{kind=link}
{kind=link}
基于关联约束的对抗跨模态检索方法
[郭倩1, 3  , 钱宇华
, 钱宇华1, 2, 3 1, 3 ]
, 钱宇华, 梁新彦]
|
|



通信作者:钱宇华,博士,教授,主要研究方向为模式识别、特征选择、粗糙集理论、粒计算、人工智能.E-mail:

作者简介:郭倩,博士研究生,主要研究方向为深度学习、跨模态检索、逻辑学习.E-mail:

梁新彦,博士研究生,主要研究方向为多模态数据融合、跨模态检索.E-mail:
现有跨模态检索方法主要使用某一指标约束得到一个子空间,检索结果往往有差异.为了提高公共子空间的鲁棒性,文中提出基于关联约束的对抗跨模态检索方法.对抗约束通过混淆判别器使其无法分辨子空间特征来自哪个模态,从而提升不同模态特征的一致性.关联约束用于增强投影子空间关联程度.三元组约束同时考虑不同模态同一语义、相同模态不同语义样本之间的结构信息.在数据集上的实验表明文中方法的检索性能得到有效提升.
About the Author:GUO Qian, Ph.D. candidate. Her research interests include deep learning, cross-modal retrieval and logic learning.
LIANG Xinyan, Ph.D. candidate. His research interests include multimodal data fusion and cross-modal retrieval.
In the existing cross-modal retrieval methods, retrieval results are obtained via the subspace acquired by a certain index constraint such as distance or similarity. Since the subspaces are learned with different index constraints, retrieval results are different. To improve the robustness of common subspace, a method for adversarial cross-modal retrieval based on association constraint is proposed. The consistency of different modality features is improved by the adversarial constraint to make the discriminator in the constraint unable to distinguish which modality the subspace features come from. The association of different modality features is enhanced by the association constraint. The structural information between example pairs with the same semantics of different modalities and different semantics of the same modality is taken into account by the triple loss constraint. Experimental results on datasets show that the proposed method is more effective than other cross-modal retrieval methods.
单模态检索是指给定某个图像或文本, 通过检索系统检索与该图像或文本语义相同的图像或文本.随着互联网的飞速发展, 图像、文本、音频等多模态数据呈现爆炸式增长, 与此同时, 人们对检索的需求也在不断增加, 人们希望可获得更好的检索体验, 因此, 以文搜图、以图搜文等各种跨模态检索方式应运而生.跨模态检索任务的关键之处在于打破不同模态间的语义鸿沟, 找到模态不变的公共特征表示子空间, 从而可在该子空间进行相似度对比, 得到正确的检索结果.
机器学习方法已在跨模态检索任务上取得一定进展, 典型相关分析(Canonical Correlation Analysis, CCA)[1]是其中一种经典的跨模态检索方法, CCA学习公共子空间, 最大化投影向量间的相关性.基于特征子空间学习的跨媒体检索方法(Singular Value Decomposition Active, SVD-Active)[2]先对来自不同模态的特征共生矩阵进行奇异值分解和子空间映射, 再通过子空间优化算法提升多模态数据的聚类效果和跨模态检索的可靠性.相关空间嵌入算法[3]在构建文本和图像特征这两个空间相关关系的同时保留原特征的结构分布, 提升跨模态检索的效果.然而, 传统机器学习方法通常需要事先人为定义特征提取方法, 费时费力, 提取的特征质量直接影响最终结果, 由于经验有限, 不能有效提取很多隐藏在数据背后的关键特征.
随着Krizhevsky等[4]提出AlexNet网络后, 涌现出各种深度神经网络.深度学习的一大优势是可以自动学习数据特征, 在识别、分类等各个任务上都效果较优[5, 6], 目前有很多学者使用深度神经网络进行跨模态检索任务的研究, 并基于此提出多种跨模态检索方法[7, 8, 9].王科俊等[10]提出决策级融合方法, 对不同模态的数据进行质量评价, 根据结果设计权重, 再分别设计分类器, 将得到的识别结果与该权重结合, 进行决策级融合.Andrew等[11]将CCA引入深度神经网络, 提出深度典型相关分析(Deep CCA, DCCA), 较大幅度提升跨模态检索的效果, 然而方法只关注一对来自不同模态数据间的相似度, 事实上, 一个模态的某个数据可能有多个标签, 因此仅关
注成对相似性是不够的.生成式对抗网络是深度神经网络的典型代表之一, 主要分为生成器网络和判别器网络, 生成器网络用于产生不易分辨的假数据, 判别器网络尽可能地区分真假数据, 整个过程可看作是两个网络在进行博弈[12], 直到生成器和判别器达到一个平衡, 终止学习过程.Wang等[13]将对抗网络引入跨模态检索任务中, 提出对抗跨模态检索方法(Adversarial Cross-Modal Retrieval, ACMR), 不仅关注不同模态数据间的成对相似度, 而且可区别数据来自哪个模态.然而当数据发生改变时, 投影向量也会随之改变, 影响基于距离的度量相似性的结果.
现有方法在跨模态检索任务上已取得极大成功, 然而, 单一指标约束可能导致学习的公共子空间不鲁棒.钱宇华等[14]和成红红等[15]给出关联学习的一般形式化定义, 关联学习是学习从输入空间到输出空间映射的过程, 存在连续型和离散型两种学习模式.
由此, 本文提出基于关联约束的对抗跨模态检索方法.首先采用VGG网络[16]和带词频-逆文本频率指数(Term Frequency-Inverse Document Frequency, TF-IDF)加权的词袋模型(Bag-of-Words, BoW), 分别提取图像特征和文本特征, 再将两种特征输入网络的生成器中, 通过关联约束和三元组约束指导生成器学习模态不变的公共特征表示子空间, 使生成器完成样本语义标签的正确分类, 同时使判别器不能辨别子空间特征来自何模态, 此时的子空间学习模型可有效减少不同模态的语义鸿沟.在此过程中, 关联约束最大化投影向量之间的相关性, 用于增强投影子空间的关联程度, 可在语义层面进行公共特征表示子空间的学习.三元组约束同时考虑不同模态同一语义、相同模态不同语义样本之间的结构信息, 使目标与同类样本之间的距离达到最小, 与不同类样本之间的距离达到最大.相比ACMR, 关联约束对三元组约束和对抗约束有正向训练作用, 关联约束可最大化投影向量之间的相关性, 从而使三元组约束和对抗约束更好地进行公共子空间的学习, 三个指标共同指导公共子空间的学习过程, 较好地完成跨模态检索任务.
基于关联约束的对抗跨模态检索方法分为三部分:特征提取、特征映射和判别网络.方法框图如图1所示.
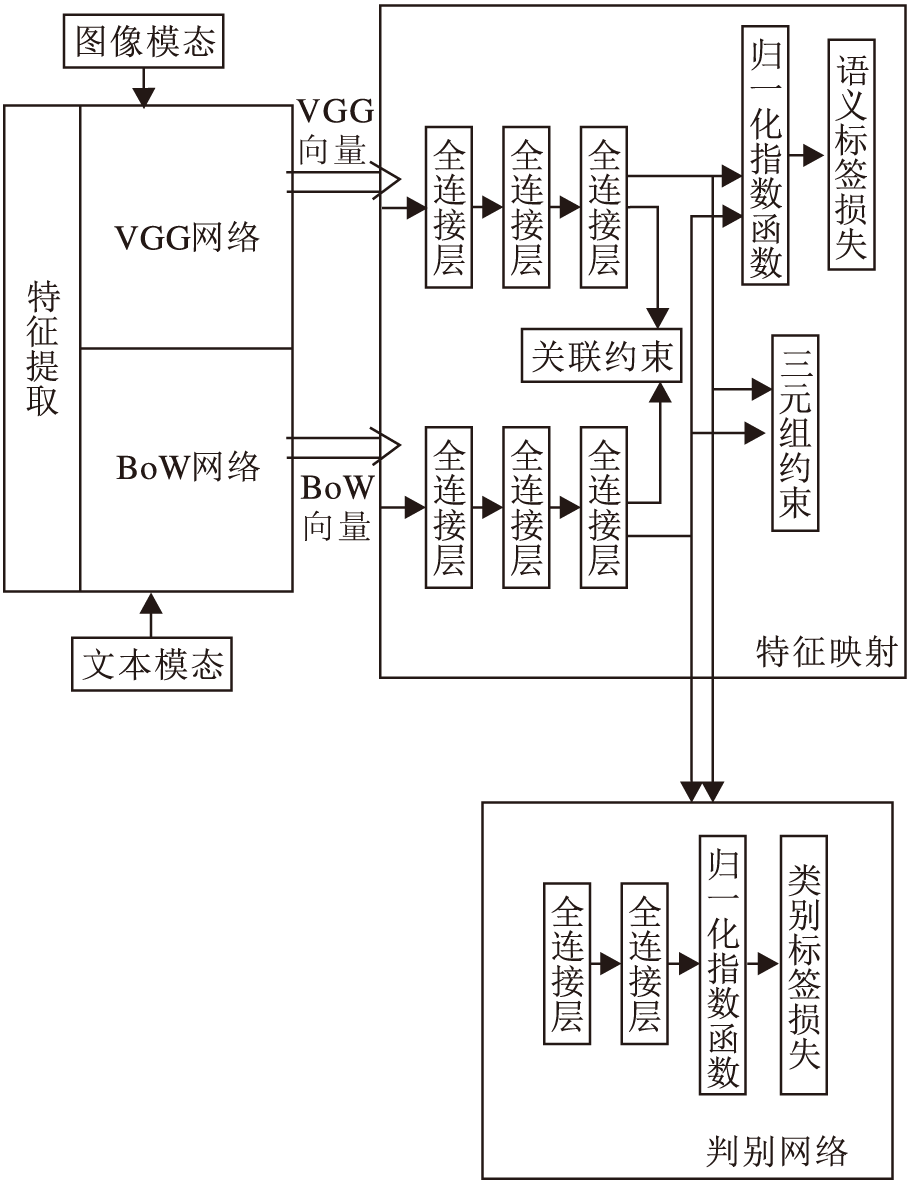 | 图1 本文方法框图Fig.1 Framework of the proposed method |
特征提取的目的是提取图像特征和文本特征.
对于图像, 本文使用VGG网络[16]提取图像特征.VGG网络由卷积层(Conv)、池化层(Pool)和全连接层(Full)组成.卷积层通过卷积核从不同维度不断滑动以提取图像特征, 卷积核的参数包括卷积核的个数、大小、步长等.卷积核和高斯核类似, 然而高斯核的参数是根据人类经验得到, 具有理论意义, 卷积核的参数需要通过反向传播不停学习得到, 参数意义对于人类来说是未知的.通过卷积操作得到的特征更丰富, 更利于后期使用.池化层的主要目的是对特征进行约简, 减少学习参数, 降低模型复杂度, 常用的池化操作有平均池化、随机池化和最大池化等.全连接层的特点是该层的所有神经元与上一层的所有神经元两两相连, 本文使用全连接层的目的是把所有特征进行加工, 作为图像特征进行下一步操作.为了方便描述, 使用vi表示学习的第i个图像特征, 一个批次中的图像特征矩阵
V=[v1, v2, …, vn].
对于文本, 本文使用带TF-IDF加权的BoW模型.BoW常被用于进行文本特征提取, 原理是把一个句子转化为向量表示.首先, BoW统计所有句子中出现的单词, 形成一个词表, 为每个句子生成一个长度等于词表长度的空向量.再将每个句子和词表进行匹配, 计算词表中某个单词在该句中出现的次数, 将次数填入该句向量的对应位置, 形成该句的BoW向量.
然而BoW不能客观反映一个句子的真正关键词, 因此提出带TF-IDF加权的BoW.TF-IDF包括两部分:TF计算某个单词在文章中出现的词频, IDF计算文档总数与包含该词的文档数的对数值, TF与IDF的乘积就是权重TF-IDF, TF-IDF越大说明该词越重要.在BoW中进行TF-IDF加权, 可自动提取句子的关键词, 本文将得到的词向量作为文本特征, 进行下一步操作.为了方便描述, 使用ti表示得到的第i个文本特征, 则一个批次中的文本特征矩阵
T=[t1, t2, …, tn].
特征映射充当对抗网络中的生成器, 主要任务如下:学习模态不变的公共特征表示子空间, 完成多语义标签任务.特征映射的损失函数由三部分组成:关联约束损失、语义标签损失、三元组约束损失.本文使用关联约束, 最大化投影向量之间的相关性, 可在语义层面进行公共特征表示子空间的学习.语义标签约束可将不同语义标签的数据分开.三元组约束可增大语义标签不同特征向量的距离, 减小语义标签相同特征向量的距离.
假设存在某个公共特征表示子空间, 图像特征和文本特征在该公共特征表示子空间投影后得到的向量间相似度最大.在提取的图像特征vi和文本特征ti后各使用一个三层全连接网络进行特征投影, 在投影向量上加入关联约束, 使投影向量之间的相关性最大化, 图像特征vi的投影向量使用
该关联约束通过CCA的原理实现, CCA的原理是:对于两组变量X、Y, 在新投影空间下进行线性变换并求取相关系数, 寻找使相关系数最大的线性变换对a, b:
ρ (X', Y')=
其中
X'=aTX, Y'=bTY.
若是两组多变量, 则继续寻找使相关系数最大的线性变换对, 不停迭代该过程, 最终得到若干对正交的典型变量.
在本文中, 关联约束的损失函数表示如下:
Lossac(θ ac)=- $\frac{1}{n} \sum^{n}_{i=1}$
其中, θ ac表示需要学习的关联约束的参数, a、b表示使相关系数最大的线性变换对, n表示每个批次中有n个图像-文本对,
跨模态检索的关键在于打破不同模态间的语义鸿沟, 学习模态不变的公共特征表示子空间.当投影向量的相关性最大时, 可在语义层面进行公共特征表示子空间的学习, 待检索数据在投影空间下不能被区分来自哪个模态, 从而尽可能地骗过判别器.
通过最小化语义标签损失将不同语义标签的数据分开.在计算损失的过程中, 使用交叉熵损失:
Losssl(θ sl)=- $\frac{1}{n} \sum^{n}_{i=1}$
其中, θ sl表示需要学习的语义标签损失的参数, n表示每个批次中图像-文本对数, yi表示第i个样本的真实语义标签,
数据的语义标签分为10类, 当语义标签的损失达到最小时, 表明分类器尽可能地给予数据正确的语义标签, 即尽可能地将不同语义标签的数据分开.
三元组约束广泛应用在人脸识别[17]、行人重识别[18]等领域.三元组约束的原理简单来说就是:选定某个目标样本, 再随机选择一个与该目标相同类的样本、一个与该目标不同类的样本, 组成一个三元组.在训练过程中, 模型尽可能地减小目标与同类样本之间的距离, 增大目标与不同类样本之间的距离, 并且这两个距离之间需要有一个最小间隔.
在本文中, 使用三元组约束后, 不仅可增大语义标签不同的特征向量的距离, 也可减小语义标签相同的特征向量的距离.本文以一个批次为单位使用三元组约束, 首先根据语义标签随机生成两组三元组:以图像为目标样本的三元组(vi,
l2(v, t)=
其中, Sv表示图像特征v的投影向量, St表示文本特征t的投影向量.
所以, 三元组(vi,
Lossvt(θ v)= $\sum^{}_{i, j, k}$ l2(vi,
其中:θ v表示需要学习的三元组(vi,
定义三元组(ti,
Losstt(θ t)= $\sum^{}_{i, j, k}$ l2(ti,
其中, θ t表示需要学习的三元组(ti,
因此, 三元组约束部分的损失函数为
Lossvt+tt(θ v, θ t)=Lossvt+Losstt.
当三元组约束的损失达到最小时, 表示目标与同类样本之间的距离达到最小, 目标与不同类样本之间的距离达到最大.
综上所述, 特征映射部分的总损失函数表示如下:
Lossfp(θ ac, θ sl, θ v, θ t)=α Lossac+β Losssl+γ Lossvt+tt,
其中, α 、β 、γ 表示3个可学习的参数, 用于平衡三项损失Lossac、Losssl、Lossvt+tt的重要性.当总损失达到最小时, 表明得到一个模态不变的公共特征表示子空间.
判别网络充当对抗网络中的判别器, 目的是使得判别器无法区分数据来自哪个模态, 进而提高不同模态特征表示的一致性.判别网络部分与特征映射部分一起完成跨模态检索任务, 损失函数为
Lossadv(θ D)=- $\frac{1}{n} \sum^{n}_{i=1}$ mi(lnDi(vi)+ln(1-Di(ti)))),
其中, θ D表示需要学习的模态判别分类器的参数, n表示每个批次中图像-文本对个数, mi表示第i个样本的真实模态标签(One-hot编码形式), Di(vi)表示图像特征vi的生成模态概率, Di(ti)表示文本特征ti的生成模态概率.
方法整体优化目标就是最大最小化特征映射部分与判别网络之差:
本文使用Adam(Adaptive Moment Estimation)优化器对优化目标进行优化, 具体的优化过程如下.
1)初始化, 以批次为单位, 每个批次中有n 个样本, 其中, 图像特征矩阵
V=[v1, v2, …, vn],
文本特征矩阵
T=[t1, t2, …, tn],
语义标签矩阵
Y=[y1, y2, …, yn],
K为超参数.
2)通过梯度下降更新参数θ ac、θ sl、θ v、θ t, 直到损失收敛:
θ ac← θ ac-μ ▽
θ ls← θ ls-μ ▽θ ls
θ v← θ v-μ ▽
θ t← θ t-μ ▽ (
3)通过梯度下降更新判别器的参数:
θ D← θ D+μ
4)返回学习的公共特征表示子空间f(V)和f(T).
本文使用Wikipedia[19]、NUS-WIDE-10k[20]、Pascal Sentence[21]、MSCOCO[22]这4个广泛使用的跨模态检索数据集, 数据集的具体信息如表1所示.
| 表1 实验数据集 Table 1 Experimental datasets |
Wikipedia数据集是由维基百科的文章生成的, 本文只考虑其中广泛使用的10类文章:Art、Biology、Geography、History、Literature、Media、Music、Royalty、Sport、Warfare.NUS-WIDE数据集是由新加坡国立大学提供, 本文使用该数据集的一个子集NUS-WIDE-10k.Pascal Sentence数据集包括20个类别, 每个类别包括50个样本.MSCOCO数据集包括500个类别, 共82 783个样本.
对于Wikipedia、MSCOCO数据集, 本文使用的图像特征为4 096维的VGG特征, 文本特征为3 000维的BoW特征.对于NUS-WIDE-10k、Pascal Sentence数据集, 本文使用的图像特征为4 096维的VGG特征, 文本特征为1 000维的BoW特征.
本文方法学习率设置为0.000 1, 批次大小设置为64, 采用Adam优化器进行优化.
特征映射和判别网络的实现采用全连接网络(Fully Connected Layer), 表2为这两部分的相关参数.
对于每个数据集, 语义标签是几类, 特征映射就是几分类问题.由于所有数据集的模态标签是2类(图像和文本), 所以判别网络是一个2分类问题. 特征映射和判别网络都采用softmax作为最后的分类器.
| 表2 特征映射和判别网络的网络参数 Table 2 Parameters of feature projection and discriminator |
为了对本文方法进行性能评估, 采用广泛使用的平均精度均值(Mean Average Precision, mAP)[7, 8]进行评价.
mAP评价指标分两步:1)计算测试集中每个检索的平均精度(Average Precision, AP):
AP= $\frac{1}{T} \sum^{R}_{r=1}$ P(r)δ (r),
其中, T表示测试集中与检索相关的数据个数, P(r)表示测试精度排名前r个数据的精度, 即TOP-r, δ (r)表示与检索目标是否相关, 若相关, δ (r)=1, 否则, δ (r)=0.
2)测试集的所有检索结果求平均, 得到mAP:
mAP= $\frac{1}{N} \sum^{N}_{i=1}$ APi,
其中N表示测试集样本数量.
在Wikipedia数据集上进行对比实验, 使用如下对比方法:CCA[1]、Corr-AE(Correspondence Autoencoder)[7]、CMDN[8]、LCFS(Learning Coupled Feature Spaces)[9]、ACMR[13]、CCA-3V(Three-View Kernel CC-A)[23]、JRL(Joint Representation Learning)[24]、JFSSL(Joint Feature Selection and Subspace Learning)[25]、Multimodal-DBN(Multimodal Deep Belief Network)[26]、Bimodal-AE(Bimodal Deep Autoen-coder)[27]、MCSM(Modality-Specific Cross-Modal Similarity Measure-ment)[28].各方法的实验结果如表3所示, 表中黑体数字表示最优结果.
| 表3 各方法在Wikipedia数据集上的实验结果 Table 3 Experimental results of different methods on Wikipedia dataset |
由表3可知, 除了在给定图像检索文本任务上与ACDM持平以外, 本文方法效果最优, 这说明本文方法可有效完成跨模态检索任务.本文方法优于CCA、Bimodal-AE、Corr-AE等只考虑减小语义标签相同特征向量距离的方法, 表明三元组约束对于同时增大语义标签不同特征向量的距离、减小语义标签相同特征向量的距离的约束是有效的.本文方法在给定图像检索文本任务上与ACMR持平, 在给定文本检索图像任务上优于ACMR, 说明关联约束在语义层面的约束更利于学习公共特征表示子空间.
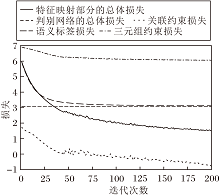
本文方法在Wikipedia数据集上的损失曲线如图2所示, 该曲线是将损失值变化到正数空间后取对数得到, 几乎全部的损失曲线都随着迭代次数的增加而下降, 表明多个约束在一定程度上都参与指导公共子空间的学习过程.
 | 图2 本文方法在Wikipedia数据集上的损失曲线Fig.2 Loss curve of the proposed method on Wikipedia dataset |
本文方法的特征映射部分的约束由关联约束、语义标签约束和三元组约束组成, 为了评估各个约束对检索结果的影响, 设计一定的消融实验:仅使用关联约束、仅使用语义标签约束、仅使用三元组约束、仅使用关联和语义标签约束、仅使用关联和三元组约束、仅使用语义标签和三元组约束.实验中其它设置保持不变.在Wikipedia数据集上的不同约束对实验结果的影响如表4所示, 表中黑体数字表示最优结果.
| 表4 在Wikipedia数据集上不同约束对实验结果的影响 Table 4 Influence of different constraints on experimental results on Wikipedia dataset |
由表4可见, 关联约束、语义标签约束、三元组约束都有利于实验效果的提升, 这表明同时优化这三个约束比只优化其中一个约束或两个约束更好.另外, 语义标签约束对整体性能的影响更大, 这是由于与不同模态间的关系一致性(关联约束、三元组约束)相比, 探索模态内部的类别判别更容易一些.
在NUS-WIDE-10k数据集上进行对比实验, 选择如下方法:CCA[1]、Corr-AE[7]、CMDN[8]、LCFS[9]、ACMR[13]、JRL[24]、Multimodal-DBN[26]、Bimodal-AE[27]、SC-ACMR(Semantic Consistent Adversarial Cross-Mo-dal Retrieval)[29].各方法的实验结果如表5所示, 表中黑体数字表示最优结果.由表可知本文方法在2种检索模式中都取得最优.
| 表5 各方法在NUS-WIDE-10k数据集上的实验结果 Table 5 Experimental results of different methods on NUS-WIDE-10k dataset |
在Pascal Sentence数据集上进行对比实验, 选择如下方法:CCA[1]、Corr-AE[7]、CMDN[8]、LCFS[9]、ACMR[13]、JRL[24]、Multimodal-DBN[26]、Bimodal-AE[27]、MASLN(Modal-Adversarial Semantic Learning Net-work)[30].各方法的实验结果如表6所示, 表中黑体数字表示最优结果.由表可知, 本文方法在2种检索模式中都取得最优.
| 表6 各方法在Pascal Sentence数据集上的实验结果 Table 6 Experimental results of different methods on Pascal Sentence dataset |
在MSCOCO数据集上进行对比实验, 使用如下对比方法:ACMR[13]、CCA(FV HGLMM(Hybrid Gau-ssian-Laplacian Mixture Model Fisher Vectors))[31]、CCA(FV GMM+HGLM(Combination of the Gaussian Mixture Model and Hybrid Gaussian-Laplacian Mixture Fisher Vectors))[31]、DVSA(Deep Visual-Semantic Align-ments)[32]、m-CNN(Multimodal Convolutional Neural Networks)[33]、DSPE(Deep Structure-Preserving Image-Text Embeddings)[34]、文献[35]方法.各方法的实验结果如表7所示, 表中黑体数字表示最优结果.由表7可知, 本文方法在2种检索模式中都取得最优.
| 表7 各方法在MSCOCO数据集上的实验结果 Table 7 Experimental results of different methods on MSCOCO dataset |
综合所有实验结果表明, 本文方法可有效学习不同模态间公共子空间特征.
本文提出基于关联约束的对抗跨模态检索方法, 同时对子空间特征施加多个约束以提高子空间特征的鲁棒性.对抗约束通过混淆判别器使其无法分辨子空间特征来自哪个模态, 从而提升不同模态特征的一致性.关联约束用于增强投影子空间关联程度.三元组约束同时考虑不同模态同一语义、相同模态不同语义样本之间的结构信息.本文方法在Wikipedia、NUS-WIDE-10k、Pascal Sentence、MSCOCO数据集上检索性能取得有效提升.今后将继续探索不同指标对跨模态检索效果的影响, 找到更有效的指标.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|