

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
局部协同视角下的鲁棒标记分布学习
[徐苏平1, 2 , 商琳1, 2  , 周宇杰
, 周宇杰1, 2 ]
, 周宇杰|
|



通信作者:商琳,博士,副教授,主要研究方向为机器学习、数据挖掘、计算智能等.E-mail:

作者简介:徐苏平,博士研究生,主要研究方向为机器学习、数据挖掘、计算智能等.E-mail:

周宇杰,硕士研究生,主要研究方向为深度学习、图像描述、图像分类等.E-mail:
已有标记分布学习(LDL)算法在一定程度上破坏不同标记间的关联性及标记分布的整体结构,同时,大多仅以提升标记分布的预测性能为目的,忽略计算代价和噪声鲁棒性在实际应用中的重要性.为了缓解上述不足,文中提出基于局部协同表达的标记分布学习算法(LCR-LDL).在LCR-LDL中,一个未标记样本可被视作由该未标记样本邻域构建的局部字典的协同表达,表达系数中的鉴别信息可用于重构未标记样本的标记分布.在15个真实的LDL数据集上的实验表明,LCR-LDL不仅可有效提升LDL的预测性能,而且具有较强的鲁棒性和轻量级的计算开销.
About the Author: XU Suping, Ph.D. candidate. His research interests include machine learning, data mi-ning and computational intelligence.)
ZHOU Yujie, master student. His research interests include deep learning, image caption and image classification.)
In the most of label distribution learning(LDL)algorithms, the correlations among different labels and the overall structure of label distribution are destroyed to a certain extent. Moreover, most existing LDL algorithms mainly focus on improving the predictive performance of label distribution, while ignoring the significance of computational cost and noise robustness in practical applications. To tackle these issues, a local collaborative representation based label distribution learning algorithm (LCR-LDL) is proposed. In LCR-LDL, an unlabeled sample is treated as a collaborative representation of the local dictionary constructed by the neighborhood of the unlabeled sample, and the discriminating information of representation coefficients is utilized to reconstruct the label distribution of unlabeled sample. Experimental results on 15 real-world LDL datasets show that LCR-LDL effectively improves the predictive performance for LDL tasks with a better robustness and low computational cost.
在机器学习[1, 2]与数据挖掘[3, 4]的研究中, 标记多义性问题受到广泛关注, 多标记学习(Multi-Label Learning, MLL)[2, 5, 6, 7]为处理一个样本可能同时属于多个标记这一多义性问题提供一种有效的技术手段.然而, 在MLL框架下, 与样本关联的所有标记都被视为同等重要.而在很多现实的应用中, 人们常期望获得描述某个特定样本时各个标记的相对重要性程度(标记集合上的一个分布).例如:在面部表情的情感分析[8, 9]中, 一个面部表情通常是由多种基本情感构成, 即愤怒、厌恶、恐惧、喜悦、悲伤和惊讶等.每种基本情感为构建面部表情做出不同程度的贡献, 所有基本情感下的贡献程度形成一个面部表情的情感分布.在电影评级预测[10, 11]中, 如果存在一个系统能够在电影上映前就准确预测电影评级的分布情况, 不仅有助于观众选择性地观看其最喜欢的电影, 而且可降低制片方的投资风险和时间成本.
尽管可通过设定一个较高(最高)的标记阈值, 将上述标记(情感、评级)分布问题转化入MLL框架, 甚至是单标记学习(Single-Label Learning, SLL)框架, 但这将丢失相关标记的相对重要的信息.Geng等[12, 13]提出标记分布学习(Label Distribution Lear-ning, LDL), 用于处理进一步的标记多义性问题.考虑到每个相关标记对样本的不同描述程度, 相比SLL和MLL, LDL可被视为一种更泛化的机器学习框架.
如今LDL大体上可分为3类:算法适应方法、问题转化方法和专门设计的方法.
算法适应方法直接修改一些约束条件, 用于扩展已有的SLL和MLL, 使其可处理标记分布问题, 如AA-kNN(Algorithm Adaptation: k-Nearest Neigh-bor)[12, 13, 14]和AA-BP(Algorithm Adaptation: BackPropagation)[12, 13, 15].
问题转化方法将LDL任务转换成多个SLL任务, 基于概率或置信度的SLL处理这些任务.例如, 将一个标记的描述度作为采样权值从原始的LDL数据中进行采样后, SLL中常见的基学习器朴素贝叶斯(Naive Bayes, NB)和支持向量机(Support Vector Machine, SVM), 分别被用于生成有代表性的问题转换方法PT-Bayes(Problem Transformation:Bayes)[12, 13]和PT-SVM(Problem Transformation:SVM)[12, 13].
专门设计的方法使预测的标记分布和真实的标记分布之间的相似度最大化, 直接聚焦标记分布的预测问题.SA-IIS(Specialized Algorithm:Improved Iterative Scaling)[14, 15]和SA-BFGS(Specialized Algo-rithm:Broyden-Fletcher-Goldfarb-Shanno)[12, 15]都是以Kullback-Leibler散度为目标函数, 构造最大熵模型, 分别采用改进迭代缩放(Improved Iterative Scaling, IIS)[16]和拟牛顿法BFGS[17]实施优化.LDLogitBoost(LogitBoost Based LDL)[18]采用Boosting策略, 借助数量递增的加权回归器(加权回归树)处理LDL任务.LSM-LDL(Least Square Method Based LDL)利用变换矩阵将每个标记视为样本特征的线性组合, 通过最小二乘法建立优化模型.现有的研究结果[11, 12]表明, 相比算法适应方法和问题转化方法, 专门设计的方法能更有效地处理真实的LDL任务.
尽管上述专门设计的方法在处理LDL任务中的标记多义性方面提升改进的性能, 却在一定程度上破坏不同标记间的关联性.保持标记分布的整体结构, 完整地保留标记间的关联性可能是一种提升LDL系统性能的有效方式.此外, 目前针对LDL开展的研究工作中, 很少有研究人员关注到LDL的计算代价及噪声破坏环境下的鲁棒性问题.
基于上述原因, 受到稀疏字典学习中表达/重构概念的启发, 本文提出基于局部协同表达的标记分布学习算法(Local Collaborative Representation Based LDL, LCR-LDL), 首先借助最近邻(k-Nearest Neigh-bor, kNN)规则搜索某一未标记样本的局部邻域空间, 再在l2范数的约束下, 使用邻域空间内全部样本构建的局部字典对未标记样本进行协同表达, 其中, 具有正表达系数的样本与未标记样本间存在正相关性, 它们的表达系数可直接被视为重构标记分布时的鉴别信息.然后, 引入映射函数ϕ (· , · ), 分别获得各个标记对该未标记样本的描述程度.最后, 采用归一化, 获得未标记样本的标记分布.在15个真实的LDL数据集上的实验表明, LCR-LDL不仅可有效提升对LDL任务的预测性能, 而且具有较强的鲁棒性和较优的计算效率.
从某种程度上讲, LDL是SLL和MLL的一种泛化形式.在SLL和MLL中, 对于一个给定样本, 全部可能的标记集合中的每个元素要么与其关联, 要么与其无关, 即学习系统建立在由“ 硬的” 1/0标识预定义的标记集合上, 1表示样本具有该标记, 0表示样本不具有该标记.特别地, 在SLL中预定义的标记是互斥的, 即每个样本仅能与单一标记关联.因此, 假设学习系统中存在p种可能的标记, 对于MLL, 共存在2p-1种可能的输出结果, 对于SLL, 共存在p种可能的输出结果.相比SLL和MLL, LDL拥有更丰富的标记形式, 即LDL可能的输出结果不再是一个标记集合, 而是所有p种可能的标记对应的多个实值描述程度, 反映全部标记在描述一个样本时的相对重要程度.
LDL的形式化描述如下.令X=Rm为m维的样本空间, Y={y1, y2, …, yp}为由全部p种标记构成的有限集合,
T={(xi, di)|i=1, 2, …, n}
为由n个已标记样本构成的LDL训练集.其中:样本
xi=[
表示为一个m维的特征向量;
di=[
是与xi关联的标记分布,
∀
成立, 这意味着所有标记能够完全描述xi.
值得注意的是, 对于一给定样本xi, di中的所有元素
由上述形式化定义可知, SLL和MLL可视作LDL的特殊情形.图1分别展示SLL、MLL和 LDL的标记分布示意图.SLL中xi仅与标记y2关联, 即y2可完全描述xi, 则有
满足
∀
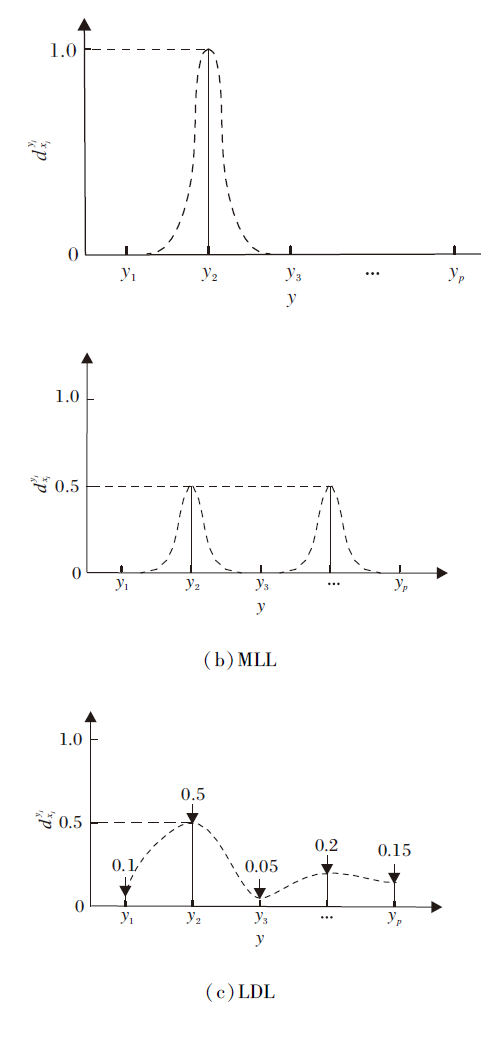 | 图1 SLL、MLL和LDL的标记分布示意图Fig.1 Label distribution of SLL, MLL and LDL |
在稀疏字典学习中, 一个过完备字典
X=
能由训练样本集合T构建.给定一个未标记样本x'i, 稀疏表达(Sparse Representation, SR)试图通过解决如下l0范数最小化问题, 获得一组表达系数:
其中, ε > 0 为误差容忍程度, ‖ · ‖ 0为一个给定向量中非零元素的个数.然而, 在大多数实际应用问题中, 式(1)构建一个欠定系统, 这意味着获得式(1)的精确解是一个NP难问题, 甚至很难被近似求解[19, 20].已有的研究工作[21, 22]表明, 如果表达系数
上式可视为经典的凸优化问题, 可被转换成一个由l1范数约束的最小二乘问题:
其中, λ > 0为正则化参数, 目的是平衡表达误差和α 的稀疏性.
Zhang等[23]研究表明, 不是l1范数最小化基于的稀疏性假设, 而是协同表达机制, 使SR在学习任务中变得有效.所有样本都应对表达一个未标记样本做出贡献.因此, 采用l2范数约束代替l1范数约束, 提出协同表达(Collaborative Representation, CR)[23, 24], 式(2)演变成:
其中λ > 0为正则化参数.由上式能推导出
其中I为单位矩阵.
在标记分布学习框架下, 一个标记分布信息矩阵
D=
可由训练样本集T构建.给定一个未标记样本x'i∈ X, 通过kNN规则生成包含x'i的k个邻居的相似空间δ (x'i).
在相似空间δ (x'i)中, 由式(3)获得一组表达系数
其中,
正的表达系数对应的样本与未标记样本x'i有正的关联性, 这些正的系数可直接视为重构x'i标记分布的鉴别信息.
根据鉴别信息和标记分布信息矩阵D, 可引入映射函数ϕ (x'i, yj), 获得yj(j=1, 2, …, p)对未标记样本x'i的描述程度, 映射函数
ϕ (x'i, yj)= $\sum^{k}_{μ=1}$ β μ
其中
β μ =
δ
根据假设“ 所有的标记能够完全地描述给定的样本” , 对全部标记的描述程度进行归一化操作.由上述分析可知, 基于局部协同表达的标记分布学习算法(LCR-LDL)包含4个主要步骤.首先, kNN规则被用于构建包含未标记样本的k个邻居的相似空间.再在相似空间内, 可通过协同机制计算得出一组表达系数, 并获得相似空间内的每个样本对于未标记样本表达的贡献程度.然后, 抽取重构未标记样本的标记分布过程中的鉴别信息, 获得每个标记对未标记样本的描述程度.最后, 执行归一化操作, 获得未标记样本预测的标记分布.LCR-LDL具体步骤如下所示.
算法 1 LCR-LDL
输入 过完备词典X=
标记分布信息矩阵D=
邻域尺寸k, 未标记样本x'i∈ X
输出 预测x'i的标记分布d'i
step 1 采用l2范数对X的每行进行归一化.
step 2 根据kNN规则, 从X中找出未标记样本x'i的k个邻居.
step 3 在δ (x'i)上对x'i进行编码:
其中, δ (x'i)∈ Rk× m是由x'i的k个邻居在X上抽取的数据矩阵.
step 4 由式(4)计算yj(j=1, 2, …, p)对x'i的描述程度ϕ (x'i, yj).
step 5 归一化ϕ (x'i, yj), 获得预测的标记分布:
d'i=
值得注意的是, 并没有声称kNN规则是部署局部策略最佳的方式.实际上, 相似空间δ (x'i)可通过其它的方式构建, 如采用聚类分析技术(k均值(k-means)、层次聚类分析(Hierarchical Clustering Analysis, HCA)、模糊C均值(Fuzzy C-means, FCM)等)识别与x'i属于同一类簇的相似样本.尽管如此, LCR-LDL采用最简单的局部策略也获得具有竞争力的预测性能.
LCR-LDL计算复杂度集中在step 3, 计算表达系数
其中,
B=δ (x'i)δ (x'i)T
的计算复杂度为O(mk2),
W=(B+λ I)-1
的计算复杂度为O(k3).此外, x'iδ (x'i)TW的计算复杂度为O(mk2)+O(mk).因此, LCR-LDL的总体计算复杂度是
O(k3)+O(mk2)+O(mk).
k被推荐设定为原始样本数量的1%~10%, 因此, 通常mk≪mk2成立, 可认为LCR-LDL的计算复杂度为O(k3)+O(mk2).相比其它最小二乘的LDL的计算复杂度O(n3)+O(mn2), 当k为n的1%~10%时, 显著降低LCR-LDL的计算代价.
为了评估LCR-LDL的有效性, 在15个真实的LDL数据集上进行实验分析, 它们源于LDL网站(http://ldl.herokuapp.com/download).表1 汇总实验数据集的基本信息.这15个数据集选自5种不同的实际应用领域:生物信息学、医学诊断、自然场景识别、面部表情识别和电影评级.
| 表1 实验数据集 Table 1 Experimental datasets |
由于每个样本同时与多个具有不同描述程度的标记关联, 相比SLL和MLL, 有关LDL学习器的性能评估更复杂.实验中使用如下6种标记分布评估度量[12]:切比雪夫距离(Chebyshev Distance)、克拉克距离(Clark Distance)、堪培拉测度(Canberra Metric)、KL散度(Kullback-Leibler Divergence)、余弦系数(Cosine Coefficient)、相交相似度(Intersection Simi-larity).
给定一个未标记样本x'i∈ X, 假设预测的标记分布
d'i=[
而真实的标记分布
6种评估指标的详情如下.
1)Chebyshev distance:
Chebyshev distance=maxj
2)Clark distance:
Clark distance=
3)Canberra metric:
Canberra metric= $\sum^{p}_{j=1}$
4)Kullback-Leibler divergence:
Kullback-Leibler divergence=$\sum^{p}_{j=1}$
5)Cosine coefficient:
Cosine coefficient=
6)Intersection similarity:
Intersection similarity= $\sum^{p}_{j=1}$ min
前4种度量从距离的角度评估LDL的性能, 值越小, 性能越优.后2种度量从相似度的角度评估LDL的性能.
在实验中, 选用如下7种主流的LDL进行对比分析:PT-Bayes、PT-SVM、AA-kNN、AA-BP、SA-IIS、SABFGS、LSM-LDL.所有对比算法的代码均由原作者分享.按照原作者建议, 在PT-Bayes中, 最大似然估计被用于估计高斯类条件概率密度函数.在PT-SVM中, 选用LIBSVM工具包中的C-SVC类型, 同时设定核函数为径向基函数(Radial Basis Function, RBF)核, C = 1.0.在AA-kNN中邻居数量k=4.在AA-BP中, 隐层神经元的数量设定为60.对于SA-IIS和SA-BFGS, 设定所有的初始化参数为默认值.此外, 为了获得较优的预测性能, 通过经验估计, 将LSM-LDL和LCR-LDL中的正则化参数均设定为λ =0.01.
值得注意的是, 在一些基于邻域的分类学习方法中, 鲜有文献报道有关邻域尺寸k设定的理论依据, 最佳的k值取决于数据集本身的特性.在大多数情况下, 较优的邻域尺寸k可通过调节训练样本的百分比决定, 本文称为邻域参数w.因此, 在实验中, 将在1%~20%内以1%为间隔, 依次调节邻域参数w, 测试邻域尺寸对LCR-LDL的性能影响.
实验在配置为Intel Core i7-6850K, 3.60 GHz处理器和32.00 GB内存的工作站上进行, 编程环境为Matlab R2017b.
本文在不同的邻域尺寸下评估LCR-LDL的预测性能.采用训练样本的百分比(邻域参数w)描述邻域尺寸, 在不同的邻域参数w下进行实验.在每个w下, 进行10折交叉验证, 记录10次实验结果的均值.
由于篇幅限制, 仅展示表1中7个LDL数据集上的Chebyshev distance指标值, 反映LCR-LDL随邻域尺寸变化时预测性能的变化趋势, 具体如图2所示.对于未显示的Yeast-cdc、Yeast-cold、Yeast-diau、Yeast-dtt、Yeast-elu、Yeast-heat、Yeast-spo、Human Gene数据集上的实验结果, 它们的预测性能的变化趋势与 Yeast-alpha数据集上的变化趋势相似.
由图2可见, 在Chebyshev distance指标上, 随着邻域参数w的增大, LCR-LDL的预测性能大体上先保持上升趋势, 再逐渐下降.特别地, 当w在[1%, 10%]内时, LCR-LDL可获得最好或是几乎最好的预测性能.主要原因如下:如果邻域尺寸设置过小, 所选邻域空间内样本数量会出现不充足的情况, 使LCR-LDL无法表达未标记样本.随着邻域尺寸的增长, 越来越多的信息可被用于表达未标记样本, LCR-LDL的预测性能呈现上升趋势.
然而, 如果邻域尺寸大于一个特定的值, 字典中大量较低相似度的噪声样本会落入未标记样本的邻域空间中, 这对以局部方式表达未标记样本造成干扰, 致使LCR-LDL的预测性能下降.
 | 图2 w不同时LCR-LDL的Chebyshev distance值对比Fig.2 Chebyshev distance value comparison of LCR-LDL with different w |
将LCR-LDL的预测性能与7种LDL进行对比分析.对于每种评估度量, 使用10折交叉验证, 评估不同算法的有效性, 分别记录10次实验结果的均值和方差.值得注意的是, 如图2所示, 从Yeast-alpha数据集到Human Gene数据集(表1第1行~11行), 当邻域参数w在10%附近时, LCR-LDL获得较优的预测性能.然而, 从Natural Scene数据集到Movie数据集(表1第12行~15行), 当邻域参数w在1%附近时, LCR-LDL可获得较优的预测性能.因此, 在前11个数据集和后4个数据集上, 分别在w = 10%和w = 1%下评估各算法的预测性能.
各算法针对6种评估指标的预测性能的对比结果如表2~表7所示, 对于每种评估指标, 最优预测性能由黑体数字表示.
针对Chebyshev distance和Cosine coefficient指标, LCR-LDL获得较令人满意的预测结果.基于Kullback-Leibler divergence、Intersection similarity指标, LCR-LDL在14个LDL数据集上获得最优的预测性能.在S-JAFFE、Movie数据集上, LCR-LDL的预测性能不是最优, 但与最优值接近.对于Clark distance、Canberra metric指标, LCR-LDL在12个LDL数据集上的预测性能显著最优, 在另外3个数据集上, LCR-LDL的预测性能与AA-kNN、SA-BFGS、AA-BP相当.综合上述实验结果可发现, LCR-LDL的预测性能明显优于其它对比算法, 主要原因如下:消除一些较低相似度样本, 局部邻域搜索策略可有效降低噪声对分类学习的影响, 协同机制可完整保持标记间的相关性及不同标记的相对重要性, 最终使标记分布学习系统的性能得到较大幅度提升.
从整体上看, 在全部预测性能的结果中, LSM-LDL和SA-BFGS排在第二位的情形分别占据53.33%和57.78%, 排在第三位的情形分别占据33.33%和20.00%, 排在第四至第八位的情形均很少.因此, LSM-LDL和SA-BFGS的预测性能也较显著, 然而, LSM-LDL和SA-BFGS存在如下不足:1)在LSM-LDL中, 当探索每维特征和每个标记的描述度之间的相关性时, 训练样本中可能存在噪声数据, 导致由训练样本的特征和对应的标记分布构造的转换矩阵在一定程度上遭到破坏.2)SA-BFGS的设计过程中同样未考虑噪声的干扰, 当处理真实的LDL任务时, 面对密集的特征噪声, 在原始特征空间上, 基于最大熵模型的各个标记下的个体学习器效果并不理想.对于AA-kNN和AA-BP, 预测性能位于第一名、第二名或第三名的情况仅占18.89%, 这意味着直接修改SLL和MLL中的一些约束条件, 对于LDL任务而言并不是最好的选择.
此外, 对于PT-SVM、SA-IIS和PT-Bayes, 它们的预测性能都排在第四至第八位之间, 不存在排名位于前三位的情况, 主要原因如下:LDL会破坏不同标记的内在关联性, 因此, PT-SVM和PT-Bayes不能获得令人满意的预测结果.
为了更完善地对比预测性能, 进一步采用Friedman检验[25], 它是一种在多个数据集上对比两种以上算法的统计学检验方法[26].假设存在s种待对比算法, N种实验数据集, rji表示第j种算法在第i个数据集上预测性能排名, 第j种算法在全部数据集上的平均排名为
Rj=
在原假设下, Friedman统计量FF符合一个自由度为(s - 1)和(s - 1)(N - 1)的Fisher分布:
FF=
| 表2 各算法在15个LDL数据集上的Chebyshev distance值对比 Table 2 Chebyshev distance value comparison of different algorithms on 15 LDL datasets |
| 表3 各算法在15个LDL数据集上的Clark distance值对比 Table 3 Clark distance value comparison of different algorithms on 15 LDL datasets |
| 表4 各算法在15个LDL数据集上的Canberra metric值对比 Table 4 Canberra metric value comparison of different algorithms on 15 LDL datasets |
| 表5 各算法在15个LDL数据集上的Kullback-Leibler divergence值对比 Table 5 Kullback-Leibler divergence value comparison of different algorithms on 15 LDL datasets |
| 表6 各算法在15个LDL数据集上的Cosine coefficient值对比 Table 6 Cosine coefficient value comparison of different algorithms on 15 LDL datasets |
| 表7 各算法在15个LDL数据集上的Intersection similarity值对比 Table 7 Intersection similarity value comparison of different algorithms on 15 LDL datasets |
当s = 8, N = 15时, 6种评估度量下的Fried-man统计量FF如下:Chebyshev distance为25.211 6, Clark distance为21.646 0, Canberra metric为20.852 5, Kullback-Leibler divergence为22.704 1, Cosine coeffi-cient为24.701 2, Intersection similarity为24.414 6, 对应的临界值为2.104 4.
对于每种评估度量, 在α =0.05显著性水平下的Friedman检验都拒绝“ 全部对比的算法具有相等的预测性能” 这一原假设.
进一步采用Post-hoc检验(本文采用Nemenyi检验)分析算法是否具有显著的差异.在全部数据集上, 如果2种对比算法预测性能的平均排序的差值大于1个临界差异(Critical Difference, CD), 称这两种算法是显著不同的.CD定义如下:
CD=qα
其中, 临界值qα 源于Studentized Range统计量除以
qα =3.031, CD=2.7110,
其中s = 8, N = 15.
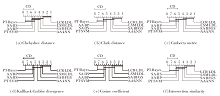
为了可视化地展示各算法在预测性能上的实际差异性, 绘制不同评估指标下的CD图[26], 如图3所示, 每种对比的LDL算法的预测性能的平均排序沿着横轴标注, 排名靠前的位于坐标轴右侧.
在图3每幅子图中, 如果一组算法在Nemenyi检验下无显著的差异性, 使用一条粗线连接它们.同时, 每种评估度量下的CD显示在对应的坐标横轴上方.
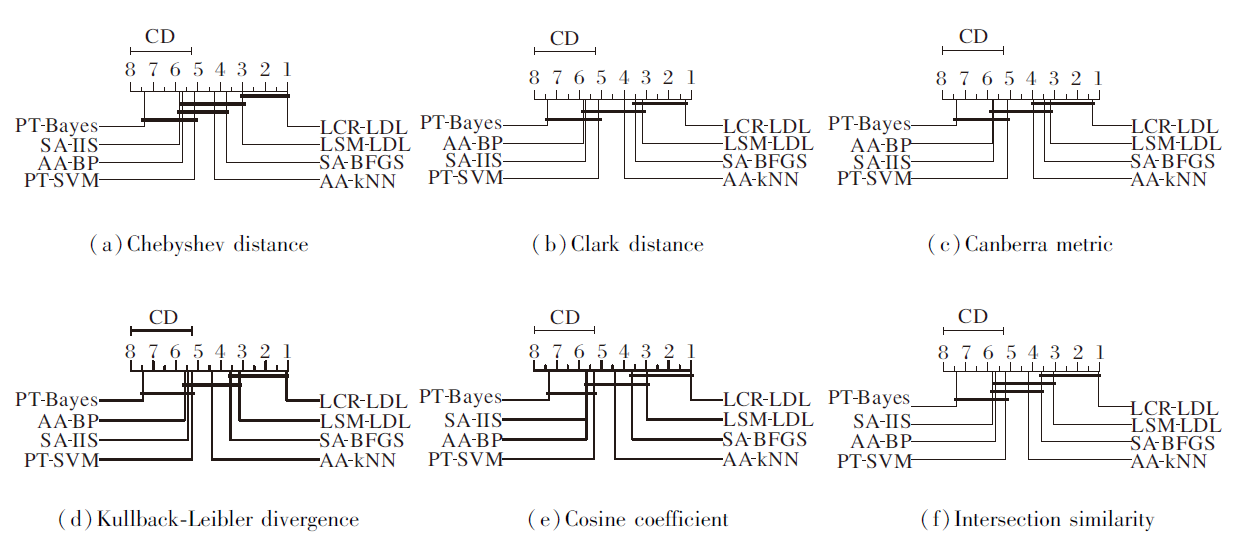 | 图3 各算法在不同评估指标上的CD图Fig.3 CD diagrams of different algorithms on different evaluation metrics |
由图3可得如下结论:1)在Chebyshev distance指标上, 相比SA-BFGS、AA-kNN、PT-SVM、AA-BP、SA-IIS、PT-Bayes, LCR-LDL获得统计上优异的预测性能; 2)在Clark distance、Kullback-Leibler divergence、Cosine coefficient、Intersection similarity指标上, 无明确的证据表明LCR-LDL、LSM-LDL、SA-BFGS的预测性能存在显著的差异; 3)在Canberra metric指标上, LCR-LDL的预测性能与LSM-LDL、SA-BFGS、AA-kNN相当, 都明显优于PT-Bayes.
从整体上看, 在全部预测性能的对比结果上, LCR-LDL仅在28.57%的情况下获得统计上可比的预测性能, 具体包括:在全部6种评估度量上与LSM-LDL的对比; 在Clark distance、Canberra metric、Kullback-Leibler divergence、Cosine coefficient和Inter-section similarity指标上与SA-BFGS的对比; 在 Canberra metric指标上与AA-kNN的对比.在其它71.43%的情况下, LCR-LDL获得统上优越的预测性能, 并且没有算法的预测性能优于LCR-LDL.由此可见, 相比其它主流的LDL, LCR-LDL在预测性能上具有优越性.
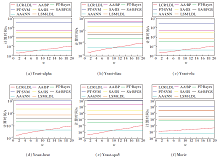
在6个LDL数据集上对比8种算法的计算时间, 结果如图4所示, 其中图4的纵坐标以常用对数刻度为单位(以10为底的log函数).
由图4可知, 随着邻域尺寸的增加, LCR-LDL的计算时间呈现逐步上升的趋势, 主要原因如下:字典中越来越多的样本可被用于对未标记样本进行表达重构, 从而导致LCR-LDL中step 3的计算效率降低.
 | 图4 各算法在6个LDL数据集上的计算时间对比Fig.4 Computational time comparison of different algorithms on LDL datasets |
然而, 当w在[1%, 10%]内时, 局部邻域搜索策略将产生较优异的计算效率.从整体上来讲, 在图4中, 8种LDL算法在6个LDL数据集上的计算效率的排名基本一致, 即
AA-kNN和LCR-LDL< PT-Bayes< SA-BFGS和LSM-LDL< SA-IIS< AA-BP< PT-Bayes.
由于没有显式的训练过程, AA-kNN和LCR-LDL在处理LDL任务时都获得较高的计算效率.特别地, 相比AA-kNN, LCR-LDL具有更显著的预测性能.
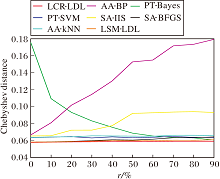
为了验证LCR-LDL对噪声干扰的鲁棒性, 在特征噪声干扰的LDL数据集上, 对比分析各算法的预测性能.具体而言, 在每个未标记样本中, 随机选择一定比例的特征进行干扰, 即使用从均匀分布中产生的独立同分布的噪声替代被选特征值.对于每个未标记样本, 被干扰的特征随机确定, 被干扰特征的百分比(噪声率r)在0%~90%内以步长10%递增.在每种噪声水平下, 实验均采用十折交叉验证的方式, 10次预测结果的均值作为最终的实验结果.
由于篇幅的限制, 仅展示Yeast-spo 数据集上, 各算法在不同随机特征噪声干扰水平下的Chebyshev distance指标值, 结果如图5所示.
 | 图5 r不同时各算法的Chebyshev distance值对比Fig.5 Chebyshev distance value comparison of different algorithms with different r |
由图5不难发现, 相比AA-kNN、PT-SVM、SA-BFGS、LSM-LDL、LCR-LDL, PT-Bayes、AA-BP和SA-IIS明显具有较差的抗噪声性能.
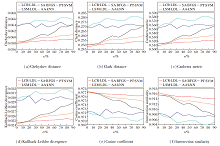
为了更详细地刻画5种较鲁棒的LDL算法(AA-kNN、PT-SVM、SA-BFGS、LSM-LDL和LCR-LDL)间抗噪声性能的差异性, 进一步绘制它们在全部6种评估指标下的抗噪声性能对比, 如图6所示.
在6种评估指标上, 5种较鲁棒的LDL算法抗噪声性能的排名一致, 即
LCR-LDL< LSM-LDL< SA-BFGS< PT-SVM< AA-kNN.
综上所述, 随着噪声率的增长, LCR-LDL在全部对比的LDL算法中获得最显著的抗噪声性能, 另外7种LDL算法的预测性能明显减弱.
 | 图6 r不同时5种较鲁棒的LDL的预测性能对比Fig.6 Predictive performance comparison of 5 robust LDL algorithms with different r |
标记分布学习是处理标记多义性的有效手段, 它考虑相关标记对样本的不同描述程度.现有的LDL不仅破坏不同标记间的关联性和标记分布的整体结构, 还忽略现实应用中的计算代价和噪声鲁棒性问题.为了缓解这些不足, 本文提出基于局部协同表达的标记分布学习算法(LCR-LDL).首先借助kNN规则为每个未标记样本构建局部字典, 再将未标记样本视作局部字典对其的协同表达.通过l2范数约束的最小化, 获得一组表达系数, 它们的鉴别信息能与标记分布信息矩阵联合, 生成未标记样本的预测标记分布.在15个真实LDL数据集上的实验表明, LCR-LDL可达到较好的预测性能和抗噪优势, 同时具有轻量级的计算代价.在一些现实场景中, 由于数据采集器精度和可靠性的限制, LDL任务可能存在冗余和无关的特征, 及不完备的数据表示.今后将对LDL任务进行特征选择或构建一个潜在语义特征空间, 进一步提升LDL算法的泛化性能.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|