




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
机器推理的进展与展望
[丁梦远1  , 兰旭光
, 兰旭光1 1 , 郑南宁1 ]
, 兰旭光, 彭茹, 郑南宁]
|
|



通信作者:兰旭光,博士,教授,主要研究方向为计算机视觉、机器学习.E-mail:

作者简介:丁梦远,博士研究生,主要研究方向为计算机视觉推理.E-mail:

彭茹,博士研究生,主要研究方向为基于计算机视觉的场景理解.E-mail:

郑南宁,博士,教授,主要研究方向为计算机视觉、模式识别.E-mail:
机器学习算法的发展仍受到泛化能力较弱、鲁棒性较差、缺乏可解释性等问题的限制.文中介绍机器推理,说明推理对于机器学习人的知识和逻辑、理解和解释世界的重要作用.首先分析人类大脑推理机制,从认知地图、神经元和奖赏回路,扩展到受脑启发的直觉推理、神经网络和强化学习.进而总结机器推理的方式及其相互关联的现状、进展及挑战,具体包括直觉推理、常识推理、因果推理和关系推理等.最后展望机器推理的应用前景与未来的研究方向.
About the Author:DING Mengyuan, Ph.D. candidate. Her research interests include computer vision reasoning.
PENG Ru, Ph.D. candidate. Her research interests include scene understanding based on computer vision.
ZHENG Nanning, Ph.D., professor. His research interests include computer vision and pattern recognition.
The development of machine learning algorithms are limited by the problems, such as weak generalization ability, poor robustness and lack of interpretability. In this paper, the important role of reasoning for machine learning human knowledge and logic, understanding and interpreting the world is illustrated. Firstly, the reasoning mechanism of the human brain is studied from cognitive maps, neurons and reward circuits, to brain-inspired intuitive reasoning, neural networks and reinforcement learning. Then, the current situation, progress and challenges of machine reasoning methods and their interrelationships are summarized, including intuitive reasoning, commonsense reasoning, causal reasoning and relational reasoning. Finally, the application prospects and future research directions of machine reasoning are analyzed.
随着1950年克劳德· 香农提出的计算机博弈[1]和1954年图灵提出的“ 图灵测试” [2], 人工智能这一概念在1956年的达特茅斯学院研讨会上被正式提出[3].近一个世纪以来, 如何让机器产生类似人类的智能成为研究者的关注焦点.在此期间, 人工智能经历三次浪潮, 第一次浪潮兴起于20世纪60年代, 标志性成就有自然语言处理[4]、人机对话[5]、知识库[6]等; 第二次浪潮兴起于20世纪80年代, 成果主要是大规模知识库[7]、非单调逻辑理论[8]、机器人学[9]和语义互联网[10]等; 第三次浪潮由2006年Lecun等[11]提出的深度学习开始, 延续至今, 成果有自动驾驶技术、自然语言问答工具、智能机器人等.
近年来, 机器学习的重要算法包括深度学习、自编码学习、自循环神经网络和强化学习[12].随着机器学习算法[13]的蓬勃发展, 人工智能在视听觉感知领域取得较大成果, 语音翻译软件、人脸识别系统、智能助手等应用的出现极大地改变人们的生活.此外, 人工智能已在很多领域媲美甚至超越人类水平.例如, 1997年“ 深蓝” 战胜国际象棋世界冠军[14]、2011年超级计算机沃森在智力竞猜节目中击败人类[15]、2016年Google开发的AlphaGo[16]战胜世界顶尖围棋棋手、2019年OpenAI击败Dota2世界冠军[17]等.
目前, 人工智能算法普遍在强监督学习、可微分和封闭静态系统下具有较好的实现效果, 对于系统鲁棒性较差、任务复杂、目标多样、样本数据不完善等情况并无合适的解决方案[18].例如, 人工智能算法依赖应用场景, 当场景的各种约束条件确定, 可调整好系统各项性能, 但如果更换场景, 就需要重新调整.这反映人工智能系统模型泛化能力较弱, 难于大范围扩展.同时, 大多数算法依靠数据驱动, 系统需要不断收集大量数据, 在应用中迭代优化, 开发维护成本也相应增加.此外, 人工智能系统除感知、运动外, 还需要理解、推理、自主决策等能力以解决复杂场景的困难问题, 这将是未来人工智能发展的首要任务[12].
从本质上讲, 机器学习的方法[13]是采用关联驱动从大量数据中拟合并总结相关规律.但是机器不具备人类的推理能力, 因此很难区分数据中的因果关联和虚假关联, 当数据较少时, 模型就难以展现类似人脑的泛化性, 导致错误[19].为了实现强大的人工智能, 需要为机器配备推理能力, 帮助机器模拟人的推理机制以建模世界, 赋予机器从观察到的现象推断原因的能力, 实现可解释的稳定预测.
本文总结人类大脑推理机制, 由脑中的认知地图、神经元和奖赏回路, 扩展至人工智能中的直觉推理、神经网络和强化学习, 并给出当前受脑启发的机器推理计算模型.讨论并分析人工智能中各类推理方式及其进展和面临的挑战.展望机器推理的应用前景与未来研究方向.
推理是是人类求解问题的主要思维方法[20].思维通过探索发现事物的内部本质联系和规律性, 其中概念、判断和推理是人类认知的高级形式, 认知是人类或其他生物大脑运作的一个过程[21].人通过感官获取信息并存储在记忆中, 当某些事物或事件对人产生刺激, 使人产生联想或推导某些含义时, 推理就发生了.推理是人类利用已有知识或表征进行推论并得出结论的过程[20], 表征是一种传递信息的物理状态.推理基于知识和方法[22], 人类依靠大脑很快找到处理知识和其中复杂关系的方法, 但机器获取的知识可能不完整, 方法可能不正确.因此, 机器实现推理必须不断地获取或学习知识、不断地修改和更新方法, 并且需要像人一样考虑各种偏好.
根据上述概念, 机器推理是指尽管知识不完整或不一致, 但机器仍可模拟人类得出有意义结论的能力[22].机器推理对于人工智能的实现极其重要, 高级的推理能力可辅助机器人和人类无缝交流互动, 但实现机器推理是一个相当复杂并困难的问题, 目前还面临很多挑战.
机器推理存在的一个问题是如何处理过量的数据.随着计算机的发展, 我们处于一个信息爆炸的时代, 每天都在主动或被动地接受各种数据.据估计, 每人每天接收到的信息量已达到惊人的109, 这比目前机器推理系统使用的知识库的数据量还要大几个数量级[23].人工智能最困难的挑战之一就是如何将机器推理扩展到该级别上运行.目前已有方案开始尝试解决这一问题, 如将部分任务重新制定为更多紧约束的任务[24].
机器推理的实现还离不开深度学习[11]、知识图谱[25]和自然语言处理[26]等技术, 但这些技术的发展各自都面临很多问题.机器推理在获取知识、建模、理解和推理等各个环节涉及深度学习算法的泛化能力较差、算法多样化但缺乏统一的评测指标、系统鲁棒性较差、可解释性差较等问题, 这是当前制约机器推理技术发展的重要因素.知识图谱构建数据繁琐、复杂, 面对海量冗杂无序的知识如何进行建模、转换和关联, 至今仍是一项具备挑战性的任务.自然语言处理难以在标注数据稀缺的任务上发挥作用, 如何让机器具备思维和逻辑、像人一样掌握自然语言, 需要长期深入探索.
如何结合多种机器推理方法, 进而灵活处理现实世界的复杂问题也仍待研究.目前多种类型的人类推理方式已被不同程度地应用到机器推理系统中, 成为机器推理的一部分.但是现实世界中的问题和场景十分复杂, 人类推理需要解决的问题对于机器而言非常困难, 单一的推理形式不足以完成复杂的任务[22].因此, 人工智能除了在特定类型的推理任务上取得进展之外, 必须了解如何使各类推理相互协作, 使其优势相辅相成, 可在更泛化的条件下提供更好的性能和更准确的结论.如果能解决这一系列具有挑战性的任务, 机器推理将有助于研究并开发下一代人工智能系统.
2.1.1 大脑脑区及功能
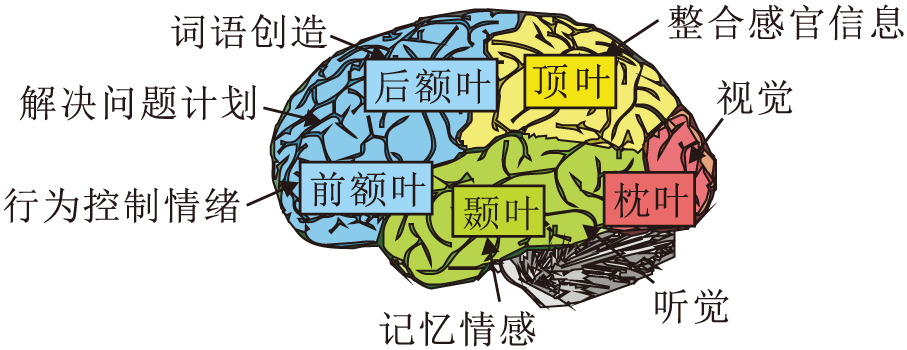
大脑作为中枢神经最复杂的结构, 由左、右两个半球组成, 都由大脑皮层覆盖.大脑皮层不仅可调节人类机体功能, 也是人类高级神经活动的基础, 如精神、意识、记忆、学习、语言等[27].Macneilage等[28]研究表明左、右大脑的功能各有区别:左侧半球主要控制人类的感觉区和运动区, 实现思维和语言活动; 右侧半球对辨认空间、音乐欣赏和深度知觉等非词语认知功能上有影响.
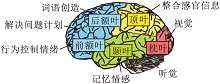
大脑脑区及功能如图1所示.大脑与认知思维有关的脑区有额叶、枕叶、颞叶、顶叶、海马体等[29].
 | 图1 脑区及功能Fig.1 Brain areas and their functions |
额叶控制人类的注意力、思维、判断等“ 高级认知” ; 枕叶能够感知视觉, 是主要的视觉皮层; 颞叶与记忆和情感相关, 可理解语言, 是主要的听觉皮层; 顶叶通过整合感官的信息实现空间导航; 大脑内部的海马体与记忆有关, 负责记忆的处理和存储等功能.
2.1.2 大脑双重过程理论与两种思维方式
认知心理学家Evans[30]提出双重过程理论, 用于解释人类大脑的两种不同处理方式, 这两种方式由一个隐性的无意识过程和一个显性的有意识过程组成, 称为直觉和分析.直觉是一个快速且自动的认知过程, 通常包含人类的主观情感, 倾向于产生受个人经验或知识背景的响应.分析涉及大脑的思考和记忆, 速度较慢且不稳定, 受人类的自觉判断和态度影响, 趋向于缓慢和规范性的响应.
双重过程理论表明人类大脑中存在两个截然不同的认知思维系统, 这两个系统在人类成长过程中共同进化发展, 但存在功能上的差异.Kuo等[31]的研究表明:大脑在处理分析“ 可解释问题” 时, 额中回、顶下小叶和楔前叶的激活程度更高; 在完成直觉的“ 纯协同任务” 时, 脑岛、前扣带回的激活程度更高.由此通过认知神经科学的角度论证人类具有两种思维的神经机制.
推理是人类求解问题的主要思维方法[20], 从双重过程理论[30]的角度, 按照直觉和分析, 可将人的推理分为直觉推理和逻辑推理.直觉推理是人类对某个问题不经逐步分析, 不受某种固定的逻辑规则约束, 仅凭自我感知迅速判断问题答案的能力[32].逻辑推理按照事物的类别、属性, 以逻辑的规律、方法和形式有步骤地从知识和条件中推导新的结论, 是经后天学习而获得的能力[33].逻辑推理分为归纳推理和演绎推理, 归纳推理可从特定的已知实例中得出对未知实例的推论, 演绎推理通过某种一般性原理和个别性例证, 得出关于该个别性例证的新结论.在演绎推理中, 临床和神经影像学的研究[34]表明, 与内容无关的推理由左半球引导, 而内容依赖的推理由右半球和双侧腹膜额叶皮层的区域引导.Stephens等[35]的研究发现, 双重过程理论中直觉和分析系统的不同类型有助于推理, 归纳推理受直觉的影响更大, 演绎推理受分析的影响更大.
2.1.3 大脑认知地图与直觉推理
人类认知世界需要理解空间概念, 并从中推导事物的抽象类别、属性及相互关系[36].人脑能够在过去的空间经验的基础上, 对周围环境和自身状态及关系构建一个可解释的认知模型, 即认知地图[37].认知地图可看作在先验知识上对局部环境的综合表征, 包含方向距离、事件顺序、事物关系、时间关系等.认知活动是实现推理的基础, 人脑通过认知地图评估和判断各种价值和风险, 进行一系列决策.信息加工理论认为, 这是获取外部信息、编码、存储、内部处理和解码的动态过程[38].
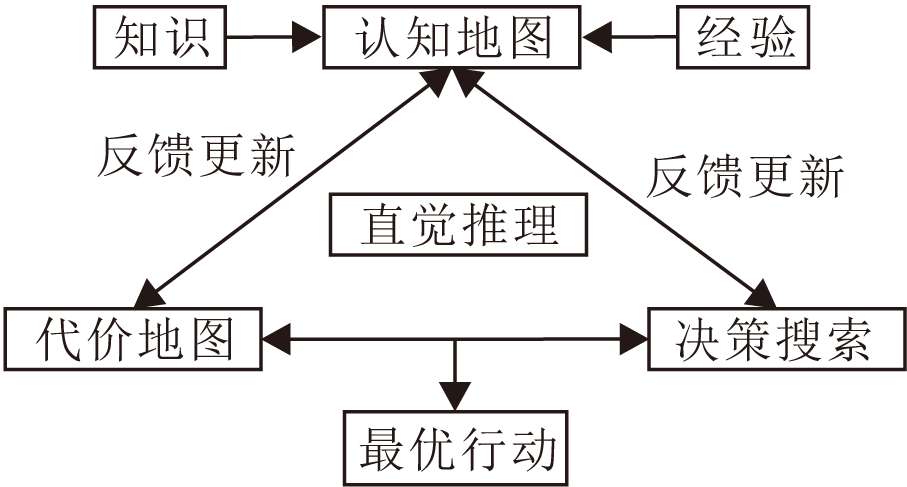
人的直觉推理基于知识和经验, 过程不仅受外部信息影响, 还受一些内在心理因素的影响, 如个人情绪、态度等[39].直觉推理需要认知地图, 人脑需要从中了解周围环境和发生的一切并做出决策.如图2所示, 人类通过日常生活中的知识和经验, 不断学习, 形成大脑的认知地图.在直觉推理中, 人脑会随机地在认知地图中进行搜寻, 希望得到最小代价和损失的有利决策, 一旦获得的决策能匹配当前直觉推理的任务, 人就做出对应的直觉反应.在这个过程中, 直觉的作用主要是构造代价空间并引导决策搜索[40].
 | 图2 基于认知地图的直觉推理Fig.2 Intuitive reasoning based on cognitive maps |
2.2.1 认知加工与神经网络
推理是认知加工的有效方式, 认知加工指人脑产生并利用心理表征, 按照一定的规则对信息进行转换的过程[21], 其中自下而上的加工基于物质世界的感觉信息, 在计算机中表示后验概率, 自上而下的加工由个人的知识、经验和预期驱动, 表示先验概率即预测.加工模型可使特定的输入产生相应的输出[41].图3表示判别一个外界刺激是否是人脑先前记忆中的刺激过程, 加工模型存在反馈不及时、无学习功能的缺点.
 | 图3 认知加工模型Fig.3 Cognitive processing model |
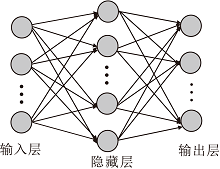
认知活动的建模可通过计算机程序执行, 模仿人类面对任务时的心理表征和加工[41].神经网络模型可解决加工模型的缺点, 是一种联结主义模型[42], 包含一系列相互联系的单元.如图4所示, 输入层负责从外界接收刺激, 每个从输入单元出发的联结都可激活或抑制一个隐藏单元, 并通过权重衡量对接收单元的影响力, 最终得到输出.
 | 图4 神经网络结构图Fig.4 Neural network structure |
神经网络的思路接近于大脑神经元的工作方式, 大脑的活动源于神经元的活动, 感受器官的输入会刺激激活神经元, 神经元进而刺激肌肉, 引发动作.神经网络通过学习、训练设计权重使之产生合适的输出.在给定不同于训练数据的输入时, 神经网络通过概括总结, 得到正确输出.
2.2.2 奖赏回路与强化学习
人类大脑可进行条件反射.如果人类的行为产生好的结果, 人类更可能重复这种行为; 如果导致坏的结果, 会避免该行为的重复.人的行为的本质是:诱因-行为-奖励, 其中奖励源于大脑的神经机制, 受神经递质多巴胺和大脑奖赏回路控制[43].当人类期待奖励时, 大脑回路会被激活, 多巴胺被释放.神经影响学的研究表明[44], 大脑的奖赏通路包括黑质、背侧纹状体、伏核及前额皮质等, 这些结构接受中脑腹侧被盖区的多巴胺传入神经纤维.
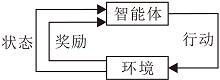
人工智能中强化学习的原理类似大脑的奖赏回路机制.如图5所示, 强化学习[45]主要研究在给定环境中, 智能体通过与环境的交互, 不断“ 试错” 进行学习以获得最大化预期收益.强化学习注重通过不断地与环境交互, 从而对动态环境进行探索.传统的决策理论, 如控制论、博弈论等可与强化学习进行有机结合, 探索人工智能下自动化决策框架.深度神经网络也可与强化学习结合, 形成处理大规模数据、解决复杂任务的有效方法, 如AlphaGo[16]求解围棋问题.
 | 图5 强化学习框架Fig.5 Reinforcement learning framework |
2.2.3 机器推理的计算模型
目前人工智能领域的一种观点[46]认为, 相比机器理性的计算, 人脑认知思维具备识别、概括和直觉推理的能力, 可独立思考并解决问题.那么能否构造新式的系统使机器真正实现推理并解决问题、让机器更好的模拟人类心智呢?为了解决这个问题, 需要探索如何构建大脑和计算机更精细的推理计算模型.
构建基于大脑推理机制的计算模型, 首先需要明确人类进行推理是在大脑提供的包含知识和经验的可解释模型, 即认知地图上, 进行价值和风险的评估和决策.人类通过认知加工获取针对特定任务的心理表征并进行信息加工和转换, 得到合适的输出, 其中选择性注意[47]可在复杂情况下深入加工当前感觉信息的一部分而忽略其它部分, 促进高效决策.人类通过多巴胺奖赏通路与环境交互得到反馈, 不断适应环境并改善当前的认知活动[43].
因此, 构建受脑机制启发的机器推理计算模型考虑的问题就是如何借鉴生物的推理模型, 整合多通道的感知计算、多模态信息的计算处理, 进行形式化表达并结合计算机的优势进行协同计算.
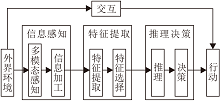
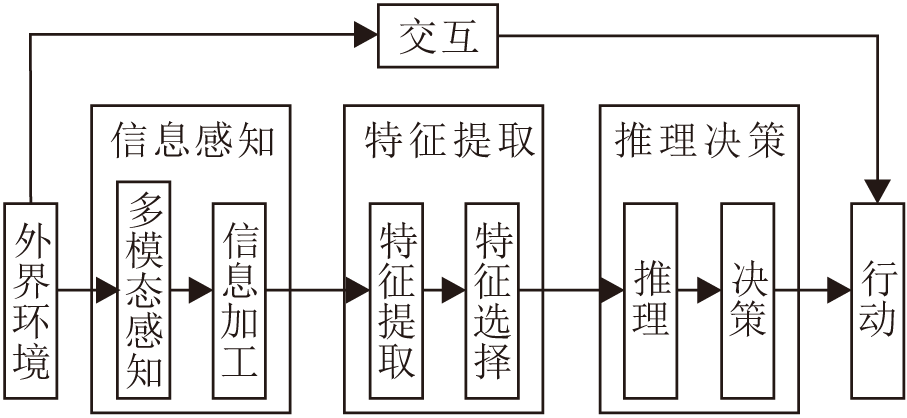
图6给出机器推理的通用框图, 架构主要分为三部分:信息感知、特征提取和推理决策.特征提取可通过神经网络实现, 推理决策部分结合强化学习可优化策略.在整体架构方面, 多模态的信息感知可得到外界环境中的图像、声音、味道等信息, 信息加工可进行信息的接收、存储、操作运算和传送[38], 特征提取可通过映射将高维的特征向量变换为低维特征向量, 特征选择能挑选一些具有代表性和分类性能好的特征, 再通过推理决策实现机器的推理过程, 还可通过决策行动与外界环境进行交互, 得到反馈, 进而优化机器的推理能力, 使机器逐渐逼近甚至超越人类能力.
 | 图6 机器推理框图Fig.6 Machine reasoning framework |
随着人工智能的发展, 多种类型的人类推理方式已被不同程度地应用到机器推理系统中, 成为机器推理的一部分.不同于人的推理方式的划分, 目前人工智能中机器推理没有明确的类别和方式对其进行划分, 不同的推理形式也常组合在一起完成困难复杂的任务.为了便于介绍人工智能中的机器推理, 本文介绍近年来取得较大进展的四种推理方式, 分别是直觉推理、常识推理、因果推理和关系推理.机器的直觉推理受到人的直觉推理的启发, 机器的常识推理、因果推理和关系推理需要借鉴人的逻辑推理, 机器因果推理包含演绎推理和归纳推理[48].
机器推理通常可看作是基于知识的推理[22], 主要以知识表达为必要前提, 通过数据分析和推理, 从现有的数据中获取新的知识和结论, 做出合理的决策规划.知识表达的形式多样[49], 如语义网络、知识库、知识图谱等.视觉知识作为知识表达的新形式, 包括视觉概念、命题、叙述, 能较好地表达场景和语义, 对人认知世界和推理十分重要[50].直觉推理基于知识和经验[36], 需要构造代价空间并引导决策搜索, 常用于解决具有复杂解空间的问题[40].常识推理需要基于世界知识或背景知识对日常遇到的场景中的问题和事物本质类型等分析推断[51], 常识知识描述默认每个人都知道的日常知识.因果推理从观察到的现象推断原因, 旨在了解常见事件或动作之间的一般因果关系, 需要基于先验因果知识[19].关系推理主要推理实体及其属性之间的关系[52], 需要基于物体关系知识.各类知识相互包含、融合, 各类推理相互联系.人类的直觉是根植于因果[19].因果也是一种关系, 因果、关系知识可以是常识, 常识可用于直觉推理, 常识和关系推理可用于因果推理.
人工智能在机器学习领域取得很多成就, 但现有的机器学习方法难以应用于真实环境中[13], 尤其是在复杂时变和较高不确定性的条件下, 例如环境感知信息有限、工作案例较少甚至无前例可循、问题的解空间存在多个较好的解等.虽然机器拥有远超出人类的符号计算能力和数据存储能力, 但仍不能解决上述问题.
相比机器, 人脑可通过直觉推理, 依赖认知地图、
代价空间和决策搜索, 根据已有知识和过去的经验做出合适决策.从数学计算角度, 对于复杂环境中特定问题的求解, 解空间通常是复杂、非凸、非结构化描述的, 人脑的推理过程就是根据各种约束条件在解空间中获得全局最优解[40], 而直觉推理可迅速找到一个有效求解的初始迭代位置, 该位置还将决定最终的迭代结果是否为全局最优.此外, 传统机器算法在复杂问题求解时会陷入局部最小值[53], 而受人脑机制启发的直觉推理可通过策略优化、行动反馈、赏罚机制等进行决策, 避免该类问题的发生, 提高人工智能的泛化能力.因此, 机器也应当具备这种直觉推理能力.
机器直觉推理的成功案例就是AlphaGo[16].AlphaGo于2015年由DeepMind开发, 并于2016年和2017年先后击败围棋世界冠军李世石和柯洁, 水准相当于围棋九段.在棋类游戏中, 1997年深蓝[14]战胜国际象棋世界冠军.但是围棋与其它棋类游戏不同, 存在极大的搜索空间和复杂的解空间, 利用计算机求解基本不能够达到穷尽, 因此解决棋类游戏的传统方法, 如穷举搜索或基于规则, 根本无法实现媲美人类棋手水准的程序.
为了达到真实的人工智能效果, AlphaGo采用直觉推理, 引入神经网络[42]和强化学习[45], 构建价值网络和策略网络, 实现对于“ 棋感” 的模拟[40].神经网络可处理当前的棋盘信息, 强化学习用于评估棋盘上各点落子的胜负概率, 即模型中价值函数的估值.AlphaGo通过已知的人类棋谱学习得到初始策略, 再经自我对弈优化策略网络.在人机对战中, AlphaGo通过蒙特卡洛搜索树[54]寻找若干手之后的可能走法, 同时采用价值函数、策略网络和快速走子方法评估并确定落子位置, 使机器能在围棋复杂的解空间中缩小搜索空间, 并通过多线迭代获得最优解[40].
随着AlphaGo的优化发展, AlphaZero[55]和MuZero[56]随之诞生.AlphaZero在AlphaGo的基础上将价值网络和策略网络合并成为一个网络, 能在仅获得游戏规则的情况下, 随机选定一个初始状态, 通过不断的自我对弈的强化学习实现超越以往的能力.MuZero不用学习相关游戏的规则, 而是通过预测策略、价值函数、即时奖励推算规划未来行为, 智能体可在内部创建规则, 实现最精确的规划.在竞技过程中, 通过机器观察学习, 事先不知道规则的MuZero可达到甚至超过已知规则的AlphaZero的水平.
AlphaGo等一系列成果表明直觉推理对于复杂问题求解的重要性.机器直觉推理的实现, 能够赋予机器有创造性的快速预测、判断和决策的能力, 适应于真实环境下的复杂问题.但是机器直觉推理目前也存在很多问题, 如在围棋游戏中如何将“ 棋感” 的直觉与游戏规则和棋谱等显性知识结合, 使机器具备关联记忆的能力.其次, 在采用强化学习实现直觉推理的过程中, 机器难于获取当前环境下合适的回报函数.此外, 机器学习算法中一直存在梯度波动、收敛速度和探索效率的问题需要解决.
早在人工智能概念[3]提出后, Mccarthy[57]于1958年提出让机器具备常识是拥有更高程度智能的必备条件.常识推理是人感知和理解世界的一项基本能力, 人工智能系统需要拥有对物理世界运行的一般理解、对人类动机和行为的基本理解和像成年人一样对普遍事物的认知[51].常识推理基于常识知识, 倾向于对日常事件进行判断.
Davis等[51]指出常识推理的挑战在于机器难以理解和规定一般或特定领域的常识知识, 并采用各种方式解决复杂的问题.要推动这一领域向前发展, 急需能够集成不同推理模式的方法及可定量衡量研究进展的基准和评估指标.近年来, 学者们已提出许多常识性推理基准.基准测试的领域广泛, 包括文字方面[58]、人为因果[59]、完整的叙述[60]等, 所有基准的共同点在于需要大量的背景知识.尽管各个基准评估的重点不同, 但其中大多数问题的结构相似:采用简短的文本描述提出的问题和几个可能的答案, 机器从中确定正确答案.常识推理的基准数据集可分为自然语言理解、知识问答、文本推理、似然推理、心理学推理和多任务推理[61].自然语言理解中存在多个表达指向同一实体的问题, 需要常识为决策提供依据, 代表数据集有Winograd Schema Challenge数据集[62].知识问答提出一些在任务中混合语言处理和推理技巧的基准, 如MCScript(Script Knowledge to Machine Comprehension)[63]、Commonsense QA(Ques-tion Answering Challenge Targeting Commonsense Know-ledge)[64].文本推理可根据常识知识推理句子之间的关系, 有SNLI(Stanford Natural Language Inferen-ce)[65]、SciTail(Textual Entailment Dataset from Science Question Answering)[66].似然推理侧重日常事件, 包含各种实践常识关系, 有Triangle-COPA(Triangle Choice of Plausible Alternatives)[67]、JOCI( JHU Ordinal Commonsense Inference )[68].心理学推理通过行为推理人类的情绪和意图, 需要社会心理学领域的常识知识, 如Story Commonsense[69]、Event2Mind(Com-monsense Inference on Events, Intents, and Reac-tions)[70].多任务推理代表数据集有GLUE数据集[71].
使用常识推理理解不完整的自然语言已被学者广泛研究, 同时还能与机器人结合实现自然语言指令.早期Bolt[72]提出的机器人系统可利用惯用的参考或指向手势理解人机交互环境中的人类指令.近年来, Prac[73]和RoboBrain[74]等机器人交互系统被提出, 这些系统利用世界知识理解自然语言指令.例如, Prac通过常识推理给出特定情景中最可能的可执行动作.
常识推理在计算机视觉方面也有很多应用, 如视觉问答、视频理解、场景图等.Wang等[75]提出基于视觉常识区域的卷积神经网络, 用于字幕和视觉问答等高级任务的视觉区域编码.Zareian等[76]从数据中获取视觉常识, 纠正场景图中由于感知错误引起的明显构图错误, 用于提高场景理解的鲁棒性.
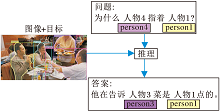
此外, 常识推理可用于检测图像的场景描述图[77], 该图通过语言模型可被直译成句子.在视觉常识推理(Visual Commonsense Reasoning, VCR)[78]任务中, 图7给定一幅图像, 要求机器回答有关理解视觉内容相关细节的问题, 还需要结合相关的视觉细节和背景知识进行上下文推理以说明答案是正确的.
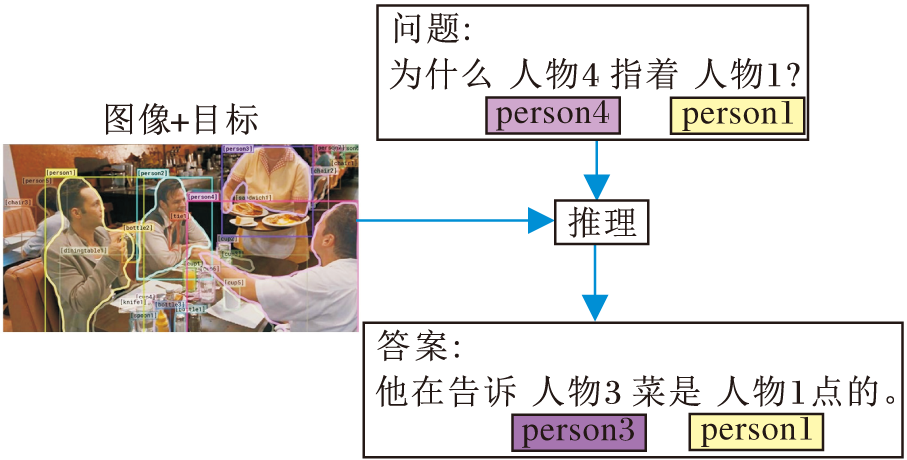 | 图7 视觉常识推理图Fig.7 Sketch map of visual commonsense reasoning |
此外, 常识推理还能与其它推理方法结合, Hou等[79]结合常识推理与关系推理, 用于理解视频内容并生成描述.如图8所示, 给出一幅很多人打着雨伞围在马路两旁的照片, 机器可推断这些人有可能是在围观一场比赛, 依据就是来源于人群围观和比赛之间的关联常识.
目前常识推理应用已十分广泛, 但它也面临许多挑战.对于很多人类能判断出来的常识和特例, 机器并不能轻易分辨.例如, 太阳每天升起这是一个常识, 学生每天吃一个苹果这属于特例, 但是机器很容易产生误判.人类能够轻易地进行判断是因为拥有足够的元知识, 而在为常识推理构建知识库时, 如何加入这些元知识就是一个难题.此外, 现有常识推理的评价主要是通过多项选择进行, 而机器构建的模型容易利用数据偏差得到高级评分, 只通过准确率去评价这些模型是不全面的, 并不能较好地反映模型的能力, 因此如何为机器构建一个合理的评价体系也是当前推进的重要工作之一.
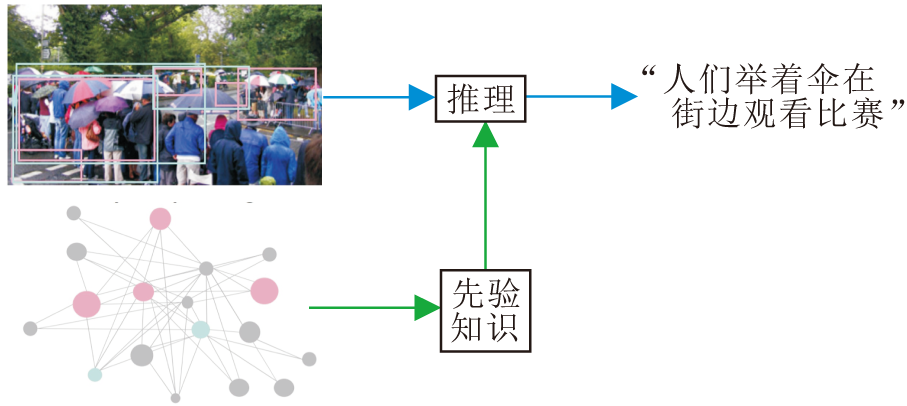 | 图8 关联常识判断示例Fig.8 Example of association commonsense judgment |
因果推理根据一个结果发生的条件对因果关系得出结论, 即从观察到的现象推断原因[80].计算机视觉系统擅长判断“ 是什么” 和“ 在哪里” , 常识推理引发一个有趣的问题“ 为什么” , 它依赖于在给定对象X的情况下观察对象Y的可能性, 当对象X的变化引起对象Y的变化时, 可认为X和Y之间有因果性[81].
计算机领域图灵奖得主Pearl[19]将因果关系分为三个层级, 分别是关联、干预和反事实, 当前的机器学习处于第一层级, 而人类通过想象可达到反事实层级.Pearl认为人工智能容易出错的根本原因就是现有的机器学习模型依赖关联驱动, 而机器很难区分数据中的因果关联和虚假关联, 解决问题的关键是使用“ 因果推理” 代替“ 因关联而推理” , 以便机器可使用适当的因果结构建模推理世界[19].为了实现强大的人工智能, 需要因果推理帮助机器学习数据中的因果关系, 实现可解释的稳定预测[82].
早期因果推理的研究集中在获取因果关系的知识方面, 主要从两方面进行.一方面是追求高精度的因果关系知识, 如因果关系网络(Causal Network, CausalNet)[83]通过收集因果关系术语对因果关系评分, 从极大文本语料库中挖掘因果模式.另一方面是使用数据驱动方法从文本中获取因果关系, 如概念网络(Concept Network, ConceptNet)[84]通过人工收集将因果事件编码为常识知识, Gordon等[85]的研究将个人故事作为因果关系的信息来源.
目前, 反事实推理作为因果推理的一部分也受到广泛研究, 反事实推理通过未发生的条件推理可能的结果.由于实际情况中测试数据往往与训练数据的分布不完全相同, 在因果推理中, 反事实分布一般与事实分布不同, 因此需要从实际数据中学习以预测反事实结果[86].Besserve等[87]提出非统计框架, 通过反事实推理揭示由纠缠的内部变量组构成的网络的模块化结构.Kaushik等[88]设计采用反事实操作文档的人在环路系统, 提出利用循环中的人的反馈消除虚假关联.
随着机器学习的发展, 因果推理可应用在自然语言处理、计算机视觉、强化学习等领域.因果推理能与自然语言处理结合, 从大型文本语料库中提取术语或短语之间的因果关系, 用于捕获和理解事件与动作之间的因果关系.Luo等[83]使用数据驱动的方法解决短文本之间的常识性因果推理问题, 提出自动从大型网络语料库中收集因果关系的框架, 可正确地建模各项之间的因果关系强度.
近年来, 计算机视觉和因果推理结合的研究激增, 并在图像分类[89]、视觉对话[90]和场景图生成[91]等方面进行探索, Wang等[75]提供图像的通用特征提取器.在图像和视频数据集推动下, 视觉推理问题已被广泛研究, 尽管这些数据集涵盖视觉的复杂性和多样性, 但推理背后的基本逻辑、时间和因果结构却很少被探索.从视频的物理事件中识别物体并推断其运动轨迹是人类推理的重要能力.如图9所示, 谷歌旗下人工智能公司DeepMind提出针对时间和因果推理问题的CLEVRER数据集[92], 通过简化视觉识别问题, 增强交互对象背后的时间和因果结构的复杂度, 从互补角度研究视频中的时间和因果推理问题.
 | 图9 CLEVRER数据集上的碰撞问题Fig.9 Collision of CLEVRER dataset |
因果推理还可应用于强化学习领域, 发现和利用环境中的因果结构对智能体是一项至关重要的挑战.Dasgupta等[93]通过无模型强化学习训练递归网络, 解决包含因果的问题.受过训练的智能体可从观测数据中进行因果推理, 并做出反事实的预测, 从而获得奖励, 这为强化学习中的结构化探索提供新的策略.
因果推理也面临许多挑战.对于机器学习而言, 获取的高质量数据越多, 越有利于通过学习和优化得到更精确的估计.但仅拥有更多的数据对于因果推理是不够的, 因为不能确保这些因果估计是无偏和正确的[91].近年兴起的因果表示学习[94]可直接从数据中学习信息, 而不用人工划分的先验知识, 即可直接获取真实世界的模型.但是这些因果模型中的变量是基本概念的抽象, 使用这些模型仍是一个难题.此外, 有效的训练数据也是因果推理的另一个难点, 在其应用的各个领域, 如医学, 现有的数据是有限的, 必须寻找、汇集编制数据的有效方法, 从而提升模型的效果.
关系推理可从知识图谱[25]进行理解.知识图谱是一种由节点和边组成的基于图的数据结构, 可连接不同种类的信息, 得到一个关系网络, 提供从“ 关系” 的角度去分析问题的能力.由于数据快速的更新迭代, 知识图谱是不完整的, 存在很多难以发现的信息, 需要关系推理帮助进行推断.
推理实体及其属性之间关系的能力对于一般的智能行为至关重要[52], 人工智能的符号方法本质上是关系型的[95], 研究者使用逻辑和数学语言定义符号之间的关系, 然后对这些关系进行推理.图10是CLEVR关系推理数据集[96]的示例, 关系问题需要对图像中四个对象之间的关系进行明确推理.
 | 图10 CLEVR关系推理数据集示例Fig.10 Example of CLEVR relational reasoning dataset |
人工智能领域有许多探索视觉方向关系推理的研究.早期的工作主要集中在特定类型的关系上, 如位置关系和动作关系[97], 通过较简单的启发式方法或采用手工特征提取这些关系, 再使用辅助组件完成相关任务.随着自然语言处理领域的发展, 可采用分类器和词组进行关系推理.Sadeghi等[98]将对象类别和关系谓词的每种不同组合视为不同的类, 即视觉短语, 但当视觉短语的数量十分庞大时, 机器性能表现并不如意.Fang等[99]合并比率关系到图像字幕框架中, 将对象类别和关系谓词统一地视为单词, 但未讨论如何解决关系检测中的各种挑战.Lu等[100]将成对检测到的对象馈送到分类器, 该分类器结合外观特征和语言, 用于关系识别.
深度学习的蓬勃发展使得关系推理结合神经网络的研究取得很大进步.DeepMind在2017年提出神经网络模块, 解决关系推理问题, 具有处理图像、文字等非结构化输入的能力, 同时可推理事物背后隐藏的关系[96].此外, Veli
关系推理除了应用在视觉领域以外, 关于物理系统的推理也是被广泛研究的领域.视觉交互网络[104]是一种在物理场景中进行预测的关系推理模型, 从几个视频画面中推理多个物体的状态关系并预测未来物体的位置.视觉交互网络还能预测几种物理系统, 如重力系统、刚体动力系统和质量弹簧系统.Van Steenkiste等[105]使用来自虚拟环境的训练实例, 以无监督的方式展示在发现对象及其相互关系方面的优异结果.
关系推理还可与其它推理或方法结合, Caden等[106]展示一个视觉问答中的多模态关系推理模型(Multimodal Relational Reasoning for Visual Question Answering, MUREL).Hou等[79]将关系推理与常识推理结合, 生成图像视频的文字描述, 较好地理解视频并生成描述.
关系推理在许多方面也存在着问题和挑战.首先, 现存的数据大部分都存在噪声和冗余, 并不能保证100%的准确性.如何从大量数据中分辨出这些存在歧义的点并将其合并是关系推理面临的难题.此外, 现实世界的数据很多都是未经处理的非结构化数据, 如文本、语音、视频等, 当数据量非常大的时候, 如何处理这些数据并提取有效信息, 将这些信息与推理算法结合也是非常关键的问题, 这对机器的关系推理能力提出更高的要求.
Stone等[107]认为到2030年, 会出现越来越多的人工智能应用, 包括更多的智能人机交互、自动驾驶技术、医疗保健诊断等, 并有望为人类生活提供各种帮助, 对社会和经济产生积极影响.人工智能发展的高级阶段就是让机器像人类一样进行思考, 赋予机器理解数据、知识表达、逻辑推理和自主学习的能力, 使机器可拥有类人的智慧, 甚至达到各个行业领域专家积累和运用知识的能力.随着大数据和机器学习等技术的快速发展, 研究者关注于在保持大数据的优势的基础上实现机器推理能力.
在当前的智能时代中, 机器可帮助或代替人类处理较复杂或困难的工作, 人工智能技术也越来越多的用于日常生活, 如智能推荐、智能搜索、精准预测等.在电商领域, 需要按照用户的购物习惯、检索频率和浏览顺序等对用户进行推荐, 而简单的识别图像、文字或视频并不能较好地利用各种多模态数据, 也难以满足用户的检索要求.如何采用机器推理技术对文本、图像、视频等多模态数据进行内容识别、关联分析和理解推理, 进而提高用户的有效检索, 实现对用户需求的精准把握与认知, 帮助用户做出更合适的决策, 这是目前人工智能领域发展研究的热点问题.此外, 在公共安全领域, 人脸识别仅能识别个人身份, 但是涉及到公安侦查、破案, 就需要对大量碎片化线索数据进行跨时间、空间的多维关联, 推理或预测可能的结果, 这是人工智能领域发展亟待解决的问题.
未来的人工智能将更全面地融合认知科学、脑科学、心理学等学科, 较好地模拟人类感知、思考、理解和推理的能力, 使机器具备高度的人类智能.综合现阶段机器推理的发展, 研究者希望未来可在百万和十亿个因素的大规模知识库中进行可靠的多模式推理, 以执行机器决策支持和设计人工智能相关任务.对涉及不同形式的推理进行深入的科学解释和理解, 建立一整套用于综合演绎和非演绎推理的开源方法, 通过各种机器推理方法逐步建立和维护成千上万个概念的成熟模型.最终使人工智能系统具备高度的认知能力, 适应复杂环境和场景, 更便捷地用于人类生活中.
本文介绍人工智能中的机器推理.首先通过大脑的生物构造和认知科学的双重过程理论分析人类的推理机制, 构建受脑启发的机器推理的计算模型, 再深入分析各类机器推理发展现状和面临的挑战, 展望未来的研究方向.由近年人工智能领域的成果不难发现, 人工智能正在朝着机器推理、可解释性的方向发展.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|
| [44] |
|
| [45] |
|
| [46] |
|
| [47] |
|
| [48] |
|
| [49] |
|
| [50] |
|
| [51] |
|
| [52] |
|
| [53] |
|
| [54] |
|
| [55] |
|
| [56] |
|
| [57] |
|
| [58] |
|
| [59] |
|
| [60] |
|
| [61] |
|
| [62] |
|
| [63] |
|
| [64] |
|
| [65] |
|
| [66] |
|
| [67] |
|
| [68] |
|
| [69] |
|
| [70] |
|
| [71] |
|
| [72] |
|
| [73] |
|
| [74] |
|
| [75] |
|
| [76] |
|
| [77] |
|
| [78] |
|
| [79] |
|
| [80] |
|
| [81] |
|
| [82] |
|
| [83] |
|
| [84] |
|
| [85] |
|
| [86] |
|
| [87] |
|
| [88] |
|
| [89] |
|
| [90] |
|
| [91] |
|
| [92] |
|
| [93] |
|
| [94] |
|
| [95] |
|
| [96] |
|
| [97] |
|
| [98] |
|
| [99] |
|
| [100] |
|
| [101] |
|
| [102] |
|
| [103] |
|
| [104] |
|
| [105] |
|
| [106] |
|
| [107] |
|