






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于堆叠边缘感知模块的显著性目标检测
[杨佳信1  , 胡晓
, 胡晓1 , 向俊将1 ]
, 胡晓, 向俊将]
|
|



作者简介:

杨佳信,硕士研究生,主要研究方向为深度学习、显著性目标检测.E-mail:1061810048@qq.com.

向俊将,硕士研究生,主要研究方向为视频分析、目标检测.E-mail:578744377@qq.com.
现有显著性目标检测算法对边缘感知的效果不理想.因此,为了有效利用高层语义信息及低层纹理信息,文中提出基于堆叠边缘感知模块的显著性目标检测算法.采用多尺度骨干网络(Res2Net)作为主干网络提取图像的多尺度、多目标的显著性特征.堆叠边缘感知模块以非对称性方式融合图像高低层信息,增强显著性目标区域.网络输出显著性目标的检测结果.在5个公开数据集上的实验表明,文中算法检测结果较优,同时,在客观评估指标和主观视觉效果上也较优.
AboutAuthor:
YANG Jiaxin, master student. His research interests include deep learning and salient object detection.
XIANG Junjiang, master student. His research interests include video analysis and object detection.
To improve the poor performance of the existing salient object detection algorithms in edge perception, a salient object detection algorithm based on stack edge-aware module is proposed to utilize high-level semantic information and low-level texture information effectively. Multi-scale backbone network is utilized as the backbone network to extract the multi-scale and multi-target salient features. In stacked edge-aware module, the high-level information and low-level information of the image are combined in an asymmetric manner to enhance the area of the salient object. The network outputs salient object detection results. The experiments on five public datasets indicate that the proposed algorithm produces better detection results and better performance in objective evaluation indicators and subjective visual effects.
本文责任编委 高隽
Recommended by Associate Editor GAO Jun
人类视觉注意力机制可捕获视觉画面中的显著信息.作为一种有效的类人眼视觉预处理技术, 显著性目标检测(Salient Object Detection, SOD)在目标跟踪[1]和行为识别[2]等视频分析领域得到广泛应用.
SOD利用稀疏表达、小波变换、离散剪切波分解等方式[3, 4], 实现图像的多尺度描述, 融合多尺度特征, 生成显著性映射图.这些方法虽然在一定程度上可实现显著性目标检测, 但是无法描述复杂场景下的显著性目标, 表达能力有限, 同时泛化能力较差.
Shelhamer等[5]将全卷积神经网络(Fully Con-volutional Networks, FCN)应用于语义分割.其后Wang等[6]运用知识迁移思想, 促进显著性目标检测的快速发展.FCN堆叠多个卷积层和池化层, 扩大特征感受野, 使高层特征获得更复杂的语义信息.Li等[7]认为多尺度特征可提高SOD的性能, 引入完全连接层, 聚合多尺度的高层语义信息, 得到较优的显著性映射图.Zhang等[8]设计基于编解码结构的深度FCN, 通过编码方式学习深度不确定卷积特征, 获得深度显著性特征, 并结合混合上采样方法与解码方式, 预测显著性映射图.然而, 上述算法未考虑低层纹理信息, 显著性映射图存在边缘细节缺失的问题.
在金字塔状的深度神经网络中, 低层特征映射图通常具有较多的空间结构和细粒度的细节, 高层特征映射图包含丰富的语义信息[9, 10].
为了实现显著性目标准确预测, Wang等[11]结合高层语义信息和低层纹理信息, 同时为了避免重复下采样操作(池化或卷积方式)导致的有利信息丢失问题, 提出金字塔池模块, 聚合各层次的显著性特征, 达到较优的SOD性能.Zhang等[10]提出聚合多层卷积特征的SOD(Amulet)网络模型, 以自上而下的方式聚合粗糙语义信息和精细细节信息, 有效实现精确的边界推断和语义特征增强.Liu等[12]采用层级递归卷积神经网络(Hierarchical Recurrent Convolutional Neural Network, HRCNN), 整合局部上下文信息, 对显著性映射进行分层逐步细化, 并组合低层特征, 重新确定粗略显著性映射图.Wu等[13]根据二值分割和边缘映射之间的逻辑相互关系进行双向信息传递, 利用多级特征, 设计有效的交叉细化单元(Cross Refinement Unit, CRU).上述方法虽然可提高显著性目标检测结果, 但都是简单融合高低层信息, 并未考虑高层语义信息和低层纹理信息对检测网络的贡献差异性及其融合的不充分性.同时, 将融入过多低层纹理特征的边缘信息作为干扰项与高层语义特征融合, 会导致边缘模糊.
为了解决上述存在的问题, 以Wu等[13]的工作为基础, 改进交叉细化单元, 设计边缘感知模块, 提出基于堆叠边缘感知模块的显著性目标检测.通过边缘感知辅助训练, 充分有效利用高层语义信息及低层纹理信息.首先, 采用多尺度骨干网络(Multi-scale Backbone Architecture, Res2Net)作为主干网络, 有效提取输入图像多尺度、多目标的显著性特征.然后, 特征中高层语义信息和低层纹理信息在边缘感知模块中通过基于通道间的级联操作和乘法运算, 以非对称性的形式融合, 有效增强显著性目标区域.最后, 由堆叠边缘感知模块输出显著性目标检测图像.在5个公开数据集上的实验表明, 本文算法在5个客观评估指标上取得较优的显著性目标检测结果.
本文提出的基于堆叠边缘感知模块的显著性目标检测网络结构如图1所示, 包括1个基于Res2Net的主干网络和4个边缘感知模块.
 | 图1 本文算法总体网络结构框图Fig.1 Framework of network structure of the proposed algorithm |
主干网络旨在学习多层次的特征.Res2Net可用于有效提取一个或多个目标的特征图.在粗略特征提取过程中, 图像通过基于Res2Net的主干网络, 将每层的特征分为显著性特征(Salient Feature, SF)和边缘特征(Edge Feature, EF), 然后输入边缘感知模块.在边缘感知模块中, 将网络划分为2个分支:1)主干网络提取的多级显著性特征.利用突出增强的乘法运算方式与低层边缘特征EFl进行融合, 辅助预测显著性映射图.2)主干网络提取的多级边缘特征.综合考量基于通道间的级联方式与高层显著性特征SFh的融合, 监督预测边缘映射图.最后, 以堆叠边缘感知模块的方式, 逐步改进各级特征, 有效预测显著性目标区域.在此过程中, 边缘特征EF和显著性特征SF相互监督、交替训练.
传统的主干网络使用现有的网络, 如视觉几何组网络(Visual Geometry Group Network, VGGNet)[14]和残差网络(Residual Network, ResNet)[15].基于ResNet的主干网络如图2(a)所示, 可较好地检测单个目标, 但难以检测多个目标, 常会漏掉目标.Gao等[16]设计Res2Net, 针对多目标的显著性目标检测, 具有良好的性能.因此, 本文采用Res2Net作为主干网络.Res2Net主干网络中的每个特征层具有多个不同尺度、方位的感受野, 模拟人类大脑对显著性、多尺度、多目标的感知.
 | 图2 ResNet主干网络及其变体Fig.2 ResNet backbone network and its variants |
如图2(b)所示, 输入图像特征先与大小为1× 1的核卷积成4个特征图xn(n=1, 2, 3, 4), 通过它们的通道将xn映射成yn, 其中3个通道是与大小为3× 3的核进行卷积运算.利用1× 1卷积核对特征图进行融合, 得到多尺度特征.Gao等[16]在论文中描述Res2Net的详细信息.
Hu等[17]将SE(Squeeze-and-Excitation)模块运用到ResNet网络中, 如图2(c)所示, 旨在通过SE模块机制, 学习使用全局信息, 选择性地强调显著性特征, 并抑制无关信息的特征.本文运用ResNet、Res2Net、SE-ResNet进行对比实验.
在Wu等[13]的用于边缘感知显著性目标检测的叠层交叉细化网络(Stacked Cross Refinement Network for Edge-Aware Salient Object Detection, SCRN)中提出CRU结构单元, 有效结合各层之间的边缘特征和显著性特征.由于高层语义信息有利于突出定位显著性目标, 而低层纹理信息有利于细化显著性目标区域边缘[18], 因此, 本文改进CRU结构中各分支的辅助特征, 设计基于高低层信息的边缘感知模块.
图3为边缘感知模块结构框图.由图所示, 边缘感知模块具有非对称性交叉结构, 有效利用基于通道间的级联操作和乘法运算的方式, 融合高层语义信息和低层纹理信息.边缘图和显著性图相互监督, 以堆叠的方式逐步细化特征并预测显著性图和边缘图.
 | 图3 边缘感知模块结构框图Fig.3 Structure of edge-aware module |
边缘感知模块定义如下:
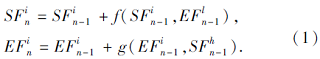
其中:S
本文从特征融合方式、高低层信息组合、模块堆叠数量这3方面验证边缘感知模块的有效性.
1.2.1 特征融合方式
低层特征包含边缘、纹理等空间结构的细节信息, 高层特征清晰突显目标轮廓, 高低层信息融合可有效实现信息互补.Zhang等[10]对低层纹理信息进行下采样操作后, 与高层语义信息简单融合, 然而这种方式无法充分利用不同层次的特征.因此本文提出基于高层语义信息和低层纹理信息的融合方式.针对不同层次的特征差异性, 以及不同层次的特征贡献和作用不同, 本文分别采用基于通道间的级联操作和乘法运算的方式, 使各层次特征得到充分利用.基于通道间级联的方式进行特征融合, 可综合考量不同特征间的关系, 有效融合不同特征的特点, 而采用乘法运算的方式进行特征融合, 可更进一步地突出增强显著性特征.f函数和g函数可表示如下:
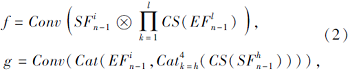
其中, Conv表示具有32个输出通道的3× 3卷积层, ⊗表示乘法运算, Cat表示通道间的级联操作, ∏ 表示累乘符号, Ca
在实验验证过程中, 本文采用堆叠4层边缘感知模块(n=4)的方式, f函数中采用2层低层纹理特征(l=2), g函数中采用2层高层语义特征(h=3).分别以f函数采用乘法运算和g函数采用级联操作、 f函数采用级联操作和g函数采用乘法运算、 f和g函数均采用级联操作、 f和g函数均采用乘法运算的方式进行实验对比.
1.2.2 高低层信息组合
针对高层语义信息适合于定位突出显著性目标而低层纹理信息更适合于细化目标边缘的现象, 本文利用其特征的作用及贡献的不同, 合理地对高低层信息进行组合.对于边缘感知模块的2个分支, 本文通过将高层语义特征(layer2、layer3、layer4)与边缘预测图分支的边缘特征进行基于通道间的级联操作, 以高层语义信息指导边缘特征图生成.另外, 将低层纹理特征(layer1、layer2、layer3)与显著性预测图分支的显著性特征进行乘法运算, 利用低层纹理信息, 进一步定位显著性目标区域, 同时细化其边缘.该过程可表示如下:

在验证过程中, 本文采用堆叠4层边缘感知模块(n=4)的方式, f函数中采用乘法运算的特征融合方式, g函数中采用基于通道间的级联操作进行特征融合, 分别采用前两层低层纹理特征和后两层高层语义特征、前三层低层纹理特征和后三层高层语义特征、各层边缘特征和各层显著性特征进行实验对比.有效利用高低层信息可在一定程度上减少信息的冗余.
1.2.3 模块堆叠数量
当卷积神经网络从输入图像中提取图像特征时, 低层的图像特征包含纹理边缘信息和部分背景噪声, 而高层的图像特征可抑制图像的背景噪声, 突出显著性目标区域.图4为低层及高层特征可视化结果, 由图可看出, 低层纹理信息对于边缘图的预测是有利的, 高层语义信息对于显著性目标区域定位是有利的.针对提出的边缘感知模块, 本文通过端到端堆叠的方式逐步优化卷积神经网络各级特征, 放大特征融合方式和高低层信息组合引入的影响.
 | 图4 低层及高层特征可视化Fig.4 Low-level and high-level feature visualization |
实验平台的操作系统为Ubuntu 14.04.3 LTS, 配置Python 3.6环境, 在PyTorch框架下实现, 计算机显卡型号为GTX 1080Ti, 优化函数采用随机梯度下降(Stochastic Gradient Descent, SGD)算法, 学习率为0.002, 迭代次数为30次.利用学习率计划, 在迭代20次后, 将学习率乘以0.1, 优化模型的收敛过程.批量化大小设置为8.参数设置与SCRN[13]完全一致, 将其作为基线.
本文使用如下5个常用于显著性目标检测的公开数据集:ECSSD[19]、DUT-OMRON[20]、PASCAL-S[21]、HKU-IS[7]、DUTS[22].ECSSD包含1 000幅从互联网上收集的图像.DUT-OMRON包含5 168幅高质量的图像.PASCAL-S包含850幅自然图像.HKU-IS包含4 447幅低对比度或多个对象的图像.DUTS分为训练数据集和测试数据集, DUTS-TRAIN包含10 553幅用于训练的图像, DUTS-TEST包含5 019幅用于测试的图像.本文使用DUTS-TRAIN作为训练数据集.
为了定量评估模型的有效性, 采用常用的评估指标:最大F度量值(max F-measure, maxF)[23]、平均绝对误差(Mean Absolute Error, MAE)[24]、增强-对准度量值(Enhanced-Alignment Measure, Em)[25]、加权F度量值(Weighted F-measure, WFm)[26]、精确率-召回率曲线(Precision-Recall, PR).
本节从特征融合方式、高低层信息组合、模块堆叠数量3方面逐步验证分析边缘感知模块的有效性.同时, 针对主干网络分别采用ResNet、Res2Net、SE-ResNet进行消融性实验.本文将SCRN作为基线, 网络结构为ResNet和堆叠的CRU单元, 其中CRU为一种有效的交叉细化单元.为了验证本文提出的Res2Net和边缘感知模块, 实验参数设置与SCRN完全一致, 在实验平台上进行消融性实验.选择2个公开数据集PASCAL-S和DUTS-TEST, 在4个评估指标(maxF、MAE、WFm、Em)上进行消融性分析.在主干网络的对比实验中, 在5个基准数据集上对比maxF、MAE.
表1为不同特征融合方式的消融性实验结果, 表中黑体数字表示最优结果.实验针对网络中边缘感知模块的2个分支(显著性预测分支SF和边缘预测分支EF), 如式(1)中的f函数和g函数的特征融合方式进行对比实验, 分别采用基于通道数的级联操作和乘法运算进行特征融合.由表可看出, 对于显著性预测分支SF中的f函数采用乘法运算, 同时对于边缘预测分支EF中的g函数采用基于通道间的级联操作, 得到较优效果.可见:利用边缘特征与显著性特征进行乘法运算, 可有效辅助预测显著性图; 利用显著性特征与边缘特征进行基于通道间的级联操作, 可指导预测边缘图生成.
| 表1 不同特征融合方式的消融性实验结果 Table 1 Ablation experimental results of different feature fusion methods |
再对高低层信息组合方式进行消融性实验, 结果如表2所示, 表中黑体数字表示最优结果.在实验中, 对式(2)的f函数采用低层纹理信息(FEl)、g函数采用高层语义信息(FSh).实验结果显示, 显著性预测分支中采用前三层低层纹理特征, 边缘预测分支中采用后三层高层语义特征, 取得最优结果, 在有效组合高低层信息的同时, 能一定程度上减少信息的冗余.
| 表2 高低层信息组合方式的消融性实验结果 Table 2 Ablation experimental results of combinations of high-level and low-level information |
为了更好地放大边缘感知模块在利用高低层信息和特征融合方式时的影响, 进一步提升显著性目标检测的精度, 对边缘感知模块的堆叠数量进行消融性实验.本文分别采用堆叠2, 4, 6, 8个边缘感知模块的方式进行测试, 结果如表3所示, 表中黑体数字表示最优结果.输出可视化结果如图5所示.
| 表3 堆叠边缘感知模块数量的消融性实验结果 Table 3 Results of ablation experiment of the number of stacked edge-aware modules |
 | 图5 堆叠不同数量边缘感知模块的输出的可视化结果Fig.5 Output visualization results of different numbers of stacked edge-aware modules |
当边缘感知模块堆叠数量大于4时, 在PASCAL-S、DUTS-TEST数据集上性能下降.这是因为堆叠过多的边缘感知模块会产生过拟合现象, 在网络中产生更多的参数, 导致信息冗余.因此, 本文采用堆叠4个边缘感知模块的方式, 通过堆叠方式, 逐步改进多层次特征, 提升显著性目标检测精度.
表4对比不同主干网络特征提取带来的不同表现结果, 表中黑体数字表示最优结果, 分别采用ResNet-50、SE-ResNet-50和Res2Net-50.在5个数据集上的maxF评估指标均得到较优性能, 同时在MAE评估指标上主干网络采用Res2Net-50, 大体上优于采用ResNet-50、SE-ResNet-50的方式.本文综合考虑性能和效益, 最终采用Gao等[16]提出的Res2Net主干网络.
| 表4 主干网络的消融性实验结果 Table 4 Ablation experimental results of backbone network |
本文与如下9种显著性目标检测算法进行对比:用于显著性目标检测的非局部深度特征(Non-local Deep Features for Salient Object Detection, NLDF)[9]、SCRN[13]、级联部分译码器实现快速准确的显著性目标检测(Cascaded Partial Decoder for Fast and Accurate Salient Object Detection, CPD-R)[14]、融合局部和全局上下文的显著性目标检测(Salient Object Detection by Fusing Local and Global Con-texts, CANet)[27]、基于反向注意力残差网络的显著性目标检测(Reverse Attention-Based Residual Network for Salient Object Detection, RAS-v2)[28]、具有通道注意力的堆叠式U形网络用于显著性目标检测(Stacked U-Shape Network with Channel-Wise Attention for Salient Object Detection, SUCA)[29]、注意反馈网络用于边界感知显著性目标检测(Attentive Feedback Network for Boundary-Aware Salient Object Detection, AFNet)[30]、基于金字塔注意力和显著边缘的显著性目标检测(Salient Object Detection With Pyramid Attention and Salient Edges, PAGENet)[31]、轮廓知识迁移用于显著性目标检测(Contour Knowledge Transfer for Salient Object Detection, C2S)[32].
为了公平对比, 本文使用作者提供的显著性目标检测结果图或运行可用的源代码.
表5为各算法在5个常用公开数据集上的maxF值和MAE值对比, 表中黑体数字表示最优结果.由表可看出, 本文算法在总体上性能更优.
| 表5 各算法在5个基准数据集上的定量对比 Table 5 Quantitative comparison of different algorithms on 5 benchmark datasets |
图6为各算法的精确率-召回率曲线, 本文算法曲线明显更高.
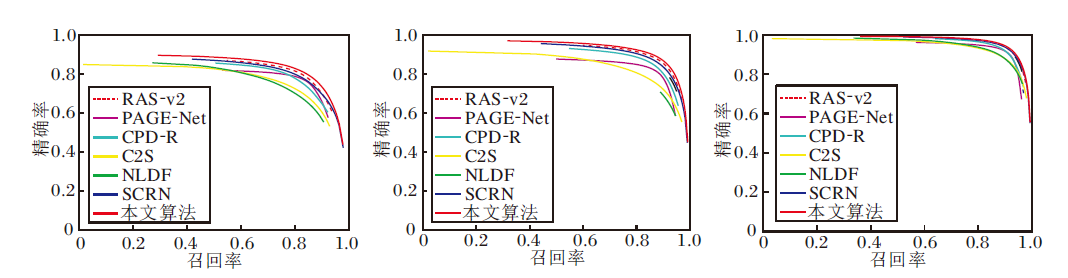 | 图6 各算法的精确率-召回率曲线对比Fig.6 Precision-recall curve comparison of different algorithms |
本文采用Res2Net作为主干网络提取图像特征, 可增强感受野, 较好地描述显著性目标.同时利用边缘感知模块, 将低层边缘特征通过乘法运算辅助监督显著性映射图预测, 将高层显著性特征通过基于通道数的级联操作指导边缘映射图预测, 以此有效融合不同层次信息, 全面表示显著性目标.最终通过堆叠边缘感知模块, 逐步改进特征, 训练鲁棒性较强的SOD, 可避免出现漏检及误检问题.图7为各算法的可视化结果视觉对比.由图可看出, 本文算法能应对处理各种具有挑战性的情况:大目标(第1列)、复杂场景(第2、4、5列)、多目标(第3列)和小目标(第6列).
 | 图7 各算法的可视化结果对比Fig.7 Comparison of visualization results of different algorithms |
本文提出基于堆叠边缘感知模块的显著性目标检测算法.通过堆叠, 逐步改进各级特征, 不仅利用低层纹理信息优化显著性目标的边缘, 而且利用高层语义信息准确定位显著性目标位置.同时采用Res2-Net作为主干网络, 提升显著性特征的表述能力.实验表明, 本文算法在定量分析和定性分析上都取得较优性能.今后, 将进一步研究细化显著性目标边缘, 并针对具有深度的RGB图像(RGB-D)进行显著性目标检测, 进一步扩展运用到视频分析、视频人脸识别、目标跟踪等.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|