
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于多模态表示学习的知识库补全
[汪璟玢1  , 苏华
, 苏华1 , 赖晓连1 ]
, 苏华, 赖晓连]
|
|



通信作者:汪璟玢,硕士,副教授,主要研究方向为知识图谱、关系推理、分布式数据管理、知识表示.E-mail:

作者简介:苏华,硕士研究生,主要研究方向为知识图谱、关系推理、知识表示.E-mail:

赖晓连,硕士研究生,主要研究方向为知识图谱、关系推理、知识表示.E-mail:
目前大多数知识图谱表示学习只考虑实体和关系之间的结构知识,性能受存储知识的限制,造成知识库补全能力不稳定,而融入外部信息的知识表示方法大多只针对某一特定的外部模态信息建模,适用范围有限.因此,文中提出带有注意力模块的卷积神经网络模型.首先,考虑文本和图像两种外部模态信息,提出三种融合外部模态信息和实体的方案,获得实体的多模态表示.再通过结合通道注意力模块和空间注意力模块,增强卷积的表现力,提高知识表示的质量,提升模型的补全能力.在多个公开的多模态数据集上进行链路预测和三元组分类实验,结果表明文中模型性能较优.
About the Author: SU Hua, master student. Her research interests include knowledge graph, relation reasoning and knowledge representation.)
LAI Xiaolian, master student. Her research interests include knowledge graph, relation reasoning and knowledge representation.
In most learning models for knowledge graph representation, only structural knowledge between entities and relations is taken into account. Therefore, the capability of the models is limited by knowledge storage, and the completion performance of knowledge base is unstable. Existing knowledge representation methods incorporating external information mostly model for a specific kind of external modal information, leading to limited application scopes. Thus, a knowledge representation learning model, Conv-AT, is proposed. Firstly, two external modes of information, text and images, are considered, and three schemes fusing external knowledge and entities are introduced to obtain multimodal representation of entities. Secondly, the performance of convolution is enhanced and the quality of knowledge representation as well as the completion ability of the model are improved by combining the channel attention module and spatial attention module. Link prediction and triple classification experiments are conducted on public multimodal datasets, and the results show that the proposed method is superior to other methods.
知识图谱作为人类知识的集合, 已成为许多人工智能和自然语言处理应用的重要资源, 如知识问答、网络搜索和语义分析等[1].知识库中的知识通常以三元组的形式存在.三元组表示为(head, relation, tail), 其中, head、tail表示实体, relation表示实体间存在的关系.目前常用的知识库有WordNet[2]、Freebase[3]、DBpedia[4]、YAGO[5]等.
知识库即使包含数十亿的三元组, 仍不完整.因此, 许多研究工作都致力于知识库的补全.知识库补全就是通过知识库中已存在的事实, 推理缺失的事实, 提高知识库的质量.知识库补全任务包括:1)链路预测[6].包括头实体预测和尾实体预测.头实体预测是在给定关系和尾实体的情况下预测头实体, 表示为(?, r, t).尾实体预测是在给定头实体和关系的情况下预测尾实体, 表示为(h, r, ?).2)关系预测[6].给定头实体和尾实体, 预测它们之间存在的关系, 即(h, ?, t).3)三元组分类[7].给定完整的三元组(h, r, t), 判断它是否为有效的三元组.
近些年, 出现各种各样的知识库补全方法, 基于知识表示学习的方法是目前知识库补全中一个活跃的研究领域.表示学习的关键问题是学习实体和关系的低维分布式嵌入[8].基于翻译的方法将每种关系看作是一个从头实体到尾实体的翻译.翻译嵌入(Translating Embedding, TransE)[9]是具有代表性的模型.针对三元组(h, r, t)中的实体和关系的嵌入, TransE认为应尽量满足h+r≈ t.TransE结构简单, 但在1-to-N、N-to-1和N-to-N复杂关系下, 容易出现语义上的悖论.Nickel等[10]提出RESCAL, 将知识库表示成三维张量, 通过两个实体表示向量和关系满秩矩阵的内积评估三元组.基于神经网络的表示学习模型, 以Dettmers等[11]提出的卷积二维知识图嵌入(Convolutional 2D Knowledge Graph Embeddings, Co-nvE)为例, ConvE首先连接头实体嵌入向量h和关系嵌入向量r, 并整合成一个矩阵, 再使用卷积进行特征的提取, 将特征进行全连接后, 与尾实体向量t进行点积, 得到三元组的评估结果.上述模型大多只考虑知识库中存储的结构知识, 补全能力受到显式存储信息的限制.
现实世界中的知识包含各种各样的数据类型.除了结构知识, 实体还拥有多种模式的知识, 如文本、图像、音频和视频等.这些不同模态的外部知识在一定程度上可丰富和扩充已有的知识库, 为下游任务, 如问答和链路预测, 提供更丰富的语义信息.
现有的融入外部信息的知识表示学习方法大多只考虑单一的外部模态信息.Xie等[12]提出包含描述的知识表示学习(Description-Embodied Knowledge Representation Learning, DKRL), 使用连续词袋(Continuous Bag-of-Words, CBOW)和卷积神经网络(Convolutional Neural Networks, CNN), 从实体描述中获得实体的嵌入, 在零样本学习(Zero-Shot)情况下, 也可对实体进行较好的建模.Xiao等[13]提出语义空间投影(Semantic Space Projection, SSP), 将三元组损失映射到由文本描述构建的语义空间中, 建立三元组和文本描述两者之间的强相关性.Veira等[14]考虑与知识图中的实体关联的两种不同形式的文本数据— — 实体描述和非结构化语料库, 提出加权词向量(Weighted Word Vectors, WWV)、参数效率加权词向量(Parameter-Efficient WWV, PE-WWV)和特征相加(FeatureSum)三种方法, 增强实体的表示.
上述方法在学习实体表示时只使用文本信息, 不考虑图像中包含的信息.Xie等[15]提出图像嵌入知识表示学习模型(Image-Embodied Knowledge Re-presentation Learning, IKRL), 融合图像信息, 帮助知识表示学习, 主要是从实体对应的图像中提取视觉表示, 用于扩展TransE.这类针对某一特定模态信息而建立的模型, 大部分都只在特定的环境下起作用, 并存在一定的局限性.Mousselly-Sergieh等[16]提出基于多模态翻译的方法, 考虑文本和图像两种外部信息.将知识库中三元组的能量定义为视觉、语言和结构知识表示的子能量函数的总和, 增强知识表示的能力.文献[16]模型使用文本和图像两种模态信息生成实体的多模态表示, 扩展翻译嵌入模型.虽然模型充分利用关系的平移性质, 但只使用简单的加法或减法, 计算实体和关系之间的语义联系, 在一定程度上限制模型的表达能力.
目前在知识图谱领域, 针对多模态融合的知识表示学习并不充分, 已有的方法未能充分利用不同模态间的互补特性, 并帮助模型获得更全面的特征.针对上述问题, 本文提出带有注意力模块的卷积神经网络模型(CNN with Attention Module, Conv-AT).首先, 在学习实体表示时, 在考虑结构知识的同时加入文本信息和图像信息, 提出三种不同融合方式, 获得实体的多模态表示.再在CNN中, 结合通道注意力和空间注意力, 增强卷积表现力, 使模型更关注那些对预测有帮助的信息, 提升模型的补全能力.在多个多模态数据集上进行的链路预测和三元组分类实验表明本文模型的有效性和稳定性.
本文将知识库定义为G={E, R, T}, 其中, E为实体的集合, R为关系的集合, T为知识的集合.一个知识也称为一个三元组(h, r, t)∈ T, 其中, h∈ E为头实体, t∈ E为尾实体, r∈ R表示关系.
本文定义3种不同模态的特征向量, 其中实体包含结构特征向量、文本特征向量和图像特征向量, 关系只有结构特征向量.具体定义如下:实体的结构特征向量estru∈
量eimage∈
本文的目标是学习一个评分函数
φ ∶ E× R× E→ score∈ [0, 1],
评估给定的三元组(h, r, t)是否为有效三元组.
Conv-AT整体架构如图1所示.本文方法由5个部分组成:多模态表示生成模块、卷积神经网络模块、通道注意力模块、空间注意力模块、输出三元组评分.
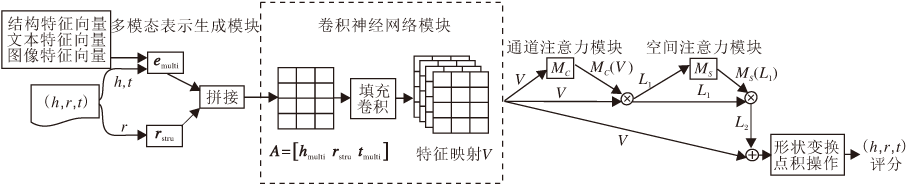 | 图1 Conv-AT整体框图Fig.1 Architecture of Conv-AT |
1.2.1 多模态表示生成模块
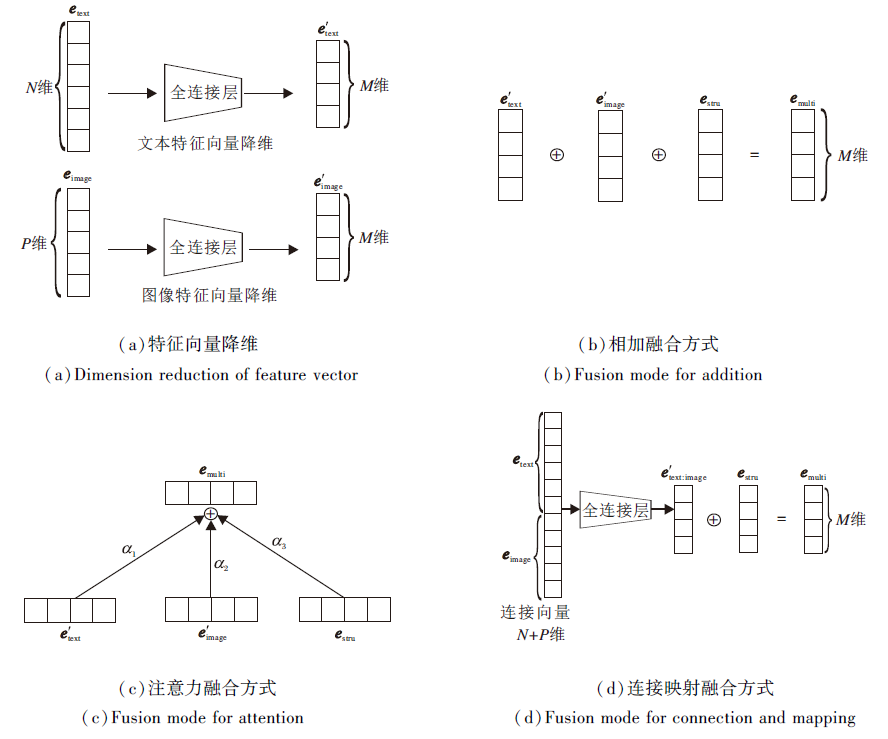
本文主要考虑结构知识及结构知识中实体对应的文本信息和图像信息.首先将实体对应的文本特征向量etext和图像特征向量eimage分别经过一个全连接层, 映射到与实体结构特征向量相同维度的空间中, 得到降维后的文本特征向量e'text和图像特征向量e'image:
e'text=etextW1+b1, e'image=eimageW2+b2,
其中, W1∈ RN× M、W2∈ RP× M为映射矩阵, b1、b2为偏参.具体如图2(a)所示.
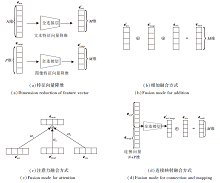
统一这些特征向量, 生成实体的多模态表示.本文提出3种融合方式:
1)相加(Add).将降维后的文本特征向量e'text和图像特征向量e'image、结构特征向量estru相加, 如图2(b)所示.实体的多模态表示定义为
emulti=e'text+e'image+estru.
2)注意力(Attention).简单地将实体对应的所有模态进行相加, 可能会带来一些噪声, 使部分特征失去重要信息.因此, 本文在相加的基础上提出基于注意力的多模态表示学习方法, 自动地从不同的模态信息中选择重要特征.具体操作如下:将文本特征向量、图像特征向量和结构特征向量在通道维度上进行拼接, 形成一个宽度为1、高度为M、通道数为3的特征映射, 作为卷积神经网络的输入.使用大小为1× M、输出通道数为3的卷积核, 在进行特征提取后, 经过激活函数Sigmoid, 得到每个模态特征向量的权重.将得到的权重与对应的模态特征向量相乘后再相加, 此时实体的多模态表示为
emulti=α 1e'text+α 2e'image+α 3estru.
具体操作如图2(c)所示.
3)连接映射(Connection and Map, ConMap).将实体对应的文本特征向量etext和图像特征向量eimage进行连接操作, 将连接后的向量经过全连接层, 映射到与实体结构特征向量相同的维度空间, 得到e'text; image.将降维的向量与结构特征向量estru相加.如图2(d)所示, 实体的多模态表示为
emulti=e'text; image+estru, e'text; image=[etext; eimage]W3+b3,
其中, [; ]为连接操作, W3∈ R(N+P)× M为映射矩阵, b3为偏参.
 | 图2 实体的多模态表示Fig.2 Framework of multimodal representation of entities |
1.2.2 卷积神经网络层
给定一个三元组(h, r, t), 使用实体和关系的结构特征向量对其初始化, 得到矩阵
A=[hstru, rstru, tstru]∈ RM× 3.
通过1.2.1节方式, 获得头尾实体的多模态表示, 得到矩阵
A=[hmulti, rstru, tmulti]∈ RM× 3.
同时为了捕获矩阵A的边缘信息, 对其左右边界填充0, 得到矩阵A'.使用大小为1× 3的过滤器ω , 有助于捕获头实体、关系和尾实体在相同维度下的交互特征, 经过卷积后获得和A形状相同的特征映射.过滤器的数量为τ , 对于第k(k=1, 2, …, τ )个过滤器, 生成特征映射Vk.Vk第i行第j列的特征
其中, ω
1.2.3 通道注意力模块
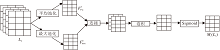
本文引入通道注意力和空间注意力, 帮助模型过滤噪声特征, 关注那些更重要的特征.将三元组特征映射V输入通道注意力模块Mc中, 获得每个特征映射的权重.具体操作如图3所示.首先将特征映射V分别通过平均池化(Average-Pooling, AvgPool)和最大池化(Max-Pooling, MaxPool)操作, 聚合每个特征映射的不同维度的信息, 得到
MC(V)=f(MLP(AvgPool(V))+MLP(MaxPool(V)))=f(Waout(Wahidden(
其中, Waout、Wahidden、Wmout、Wmhidden为MLP权重参数矩阵, f(· )为Sigmoid函数.
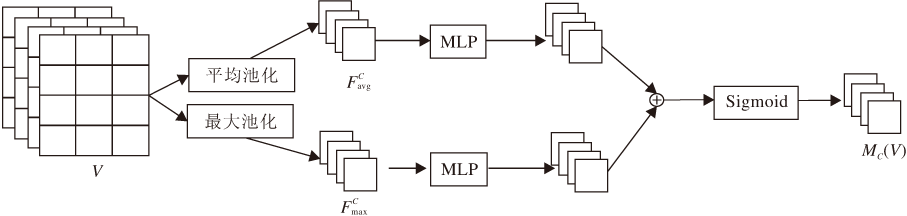 | 图3 通道注意力模块框图Fig.3 Flow chart of channel attention module |
1.2.4 空间注意力模块
将通道注意力模块得到的特征权重MC(V)和特征映射V进行元素乘法操作, 得到特征映射
L1=MC(V)V,
其中表示元素乘.
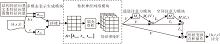
将特征映射L1作为空间注意力模块MS的输入.空间注意力模块可计算特征映射不同空间位置的权值大小.首先, 在通道维度上进行平均池化和最大池化操作, 聚合不同特征映射的通道信息, 得到
得到一个宽度为3、高度为M、通道数为2的特征映射.然后使用单个卷积核进行卷积, 卷积得到的特征映射与特征映射L1在空间维度上保持一致.最后经过Sigmoid层, 得到空间位置的权重.空间注意力模块
MS(L1)= f(convolve[AvgPool(L1); MaxPool(L1)])= f(convolve(
其中, [; ]为连接操作, f(· )为Sigmoid函数.
空间注意力模块具体过程如图4所示.
 | 图4 空间注意力模块框图Fig.4 Flow chart of spatial attention module |
1.2.5 输出三元组评分
将空间注意力模块计算得到的MS(L1)和特征映射L1进行元素乘操作, 得到特征映射
L2=MS(L1)L1.
再将L2与原始特征映射V按位相加, 经过形状变换操作(Reshape)后, 得到高度为3Mτ 、宽度为1的特征向量.然后与权重向量w∈ R3Mτ × 1进行点积操作, 得到三元组(h, r, t)的评分.本文将Conv-AT的评分函数F定义为
F(h, r, t)=reshape(L2V)w.
在训练的过程中, 最小化损失函数Loss, 损失函数为
Loss=
其中
lab(h, r, t)=
G为正确的三元组集合, G'为不正确的三元组集合, 是经过随机替换G中三元组的头实体或尾实体生成的, θ 为正则化参数, w为权重向量, ‖ ·
本文在如下3个多模态数据集上进行实验:WordNet Combined with Images(WN9-IMG)[16]、Freebase Combined with Images(FB-IMG)[16]和Freebase Combined both Image and Text(FB-IMG-Text).
1)WN9-IMG数据集.基于WordNet, 包含如下4部分:知识三元组、结构特征向量、实体文本特征向量和实体图像特征向量.结构特征向量使用TransE训练, 按照Bordes等[9]建议设置超参数值, 维度为100.实体文本特征向量使用扩展词嵌入模型(Extending Word Embeddings to Embeddings for Synsets and Lexemes, AutoExtend)[17]进行训练, 维度为300.实体图像特征向量的维度为4 096, 使用深度为19的视觉几何组模型(Visual Geometry Group, VGG19)[18]进行训练.
2)FB-IMG数据集.基于FB15K, 包含如下4部分:知识三元组、结构特征向量、实体文本特征向量和实体图像特征向量.对数据进行过滤, 删除出现在验证集和测试集但不出现在训练集的一些实体和关系.结构特征向量采用和WN9-IMG数据集结构特征向量相同的训练方式.实体文本特征向量维度为1 000, 使用单词嵌入模型[19]进行训练.实体图像特征向量使用中型架构VGG模型(VGG-Medium-128, VGG-M-128) CNN[20]训练, 维度为128.
3)FB-IMG-Text数据集.本文在FB-IMG数据集上添加Veira等[14]提供的实体描述和非结构化的语料库.对于实体描述, 使用与每个实体关联的维基百科文章的摘要部分.非结构化文本语料库使用谷歌新闻数据集, 然后运用词向量模型(Word to Vector, word2vec)对其进行预训练.FB-IMG数据集上实体的一些名称和维基百科文章不可用, 因此删除所有没有描述的实体及所有涉及它们的三元组.
3个数据集详细信息如表1所示.
| 表1 实验数据集 Table 1 Experimental datasets |
在训练期间, 使用自适应矩估计(Adaptive Moment Estimation, Adam), 学习率λ =1e-5, 5e-5, 1e-4, 批处理大小为256, 过滤器ω 初始化为正态分布或[0.1, 0.1, -0.1].过滤器数量τ =64, 128, 256.感知机隐层的缩小比率q=16.空间注意力模块中单卷积核大小为1× 3, 1× 2, 2× 3, 3× 3, 3× 2.θ =0.001.为防止过拟合, 在最后连接向量与权重向量点积前, 设置连接向量的丢失率为0.8和1.
Conv-AT的最优参数设置如下:学习率为1e-4, 过滤器初始化采用正态分布, 过滤器数量为128.空间注意力中卷积核大小如下:在WN9-IMG数据集上, ConMap为3× 3, Add为2× 3, Attention为2× 1.在FB-IMG数据集上, ConMap为1× 2, Add为3× 2, Attention为3× 2.
对比模型如下:TransE[9]、IKRL[15]、文献[16]模型、Veira等[14]的3种文本增强实体嵌入方式(WWV、PE-WWV、FeatureSum).对于IKRL和文献[16]模型, 采用文献[16]中表现最优的IKRL(Concat)和文献[16]模型(Concat), 作为结合多模态方法的对比实验.对于WWV、PE-WWV和FeatureSum, 只展示表现最优的基于TransE嵌入模型的结果.
本文使用链路预测和三元组分类任务评价模型补全能力.对于测试集中每个有效的三元组, 使用实体集E中的每个实体替换真实的头实体h或尾实体t, 这会产生包含有效三元组的假三元组集合.上述这种设置记为Raw.如果删除上述创建的假三元组集合中有效的三元组, 即那些出现在训练集和验证集的三元组, 那么这种设置记为Filter.
本文将平均排名(Mean Rank, MR), 平均倒数排名(Mean Reciprocal Rank, MRR), Hits@10, Hits@3, Hits@1作为链路预测的评价指标, 使用精确度作为三元组分类的评价指标.
1)平均排名(MR).包括两部分.(1)评估头实体预测.使用实体集E中的每个实体替换正确三元组的头实体, 使用评分函数计算假三元组集合中每个三元组的得分, 并将假三元组集合的得分按升序排列, 记录原测试三元组在其中的排名.(2)以相同的方式评估尾实体.将测试三元组中的头实体排名和尾实体排名进行平均, 得到最终的平均排名.
2)平均倒数排名(MRR).和MR计算方式相同, 求出每个三元组的排名后, 将头实体排名的倒数和尾实体排名的倒数求均值.
3)Hits@N.测试三元组集合中实体排名小于等于N的比例.正确的头实体或尾实体排名在前N个命中次数(Hit Count)加1, 再对头实体和尾实体的命中数求均值.
4)精确度.预测正确样本占总预测样本的比例.预测为正实际样本为正的个数与预测为负实际样本为负的个数之和除以所有预测样本的个数.
本文研究模型的4种设置:1)Base.只使用结构知识.在训练过程中, 实体和关系向量使用随机初始化.2)Add.使用结构知识, 同时在实体结构特征向量中以Add融入文本特征向量和图像特征向量.3)Attention.使用结构知识, 同时在实体结构特征向量中以Attention融入文本特征向量和图像特征向量.4)ConMap.使用结构知识, 同时在实体结构特征向量中以ConMap融入文本特征向量和图像特征向量.
各模型在WN9-IMG、FB-IMG数据集上的链路预测结果如表2所示.在表中, 评估方式为Filter, 黑体数字表示最优结果, 斜体数字表示次优结果.
| 表2 各模型在2个数据集上的链路预测结果 Table 2 Link prediction results of different models on 2 datasets |
由表2可见, 在WN9-IMG数据集上, Conv-AT(ConMap)在MRR、Hits@3和Hits@1指标上取得最优结果, 尤其在Hits@1指标上, 相比文献[16]模型(Concat), Conv-AT(ConMap)提高24.5%.采用ConMap的实体多模态表示模型在此数据集上表现优于本文提出的另两种模型.Conv-AT(Attention)的实验结果优于Conv-AT(Add), 说明注意力方法可自动选择不同模态中的重要特征, 过滤一些噪声, 帮助模型学习更有区分力的实体表示.
相比WN9-IMG数据集, FB-IMG数据集包含更多的实体和关系, 更复杂, 更接近于真实的知识图谱.在FB-IMG数据集上, 本文模型在MRR、Hits@10和Hits@3指标上最优, 表明本文模型的有效性.相比Conv-AT(Base), Conv-AT(Attention)的MR值提高66.4%, MRR值提高52.5%, Hits@10值提高22.7%, Hits@3值提高54.7%, Hits@1值提高89.8%.这显示实体多模态表示的好处, 可帮助模型学习更显著的特征.
为了进一步分析不同模型的特性, 参考文献[9]的方法, 对WN9-IMG、FB-IMG测试集上的关系类型进行统计.计算每个关系的平均头实体个数和尾实体个数, 将测试集划分为4部分:一对一关系(1-to-1)、一对多关系(1-to-N)、多对一关系(N-to-1)、多对多关系(N-to-N).如果平均个数小于1.5, 标记为1, 否则标记为N.例如, 对于一个关系, 头实体的平均个数为1.1, 尾实体的平均个数为2.5, 这个关系标记为一对多关系.2个数据集统计结果如表3所示.从统计结果可看到, 2个数据集的测试集包含较多的复杂关系, 即1-to-N、N-to-1和N-to-N关系.
| 表3 测试集关系类型统计 Table 4 Statistics of relational type on test sets |
WN9-IMG数据集上不同关系类型的链路预测结果如表4所示, 表中黑体数字表示最优结果.斜体数字表示次优结果.
由表4可见, Conv-AT(ConMap)在MRR、Hits@3和Hits@1指标上均有明显提升, 但在Hits@10指标上不如基线模型, 主要原因在于WN9-IMG数据集包含较少的关系, 文献[16]模型(Concat)能充分利用翻译嵌入模型的关系平移特性, 提升前10的命中率.
| 表4 各模型在WN9-IMG数据集的不同关系类型上的链路预测结果 Table 4 Link prediction results of different models for different relationship types on WN9-IMG dataset |
FB-IMG数据集上不同关系类型的链路预测实验结果如表5所示, 表中黑体数字表示最优结果, 斜体数字表示次优结果.本文模型在1-to-1、1-to-N和N-to-1关系类型上的预测结果总体优于文献[16]模型(Concat).但是在N-to-N关系类型的预测中, 本文模型出现部分负例三元组和正例三元组得分相同的情况, 使模型无法正确区分它们, 因此本文模型在该类型预测的Hits@1指标上不如文献[16]模型(Concat).
| 表5 各模型在FB-IMG数据集的不同关系类型链路上的预测结果 Table 5 Link prediction results of different models for different relationship types on FB-IMG dataset |
为了进一步评估不同模态的知识对实体表示的影响, 在FB-IMG、FB-IMG-Text数据集上进行实验.在FB-IMG-Text数据集上, 剔除图像模态, 将实体对应的结构特征向量和文本特征向量直接相加作为实体的多模态表示, 将这种方法记为Text.Ling和Vis为文献[16]中的实验设置, Ling表示仅使用文本特征向量作为外部模态, Vis表示仅使用图像特征向量作为外部模态.
本文与Veira等[14]提出的3种文本增强实体嵌入方式进行对比, 采用与其相同的评估方式Raw, 并设置相同的训练次数(200).链路预测结果如表6所示, 表中黑体数字表示最优结果, 斜体数字表示次优结果.相比3种文本增强嵌入方式表现最优的FeatureSum(TransE), 本文模型的MR值提高28%, MRR值提高15.4%, Hits@10值提高7%, Hits@3值提高10.7%, Hits@1值提高35.6%.IKRL是针对图像信息帮助知识表示学习而建模的, 当只有文本嵌入作为辅助模态时, IKRL(Ling)性能明显下降, 而文献[16]模型(Ling)和本文模型依然保持相对稳定的结果.一定程度上说明针对多模态建模的模型比针对单模态建模的模型更稳定.
| 表6 各模型在FB-IMG-Text数据集上的链路预测结果 Table 6 Link prediction results of different models on FB-IMG-Text dataset |
在FB-IMG数据集上, 剔除文本模态, 将实体对应的结构特征向量和图像特征向量直接相加作为实体的多模态表示.本文将这种方法记为Image.实验结果如表7所示, 表中黑体数字表示最优结果, 斜体数字表示次优结果.在FB-IMG数据集上采用Filter评估方式.
由表7可见, 本文模型最优.只加入图像表示的方法优于本文模型, 这表明图像信息可帮助Conv-AT捕获更显著的特征.另外可发现, 当文本特征向量或图像特征向量失去作用时, 基线模型的实验结果都有所影响, 而本文模型依然能保持较稳定的预测结果.
| 表7 各模型在FB-IMG数据集上的链路预测结果 Table 7 Link prediction results of different models on FB-IMG dataset |
为了分析通道注意力模块和空间注意力模块对模型预测能力的影响, 进行Conv-AT网络结构消融实验.在该项实验中, MCONV表示卷积神经网络模块, MC表示通道注意力模块, MS表示空间注意力模块.Conv-AT(MCONV)表示直接使用卷积神经网络模块提取的特征映射计算三元组的得分, 它是最基础的模型.Conv-AT(MCONV+MC)表示使用卷积神经网络模块和通道注意力模块得到的特征映射计算三元组得分.Conv-AT(MCONV+MC+MS)为完整的Conv-AT.本文进行链路预测任务, 使用Filter评估方式, 统一使用ConMap获得实体的多模态表示.
表8为2个数据集上Conv-AT网络结构消融实验的结果, 表中黑体数字表示最优结果, 斜体数字表示次优结果.
由表8可知, Conv-AT(MCONV+MC+MS)在链路预测的各项指标上均有不同程度提高.由此验证通道注意力和空间注意力可帮助模型捕获对预测更有帮助的特征, 提升模型的补全能力.
| 表8 Conv-AT网络结构在2个数据集上的消融实验结果 Table 8 Ablation experiment results of Conv-AT model network structure on 2 datasets |
根据给定的度量, 判断三元组(h, r, t)是否为正确的三元组.本文采用与文献[16]相同的评估方式:为每个关系学习一个阈值.当三元组的得分小于阈值, 认为它是正确的, 否则认为是错误的.使用验证集确认阈值.对于验证集和测试集上的每个正确三元组, 随机替换头实体或尾实体, 生成不正确三元组.对于三元组分类, 进行10次测试.本文给出三元组分类精确度的最大值、最小值、平均值和标准差, 如表9~表11所示, 表中黑体数字表示最优结果, 斜体数字表示次优结果.
| 表9 各模型在WN9-IMG数据集上的三元组分类精确度 Table 9 Triple classification accuracies of different models on WN9-IMG dataset% |
| 表10 各模型在FB-IMG数据集上的三元组分类精确度 Table 10 Triple classification accuracies of different models on FB-IMG dataset% |
| 表11 各模型在FB-IMG-Text数据集上的三元组分类精确度 Table 11 Triple classification accuracies of different models on FB-IMG-Text dataset% |
表9为各模型在WN9-IMG数据集上的三元组分类结果.由表可知, 本文模型最优.相比文献[16]模型(Concat), 本文模型的最高精确度提高1.3%, 平均精确度提高1.3%.表10为各模型在FB-IMG数据集上的三元组分类结果.表11为各模型在FB-IMG-Tex数据集上的三元组分类结果.由表10、表11可知, 在包含更多实体和关系的数据集上, 本文模型依然具有明显优势.为此, 对比基线模型, Conv-AT对于正确的三元组和不正确的三元组具有较强的区分力, 正确三元组的得分为负数, 而不正确三元组会得到一个正数的评分.
本文提出带有注意力模块的卷积神经网络模型(Conv-AT).结合通道注意力模块和空间注意力模块, 增强卷积表现力, 提高模型知识补全能力.另外, 在学习实体表示时, 在结构知识中加入文本描述信息和图像信息.本文提出3种不同的融合方式, 增强实体嵌入的特征, 并将它们作为表示学习模型的输入.链路预测和三元组分类任务的实验表明本文模型在评估任务和不同的评估数据集上的鲁棒性.今后将进一步改进模型在多对多关系中的预测能力.另外, 下一步将结合多模态信息进一步研究在少样本学习(Few-Shot)环境下的知识表示学习.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|