


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
结合源域差异性与目标域不确定性的深度迁移主动学习方法
[刘大鹏1  , 曹永锋
, 曹永锋1 , 苏彩霞1 , 张伦1 ]
, 曹永锋, 苏彩霞, 张伦]
|
|



作者简介:

刘大鹏,硕士研究生,主要研究方向为图像处理、机器视觉.E-mail:490163724@qq.com.

苏彩霞,硕士,讲师,主要研究方向为遥感图像处理.E-mail:761289416@qq.com.

张 伦,硕士研究生,主要研究方向为图像处理、机器视觉.E-mail:1032476110@qq.com.
针对训练深度模型时样本标注成本较大的问题,文中提出结合源域差异性与目标域不确定性的深度迁移主动学习方法.以源任务网络模型作为目标任务初始模型,在主动学习迭代中结合源域差异性和目标域不确定性挑选对模型最具有贡献的目标域样本进行标注,根据学习阶段动态调整两种评价指标的权重.定义信息榨取比概念,提出基于信息榨取比的主动学习批次训练策略及 T& N训练策略.两个跨数据集迁移实验表明,文中方法在取得良好性能的同时可有效降低标注成本,提出的主动学习训练策略可优化计算资源在主动学习过程中的分配,即让方法在初始学习阶段对样本学习更多次数,在终末学习阶段对样本学习较少次数.
About Author:
LIU Dapeng, master student. His research interests include image processing and machine vision.
SU Caixia, master, lecturer. Her research interests include remote sensing image processing.
ZHANG Lun, master student. His research interests include image processing and machine vision.
Training deep neural network models comes with a heavy labeling cost. To reduce the cost, a deep transfer active learning method combining source domain and target domain is proposed. With the initial model transferred from source task, the current task samples with larger contribution to the model performance improvement are labeled by using a dynamical weighting combination of source domain difference and target domain uncertainty. Information extraction ratio(IER) is concretely defined in the specific case. An IER-based batch training strategy and a T&N batch training strategy are proposed to deal with model training process. The proposed method is tested on two cross-dataset transfer learning experiments. The results show that the transfer active learning method achieves good performance and reduces the cost of annotation effectively and the proposed strategies optimize the distribution of computing resources during the active learning process. Thus, the model learns more times from samples in the early phases and less times in the later and end phases.
本文责任编委 于 剑
Recommended by Associate Editor YU Jian
近年来, 深度学习在图像、语音和自然语言处理等领域取得显著成效[1, 2, 3].训练目标任务深度模型需要数以万计带有标签的样本, 获取这些标签(标注)需要耗费大量的经费、时间和精力, 成本昂贵.如何利用少量的目标域标注样本实现目标任务模型高性能已成为迫切需要解决的问题.深度迁移学习和深度主动学习是深度学习领域中用于解决这一问题的两类主流方法.
深度迁移学习降低训练样本必须与测试样本独立同分布的要求, 尝试将知识从源域迁移到目标域[4].从空白开始训练一个目标任务模型需要大量目标域标注样本, 而从一个与目标任务相关的源任务模型开始训练, 会大量减少所需的目标域标注样本[5].Oquab等[6]在ImageNet数据集[7]上训练特征提取层, 并在其后新添两个全连接层以构建目标任务模型.在微调模型以适应目标任务时, 使用较少的目标任务样本可得到较优效果.Tzeng等[8]在源任务模型中引入适应层和域距离损失, 优化源域表达对目标域的适应性.在适应层中利用最大平均差异(Maximum Mean Discrepancy, MMD)[9]计算两域的分布距离, 通过最小化域距离损失得到域不变表达.Long等[10]在文献[8]的基础上进行改进, 使用多核最大平均差异(Multi-kernel MMD, MK-MMD)[11]替换MMD计算域分布距离, 将一个适应层替换为三个全连接层.Tzeng等[12]提出基于对抗学习的域适应方法(Adversarial Discriminative Domain Adaptation, ADDA), 在考虑源域分类损失的同时, 引入生成对抗网络(Generative Adversarial Networks, GAN)[13], 学习域不变的特征表示.上述工作均致力于构建能较好泛化到目标域中的源任务模型/特征表达.然而, 在此基础上, 需要将源任务模型调整至适应目标任务, 仍需很多目标域标注样本.
深度主动学习对未标记样本池进行选择性采样和标注, 试图使用少量选择性标注的样本, 使深度模型达到预期性能.现有研究表明[5, 14, 15], 深度主动学习能以一定比例减少训练深度模型所需的标注样本.Wang等[16]提出与半监督方法结合的深度主动学习方法, 在主动查询时挑选两种互补性样本(高置信度样本和低置信度样本), 训练当前深度模型.Smailagic等[15]提出用于医学图像分割的深度主动学习方法, 基于样本之间的差异性度量进行主动查询.Zhou等[17]提出基于样本多样性的深度主动学习方法, 将样本多样性定义为对样本增广图像的预测一致性.
已有研究者开始结合深度主动学习和深度迁移学习.Zhou等[17]提出主动增量微调方法(Active Incremental Fine-Tuning, AIFT), 迁移在ImageNet数据集上训练的AlexNet[18], 使用结合多样性与不确定性的主动学习方法, 在目标域未标注样本池中挑选最具信息量的样本进行标注.Huang等[5]同样迁移在ImageNet数据集上预训练的深度网络模型, 使用动态权衡独特性和不确定性的主动学习方法, 从目标域未标注样本池中挑选样本进行标注.Deng等[19]同时迁移在源域中预训练过的深度模型和部分源域样本, 并主动从目标域中挑选最具不确定性的样本进行标注.
为了更有效地降低训练模型需要的样本标注成本, 本文提出结合源域差异性与目标域不确定性的深度迁移主动学习方法(Deep Transfer Active Lear-ning Method Combining Source Domain Difference and Target Domain Uncertainty, DeepTAST).以源任务网络模型作为目标任务初始模型, 在主动学习迭代中结合源域差异性和目标域不确定性两种评价指标, 挑选目标域样本进行标注, 并根据主动学习的迭代轮次动态调整两种评价指标权重.本文方法在每个主动学习轮次中对样本包含信息的学习程度定义为信息榨取比(Information Extraction Ratio, IER), 提出基于信息榨取比的主动学习批次训练策略, 可有效避免模型在初始学习阶段对样本学习不足, 而在终末学习阶段对样本学习过度的问题.在二分类和多分类公开图像数据集上进行对比实验, 并对基于信息榨取比的主动学习批次训练策略进行深入探究和分析.实验表明, 本文方法具有较优性能, 可节约更多的标注成本.基于信息榨取比的批次训练策略可显著提高深度主动学习的学习效率, 适用于不同深度主动学习方法.
定义
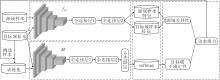
结合源域差异性与目标域不确定性的深度迁移主动学习方法(DeepTAST)框图如图1所示.在任一迭代轮次t, 运行流程如下.首先, 将源域样本和目标域未标注样本同时通过
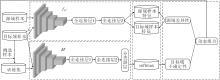 | 图1 本文方法框图Fig.1 Framework of the proposed method |
源域差异性准则基于如下两个基本认知.
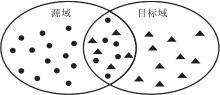
基本认知1.可将源任务深度神经网络分为两部分:特征提取层和分类器层.特征提取层作用是从原始样本中提取更抽象的特征, 分类器层作用是根据提取的特征对样本进行分类.一般地, 分类器层是带有softmax函数的线性分类器.如果线性分类器层能对样本进行较好的分类, 说明特征提取层可从原始样本中提取到线性可分的特征.在线性可分特征表示下, 相似样本距离较近, 相异样本距离较远.因此, 将源域样本和目标域样本在源任务模型的特征提取层重新投影, 如图2所示.重新投影后的两域相似的样本会距离较近, 如图2中两域重叠部分; 两域中差异性较大的样本距离会较远.
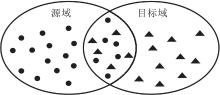 | 图2 源域样本和目标域样本的分布示意图Fig.2 Distribution of source domain samples and target domain samples |
基本认知2.对于模型迁移应用, 即使用源域样本训练一个初始模型, 再使用目标域样本对其微调, 以适应目标任务.目标域中与源域高度相似的样本对初始模型的改进贡献较小, 因为模型已学习过相似的样本, 与源域差异越大的样本对初始模型改进的贡献越大.
基于上述认知, 设计源域差异性准则(Other-ness), 用于从目标域中挑选与源域差异性较大的样本.源域差异性定义为
Otherness(
其中,
本文基于信息熵计算样本的目标域不确定性指标, 目标域不确定准则定义为
Uncertainty(
其中,
目标域不确定性准则用于衡量目标域样本在当前模型下的预测不确定性.不确定性较大的样本位于分类器类别分割超平面附近, 一旦获得标注, 容易产生对该超平面的局部改进.
源域差异性准则从目标域中挑选与源域差异性较大的样本, 目的是让目标任务模型能快速适应到目标任务中, 这个准则在学习初期起主要作用.随着迭代进行, 当目标任务模型已逐渐学习到针对目标任务的特征表示后, 提高模型的分类性能成为主要目标, 此时目标域不确定性准则应起主要作用.
为了让目标任务模型在不同的迭代阶段都学习到最具信息量的目标样本, 本文设计动态调整策略DAS, 将源域差异性指标和目标域不确定指标进行动态权衡.动态调整策略定义为
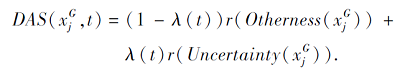
上述公式中包含2个预定义的函数:
λ:{1, 2, …, T}→ [0, 1], r:R→ [1, 2, …, u].
λ为动态权重函数, 它的引入是为了根据学习阶段动态调整两种指标的权重, 表示为
λ(t)=
其中, β∈ [0, 1], t=1, 2, …, T, T为迭代总轮数.
r为取升序排序序号函数, 它的引入是为了对样本的源域差异性指标和目标域不确定指标进行量纲统一, 表示为
r(F(xi))=mi,
其中,
F(xi)≤F(xj)⇔mi<mj,
mi=1, 2, …, u, mj=1, 2, …, u,
u为目标域中未标记样本的总个数,
F∈ {Otherness, Uncertainty}.
批次训练策略是深度主动学习中常用的模型训练策略, 应用于每次主动学习迭代.设已将新标注样本放入已标注样本集中, 则N遍批次训练策略如下:从已标注样本集中迭代挑选批次样本训练模型, 直到所有已标注样本都被挑选过, 这个过程称为训练模型1遍.然后重新打乱样本顺序, 再训练模型N-1遍, 其中N为经验超参数.
批次训练策略在实际操作中存在问题:当样本携带信息量较大且深度模型参数较多时, 在主动学习迭代前期, 训练模型1遍(即N=1)很难让深度模型充分学习样本包含的信息; 当训练模型多遍时, 即N=n, n≫1, 若主动学习迭代进行到第m(m≫1)次, 第1次挑选的样本总共被模型学习过mn次, 第2次挑选的样本总共被模型学习过(m-1)n次.以此类推, 第m次挑选的样本总共被模型学习n次.第i(i≪m)次挑选样本的总学习次数是第m次挑选样本总学习次数的m-i倍, 则第i次挑选的样本可能由于学习过多的次数导致模型过拟合.本文提出的基于信息榨取比(IER)的批次训练策略能够解决上述问题.
信息榨取比定义为方法对当前样本集合包含信息的学习程度.具体地, 这里使用方法已学习过的某一批次样本的平均预测准确率作为方法对该批次样本的信息榨取比, 表示为
IER=
其中,
基于信息榨取比的批次训练策略单独运行于每个主动学习迭代轮次, 具体如下:1)对当前所有已标注样本进行随机打乱; 2)从已标注样本集中取出一个批次样本进行模型训练, 计算模型对该批次样本的信息榨取比; 3)当信息榨取比低于信息榨取比阈值T时, 使用该批次样本对模型进行循环训练, 直到模型对该批次样本的信息榨取比高于T时停止; 4)取下一个批次样本重复上述的训练方式, 直到用光已标注集样本.
在主动学习迭代前期, 基于信息榨取比的批次训练策略会促使方法对同一批次样本循环训练多次, 使方法对该批次样本信息的学习程度达到设定的阈值T.随着主动学习迭代轮次的增加, 方法对主动学习前期标注样本的信息已具有较高的学习程度, 而仅对当前轮次新加入的标注样本信息学习不足, 因此会对包含新标注样本的批次多次学习, 而对仅包含旧标注样本或包含很少新标注样本的批次学习次数减少.这样就避免一般批次训练策略造成的问题.
需要注意的是, 信息榨取比阈值T需要根据所用模型和目标任务信息的复杂度进行调整.一般地:方法参数越多, 目标任务信息越复杂, 信息榨取比阈值相应越高; 否则, 阈值越低.当该阈值为0时, 基于信息榨取比的批次训练策略等同于N=1的一般批次训练策略.
实验采用4个广泛应用的公开分类数据集:CIFAR-10、Cats vs.Dogs、MNIST、USPS数据集.基于上述数据集构建2个跨数据集迁移实验:手写数字识别迁移(从MNIST迁移到USPS)和猫狗识别迁移(从CIFAR-10迁移到Cats vs.Dogs).在手写数字识别迁移实验中, 为统一输入尺寸, 将MNIST数据集的图像缩放至16× 16.由于2个数据集类别一致, 可直接将在MNIST任务预训练的完整深度模型迁移到USPS数据集上使用.在猫狗识别迁移实验中, 将Cats vs.Dogs数据集的图像缩放至32× 32× 3的大小, 与CIFAR-10数据集的图像尺寸一致.由于2个数据集类别不一致, 需要把CIFAR-10数据集上任务预训练的深度模型中最后的十分类层替换成一个二分类层, 再迁移到Cats vs.Dogs数据集上使用.此外, 在计算源域差异性指标时, 只采用源域中与目标域相同类别的图像.
为了验证本文方法(DeepTAST)的有效性, 使用如下对比方法:迁移学习+源域差异性策略(Trans-fer and Otherness Strategy, T-Otherness)、迁移学习+随机抽样策略(Transfer and Random Strategy, T-Random)、迁移学习+最大信息熵策略(Transfer and Entropy Strategy, T-Entropy)、AIFT[17].AIFT仅适用于二分类任务, 仅在猫狗迁移实验中进行对比.
准确率是常用的分类性能评价指标, 表示被分类模型正确预测的样本数在总样本数中所占的比例:
accuracy=
其中, TP表示实际为正例且被分类器划分为正例的样本数, FP表示实际为负例但被分类器划分为正例的样本数, TN表示实际为正例但被分类器划分为负例的样本数, FN表示实际为负例且被分类器划分为负例的样本数.准确率越高, 表示方法性能越优.
学习曲线是评价主动学习算法性能的常用方式.此外, 杨菊[20]通过大量实验证实, 学习曲线下面积(Area under the Learning Curve, ALC)、对数学习曲线下面积(Logarithmic ALC, LALC)可保证在同质分类器下不同主动学习方法评估结果的公正性.
ALC是指整个学习曲线下包含的面积, 是评价整个迭代过程中不同主动学习算法优劣的综合性指标.假设主动学习算法需要进行N次迭代, 学习曲线可表示为一个由N+1个元素组成的一维向量[p0, p1, …, pN], 则
ALC=
主动学习的目的是利用尽可能少的标注样本, 使方法达到尽可能好的性能, 初始学习阶段的模型性能提升尤为重要.LALC可突出评价不同主动学习算法在学习初始阶段的性能差距:
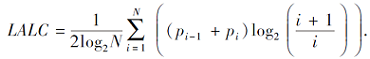
为了直观看到主动学习方法挑选样本与源域样本集及目标域样本集之间的关系, 对于所有样本(在
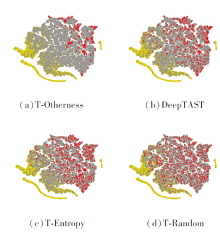
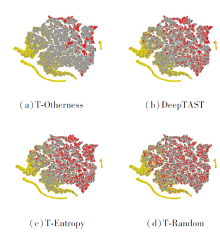 | 图3 猫狗识别迁移实验中各方法挑选样本的可视化Fig.3 Visualization of samples selected by different methods in cat and dog recognition transfer experiment |
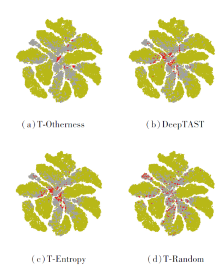
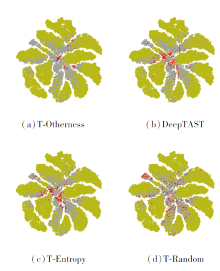 | 图4 手写数字识别迁移实验中各方法挑选样本的可视化Fig.4 Visualization of samples selected by different methods in handwritten digit recognition transfer experiment |
由图3和图4均可见, T-Otherness挑选的样本大多距源域样本偏远, 这正是方法期望达到的效果.T-Random挑选的样本分布较均匀, 部分样本与源域样本重合, 属于重复标注, 从标注成本角度上讲有些浪费.T-Entropy挑选的样本与源域样本具有一定的差异性, 重合区域不大, 但相比T-Otherness挑选的样本, 样本分布更分散.DeepTAST挑选的样本在分布上近似结合T-Otherness和T-Entropy的特点, 只不过在主动查询时间上, 前期主要是T-Otherness起作用, 后期主要是T-Entropy起作用.
在猫狗识别迁移实验中, 本文选用经典网络框架视觉几何组(Visual Geometric Group 16, VGG16)作为基础模型, 将VGG16在CIFAR-10数据集上进行预训练, 预训练后的方法测试准确率为89.5%.采用基于信息榨取比的批次训练策略训练目标任务模型, 信息榨取比阈值T=0.85.
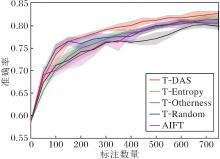
实验共15次迭代, 每轮挑选50个目标样本.各方法的学习曲线如图5所示, 图中给出4次重复实验的平均水平, 阴影部分表示多次实验的波动情况.
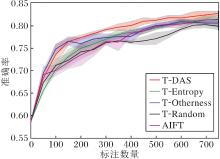 | 图5 各方法在猫狗识别迁移实验上的学习曲线Fig.5 Learning curves of different methods in cat and dog recognition transfer experiment |
分析图5的实验结果, 可得如下结论.
1)在迭代的第1~3周期(对应标注数量50~150), 5条学习曲线都迅速提升.这是由于初始模型来自源任务, 初学目标域样本让初始模型快速适应目标任务.性能增长速率最快的是T-Otherness和DeepTAST, 表明在迭代前期根据源域差异性准则挑选的样本对方法改进更大.
2)在迭代的第4~12周期(对应标注数量200~600), T-Random性能最差.这是由于很多样本的信息已在源域中学过.T-Entropy在这个周期中的性能增长速率高于T-Otherness, 体现出T-Entropy的优势, 而T-Otherness对方法改进的贡献逐渐下降.DeepTAST在主动迭代前期侧重于Otherness, 随着迭代轮数的增加, 逐渐向Entropy进行转变, 结合两种策略的优势, 因此取得最高性能.
3)在迭代的第13~15周期, 对应标注数量650~750, 5种方法学习曲线的增长速率都已趋近于0, 处于收敛阶段.DeepTAST性能最高, 然后依次是AIFT、T-Entropy、T-Otherness、T-Random.
各方法的ALC和LALC指标如表1所示.由表可知, DeepTAST的ALC和LALC指标最高.T-Otherness的ALC和LALC指标排在第二位.T-Entropy的ALC指标略高于AIFT.LALC指标略低于AIFT.T-Ran-dom的ALC和LALC指标最差.
| 表1 各方法在猫狗识别迁移实验上的指标值对比 Table 1 Index values of different methods in cat and dog recognition transfer experiment |
取模型准确率到达80%时, DeepTAST相对T-Entropy和T-Random节省的标注量.实验表明, 为使模型准确率到达80%, DeepTAST使用400个目标域样本, T-Entropy使用550个目标域样本, T-Random使用650个目标域样本.相比T-Random, DeepTAST节约38.5%的标注量, 相比T-Entropy, DeepTAST节约27.3%的标注量.
在相同标注量时, DeepTAST与T-Entropy的渐进模型性能差距为1.2%, 即曲线近似走平后最后一次迭代时的性能指标差.在迭代过程中最大的模型性能差距为3.2%, 即两者性能曲线中的最大差值.
在手写数字识别迁移的实验中, 本文选用LeNet-5作为基础模型, 并将LeNet-5在MNIST数据集上进行预训练, 预训练后的方法测试准确率为98%.采用基于信息榨取比的批次训练策略训练目标任务模型, 信息榨取比阈值T=0, 相当于N=1的批次训练策略.
实验共18次迭代, 每轮挑选10个目标样本.各方法的学习曲线如图6所示.
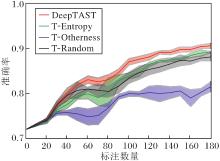 | 图6 各方法在手写数字识别迁移实验上的学习曲线图Fig.6 Learning curves of different methods in handwritten digit recognition transfer experiment |
分析图6的实验结果可得如下结论.
1)在迭代的第1~8周期, 对应标注数量10~80, DeepTAST性能最高.T-Entropy性能低于T-Ran-dom, 这可能由两点原因导致:(1)目标任务模型在主动学习迭代前期预测性能较差, 导致信息熵计算结果不可靠; (2)T-Random挑选的样本在各个类别的占比更均衡.
2)在迭代的第9~15周期, 对应标注数量90~150, DeepTAST性能最高.T-Entropy性能超过T-Random, 这可能由如下两点导致:(1)目标任务模型预测性能变好后, T-Entropy的优势开始体现; (2)T-Random挑选的很多样本的信息已被模型在源域中学过.
3)在所有迭代轮次中, T-Otherness性能最低.通过检查T-Otherness挑选的样本标签发现, 类别聚集和类别缺失为主要原因.T-Otherness挑选样本的类别大量集中在类别5和类别7(说明源域和目标域的差异性主要体现在这两类样本中), 而缺失类别0、类别1、类别6、类别8的样本.DeepTAST性能高于T-Entropy和T-Otherness, 说明动态结合可在较好地弥补各自短项的同时增强性能.
各方法的ALC和LALC指标对比如表2所示.由表可知, DeepTAST的ALC和LALC指标最高.T-Entropy的ALC指标高于T-Random, LALC指标低于T-Random.这说明T-Entropy的整体性能优于T-Random, 但在初始学习阶段, T-Random优于T-Entropy.T-Otherness的ALC和LALC指标最差.
| 表2 各方法在手写数字识别迁移实验上的指标值对比 Table 2 Index values of different methods in handwritten digit recognition transfer experiment |
取模型的准确率到达88%时, DeepTAST相对T-Entropy和T-Random节省的标注量.实验表明, 为了使模型准确率达到88%, DeepTAST使用120个目标域样本, T-Entropy使用160个目标域样本, T-Random使用180个目标域样本.即DeepTAST相比T-Random, DeepTAST节约33.3%的标注量, 相比T-Entropy, DeepTAST节约25%的标注量.
在相同标注量情况下, DeepTAST与T-Entropy的渐进模型性能差距为1.4%, 即曲线近似走平后最后一次迭代时的性能指标差, 在迭代过程中最大的模型性能差距为3.5%, 即两者性能曲线中的最大差值.
在猫狗识别迁移实验中, 本节设置T=0, 0.65, 0.75, 0.85, 1, 观察T对不同迁移主动学习方法性能的影响, 具体如图7所示.
 | 图7 T对各方法性能的影响Fig.7 Effect of T on performance of different methods |
在主动学习前期和中期的迭代轮次中, 各方法的性能都随阈值T的增高而显著增高.这可能由于此阶段目标域样本集还有大量信息未被模型学习, 增高阈值T会增加对样本的学习次数, 进而学习更多信息, 用于改善性能.在主动学习后期的迭代轮次中, 不同阈值T得到的方法性能趋于相近.这可能是由于经过多轮学习, 目标域样本集的大部分信息已被学习, 增高阈值T带来的学习次数增长、新信息及模型改善越来越小.
当阈值T=1时, 性能曲线出现很大波动, 提示过高的信息榨取比阈值会造成过拟合, 导致性能波动加剧.
各方法在不同阈值T下的ALC和LALC指标如表3所示.随着T值增高, 所有方法的ALC和LALC指标都呈现上升趋势, 其中DeepTAST在不同阈值T下的指标都最优.相比T=0.85, 当T=1时, DeepTAST和T-Otherness的ALC指标有所下降, 提示学习过度造成的性能波动.
| 表3 T不同时各方法的指标值对比 Table 3 Index values of methods with different T |
本节将对比基于信息榨取比的批次训练策略(基于参数T动态调整每个主动学习轮次内对已标注样本集的学习次数)与常规的批次训练策略(基于参数N固定设置每个主动学习轮次内对已标注样本集的学习次数).具体地, 在猫狗识别迁移实验中, 将T=0.85的基于信息榨取比的批次训练策略与N=1, 2, 3, 5的常规批次训练策略进行对比.结果如图8所示.
 | 图8 T、N、T&N对各方法的性能影响Fig.8 Effect of T, N and T&N on performance of different methods |
从模型性能上看, 在主动学习迭代前期, T=0.85策略优于N=1, 2, 3, 5策略, 这是由于N=1, 2, 3, 5策略对样本学习次数不足.在主动学习迭代后期, T=0.85策略性能高于N=1, 2策略, 相似于N=3策略, 低于N=5策略, 多种训练策略的性能差距逐渐缩小.这主要是因为目标任务样本集的可学习信息具有一个随着已标注样本增多而收敛的上限.
统计模型训练的总步数(模型学习一个批次样本为1步)发现, T=0.85策略的总训练步数如下:(T-Random为178步、T-Otherness为199步、DeepTAST为207步、T-Entropy为217步、AIFT为147步.上述步数都在N=1, 2策略的总训练步数120~240之间, 远少于N=3, 5批次训练策略的总训练步数360~600.T=0.85策略花费较少的训练总步数, 在主动学习迭代前期性能高于N=1, 2, 3, 5策略, 仅在主动学习迭代后期略低于N=5策略.
各方法在不同训练策略下的指标值对比如表4所示.由表可知, T=0.85策略在各方法下的ALC和LALC指标均高于N=1, 2, 3, 5策略.但有2个例外:在T-Entropy、AIFT下, T=0.85策略的ALC指标略低于N=5策略.
| 表4 各方法在不同训练策略下的指标值对比 Table 5 Indicator comparison of methods with different training strategies |
信息榨取比阈值T可动态调整在主动学习迭代中对样本的学习次数, 尤其是可使方法在主动迭代前期增加对样本的学习次数.一般批次训练策略的参数N可控制方法对样本学习次数的底线.因此本文结合两者, 提出T&N策略.
T&N策略单独运行于每个主动学习迭代轮次, 具体如下:1)对当前所有已标注样本使用N=n的批次训练策略进行训练; 2)计算方法对所有已标注样本的信息榨取比; 3)当信息榨取比低于阈值T时, 对已标注样本集打乱顺序重新学习一遍, 直到当前方法对所有已标注样本的信息榨取比高于T时停止.
在猫狗识别迁移实验中采用T=0.85、N=5的T&N策略, 得到的迁移主动学习性能曲线如图8所示.由图可见:在主动学习迭代前期, T&N策略取得的性能接近于T=0.85策略; 在主动学习迭代后期, T&N策略的性能接近于N=5策略.该策略能较好地结合阈值T和参数N两者优点.
由表4可见, T&N策略在各方法下的ALC和LALC指标均高于N=1, 2, 3, 5策略及T=0.85策略.
从空白开始训练一个深度模型需要耗费大量的标注成本和训练时间.本文提出结合源域差异性与目标域不确定性的深度迁移主动学习方法, 从源域迁移网络模型和样本, 并且主动从目标域挑选最有价值的样本微调模型.提出与迁移学习强结合的主动学习动态样本挑选策略, 以源任务网络模型作为目标任务初始模型, 在主动学习迭代中结合源域差异性和目标域不确定性, 挑选目标域样本进行标注, 根据学习阶段动态调整两种评价指标的权重.在猫狗识别和手写体数字识别两个跨域迁移数据集上的实验表明, 本文方法性能较优, 可有效降低标注成本.此外, 本文定义信息榨取比概念, 提出基于信息榨取比的主动学习批次训练策略及T&N策略.实验表明, 主动学习训练策略可优化计算资源在主动学习过程中的分配, 即让方法在初始学习阶段对样本学习更多次数, 而在终末学习阶段对样本学习较少次数.本文方法的跨领域性能还需在其它类别数据集(如文本, 语音等)上进行验证, 这将是今后工作之一.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|