






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
深度多网络嵌入聚类
[陈锐1, 2, 3  , 唐永强
, 唐永强2 , 张彩霞1, 3 2 , 郝志峰1 ]
, 唐永强, 张彩霞, 张文生, 郝志峰]
|
|



通信作者:张彩霞,博士,教授,主要研究方向为人工智能、机器学习、数据挖掘.E-mail:

作者简介: 陈锐,硕士研究生,主要研究方向为机器学习、数据挖掘、计算机视觉.E-mail:

唐永强,博士,助理研究员,主要研究方向为机器学习、数据挖掘、计算机视觉.E-mail:

张文生,博士,教授,主要研究方向为人工智能、机器学习、数据挖掘.E-mail:

郝志峰,博士,教授,主要研究方向为人工智能、机器学习、数据挖掘.E-mail:
现有的深度无监督聚类方法通常局限于单网络结构设计,无法充分利用多种异构网络提取特征中蕴含的互补信息,制约深度聚类方法性能的进一步提升.为此,文中提出深度多网络嵌入聚类算法(DMNEC).首先,以端到端的方式预训练多个异构网络分支,获取各网络的初始化参数.在此基础上,定义多网络软分配,借助多网络辅助目标分布建立面向聚类的KL散度损失.与此同时,利用样本重建损失对预训练阶段的解码网络进行微调,保留数据的局部结构性质,避免特征空间发生扭曲.通过随机梯度下降与反向传播优化重建损失与聚类损失的加权和,联合学习多网络表征及其簇分配.在4个公开图像数据集上的实验验证文中算法的优越性.
About the Author:CHEN Rui, master student. His research interests include machine learning, data mi-ning and computer vision.
TANG Yongqiang, Ph.D., assistant professor. His research interests include machine learning, data mining and computer vision.
ZHANG Wensheng, Ph.D., professor. His research interests include artificial intelligence, machine learning and data mining.
HAO Zhifeng, Ph.D., professor. His research interests include artificial intelligence, machine learning and data mining.
Existing deep unsupervised clustering methods cannot make full use of the complementary information between the extracted features of different network structures due to the single network structure in them, and thus the clustering performance is restricted. A deep multi-network embedded clustering(DMNEC) algorithm is proposed to solve this problem. Firstly, the initialization parameters of each network are obtained by pretraining multi-network branches in an end-to-end manner. On this basis, the multi-network soft assignment is defined, then the clustering-oriented Kullback-Leibler divergence loss is established with the help of the multi-network auxiliary target distribution. The decoding network in the pretraining stage is finetuned via reconstruction loss to preserve the local structure and avoid the distortion of feature space. The weighted sum of reconstruction loss and clustering loss is optimized by stochastic gradient descent(SGD) and back propagation(BP) to jointly learn multi-network representation and cluster assignment. Experiments on four public image datasets demonstrate the superiority of the proposed algorithm.
无监督聚类[1]旨在对无标注数据的潜在分布结构进行分析, 进而将相似样本划分至同一簇内, 是数据科学和机器学习领域中的一个重要研究课题, 已成功在图像分类[2, 3, 4]、数据可视化[5]等众多现实场景中得到广泛应用.无监督聚类方法的性能很大程度上取决于数据的表征, 例如, 对于传统聚类方法K-均值(K-means, KM)[6]或高斯混合模型(Gaussian Mixture Model, GMM)[7]而言, 随着数据表征维度的升高, 相似性度量不再可靠, 致使聚类变得无效.针对这一问题, 一种直观的解决方案是首先利用降维技术, 如主成分分析(Principal Component Analysis, PCA)[8]、非负矩阵分解(Non-negative Matrix Factoriza-tion, NMF)[9]、多维缩放(Multiple Dimensional Sca-ling, MDS)[10]等, 将数据从高维空间转至低维空间, 再对降维后的数据进行聚类.然而, 典型的PCA、NMF、MDS等降维方法本质上属于线性模型, 难以深刻描述实际数据中蕴含的复杂分布结构.
深度神经网络作为一种非线性关系建模的有力工具, 可对输入的原始数据进行连续、非线性变换, 从而获得高质量的数据表征.其中, 自动编码器(Autoencoder, AE)[11]是深度神经网络的一种特殊形式, 以完全无监督的方式学习数据表征.AE基本原理为:首先将原始数据嵌入低维表征空间, 基于此空间重建原始数据.尽管AE在数据表征的非线性提取方面优势明显, 但其学习到的表征往往难以与数据的聚类结构相适配.
针对这一问题, 近年来, 学者们相继提出一系列深度无监督聚类方法, 旨在利用深度神经网络同时学习原始数据的表征及其对应的簇分配.Yang等[12]提出联合无监督学习(Joint Unsupervised Lear-ning, JULE), 结合卷积神经网络(Convolutional Neural Network, CNN)[13]的表征学习与层次聚类, 基于统一权重的三元组损失进行优化, 取得较优的聚类表现, 但计算复杂度较高.Xie等[14]提出深度嵌入聚类算法(Deep Embedded Clustering, DEC), 预训练自动编码器, 学习原始数据的低维表征, 在自学习辅助目标分布的帮助下迭代优化基于KL散度的聚类损失.Guo等[15]提出改进的深度嵌入聚类算法(Improved DEC, IDEC), 在DEC损失函数中加入重建项, 用于保留特征空间属性.Li等[16]提出判别性提升聚类(Discriminatively Boosted Clustering, DBC), 将DEC的预训练网络置换为CNN, 提取包含像素空间信息的高质量特征, 提升整体聚类性能.Yang等[17]提出深度聚类网络(Deep Clustering Network, DCN), 利用深度神经网络进行数据降维, 学习一个与KM算法相适配的潜在表征空间, 在此空间中交替优化网络参数、簇质心、簇分配.Fard等[18]提出深度K-均值 (Deep K-means, DKM), 对数据表征、簇质心及簇分配进行连续的端到端联合学习.Guo等[19]提出自适应自步聚类(Adaptive Self-paced Clustering, ASPC), 借鉴自步学习(Self-paced Lear-ning, SPL)思想, 优先利用高置信度样本训练聚类网络, 消除聚类边界样本的负面影响.Peng等[20]提出深度子空间聚类(Deep Subspace Clustering, DSC), 计算样本的稀疏重构关系, 保留样本的局部性子空间结构和全局性子空间结构.Chang等[21]提出深度自适应聚类(Deep Adaptive Clustering, DAC), 假设成对图像为二进制关系, 将聚类目标转化为二值成对分类问题.Bo等[22]提出结构化深度聚类网络(Structural Deep Clustering Network, SD-CN), 将图卷积网络融入聚类网络中, 旨在捕捉数据的结构化信息, 获取更具判别性的数据表征, 提升模型聚类性能.有关更多方法的介绍可参考文献[23]、文献[24].
尽管上述深度方法显著提升聚类性能, 但均运行于单网络结构环境下.DEC借助有效的辅助目标分布指导聚类, 取得良好的性能.但是, 基于单网络结构设计提取的表征质量不高, 导致初始化表现不理想, 经常出现数值不稳定情况, 最终难以获得优越的聚类表现.
众所周知, 同个网络结构的不同层提取的特征存在互补性:低层包含较多细节信息, 但是语义性较低; 高层具有较强的语义信息, 但是分辨率较低, 对细节感知能力较差.受此启发, 本文提出深度多网络嵌入聚类算法(Deep Multi-network Embedded Clus-tering, DMNEC), 旨在将DEC从单网络结构扩展至多网络, 捕获包含多种异构网络互补信息的高质量表征, 解决由DEC基于单网络结构设计引起的聚类性能不佳问题.同时, 为了避免特征空间扭曲, 进一步引入局部结构保留(Local Structure Preservation, LSP)机制.通过优化多网络表征与相应簇质心, 达成聚类目的.在MNIST[25]、USPS[26]、FMNIST[27]、COIL20[28]基准图像数据集上的实验验证本文算法的有效性和优越性.
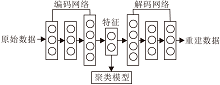
深度嵌入聚类(DEC)[14]框图如图1所示.
 | 图1 DEC框图Fig.1 Framework of DEC |
DEC包含两个阶段:参数初始化阶段与联合学习阶段.在参数初始化阶段, DEC首先使用3个去噪自动编码器(Denoising Autoencoder, DAE)进行逐层贪婪训练(Greedy Layer-Wise Training), 将编码层按顺序连接, 解码层按逆序连接, 形成一个堆栈式自动编码器(Stacked Autoencoder, SAE).然后, 以SAE作为基础模型, 将原始数据xi∈ RD映射至潜在特征空间, 用于学习低维表征zi∈ Rd, 再基于表征
Z={z1, z2, …, zn}∈ Rd×n
执行KM算法, 获取初始化簇质心μ j.在联合学习阶段, DEC移除SAE的解码网络gθ '(· ), 仅保留编码网络fθ (· ), 其中θ 表示编码网络的参数集.在t分布随机邻域嵌入(t-Distributed Stochastic Neighbour Embedding, t-SNE)[5]的启发下, DEC采用学生t分布(Student's t-Distribution)作为软分配, 度量低维表征zi=fθ (xi)与簇质心μ j之间的相似性:
qij=
其中, α 表示学生t分布的自由度, 通常取值为1.qij被称为软分配, 是因为它可解释为模型将第i个样本分配给第j个簇的概率.由于无监督任务中原始数据是未标注的, 所以DEC借助辅助目标分布pij, 通过提高软分配的高置信度以指导聚类.辅助目标分布的定义为
pij=
利用上述软分配qij和辅助目标分布pij, DEC优化如下基于KL散度的聚类目标:
L(zi, μ j)=
采用随机梯度下降(Stochastic Gradient Descent, SGD)与反向传播(Back Propagation, BP)迭代更新低维表征zi和簇质心μ j:
zi=zi-λ
其中λ 表示学习率.网络训练结束后, 未标注数据的簇分配为
si=arg
相比DEC, 改进的深度嵌入聚类算法(IDEC)[15]保留数据的局部结构, 框图如图2所示.
 | 图2 IDEC框图Fig.2 Framework of IDEC |
为了实现这个目的, IDEC保留解码网络, 目标函数为
L(zi, μ j)=
其中γ ≥ 0用于权衡重建损失与聚类损失的重要性.将重建损失加入目标函数中可避免嵌入空间出现大范围的扭曲, 较好地保留数据局部结构与特征属性.
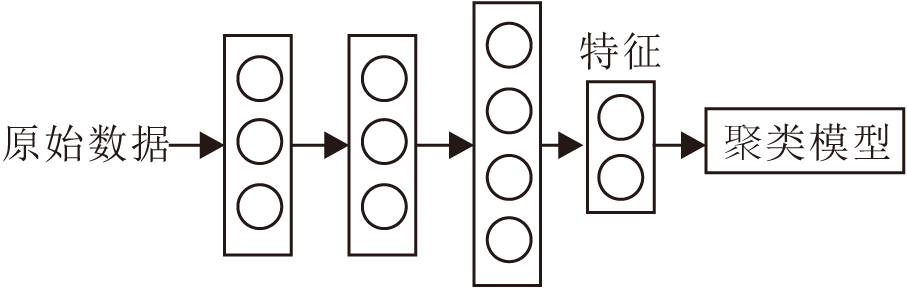
为了解决DEC基于单网络结构设计引起的聚类性能不佳问题, 本文提出深度多网络嵌入聚类算法(DMNEC), 旨在将DEC扩展为多网络结构设计, 提升聚类性能.与DEC相似, DMNEC也包含特征提取阶段和网络微调阶段.具体而言, 在特征提取阶段, 首先以不同结构的自动编码器作为多网络分支, 预训练多网络分支, 提取每个网络分支的潜在表示.再将潜在表示进行拼接融合, 得到包含互补信息的完备融合表示.基于融合表示执行KM算法, 得到初始化簇质心.在网络微调阶段, 引入多网络软分配及其辅助目标分布, 保留多网络分支的解码网络.基于聚类损失和多网络分支重建损失微调网络, 实现多网络分支特征和簇质心的联合学习.DMNEC框图如图3所示.
 | 图3 DMNEC框图Fig.3 Framework of the proposed DMNEC |
给定原始数据集
X={x1, x2, …, xn}∈ RD× n,
DMNEC使用多个非线性编码映射建模xi∈ RD与其潜在表示
其中, f
特征提取工作完成, 将多个低维特征
qij=
其中α =1表示学生t分布的自由度.由qij可推导对应辅助目标分布:
pij=
基于上述多网络软分配Q和辅助目标分布P, 以 KL(P‖ Q)作为聚类约束:
Lc=
受IDEC[11]启发, 进一步保留各个分支对应的解码网络, 保留数据特征属性.因此, DMNEC的损失函数如下:
L(
其中, γ ≥ 0用于平衡多网络分支重建损失与聚类损失.
基于上述损失微调网络, 可最大限度地避免扭曲特征空间, 最终实现对多网络分支特征和簇质心的联合学习.
通过随机梯度下降和反向传播优化L(
因此, 聚类损失Lc关于多网络分支特征
推导可得
在学习率λ 下, 簇质心
θ =θ -λ
θ '=θ '-λ
待所有参数优化完毕, 无标签样本的预测标签为
si=arg
DMNEC步骤如算法1所示.
算法 1 DMNEC
输入 数据集X, 簇数量K, 平衡系数γ ,
收敛阈值δ , 最大迭代次数T
输出 簇分配S
// 多网络分支预训练
for v={1, 2, …, n} do
根据式 (1) 初始化θ 、θ ', 获取低维表征
Z(v)=f
end for
// 质心初始化
基于Z(v)执行KM算法以获取簇质心M(v)
// 网络微调
for t={1, 2, …, T} do
根据式(2)更新辅助目标分布P
根据式(6)更新簇分配S
根据式(3)~式(5)更新簇质心
θ 、解码参数θ '
if 1-
满足收敛判别准则, 停止迭代
end if
end for
本文实验环境如下:操作系统为Linux.硬件平台为Intel(R) Xeon(R) E5-2640 v4@2.40 GHz CPU, 120 GB内存, 11 GB高速缓存, NVIDIA GeForce GTX 1080 Ti GPU.编程环境为Python 3.7.深度学习框架为Tensorflow 2.0.0-beta0.
在MNIST[25]、USPS[26]、FMNIST[27]、COIL20[28]图像数据集上评估DMNEC.MNIST数据集为经典手写数字识别库, 包含70 000个样本, 类别总数为10类, 图像大小为28× 28, 每幅图像中的数字都是居中状态, 已标准化处理.其中训练集包含60 000个样本, 测试集包含10 000个样本.USPS数据集包含9 298幅来自10个类别的灰度手写数字图像, 图像大小为16× 16.FMNIST数据集涵盖70 000幅来自10种类别的时尚产品正面图像, 图像大小、格式、训练/测试划分比例与MNIST数据集完全一致.COIL20数据集包含1 440幅来自20个类别的灰度实体图像, 图像大小为128× 128, 实验中将尺寸重置为32× 32.
上述图像数据集的属性描述如表1所示.特别说明, 对于已被划分为训练集和测试集的数据集, 合并后再进行实验.另外, 所有数据集的图像像素值都被缩放至数值区间[-1, 1], 以便神经网络更好地训练.
实验选用的对比算法如下:
1)传统聚类算法:KM[6]、GMM[7]、谱聚类(Spectral Clustering, SC)[34].
2)基于表征的聚类算法:SAE+KM、变分自动编码器(Variational Autoencoder, VAE)+KM、卷积自动编码器(Convolutional Autoencoder, CAE)+KM.
3)深度聚类算法:DEC[14]、IDEC[15]、DCN[17]、DKM[18]、ASPC[19]、SDCN[22]、深度散度聚类(Deep Divergence-Based Clustering, DDC)[35]、深度张量核聚类(Deep Tensor Kernel Clustering, DTKC)[36]、深度堆栈式稀疏嵌入聚类(Deep Stacked Sparse Embedded Clustering, DSSEC)[37].
| 表1 实验数据集 Table 1 Experimental datasets |
为了衡量算法的聚类性能, 采用如下3个聚类评价指标:聚类精度(Clustering Accuracy, ACC)[29]、归一化互信息(Normalized Mutual Information, NMI)[30]和调整兰德指数(Adjusted Rand Index, ARI)[31].
ACC计算如下:
ACC=
其中, n为样本数量, li为真实标签, ci为模型产生的预测标签, map(ci)为映射函数, 包含预测标签与真实标签之间所有可能的一对一映射.匈牙利算法(Hungarian Algorithm)[32]可有效计算最佳映射.
NMI是衡量2个聚类之间共享信息量的信息论度量, 较可靠地评价不平衡数据集聚类效果.NMI计算如下:
NMI=
其中, I(l; c)表示l和c之间的互信息, H(l)表示的熵值, H(c)表示c的熵值.
ARI是兰德指数(Rand Index, RI)[33]的修正版本, 计算如下:
ARI=
其中E(RI)表示RI的数学期望.
总体而言, 上述3种指标是评价聚类性能较常用的度量, 各有利弊, 将它们综合起来可更客观地说明聚类算法的有效性.ACC、NMI在[0, 1]内取值, 数值越大表示聚类性能越优; ARI在[-1, 1]内取值, 1表示最优的聚类表现, -1表示最差的聚类表现.
DMNEC设置3个多网络分支, 分别为堆栈式自动编码器(SAE)、变分自动编码器(VAE)和卷积自动编码器(CAE).对于第1个网络分支SAE, 编码网络结构为配备全连接层 (Fully Connected Layer) 的多层感知机 (Multi-layer Perceptron, MLP), 前向网络维度变化为
D→ 500→ 500→ 2000→ 10,
其中D表示输入数据的原始维度.对于第2个网络分支VAE, 编码网络结构为
con
其中:con
con
解码网络均为编码网络的镜像版本, 将编码网络置于解码网络顶部, 形成端到端连接的3个异构深度神经网络, 除了输入层、瓶颈层和输出层之外, 其它层均使用修正线性单元(Rectified Linear Unit, ReLU)进行非线性数值转换.
对上述3个多网络分支分别进行端到端的预训练, 次数分别为200、400、600, 采用自适应矩估计(Adaptive Moment Estimation, Adam)优化器(初始学习率为0.001)优化对应分支的网络参数, 批量大小设置为256.在后续微调网络过程中, 采用自适应梯度(Adaptive Gradient, Adagrad)优化器, 初始学习率设置为0.000 1, 批量大小设置为256, 平衡系数γ =0.1, 最大迭代次数设置为20 000.当满足收敛判别准则δ =0.001时, 停止迭代.
此外, 为了公平起见, 在4个图像数据集上对DMNEC进行10次随机重启, 求取各个指标的平均值, 将其作为最终实验结果.
各算法在4个数据集上的指标值对比如表2所示, 其中, 黑体数字表示最优结果, 斜体数字表示次优结果, -表示没有结果.
为了说明局部结构保留的重要性, 表2中也给出DMNEC在网络微调阶段的多分支解码网络移除后所得算法(简称为DMNEC w/o LSP)的结果.
由表可知:DMNEC在3个聚类评价指标上最优.特别地, 在MNIST数据集上, 相比ASPC、DSS-EC, DMNEC的ACC值分别提升7.5%、5.7%, 达到93.4%, 这表明DMNEC的优越性.在USPS数据集上, 相比SDCN, DMNEC的ACC值、NMI值、ARI值分别提升0.6%、3.4%、3.3%, 达到78.7%、82.9%、75.1%, 表明DMNEC性能较优.另外, 在小型数据集COIL20上, 相比ASPC, DMNEC的NMI值分别提升5.3%, 达到79.6%, 这表明DMNEC具备良好的泛化性能.
由表2可看出, DMNEC w/o LSP在4个数据集上均取得较优的聚类表现, 表明DMNEC在预训练阶段使用多网络分支, 可有效挖掘多种网络结构特征之间的互补信息, 学习更高质量的嵌入特征, 更好地衔接后续的聚类任务.此外, 在大多数数据集上, DMNEC性能优于DMNEC w/o LSP, 表明DMNEC在网络微调阶段保留的解码网络可一定程度上避免特征空间扭曲, 最大限度保留数据局部结构, 提升最终聚类性能.
| 表2 各算法在4个图像数据集上的指标值对比 Table 2 Comparison of metric values of different algorithms on 4 image datasets |
图4为DMNEC、DEC在MNIST数据集上的部分聚类结果, 随机筛选每簇中的10个图像样本进行可视化, 每行对应一个簇.
 | 图4 各算法在MNIST数据集上的部分聚类结果Fig.4 Some clustering results of different algorithms on MNIST dataset |
由图4可清晰地观察到, DEC经常混淆数字4、9, 说明DEC倾向于将手写数字集合聚为9类, 与实际类别数(10类)矛盾.而这一现象在图4(a)中未出现, 说明DMNEC可准确地将手写数字集合聚为10类, 反映DMNEC在聚类任务中表现更出色.
由于本文算法包含多个异构网络分支, 因此探究每个网络分支对最终聚类结果的影响.DMNEC配备3个网络分支:Net 1(SAE)、Net 2(VAE)、Net 3(CAE).图5为在USPS数据集上算法只考虑单个网络与同时考虑3个网络的ACC、ARI指标随迭代次数的变化情况.
由图5可观察到, 在迭代过程的各个阶段, 多网络模型的聚类性能明显优于任何单网络模型, 表明预训练阶段使用多网络结构, 可获取包含互补信息的高质量特征, 进而更好地衔接后续的聚类任务.
 | 图5 网络数量不同时指标值随迭代次数的变化情况Fig.5 Metric values variation with iteration times with different numbers of networks |
为了更直观的理解, 在此将预训练阶段使用单网络提取的特征和使用多网络提取的特征进行可视化, 如图6所示.由图可看出, 相比使用单网络提取的特征, 使用多网络提取的特征表现更佳的团簇结构, 说明多网络模型可捕获不同网络结构特征之间的互补信息, 充分反映数据潜在的聚类结构.
 | 图6 基于MNIST子集的异构网络特征鲁棒性可视化结果Fig.6 Visualization results of robustness of heterogeneous network features based on a subset of MNIST |
在FMNIST、COIL20数据集上的实验结果如表3所示, 这也验证上述结论.
| 表3 DMNEC在2个数据集上的消融实验结果 Table 3 Results of ablation experiment of DMNEC on 2 datasets |
本节分析DMNEC的收敛情况.首先使用t-SNE[5]对DMNEC在MNIST子集 (包含1 000个样本) 上的聚类过程进行可视化, 完整的聚类过程如图7所示.
由图7可看出, 原始数据点分布高度重叠, 这意味着聚类任务的艰巨.簇质心初始化后, 相比原始数据点, 预训练多网络分支提取的融合特征点更容易被分离, 但仍存在许多边缘样本点.随着微调网络的进行, 如在第140次迭代时, 同个簇中的大多数数据点都聚集在一起, 只有少数未被较好地分离.迭代过程继续进行, 当满足收敛判定准则时, 训练进程终止, 此时数据点分布已达到稳定状态, 较好地分离数据点, 簇内元素高度集中, 簇间间隔尤其明显.
 | 图7 DMNEC在MNIST子集上不同阶段的可视化Fig.7 Visualization of DMNEC on a subset of MNIST at different phases |
图8为DMNEC在MNIST、USPS数据集上的聚类指标随迭代次数的变化情况.
由图8可看出, 指标数值在最初的几轮迭代不断升高, 最后趋于稳定.
综上所述, DMNEC在通常情况下都可在一个较理想的局部极小值处收敛.
 | 图8 DMNEC在2个数据集上的指标值随迭代次数的变化情况Fig.8 Variation of metric values of DMNEC with iteration times on 2 datasets |
考虑到对深度模型的复杂度理论分析较困难, 在此采纳模型在某个数据集上的训练时长, 用于评价模型的复杂度.
表4为不同聚类算法在USPS数据集上的耗时与性能情况, 由表可看出, KM算法效率较高但性能较差.DEC、IDEC由于只涉及单个网络的预训练, 效率可观, 性能良好.特别地, DMNEC耗时为DEC和IDEC的8倍多, 这也反映DMNEC虽然性能优越, 但是多网络分支的预训练过程及解码网络的微调过程较耗时, 导致效率并不理想.
在今后的研究工作中, 将致力于改进模型的训练效率.
| 表4 各算法在USPS数据集上的耗时与指标值对比 Table 4 Comparison of time consumption and metric values of different algorithms on USPS dataset |
本文提出深度多网络嵌入聚类算法(DMNEC), 可联合学习包含互补信息的多网络特征及其簇分配.DMNEC包含2个阶段:第1阶段通过端到端地预训练多网络分支, 获取完备的鲁棒低维表征; 第2阶段定义多网络软分配, 借助多网络辅助目标分布建立面向聚类的KL散度损失.同时, 保留编码器的解码网络以保留数据局部结构, 最大程度地避免特征空间扭曲.最后基于多网络分支重建损失和聚类损失微调网络.在4个公开的图像数据集上的实验表明, DMNEC具有较优的聚类性能与良好的泛化性能.今后将会探究更有效的特征融合机制, 用于挖掘多网络特征之间更深层次的互补信息, 尝试在大型三通道场景数据集上进行实验, 探索更先进的深度多网络聚类算法.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|