


{kind=link}
{kind=link}
{kind=link}
基于可变形卷积的多人人体姿态估计
[赵云霄1, 2, 3  , 钱宇华
, 钱宇华1, 3 , 王克琪1, 3 ]
, 钱宇华, 王克琪]
|
|



作者简介:

赵云霄,硕士研究生,主要研究方向为模式识别、深度学习.E-mail:384498377@163.com.

王克琪,硕士,主要研究方向为机器学习、计算机视觉、计算理论.E-mail:76190504@qq.com.
目前针对人体姿态估计的深度神经网络都是在特征图的固定位置上进行采样,无法对人体姿态的几何变换进行建模,当人体实例在尺寸、姿势、拍摄角度等方面发生变化后,网络泛化能力较差.因此,文中提出基于可变形卷积的多人人体姿态估计方法.利用可变形卷积对目标几何变换建模能力较强的特性,设计特征提取模块,可在人体关键点几何变化的条件下保证检测的准确性.为了进一步提高网络性能,利用预训练残差网络.模型的预测值与二维高斯模型生成的真值用于计算损失,并迭代训练模型,能在拍摄视角、附着物及人物尺度变化等复杂条件下有效检测人体关键点.实验表明,文中模型可有效提升人体关键点检测的准确性.
AboutAuthor:
ZHAO Yunxiao, master student. His research interests include pattern recognition and deep learning.
WANG Keqi, master. His research inte-rests include machine learning, computer vision and theory of computation.
Deep neural networks for human pose estimation all sample at the fixed position of the feature map, and therefore it is difficult to model the geometric transformation of human pose. The generalization ability of the network is poor with the variation of the size, pose and shooting angle of the human instance. To solve this problem, multi-person human pose estimation based on deformable convolution is proposed.Based on the strong ability of deformable convolution in modeling geometric transformation of targets, a feature extraction module is designed to ensure the detection accuracy under the geometric changes of human key points. To further improve the performance of the network, the prediction value of the model and the truth value generated by the two-dimensional Gaussian model are employed to calculate the loss, and the model is trained iteratively. The human key points are detected effectively by the proposed model under the complex conditions, such as shooting angle, attachment and character scale changes. The experiment shows that the proposed model effectively improves the accuracy of human key point detection.
本文责任编委 张燕平
Recommended by Associate Editor ZHANG Yanping
人体关键点检测又称为人体姿态估计, 是指从给定的图像或视频中检测并定位人体关节节点.目前, 包括运动捕捉、虚拟现实、增强现实、视屏监控、三维动画等大量的人机交互应用都需要准确、实时地定位并识别人体关节节点.然而, 由于人体肢体的灵活性、人体遮挡和拍摄视角的变化、附着物的变化及人物尺度的不确定性等原因, 人体姿态估计是一个极具挑战的任务.
对于多人体姿态估计任务, 绝大多数的经典方法都使用概率图模型或图结构模型.由于空间的变换、图像尺度变化、人体遮挡等问题, 这些传统方法都表现较差.近些年, 深度卷积神经网络在人体关键点检测任务上的应用使该问题的准确率具有较大提升.
基于深度神经网络的方法分为自顶向下的方法[1, 2, 3, 4]和自底向上的方法[5, 6, 7]两种.自顶向下的方法是指先对人体生成候选框, 并在候选框的基础上进行人体关键点检测.由于方法可通过目标检测模型获取的结果限制关键点的边界, 因此准确率更高.自底向上的方法是在估计所有人体关节点位置的基础上, 再将这些候选节点与人体实例进行关联.方法不需要先进行目标检测, 而是直接检测特征图的所有点, 因此效率更高.
Newell等[8]提出堆叠沙漏网络(Hourglass Net-work), 在MPII数据集上效果较优, 也作为很多模型的基础网络被广泛使用.Hourglass模型是一种多层架构的网络, 先进行多次上采样, 再进行多次下采样, 并在对称的网络中使用多个连接层.级联金字塔网络(Cascade Pyramid Network, CPN)[1]是一种多层的金字塔网络, 在COCO数据集上表现良好.CPN网络同样使用多个连接层, 并使用困难样本挖掘的方法, 用于提高网络精度.人体姿态估计和跟踪的简单基线(Simple Baselines for Human Pose Estimation and Tracking, SimpleBaselines)[9]是在未进行跨层连接的情况下, 使用更简单的反卷积操作, 可有效提取具有高分辨率的特征图.
目前的卷积神经网络(Convolutional Neural Net-work, CNN)在人体姿态估计任务上已取得较大成功.然而, 基于CNN的神经网络模型是在特征图的固定位置上进行卷积操作, 对于目标的几何变化没有较好的解决办法.对于图像的几何变化, 目前的解决思路如下:1)对数据集上的图像进行数据扩增, 即旋转、扩大或缩小图像, 使数据集更丰富; 2)加强模型的泛化能力, 对几何变换具有较强的适应性.
学者们提出多种通过数据学习几何变化的方法, 在深度神经网络模型中得到广泛应用.Jaderberg等[10]提出空间变换网络, 学习一个全局的转换参数, 通过该转换参数对特征图进行变形.Wang等[11]学习目标的一部分几何变换, 使分类值最大化.上述方法都是通过多个卷积核的权重学习图像的几何变化.
Dai等[12]和Zhu等[13]将可变形卷积应用在基于候选区域的目标检测任务当中, 作为特征提取的方法将可变形卷积应用于主干网络最后若干层.为了把可变形卷积层成功融入ResNet-101及Inception-ResNet网络中, Dai等[12]首先使用ResNet-101或Inception-ResNet对整幅图像生成特征图, 并在生成特征图的基础上使用若干可变形卷积层, 生成最终输出.
与基于候选区域的目标检测方法不同, 本文提出基于可变形卷积的多人人体姿态估计模型, 将可变形卷积[12]引入人体关键点检测任务, 可对人体关键点的几何变换有效建模, 提升人体姿态估计的准确度.将经典的深度残差网络(Residual Network, ResNet)[14]作为基础网络, 对输入生成特征图.使用反卷积网络作为最终层, 并使用二维高斯函数通过标注位置生成的目标值与网络预测值进行均方误差生成损失, 训练深度神经网络.在经典的MS COCO数据集[15]上的大量实验表明, 本文模型在越深的网络上的实验效果越优, 可有效提升人体关键点的检测精度.
输入图像首先经过一个预训练好的目标检测模型, 获取人体实例边框, 再根据边框数据生成的变换矩阵对原图进行仿射变换, 输出统一尺寸的图像.同时对标注数据进行相同的仿射变换, 使用经过预处理的图像及标注数据对人体姿态估计模型进行训练.
目前通用的目标检测模型为更快速的候选框网络(Faster Region Proposal Networks, Faster R-CNN)[16]、掩模候选框网络(Mask Region Proposal Network, Mask R-CNN)[2]等, 本文采用的目标检测模型为Wang等[17]提出的Guided-Anchoring目标检测模型.该模型是在预测目标中心点的基础上, 在每个目标中心点位置预测目标框的大小, 可使Faster R-CNN及Mask R-CNN等模型在训练时大量出现的锚点减少90%, 相比Faster R-CNN, 目标检测准确率提升约2.7%.
算法1 图像处理算法
输入 原始图像I, 目标检测模型Mdetection,
人体姿态估计模型Mestimation,
输出图像尺寸ImageSize
输出 检测人体关键点KP
BBoxes← Detection(I, Mdetection) /* 使用目标检测模型生成人体实例的目标框* /
for each Box in Boxes
Center, Scale← Box2CS(Box, ImageSize)
/* 通过目标框及输出尺寸生成中点、变换比例* /
T← GetAffineTransform(Center, Scale, Size)
/* 生成仿射变换矩阵* /
P← WarpAffine(I, T)
/* 通过仿射变换矩阵为图像的每个标注框生成对
应的输出* /
KP← DetectionKepoints(P, Mposeestimation)
end for
基于可变形卷积的多人人体姿态估计模型框架如图1所示.图像经过目标检测模块后生成一个或多个人体实例边框, 并对每个人体实例进行仿射变换, 生成统一尺寸的目标图.
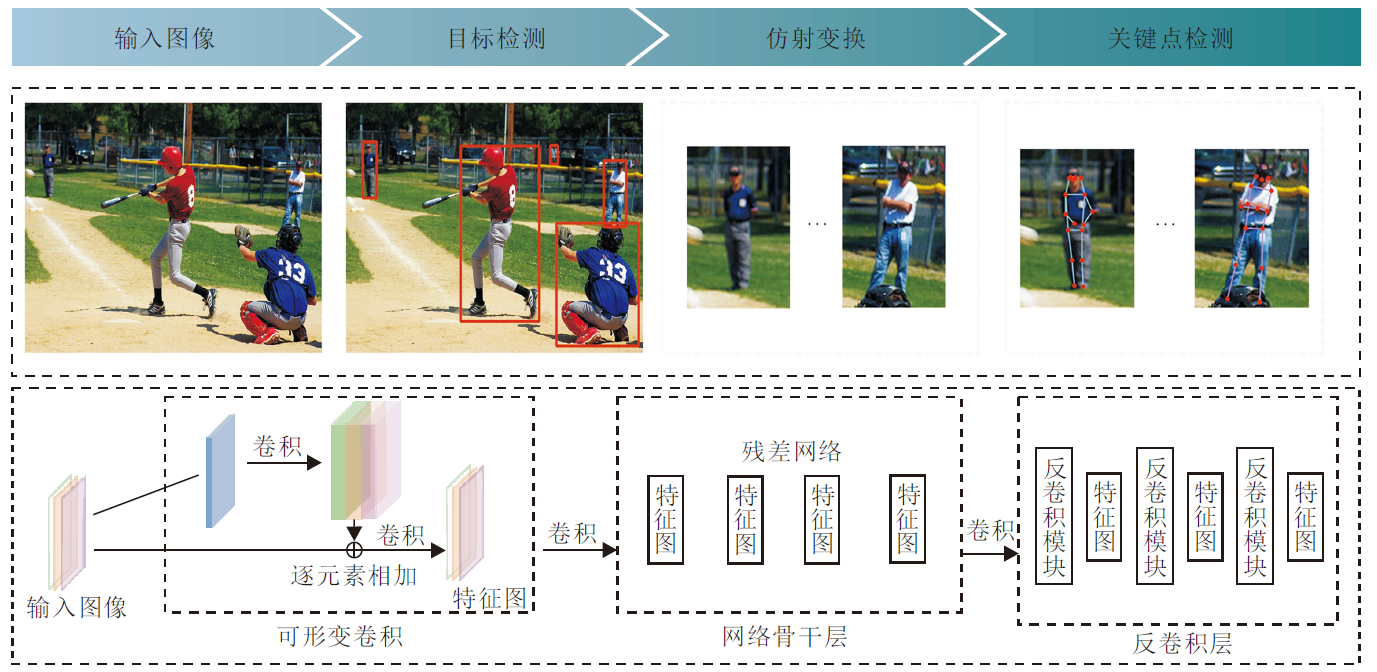 | 图1 本文模型框图Fig.1 Flow chart of the proposed model |
作为特征提取方法, 文献[12]将可变形卷积应用在网络的最后几个卷积层, 而本文采用的特征提取方法是将可变形卷积直接与输入图像连接, 生成特征图.实验表明, 这种特征提取方式可对人体关键点的几何变换有效建模, 并有效提升人体关键点的检测精度.
算法2 可变形卷积输出特征图的计算算法
输入 长度为b× h× w× c的原始特征图U,
普通的卷积核C
输出 M
V← Conv2D (U, C);
/* 将原始特征图U、普通的卷积核C经过普通的卷
积操作生成尺寸为b× h× w× 2c的特征图V,
V表示U中每个特征点的偏移量* /
P← addConv(V, U);
/* 原始特征图U、V相加生成偏移后的坐标值* /
P← BilinearInterpolation(P, U);
/* 使用双线性插值法, 计算偏移后特征图U中的
具体坐标值* /
M← getTargetImg(U, P); /* 生成输出特征* /
本文采用的可变形卷积是在标准的卷积操作之前给每个采样点加上一个偏移量, 使标准的卷积操作采样点发生偏移.最后, 使用标准的卷积操作, 对经过偏移的特征图操作生成输出结果.
对于输出特征图y上的每个位置p0:
y(p0)=
其中R表示对应输入特征图上的采样坐标.
在可变形卷积操作中, R上的每个位置都会经过偏移量{Δ p|n=1, 2, …, N}发生变化, 其中N=|R|.
目前采样点是在经过偏移的位置pn+Δ p上, 由于Δ p的值较小, 并可能产生浮点数, 因此通过双线性插值算法实现:
y(p0)=
本文使用ResNet作为网络骨干层, 对经过可变形卷积处理的输入图像进行基本的特征提取.Res-Net使用Residual Unit训练152层深的神经网络, 可加速超深神经网络的训练, 准确率也具有较大提升.
在ResNet卷积层的最后一层, 使用文献[9]中采用的反卷积层.该反卷积层可解决深度神经在深层网络中产生的特征图分辨率较低的问题, 并通过二维高斯函数生成表示概率的热图.反卷积层的结构如图2表示.
 | 图2 本文模型输出的热图Fig.2 Heatmaps output from the proposed model |
本文使用3个反卷积层, 其中每个卷积中都包含批量标准化及ReLU激活函数等操作, 每层中都有256个4× 4的卷积核, 步长(Stride)值为2.在反卷积层的末端, 使用1× 1的卷积核为每个关键点生成表示概率值的热图.通过一个二维的高斯函数生成的节点k的热图:
Hk=exp[-
其中, x0、y0表示第k个节点的真实位置, σ 表示值为3的超参数, yk表示由模型输出的预生成的热图.
最后, 使用均方误差(Mean Square Error, MSE)表示预测热图和由标注数据生成的热图之间的损失:
MSE=
其中tk表示由标注数据使用式(1)生成的热图.
数据集COCO关键点挑战赛是一个由微软赞助的多人人体关键点检测挑战赛.数据集分为训练集、测试集及正式比赛测试集, 包含超过200 000幅的图像及250 000个人体的实例.训练集有150 000多个人体实例及118 000幅图像, 每个人体实例都通过17个人体关键点标注.本文模型仅在训练集上训练生成, 并在验证集上获取对比实验的结果.
图3为本文方法在COCO数据集的测试集上的部分可视化结果.
 | 图3 本文模型在COCO dev-test数据集上的部分可视化结果Fig.3 Some visual results of the proposed model on COCO dev-test dataset |
与文献[18]相似, COCO关键点挑战赛定义目标关键点相似度(Object Keypoint Similarity, OKS), 并在10个OKS阈值上分别使用平均精度均值(Mean Average Precision, mAP)作为度量标准.OKS跟目标检测的交并比(Intersection over Union, IOU)类似, 计算预测关键节点与真值之间的距离, 并将该距离通过人体的尺度归一化生成:
OKS=
其中, di表示预测值与真值之间欧氏距离, vi表示真值的可见性标志, s表示目标尺度, ki表示每个关键点的控制参数.
本次实验对比方法如下:掩模候选框网络(Mask-RCNN)[12]、级联金字塔网络(Cascade Pyramid Network, CPN)[19]、针对野外场景多人精确姿态估计(Towards Accurate Multi-person Pose Estimation in the Wild, G-RMI)[6]、基于局部相似场的多人二维姿态实时估计(Multi-person 2D Pose Estimation Using Part Affinity Field, CMU-Pose)[20]、FAIR、G-RMI、oks、Bangbangren、CPN、SimpleBaselines.其中FAIR、G-RMI、oks、Bangbangren为COCO竞赛榜[15]中的方法, 各模型的具体实验结果如表1所示.在表中, 平均精度(Average Precision, AP)表示OKS=0.50, 0.55, …, 0.95这10个位置上的平均值, AP50表示OKS=0.5时的AP值, AP75表示OKS=0.75时的AP值.APM表示中等目标的AP值, APL表示大目标的AP值, AR表示OKS=0.50, 0.55, …, 0.95这10个位置上的平均查全率, * 表示模型使用额外的数据集, +表示模型己公开发布.本文模型未使用困难样本挖掘等方法进行训练, 实验结果是在测试数据集上提交生成.由表1可见, 本文模型性能更优.
| 表1 各模型在COCO test-dev数据集上的实验结果对比 Table 1 Experimental results comparison of different models on COCO test-dev dataset |
为了研究网络中不同模块及参数对实验结果的影响, 修改主干网络的深度、反卷积层卷积核的大小、输入图像的尺寸及上采样层的深度, 进行相关的消融实验.表2为本文网络模型设置为不同参数时在COCO val数据集上的消融实验结果对比.
| 表2 本文网络模型设置为不同参数时的消融实验结果 Table 2 Comparison of ablation experiment results on COCO val dataset with different parameters settings of the proposed model |
模型a使用3个反卷积层生成尺寸为64× 48的热图, 模型b使用2个反卷积层生成32× 24的热图.模型a比模型b在AP指标上提升4.2%, 所以反卷积层的深度默认设置为3.
模型a、模型c和模型d说明较小的卷积核尺寸会使AP值产生微小的变化, 所以反卷积的卷积核默认设置为4.
骨干网络ResNet设置为不同参数时在COCO val数据集上的实验结果如表3所示.在表中, 对比模型a和模型b、模型c和模型d、模型e和模型f的实验结果充分说明越深的骨干网络层具有越优的性能.对于输入尺寸为256× 192的图像, AP值从71.8%上升为74%, 对于尺寸为384× 288的图像, AP值从72.1%上升为75.0%.
| 表3 骨干网络ResNet设置为不同参数时实验结果 Table 3 Experiment Results with different parameters of ResNet on val dataset |
表2中模型a、模型g和模型h, 表3中模型a和模型b、模型c和模型d、模型e和模型f都说明输入图像尺寸对于性能具有较大影响, 表3中模型b的AP值比模型a提升0.3%, 但模型c和模型d、模型e和模型f的AP值提升分别为0.8%和1.0%.
本文提出自顶向下的基于可变形卷积的多人人体姿态估计模型.在使用目标检测模型检测人体实例的基础上, 引入可变形卷积对人体实例的几何变换有效建模, 使用ResNet有效提取图像特征, 并使用反卷积层对图像特征进行上采样操作.实验表明, 本文模型在准确度和效率方面较优.因此, 本文模型是可行、高效的.然而, 自顶向下的方法需要先对图像中的人体进行检测, 再进行人体关键点检测, 虽然准确率较高, 但是效率较低.如何在保持并提高准确率的同时, 进一步提高模型效率, 这是未来的研究工作.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|