




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于GhostNet的端到端红外和可见光图像融合方法
[程春阳1  , 吴小俊
, 吴小俊1 , 徐天阳1 ]
, 吴小俊, 徐天阳]
|
|



作者简介:

程春阳,硕士研究生,主要研究方向为图像融合、深度学习.E-mail:chunyang_cheng@163.com.

徐天阳,博士,副教授,主要研究方向为人工智能、模式识别、计算机视觉.E-mail:tianyang_xu@163.com.
现有的基于深度学习的红外和可见光图像融合方法大多基于人工设计的融合策略,难以为复杂的源图像设计一个合适的融合策略.针对上述问题,文中提出基于GhostNet的端到端红外和可见光图像融合方法.在网络结构中使用Ghost模块代替卷积层,形成一个轻量级模型.损失函数的约束使网络学习到适应融合任务的图像特征,从而在特征提取的同时完成融合任务.此外,在损失函数中引入感知损失,将图像的深层语义信息应用到融合过程中.源图像通过级联输入深度网络,在经过带有稠密连接的编码器提取图像特征后,通过解码器的重构得到融合结果.实验表明,文中方法在主观对比和客观图像质量评价上都有较好表现.
About Author:
Cheng Chunyang, master student. His research interests include image fusion and deep learning.
XU Tianyang, Ph.D., associate professor. His research interests include artificial intelligence, pattern recognition and computer vision.
Most of the existing deep learning based infrared and visible image fusion methods are grounded on manual fusion strategies in the fusion layer. Therefore ,they are incapable of designing an appropriate fusion strategy for the specific image fusion task.To overcome this problem, an end-to-end infrared and visible image fusion method based on GhostNet is proposed.The Ghost module is employed to replace the ordinary convolution layer in the network architecture, and thus it becomes a lightweight model.The constraint of the loss function makes the network learn the adaptive image features for the fusion task, and consequently the feature extraction and fusion are accomplished at the same time. In addition, the perceptual loss is introduced into the design of the loss function. The deep semantic information of source images is utilized in the image fusion as well.Source images are concatenated in the channel dimension and then fed into the deep network.A densely connected encoder is applied to extract deep features of source images. The fusion result is obtained through the reconstruction of the decoder. Experiments show that the proposed method is superior in subjective comparison and objective image quality evaluation metrics.
本文责任编委 兰旭光
Recommended by Associate Editor LAN Xuguang
图像融合是一种将不同传感器得到的图像融合为一幅图像的技术.经过该技术得到的融合图像会比任意一幅源图像都要包含更多的信息.以红外和可见光图像融合为例:在红外图像中包含物体发射的热辐射信息, 该信息不受恶劣或昏暗天气影响, 能较好地被红外传感器捕捉, 但红外图像中缺少物体和背景中的纹理细节信息, 而这些信息却被可见光图像较好地保留下来.因此, 红外和可见光图像的融合能使这两种图像的信息相互补充, 得到的融合图像更适合人眼的观察或用于其它计算机视觉的相关任务, 如目标检测和目标跟踪[1, 2].
现有的图像融合方法大体上可分为两类:传统的图像融合方法和基于深度学习的图像融合方法.传统的图像融合方法大多先通过信号处理技术提取图像特征[3], 如基于多尺度变换的融合方法[4, 5, 6, 7], 首先将图像分解为多个尺度的特征表示, 再使用合适的融合策略融合各尺度的图像特征, 最后通过逆多尺度变换重构, 得到融合结果.
此外, 基于稀疏表示的方法和基于低秩表示的方法也应用到图像融合中[8, 9].基于稀疏表示的方法先从一些高质量的图像中学习一个过完备字典, 再对每个滑动窗口使用稀疏编码得到稀疏表示系数, 最后使用字典重构得到最终融合结果.而基于低秩表示的方法通过低秩表示提取图像特征, 使用特定的融合策略融合图像特征, 通过重构得到融合结果.
虽然这些传统的图像融合方法已取得较优效果, 但是性能在很大程度上依赖于手工设计的融合策略.随着深度学习的发展, 深度网络更强大的特征提取和重构能力已被应用到图像融合任务中, 大幅提升图像融合方法的性能[3].在这些基于深度学习的图像融合方法中, 有些方法使用手工制作的数据集训练卷积神经网络, 实现多聚焦图像融合任务.Liu等[10]使用大量手工制作的清晰和模糊的图像块, 完成卷积神经网络的训练, 训练得到的网络用于进行清晰块和模糊块的分类任务, 得到一个决策图.之后, 源图像可经由该决策图通过加权平均的方式得到多聚焦图像的融合结果.虽然该方法在多聚焦图像融合任务中取得较优效果, 但由于其它融合任务和多聚焦图像融合任务的差异性, 仅适用于特定的融合任务, 存在局限性.
此外, 生成对抗网络也应用到红外和可见光图像融合任务中, Ma等[11]提出基于生成对抗网络的红外和可见光图像融合方法(Infrared and Visible Image Fusion Method Based on the Generative Adversarial Network, FusionGAN), 建立红外和可见光图像之间的对抗关系, 使用生成对抗网络实现红外和可见光图像的融合, 但是, 由于生成对抗网络训练时的不稳定性, 最终生成的融合结果包含较多噪声, 因此生成结果也较模糊.
针对上述问题, 学者们尝试使用无监督的方式解决图像融合问题.Prabhakar等[12]使用由编码器、融合层和解码器组成的深度网络, 使用无监督训练的方式实现多曝光图像融合任务.在融合层仅使用加和方式进行特征的融合操作, 而在损失函数的设计方面, 使用结构相似性(Structural Similarity, SSIM)作为图像评价指标.该损失函数的约束能使输出图像和源图像有更多的结构相似性, 但由于使用的融合策略过于简单, 无法应付更复杂的融合任务.为此, Li等[13]提出基于稠密连接的图像融合方法(Image Fusion Method Based on the Dense Connection, DenseFuse), 将图像融合分解为多个步骤, 首先训练一个自编码器, 再在训练好的自编码器中通过手工设计的融合策略完成特征融合, 最后经过解码器得到融合结果.改进后的这类基于自编码器的方法能实现红外和可见光图像的融合.
上述方法虽然使用深度网络充分提取输入图像的特征, 但仍需要为特定的融合任务手工设计融合策略.常用的融合策略包括最大、最小、加和、L1范数等策略, 在融合策略上有限的选择给图像融合方法性能的提升带来阻碍[14].此外Zhang等[15]提出基于梯度和像素强度比例保持的图像融合方法(Image Fusion Method Based on Proportional Main-tenance of Gradient and Intensity, PMGI), 利用双分支的卷积神经网络, 使用网络的两个分支代表源图像的梯度和像素强度信息, 虽然实现图像融合目的, 但在梯度和强度分支提取特征完毕后, 仅简单地使用一个1× 1的卷积层作为解码器部分, 融合结果较模糊.
针对上述问题, 本文提出基于幽灵模块的卷积神经网络(Convolutional Neural Network Based on the Ghost Module, GhostNet)的端到端红外和可见光图像融合方法.本文方法省去手工制作融合策略的过程, 在执行过程中, 只需将红外和可见光图像级联后输入深度网络中, 通过损失函数的约束, 使网络适应地学习针对红外和可见光图像融合任务的图像特征, 通过解码器对这些特征进行重构, 得到融合结果.此外, 在现有的一些端到端图像融合方法[14, 15]中, 只有像素和梯度信息引入损失函数中用于优化深度网络, 为了能进一步在融合结果中保留源图像中的显著信息, 本文方法在损失函数中添加感知损失项, 用于挖掘图像的深层语义信息.其次, 现有的一些端到端红外和可见光图像融合方法存在融合结果不够清晰、目标区域热辐射信息不显著等问题, 为了缓解这一问题并精细化对图像特征的重构, 受基于嵌套连接的红外和可见光图像融合方法(Infrared and Visible Image Fusion Method Based on Nest Connection, NestFuse)[16]启发, 本文在设计的深度网络中添加稠密连接的结构, 并在编码器和解码器网络之间添加直接连接, 加深网络深度, 使解码器能在生成融合结果时, 补充编码器提取的图像不同层次的特征, 提高融合结果的质量.此外, 本文方法是基于GhostNet[17]的Ghost模块搭建的, 在编码器中, 所有的卷积层都由GhostNet中的瓶颈结构代替, 解码器中的卷积层全由Ghost模块代替, 减小网络模型的大小和参数量, 提高计算效率.在主观和客观的评估实验上, 本文方法都取得较好的结果.
Han等[17]提出GhostNet, 指出现有网络模型卷积层中存在大量冗余特征图, 这些冗余特征图可经由同一卷积层中其它特征图(本质特征图)通过线性变换得到.为此, 提出Ghost模块, 先通过少量的卷积操作得到本质特征图, 再对这些本质特征图施加线性变换, 得到Ghost特征图(冗余特征图).最后, 将本质特征图和冗余特征图进行级联操作, 得到和普通卷积层输出相同数量的特征图.这样的分步操作大幅减少深度网络中卷积层的计算量.基于减小深度网络模型的考虑, 本文在网络设计中使用Ghost模块代替所有的卷积层, 并在编码器网络中使用GhostNet中的瓶颈结构.
Huang等[18]提出稠密连接的卷积网络(Densely Connected Convolutional Networks, DenseNet).在该网络模型中, 所有卷积层输出的特征图级联后作为后续卷积层的输入, 可有效传递网络中各深度的图像特征, 充分利用网络中的图像特征.
为了能在提取图像特征时不丢失图像的浅层语义信息, 提升融合结果的质量, 本文考虑在编码器中也采用这样的稠密连接方式, 将所有Ghost瓶颈结构输出的特征图进行级联, 作为随后瓶颈结构的输入.
本文提出基于GhostNet的端到端红外和可见光图像融合方法, 网络模型主要由编码器和解码器两部分组成, 具体如图1所示.在整个网络中, 所有卷积层都由一个GhostNet中的Ghost模块代替, 图中的数字标注输入输出特征图的通道数信息.
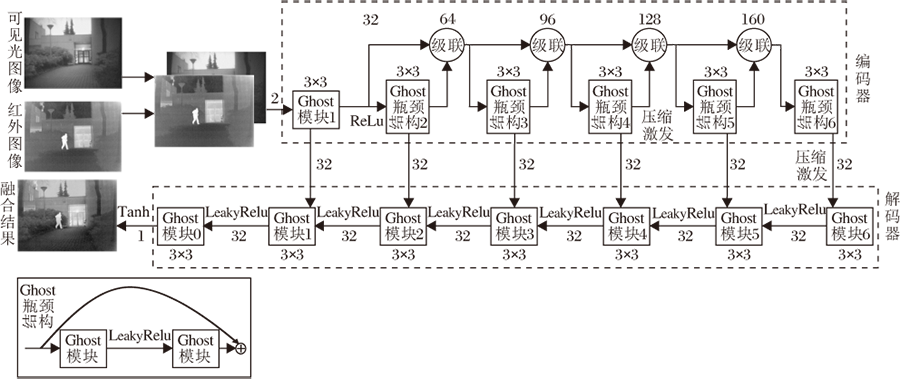 | 图1 本文方法结构图Fig.1 Architecture of the proposed method |
在编码器中, 根据现有的一些基于深度网络的方法[14, 15], 在通道维度对红外和可见光图像进行级联操作, 再通过一个Ghost模块进行浅层图像特征提取.这些浅层的图像特征被输入带有稠密连接的特征提取块中.该特征提取块由5个Ghost瓶颈结构组成, 在稠密连接中经过级联得到的特征图通道数由32递增至160, 这样做使编码器能充分提取源图像特征.这些特征图被输入解码器中进行融合结果的重构.解码器中每个Ghost模块的输入都是上一层Ghost模块的输出和编码器中对应层级提取图像特征的级联, 这样的连接使融合结果在解码器重构过程中可补充编码器中不同层次的图像特征, 提高融合图像的质量.
此外, 编码器中使用的压缩和激发操作[19]引入特征图通道之间的非线性关系, 加强不同通道的图像特征.除编码器的初始升维阶段和解码器的末端分别使用ReLu和Tanh激活函数之外, 网络中其它部分都使用LeakyRelu激活函数.网络中的卷积运算使用标准的3× 3卷积核, 进行填充操作时选取的填充值固定为1.该设置保证卷积操作前后, 特征图大小不会发生改变, 从而该网络可接受任意尺寸大小图像的输入.
在损失函数的设计方面, 希望融合图像和源图像拥有一致的像素强度分布及结构相似性(SSIM).因此, 本文在损失函数中引入像素强度损失和结构相似性损失.此外, 为了能在融合结果中保留源图像中深层的语义信息, 受基于卷积神经网络的通用融合方法(General Image Fusion Framework Based on Convolutional Neural Network, IFCNN)[20]的启发, 本文方法还在损失函数中设计感知损失项.因此, 总损失函数定义为
Ltotal=α Lpixel+β Lssim+γ LP, (1)
其中, Lpixel表示像素强度损失, Lssim表示结构相似性损失, LP表示感知损失项, α 、 β 、γ 将不同的损失项控制在同一数量级, 并按比例进行调节.
这里的像素强度损失项用于约束融合图像和可见光及红外图像, 使融合结果拥有和源图像相似的像素强度分布, 该损失项的定义为
Lpixel=
其中, O表示输出的融合图像, Ivis表示输入的可见光图像, Iir表示输入的红外图像,
结构相似性损失项用于约束融合图像和输入的源图像, 使它们有一致的结构相似性.这一损失项是基于SSIM这一图像质量评价指标得到的[21], 即
Lssim=(1-SSIM(O, Ivis))+(1-SSIM(O, Iir)),
其中SSIM(· )表示两个图像的结构相似性度量.
感知损失项是将融合图像和源图像分别输入预训练的VGG19网络[22]中提取深度特征, 再计算特征图的均方损失得到的.在这里, 本文方法只希望融合结果与源图像在较深层的语义信息上保持一定的相似性, 所以在计算特征损失时, 本文方法只选取在图像输入预训练好的VGG19网络后, 最后k(k=1, 2, …, 5)个池化层前得到的特征图.这样做能在深层特征空间中约束融合结果, 在像素和结构损失保留源图像信息的基础上进一步体现各源图像的优势, 这一感知损失项的定义为
LP=
其中,
为了验证本文方法的有效性.在TNO(https://figshare.com/articles/dataset/TNO_Image_Fusion_Dataset/1008029)、RoadScene[14]两个公开可用的红外和可见光图像数据集上进行实验, 并且在相同的实验环境下对比如下红外和可见光图像融合方法.1)传统方法:基于梯度转移和最小差异和的融合方法(Fusion Method Based on Gradient Transfer and Total Variation Minimization, GTF)[23]; 2)4个基于深度学习的方法:FusionGAN[11]、DenseFuse[13]、一个通用的无监督图像融合网络(Unified Unsupervised Image Fusion Network, U2Fusion)[14]、 PMGI[15].
因为现有的红外和可见光图像数据集上图像的数量较少, 因此在本文中, 首先选取TNO数据集上15对图像, 再将这些图像稠密地裁剪为64× 64的图像块, 得到22 853对红外和可见光图像.使用这些图像进行无监督的训练.训练时, 式(1)中各损失项的参数α =10, β =1, γ =1, 而式(2)中感知损失项的k=3.批尺寸大小为48, 迭代次数为5.损失函数式(1)是使用自适应矩估计(Adaptive Moment Estimation, Adam)优化器在10-4的学习率设置下进行优化.对比方法的实验是使用相应论文提供的代码进行的.
本文方法使用Pytorch框架在Python3.7.3环境下完成.实验都是在NVIDIA RT-X2080Ti GPU和i9-10980XE CPU的硬件环境下完成.
首先, 从TNO数据集上选取一对图像, 进行主观对比实验, 各方法的融合结果如图2所示.由图可见, GTF和FusionGAN虽然在目标区域保留较多的热辐射信息, 但在图像中引入许多人工噪声, 图像较模糊.此外, 在标注的区域内, DenseFuse和PMGI都不能较好地保留可见光图像中的细节纹理信息.只有本文方法和U2Fusion可较清晰地呈现标注区域中草丛的边缘和纹理细节.但是在U2Fusion的融合结果中, 并未较好地保留目标的热辐射信息.
 | 图2 各方法在TNO数据集一对图像上的融合结果Fig.2 Fusion results of different methods for a pair of images on TNO dataset |
再使用TNO数据集上21对图像进行客观对比.采用信息熵(Entropy, EN)、相关性差异之和(Sum of Correlations of Differences, SCD)[24]、结构相似性(SSIM)[21]、互信息(Mutual Information, MI)、均方差(Standard Deviation, SD)、相关系数(Correlation Coefficient, CC)和视觉信息保真度(Visual Information Fidelity, VIF)[25]这7个图像质量评估指标.各方法计算的指标值的平均值如表1所示, 表中黑体数字表示最优结果, 斜体数字表示次优结果.
| 表1 各方法在TNO数据集21对图像上的指标值对比 Table 1 Index value comparison of different methods for 21 pairs of images on TNO dataset |
由表1可见, 本文方法在计算的7个指标中, 有5个排名第一, 另外2个排名第二.相比使用手工设计融合策略、同为基于深度学习的方法DenseFuse, 本文方法在这7个指标上分别提升2.82%、15.00%、0.52%、2.82%、3.20%、4.45%、52.95%.这表明本文方法融合效果优于传统的手工设计融合策略的方法.本文方法在EN指标上排名第一, 说明融合结果中包含更多的图像信息.
排名第一的SCD、MI、SSIM指标和排名第二的CC指标表明本文方法的融合结果与源图像具有更高的相关性和结构相似性.最后, 排名第一的SD指标和第二的VIF指标从清晰度上说明本文方法的优越性.与此对应, GTF和Fusion-GAN在这两个指标上较差的表现则解释它们在主观实验中稍差的图像清晰度的原因.
为了进一步验证本文方法的有效性及泛化性能, 在另一个包含图像数量更多的RoadScene红外和可见光图像数据集[14]上进行对比实验.首先, 从RoadScene数据集上选取一对图像, 进行主观对比.
各方法在RoadScene数据集一对图像上的融合结果如图3所示, GTF和FusionGAN仍然在蓝色区域中引入人工噪声.而从红色区域中可看到, 本文方法在目标上较好地保留热辐射信息, 更适宜人眼观察.而U2Fusion虽然在融合结果中保留较多的纹理细节, 但融合结果更偏向于可见光图像.
 | 图3 各方法在RoadScene数据集一对图像上的融合结果Fig.3 Fusion results of different methods for a pair of images on RoadScene dataset |
在目标区域的周围, DenseFuse、U2Fusion、PMGI的融合结果都在一定程度上丢失热辐射信息.这也体现出本文方法在损失函数中引入感知损失项的作用— — 在融合结果中可以有效保留更重要的图像信息.
再选取50对来自RoadScene数据集上的图像, 进行定量实验, 同样计算7个指标的平均值.各方法在RoadScene数据集50对图像上的指标值对比如表2所示, 表中黑体数字表示最优结果, 斜体数字表示次优结果.
| 表2 各方法在RoadScene数据集50对图像上的指标值对比 Table 2 Index values of different methods for 50 pairs of images on RoadScene dataset |
由表2可知, 本文方法在测试的7个指标中, 有4个排名第一, 另外3个排名第二.GTF在EN、SD指标上高于本文方法, 一个重要的原因可能是它们的融合结果中包含较多的人工噪声[26].
另外, 在VIF指标上较好的表现也说明本文方法的融合结果更符合人的视觉感知.本文方法在2个数据集上都拥有出色的表现, 说明自身能有效完成红外和可见光图像的融合任务, 具有较强的泛化能力.
为了研究感知损失函数中选用不同深度的图像特征对融合结果的影响, 从TNO数据集上选取一对图像, 对式(2)中感知损失函数不同的k值及去除感知损失的情形进行主观对比实验, 融合结果如图4所示.当k=5时, 感知损失将低、中、高层的图像特征都进行约束, 而对低层图像特征的约束与像素强度损失项的作用有一定程度的重叠, 导致融合结果中标注区域较暗.而当k=1时, 感知损失只考虑最高层的语义信息, 这使融合结果在标注区域中丢失红外图像中物体的结构、形状等信息.只有选择适中的k值, 如k=2, 3, 这时感知损失对中、高层的图像特征进行约束, 与像素损失项的约束相互补充, 融合结果中的强调区域才能有效保留清晰的红外图像信息.
 | 图4 去除感知损失及感知损失中k不同值在TNO数据集一对图像上的融合结果Fig.4 Fusion results obtained by removing perception loss and using different settings of k for one pair of images on TNO dataset |
此外, 在去除感知损失后, 在标注区域中, 云的周围产生不自然的边缘, 而在加入感知损失后未出现这一人工噪声, 这也验证本文感知损失的有效性.
实验同样选用TNO数据集21对图像, 针对感知损失中不同k值及去除感知损失项的情形, 计算各方法在7个指标中的平均值, 具体如表3所示, 表中黑体数字表示最优结果, 斜体数字表示次优结果.
| 表3 感知损失项中k不同时在TNO数据集21对图像上的指标值对比 Table 3 Index values with different settings of k from perception loss item for 21 pairs of images on TNO dataset |
由表3可见, 当k=2时, 融合结果在SD、VIF指标上排名第一, 这说明融合结果更符合人的视觉感知.而当k=3时, 融合结果在EN、MI、CC指标上都排名第一, 这说明该实验设置下的融合结果中包含更多的信息, 与源图像具有更强的相关性.
在其它k值及去除感知损失项的情况下, 融合结果的各个指标稍差, 这也与主观对比中呈现的融合结果一致.
本文在设计网络时, 在编码器和解码器之间添加直连结构, 为了验证此结构的有效性, 在TNO数据集上进行定量的对比实验, 结果如表4所示, 表中黑体数字表示最优结果.
| 表4 直连结构在TNO数据集图像上的指标值对比 Table 4 Index value comparison of skip connections on TNO dataset |
由表4可见, 在添加直连结构之后, 本文方法在EN、SSIM、MI、SD指标上都有提升, 这表明在增加直连结构之后, 本文方法产生的融合结果包含更多的信息, 并且在相关性及清晰度上都更有优势.虽然在其余3个指标上的性能有所下降, 但可看到在CC、VIF指标上, 相比不使用直连结构的方法, 使用本文方法数值的差异非常微小.
本文提出的深度网络是基于轻量级的GhostNet网络模型搭建的, 目的是为了减少网络模型的参数量, 提高计算效率.为此, 对比各基于深度学习的图像融合方法的模型参数量.具体如下:FusionGAN为1 326 200, U2Fusion为659 200, DenseFuse为74 200, PMGI为42 200, 本文方法为53 100.本文方法模型参数量略高于PMGI, 但是从2个数据集上的实验结果来看, 本文方法的融合结果优于PMGI.此外, 本文方法在取得更好的融合结果的同时, 参数量的大小仅为U2Fusion的1/10.
针对视频监控中会出现的低光照环境, 本文选取街景数据集2对RGB可见光和红外图像进行融合实验.根据文献[14]中使用的策略, 将RGB图像转换到YCbCr色彩空间中, 由于图像的结构细节及色彩变化等主要保留在Y通道中, 因此采用本文方法对Y通道和红外图像进行融合操作, 融合后的Y通道再与Cb、Cr通道一起转换为RGB融合结果, 具体融合结果如图5所示.
 | 图5 RGB可见光图像和红外图像融合结果Fig.5 Fusion results of RGB visible and infrared images |
由图5可见, 标注行人的第1列图像对中的行人在保留热辐射信息之后在融合结果中变得更显著, 而标注汽车的第2列图像中车辆细节在融合结果中变得更清晰, 并且一定程度上缓解欠佳的曝光问题.
本文提出基于GhostNet的端到端红外和可见光图像融合方法, 在图像融合的过程中不需要手工干预和设计复杂的融合策略.设计的深度网络由编码器和解码器组成, 在编码器端采用稠密连接的方式, 充分利用各层次的Ghost瓶颈结构, 提取图像特征.在解码器和编码器网络之间添加直连结构, 使融合结果在重构过程中能补充编码器中提取的各层次的图像特征, 提高融合结果的质量.此外, 本文方法在损失函数中引入感知损失项, 挖掘源图像和融合结果中的深层语义信息, 使融合结果和源图像在特征维度上也能保持一定的相似性.实验结果显示, 本文方法在2个公开可用的红外和可见光图像数据集上都取得较优的定性和定量结果.
虽然本文方法已取得较优的结果, 但是在进行融合操作时, 使用的都是已预先对齐好的图像.在现实应用中, 存在大量未经对齐的图像, 这必然会影响融合方法的性能.此外, 方法的轻量化也是图像融合投入实际应用中的关键.这些都是今后研究需要解决的问题.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|