
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
融合多维空洞卷积算子和多层次特征的深度网络检测算法
[张新良1  , 谢恒
, 谢恒1 , 赵运基1 , 王琬如1 , 魏胜强1 ]
, 谢恒, 赵运基, 王琬如, 魏胜强]
|
|



作者简介:

张新良,博士,副教授,主要研究方向为智能控制、检测技术、自动化装置等.E-mail:zxldq@hpu.edu.cn.

谢 恒,硕士研究生,主要研究方向为模式识别、数字图像处理.E-mail:708998966@qq.com.

王琬如,硕士研究生,主要研究方向为模式识别、数字图像处理.E-mail:870925329@qq.com.

魏胜强,硕士研究生,主要研究方向为模式识别、数字图像处理.E-mail:963306062@qq.com.
在基于深度网络的目标检测模型中,仅利用串行的卷积操作,模型会缺少描述网络不同层次的细节信息和特征图全局信息的能力,减弱小目标的检测能力,影响检测精度.基于残差网络结构,文中提出融合多维空洞卷积(MDC)算子和多层次特征的深度网络检测算法.首先设计MDC算子,卷积核具有5种不同的感受野,可获取8种不同语义的特征图,并引入串行网络的特征提取环节,构造特征层.再通过转置卷积操作实现检测层升维,用于级联不同层次的特征层,得到检测层并保证能在最大程度上保留目标的原始特征.最后使用非极大抑制完成检测算法的构建.实验表明,文中算法有效提高目标平均检测精度和小目标的检测能力.
AboutAuthor:
ZHANG Xinliang, Ph.D., associate professor. His research interests include intelligent control, detection technology and automatic equipment.
XIE Heng, master student. His research interests include pattern recognition and digi-tal image processing.
WANG Wanru, master student. Her research interests include pattern recognition and digital image processing.
WEI Shengqiang, master student. His research interests include pattern recognition and digital image processing.
The exclusive usage of sequential convolution operation in the deep networks results in the lack of the target detailed information of feature layers and global characteristics. The detection performance for small objects and the detection accuracy are reduced. In this paper, a deep networks detection algorithm fusing multiple dilated convolution(MDC) operator and multi-level characteristics is proposed based on the residual network structure. The convolution kernel is composed of 5 different receptive fields and 8 different semantic feature maps can be generated. The MDC operator is introduced into the feature extraction block to build a new feature layer. The transposition convolution is employed to increase the dimension of the detection layer and make a collage of multi-level feature layers. Thus, the original features of the targets can be retained in the newly generated detection layer to the most extent. Finally, the detection model is constructed by the non-maximal suppression. The experimental results show that the proposed model with the multi-leveled features and MDC operator can effectively improve the mean average precision and detection performance for small targets.
本文责任编委 徐勇
Recommended by Associate Editor XU Yong
在计算机视觉领域, 目标检测得到广泛应用, 主要分为传统检测算法和深度学习目标检测算法.目前研究主要以深度学习目标检测算法为主[1, 2, 3], 如卷积神经网络(Convolutional Neural Network, CNN)等作为人工智能的新兴领域, 相比传统算法, 鲁棒性和准确性更优[4].
大量实验证实, 在基于CNN的检测模型中, 多层结构信息[5]可改善目标检测效果[6, 7, 8].Cai等[9]使用不同尺度的特征图构建检测层, 增加模型对目标尺度的适应性.Girshick等[10]利用选择性搜索算法(Selective Search)生成候选区域[11], 通过CNN提取特征, 提高支持向量机(Support Vector Machine, SVM)分类器的分类功能.Girshick[12]在R-CNN(Rich Feature Hierarchies for Accurate Object Dete-ction and Semantic Segmentation)的基础上增加感兴趣区域(Region of Interest, ROI)池化模块, 保持特征不变性, 结合softmax分类器进一步提高检测性能.Ren等[13]基于R-CNN, 使用区域生成网络(Region Proposal Network, RPN)[14]进行候选区域建议, 共享RPN和CNN, 在提升精度的同时减少计算量.
上述算法都是将多层结构信息按照串行顺序经由输出进行检测, 但未结合前后特征层次信息, 未对生成特征图进行全局特征联合, 卷积操作会带来特征损失, 导致在小物体检测方面检测精度较低.联合不同维的特征图有利于完善特征信息, 由此, Bell等[15]采用并行拼接的方式构建网络, 拼接4个特征层的信息作为新特征层.Cui等[16]在解决小目标检测精度的问题时, 利用反卷积升维融合不同层次的特征信息等, 在一定程度上实现不同维度特征层的联合, 提升检测精度.
特征层信息的完整性直接决定目标检测的最终精度.为了有效获取目标特征, 减少因不连续卷积导致的特征损失和语义信息丢失, 本文提出融合多维空洞卷积(Multiple Dilated Convolution, MDC)算子和多层次特征的深度网络检测算法, 简记为MDC模型(MDC Deep Network Model).利用MDC算子提取特征图全局信息, 结合相邻特征图构建检测层, 提升检测精度.
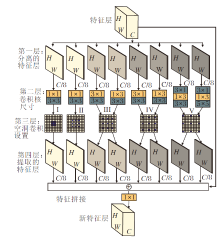
MDC算子如图1所示, 采用残差网络结构, 利用5种不同感受野的空洞卷积核分别提取原特征图信息.如图1第1层所示, 为了保证计算效率, 将原始特征层均分为8组.第2层分别使用横向和纵向异形卷积核提取方向特征, 在最大程度上保留单方向层次特征信息.第3层为不同感受野的卷积核, 感知不同范围的特征图, 根据特征图尺寸, 分别设置感受野尺寸为I~V, 其中较大感受野(III、IV、V)分别使用2组卷积核, 在横向和纵向分别提取特征, 形成2组方向不同但维度相同的特征图.考虑到在将空洞卷积增加至6层及以上时, 空洞卷积核会因超出特征图范围而无法计算, 因此, 采用5种不同尺度的空洞卷积核.最后, 将感知的8组特征图进行维度拼接与特征融合, 获取丰富的全局信息和细节信息.
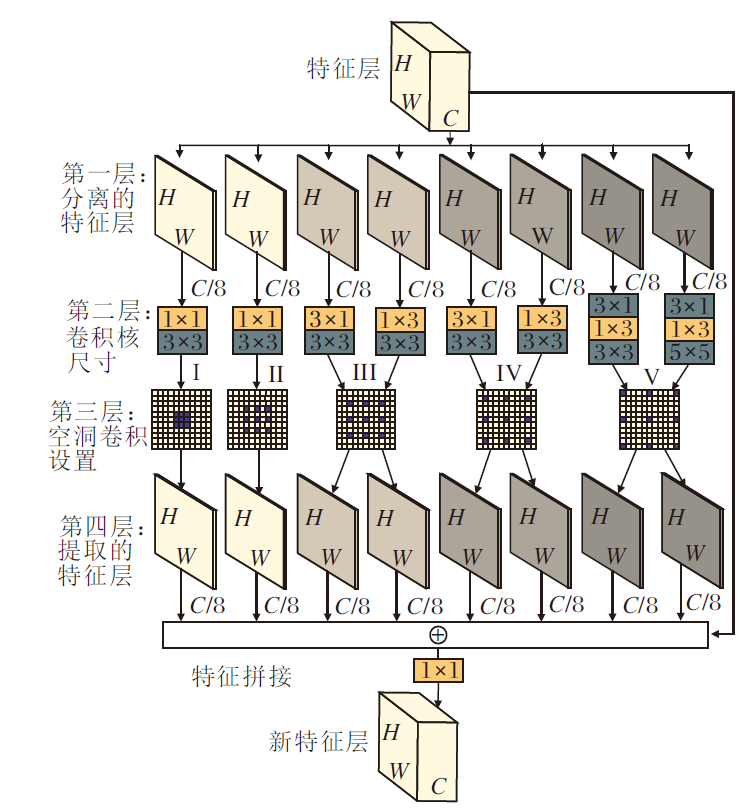 | 图1 MDC算子网络结构图Fig.1 Network structure map of MDC operator |
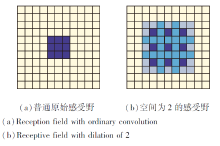
相比原始特征图, MDC算子通过5种不同的空洞卷积提取原始特征图信息, 由小到大不断提升空洞卷积核感知范围.感知范围增大, 信息量增加, 感知的全局信息更全面, 产生更具体的细节特征.如图2所示, 空洞卷积可在不改变卷积参数量的前提下, 提升卷积核的感受野, 获取特征图的不同范围信息.与以往多空洞卷积[17]不同, MDC算子使用多感受野空洞卷积获取特征图多个范围信息, 进一步融合感知特征, 使信息更丰富、全面.
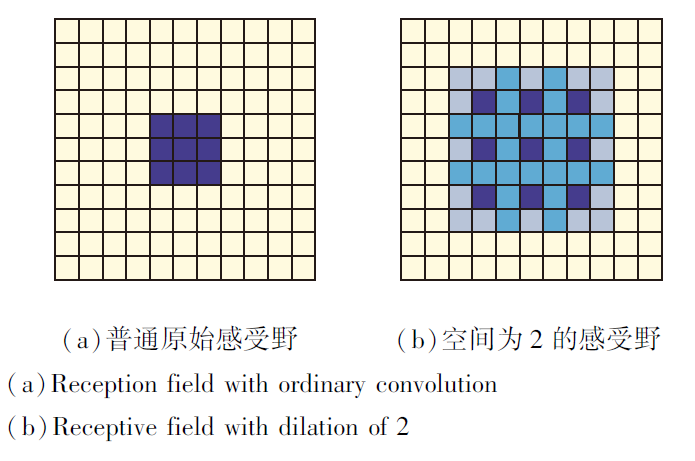 | 图2 空洞卷积感受野Fig.2 Receptive field of dilated convolution |
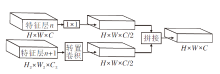
采用特征级联的方式连接相邻特征图不同尺度的信息, 如图3所示, 特征层n的原始输入特征图尺寸为H× W× C, 其中, H为特征图的长度, W为特征图的宽度, C为特征图维度.特征层输出经由一层卷积核大小为1× 1的卷积操作后, 通道数减至C/2.
 | 图3 特征级联过程Fig.3 Process of feature cascade |
在特征层n的相邻特征层n+1, 特征图原始尺度为H2× W2× C2, 通过转置卷积升维至H× W× C/2, 对于由
Y[a, c]=
描述的普通卷积操作, 转置卷积可描述为
其中, Y为普通卷积输出特征向量, 即转置卷积的输入向量, X1为向量化的普通卷积输入特征图, X2为转置卷积输出特征向量, B1、B2为向量化的卷积矩阵, [a, c]、[a, b]及[b, c]分别为对应矩阵的大小.
将n层和n+1层特征图输出在维度层次上拼接, 形成H× W× C的新检测层, 此时新检测层具有与原特征层n相同的维度.
同时, 在卷积过程中, 将对称卷积核n× n进行拆分, 分别使用异形卷积核n× 1和1× n对特征图进行纵向和横向卷积, 最大程度上保留原始信息.从而, 对于经MDC算子提取后的特征图, 通过残差网络结合原始特征层和多个空洞卷积特征层信息, 丰富原始特征和深层次语义特征.
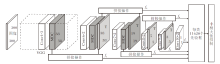
基于MDC算子, 构造MDC模型, 如图4所示.
 | 图4 MDC模型网络结构图Fig.4 Network structure of MDC deep network model |
MDC模型采用串行网络结构的端到端检测模式, 由VGG16(Visual Geometry Group 16)分类骨干网络和头网络组成.不同尺度和不同维度的特征层构成金字塔结构检测层, 使用单点多框方式形成长宽比不同的先验框, 对目标进行识别和分类.
MDC模型网络结构在SSD(Single Shot Multi-box Detector)网络基础上添加MDC算子, 在原始检测层的基础上使用MDC算子提取特征, 后使用转置卷积代替上采样进行升维, 不会产生因上采样导致的梯度化, 保证特征图的平滑性, 并将新特征图与上层检测层进行通道融合, 作为最终检测层.
图4中f1~f6表示最终检测层.在MDC特征提取块获取conv4-3、conv6-2、conv7-2层特征之后, 分别融合下一层的上采样信息构成f1、 f2、 f3.符号T表示对卷积层输出特征图的转置操作.f4、 f5、 f6为小尺度特征层, 不再使用MDC提取特征. f4融合当前层和下层特征图信息, f5和f6具有更小尺度和更深层次的信息, 直接由卷积后特征图构成.在检测层输出末端, 对形成的单目标多检测框使用非极大值抑制, 剔除无效及多余检测框.
在获取6层检测特征图后, 根据特征图尺寸采用单点多框方法设置先验框.大尺度的特征图包含的细节信息相对丰富, 小尺度的特征图在检测大物体时具有较优性能, 因此分别在f1~f6特征图上每点构造6, 6, 6, 6, 4, 4个先验框, 共生成11 620个先验框.
各个先验框的宽高呈现不同比例, 定义如下:
sk=smin+
其中:m ≠ 1表示特征图个数; k=1, 2, …, m; smin=0.2, smax=0.9, 表示先验框大小相对图像的比例.先验框的大小根据目标大小和不同的长宽比设计, 共有5种不同参数, 分别为1, 2, 3, 1/2, 1/3, 由特征图尺寸计算先验框尺寸, 分别为30, 60, 111, 162, 213, 264.
在匹配时, 先验框与真实目标(Ground Truth)的匹配由Jaccard系数决定:
J(A, B)=
设定阈值为0.5, 对高于阈值的先验框分配物体标签.
MDC模型的目标损失函数由置信度损失和位置损失两部分构成:
L(x, c, l, g)=
其中:a为权重参数, 即位置损失与置信度损失所占权重; N为候选框总个数; l为先验框位置参数; c为先验框的置信度; g为真实框的位置参数; x表示先验框与真实框是否匹配, 若匹配为1, 否则为0.
置信度损失Lconf(x, c)和位置损失Lloc(x, l, g)分别定义如下:
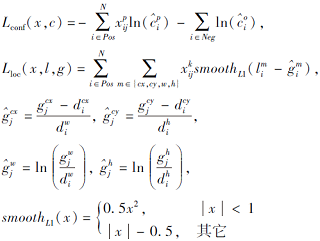
在MDC模型网络前向传播时, 通过损失函数计算损失, 利用随机梯度下降法(Stochastic Gradient Descent, SGD)反向传播, 修正神经网络的权重.
在Pascal VOC2007数据集上测试算法性能, 使用VOC2007和VOC2012训练集进行训练, 在VOC2007测试集上进行性能评估.使用平均精度均值(Mean Average Precision, mAP)作为检测精度的评价指标.
实验环境配置如下.操作系统为Ubuntu 16.04, CPU为I7-8700K @3.7 GHz, 内存为32 GB, GPU为2块NVIDIA GeForce 1080Ti.采用CUDA 10.1 cuDNN v7.5.0作为GPU加速库, 使用torch 1.2.0 torchvision 0.4.0深度学习框架和Python3.5编程语言.
训练输入尺寸为300× 300, 批次(Batch Size)设置为64, 采用SGD进行训练.训练过程采用大学习率逐步衰减方案[18], 初始学习率设置为0.05, 初始30 epoches和100 epoches分别设置衰减0.1倍, 后续每50 epoches衰减0.1倍.在原始conv-relu基础上加入批量标准化(Batch Normalization, BN)层, 采用conv-bn-relu训练模式对模型进行训练, 提高训练的稳定性[19].MDC模型训练时去除预训练模型, 从0开始训练, 训练结束后直接输出结果.
表1为MDC算子对检测模型精度的影响.表中实验1采用预训练模型和原始的网络参数配置[20].实验2至实验6在摒弃预训练模型后, 分别采用在骨干网络(Backbone)和头网络(Head)中添加BN层的方式以提高稳定性, 学习率均设置为0.05.实验6显示添加MDC算子对网络精度的影响.
| 表1 各模块实验对比 Table 1 Comparison of experimental modules |
由表1中前5列对应的实验结果对比可看出, 通过迁移学习加载预训练模型有利于保证检测模型的稳定性, 而完全摒弃预训练模型, 如实验2, 将导致检测模型失效.添加BN层, 能在一定程度上提高检测模型的稳定性, 但仍难以达到预训练模型的检测精度, 如实验3~实验5的mAP均小于原始检测精度模型的精度, 其中实验4对应的Loss不收敛, 检测网络失效.对比实验5和实验6可看出, 在加入MDC算子以后, mAP提升4.26%, 因此MDC算子对提升检测精度具有显著作用.
在Pascal VOC2007和Pascal VOC2012上进行训练, 在Pascal VOC2007公共测试集上测试MDC模型的性能, 测试集的测试样本共计4 952幅图像.
具体对比算法如下:Fast R-CNN, Faster R-CNN(Towards Real-Time Object Detection with Region Proposal Networks), ION(Inside-Outside Network), DSSD[21], Feature-Fused(Fast Detection for Small Ob-jects), MDSSD(Multi-scale Deconvolutional Single Shot Detector for Small Objects), ScratchDet(Exploring to Train Single-Shot Object Detectors from Scratch), SSD.表2为各算法与一阶段检测算法及二阶段检测算法的性能对比.在表中, SSD300[Liu]为SSD原论文所得结果, SSD300[本文]为MDC模型在相同实验环境下所得结果.
| 表2 各算法在PASCAL VOC2007测试集上的测试结果 Table 2 Detection results of different algorithms on PASCAL VOC2007 test set |
对比二阶段检测算法, MDC模型比Fast R-CNN的mAP值提高10.4%, 比采用锚机制的Faster R-CNN的mAP值提高7.2%对比一阶段算法, MDC模型比SSD的mAP值提高3.3%, 比DSSD的mAP值提高1.8%.在检测速度方面, 原始SSD为57帧/秒, MDC模型可达到48帧/秒, 满足实时性的要求.
为了进一步直观体现MDC模型检测效果, 本文对VOC2007测试集共计4 952幅图像的检测结果进行统计分析, 以检测框尺寸占图像尺寸的百分比作为衡量标准, 统计0.5%、1%、2%、3%、5%、10%、20%、30%、40%、50%这20类目标的检测数目, 结果如表3所示.
| 表3 两种算法在PASCAL VOC2007 测试集上的检测数目对比 Table 3 Detection number comparison of 2 algorithms on PASCAL VOC2007 test set |
整理统计结果, 进行差值计算, 从0.5%至50%阶段, MDC模型的检测效果均优于SSD.将尺寸低于3%的认定为小目标, MDC模型对小目标的检测性能高于SSD, 为45.7%.
图5为分别使用SSD和MDC模型对含有小物体的目标图像的检测效果.由图可看出, 由于MDC模型引入相邻层信息, 保留更丰富的细节特征, 相比普通卷积, 经由MDC算子得到的特征图同样可获取更细微的信息, 因此改进后的MDC模型测试结果更优.对于人物和椅子等细节特征, 船等小物体的检测上, MDC模型比SSD具有更优的检测性能.对于人物和马匹等目标出现重叠的情况, SSD出现漏检的情况, 而MDC模型可准确检测目标, 对重叠干扰具有鲁棒性.
 | 图5 SSD和MDC模型在PASCAL VOC2007测试集上的检测结果Fig.5 Detection results of SSD and MDC deep network model on PASCAL VOC2007 test set |
本文提出融合MDC算子和多层次特征的深度网络检测算法.首先使用MDC算子提取原特征层特征信息, 融合下层特征层转置卷积与当前层, 形成富有全局信息和语义信息的特征层, 使用检测层预测物体信息和边界信息, 在最大程度上减小因卷积导致的特征损失.实验表明, 本文算法在精度方面较优, 尤其是在对小目标的检测方面, 具有显著提升.但在检测重叠目标和遮挡严重目标仍旧存在不足.后续研究将会针对于全局语义信息融合, 充分结合前后特征图更详细的信息, 期望在检测精度上有所提高.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|