standard test datasets show that the proposed target detector is suitable for low-resolution images and obtains a better detection result for small targets.
本文责任编委 兰旭光
Recommended by Associate Editor LAN Xuguang
目标检测是计算机视觉领域的重要研究方向, 本质是从图像中检测不同尺度、类别的物体, 并给出不同类别物体的预测位置[1].目标的多尺度变换、输入图像的分辨率较低和目标尺寸过小是目标检测任务的主要问题[2].
针对目标的尺度变换这个难点, 近年来的研究主要采用两种策略.1)图像金字塔方法[3, 4, 5].输入经过一系列尺寸调整的图像副本, 生成具有语义代表性的多尺度特征.使用特征分别产生预测, 共同给出最终的检测结果.2)特征金字塔方法[6, 7, 8].输入单一尺度的图像, 从网络的特定层中提取特征金字塔检测目标.相比图像金字塔方法, 特征金字塔方法需要的额外内存和计算成本更低, 可以在训练和测试阶段同时应用, 并且特征金字塔结构容易修改, 便于与其它任务结合.
单步多边框检测器(Single Shot MultiBox-Detec-tor, SSD)[6]在全卷积神经网络中构建多级特征金字塔, 使用不同分辨率的6个特征层预测处理不同尺度的物体.浅层特征检测最小尺寸的目标, 较深层的特征检测相对较大的目标.Fang等[9]结合图像金字塔和特征金字塔, 生成特征表达能力更强的特征图用于预测, 有利于小目标检测.算法在位置预测时进行相应微调, 在不影响大目标检测的情况下, 加大小目标的权重, 保留小目标的特征, 利用残差网络(Residual Network, ResNet)取得一定效果.Lin等[10]开发具有横向连接的自顶向下的网络结构, 在所有尺度上构建高级语义特征图, 结合低分辨率但强语义的特征和高分辨率但弱语义的特征, 预测检测层特征.Fu等[11]提出基于自顶向下的网络结构, 加入反卷积进行上采样, 并在预测阶段引入残差元素, 优化后用于候选框回归和分类任务特征图.Kong等[7]使用反向连接融合不同尺寸的特征图.Zhou等[12]利用密集连接卷积网络(Dense Convolu-tional Network, DenseNet)[13]最后一个密集块, 通过池化和尺度变换层构建特征金字塔.Zhang等[8]采用传输连接块自顶向下融合深层和浅层, 构建特征金字塔, 将锚框细化模块(Anchor Refinement Mo-dule, ARM)中的特征和细化后的默认框传输到目标检测模块(Object Detection Module, ODM)中, 预测位置、大小和类别标签, 检测效果较高, 对小目标的检测有效.Zhang等[14]添加语义分割分支, 丰富底层特征的语义.Zhao等[15]提出使用多层次的特征金字塔网络(Multi-level Feature Pyramid Network, MLFPN), 构造有效的特征金字塔, 融合主干网络提取的特征.该模型采用细化U型模块(Thinned U-shape Module, TUM)和特征融合模块(Feature Fusion Mo-dule, FFM)提取具有代表性的多层次多尺度的特征, 使用尺度特征聚合模块(Scale-Wise Feature Aggregation Module, SFAM)融合多级特征, 得到多级特征金字塔, 用于最终阶段的预测, 但在速度上有大幅下降.Li等[16]设计特征聚合模块(Feature Aggregation Module, FAM), 融合浅层和深层特征, 同时使用两个连续的残差结构作为浅层特征的增强模块(Shallow Feature Enhancement, SFE), 将原始SSD的卷积层更换为3个深层特征增强层(Deep Feature Enhance, DFE), 提高小目标检测精度和速度.
虽然上述具有特征金字塔结构的目标检测器取得不错的检测效果, 但是它们在构建特征金字塔时仅考虑特征的局部信息, 未考虑全局信息, 并以固定尺度的方式构造特征金字塔, 在低分辨率图像的目标检测和小目标检测方面存在一定的局限性.
因此, 在SSD目标检测器的基础上, 本文提出引入通道注意力机制和残差学习块的目标检测器(Target Detector with Channel Attention and Residual Learning, CARLDet), 构建通用的全局特征增强模块(Global Feature Enhancement Block, GFE), 增强特征图中的全局信息和局部信息.融合具有丰富语义信息的深层特征和高分辨率的浅层特征、经过全局特征模块增强后的中层特征和浅层特征, 构建轻量级的特征融合模块(Feature Fusion Block, FFB).结合上述两个模块, 构建轻量级、特征表达能力较强的特征金字塔结构, 提高低分辨率图像目标和小目标的检测精度.
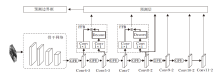
CARLDet目标检测器以SSD为基础, 引入6个全局特征增强模块(GFE)和2个特征融合模块(FFB).其中5个用于增加SSD目标检测器中用于预测的Conv4-3层到Conv10-2层的特征表达能力, 1个增强中层特征Conv5-3.Conv11-2层的特征图大小仅为1, 增强过低分辨率的特征图不能改善检测效果, 反而会降低检测速度.FFB模块融合预测小尺寸物体的Conv4-3层和增强后的中层Conv5-3层特征图, 同时融合Conv7层和Conv8-2层特征, 提高小目标检测精度.考虑到平衡提升检测精度和检测速度, 选择只增加2个FFB模块, 通过实验验证, 最终选择如图1所示的网络结构.
 | 图1 整体网络结构图Fig.1 Global network structure |
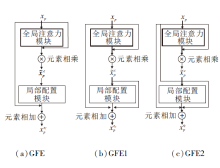
GFE模块的内部结构如图2所示, 由通道全局注意力(Global Attention)模块和局部配置(Local Configuration)模块组成.
 | 图2 GFE结构图Fig.2 GFE structure |
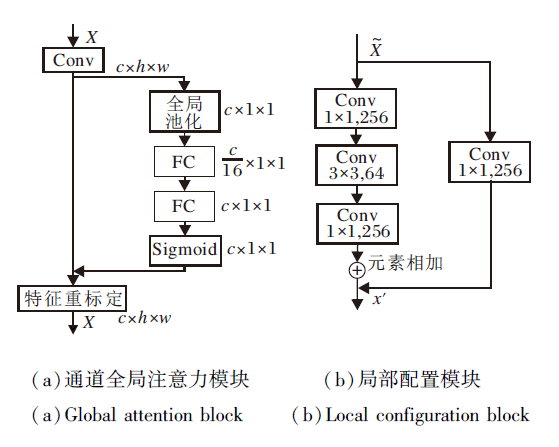
受挤压和激励网络(Squeeze-and-Excitation Net-works, SENet)[17]启发, 本文的通道注意力模块采用SENet提出的Squeeze-and-Excitation block作为基础模块.该模块包含压缩和激励两个操作, 网络结构如图2(a)所示.
用于预测的特征层输出标记
Xpred={
其中p=23, L为基础网络的最后一层.对于p层, 压缩操作指在输入维度为W× H× C的
其中,
激励操作指对全局信息
其中:W1∈
其中⊗为元素相乘操作.经过重新标定后的特征图为
通道全局注意力模块有助于提高特征的可辨别性, 并在全局范围内选择更有效的信息, 增强用于预测的每层特征金字塔的表达能力.
He等[18]提出的残差网络引入跳跃连接, 将卷积层拟合一个潜在的恒等映射函数(H(x)=x)的任务转变成学习一个残差函数(F(x)=H(x)-x).残差网络的本质是一个通用函数逼近器[19], 通过网络训练, 可去除特征中相同的主体部分, 突出它们之间微小的变化.因此本文采用He等[18]提出的残差块, 构建局部配置模块, 通过反向传播进行训练, 更细化局部特征.
本文的残差块和残差网络中提出的残差块存在一些差异.1)因为语义信息一般分布在特征层次中, 因此本文的局部配置模块目的是优化附加的通道信息, 提升检测精度.残差网络学习的目的是通过加深网络提高精度.2)本文在通道注意力模块后使用残差块, 本文残差块的输入是全局增强后的特征.残差网络的输入是经过一层卷积后的特征.3)为了保留经过通道注意力模块增强的特征通道信息的有效性, 局部配置模块中跳跃连接卷积核的通道数和经过全局特征增强后的卷积通道数相同.另外, 为了降低参数量, 对于恒等映射的残差块, 第1个尺度为1的卷积核的通道数设置为128, 第2个尺度为3的卷积核的通道数设置为256, 第3个尺度为1的卷积核的通道数与跳跃连接的卷积核尺度相同, 便于将其与跳跃连接卷积核进行元素相加, 即对应元素相加操作.局部配置模块的网络结构如图2(b)所示.
除上述GFE模块以外, 本文还设计另外2种GFE模块的结构, 即图3(b)、(c)所示的GFE1模块和GFE2模块.GFE1模块将得到的全局特征
 | 图3 GFE模块结构图Fig.3 Structure of GFE module |
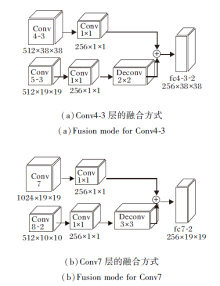
现在通用的特征融合方式主要是对检测层进行融合, 本文考虑使用非预测层的中间层进行融合.本文的特征融合模块(FFB)结构如图4所示.
 | 图4 FFB模块结构图Fig.4 FFB module structure |
因为Conv9-2层、Conv10-2层、Conv11-2层的特征图分辨率过低, 过低的分辨率特征的融合对检测精度提高不大, 反而降低检测速度, 所以未对这几层进行融合.Conv5-3层处于Conv4-3层和Conv7层中间, 和Conv7层分辨率相同, 但具有不同的语义信息, 所以本文分别对比Conv4-3层和Conv7层及Conv5-3层的融合效果.根据实验结果, Conv4-3层和Conv5-3层融合比Conv4-3层和Conv7层融合的检测精度均值(Mean Average Precision, mAP)提高0.3%, 所以本文采用图4(a)的融合方式.
与反卷积单步目标检测器(Deconvolutional Sin-gle Shot Detector, DSSD)采用的Top-Down融合方式不同, CARLDet采用尺寸为1的卷积核进行降维.再根据输入尺寸, 采用不同尺寸大小的反卷积进行上采样.反卷积不仅提升特征图的维度, 还可以对高层特征进行解码, 学习其中的语义信息.具体的融合方案和特征金字塔各层参数如表1所示.
| 表1 用于预测的特征金字塔各层参数 Table 1 Parameters of each layer of feature pyramid for prediction |
SSD由m个特征层参与检测, m=1, 2, …, 6, 每个特征图中默认框的尺寸为
Sn=Smin+
其中:n=1, 2, …, m, 为当前默认框编号; Smin为最底层的预测层默认框尺度, 取值为0.2; Smax为最高层默认框尺度, 取值为0.9.使用长宽比设置默认框大小, 长宽比
α r={1, 2, 3,
每个默认框的宽
高
当长宽比为1时, SSD增加一个默认框的尺度:
S'n=
默认框的大小直接决定预测图像中预测的物体尺寸, 所有默认框对应的检测框应尽可能覆盖整幅图像, 用于提升检测精度.除了Conv4-3层以外, 在其它层均使用6个尺度的预测框, 提高默认框的密度, 从而增加检测精度.因为Conv4-3层尺寸较大, 因此只使用3个尺度的默认框, 分别为0.1、1/2、2.
为了验证CARLDet目标检测器的有效性, 在PASCAL VOC 2007、VOC 2012、MS COCO数据集上进行实验, 对比300× 300和512× 512分辨率下的图像检测性能.
对比方法如下.1)SSD.2)以SSD为基础改进的一阶段的方法:DSSD, 尺度变换目标检测器(Scale-Transferrable Object Detection, STDN), 单步细化目标检测器(Single-Shot Refinement Neural Network for Object Detection, RefineDet), 特征聚集和增强的单步目标检测器(Single Shot Object De-tector with Feature Aggregation and Enhancement, FAENet).3)两阶段基于特征金字塔的方法:更快的基于区域的卷积神经网络(Towards Real-Time Object Detection with Region Proposal Networks, Faster R-CNN).
实验均基于重构的SSD, 实验使用2块GTX 1080Ti, 所有网络骨架都在ImageNet分类集上进行预训练, 并在检测数据集上进行微调.为了公平, 使用预先训练好的VGG-16模型和ResNet模型作为骨干网络, 并以Tensorflow作为深度学习框架进行训练.
实验1 各方法在PASCAL VOC数据集上的性能对比
PASCAL VOC挑战赛[19]是视觉对象的分类识别和检测的一个基准测试, 提供用于训练模型的训练集和评估模型的测试集, 包含20个类别.实现细节如下:所有模型都是使用VOC 2007、VOC 2012训练集进行训练, 在VOC 2007数据集上进行测试, 使用300× 300、512× 512分辨率的图像作为输入, 训练共迭代120 000次, 其中前1 000次学习率为10-4, 1 000~80 000次学习率为10-3, 80 000~100 000次学习率为10-4, 100 000~120 000次学习率为10-6.训练中默认的批处理大小为32, 其它参数和SSD一样.对于VOC 2012数据集, 遵循VOC 2007数据集的设置, 但有一些不同.训练数据集使用VOC 2007训练数据集和测试数据集, 以及VOC 2012训练数据集, 使用VOC 2012测试集进行测试.
表2为各方法在PASCAL VOC测试集上的检测结果, 其中CARLDet300* 和CARLDet512* 表示骨干网络为ResNet-101.由表可看出, 在VOC 2007测试集上, 输入图像大小为300× 300时, 以VGG-16为骨干网络的方法的检测性能与RefineDet和FAENet性能接近, 高于其它对比算法.当输入图像大小为512× 512时, CARLDet目标检测器mAP值高于其它对比算法, 比当前性能最优的单阶段目标检测器RefineDet低0.2%, 但检测速度高于RefineDet, 达到29帧/秒.骨干网络VGG-16替换为ResNet-101时, 不论是300× 300还是512× 512的输入图像尺寸, CARLDet目标检测器均达到最高的mAP, 分别为80.4%和83.2%.
| 表2 各方法在PASCAL VOC测试集上的检测结果 Table 2 Detection results of different methods on PASCAL VOC test set |
由表2还可看出, 在VOC 2012测试集与VOC 2007测试集上具有相同的性能趋势, 无论输入图像尺寸为300× 300还是512× 512, CARLDet目标检测器结果最优, 包括RefineDet.结果表明CARLDet目标检测器的有效性, 特别是对于较复杂的场景.
表3为各方法在VOC 2007数据集上的mAP值.由表可看出, 当输入图像大小为300× 300时, CARLDet目标检测器的mAP值达到最高, 为80.4%, 在20个类别中有7个类别物体的mAP值最优.RefineDet与CARLDet目标检测器相同, 也是针对7个类别的mAP值最优.特别是在其中检测难度最大的boat、bottle类别上达到最佳效果, 充分说明CARLDet目标检测器在低分辨率图像上的检测效果最佳, 在尺度变化大的物体和小目标检测上的有效性.
| 表3 各方法在PASCAL VOC 2007测试集上的mAP值对比 Table 3 mAP value comparison of different methods on PASCAL VOC 2007 test set % |
实验2 各方法在MS COCO数据集上的性能对比
MS COCO数据集[21]包含80个对象类别, 相比PASCAL VOC数据集, 目标种类更多, 场景更复杂, 包含更多小目标.为了进一步验证CARLDet目标检测器的性能, 本文使用35 000幅验证数据集联合训练, 使用MS COCO数据集训练好的SSD300作为预训练模型.由于MS COCO数据集比PASCAL VOC数据集包含更多的小目标, 使用更小尺寸的默认框效果会更好, 实验中将最小尺寸从0.2改为0.15, 测试结果提交到测试集的评估服务器.输入大小为300× 300时批处理大小设置为32, 输入大小为512× 512时批处理大小为12, 学习率初始为2× 10-3.先将数据集整体以初始学习率训练5轮, 在第80轮和第110轮分别缩小为1/10, 总共训练140轮.
表4为各方法在MS COCO测试集上的平均精度(Average Precision, AP), 其中:AP50指IoU=0.50, 即VOC数据集标准; AP75指IoU=0.75, 为更严格的标准; APS为对于目标面积低于32× 32的目标检测效果; APM为对于面积在32× 32和96× 96之间的目标检测效果; APL为对于面积在96× 96以上的目标检测效果.
| 表4 各方法在MS COCO测试集上的AP值对比 Table 4 AP value comparison of different methods on MS COCO test set |
由表4可看出, 当输入图像为300× 300时:CARLDet目标检测器以VGG-16为骨干网络的AP值高于其它用于对比的目标检测器, 仅比RefineDet低0.9%; 小目标的AP值比RefineDet高0.9%, 超过其他用于对比的目标检测器.当输入为512× 512时, CARLDet目标检测器的小目标AP值比SSD提高5.2%, 但比RefineDet降低0.2%, 说明CARLDet目标检测器对低分辨率图像和小目标的检测具有更好的检测效果.使用分类效果更好的ResNet-101作为骨干网络, 可以更好地发挥CARLDet目标检测器的全局特征增强模块和特征融合模块的作用, 进一步提高CARLDet目标检测器的检测性能, CARLDet300的AP值达到32.7%, CARLDet512的AP值达到36.7%, 结果最优.
图5为SSD与CARLDet目标检测器的可视化效果.图中不同颜色的检测框为网络检测目标.观察图5发现, SSD容易漏检远处的小目标、密集的目标和遮挡目标, CARLDet目标检测器可较好地解决这些问题.上述实验表明, CARLDet目标检测器对小目标具有更高的检测精度.
 | 图5 SSD与CARLDet检测效果对比Fig.5 Comparison of detection results of SSD and CARLDet |
为了评估CARLDet目标检测器不同模块的有效性, 在SSD框架下构建6种变体进行消融研究.所有实验均在PASCAL VOC 2007测试集上测试, 使用PASCAL VOC 2007和PASCAL VOC 2012训练集训练, 训练参数与CARLDet目标检测器相同, 实验结论如下.
Only Global是基于SSD的基础网络结构, 在检测层只使用经过全局注意力模块的全局特征.相对SSD(mAP值为77.50%), only Global的mAP值为76.53%, 下降1%.这说明使用全局注意力模块确实可获得全局信息, 抑制无用信息, 但是只使用全局信息进行检测, 会丢掉细节信息.
SSD+Global为将得到的全局信息加到原先检测层的特征中, mAP值为78.54%, 相比SSD, 有1%的提升, 表明本文使用的全局信息有效.
SSD+GFE1是在SSD的基础网络结构中, 用于检测的特征金字塔的每层前加入GFE1模块(除Conv11-2), 精度达到78.43%, 提升接近1%.
SSD+GFE2是在SSD的基础网络结构中, 用于检测的特征金字塔的每层前加入GFE2模块(除Conv11-2), 精度达到78.35%, 和GFE1模块的提升效果接近.
SSD+GFE是在SSD的基础网络结构中, 用于检测的特征金字塔的每层前加入GFE模块(除Conv11-2), 精度达到78.77%.相比GFE1模块和GFE2模块, GFE模块效果更优.
SSD+GFE+2FFB为得到最优效果的SSD+GFE形式的网络结构中, 再加入2个FFB模块, 精度达到80.04%, 结果最优, 表明本文FFB模块的效果显著.
为了验证GFE模块和FFB模块的通用性, 在两阶段目标检测器Faster R-CNN[21]框架下, 添加GFE模块和FFB模块.为了对比公平, 本文分别以ResNet-50和ResNet-101为骨干网络重构Faster R-CNN.各种模块的mAP值如表5所示, 其中Faster R-CNN(本文)为Faster R-CNN使用Tensorflow框架的重现.
| 表5 Faster R-CNN中各种模块的有效性实验结果 Table 5 Effectiveness experiment results of different modules in Faster R-CNN % |
以ResNet-50为骨干网络的Faster R-CNN和以ResNet-101为骨干网络的Faster R-CNN添加GFE模块和FFB模块具有相似效果, 本文以效果更好的ResNet-101为骨干网络的Faster R-CNN为例做如下说明.
1)Faster+Global.在表5中, 本文重构以ResNet-101为骨干网络的Faster R-CNN, 获得的mAP值为78.9%, 加入全局信息提高mAP值到79.6%, 相比Faster R-CNN, 提高0.7%, 说明全局注意力模块的有效性, 结合全局信息可提高检测精度.
2)Faster+GFE.在重构的Faster R-CNN目标检测器中加入本文构建的通用的GFE模块, 即在Faster+Global的基础上再加入细化后的局部信息, mAP值为80.7%, 相比Faster R-CNN, 提高1.8%, 充分说明GFE模块的通用性和有效性.
3)Faster+GFE+FFB.在重构的Faster R-CNN目标检测器中加入本文构建的通用的GFE模块和FFB模块, mAP值提高到81.6%, 相比Faster R-CNN, 提高2.7%.
实验结果表明, 本文构建的GFE模块和FFB模块对于两阶段的目标检测框架也有较优的检测效果, 具有较强的通用性.
考虑提高用于检测小目标的Conv4-3层和Conv7层的语义信息, 对比3种融合方案:Conv4-3层和Conv7层融合、Conv4-3层和Conv7层融合、Conv7层和Conv8-2层融合.对比对应元素相加和特征图堆叠两种融合方式.在VOC 2007测试集上进行测试, 结果如表6所示.由表可看出, Conv7层和Conv8-2层采用对应元素相加操作方式的融合效果最优.
| 表6 不同特征融合方式的mAP对比 Table 6 mAP comparison of different feature fusion methods |
在特征金字塔结构中如何充分利用特征的全局信息和局部信息是提高检测精度的关键问题.针对此问题, 本文提出引用通道注意力和残差学习的目标检测器(CARLDet).结合特征全局信息和局部信息的特征金字塔嵌入在SSD和Faster R-CNN的目标检测框架中, 提高目标检测精度, 特别是低分辨率图像和小目标的检测精度.在特征金字塔结构的全局特征增强模块中, 引入通道注意力和残差学习, 分别增加特征的全局和局部信息, 提高特征金字塔表达能力, 可方便地与其它任务结合.本文将经过全局增强的中层特征和浅层特征使用特征融合模块进行融合, 将高层语义信息融入浅层特征, 大幅提升小目标检测精度.在PASCAL VOC、MS COCO数据集上的实验表明, CARLDet目标检测器对低分辨率图像和小目标的检测效果更优.特征金字塔可提高特征的表达能力, 但对多尺度效果检测不理想, 下一步工作是进一步研究如何自适应融合不同的尺寸特征.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|