
{kind=link}
{kind=link}
{kind=link}
{kind=link}
时序增强的视频动作识别方法
[张浩博1, 2  , 付冬梅
, 付冬梅1, 3 , 周珂4 ]
, 付冬梅, 周珂]
|
|



作者简介:

张浩博,硕士研究生,主要研究方向为深度学习、视频动作识别.E-mail:929817721@qq.com.

周 珂,硕士,高级工程师,主要研究方向为深度学习、图像识别.E-mail:zhouke@ustb.edu.cn.
针对视频动作识别中的时空建模问题,在深度学习框架下提出基于融合时空特征的时序增强动作识别方法.首先对输入视频应用稀疏时序采样策略,适应视频时长变化,降低视频级别时序建模成本.在识别阶段计算相邻特征图间的时序差异,以差异计算结果增强特征级别的运动信息.最后,利用残差结构与时序增强结构的组合方式提升网络整体时空建模能力.实验表明,文中算法在UCF101、HMDB51数据集上取得较高准确率,并在实际工业操作动作识别场景下,以较小的网络规模达到较优的识别效果.
AboutAuthor:
ZHANG Haobo, master student. Her research interests include deep learning and video action recognition.
ZHOU Ke, master, senior engineer. Her research interests include deep learning and image recognition.
Aiming at the spatio-temporal modeling in video action recognition, a temporal enhanced action recognition algorithm based on fused spatio-temporal features is proposed under the deep learning framework. To lower the cost of video-level temporal modeling, a sparse sampling strategy is employed to adapt to video duration changes. In the recognition stage, temporal difference between adjacent feature maps is calculated to enhance the motion information in the feature level. The combination of residual structure and temporal enhanced structure is introduced to further improve the representation ability of the network. Experimental results show that the proposed algorithm obtains higher accuracy on UCF101 and HMDB51 datasets and achieves better results in the actual industrial operation recognition scene with a smaller network scale.
本文责任编委 徐勇
Recommended by Associate Editor XU Yong
视频动作识别是视频理解的关键, 是计算机视觉中的重要研究内容, 在安防监控、无人驾驶、智能机器人设计等方面具有广泛的应用前景.相比静态图像, 视频除了具有图像空间信息, 还具有丰富的时序信息, 因此利用两种信息构建视频语义用于动作分类是动作识别方法设计的关键.
随着卷积神经网络(Convolutional Neural Net-works, CNN)在图像分类[1]、目标检测[2, 3]等任务中取得进展, 深度学习也成为动作识别的主流方式.由于CNN侧重于图像的外观表示, 因此利用CNN进行视频动作识别时, 关键在于同时建模视频中的运动信息.按照视频中运动信息建模方式不同, 基于深度学习的动作识别方法主要分为两类:利用光流信息显式表征运动信息的方法和利用卷积隐式建模运动信息的方法.
Simonyan等[4]提出双流2D网络, 运用输入视频的RGB图像和光流图, 分别训练两套2D CNN, 最终的动作预测结果为两套网络输出结果的平均值.虽然光流可表征运动信息, 但是由于其进行帧间像素级别的计算, 缺乏长期建模能力, 因此后续基于2D CNN的模型主要关注中间层的特征融合, 建模长时的时序关联, 扩展结构如时序分割网络(Temporal Segment Network, TSN)[5]、时序关联网络(Temporal Relation Network, TRN)[6]、时序三维网络(Temporal 3D ConvNet, T3D)[7]等.TSN应用稀疏时序采样策略, 在缩减输入运算量的同时提高网络的长时建模能力.TRN利用时间维度上的多尺度特征融合, 提高动作识别的鲁棒性.T3D采用密集连接的结构及组合不同时序窗的方式完成时序关联建模.上述方法中时序融合多集中在网络深层, 在底层特征提取时是帧间独立的, 并未考虑帧间的空间特征变化.
利用卷积隐式建模运动信息的方式得益于3D卷积[8]的出现, 利用3D卷积多出的深度通道完成在空间维度、时间维度的统一卷积.Tran等[9]提出三维卷积网络(Convolutional 3D Network, C3D), 虽然可在网络中同时提取时空特征, 但随着网络加深, 通道数增加, 特征计算代价变大.为了减少3D卷积的运算代价, 学者们提出2D+3D的混合结构[10, 11].高效卷积网络(Efficient Convolutional Network, ECO)[11]利用批规范化初始网络(Batch Normali-zation Inception)的浅层卷积结合3D网络Res3D-18的深层结构, 减少网络参数量.浅层发挥空间建模作用, 深层发挥时序建模作用.但是, 这样的设计忽略浅层特征中的时序关联.还有一些工作致力于将3D卷积分解为2D空间卷积与1D时序卷积[12, 13, 14, 15, 16].时序移位模型(Temporal Shift Module, TSM)[13]利用特征图移位操作代替时序卷积, 与残差结构结合进行时空建模.(2+1)D的方式虽然在一定程度上分解3D卷积的计算代价, 但时间维度与空间维度需要分开操作, 通常中间需要额外的变量存储或融合操作, 使时空建模统一.
考虑到算法效率及运算代价, 本文提出基于融合时空特征的时序增强动作识别方法, 设计基于2D卷积结构的时空特征提取网络, 避免3D卷积的计算代价.为了获取视频中的运动信息, 设计特征图层面的时序增强, 计算相邻时序特征图之间的空间差异, 加强网络的时序建模能力.同时通过残差结构和时序结构的组合将空间维度、时间维度结合应用, 使网络在不同深度都具备时空建模能力.实验表明, 本文方法通过时空特征提取后可关注动作发生的关键区域, 区分动作间的时序差异.
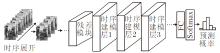
为了对视频中的动作进行时空建模, 本文设计时序差异残差网络(Temporal Difference ResNet, ResTD), 整体架构如图1所示.
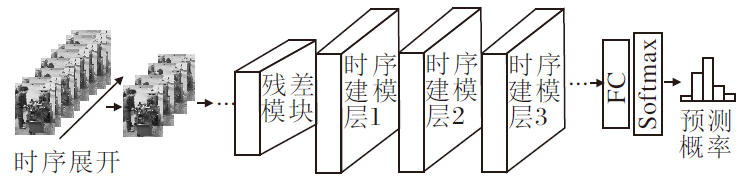 | 图1 ResTD结构示意图Fig.1 Network structure of ResTD |
ResTD主要分为3阶段.输入采样阶段、时空特征提取阶段、特征分类阶段.
1)在输入采样阶段, 为了覆盖输入视频的整体时序, 对输入视频沿时间维度展开, 进行稀疏时序采样, 组成具有时序顺序的序列图像, 作为网络训练输入.
2)在时空特征提取阶段, 主要完成空间特征与时序特征的统一提取.其中空间特征提取通过残差模块(ResNet Block)实现, 利用短路连接机制, 使网络加深时无损地进行梯度传播, 并且通过下采样操作, 使特征图空间大小减半.时序特征的提取通过时序建模层(Temporal Model, TM)实现, 利用特征级别的时序差异计算得到激活图, 用于增强特征的运动信息.
3)在特征分类阶段, 通过全连接层实现特征映射, 将时空特征提取阶段已编码好的高维特征映射为具有动作类别数目的分类特征, 应用Softmax激活函数将分类特征转化为概率表示, 与真实目标类别计算损失.
由于在连续视频帧中, 相邻较短时间内图像的外观信息并不会发生显著变化, 若通过密集时间采样得到视频帧, 帧间信息会存在大量冗余.因此为了去除冗余信息, 降低计算量, 同时适应不同序列长度的视频输入, 对视频样本进行稀疏时序采样.
稀疏时序采样具体过程如下.首先将视频样本沿时间维度进行等时长分组, 分组数目为K, 得到视频片段的组合{S1, S2, …, SK}.再从每个视频片段中随机抽取其中的一帧, 记为Ti, i=1, 2, …, K.最后将抽样得到的所有视频帧整体按照时序顺序排列, 得到具有K帧的输入图像序列{T1, T2, …, TK}.本文选取K=16.
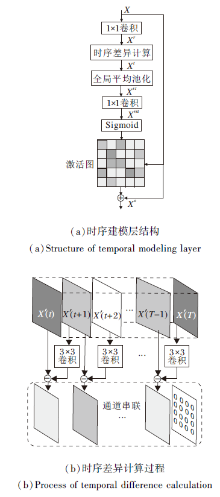
对动作的时序建模主要是提取视频中的运动信息, 直观上视频中的运动信息可理解为目标的运动趋势, 在光流图中以运动矢量表征.光流的获取需要对RGB图像进行像素级别的灰度差异计算, 这为视频的处理带来额外的计算代价.受光流计算方式的启发, 本文进行特征图级别的空间差异计算, 由时序差异模块(Temporal Difference Module)计算相邻时序特征图间的空间特征变化, 用于表征视频运动信息.另外, 将差异计算得到的特征向量通过Sigmoid转化为激活图形式, 与原始输入相乘进行时序维度上的增强.整体时序建模层结构如图2(a)所示, 其中时序差异计算模块是主要的功能部分, 实现细节如图2(b)所示.
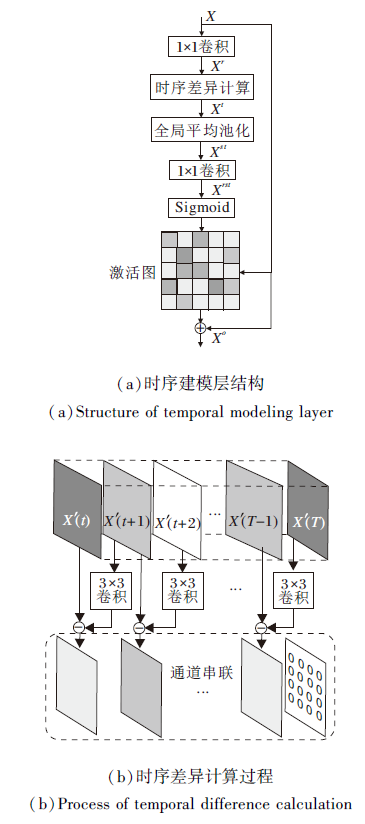 | 图2 时序建模层结构图Fig.2 Structure of temporal modeling layer |
时序建模层对于五维的中间层特征X(大小为[N, T, C, H, W])进行操作, 其中, N为训练批次, T为特征的时间维度, C为特征的特征图通道数, H、W为输入特征的空间维度.首先为了计算效率, 应用1× 1卷积将特征图通道数进行降维, 其中降维比例为r, 本文取r=4.得到通道降维后的特征记为Xr, 大小为[N, T, C/r, H, W].
为了计算特征级别的时序差异, 将降维得到的Xr沿着时序维度展开, 分别得到Xr(t), 大小为[N, C/r, H, W], t∈ [0, T].相比进行相邻时序间的特征图的直接相减, 利用3× 3卷积对t+1时刻的特征进行变换, 利用变换后的特征进行差异计算, 得到差异特征:
d(t)=Conv3× 3(Xr(t+1))-Xr(t), t∈ [0, T)
大小为[N, C/r, H, W].由于t=T时不存在下一帧内容, 因此d(T)=0.
将得到的所有差异特征按照时序顺序进行串联, 得到整体时序差异特征Xt, 大小为[N, T, C/r, H, W].由于空间维度并不对时序通道增强造成影响, 应用全局平均池化(Global Average Pooling, GAP)对整体时序差异特征Xt进行空间信息压缩, 得到空间压缩后的特征Xst, 大小为[N, T, C/r, 1, 1].对Xst进行通道恢复, 即通过1× 1卷积将通道C/r恢复为原来的C, 升维后的特征记为Xrst, 大小为[N, T, C, 1, 1].在特征Xrst上应用Sigmoid函数得到激活图, 相当于将时序差异信息转化成概率信息.再应用短路连接的思想, 利用激活图增强原始输入特征中的时序部分, 计算过程如下:
XO=X+M* X,
其中* 表示元素级别相乘.最终得到时序增强后的输出XO, 大小与原始输入特征X保持一致.
对动作的空间建模主要是对视频图像的外观信息进行特征提取, 而2D卷积具有良好的空间抽象能力.在主流2D CNN框架中, 残差网络[17]在图像的分类识别任务中取得良好效果, 因此本文利用带有短路连接机制的残差模块, 完成视频图像的空间特征抽象.
网络主体部分采用残差模块与时序建模层的串联结构, 如图1所示.首先通过残差模块完成下采样, 串联时序建模层进行时序增强.其中每个时序层对特征图通道数产生不同作用, 时序层串联后的输出通道数与残差模块的输出通道数保持一致.
对于内部时序层个数的设置, 本文验证3种设计方式, 如图3所示.
 | 图3 内部时序建模层的可能结构Fig.3 Possible structures of temporal module layer |
在图3中, 分别在残差块后串联1、2、3个时序建模层:
TM1=
各时序建模层对于特征图通道数的处理如下:TM1将输入通道降维成1/expansion; TM2不改变通道数; TM3对输入通道进行升维.本文设置通道扩充参数expansion=4.
对于图3(c)中3个时序层的结构, 最终输出通道恢复为原始输入通道.对于图3(a)、(b)中2种情况, 使用1× 1卷积将最终输出通道数升维成原始输入通道.
由于动作识别任务的本质是多分类问题, 因此本文网络损失函数设计为交叉熵函数.整体损失L由N个观测样本的损失值取平均值得到:
L=
其中:Li表示第i个观测样本的损失值; M表示动作类别数量; yic表示指示变量, 取值为0或1, 当预测类别正确时, yic=1, 否则, yic=0; pic表示观测样本i属于类别c的预测概率.
实验环境为Pytorch 0.4, 实验平台设置包括Intel(R) Core(TM) i5-8250U型号CPU(八核心, 1.8 GHz), 4块NVIDIA GeForce GTX 1080 Ti型号GPU(显存为11 GB), Ubuntu 16.04操作系统.
实验数据集包括公共数据集和自建数据集.公共数据集采用UCF101数据集[18]和HMDB51数据集[19].UCF101数据集包括101类人体动作, 共13 320段视频, 数据主要来源于网络视频及体育录像.HMDB51数据集包括51类人体动作, 共6 766段视频, 数据主要来源于电影片段及网络视频.
自建数据集使用从实际工业车间收集整理的车床加工操作视频.相比公共数据集中的人体行为, 车工动作具有如下特点:1)动作的发生与车床关键部件位置相关; 2)动作幅度变化小, 相比公共数据集的动作更细微; 3)动作具有很强的时序关联.
本文收集的车工动作视频样本来源于北京科技大学东区训练中心, 操作车床型号为CA6140, 是一种普遍使用的国标CA系卧式车床.CA系卧式车床在主体结构、部件分布位置、操作流程上具有相似性, 对CA6140型号车床的操作识别研究具有一定的推广作用.通过海康威视摄像机取得H.265编码、分辨率1920× 1080、帧率25帧/秒的原始视频, 对车床提取感兴趣区域(Region of Interest, ROI), 使画面中清楚呈现人员操作动作, 提取后视频宽高比像素比例在1∶ 1.3左右.
根据车床操作流程要求[20], 操作人员需要转动尾座, 使顶尖对装夹工件进行固定, 开车后通过变换溜板箱的转盘位置, 实现主轴箱和进给箱的变速, 进行纵横机动进给完成对工件的切削, 切削完成后停车, 通过游标卡尺对工件尺寸进行测量, 重复上述步骤直到切削满足要求.因此按照车工流程将人员操作划分为5个车工动作, 分别是尾座操作动作、开车动作、进给动作、关车动作、测量动作, 共收集644段视频, 123 256幅图像帧.对于尾座操作、测量、进给, 每个视频样本时长维持在10 s左右.开车、关车因动作迅速, 视频样本时长在2~4 s.与公共数据集中设置一致, 每个视频只包含1个动作.
对于公共数据集, 采用官方提供的第1种训练集/验证集划分方式.对于车工动作数据集, 按照7∶ 3划分得到训练集450段视频、测试集194段视频.训练阶段对输入图像进行预处理, 首先保持图像宽高比, 将图像较短边调整至256, 通过多尺寸随机裁剪, 使图像尺寸为224× 224, 进行随机水平翻转(概率p=0.5).测试阶段先进行尺寸调整, 使图像短边为256, 之后进行中心裁剪, 使图像大小为224× 224.
为了直观感受方法的有效性, 网络初始化不采用任何预训练权重, 从头训练, 采用Xavier权重初始化策略[21], 通过动量为0.9、权重衰减量为5e-4的小批量随机梯度下降(Mini-Batch Stochastic Gradient Descent, mini-batch SGD)优化算法更新网络参数, 批处理大小(Batch Size)设置为32.对于公共数据集, 初始学习率设置为0.1, 分别在30、60轮控制学习率降至原来的1/10.对于车工数据集, 初始学习率设置为0.01, 分别在20、60轮控制学习率降至原来的1/10.
为了验证残差块与时序层排列方式的有效性, 在车工数据集上进行消融实验, 结果如表1所示.Res{2, 3, 4}表示网络各层中残差块编号, TM{1, 2, 3}表示每个残差块串联的时序层个数.
| 表1 时序建模层不同组合方式的对比结果 Table 1 Result comparison of different combinations of temporal model layer |
由表1可看出:在串联两个时序建模层时, 达到最优的测试效果, 说明对于车工动作, 两个时序层可进行有效的时空建模; 串联3个时序建模层在训练中获得最高的准确率, 具有更强的拟合能力, 适用于动作种类更多的公共数据集.
在UCF101、HMDB51数据集上, 本文对比同样从头训练的动作识别方法:双流网络、C3D、TSN、时空通道相关性网络(Spatio-Temporal Channel Corre-lation Networks, STC)[22]、长时时序卷积网络(Long-Term Temporal Convolution Network, LTC)[23]、双路网络[24], 以2D ResNet-18结果作为对比基准.LTC、双路网络在HMDB51数据集上, 除了提供以RGB图像作为输入模态的结果以外, 还提供以光流(Optical Flow, OF)作为网络输入的准确率结果, 因为额外的光流计算通常可使网络获得更优的准确率.
表2为各方法在2个数据集上的准确率对比.由表可看出, 本文方法在不利用预训练权重初始化的情况下, 基于RGB图像, 在UCF101数据集上取得最高的准确率.同时在HMDB51数据集上, 对比其余RGB模态输入结果, 本文方法效果最优.这说明本文方法仅在RGB模态输入下, 就可更好地建模视频中动作的时空特征, 基于特征图差异的时序增强的优势得以显现.
| 表2 各方法在2个数据集上的准确率对比 Table 2 Accuracy comparison of different algorithms on UCF101 and HMDB51 % |
在车工数据集上对比TSN、C3D、ECO、TSM和本文方法.稀疏采样参数统一选取16帧.由于工业动作识别还需要考虑算法部署的可行性, 除识别准确率以外, 还需要考虑方法的计算复杂度、内存开销、模型推理速度.本文采用浮点运算数(Floating Point Operations, FLOPs)[25]衡量方法的计算复杂度, 利用参数量表征内存消耗.对于推理时间的统计, 虽然在GPU上测试速度更快, 但是出于工业成本考虑, 本文在CPU上测试方法的视频推理速度(不考虑数据I/O), 结果如表3所示, 最后一列的CPU时长表示CPU下的平均视频处理时长.
| 表3 各方法在车工数据集上的实验结果对比 Table 3 Comparison of different algorithms on lathe action dataset |
由表3可知, 本文方法达到89.06%的最佳准确率, 相比其它方法, 在参数量、推理速度上占优.TSN作为典型的2D双流网络, 在仅有RGB输入模态时, 时序建模受限.C3D整体都采用3D卷积结构, 性能上具有一定提升, 但计算量上不具备优势.ECO采用2D+3D的组合方式, 在一定程度上减少方法计算复杂度, 但同时限制网络的时序建模能力, 只在深层特征图上提取时间通道特征.TSM与本文均基于ResNet50进行扩展, 但是模型结构、时间通道的操作存在本质差异.TSM完全采用残差网络结构, 保留16个残差卷积模块, 在其中添加内部时间维度操作.
本文方法仅利用3个残差模块, 串联时序层完成时间通道的处理, 缩减参数量.对比TSM中对特征时间维度的移动操作, 本文设计特征图差异计算, 增强特征时间维度, 不仅是简单的相减操作, 在时序建模效果上更具优势.
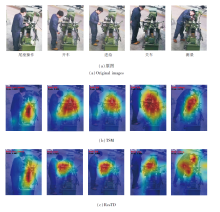
为了直观地观察动作识别效果, 基于类激活映射(Class Activation Map, CAM)[26]对车工数据集中5类动作进行可视化分析, 以热力图形式标注深度网络对不同动作的空间注意力.选取对比实验中效果最好的TSM与本文方法进行对比, 提取池化层之前的中间特征的可视化结果如图4所示.每幅图左上角标注预测的动作类别(红色)及预测概率(黑色).由图可知, 相比TSM, 本文方法可更精确地将注意力集中在动作发生的空间区域.TSM的激活映射区均集中在车床大范围区域上, 判断位置不够精确, 因此错误地将如开车、关车这样短时序的动作判断为进给动作.而本文方法的激活区域范围更收敛集中, 有助于做出正确的识别.对于其余三个动作, 本文方法也关注到动作发生的空间区域, 如车身的尾座滑轨、床鞍上的刻度转盘及装夹工件区域.
 | 图4 两种方法在车工数据集上的可视化结果对比Fig.4 Comparison of visualization results of 2 methods on lathe dataset |
基于视频的动作识别方法主要从时序建模与空间建模的角度设计特征提取网络进行分类, 本文设计具有时序增强的视频动作识别方法, 可同时进行空间及时序的建模.首先利用稀疏时序采样减少视频帧间冗余及统一视频样本的输入长度.再基于输入视频的RGB信息与时间维度, 设计差异增强的时序建模结构, 通过特征级别的差异计算加强对运动信息的编码.最后通过残差模块与时序模块的排列, 使网络在不同深度都具有时空建模能力.实验部分面向真实车间监控整理形成车工动作数据集, 相比目前较通用的动作识别方法, 获得更优的识别效果.为了进一步提高方法的识别性能, 今后可结合目标检测技术、视频流在线处理技术, 使动作识别方法在实时性、鲁棒性上得到加强.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|