




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于YOLOv3与注意力机制的桥梁表面裂痕检测算法
[蔡逢煌1, 2  , 张岳鑫
, 张岳鑫1, 2 , 黄捷1, 2 ]
, 张岳鑫, 黄捷]
|
|



作者简介:

蔡逢煌,博士,副教授,主要研究方向为电力电子和控制、DSP控制应用、模式识别.E-mail:caifenghuang@fzu.edu.cn.

张岳鑫,硕士研究生,主要研究方向为图像处理、模式识别.E-mail:1465319577@qq.com.
为了实现桥梁表面裂痕的快速准确检测和及时修复,在目标检测网络YOLOv3的基础上,结合深度可分离卷积与注意力机制,提出实时检测桥梁表面裂痕的轻量级目标检测网络.使用深度可分离卷积操作替换YOLOv3的标准卷积操作,达到降低网络参数量的目的.同时为了解决深度可分离卷积操作带来的网络精度下降的问题,引入MobileNet v2的反转残差块.卷积块注意力模块同时关注图像的通道注意力和空间注意力,较好地进行特征的自适应学习.实验表明,文中算法可实现对桥梁表面裂痕的实时检测.相比YOLOv3,具有更高的检测精度和检测速度.
AboutAuthor:
CAI Fenghuang, Ph.D., associate profe-ssor. His research interests include power electronics and control, digital-signal-processing-based control applications and pattern recognition.
ZHANG Yuexin, master student. His research interests include image processing and pattern recognition.
To realize fast and accurate detection of bridge surface cracks for the timely repair, a bridge surface crack detection algorithm based on improved YOLOv3 (Crack-YOLO) is proposed. Crack-YOLO is combined with depthwise separable convolutions and attention mechanism to detect bridge surface cracks in real time. The standard convolution of YOLOv3 is replaced with the depthwise separable convolution to reduce the number of network parameters. Moreover, the inverted residual block of MobileNet V2 is introduced to solve the problem of precision decline caused by depthwise separable convolution. In Crack-YOLO, both channel attention and spatial attention of the image are taken into account through the convolution block attention module to learn the feature selectively. The experimental results show that Crack-YOLO detects the cracks on the surface of the bridge in real time. Compared with YOLOv3, Crack-YOLO produces smaller weights and higher detection accuracy at a higher detection speed.
本文责任编委 张军平
Recommended by Associate Editor ZHANG Junping
混凝土桥梁作为交通的重要节点, 在建成投入使用后, 会不可避免地遭遇大风、雨雪、地震及冰冻等各种自然力的影响.随着时间的推移, 还可能遭受超载、撞击等人为因素的影响, 必然会造成桥面桥墩等各种病害及损坏[1].在诸多桥梁的病害中, 桥梁的裂缝是较难以检测的一种破损状态, 也是危及桥梁安全的一个重要问题[2].当裂缝宽度过大时会直接破坏结构的整体性, 引起混凝土碳化、保护层剥落和钢筋腐蚀等问题, 大幅降低桥梁承载能力, 严重时甚至发生垮塌事故[3].因此, 采取有效手段对桥梁裂缝进行监测并预防, 对确保桥梁交通的安全和正常运行具有重要的作用.在所有裂痕检测技术中, 利用视觉检查最为方便快捷.然而, 人工检测高度依赖检查员的主观经验, 有时会出现错误的检测结果.计算机图像处理技术能对采集的大量图像进行自动处理和分析, 从图像中识别桥梁裂缝.
现有的裂痕检测算法主要是以手工特征设计和模板匹配等为代表的传统图像处理算法.Abdel-qader等[4]对比4种裂痕检测算法:快速Haar变换、快速傅里叶变换、Sobel算法和Canny算法.在4种检测算法中, 快速Haar变换的性能明显最优, 但难以对含有噪声的图像数据进行阈值处理, 检测精度也远低于人工检测.阮小丽等[5]在图像预处理基础上, 通过裂缝的特性寻找裂缝区域的交叉点, 并提取裂痕, 但是对图像的光照和角度具有较高要求, 泛化性较差.Zalama等[6]提出使用Gabor作为特征提取的算法, 采用Adaboost算法对分类器进行选择和组合, 提高单个分类器的分类结果.上述算法虽然自动化程度较高, 但是在图像噪声过于复杂时算法的检测精度仍然会在很大程度上被影响.因此, 需要一种可准确识别和定位桥梁裂痕的检测算法, 以便能够适用于各种复杂条件下的裂痕图像.
Krizhevsky等[7]提出AlexNet网络结构模型, 使卷积神经网络(Convolutional Neural Networks, CNN)成为图像分类上的核心算法, 并相继在图像分类、目标检测、图像分割等多种图像处理任务中取得突破性进展.与神经网络不同, CNN从训练数据中自动学习适当的特征, 相比传统手工设计的特征描述, 深度卷积特征在语义抽象能力上具有大幅提升[8].李良福等[9]和Zhang等[10]各自提出基于CNN的分类模型, 识别裂缝时精度较高, 但是不能对裂痕进行定位, 只能识别图像中是否存在裂痕.而基于CNN的目标检测算法可识别裂痕并进行定位, 还可克服复杂环境下检测的困难和瓶颈, 因此适用于桥梁表面的裂痕检测.
目前基于深度学习的目标检测算法根据预测流程可分为2类.第1类为基于候选区域的深层卷积神经网络的目标检测算法, 代表性算法为R-CNN(Region CNN)[11]、Fast R-CNN(Fast Region-Based CNN)[12]和Faster R-CNN(Faster Region-Based CNN)[13].这类算法将目标检测分为两步, 先通过区域建议算法生成可能包含目标的候选区域, 再通过CNN对候选区域进行分类和位置回归, 得到最终的检测框.因为此类算法需要逐个处理产生的候选框, 检测速度受到限制, 难有较大提升, 很难实现桥梁裂痕的实时检测.第2类为基于回归的深层卷积神经网络的目标检测算法, 代表性算法有YOLO(You Only Look Once)[14]、YOLO9000[15]和YOLOv3(YOLO Version 3)[16].此类算法去除候选区域生成环节, 将目标定位和分类整合在单个CNN中, 只需进行前向运算就可对多种物体进行检测, 检测速度远高于第1类算法.YOLOv3在融合特征提取阶段采用浅层次特征和深层次特征, 提取更具鉴别性的深层特征, 大幅提高正确率, 尤其在小目标的检测与识别上.因此, YOLOv3可为桥梁表面裂痕检测任务提供解决方法.
YOLOv3是目前较优的目标检测算法之一, 学者们将其应用到不同对象的检测, 并提出不同的改进方案.对于水下鱼类目标的实时检测, 文献[17]改进YOLOv3, 对海底鱼类小目标和重叠目标具有较好的检测性能, 检测速度也有大幅提升.虽然YOLOv3在COCO、VOC等常规数据集上都取得较优的检测效果, 但是不能直接应用于桥梁表面裂痕的检测, 主要有如下2点原因:1)因为YOLOv3的网络结构十分复杂, 而本文只需要对桥梁裂痕一种类别进行检测, 特征数量较少.所以导致训练集的数量不足以训练YOLOv3, 训练过程容易出现过拟合现象, 而且图像中的裂痕与桥梁表面的对比度较低, 纹理细节容易受到光照影响.2)网络的参数过多, 会使训练时间变长, 难度变大, 图像的检测时间也会变长.
本文提出基于YOLOv3与注意力机制的桥梁表面裂痕检测算法, 将注意力机制、深度可分离卷积和反转残差结构与YOLOv3结合, 实现桥梁表面裂痕的识别和定位, 同时拥有实时检测的速度.因此, 本文以YOLOv3为基础, 改进网络结构, 提出适合桥梁裂痕检测的轻量级网络(Crack-YOLO).针对YOLOv3复杂度过高的问题, 对特征提取网络重新设计, 引入MobileNet[18]的深度可分离卷积, 替代标准卷积, 达到降低网络参数量的目的.使用Mobile-Net v2[19]的反转残差结构, 减小深度可分离卷积带来的检测精度轻微下降的影响.同时, 将卷积块注意力模块(Convolutional Block Attention Module, CBAM)[20]嵌入卷积层中, 从众多信息中选择对当前任务目标更关键的信息, 抑制其它无用信息.最后, 通过实验分析Crack-YOLO对桥梁表面裂痕的检测效果.
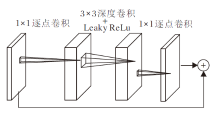
YOLOv3网络借鉴残差网络(Residual Network, ResNet)[21]的思想, 引入多个残差网络模块, 使用多尺度预测的方式提高预测精度.YOLOv3的特征提取结构使用大量3× 3和1× 1的卷积层, 由于具有53个卷积层, 因此也称作Darknet53.Darknet53由5个残差块构成, 每个残差块由多个残差单元组成, 通过输入与2个DBL单元进行残差操作, 构建残差单元, 如图 1(a)所示.DBL单元包含卷积、批量归一化(Batch Normalization)和Leaky ReLU激活函数, 如图 1(b)所示.引入残差单元加深网络深度, 避免梯度消失.
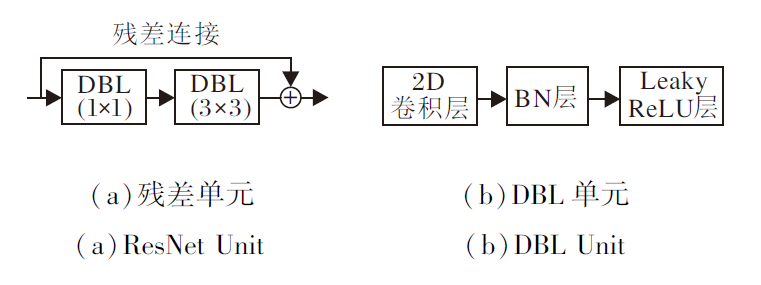 | 图1 YOLOv3结构单元Fig.1 Structural unit of YOLOv3 |
YOLOv3的网络结构如图2所示, 卷积网络在79层后, 再经过1层卷积层得到1种尺度的检测结果.
 | 图2 YOLOv3网络结构Fig.2 YOLOv3 network structure |
相比输入图像, YOLOv3用于检测的特征图有32倍的下采样.假设输入为416× 416的图像, 特征图为13× 13.由于下采样倍数较高, 特征图的感受野较大, 因此适合检测图像中尺寸较大的对象.为了实现细粒度的检测, 第79层的特征图又开始进行上采样, 然后与第61层特征图融合, 得到第91层较细粒度的特征图, 同样经过几个卷积层后得到相对输入图像16倍下采样的特征图, 具有中等尺度的感受野, 适合检测中等尺度的对象.最后, 第91层特征图再次上采样, 并与第36层特征图融合, 最后得到相对输入图像8倍下采样的特征图, 感受野最小, 适合检测小尺寸的对象.同时, 随着输出的特征图的数量和尺度的变化, 先验框的尺寸也在相应调整.YOLOv3采用K-means聚类得到先验框的尺寸, 为每种下采样尺度设定3种先验框, 总共聚类9种尺寸的先验框.
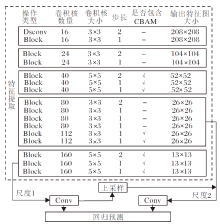
为了克服YOLOv3网络应用到桥梁裂痕检测任务中存在的不足, 本文提出基于改进型YOLOv3的实时目标检测算法, 算法的网络结构如图3所示.在图中, Dsonv为深度可分离卷积, Conv为常规卷积, CBAM为卷积块注意力模块, Block为带反转残差结构的深度可分离卷积操作.输入图像经过5次降采样之后得到第1种13× 13特征图, 预测3个检测框.经过上采样后, 与26× 26的特征图拼接, 得到第2种尺度为23× 23的特征图, 预测3个检测框.
 | 图3 改进后的YOLOv3网络结构Fig.3 Network structure of improved YOLOv3 |
本文算法主要包括4个部分:训练样本的边界框标记、深度可分离卷积、反转残差块结构、卷积块注意力模块.下面具体介绍各模块的实现过程.
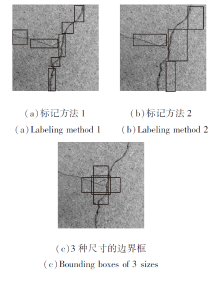
桥梁表面裂痕数据集匮乏, 裂痕形状各异, 同种裂痕可使用不同大小的包围框检测.如图4(a)、(b)所示, 同幅裂痕图像使用不同尺寸的边界框标注.如果标记样本时一幅图像中边界框的数量过多或边界框的形状差异过大, 会增加训练难度并降低检测时的准确率.因此, 如果仅使用少数个固定尺寸的边界框对大部分裂痕进行标记, 那么在减小网络的收敛时间同时可提高网络的检测精度.本文主要使用3种尺寸的边界框标记样本.(c)为3种边界框与样本图像的大小对比, 样本图像的分辨率为1 024× 1 024, 3种边界框的尺寸分别为170× 478、478× 170、239× 239.通过测试, 使用这3种边界框的组合可检测90%以上的裂痕.
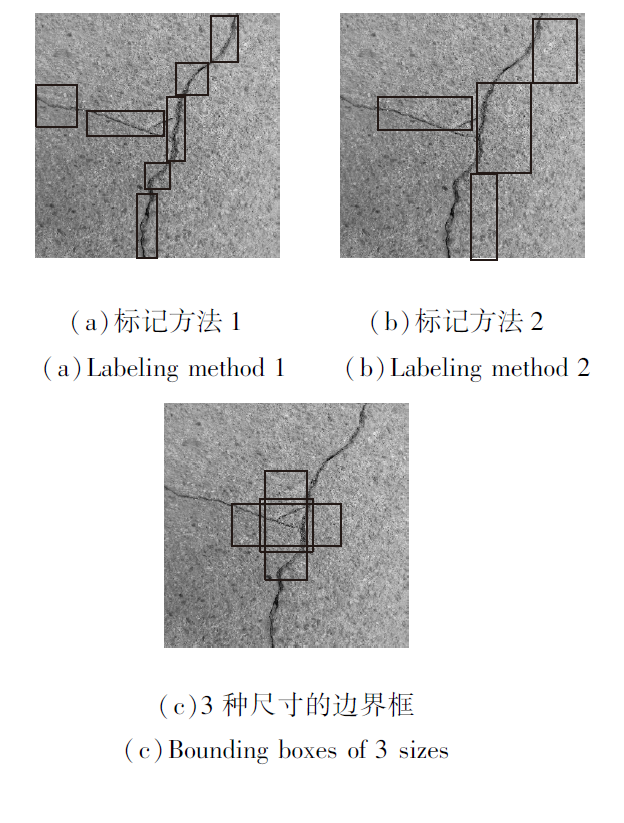 | 图4 样本的边界框标记Fig.4 Bounding box labeling of sample |
使用MobileNet的深度可分离卷积, 将卷积层中的卷积操作分解为1个深度卷积(Depthwise Convo-lution)和1个1× 1的卷积, 即逐点卷积(Pointwise Convolution), 这种分解可有效且大量地减少计算量及模型大小.深度卷积针对每个单个输入通道, 应用单个滤波器进行滤波, 然后逐点卷积应用1× 1的卷积操作, 结合所有深度卷积得到输出.而标准卷积一步即结合所有的输入, 得到新的一系列输出.深度可分离卷积将其分成两步, 针对每个单独层进行滤波, 然后再结合.图5为一个标准的卷积, (a)被分解成深度卷积(图5(b))及1× 1的逐点卷积(图5(c)).
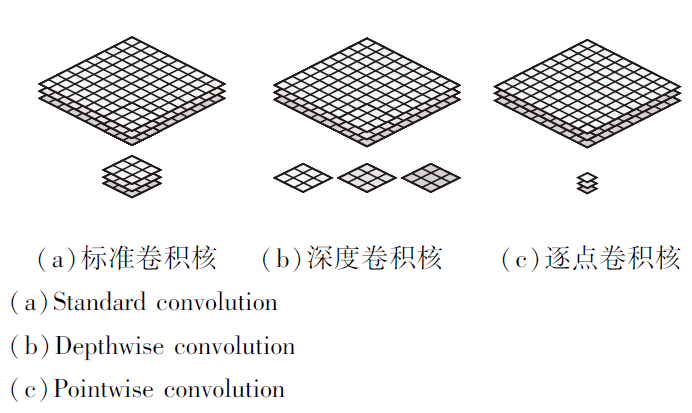 | 图5 标准卷积与深度可分离卷积Fig.5 Standard convolution and depthwise separable convolution |
假设输入的特征图F大小为DF× DF× M, 经过卷积操作后得到大小为DG× DG× N的特征图G, 其中DF为输入特征图的宽和高, M为输入的通道数, DG为输出特征图的宽和高, N为输出的通道数, DK为卷积核的宽和高, 则标准卷积的计算量为DKDKMNDGDG, 深度可分离卷积的计算量为
DKDKMDGDG+MNDGDG,
将卷积分为滤波和组合的过程, 得到计算量的缩减:
若使用3× 3的卷积核, 相比标准卷积, 深度可分离卷积减少至1/9~1/8的计算量, 却只有极小的准确率的下降.
相比普通卷积核, 深度可分离卷积的每个卷积核更小, 卷积后再通过激活层会导致部分信息的丢失, 而且将特征图进行升维降维操作时, 如果维度过小也会造成信息丢失.因此本文引入MobileNet v2的反转残差块结构, 去除一部分激活层, 可有效减少特征信息的丢失, 提高检测精度.
假设1个输入图像首先通过1个随机矩阵T将数据转换为n维, 然后对这n维数据进行ReLU操作, 最后再使用T的逆矩阵转换回来.当n很小时, 后面接ReLU非线性变换会导致很多信息的丢失, 反而维度越高还原的图像和原图越相似.由于深度可分离卷积的每个卷积核维度相对普通卷积核要小得多, 使用非线性层会毁掉一部分信息, 因此使用线性瓶颈层, 即去除小维度输出层后的非线性激活层, 目的是为了保证模型的表达能力.
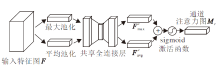
由于瓶颈层的输入包含所有的必要信息, 能防止信息丢失, 因此部分层后面不加激活层.足够多的通道可使丢失的信息保留在其它通道中, 因此才会在瓶颈层内部对特征进行升维.升维后信息更丰富.此时在激活层之后再降维, 理论上可保持所有的必要信息不丢失.反转残差块是在传统残差块的基础上进行改进, 如图6所示, 先将低维特征使用1× 1逐点卷积升维, 而后使用3× 3深度卷积和激活函数对特征进行滤波, 并使用1× 1逐点卷积对特征再降维, 得到本层特征的输出, 并与输入的低维特征进行逐元素的相加.
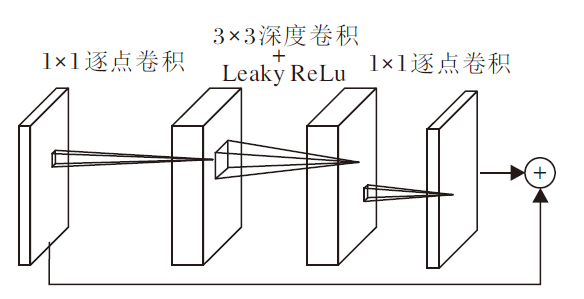 | 图6 反转残差块Fig.6 Inverted residual block |
为了从众多特征信息中选择对当前任务目标更关键的信息, 提高图像信息处理的效率与准确性, 本文引入深度学习的注意力机制.从本质上讲, 深度学习中的注意力机制和人类的选择性视觉注意力机制类似, 都是通过快速扫描全局图像, 获得需要重点关注的目标区域, 然后对这一区域投入更多的注意力资源, 从大量信息中快速筛选高价值信息, 抑制其它无用信息.CBAM是为卷积神经网络设计的简单有效的注意力模块.
对于一个中间层的特征图F∈ RC× H× W, 其中C为特征图的通道, H为特征图的高, W为特征图的宽, CBAM会顺序推理一维的通道注意力特征图MC∈ RC× 1× 1, 二维的空间注意力特征图MS∈ R1× H× W, 整个过程如下:
F'=MC(F)⊗F, F″=MS(F')⊗F',
其中⊗为逐元素相乘.首先将通道注意力特征图与输入的特征图相乘得到F', 再计算F'的空间注意力特征图, 并将两者相乘得到最终的输出F″.通道注意力模块和空间注意力模块的计算过程如下.
通道注意力模块主要关注于输入图像中什么是有意义的.如图7所示, 为了高效计算通道注意力, CBAM使用最大池化(Max Pooling, MaxPool)和平均池化(Average Pooling, AvgPool)对特征图在空间维度上进行压缩, 得到两个不同的通道背景描述:

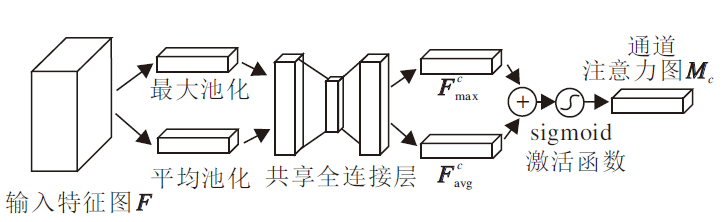 | 图7 通道注意力模块Fig.7 Channel attention module |
其中, σ 为Sigmoid激活函数, MLP为共享全连接层, W0为共享全连接层的第1层, 输出向量长度为r× C, W1为共享全连接层的第2层, 输出向量长度为C.
空间注意力模块主要关注位置信息.如图8所示, 首先在通道的维度上使用最大池化和平均池化, 得到2个不同的空间背景描述
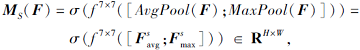
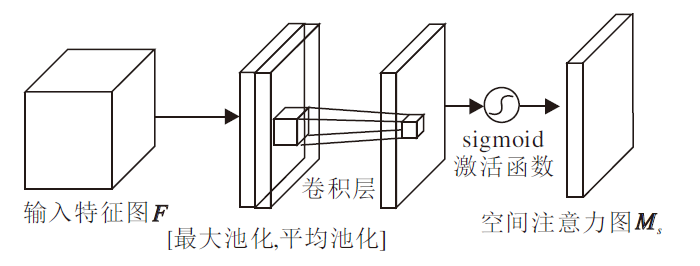 | 图8 空间注意力模块Fig.8 Spatial attention module |
其中 f7× 7表示7× 7的卷积层.
对于CNN生成的特征图, CBAM从通道和空间两个维度计算特征图的注意力图, 将注意力图与输入的特征图相乘, 用于特征的自适应学习.CBAM作为一个轻量的通用模块, 可融入目标检测网络中的卷积层进行训练.在本文中, 将卷积块注意力模块融入卷积层中, 从众多信息中选择桥梁裂痕的信息, 抑制其它无用信息.
本文一共收集1 500幅分辨率为1 024× 1 024的不同裂痕的桥梁图像, 对收集的图像使用图像标注工具LabelImg进行人工标注.图像标注后, 生成对应相同文件名的xml文件.xml文件记录标注框的位置和目标类别等信息.为了增强数据的可靠性, 对图像同一缩放为分辨率为416× 416的图像, 将数据集分为3组, 其中训练集为960幅, 验证集为240幅, 测试集为300幅.为了增加数据多样性, 对训练数据进行随机翻转、平移、模糊和改变亮度、对比度和曝光度等操作.图9为桥梁裂痕数据集的部分样本图像.
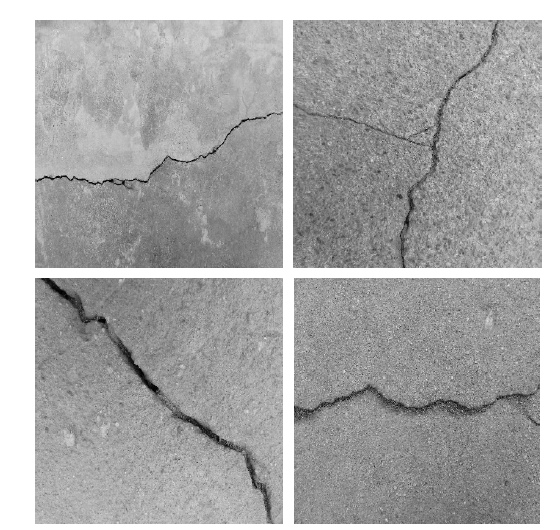 | 图9 桥梁裂痕数据集的部分样本图像Fig.9 Some sample images of bridge crack dataset |
本文实验配置环境如下:Windows 10操作系统、CPU为Intel Core i5-8500、GPU为NVIDIA GeForce GTX 2070(8 GB显存)、内存16 GB.使用Python 3.6, 深度学习框架为Keras, 并安装cuda10.0实现加速计算.
使用K-means对标注的候选框进行聚类, 得到优化框, 将交并比(Intersection over Union, IOU)代替欧氏距离作为衡量标准:
d(box, center)=1-IOU(box, center).
得到的优化框为(213, 212), (218, 223), (228, 231), (230, 219), (240, 238), (458, 150).配合本文设计的网络的2种预测框尺度, 每个尺度分别分配3个锚点框进行训练.
分别对Crack-YOLO和YOLOv3网络进行训练, 权值的初始学习率为0.1, 使用TensorFlow的回调函数ReduceLROnPlateau监测模型的损失值, 如果连续10轮验证集的损失值未下降, 方法自动将学习率降至原来的3/5.同时, 由于深度学习网络的结构复杂, 若训练时在训练集上表现越来越好, 错误率越来越低, 表明网络已过拟合.为了获得最优的泛化性能, 在训练时引入早停法, 当方法在验证集上的表现开始下降时, 停止训练, 避免继续训练而导致的过拟合现象.
测试集的数量为300幅, 使用该测试集对本文算法进行测试评估, 图10为部分检测结果.
 | 图10 本文算法的部分检测结果Fig.10 Some detection results of the proposed algorithm |
作为对比, 使用YOLOv3原网络进行相同测试.结果如表1所示.其中IOU阈值为检测框与框之间IOU的限制, 设置为0.1, 即不超过10%.网络权重大小为网络训练好后生成的网络参数的大小.
| 表1 两种算法的检测效率对比 Table 1 Detection efficiency comparison of 2 algorithms |
准确率为正确预测的裂痕数量与预测的裂痕数量的比值.误检率为错误预测的裂痕数量与预测的裂痕数量的比值.召回率为正确预测的裂痕数量与样本的裂痕数量的比值.漏检率为未被正确预测的裂痕数量与样本的裂痕数量的比值.检测速度为每秒检测图像的数量.如图4所示, 一幅图像的裂痕会被分段识别, 在一条裂痕中若只被识别一段, 则只有该段裂痕算入召回率.
由表1可看出, 在相同的测试条件下, 相比YOLOv3, Crack-YOLO准确率降低2.22%, 召回率提高3.92%, 检测速度提高5帧/秒.但是Crack-YOLO的网络权重大小只有11.1 MB, 远小于YOLOv3的235 MB, 小的参数量可减小网络的训练时间, 同时加快收敛速度.
现通过消融实验验证本文的桥梁表面裂痕检测网络的有效性.删除部分研究网络, 更详细了解各个模块起到的作用.使用相同的测试集, 以Crack-YOLO作为基础结构, 并采用相同的数据增强方案进行训练, 分别测试深度可分离卷积、注意力机制和反转残差块的作用.学习率从0.1开始, 使用TensorFlow的回调函数ReduceLROnPlateau监测模型的损失值, 如果连续10轮验证集的损失值未下降, 则方法自动将学习率降至原来的3/5.训练停止的条件为验证集的loss连续20次迭代未下降.测试结果如表2所示, 表中DSC为深度可分离卷积模块, CBAM为卷积块注意力模块, IRB为反转残差模块.
| 表2 消融实验的结果 Table 2 Results of ablation experiment |
由表2可知, 相比完整Crack-YOLO的检测结果, 删除DSC会使网络的参数量增加, 检测速度降低, 召回率提高, 准确率提高.删除CBAM会使网络的参数量减小, 检测速度提高, 召回率提高, 准确率下降.删除IRB会使网络的参数量减小, 检测速度提高, 召回率下降, 准确率下降.因此, 深度可分离卷积的主要作用是降低网络的参数量, 反转残差块和卷积块注意力机制的主要作用是提升网络的检测精度.
本文针对桥梁表面裂痕检测任务, 提出结合YOLOv3和注意力机制的轻量级桥梁表面裂痕检测算法.在Crack-YOLO的特征提取网络设计上, 将卷积层的层数设置为16层, 输出检测框设置为2种尺度共6个检测框, 可降低网络复杂性, 适用于裂痕检测.同时使用MobileNet的深度可分离卷积将标准卷积分解为一个深度卷积和一个1× 1的逐点卷积, 降低网络的参数量, 实现网络轻量化的目的.使用MobileNet v2的反转残差块结构, 去除一部分激活层, 可有效减少特征信息的丢失, 提高预测精度.引入注意力机制, 从图像信息中快速筛选裂痕信息, 抑制其它无用信息, 提高图像信息处理的效率与准确性.实验表明, 本文算法在桥梁表面裂痕目标数据集上取得较优的检测效果, 检测精度和速度均优于YOLOv3, 而且网络权重大小只有11.1 MB.最后通过消融实验验证深度可分离卷积起到的作用.今后将使用SSD(Single Shot Multibox Detector)、Corner-Net等目标检测算法的训练数据集, 将得到的检测结果与本文算法的检测结果进行对比, 寻找本文算法可进一步优化的步骤.同时, 将收集更多关于桥梁缺陷的图像, 包括桥面剥落、钢筋外漏及混凝土腐蚀等各种情况, 使算法可检测更多的桥梁病害.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|