





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于双流网络的多模态多标签漫画情感检测方法
[林镇涛1  , 曾碧
, 曾碧1 , 潘志豪1 , 文松1 ]
, 曾碧, 潘志豪, 文松]
|
|



作者简介:

林镇涛,硕士研究生,主要研究方向为多模态情感分析、模式识别.E-mail:2112005050@mail2.gdut.edu.cn.

潘志豪,硕士研究生,主要研究方向为自然语言处理、情感分析.E-mail:pzh@mail2.gdut.edu.cn.

文 松,硕士研究生,主要研究方向为多模态融合、大数据.E-mail:ws@mail2.gdut.edu.cn.
近年来,社交媒体常会以漫画的形式隐喻社会现象并倾述情感,为了解决漫画场景下多模态多标签情感识别存在的标签歧义问题,文中提出基于双流结构的多模态多标签漫画情感检测方法.使用余弦相似度对比模态间信息,并结合自注意力机制,交叉融合图像特征和文本特征.该方法主干为双流结构,使用Transformer模型作为图像的主干网络提取图像特征,利用Roberta预训练模型作为文本的主干网络提取文本特征.基于余弦相似度结合多头自注意力机制(COS-MHSA)提取图像的高层特征,最后融合高层特征和COS-MHSA多模态特征.在EmoRecCom漫画数据集上的实验验证文中方法的有效性,并给出方法对于情感检测的可视化结果.
About Author:
LIN Zhentao, master student. His research interests include multi-modal emotion analysis and pattern recognition.
PAN Zhihao, master student. His research interests include natural language processing and emotion analysis.
WEN Song, master student. His research interests include multi-modal fusion and big data.
Comic is widely applied for metaphorizing social phenomena and expressing emotion in social media. To solve the problem of label ambiguity in multi-modal and multi-label emotion detection of comic scenes, a multi-modal and multi-label emotion detection model for comics based on two-stream network is proposed. The inter-modal information is compared using cosine similarity and combined with a self-attention mechanism to merge image features and text features. Then, the backbone of the method is a two-stream structure taking the Transformer model as the image backbone network to extract image features and taking the Roberta pre-training model as the text backbone network to extract text features. The improved cosine similarity is combined with cosine self-attention mechanism and multi-head self-attention mechanism(COS-MHSA) to extract the high-level features of the image. Finally, the multi-modal features of the high-level features and COS-MHSA are fused. The effectiveness of the proposed method is verified on EmoRecCom dataset, and the emotion detection result is presented in a visual manner.
本文责任编委 张军平
Recommended by Associate Editor ZHANG Junping
漫画是一种描绘生活和现实的艺术, 对比单纯的文本信息, 漫画具有丰富的图文信息, 更能唤醒读者不同的情感反应, 体现漫画作者的思维意识.在社交媒体上, 常有用户通过漫画进行叙事视觉化描绘, 隐喻社会现象并表达不同的情感倾向[1].
在多模态情感分析领域, 目前的研究较多关注真实场景下的人物情感, 提取文本、图像、声音等模态之间的互补信息进行情感预测.例如通过分析视频中人物的姿态、面部表情, 融合语音文本信息, 完成对视频中人物的情感挖掘[2].
早期研究情感检测的任务主要关注深度学习的方法[3].Zhang等[4]在多模态情感上研究情感数据集和深度学习的方法, 认为充分融合多模态信息进行情感预测能有效提升预测性能.Tzirakis等[5]和Tsai等[6]提出基于循环神经网络(Recurrent Neural Network, RNN)和卷积神经网络(Convolutional Neural Network, CNN)融合声学信息和视觉信息的方法, 解决模态之间对齐的问题.Cimtay等[7]使用预训练模型的方式, 验证利用预训练模型提取高维特征有助于模态学习.也有一些学者关注多模态的融合问题.Liu等[8]直接拼接高维特征向量.Anastasopoulos等[9]使用预训练模型提取高维特征再进行融合.Zoph等[10]使用加权方式融合不同模态间的特征.Xu等[11]在RNN的基础上增加图像的注意力.Li等[12]基于Transformer, 使用注意力融合双流的文本和图像模态.Yu等[13]使用双线性池化交替共同学习注意力的权重, 实现各模态的加权融合.
近年来, 学者对多模态单标签情感进行独立分类, 但并未考虑多情感共存和多情感重叠的问题.Ding等[14]提取文档中潜在情感, 通过滑动多标签学习窗口大小, 匹配不同文本的情感极性.对比多模态单标签的方法, Ranjan等[15]引入多标签相关分析机制(Multi-label Canonical Correlation Analysis, mlCCA), 在跨模态检索任务中为多标签建立相关联系, 但忽视对多模态多标签的标签指向问题, 无法将标签与检索信息进行准确对应.Zhang等[16]提出模态和标签依赖的多模态多标签情感识别框架(Multi-modal Multi-label Emotion Detection with Modality and Label Dependence, MMS2S), 解决视频中多情感标签依赖问题, 实现时序上的情感标签指向.
不同于上述研究, 为了解决多模态漫画情感识别中多标签歧义的问题, 本文提出基于双流网络的多模态多标签漫画情感检测方法, 解决多模态中多标签存在的潜在歧义问题.首先, 利用Roberta[17]预训练模型提取文本特征, 视觉Transformer编码器(Vision Transformer Encoder)[18]提取图像特征.然后, 基于余弦相似度(Cosine Similarity)结合多头自注意力(Multi-head Self-Attention, MHSA)[19]机制(COS-MHSA)阶段性地融合重构图像特征和文本特征, 使文本特征具有图像的全局空间信息, 图像特征具有文本的局部语义信息.在模态融合层对这些特征向量进行加权平均, 并注入分类层, 得到最终结果.在EmoRecCom漫画数据集上的实验验证本文方法的有效性.
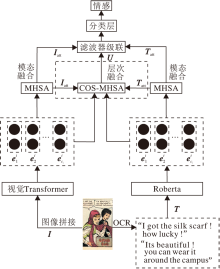
基于双流网络的多模态多标签漫画情感检测方法框图如图1所示.
 | 图1 本文方法框图Fig.1 Flow chart of the proposed method |
不同于单模态下的双流网络常使用不同的分支提取同一模态下不同特征信息[20, 21], 本文方法利用不同流的分支分别提取图像特征和文本特征.首先将漫画中的文本、图像作为两种不同的模态信息, 并使用视觉Transformer编码器接收漫画中的视觉信息
I=[
其中,
Ei=[
其中
T=[
其中,
Ei=[
其中
为了充分使用融合图文特征, 本文提出COS-MHSA模态阶段性融合机制.
常见的图像特征提取器有CNN.相比RNN和Transformer, CNN对于远距离的特征建模能力有限[22].如果使用具有长距离捕获能力的RNN作为图像特征提取, 相比Transformer和CNN, 却存在并行计算效率较低、无法捕获全局信息等问题.而使用基于位置编码的视觉Transformer提取图像特征, 将图像的RGB三通道信息转为带有时序的特征[23], 再利用自注意力机制(Self-Attention), 能更好地捕获图像的有价值长距离特征并过滤多余的无用特征, 获取图像全局的语义信息.
将图像RGB三通道特征I=[
 | 图2 视觉Transformer模块Fig.2 Vision transformer block |
输入漫画图像的特征, 重构
h0=[
其中, l=1, 2, …, L,
h'l=MHSA(Norm(hl-1))+hl-1,
hl=MLP(Norm(h'l))+h'l,
Ei=Norm(
其中, MHSA表示多头注意力机制, Norm表示归一化层, MLP表示多层感知机(Multilayer Perceptron, MLP).
自注意力机制将每个
MHSA(Q, K, V)=
Concat(head1, head2, …, headh)WO,
headi=Attention(
其中, W表示线性变化, h表示第h个注意力.
Roberta[17]以Transformer作为主干网络, 对比传统的词向量模型, 如词映射向量(Word to Vector, word2Vec)、全局向量单词嵌入算法(Global Vectors for Word Representation, GloVe)[24].Roberta基于更大的数据集, 使用遮罩和预测下一句的方法进行训练, 得到预训练语言模型.对比RNN每次只能往后学习一个单词的模式, Roberta对于整个句子的建模能力更强.Roberta的输入由词向量(Token Embe-ddings)、句向量(Segment Embeddings)拼接构成, 并使用位置向量(Position Embeddings)对词向量构造时序关系.计算过程如下:
其中, MLP表示前向多层感知机, l表示Transformer的深度.
本文使用Roberta提取文本特征, 将文本
T=[
构成Roberta的输入词向量tc∈ Rh、位置向量pc∈ Rh和句向量sc∈ Rh, 最后拼接句子的开头和结尾的< s> 和< /s> 关键字符, 得
T=[
作为Roberta的输入.计算过程如下:
[
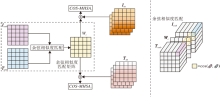
COS-MHSA机制用于解决多标签情感检测任务, 获取更丰富的模态间的交互信息.传统的余弦相似度多用于求取单一模态特征的相似度, 对比文献[25], COS-MHSA机制首先用于计算图像和文本之间的余弦相似度, 得到余弦相似度矩阵Wc.再使用图文模态各自的自注意力与该权重矩阵运算得到对齐后的COS-MHSAi和COS-MHSAt.最后, 通过文本自注意力筛选图像特征、通过图像自注意力筛选文本特征, 完成对噪声特征的过滤和增强重要的信息.
使用视觉Transformer抽取图像特征
Iemb=[
使用Roberta抽取本文特征
Temb=[
分别计算图像和文本的自注意力权重矩阵:
Iatt=MHSA[
使用余弦相似度计算Iemb和Temb之间模态融合的余弦相似度矩阵Wc, 分别对Iatt和Tatt通过L2范数选取有意义的特征, 然后与Wc进行矩阵乘法, 得到具有模态间信息的融合注意力向量U.COS-MHSA机制框图如图3所示.
 | 图3 COS-MHSA机制框图Fig.3 Framework of COS-MHSA mechanism |
算法1给出COS-MHSA机制步骤.
算法 1 COS-MHSA机制
输入 图像特征向量Iemb, 文本特征向量Temb
输出 阶段性融合向量U
function COS-MHSA(Iemb, Temb)
Wc=w· cos(Iemb, Temb)← NULL
If Iemb!=NULL, Temb !=NULL then
logitscale← 自学习权重参数
for each ei∈ Iemb, et∈ Temb do
if loss持续下降n步 then
else
end if
end for
end if
Wc←
Iatt← MHSA(Iemb)
Tatt← MHSA(Temb)
COS-MHSAi← Iatt· Wc
COS-MHSAt← Tatt· Wc
U← concat(Wc· Iatt, Wc· Tatt)
return U
end function
本文采用ICDAR 2021(https://icdar2021.org/program-2/competitions/)漫画情感分类任务的EmoRecCom漫画数据集.此数据集具有丰富的图文信息, 选取COMICS漫画集[26]中多个场景的漫画, 使用OCR[27]识别漫画中的文本信息.通过视觉信息、语音文本、字幕和拟声词描述数据集上的漫画人物的情感, 包含8种情感极性:愤怒(Angry)、厌恶(Disgust)、恐惧(Fear)、快乐(Happy)、悲伤(Sad)、惊讶(Surprise)、中立(Neutral)、其它.
EmoRecCom漫画情感数据集为多情感标签数据集, 对于一个样本数据, 具有多个标签的EmoRec-Com数据集的各情感标签总数和数据集详细信息如表1所示.
| 表1 EmoRecCom数据集详细信息 Table 1 Details of EmoRecCom dataset |
EmoRecCom漫画数据集的视觉信息、语音文本、字幕和拟声词的描述样例如图4所示, 视觉信息主要由漫画人物和背景构成, 文本信息主要由语音文本、字幕和拟声词构成.
 | 图4 EmoRecCom数据集样例Fig.4 An example of EmoRecCom dataset |
相比纯文本的情感分析, 结合图像的多模态方法更能丰富特征的语义信息, 借助其它模态信息的互补, 能更好地判别人物的意图和情感.例如, 对于图5中的漫画样例:(a)从文本“ C'MON, GIRLS, LET'S GO, TO WORK” 表达女孩高兴或中性的情感, 结合图像信息, 可进一步推测女孩高兴的情感; (b)从文本“ WE ARE LOST!” 表达人物A失望的情感, 但是结合图像信息, 可知道(b)传达的不是失望, 而是害怕.由此可见, 图像和文本的模态融合可有效提高情感分析的可信度, 避免单模态存在的歧义和低可信度的问题.
 | 图5 多模态漫画样例Fig.5 Examples of multi-modal comics |
早期的多模态识别研究主要关注单一情感的识别, 但多模态中常存在多人物多场景的现象.因此区分多个人物的多种情绪是具有挑战性的工作[28], 解决多模态融合时多标签的情感指向也同样具有挑战性.
图6(a)中很难辨认女孩的情绪, 但整个情境确实显示她的惊讶.(b)中有3个人物, 仅从人物C的回答进行分析, 无法分析人物C的害怕, 但结合人物A的回答和图像中丰富的语义信息, 不仅可分析人物C害怕的情感, 还可分析人物A愤怒的情感.因此对于多标签情感分析人物, 结合不同模态的信息, 通过模态互补和上下文分析能更精确地分析多人物的情感.
 | 图6 多标签情感漫画样例Fig.6 Examples of multi-label emotion in comics |
本文的实验目的是对多模态多标签漫画中的情感进行检测分类, 实验均在Ubuntu20.04下完成, 模型训练在2个12 GB显存的NVIDIA RTX 2080TI显卡上使用Tensorflow 2.4.1完成.Roberta为遮罩语言建模机制的英文预训练模型, 以一个句子为例, 模型随机屏蔽输入的15%单词, 然后预测被遮罩的单词.
视觉Transformer使用基于Transformer编码器的模型, 不同于传统的Transformer编码器, 本文将归一化层提取到多头自注意力和全连接层前, 如图2所示.实验中使用八层视觉Transformer, 并使用4个头的MHSA提取图像特征.
实验中使用自适应矩估计(Adaptive Moment Estimation, Adam)优化器对损失函数进行优化求解, 并使用五折交叉验证对模型进行选择.实验超参数选择如下:模型参数均为随机初始化, 学习率设置为0.000 03, 批次为32, 迭代次数为5.
实验中分别使用文本或图像单模态信息和多模态融合进行对比, 并对比如下多个基准模型.
1)Text(GloVe+GRU).门控循环神经网络(Gated Recurrent Units, GRU)[29]是一种可有效解决文本分类问题的方式, 实验中使用GloVe作为词向量输入GRU中, 学习文本表示用于分类.
2)Text(Roberta-base).谷歌2018年提出自监督的预训练模型Bert, 而Roberta是基于Bert的优化, 使用更多的数据、更大的批尺寸、更久的训练、更长的样本和动态改变遮罩的位置.
3)Image(EfficientNet B3)[30].基于CNN的图像分类方式, 效率更高、模型更小.通过固定缩放系数和均匀缩放每个维度, 并结合神经网络搜索的方式, 避免大量人工调参工作.图像特征经过最后的池化层作为分类器的输出, 实验中使用EfficientNet预训练模型进行微调, 仅更新分类器的参数.
4)Image(视觉Transformer).文献[5]中较早地将自然语言领域通用的Transformer模型的编码器模块用于图像分类任务, 将图像分割为多个小块并结合位置信息, 得到有序列的图像特征并输入编码器中, 实现快速的并行计算.
5)晚期融合(Late-Fusion).过去许多研究会使用晚期融合模态的方式, 拼接不同的模态信息, 作为分类器的输入.本文使用不同的特征提取器提取不同模态的高维特征, 最后拼接这些特征作为分类器的输入.实验中使用Roberta作为文本的特征抽取器, EfficientNet或Transformer编码器作为图像的特征抽取器.
6)用于多模态情感分析的深度语义网络(A Deep Semantic Network for Multimodal Sentiment Analy-sis, MultiSentiNet)[31].以视觉为主导的注意力长短期记忆网络(Long Short-Term Memory, LSTM)模型.通过牛津视觉几何学组(Visual Geometry Group, VGG)提出的CNN检测图像的场景和目标, 使用LSTM抽取文本特征.最后, 通过视觉特征为主导的注意力机制增强文本特征.
7)基于双向Transformer的多模态模型(Multi-modal Bitransformer, MMBT)[32].分别使用残差网络(Residual Network, ResNet)和Bert单模态编码器提取图像特征和文本特征, 将图像特征映射到文本空间, 通过线性分类层完成分类任务.
本次实验根据受试者工作特征(Receiver Operating Characteristic Curve, ROC)分数和ROC曲线下面积(Area under Curve, AUC)进行评估, 即得分是每个预测情绪的AUC的平均值.实验使用ICDAR 2021的多模态漫画数据集, 包括6 112个训练集样本、2 046个公开测试集样本、2 041个私有测试集样本.
在EmoRecCom漫画数据集上各方法的AUC平均值如表2所示.使用图像主干网络和文本主干网络分别提取图像和文本的高维特征, 并使用晚期融合的方式结合模态间的信息.
| 表2 各方法的AUC平均值对比 Table 2 Comparison of average AUC values of different methods |
由表2可知, 仅使用文本模型或图像模态的表现不佳, 但Text(Roberta-base)的AUC平均值比Text(GloVe+GRU)提升8.0%~10.4%, 说明文本预训练模型对于文本特征的提取具有更好效果.单模态的Image(EfficientNet B3)的AUC平均值比Image(Vision Transformer)提升1.7%~2.4%, 说明预训练的EfficientNet在提取图像特征时能捕获一定的增益信息.
使用晚期融合图文特征的方式能显著提高模型性能, 然而Roberta+Efficient B0、Roberta+Efficient B2、Roberta+Efficient B3在EmoRecCom私有测试集上无明显提升.对比Roberta+Transformer使用非预训练的Transformer编码器提取图像特征的方式, 可知EfficientNet预训练使用的图像数据集多为真实场景中的图像, 对于漫画数据集的迁移能力有限.
同时, 对比以视觉特征为主导的Multi-SentiNet和将图像特征映射到文本空间的MMBT, 本文方法在漫画情感分类任务上更具优势.
根据上述实验对比结果, 本文选择Roberta+Transformer模型作为图文特征提取的主干网络.
在EmoRecCom漫画数据集上的消融实验结果如表3所示, 表中, baseline采用基于Transformer+Roberta的主干网络, “ +” 是向baseline中添加不同的组件.Image-MHSA为图像的自注意力机制; Text-MHSA为文本自注意力机制; MHSA为MHSA+COS-MHSA去除自学习的权重参数矩阵Wc, 直接使用MHSA; COS-MHSAt为仅使用Text-MHSA的单边COS-MHSA机制; COS-MHSAi是仅使用Image-MHSA的单边COS-MHSA机制, +MHSA+OCS-MHSA使用Roberta和Transformer编码器作为图文特征提取的主干网络, 并使用MHSA机制对文本特征和图像特征分别增强, 最后结合COS-MHSA阶段性融合机制, 即本文方法.
| 表3 各方法的消融实验结果 Table 3 Ablation experiment results of different methods |
由表3可知, 在增强Text-MHSA时, 模型的AUC平均值仅有0.42%~0.55%的提升.在增强Image-MHSA时, 模型性能没有提升, 反而降低.但使用晚期融合的方式, 结合Image-MHSA和Text-MHSA对模型性能有显著的提升, 超过仅使用Text-MHSA和Image-MHSA的方式.
在baseline的基础上, 增加COS-MHSA机制对漫画中的图像特征和文本特征进行阶段性融合, 性能提升1.32%~3.11%, 说明当使用COS-MHSA阶段性融合机制时, 可进一步扩充漫画中的图文交互的信息.
为了增强模态间的交互能力, 进一步增加COS-MHSAi或COS-MHSAt模块, 发现较单纯的MHSA性能反而有显著提升.推测COS-MHSA机制受益于MHSA和余弦相似度阶段性融合的方式, 表明COS-MHSA机制在融合图文特征方面的有效性.最后, 对比未使用自学习的权重参数的baseline模型和使用完整的COS-MHSA机制, 发现本文方法能最大化图文的自注意力, 性能提升3.37%~3.81%.
对图像单模态的注意力机制和COS-MHSA中的注意力U进行可视化[33]的结果如图7和图8所示.本文对漫画中的人物、卡通人物进行对立情感、消极情感、积极情感的对比, 进一步验证COS-MHSA模态交互机制对漫画情感检测的增益效果.
 | 图7 单标签情感注意力可视化Fig.7 Visual attention of single-label emotion |
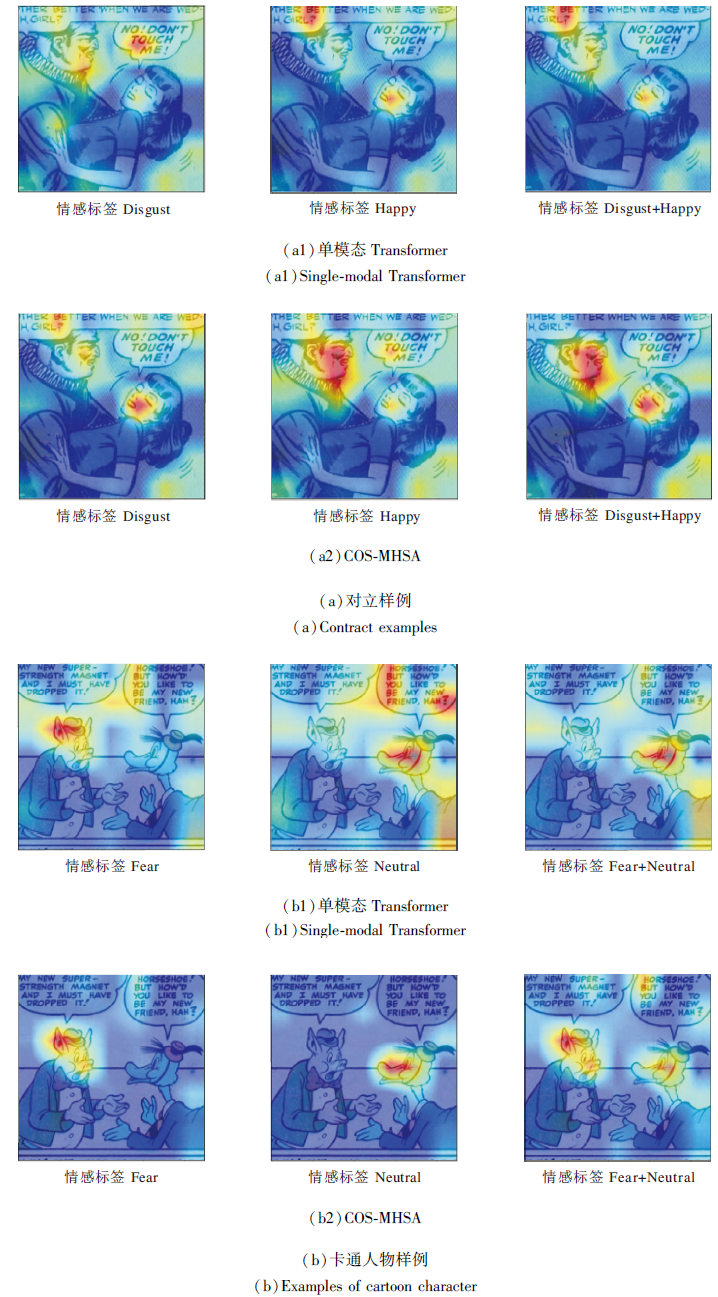 | 图8 多标签情感注意力可视化Fig.8 Visual attention of multi-label emotion |
图7(c)中第1幅为COS-MHSA在单标签下情感权重的注意力可视化, 可发现使用COS-MHSA的模态融合方式不仅关注于人物的面部表情, 也关注细粒度的信息.如图中不仅关注到愤怒的男人的面部表情, 也对他紧握的拳头进行关注.对比单模态视觉Transformer, COS-MHSA在单标签情感检测任务中能检测视觉Transformer关注不到的细节.
图7第2列和第3列为漫画常见的卡通兔子, 由可视化结果可发现, 仅使用单模态Transformer提取的图像特征对卡通人物进行情感检测的关注点过于离散, 这也验证表2中单模态与多模态对比的结果.对比可见, 结合图文融合的COS-MHSA机制能正确关注兔子的面部表情, 可见结合图文的COS-MHSA阶段性融合机制能对漫画中的卡通人物进行更好地建模, 并分析其情感.
图8(a)显示COS-MHSA可正确预测多标签的对立情感极性, 同时展示COS-MHSA多模态融合的方式能消除多标签之间的歧义.例如图中多标签对立情感的样例, 使用图像单模态信息定位漫画中愤怒和高兴的情感指向, 但注意力机制却将女孩的情感误识别为高兴, 男生的情感识别为愤怒.图文融合的COS-MHSA能使用注意力的情感权重正确识别男生和女孩的情感.同时, COS-MHSA在关注漫画人物情感时, 比单模态的视觉Transformer更集中关注到人物的面部表情, 效果更优.
图8(b)显示对漫画场景中卡通人物的多标签情感检测, 不同于现实人物的描绘, 虽然未出现标签歧义的问题, 但卡通人物的表情难以直接从面部表情进行捕获, 可视化基于图像单模态的结果也验证上述结论.使用COS-MHSA层次化融合的方式, 可更集中关注卡通人物的面部表情, 也进一步增加情感检测的准确性.
通过可视化的结果发现, 相比只使用Trans-former的单模态机制, 使用COS-MHSA机制对漫画中多标签情感检测的方式效果更优, 这也进一步证实使用图文各自的MHSA并通过余弦相似度交叉融合的特征更具有情感表现力.
本文提出基于双流网络的多模态多标签漫画情感检测方法.基于余弦相似度结合多头自注意力机制(COS-MHSA), 对文本特征和图像特征进行阶段性融合, 充分利用模态间交互的信息, 解决多模态多标签漫画情感分类任务中存在的标签歧义问题.可视化结果表明COS-MHSA机制能更好地利用模态交互信息, 避免标签和模态之间的歧义, 使文本特征具有图像的全局空间信息, 图像特征具有文本的局部语义信息.今后, 将使用更大的漫画数据集构造漫画多模态预训练模型, 用于漫画场景下的情感检测任务.同时融合更丰富的常识知识到多模态模型中, 提高模型对于多模态多标签场景的泛化能力.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|