
{kind=link}
{kind=link}
{kind=link}
基于对抗式分布对齐的跨域方面级情感分析
[杜永萍1  , 刘杨
, 刘杨1 , 贺萌1 ]
, 刘杨, 贺萌]
|
|



通信作者:杜永萍,博士,教授,主要研究方向为信息检索、信息抽取、自然语言处理.E-mail: ypdu@bjut.edu.cn.

作者简介:刘杨,硕士研究生,主要研究方向为自然语言处理、情感分析.E-mail: 842178881@qq.com.

贺萌,硕士研究生,主要研究方向为自然语言处理、情感分析.E-mail: hemeng199412@163.com.
跨领域情感分类任务旨在利用富含情感标签的源域数据对缺乏标签的目标域数据进行情感极性分析.由此,文中提出基于对抗式分布对齐的跨域方面级情感分类模型,利用方面词与上下文的交互注意力学习语义关联,基于梯度反转层的领域分类器学习共享的特征表示.利用对抗式训练扩大领域分布的对齐边界,有效缓解模糊特征导致错误分类的问题.在Semeval-2014、Twitter数据集上的实验表明,文中模型性能较优.消融实验进一步表明捕获决策边界的模糊特征并扩大样本与决策边界间距离的策略可提高分类性能.
About the Author: LIU Yang, master student. His research interests include natural language processing and sentiment analysis.
HE Meng, master student. Her research interests include natural language processing and sentiment analysis.
The source domain data with rich sentiment labels is utilized to classify the aspect-level sentiment polarity for the target domain data without labels. Therefore, a cross-domain aspect-level sentiment classification model based on adversarial distribution alignment is proposed in this paper. The interactive attention of aspect words and context is employed to learn semantic relations, and the shared feature representations are learned by domain classifiers based on gradient reversal layers. The adversarial training is conducted to expand the alignment boundary of the domain distribution. And then the misclassification problem caused by fuzzy features is alleviated effectively. The experimental results on Semeval-2014 and Twitter datasets show that the performance of the proposed model is better than other classic aspect-level sentiment analysis models. The ablation experiment proves that the classification performance can be improved significantly by the strategy of capturing fuzzy features of decision boundary and expanding the distance between sample and decision boundary.
互联网上的文本信息日益增长, 在社交媒体、电商平台上产生大量带有情感信息的文本.情感分析是对文本意见和评论进行情感极性的划分, 是自然语言处理中的一项重要任务.近年来, 情感分析在工业界和学术界都受到广泛关注.
方面级情感分析也称为特定目标情感分析或细粒度情感分析, 是指给定一段文本及特定的方面词, 分析文本中涉及的方面(目标)的情感极性.在情感表达句子中, 不同的方面可能表达不同的情感.Wang等[1]提出基于注意力机制的长短时记忆网络(Attention-Based Long Short-Term Memory, ATAE-LSTM), 将方面词的词嵌入添加到句子中每个单词的词嵌入中, 生成方面感知的句子表示, 使用基于注意力机制的长短时记忆网络预测给定方面词的文本情感极性.Ma等[2]提出交互注意力网络(Interactive Attention Networks, IAN), 对上下文和方面词的注意力进行交互式的学习, 分别生成方面词和上下文的表示.曾义夫等[3]构造两个外部记忆单元, 利用注意力机制分别捕获语句中与方面词相关的单词级和短语级的特征.Xue等[4]使用卷积神经网络提取情感特征, 通过门控机制选择性地输出与方面词相关的特征, 用于情感分类.孙小婉等[5]引入多头注意力机制, 获取更全面的注意力信息, 融合上下文自注意力和特定方面的单词注意力, 进行特定方面情感极性的预测.大量的工作通过构造不同的注意力网络使方面级情感分类任务取得较优性能.
情感表达与领域高度相关, 同个情感词在不同的领域既有可能表达相同或相似的情感, 也有可能表达相反的情感.在处理这类样本时, 情感分类器比较容易进行领域迁移, 没有对目标域进行领域适应的分类器, 很难正确区分含有这类词的语句的情感极性.传统的情感分类方法需要充分的带标签的训练数据, 并要求训练集和测试集同分布[6].新出现的领域往往缺少充足的标记数据, 如何利用源域丰富的方面级情感类别标签, 为目标域指定的方面词判断情感极性是情感分析领域受到广泛关注的问题.跨领域情感分类任务通过充分利用源领域标注的大规模数据, 使用算法将其迁移到标注数据稀少的新领域[7], 实现对新领域的情感分类.
在跨域方面级情感分类任务上, Zhang等[8]提出交互式注意力转移网络(Interactive Attention Trans-fer Network, IATN), 将方面词的影响融入跨领域情感分类模型的表示学习中.Hu等[9]提出在方面词检测任务的辅助下提取领域不变的情感特征, 进行跨领域的方面级情感分类.Li等[10]将方面词和情感特征联合提取, 进行无监督的域适应设置, 通过选择性对抗学习方法对齐自动捕获的相关向量, 实现单词级别的领域之间的适应性.
虽然不同的领域方面词表示存在差异, 但是方面词与情感特征的语义关系在不同领域间却是相似的.本文提出基于对抗式分布对齐的跨域方面级情感分类模型(Cross Domain Aspect Level Sentiment Classification Model Based on Adversarial Distribution Alignment, ADA), 通过方面词与上下文的交互注意力学习语义关联, 通过基于梯度反转层的领域分类器学习共享的特征表示.由于这种训练领域分类器的方法存在一定不足, 在将不同领域样本的特征映射至同一空间中时, 仅对齐领域的边缘分布, 往往会造成决策边界附近存在模糊特征的问题, 阻碍域适应的性能.因此, 本文构建2个不同的情感分类器, 通过对抗式训练扩大不同领域样本在向量空间中的特征分布对齐边界, 减少模糊特征导致的错误分类的问题.
在跨域方面级情感分类中, 假设源域中包含标记数据
Ds=
目标域中包含未标记的数据
Dt=
其中, x表示数据集中的句子, a表示x中的方面词之一, ys表示源域方面词a的情感类别标签, Ns表示源域中标记数据的数量, Nt表示目标域中未标记数据的数量.跨域方面级情感分类的目标是学习一个源域和目标域之间共享的映射
F∶ {x}→ {f}→ y,
即使用源域的标记样本Ds训练分类器, 使分类器适应预测目标域中未标记样本Dt中指定的方面词的情感类别.
本文提出基于对抗式分布对齐的跨域方面级情感分类模型(ADA) , 结构如图1所示.
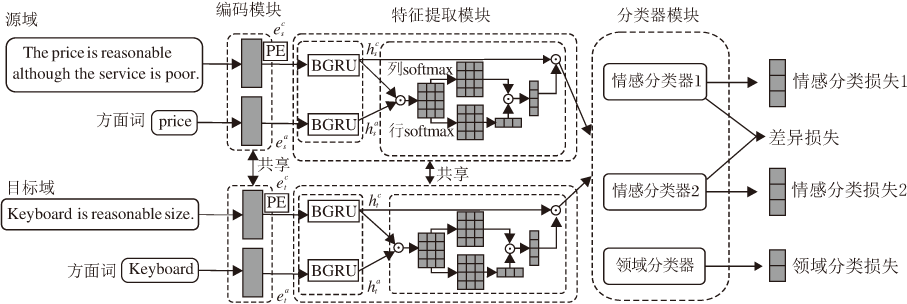 | 图1 本文模型框图Fig.1 Flow chart of the proposed model |
给定来自源域和目标域的输入句子及指定的方面词, 模型包含模块如下: 1)编码模块.将输入文本进行编码, 得到各自的分布式表示.2)特征提取模块.对于编码模块得到的上下文嵌入表示和方面词嵌入表示, 经过循环神经网络学习上下文表示, 交互注意力层进行重要信息的捕捉, 完成特征提取.3)分类器模块.对特征提取模块得到的源域表示和目标域表示分别经过分类器进行类别预测, 得到不同的损失.两个情感分类器对源域特征表示情感标签的预测作为情感分类损失.将源域和目标域特征表示预测结果的差值作为差异损失, 使两个情感分类器趋于不同.增加梯度反转层的领域分类器, 对两个领域特征表示进行领域类别预测, 作为领域分类损失.
文本的表达含义多样, 分布式表示可更好地表达文本的语义信息.本文采用预训练的GloVe(Global Vector for Word Representation)[11]词向量, 为文本数据中的每个词生成分布表示.首先生成词嵌入(Embedding)查找矩阵L∈
x=[w1, w2, …, wn],
可将输入映射为上下文嵌入
同时, 对给定的输入方面词
a=[w1, w2, …, wm],
映射为方面词嵌入表示
Ea=[e1, e2, …, em]T∈
跨域方面级情感分类任务需要充分利用所给的方面词信息, 建立方面词与文本情感信息的联系.在评论文本中, 通常表达情感的特征词与其相关的方面词接近, 本文采用融合位置信息的方式丰富嵌入表示信息, 有助于提高方面级情感分类的性能.对于嵌入句子表示
PE(pos, 2i)=sin
其中, pos表示在句子中单词所在的位置, i表示位置编码PE中pos处对应向量的第i维.
由于评论文本中各领域的方面词可能含有不只一个单词, 需要学习长距离依赖性的特征.对上下文句子嵌入表示Ec和方面词嵌入表示Ea分别使用双向门控循环单元(Bidirectional Gated Recurrent Unit, BiGRU)进行特征提取, 生成融入上下文丰富语义的表示Hc和Ha:
Hc=
对于上下文特征表示Hc和方面词特征表示Ha, 通过交互注意力(Interaction Attention, IA)层计算注意力权重, 建立上下文与方面词之间的交互关系, 使上下文表示更关注与方面词关联度较高的特征.计算2种特征表示的交互矩阵
I=HcHa,
通过I进行列softmax和行softmax, 得到α 和β , 进行再一次交互, 得到与方面词密切相关的上下文注意力γ :
γ = $\frac{1}{n} \sum^{}_{i}$ α β T.
将γ 作用于上下文表示Hc, 重点关注与方面词关系密切的特征, 得到最终的特征表示:
H=Hcγ .
对于源域数据和目标域数据经过前面各层得到的特征表示H, 使用基于梯度反转层GRLd进行梯度反转:
GRLd(x)=x,
通过反转梯度方向训练领域分类器, 使源域和目标域表示可映射到同一分布空间中进行边缘对齐.在这里, 领域边缘是指将2个不同领域的样本的特征映射到同一向量空间时不同领域样本的分布边界.领域边缘对齐或特征对齐是指在同一向量空间中, 使不同领域样本的特征分布接近, 分类器可较好区分来自不同领域的样本的情感极性.通过领域分类器, 预测领域类别标签:
yd=softmax(WdGRLd(H)+bd).
在训练领域分类器和特征提取器时, 将源域和目标域表示映射到同一分布空间中, 缩小两个领域特征表示之间的距离.但是情感分类器形成的决策边界附近可能会存在模糊的特征, 这些特征使样本容易被错误地归类, 为了更好地进行域适应, 解决决策边界样本被错误分类的问题, 训练2个情感分类器C1、C2, 检测这些决策边界附近容易出现错误分类的样本点, 进一步训练特征提取器, 生成更好的特征, 使样本点远离决策边界.
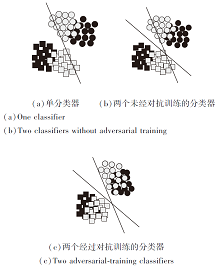
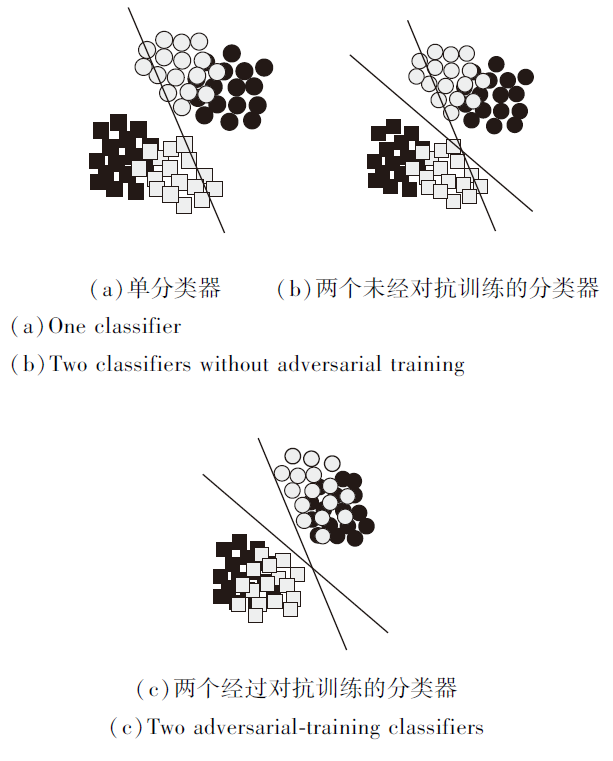
如图2所示, 黑色表示源域数据, 灰色表示目标域数据, 圆形表示积极样本, 正方形表示消极样本.
 | 图2 不同类型分类器形成的决策边界Fig.2 Decision boundaries formed by different classifiers |
由图2(a)可观察到决策边界附近的目标域样本有部分被错误分类.当额外训练一个不同的情感分类器形成另一个不同的决策平面时, 如(b)所示, 经过训练最终会达到如(c)所示的效果, 较大程度缓解决策平面附近的样本错误分类的问题.
源域标记数据经过特征提取模块G得到特征表示H(s), 分别经过两个情感分类器C1、C2, 进行情感类别标签的预测, 最小化情感分类损失以优化参数, 情感分类损失
Lcls=- $\frac{1}{N_{s}} \sum^{N_{s}}_{i=1} \sum^{K}_{j=1}$
其中,
K表示情感极性类别的类别数.
如果改变情感分类器C1、C2定义的决策边界, 靠近决策边界的样本会相应产生变化.为了使C1、C2针对这些边界样本提供不同的指导, 形成不同的决策边界, 用于对齐特征表示, 首先需要定义两个情感分类器的差异性函数.对两个情感分类器的概率输出
p1=(y|x), p2=(y|x)
定义差异损失:
Ldis=
差异性函数d(p1(y|x), p2(y|x))是通过计算C1、C2输出概率之差的绝对值在各个类别上的均值实现的, 即
d(p1(y|x), p2(y|x))= $\frac{1}{H} \sum^{K}_{i=1}$ |1i(y|x)-p2i(y|x) |.
使用对抗性训练的思想训练情感分类器C1、C2, 用于对齐特征分布表示.为了使原本靠近决策边界的点远离决策边界, 需要将2个情感分类器的差异性损失最大化.将其它模块的参数固定, 只训练2个情感分类器C1、C2的参数, 通过最大化差异性函数检测决策边界附近的点.训练目标如下:
为了使原先决策平面附近容易误分类的点重新被正确归类, 需要使其远离由两个不同情感分类器重新构建的新的决策边界.因此固定两个情感分类器C1、C2的参数, 训练特征提取器部分G的参数, 使差异最小化, 优化目标如下:
重复性的对抗训练使模型可定位到原本决策平面附近误分类的样本点, 进一步使其远离新形成的决策平面, 进行正确的分类, 而不再是简单的领域边缘对齐.
模型的训练过程步骤如下.
1)由情感分类损失和领域分类损失构成损失
L1=Lcls+λ 1Ld,
通过最小化损失L1优化整个模型各层的相关参数.
2)损失
L2=Lcls-λ 2Ldis,
固定其它层参数, 仅优化两个情感分类器C1、C2的参数, 通过最小化情感分类损失并最大化C1、C2的差异性, 使两个分类器形成的决策平面趋于不同, 形成更大的决策平面间隔, 扩大对齐边界, 定位决策边界的模糊特征.
3)损失
L3=Lcls+λ 3Ldis,
固定其它层参数, 仅训练特征提取层, 通过最小化情感分类损失和C1、C2差异性, 使特征提取层提取到远离决策边界的特征.
本文使用的数据集来自公开评测的SemEval-2014任务4[13]数据集和Dong等[14]构建的Twitter数据集, 包括3个领域:餐厅(Restaurants, R), 平板电脑(Laptops, L), 推特(Twitter, T).数据集的统计结果如表1所示.
| 表1 实验数据集 Table 1 Experimental datasets |
由R、L、T领域可构建6个跨域对(源域→ 目标域), 分别为L→ R, R→ L, L→ T, T→ L, R→ T, T→ R.对于每个跨域对Ds→ Dt, 训练集由源域的标记数据和目标域的未标记数据构成, 目标域数据仅保留方面词信息.训练集包括源域的训练集和目标域的训练集, 源域的测试集作为验证集以选择最优模型.
词嵌入使用100维的预训练的GloVe向量(https://apache-mxnet.s3.cn-north-1.amazonaws.com.cn/gluon/embeddings/glove/glove.6B.zip)进行初始化, 在训练过程中微调.模型的隐藏层大小设为100, BiGRU的层数设置为2, 网络权重是从均匀分布U [-0.01, 0.01]上随机初始化.在训练过程中, 使用Adam(Adaptive Moment Estimation)算法进行优化, 默认初始学习率为1e-3.批次大小设为64, 其中50%来自源域, 50%来自目标域.
选择如下基线模型验证ADA的有效性.
1)ATAE-LSTM[1].学习方面词嵌入, 使用方面词参与注意力权重的计算, 生成特定方面的句子表示.
2)RAM(Recurrent Attention Network on Memo-ry)[15].采用多重注意力机制捕获距离较远的情感特征, 将多重注意力结果与递归神经网络进行非线性组合, 提取重要信息预测情感极性.
3)Cabasc(Context Attention Based Aspect Based Sentiment Classification Model)[16].基于方面的内容注意力机制的情感分类模型.句子级内容注意力机制从全局捕获给定方面词重要信息, 上下文注意力机制考虑词序和相关性.
4)IAN[2].交互地分别学习上下文表示和方面词表示.
本文也选择与本文任务相似设置, 进行域适应的基线模型.
1)IATN[8].使用领域分类器识别共有特征, 并从方面词提取信息, 合并句子和方面词的信息, 较好地进行跨领域情感迁移.
在6个跨域上对比模型的分类性能, 评价指标采用准确率(Accuracy, Acc)和F1值, 结果如表2所示.
由表2可看出, ADA在大部分跨域对上的Acc值与F1值均取得最优值, 表明加强决策边界附近的模糊特征的学习有利于提升跨域情感分类任务性能.在T→ R跨域对上, 相比IATN, ADA的准确率提高29.74%, 原因在于T作为源域, R作为目标域学习的决策边界附近的模糊特征较多, ADA减少这些模糊特征的误分类问题.对于那些没有针对跨域进行策略调整的其它基线方法, 虽然在源域的验证集上取得较好结果, 但应用于目标域时, 分类性能显著下降, 这进一步验证针对跨领域进行策略调整的必要性.
| 表2 各模型在6个跨域对上的实验结果对比 Table 2 Experimental results comparison of different models with 6 cross-domain pairs% |
为了验证ADA中各个策略的有效性, 分别对对抗式情感分类器(Adversarial Sentiment Classifier, ASC)和交互注意力机制(IA)进行消融实验, 定义如下对比模型.
1)ADA-ASC.在ADA的基础上, 不再对抗式地训练两个情感分类器, 捕获决策边界的模糊特征, 仅保留ADA的训练过程的第一步, 仅使用一个情感分类器.
2)ADA-IA.与ADA唯一区别是不使用交互注意力层, 其它完全相同.
3种模型在6个跨域对上的实验结果对比如表3所示.由表可进一步验证对抗式训练情感分类器进行分布对齐和运用交互注意力这两种策略的有效性.在大部分的跨域对数据上, ADA-IA性能均优于ADA-ASC, 与ADA的性能差异较小, 说明跨域方面级情感分类性能的提高不仅依赖于领域之间共享的方面词与情感特征的语义关系, 更依赖于决策边界的误分类问题.将源域和目标域的表示映射到同一空间, 对于执行边缘对齐方式产生的不足, 可通过对抗训练两个情感分类器、扩大对齐边界的方式进行有效缓解.
| 表3 各模型的消融实验结果对比 Table 3 Result comparison of ablation experiment of different models% |
为了进一步表明ADA进行对抗式分布对齐的效果优于广泛使用的边缘对齐方法, 在R→ L跨域对上, 对ADA和ADA-ASC进行源域和目标域特征表示分布的可视化, 如图3所示.
由图3(a)可发现, ADA-ASC源域积极样本和消极样本区分性较好, 但目标域的各类样本之间不具有区分性, 源域和目标域样本距离较远, 领域适应性较差.由(b)可发现, ADA中源域积极样本和目标域积极样本、源域消极样本和目标域消极样本彼此靠近, 同时不同极性之间又具有较好的区分性.两种模型均使用对抗性的领域分类器进行领域共享特征的学习, 但是ADA使用两个情感分类器进行对抗式训练, 扩大对齐边界, 使模糊特征导致的样本误分类可能性下降, 学习更好的决策边界, 有助于最终的情感类别正确预测.
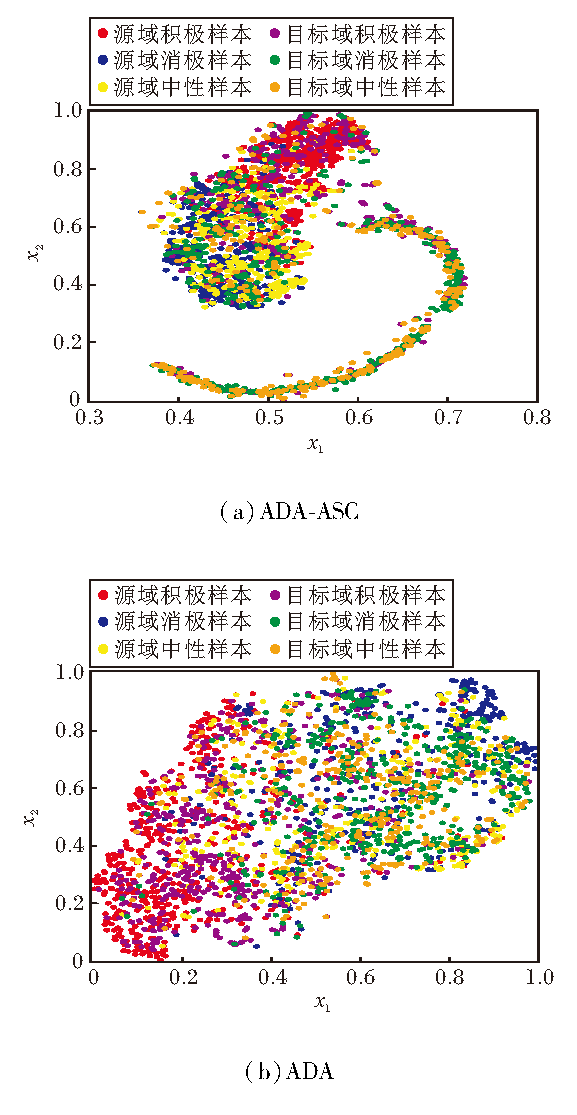 | 图3 各模型在R→ L跨域对上的特征表示可视化Fig.3 Feature representation visualization of different models with R→ L cross-domain pair |
本文针对跨域的方面级情感分类任务, 提出基于对抗式分布对齐的跨域方面级情感分析模型(ADA), 使用交互注意力机制建立方面词与上下文的语义关联, 使用基于梯度反转层的领域分类器学习领域之间的共享特征表示.特别地, 针对决策边界附近存在模糊特征的问题, 对抗式训练多个不同的情感分类器, 扩大决策边界与边界样本的距离, 缓解模糊特征导致的样本错误分类问题.在公开评测的跨域方面级情感分类数据集上评测模型性能, 验证ADA优于经典的方面级情感分类模型, 充分的实验分析表明ADA中各种策略的有效性.今后将从如何提取领域独有特征和通过梯度反转之外的其它策略提取领域共有特征这两方面获得更好的语义表示, 进一步提高模型性能.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|