
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于度量的小样本分类方法研究综述
[刘鑫1, 2  , 周凯锐
, 周凯锐1, 2 , 何玉琳3 , 景丽萍1, 2 , 于剑1, 2 ]
, 周凯锐, 何玉琳, 景丽萍, 于剑]
|
|



作者简介:

刘 鑫,博士研究生,主要研究方向为机器学习、度量学习、小样本学习.E-mail:xin.liu@bjtu.edu.cn.

周凯锐,硕士研究生,主要研究方向为机器学习、小样本学习.E-mail:20120460@bjtu.edu.cn.

何玉琳,博士,主要研究方向为企业级架构设计、高性能分布式交易系统、离线及实时大数据分析等.E-mail:heyl@xnewtech.com.

于 剑,博士,教授,主要研究方向为人工智能、机器学习.E-mail:jianyu@bjtu.edu.cn.
小样本学习旨在让机器像人类一样通过对少量样本的学习达到对事物认知和概括的能力.基于度量的小样本学习方法希望学习一个低维嵌入空间,直接对比查询集合和支持类之间的相似性,分类测试样本.文中针对基于度量的小样本学习方法,尝试从这类方法需要解决的关键问题、类表示学习和相似性度量入手,梳理相关文献.与已有相关综述不同,文中只针对基于度量的小样本学习方法进行更详尽全面的分类,而且从关键问题角度进行分类.最后总结目前代表性工作在常用的图像分类任务数据集上的实验结果,分析现有方法存在的问题,并展望未来工作.
About Author:
LIU Xin, Ph.D. candidate. Her research interests include machine learning, metric learning and few-shot learning.
ZHOU Kairui, master student. His research interests include machine learning and few-shot learning.
HE Yulin, Ph.D. His research interests include enterprise architecture design, high-performance distributed trading system, offline and real-time big data analysis.
YU Jian, Ph.D., professor. His research interests include artificial intelligence and machine learning.
Few-shot learning aims to make machines recognize and summarize things by learning from a small number of samples like humans. The metric-based few-shot learning method is designed to learn a low-dimensional embedding space and query samples can be classified based on a distance between the query samples and the class embeddings in this space. In this paper, the key issues, class representation learning and similarity learning , are discussed to sort out the relevant literature. Only metric-based few-shot learning methods are classified in a detailed and comprehensive way, and they are classified from the perspective of key issues. Finally, the experimental results of current representative research on commonly used image classification datasets are summarized, the problems of the existing methods are analyzed, and the future research is prospected.
本文责任编委 王士同
Recommended by Associate Editor WANG Shitong
大数据时代人类搜集、存储、传输和管理数据的能力日益提高, 积累大量的数据资源, 如何快速有效分析海量数据成为难点问题[1].在此背景下, 深度学习由于强大的特征提取能力得到学术界和工业界的广泛关注, 并在图像分类[2, 3]、人脸识别[4, 5]等任务上取得较大成功.然而深度学习需要依靠大量的标签数据, 在实际生活中, 有些领域有标签的数据却很难获得或获取成本非常高, 如医学、金融等.相比计算机, 人们不仅可从大量数据中挖掘知识, 也可从很少的数据中进行学习, 这就是机器学习和人类学习之间存在的差距.受人类学习观点的启发, 如何让机器模仿人类, 对于新的事物, 只需要少量样本就可以进行学习, 由此产生的小样本学习成为一个研究热点.
小样本学习最早兴起于计算机视觉领域[6], 近年来在其它领域, 如自然语言处理[7], 也受到学者们的关注, 并在图像分类[8, 9, 10, 11]、文本分类[12, 13, 14]等任务上取得不错的成绩.小样本学习的难点是容易过拟合.为了解决这一问题, 常用的方法是数据扩充[15]和知识迁移[16].数据扩充是对数据集中样本或特征进行变换(如旋转[17]、裁剪[18]、缩放[19]等), 增加样本量, 避免过拟合, 但数据扩充的方式很大程度上取决于数据集, 在某个数据集上有效的数据扩充方式不一定对另一个数据集有效[20].因此, 可以把数据扩充作为数据预处理手段与知识迁移的方法一起使用.
知识迁移是将在大量非目标数据集上学到的知识迁移到目标数据集上.在小样本学习中, 常用的知识迁移技术是元学习[17, 21, 22], 在一系列小样本任务上学习, 得到解决这类任务的元知识, 再将元知识迁移到只有少量有标记样本的目标任务上.根据要迁移的元知识, 小样本学习方法大致可分为基于微调的小样本学习方法[23, 24, 25, 26, 27, 28, 29, 30, 31]和基于度量的小样本学习方法[8, 9, 32, 33, 34, 35, 36, 37, 38, 39, 40].基于微调的小样本学习方法学到的元知识通常是一个好的初始点, 当一个新的任务到来时, 利用新任务中的少量支持集样本调整模型参数, 可快速收敛到新任务的最优点.基于度量的小样本学习方法学到的元知识是一个低维嵌入空间, 直接对比新任务中查询集合和支持集之间的相似性, 以此分类测试样本.关于小样本学习方法的相关综述可见文献[41]~文献[43].
相比基于微调的小样本学习方法, 基于度量的小样本学习方法简单有效, 是小样本学习中的重要分支.例如, 在文献[41]中的小样本学习发展图中, 基于度量的小样本学习方法与所有基于深度学习代表方法数量的比值为1/2.在文献[42]中的典型方法分类图中, 基于度量的方法占9/26.文献[43]中基于度量的分类方法与所有方法的占比为9/29.因此, 本文决定详述基于度量的小样本学习方法.
本文首先简要介绍小样本学习任务和基于度量的小样本学习方法, 分析基于度量的小样本学习方法的难点及优势, 并根据这类方法要解决的问题将基于度量的小样本学习方法分类为类表示学习方法和相似性学习方法.在实际数据上进行实验对比, 分析近年基于度量的小样本学习方法的差异.再分析现有基于度量的小样本学习方法的不足, 包括方法训练依赖于非目标数据集、泛化能力难以保证、训练机制和优化过程有待改进、模型缺乏可解释性和理论保证.针对上述问题, 提出可能的解决思路, 展望未来的研究方向.
小样本学习是指利用少量样本对事物进行认知的过程.为了方便对比不同方法, 在N-way K-shot任务上进行测试, 认为如果一个方法可在N-way K-shot任务上取得好的结果, 该方法就具备小样本学习能力.
N-way K-shot任务通常包括两部分数据:支持集(Support Set)和查询集(Query Set).支持集包括N×K个样本, 其中N为需要学习的类的数目, 每类包含K个样本, 通常设为1或5.查询集包括N×Q个样本, 来自支持集中的N类, 每类Q个样本, 用于验证方法通过支持集样本对N类的认知能力.
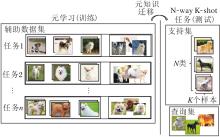
然而, 只利用N×K个样本学习容易导致过拟合, 为了解决此问题, 常借助其它有大量标签的非目标数据集A, 利用元学习的技术进行知识迁移.具体地, 在非目标数据集A上构造一系列N-way K-shot任务(通常称为Episode), 在这一系列任务上学习解决这类任务的元知识, 再将元知识迁移到只有少量有标记样本的目标任务上进行测试.
基于元学习训练机制的小样本学习方法如图1所示.由图可看出, 基于元学习的小样本学习方法的关键是元知识的迁移, 只有学到迁移性较强的元知识, 才能在测试时的小样本数据集上取得较优结果.
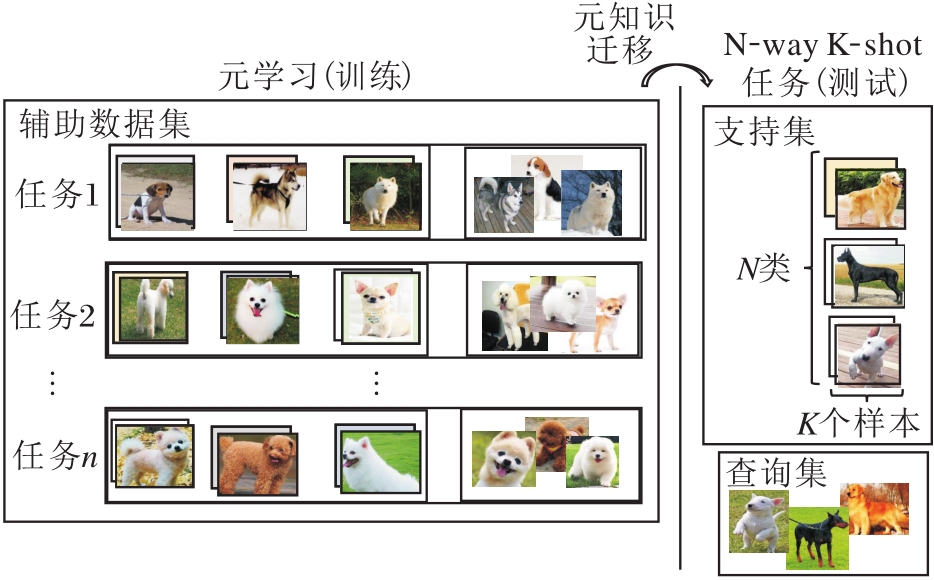 | 图1 N-way K-shot任务和基于元学习训练机制Fig.1 N-way K-shot task and meta-learning training mechanism |
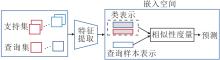
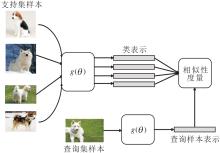
基于度量的小样本学习方法需要学习的元知识是一个嵌入空间(Embedding Space), 在该空间中同类样本的距离更近, 不同类样本的距离更远.由于基于度量的小样本学习方法将样本投影到一个更低维的空间, 所以训练时需要的样本量会下降[43, 44].在测试时, 计算查询样本和支持集中各个类的相似性, 分类查询样本.
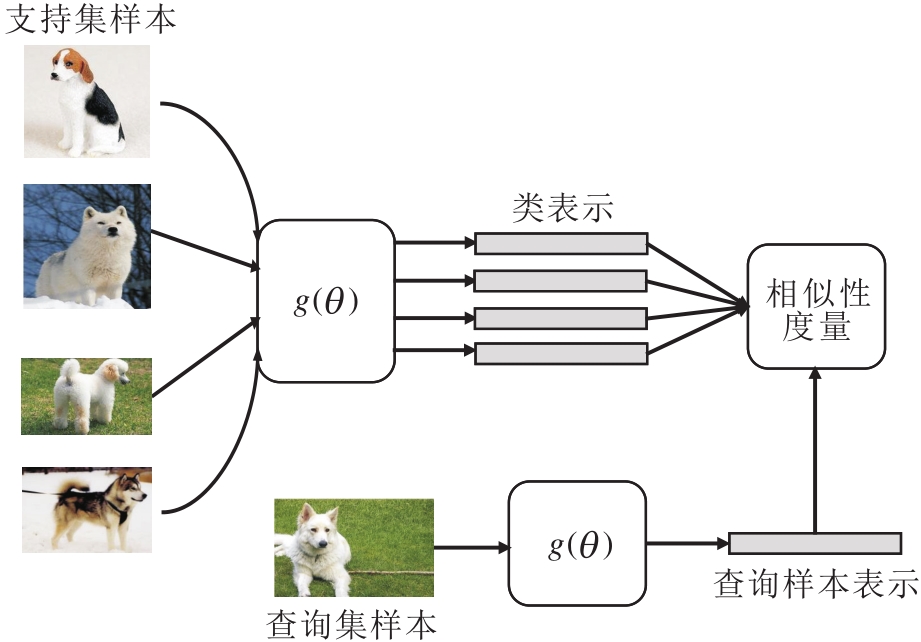
基于度量的小样本学习方法一般框架如图2所示.由图可看出, 基于度量的小样本学习方法与人类认知事物的思路一致.在对查询样本进行分类时, 依据该样本与类之间的相似性进行判断.例如, 机器学习公理化[45]中提出归类原则:归哪类, 像哪类, 像哪类, 归哪类.根据归类原则可知, 在进行归类时包括2个关键问题:类表示和相似性度量.只有将这两个问题学习好, 才能根据归类原则正确查询到样本归类.因此, 本文主要从两个问题上对基于度量学习的小样本学习方法进行综述.事实上, 任何一种方法都会涉及到这两个关键问题, 只不过在方法设计时, 通常主要解决其中一个问题.
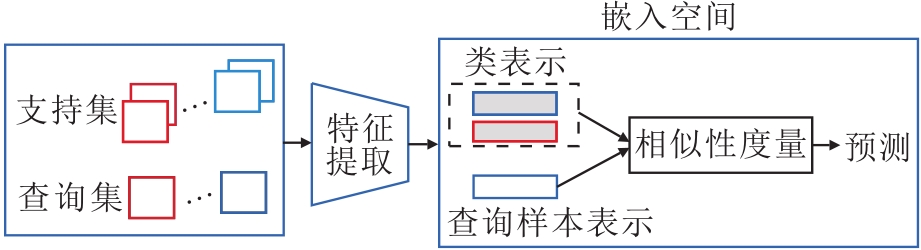 | 图2 基于度量的小样本学习方法框图Fig.2 Framework of metric learning based few-shot learning methods |
在类表示的方法中, 本文依据认知科学中概念表示的不同理论将类表示学习分为基于原型的类表示学习方法、基于样例的类表示学习方法和基于任务的类表示学习方法.在相似性学习方法中, 本文依据相似性计算的方式将方法分为特征独立的距离度量、特征相关的距离度量和自适应距离学习.此外, 还可依据表示形式将类表示方法分为基于向量表示的方法、基于张量表示的方法和基于图表示的方法.在相似性学习方法中, 可依据相似性计算的对象分为基于特征的相似性计算和基于关系的相似性计算, 但目前大部分文献的表示形式都是采用向量, 相似性计算方式都是基于特征.
本文与其它小样本学习综述的区别如下.
1)本文只针对于基于度量的小样本学习方法.虽然目前有一些关于小样本学习的研究综述, 但均是对小样本学习相关的所有论文进行分类, 而本文只强调基于度量的小样本学习方法, 对该类方法进行更详尽的分类.
2)本文基于关键问题进行分类, 而不是根据方法类型进行分类.从问题出发对方法进行分类更容易让初学者了解不同方法设计的初衷及现有方法存在的问题和改进空间.
3)本文在分类时结合人类认知理论和机器学习公理化中的相关内容, 基于小样本学习方法的出发点, 让机器模仿人类认知的联系更紧密.
小样本学习中首要解决的问题是如何从数据中学习概念(类).机器学习的基本任务是获取知识, 最终输出结果为知识.机器学习公理化[45]中指出, 知识由各种概念组成, 概念是构成人类认知世界的最小单元.因此, 机器学习首先要解决如何从数据中学习概念(类).同样, 在小样本学习中首要解决的问题也是如何从数据中学习概念, 由于小样本学习中数据不充分, 概念的学习更困难.
在1953年前, 人们通常认为概念是可精确定义的, 所有目前不能准确定义的概念仅是因为受限于目前的认知水平.按照这样信念得到的概念的定义叫作经典定义.Wittgenstein[46]通过研究“ 游戏” 这个概念, 对于概念是否一定存在精确定义提出质疑.现代认知科学的发展支持这一看法, 明确指出, 各种概念, 如人、猫、狗等, 都不一定存在经典的内涵表示.现代认知科学已提出新型的概念内涵表示理论, 如原型理论、样例理论和知识理论[47].基于上述理论, 本文将小样本类表示学习方法分为3种:基于原型理论的类表示学习方法、基于样例的类表示学习方法和基于任务的类表示学习方法.
原型理论认为一个概念可由一个原型表示, 一个原型可以是一个实际或虚拟的对象样例, 通常假设为概念的最理想代表.
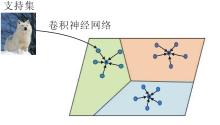
最早的基于类原型理论的小样本学习方法是类原型网络[8], 将每类样本在嵌入空间表示的均值作为该类的类原型, 通过对比查询样本与类原型间的距离将查询样本进行分类.
类原型网络示意图如图3所示, 图中彩色圆圈表示不同类样本在嵌入空间的表示, 黑色圆圈表示类原型, 由各类样本在嵌入空间中的特征求均值得到.此方法简单有效, 是基于度量的小样本分类方法中代表性研究之一.
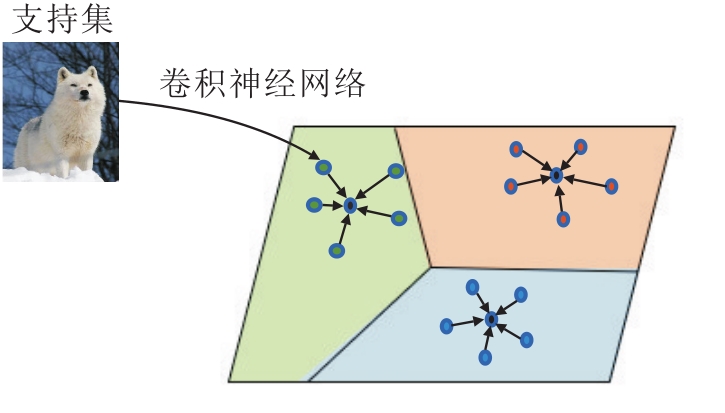 | 图3 类原型网络Fig.3 Prototype network |
虽然文献[8]证明在一个特定的空间点集中, 不论样本点满足何种概率分布时, 这些点的平均点是这个空间的最小平均距离.但是小样本学习中每类样本量太少, 难以满足任何概率分布, 即小样本学习中的每类样本只是该类所有样本中非常小的一部分, 难以代表该类的分布.
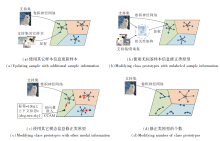
此外, 小样本学习中的另一个问题是类内方差较大.因此, 简单采用样本均值作为该类的类原型可能是有偏的.为了解决这一问题, 学者们提出类原型计算方法.这些方法的基本思想是利用一些其它信息以修正类原型, 如图4(a)所示.
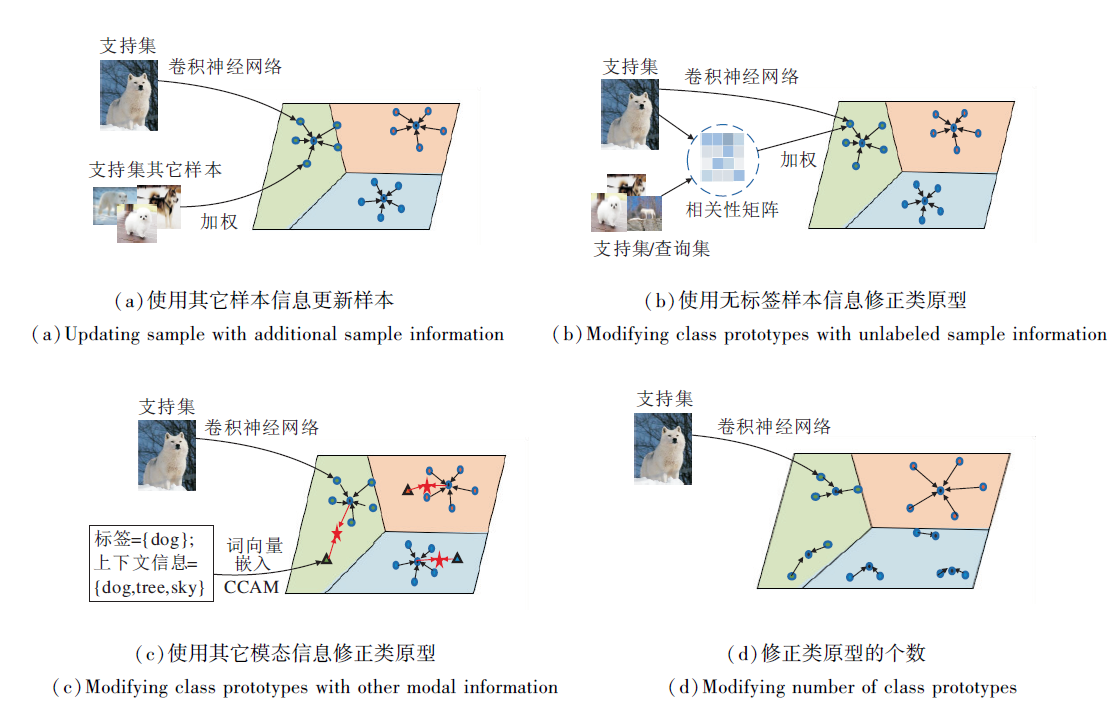 | 图4 不同类型的类原型修正Fig.4 Different types of class prototype modification |
Zheng等[48]提出主要特性网络(Principal Cha-racteristic Networks, PCN), 采用绝对差之和(Sum of Absolute Difference, SAD)衡量每个样本的重要性, 由于类原型是由样本计算得到, 如果能给具有代表性的样本更大的权重就会得到更好的原型.在小样本学习中, 样本的重要性尤为重要.Zheng等[48]根据每个样本与其它样本的差异作为自身的重要性, 并对样本进行加权, 得到最终的类原型表示.每个样本在隐空间的SAD如下所示:
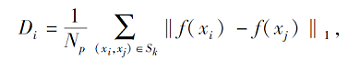
其中, f(xi)表示第i个样本在嵌入空间的表示, Sk表示支持集中样本集合, Np表示第i个样本所在类的支持集中样本对的个数.可以看出, 样本与该类其它样本之间的差异越大, SAD值越大.在此基础上, 类原型表示为
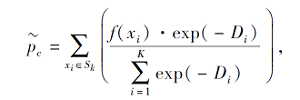
其中K表示某类支持集中样本个数.可以看出, 上式中的类原型是通过对支持集中样本加权求均值得到的.样本与类内其它样本的差异越大, 该样本的权重越小.因此, 此方法可降低异常点对类原型计算的干扰.
Ren等[49]引入无标签样本, 增加样本数量, 避免小样本原型学习不准确的问题.计算无标签样本 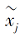
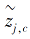
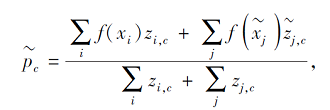
置信度
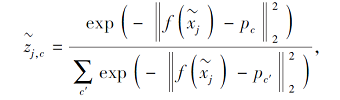
其中c'表示所有类原型.可以看出, 无标签样本与某类初始类原型的距离越近, 该样本属于该类的置信度越大.此外, 针对更复杂的实际情况, Ren等[49]设计另外两种引入无标签数据的策略以更新类原型, 共设计3种半监督小样本学习方法.
虽然Ren等[49]引入未标记样本, 可对类原型进行更新, 但将监督的小样本学习方式转换成半监督学习方法.Hou等[32]提出交叉注意力网络(Cross Attention Network, CAN), 只利用每个任务中给定的部分未标记样本, 通过均值得到的类原型和查询样本的相关性作为权重以更新类原型.具体地, 先通过简单求均值得到一个初始的类原型, 再计算查询样本和初始类原型的相关性矩阵, 最后基于相关性矩阵更新初始类原型的表示.
Liu等[50]提出消除偏见-基于余弦相似性的原型网络(Bias Diminishing-Cosine Similarity Based Prototypical Network, BD-CSPN), 也是利用查询样本(Query)修正类原型, 但同时考虑类间偏差的影响.先采用伪标签生成策略为查询样本预测类别, 根据查询样本与原始类中心直接的相似性得到查询样本属于每个类的概率w:
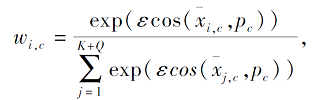
其中, ε表示一个标量参数, xi, c表示第c类的第i个样本,
将查询样本也加入到类原型的计算中:
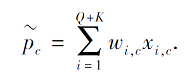
然后为标准化的类原型引入偏移项, 消除类和类之间的偏差.偏移项的定义如下:
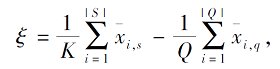
其中,
除了利用已(未)标记样本信息对类原型进行修正以外, 学者们还利用其它额外信息, 如文本信息、修正类原型.Xing等[33]提出自适应模态混合机制(Adaptive Modality Mixture Mechanism, AM3), 引入类别的词向量表示, 使用多模态信息(文本信息和图像信息)进行类原型学习.当图像提供的信息难以进行分类时, 由于文本信息包含丰富的语义信息, 可利用文本信息辅助学习.因此, Xing等[33]提出自适应融合视觉类原型和文本类原型的方法, 融合后的类原型表示为
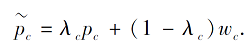
其中:pc表示视觉类原型, 即对类内样本的图像表示求均值得到的类原型;wc表示文本类原型, 通过对类别的词向量表示进行映射得到;λ c表示视觉类原型的权重, 通过自适应机制学习得到.类似地, Fortin等[51]引入上下文信息, 基于注意力机制学习为每类学习一个上下文表示, 作为文本信息的类原型, 再将文本类原型和视觉类原型自适应融合, 得到最终的类原型.
上述方法中假设每类只有一个类原型, 当数据分布较简单时, 用一个类原型就可较好地表示该类.但是针对类别分布较复杂的情况, 如果每类只学习一个类原型, 就难以有效地对该类进行表示.于是, Allen等[52]提出无限混合原型学习(Infinite Mixture Prototypes Learning, IMP), 可自适应地为不同类学习不同数目的类原型.分布复杂的类学习多个类原型, 分布简单的类学习一个类原型.
总之, 基于原型理论的类表示学习方法的关键是如何得到更好的类原型, 使类原型可更好地代表这个类, 包括样本修正、类原型计算方式和数目修正.
样例理论认为, 人们主要根据新样例与记忆中存储先前碰到的一个或多个实例的相似程度对新样例的范畴隶属进行判别, 所以样例理论中的类表示为单个或多个样本.
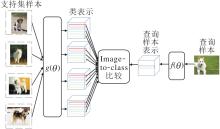
小样本学习中基于样例理论进行类表示学习的最早的方法是匹配网络(Matching Network)[39].该方法结合注意力机制, 计算查询样本与支持集中每类样本之间的相似性, 作为查询样本属于该类的概率:
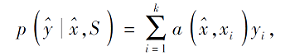
其中, a表示通过注意力机制学到的权重,
 | 图5 匹配网络框图Fig.5 Sketch map of matching network |
但匹配网络是为单样本(One-Shot)学习设计的, 在单样本学习的情况下, 每类只有一个样本, 因此, 使用唯一的样本表示每类.分类时, 对比查询样本和每类的唯一样本, 得到最终分类结果.事实上, 所有的单样本学习的模型都是基于样例理论表示类, 因为每类只有一个样本, 如果不进行数据扩充等操作, 该类只能由这唯一的样本表示.在分类时, 查询样本也只是和每类唯一的样本进行对比.
对于每类样本不止一个的小样本学习方法, 典型的基于样例理论进行类表示学习的方法为深度近邻网络(Deep Nearest Neighbor Neural Network, DN4)[35].DN4框图如图6所示.
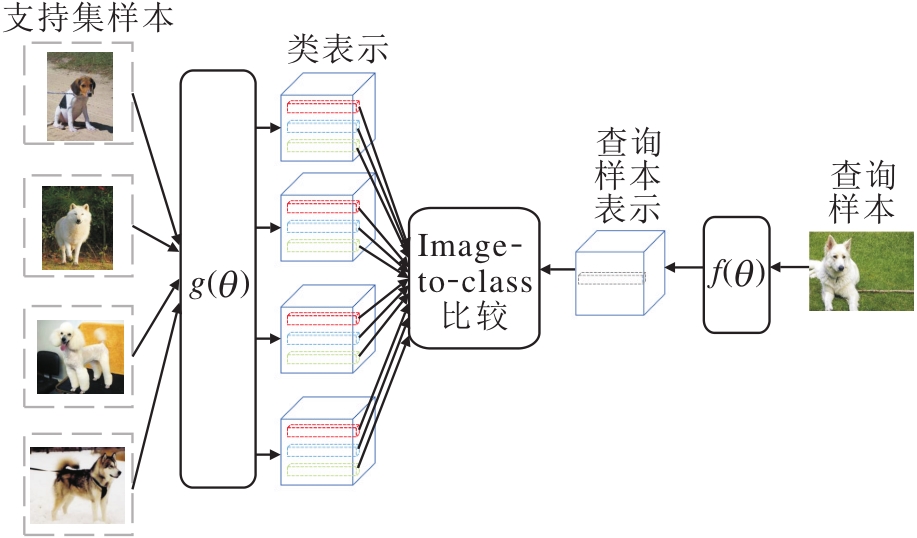 | 图6 DN4框图Fig.6 Sketch map of DN4 |
与样例理论中近邻方法相似, DN4的类由所有样本表示, 在进行分类预测时, 计算查询样本与其近邻的距离作为样本与类的距离.此外, 与一般的小样本类表示不同, DN4中类表示是基于局部信息进行表示的.较早的小样本学习中通常将类表示为一个向量, 表示这类的全局信息, 但对于小样本学习, 由于样本量太少, 一些局部信息可能更有用.实际上, 人类在进行分类时, 当样本量不充足时, 更关注的也是具有判别性的局部信息.因此, DN4将类表示成为一个张量x∈ Rc× w× h, c表示网络的通道数, w表示高度, h表示宽度, 更好地捕捉类的局部判别信息.在计算相似性时, DN4计算查询样本中所有特征图(Feature Map)xi与某个类中最近k个特征图距离的均值, 以此作为查询样本与该类的相似性:

其中, xi表示查询样本的第i个特征图,
目前小样本学习中大部分的类表示都是基于原型理论.由于基于样例的方法需要储存多个样本, 占用更多的储存空间, 时间复杂度更高, 所以这类方法相对较少.
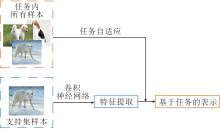
认知理论中的知识理论认为, 概念是特定知识框架(文明)的一个组成部分.类似地, 在基于度量的小样本学习中, 类(样本)的表示也不能独立于任务而存在.本文把在小样本学习中这种基于知识的概念表示学习方法称为基于知识(任务)的类表示学习方法.这类方法的关键是如何利用任务信息对表示(样本表示)进行调整, 生成基于任务的表示, 一般框架如图7所示.
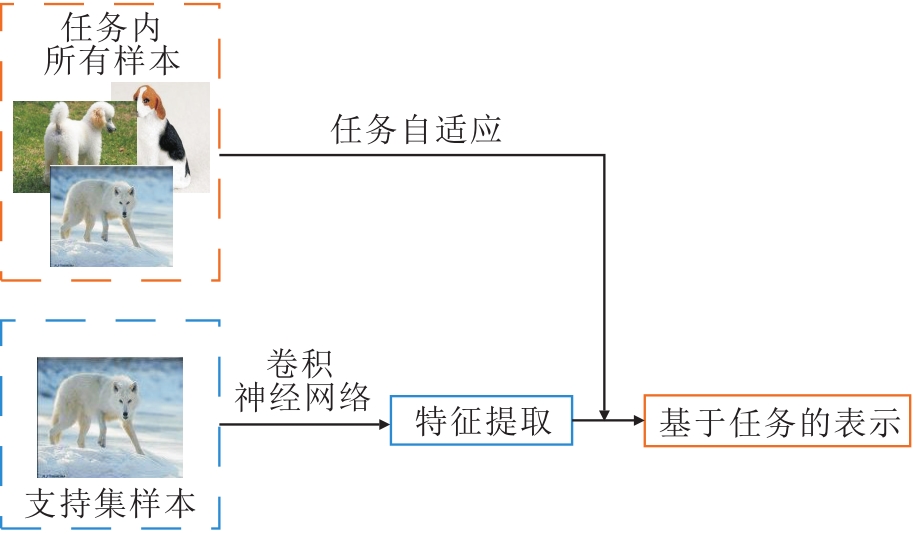 | 图7 基于任务的类表示学习方法框图Fig.7 Framework class representation of knowledge-based learning |
在对类(样本)表示进行调整时, 一种策略是利用类似条件批正则化[53]或面向特征的仿射变换(Feature-Wise Linear Modulation, FiLm)[54]的方式对卷积神经网络(Convolutional Neural Network, CNN)中每层隐表示都进行调整.Oreshkin等[36]提出任务相关自适应度量(Task Dependent Adaptive Metric, TADAM), 将所有类的均值作为任务表示, 将任务表示输入2个残差网络, 学习缩放系数γ和平移系数β, 通过对CNN中样本的每层隐表示进行缩放和平移, 得到基于任务的表示:
hl+1=γ☉hl+β,
其中, hl表示特征学习网络中第l层的表示, ☉表示对应元素的积运算.Bateni等[37]提出简单的基于类协方差矩阵的距离度量(Simple Class-Covariance-Based Distance Metric, Simple CNAPS), 利用类似上述机制生成基于任务的表示.此外, 除学习基于任务的表示, 在进行相似性计算时也采用基于任务的马氏距离作为度量函数.
另一种策略是直接对经过CNN学习的高层特征表示进行调整.Wang等[38]将所有类的属性信息作为任务表示, 放入多个网络中生成多个权重Wi, 得到基于任务的表示:
xi+1=Wixi+b.
Li等[55]拼接任务内所有样本, 通过网络学习可体现任务内共性和类间差异的一个掩膜 p, 再将掩膜作用到样本表示上, 生成基于任务的样本表示:
x=x☉p.
Ye等[56]为了避免任务之间类别的顺序对基于任务的表示造成负面影响, 提出使用集合到集合类型的映射, 学习不同分类任务之间的相关性, 通过集合自适应的方法, 适配特征提取方法, 学习与目标任务相关的特征, 适应到不同的分类任务中.
基于任务的类表示方法由于考虑不同任务的差异性, 会得到更稳定的类表示, 是近年来研究较多的方向.
基于度量的小样本分类方法的第2个关键问题是如何计算查询样本与类的相似性.机器学习公理化[45]指出人类进行分类的原则就是“ 归哪类, 像哪类, 像哪类, 归哪类” .同样, 在基于度量的小样本分类任务中, 也是依据查询样本和类表示的相似性对查询样本进行分类.因此, 如何度量测试样本和类表示之间的相似性成为基于度量的小样本分类任务中的关键问题.根据相似性学习的方式, 本文将小样本学习分为3类:特征独立的距离度量、特征相关的距离度量和自适应距离学习.
特征独立的距离度量是指在计算查询样本和类表示时采用的距离函数假定任务特征之间是独立的, 如欧氏距离、余弦距离等.代表性的原型网络和匹配网络采用特征独立的距离函数.然而在实际应用中, 在没有强加正交约束下很难保证特征之间是独立的, 因此, Bateni等[37]提出使用马氏距离作为距离函数.马氏距离可学习不同特征之间的相关性, 更好地计算样本之间的相似性.然而马氏距离计算向量之间的距离, 考虑向量中特征之间的相关性.在类表示学习中, 为了更好地捕获数据的局部信息, 有学者将类表示成张量.因此, Zhang等[11]采用推土机距离(Earth Mover's Distance, EMD), 考虑两个张量之间的相关性, 结合深度学习, 提出DeepEMD, 更好地学习张量间的相似性.具体地, DeepEMD将查询集和支持集样本表示成张量, 张量中不同的向量表示图像的不同部分, 计算两者之间的最佳匹配代价, 表示得到二者之间的相似程度.当每类样本数目为1时, 查询集的类表示为该样本表示, 当样本数目大于1时, 如果通过简单求均值的方式计算类原型, 会忽略不同图像中目标物体可能出现在不同位置的问题, 因此通过学习的方法得到基于张量的类原型.
虽然马氏距离和EMD可考虑特征间的相关性, 但只能衡量特征间较简单的相关性.例如, 2个样本点x和y之间的马氏距离表示为
dM=
其中M为特征之间的相关性矩阵.从公式可看出, dM在计算时只考虑特征间一层相关性.
受神经网络可提取数据间复杂关系的启发, Sung等[9]提出使用神经网络代替距离函数, 自适应地学习样本间的相似性.关系网络(Relation Net-work)[9]是小样本学习中代表性工作, 框图如图8所示.Sung等[9]指出想要学习一个可迁移的距离度量, 而不是采用固定的距离函数, 又由于神经网络可较好地学习数据的非线性结构, 因此, 将类原型和查询样本拼接后放入一个神经网络中, 自适应地学习它们之间的相似性.
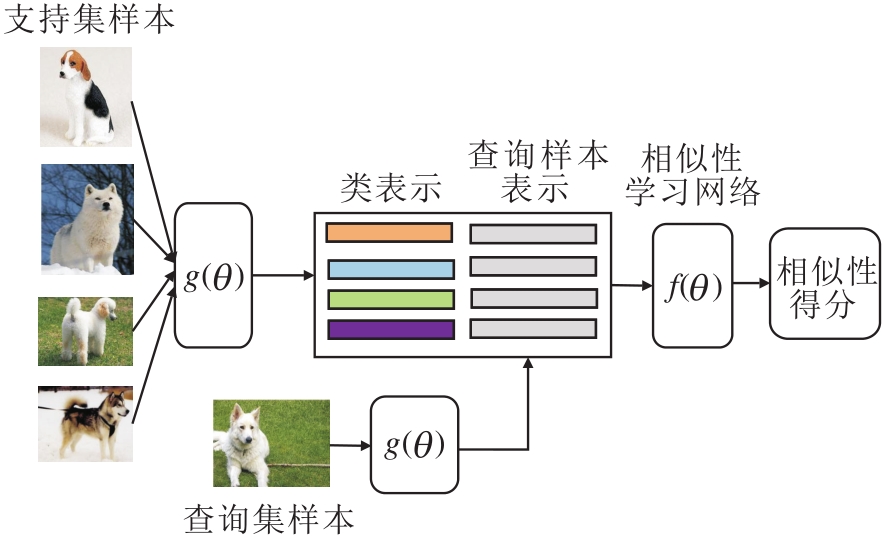 | 图8 关系网络框图Fig.8 Sketch map of relation network |
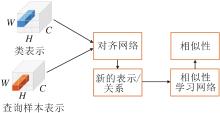
在关系网络中, 网络输入类表示和查询样本拼接后的向量.有学者指出针对小样本学习的相似性问题, 采用张量计算更好[11, 32, 34, 35, 57].因为张量体现样本的局部信息, 在进行小样本分类时, 局部信息可能会提供更具有判别性的信息.
将关系网络中的向量表示拓展到张量上, 首先将类表示和查询样本表示成张量, 拼接后放到一个网络中, 学习对应局部信息的相关性, 大致框图如图9所示.
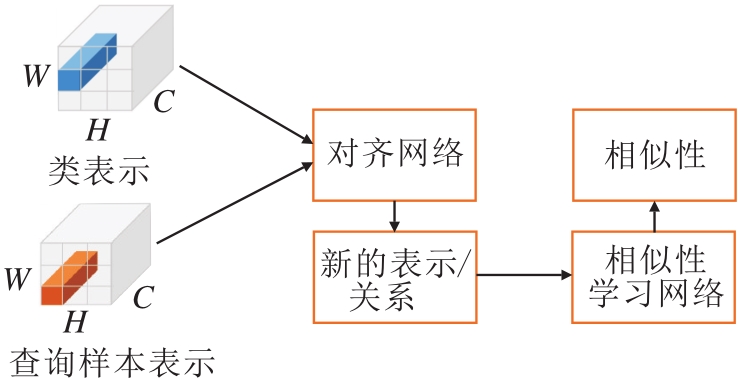 | 图9 基于张量表示的相似性计算框图Fig.9 Framework of similarity calculation based on tensor representation |
由于目标物体通常出现在图像的不同位置, 直接将特征图拼接后放入网络中, 学习相关性未考虑到类和查询样本的位置对齐和语义对齐, 需要将类和查询样本对齐后再计算相似性.
为了解决这一问题, Hou等[32]通过注意力机制, 先修正类表示和测试样本, 再进行语义对齐, 修正后的类表示和测试样本拼接后放到网络中学习相似性.
上述方法都是计算特征之间的相似性.在小样本学习中, 特征之间的相似性关系因位置不同等原因可能并不是很稳定, 于是增加相对位置之间的相似性计算, 同时计算相对位置和特征之间的相似性[16, 18, 57].Hao等[40]提出语义对齐的度量学习(Semantic Alignment Metric Learning, SAML), 先计算类表示的每个特征图和查询样本每个特征图之间的距离, 得到一个相似性矩阵:
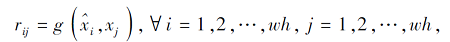
其中, 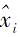
相似性学习虽然已有很多成果, 但仍是一个难点问题.因为相似性学习与任务和数据密不可分, 独立于任务和数据的相似性计算函数并无实际意义, 因此, 如何结合小样本分类任务的特性及数据的表现形式, 更好地度量数据之间的相似性仍值得研究.
除了上述主流方法以外, 还有一些其它的基于度量的小样本学习方法.
在类表示时, 上述方法都是将类表示成向量或张量.还有一些学者将类表示成图(Graph), 更好地挖掘样本之间的关系.Garcia等[58]将图卷积神经网络应用到小样本图像分类任务上, 将每个样本视为图中的一个节点, 通过图卷积网络学习样本的表示.Kim等[59]在构建图时不仅利用节点信息, 还利用边的连接信息, 使网络可直接利用类内相似性和类间不相似性指导表示的学习.Cheng等[60]在图卷积网络构建时, 引入注意力机制, 包括节点自注意力(Node Self-Attention)、邻居注意力(Neighborhood Attention)、层间记忆注意力(Layer Memory Atten-tion), 提高方法泛化能力.Shi等[61]在构建图时, 不仅考虑新类的关系, 同时考虑新类和基类的关系, 在原型网络的基础上, 提出广义的小样本学习方法(Graph-Convolutional Global Prototypical Networks, GcGPN), 不仅可对新类分类, 还可以对基类分类.Zhang等[62]提出自适应聚合图卷积的方法, 减小数据集中噪声(不相关的图像)的影响.
在相似性学习时, 上述方法都是为了设计更好的相似性计算方式.还有学者引入间隔(Margin)和度量学习的思想, 设计更好的损失函数以更好地学习相似性.Oreshkin等[36]和Zhang等[63]提出使用可学习的温度参数以调整距离度量, 在普通的交叉熵损失中引入调整机制, 并从理论上分析调整的作用.Li等[64]指出使用自适应的间隔损失函数替换交叉熵损失函数, 更好地区分类间距离, 并利用类别的语义信息提出任务相关的自适应间隔学习方法.Li等[65]借鉴度量学习中的N对损失[66], 提出K元组损失函数, 利用样本间的关系, 更好地学习度量空间.
已有很多学者研究关于间隔和度量学习[67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77], 怎样更好地将这些工作与小样本学习结合, 也是一个值得思考的问题.
此外, 随着自监督学习的发展, 利用自监督技术更好地帮助小样本学习的方法也得到广泛关注.Su等[78]和Li等[79]通过在预训练过程中引入自监督损失(旋转损失或位置预测损失), 提取更鲁棒的表示.
在小样本图像分类任务中, 不同文献中标准数据集使用都是一致的.常用的数据集包括Omniglot[80]、miniImageNet[81]、tieredImageNet[48]数据集.此外还有一些细粒度数据集, 如CUB数据集[82].
Omniglot数据集由来自50种不同语言的1 623个手写字符构成, 每个字符都是由20个不同的人通过亚马逊的Mechanical Turk在线绘制.数据集样本类别很多(1 623种), 但每种类别的样本数量较少(20个).在实验中通常选择1 200种字符作为训练集, 剩余的423种字符作为测试集.
MiniImageNet数据集是ImageNet数据集的一个子集, 共有60 000幅图像, 100类, 每类有600幅图像, 每幅图像的尺寸为84× 84.实验中通常选择其中80类作为训练集, 剩余的20类作为测试集.也有的实验选择64类作为训练集, 16类作为验证集, 剩余的20类作为测试集.
TieredImageNet数据集也是ImageNet数据集的一个子集, 具有层级结构, 包含34个大类(Cate-gories), 每个大类又包含10~30个小类(Classes), 每类的图像数量不等, 共608个类别, 779 165幅图像.实验中通常选择20个大类作为训练集, 6个大类作为验证集, 剩余的8个大类作为测试集.
CUB-200数据集的全称为Caltech-UCSD Birds-200-2011数据集, 是由加利福尼亚理工学院提供的鸟类数据库, 共包含200种鸟类的11 788幅图像, 每幅图像的尺寸也统一裁剪为84× 84.使用中通常选择100类作为训练集, 50类作为验证集, 剩余的50类作为测试集.
为了更好地对比现有方法以进行后续研究, 本文整理一些典型的基于元学习训练机制模型的实验结果, 具体如表1和表2所示.
| 表1 基于度量的小样本学习方法特点 Table 1 Characteristics of metric-based few-shot learning methods |
| 表2 基于度量的小样本学习方法在4个数据集上的精确度对比 Table 2 Accuracy comparison of metric based few-shot learning methods on 4 datasets % |
由表1和表2可看出, 早期方法都在Omniglot、miniImagnet数据集上进行验证.不同方法在不同数据集上的表现相似.由于Omniglot数据集较简单, 精度接近100%, 提升空间很小, 因此, 后期方法大都在miniImagnet、tieredImageNet数据集上进行验证.随着近几年小样本学习的发展, 不论是1个样本任务还是5个样本任务, 在各数据集上的精度都有较大提升, 但仍有很大的提升空间.
由于本文只是整理不同方法的实验结果, 而不同方法采用的数据预处理及网络框架等设置并不相同, 所以很难对比不同方法真正的优势.从表1可大致得出以下结论.在类表示方法上, 目前大部分的方法都是基于原型的方法, 基于样例的方法很少, 基于知识的方法最近开始受到学者们的关注.较早的论文大部分都采用基于向量的表示形式, 最近基于张量的方法逐渐增加.在相似性学习上, 近期都采用自适应学习的方法.在网络架构上, ResNet-12[2]被广泛使用.从实验精度上看, 基于原型的方法和基于知识的方法优于基于样例的方法.
尽管近年来基于度量的小样本学习已得到深入研究, 取得一定进展, 但仍然存在一些问题.
1)泛化性难以保证.目前基于度量的小样本学习方法都是基于迁移学习的方法, 需要在大量的非目标数据集上进行预训练, 如果目标数据集与非目标数据集差异较大, 难以保证迁移的效果.虽然最近有些学者[83, 84, 85, 86, 87]提出在预训练时使用自监督的技术, 可提高方法的泛化能力, 但这些方法只能部分解决该问题.如何只利用目标数据集上的少量样本, 实现真正意义上的小样本学习仍是一个难点问题.
2)训练机制有待优化.目前基于度量的小样本学习方法均采用元学习的训练机制, 构建一系列小样本任务, 学习解决这类问题的元知识, 但在构造不同任务时都是随机的, 未考虑任务的重要性和任务之间的关系.从理论上来说, 任务的构建和学习中任务的先后对方法的优化和泛化能力具有重要影响.因此, 之后的小样本学习方法不应只关注单个任务上的学习性能, 更应关注整体的训练和学习.
3)缺乏可解释性.虽然基于度量学习的小样本学习方法可从人类认知的角度进行分类, 分类时也是利用查询样本与类表示之间的相似性, 依据“ 归哪类像哪类” 的原则, 有一定的可解释性, 但分类是在由深度网络得到的嵌入空间上进行, 而嵌入空间中特征的含义难以解释, 导致这类方法仍不具备可以让人类能理解的解释性.
4)设计缺乏理论指导.虽然近年来小样本学习受到学者们广泛关注, 并取得不错的成果, 但是关于小样本学习的理论研究却很少.大部分方法设计的初衷都是来源于人类认知过程中的启发或猜测, 并无理论保证或指导.
通过对当前基于度量的小样本学习研究方法的梳理及目前基于度量的小样本学习难点的分析, 可以展望未来小样本学习的发展方向.
1)多模态小样本学习.小样本学习的难点是样本量少, 难以学到类的正确表示.如果可以将其它模态信息加以利用, 就可得到更丰富的信息, 这有利于小样本学习, 尤其是认知视觉上较相近的类.事实上, 人类在对小样本进行认知时, 多模态信息也会发挥重要的作用.除了音频、文本等其它模态信息也可提供丰富且重要的信息.目前已有一些多模态小样本学习文献, 但大都只利用标签的文本信息.此外, 虽然多模态信息可带来更多信息, 但也可能会引入噪音和信息冗余.如何充分合理利用多模态信息, 既考虑不同信息源的一致性, 又考虑它们直接的互补性, 同时消除多源信息的冗余性, 弥补小样本数据匮乏的问题是一个值得研究的方向.
2)可解释小样本学习.已有多数小样本学习方法仅提供分类预测的准确率, 而对于为什么这么分类的解释却很少.虽然原型理论、样例理论和知识理论可部分解释为什么将查询样本分为某类, 但具体依据哪些特点(如形状或颜色)却并不知道.人类在对小样本分类时, 不仅可给出分类时依靠的理论, 还可给出分类时具体依据的特征.因此, 如何设计可解释小样本学习方法, 如通过特征解耦或部分原型学习的方法, 使学到的特征具有解释性, 更好地让机器像人一样学习是未来值得研究的问题.
3)因果小样本学习.目前的小样本学习主要依靠元知识的迁移, 要求目标域与训练时的非目标数据集相差不大, 如果相差太大, 就难以将元知识迁移到目标数据中.不仅如此, 在非目标数据集上进行训练, 还可能导致负迁移.出现这种情况的主要原因是方法在学习时未学到变量间的因果关系, 只学习相关关系.
为了解决这一问题, Yue等[88]提出因果小样本学习方法.在已有模型上引入因果机制, 可让已有方法得到更优的泛化能力.这虽然在一定程度上解决预训练带来的虚假因果关系, 但在设计时需要提前假设混淆因子是什么.在实际应用中, 可能只知道部分混淆因子或根本不知道混淆因子.Yue等[88]提出可混合一些补丁, 如使图像变得更多样化, 再通过对比损失进行学习, 使一些简单的关联不再有效, 学习一些真正的规则.上述方法只是对因果小样本学习的初探.如何设计更好的因果小样本学习方法, 提高小样本学习的泛化性能, 仍是一个值得研究的方向.
4)小样本学习的优化和理论.目前大部分小样本学习都是基于元学习的训练机制, 文献[89]~文献[93]中关于元学习的理论已很多, 但基于元学习训练的小样本学习方法的相关理论文献却很少[94, 95].如何结合元学习理论, 设计更好的优化方法, 加速模型的优化过程, 使小样本学习可真正应用到实际场景中也是今后关注的问题.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|
| [44] |
|
| [45] |
|
| [46] |
|
| [47] |
|
| [48] |
|
| [49] |
|
| [50] |
|
| [51] |
|
| [52] |
|
| [53] |
|
| [54] |
|
| [55] |
|
| [56] |
|
| [57] |
|
| [58] |
|
| [59] |
|
| [60] |
|
| [61] |
|
| [62] |
|
| [63] |
|
| [64] |
|
| [65] |
|
| [66] |
|
| [67] |
|
| [68] |
|
| [69] |
|
| [70] |
|
| [71] |
|
| [72] |
|
| [73] |
|
| [74] |
|
| [75] |
|
| [76] |
|
| [77] |
|
| [78] |
|
| [79] |
|
| [80] |
|
| [81] |
|
| [82] |
|
| [83] |
|
| [84] |
|
| [85] |
|
| [86] |
|
| [87] |
|
| [88] |
|
| [89] |
|
| [90] |
|
| [91] |
|
| [92] |
|
| [93] |
|
| [94] |
|
| [95] |
|