
{kind=link}
{kind=link}
面向方面级情感分类的特征融合学习网络
[陈金广1  , 赵银歌
, 赵银歌1 , 马丽丽1 ]
, 赵银歌, 马丽丽]
|
|



作者简介:

陈金广,博士,教授,主要研究方向为信息融合、机器学习、计算机应用.E-mail:xacjg@163.com.

赵银歌,硕士研究生,主要研究方向为自然语言处理、情感分析.E-mail:2843935531@qq.com.
在方面级情感分类任务中,现有方法强化方面词信息能力较弱,局部特征信息利用不充分.针对上述问题,文中提出面向方面级情感分类的特征融合学习网络.首先,将评论处理为文本、方面和文本-方面的输入序列,通过双向Transformer的表征编码器得到输入的向量表示后,使用注意力编码器进行上下文和方面词的建模,获取隐藏状态,提取语义信息.然后,基于隐藏状态特征,采用方面转换组件生成方面级特定的文本向量表示,将方面信息融入上下文表示中.最后,对于方面级特定的文本向量通过文本位置加权模块提取局部特征后,与全局特征进行融合学习,得到最终的表示特征,并进行情感分类.在英文数据集和中文评论数据集上的实验表明,文中网络提升分类效果.
About Author:
CHEN Jinguang, Ph.D., professor. His research interests include information fusion、machine learning and computer applications.
ZHAO Yinge, master student. Her research interests include natural language processing and sentiment analysis.
In the aspect-level sentiment classification task, the abilities of the existing methods to enhance aspect terms information and utilize local feature information are weak. To settle this problem, a feature fusion learning network(FFLN) is proposed. Firstly, comments are processed into text, aspect and text-aspect as input. After obtaining vector representation of the input by bidirectional encoder representation from the transformers model, the attention encoder is utilized to obtain the hidden state of the context and aspect items and extract the semantic information. Then, based on the hidden state feature, aspect-specific text vector representation is generated using aspect-specific transformation component to integrate aspect terms information into context representation. Finally, the local features are extracted from aspect-specific text vector by the context position weighted module. The final representation features are obtained by the fusion learning of global and local features, and sentiment classification is conducted. Experiments on classical English datasets and Chinese review datasets show that FFLN improves the classification effect.
本文责任编委 马少平
Recommended by Associate Editor MA Shaoping
互联网中的评论信息反映人们对社会事件或商品的主观意见和态度, 具有较大的应用价值[1].方面情感分类(Aspect Sentiment Classification, ASC)是一项细粒度的情感分析任务[2], 可预测同一句子中出现的不同方面的情感态度(如消极、中性或积极)[3].ASC任务挖掘不同目标对应的情感极性, 准确预测多目标评论文本的情感, 而不是仅判断整个句子的情感极性[4].
早期的方法主要使用特征工程以监督学习的方式进行文本情感分类.Jiang等[5]基于句子的语法结构, 创建多个与方面词相关的特征, 识别方面情绪的极性.Kiritchenko等[6]采用支持向量机, 结合n-gram和情感字典等特征进行识别.这类方法需要花费大量的时间分析和处理数据, 并且根据数据集的特点设计特征提取规则, 通用性不高, 效率偏低.
近年来, 基于端到端学习方式的深度神经网络在ASC任务上取得较好的识别效果[7].Tang等[8]提出目标依赖的长短期记忆(Target-Dependent Long Short-Term Memory, TD-LSTM)网络, 将方面信息融入输入中, 使用2个长短期记忆网络(Long Short-Term Memory, LSTM), 提取目标字词左、右两个不同方向的文本特征进行预测, 但文本与方面词交互方式较单一.随着注意力机制的广泛应用, 在ASC任务中可让模型更关注与方面词相关的文本信息, 自动学习更多的隐藏特征[9].现已有学者对此进行研究.Fan等[10]提出多粒度注意力网络(Multi-grained Attention Network, MGAN), 使用细粒度注意力机制捕获方面词和上下文之间的词级交互关系, 并提出方面对齐损失, 描述具有相同上下文的方面词之间的交互关系.Huang等[11]在评价目标和上下文之间, 根据双重注意力(Attention-over-Attention, AOA)机制, 共同学习上下文和方面的表示, 获取深层次的隐藏信息.Chen等[12]提出基于记忆机制的递归注意力(Recurrent Attention on Memory, RAM)网络, 捕获长距离的情绪信息.Phan等[13]、Lu等[14]设计一定的结构, 将句法和语义融入模型中.
上述模型都基于循环神经网络(Recurrent Neural Network, RNN)获取文本间的隐藏状态, 但是RNN结构很难并行计算, 消耗大量内存, 并且基于截断的反向传播, 不能获取长距离的语义关系.对于由多个词汇构成的评价目标, Wang等[15]、Ma等[16]将多个词汇均值化后的向量作为评价目标的表示, 减弱不同词汇对评价目标的影响程度.
Song等[17]提出注意力编码器网络(Attentional Encoder Network, AEN), 采用多头注意力建模方面词与上下文的关系, 解决RNN出现的问题.杨玉亭等[18]提出面向上下文注意力的联合学习网络(Con-text-Oriented Attention Joint Learning Network, CAJLN), 将双向Transformer的表征编码器(Bidirectional Encoder Representation from Transformers, BERT)[19]作为编码器, 在上下文和方面词之间建立多种注意力机制, 增强模型对方面词的感知能力.近来也有一些研究者将图卷积应用到ASC任务中.Zhang等[20]提出特定方面的图卷积网络(Aspect-Specific Graph Convolutional Network, ASGCN), 基于句子的依赖树结构, 建立图卷积网络以利用语法信息和单词的依赖关系.Tang等[21]提出增强的依赖图双向Transformer网络, 支持平面表示学习和基于图的表示学习之间的相互强化, 解决依赖树存在的噪声和不稳定性问题.
受文献[18]的启发, 并针对上述问题, 本文以注意力编码网络为基础, 提出面向方面级情感分类的特征融合学习网络(Feature Fusion Learning Network, FFLN).首先使用BERT预训练模型得到文本嵌入向量和方面词嵌入向量, 并通过注意力编码器获取输入向量间的隐藏状态.然后, 为了加强方面词与文本之间的交互, 利用特定方面转换(As-pect-Specific Transformation, AST)模块获取特定的方面词级的上下文特征表示.研究发现, 在提取评价目标情感信息时, 距离目标较远的词可能会干扰情绪的分析, 因此, 本文保留目标的局部特征, 减少与目标无关的文本单词的影响, 对局部与全局的特征信息进行联合学习, 定位评价目标的情感.在数据集上的实验证实FFLN可提升分类效果.
方面级情感分析要解决的任务是:对于长度为n的评论文本
s={w1, w2, …, wt, …, wt+m-1, …, wn}
和出现在s中长度为m的方面
a={wt, wt+1, …, wt+m-1},
预测a的情感极性, 其中, wi表示一个单词或字符, a由单个字符或短语构成.
本文提出面向方面级情感分类的特征融合学习网络(FFLN), 结构如图1所示, 数据输入后, 经过嵌入层获取词向量表示.再通过注意力编码器得到句子中各词汇之间和句子与方面词的信息依赖关系.经过交互注意力层获取特定的方面级的上下文表示, 并通过特征提取层得到局部信息.在输出层, 融合局部特征与全局特征, 融合后的特征用于预测评论文本中目标的情感类别.FFLN结构分为嵌入层、注意力编码层、交互注意力层、特征提取层和输出层.
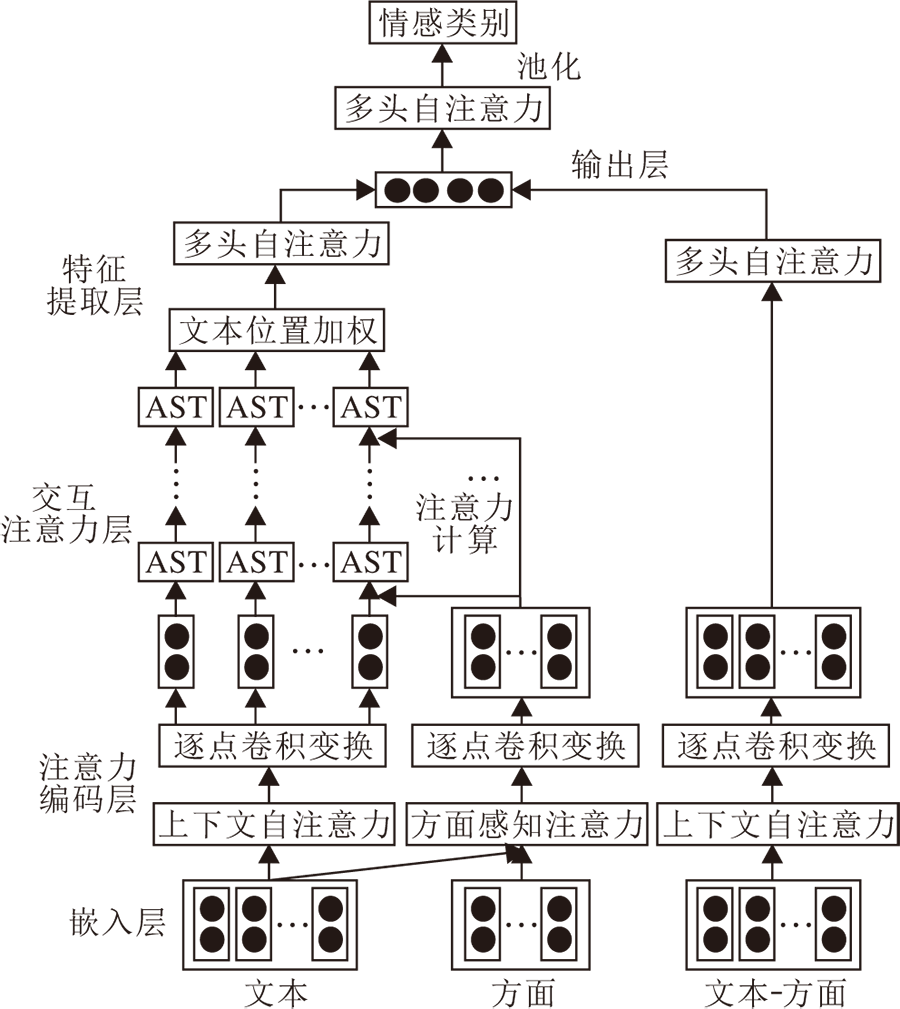 | 图1 FFLN结构图Fig.1 Structure of FFLN |
嵌入层是整个网络的基础层, 作用是将文本中每个单词映射到低维语义向量空间.早期的预训练语言模型[22, 23]无法区分不同语境下词汇表达的不同意义.经过ELMo(Embeddings from Language Mo-dels)[24]和GPT(Generative Pre-Training)[25]的发展后, 出现BERT, 它是一种通过自监督学习在大型语料库上训练而成的语言表示模型, 无关于具体任务, 可得到词汇在特定语境中的语义表示, 具有更强大的信息表达能力.因此, 嵌入层使用BERT提取句子特征.
基于BERT的句子对分类模型(BERT for Sen-tence Pair Classification, BERT-SPC)[17]把文本和方面作为输入的两个部分, 将BERT应用到ASC任务中.受BERT-SPC的启发, 将FFLN嵌入层中的3种输入方式分别调整为[CLS]-文本-[SEP]、[CLS]-方面词-[SEP]、[CLS]-文本-[SEP]-方面词-[SEP]结构, 使其适用于BERT的输入形式, 其中, [CLS]作为输入开始的标志, [SEP]用于分隔2个不同的输入.经过嵌入层处理后, 对于输入中的一个词汇wi, 可得到嵌入向量xi∈
与RNN不同, 注意力编码器是一个可并行计算结构, 用于提取输入向量的隐藏特征.这一层包含2个子模块:多头注意力计算(Multi-head Attention, MHA)[26]和逐点卷积变换(Point-Wise Convolution Transformation, PCT).
1.2.1 多头注意力计算
MHA[26]是指可并行执行多头注意力计算功能的方法.注意力函数可抽象描述为将查询序列Q={q1, q2, …, qn}与键向量K={k1, k2, …, km}、值向量V={v1, v2, …, vm}从映射到输出, 输出被计算为值的加权和, 其中分配给V的注意力权重是由查询qi与键K的相似性函数得到.同时计算一组查询Q上的注意力函数:
Attention(Q, K, V)=softmax〔
其中, dk表示q、k的维度,
多头注意力机制可同时关注来自句子不同位置的字词信息, 进而关注不同表示子空间的信息.将输入中的每个元素通过不同的线性变换映射到dk、dk和dv维度上, 再执行注意力函数, 会得到单个注意力头的表示向量:
headi=Attention(Q
经过并行计算后, 得到多个注意力头的输出向量, 最后将这些输出进行拼接, 再通过线性变换得到预期的维度:
MHA(Q, K, V)=tanh({head1; head2; …; headh}· WO).
其中:WQ∈
在图1中, 上下文自注意力(也叫多头自注意力)用于处理查询和键向量相等(即Q=K )的情况, 使其关注自身特征.通过计算输入的每个词向量和其它词向量之间的关系, 得到输入中每个词向量新的注意力表示, 进而可感知句子中每个位置的信息, 获得长期依赖关系.对于嵌入层得到的文本向量xc和全局特征向量xg, 由
cc=MHA(xc, xc, xc), cg=MHA(xg, xg, xg)
可得到文本表示向量cc={
方面感知注意力用于处理查询和键向量不相等(即Q≠ K)的情况, Q和K分别是嵌入层得到的文本向量xc和方面词向量xa, 方面感知注意力可表示为
ca=MHA(xc, xa, xa).
通过该交互操作, 加深上下文和方面词的联系, 由xc中元素根据注意力分数进行加权计算后, 得到评价方面中每个词汇向量
ca={
1.2.2 逐点卷积变换
PCT对MHA获取的特征进行信息转换, 获取文本的序列关系.逐点卷积意味着卷积核为1, 对于输入的每个词将应用同样的卷积操作.假设输入序列为H, PCT操作定义如下:
PCT(H)=σ (H* W1+b1)* W2+b2,
其中, σ 表示ReLU激活函数, * 表示卷积操作, W1∈
cc、ca、cg经过PCT操作后, 分别得到文本、方面和全局特征的注意力编码层隐藏特征hc、ha、hg.
当前关于字符级别的文本特征向量hc未考虑方面词的信息, 为了加强文本与方面之间的关系, 使用方面转换模块(AST)进行学习, 并使用残差结构增加信息的传递.将方面词的信息融入文本表示中, 获得特定的方面级的文本特征.
AST首先需要生成方面的向量表示, 但是文本中的评价目标可能是单个字符或短语, 对于短语的目标来说, 将其均值化后的向量作为目标表示, 在很多场景下不合适, 因为不同词对评价目标的重要程度不一样.因此, 这里对句子中的每个字符分别与方面词进行注意力计算, 得到对于文本中单个词汇特定的方面表示特征.
对于评论文本中的每个字符i, 动态计算文本特征
其中, i=1, 2, …, s, m表示方面词的最大长度, s表示最大句子长度, F表示衡量第j个方面词向量
F(
接下来需要对信息进行融合, 将注意力编码层得到的文本特征向量hc与式(1)得到的专门针对上下文的方面特征rc={
其中, g表示ReLU激活函数, Wc∈
为了保留上下文信息, 使用残差网络[27]中信息保存的策略, 将融合方面词信息的上下文向量
h=
通过实验, 最终模型选择使用一层AST模块进行方面词信息的融合.
1.4.1 局部特征提取
为了捕获评价目标的情感信息, 一些方法通过注意力机制, 计算方面和整个句子之间的相关性.然而研究发现, 不同位置的情感词汇对于特定方面情感识别具有不同的作用, 一个方面的情感极性可能与它周围的文本更相关, 而距离较远的词汇会干扰它的判断.本文同样考虑该情况, 设置文本位置权重模块, 并引入语义距离(Semantic Distance, SD)的概念, 采用邻近策略评估文本中当前词与方面词之间的相关关系.
SD根据文本中词汇与方面词的位置关系进行计算, 可表示为
SDi=|i-Pa|-
其中, i=1, 2, …, s, i表示文本中单词的位置, Pa表示评价目标的中心位置.
引入语义距离阈值α , 完全保留小于α 的特征, 削弱大于α 的特征, 即根据SD减少远离评价目标的文本词汇特征:
Vi=
其中, I表示单位矩阵, 得到位置权重V后, 与上一层的输出h进行逐元素相乘, 得到局部特征序列OL=V☉h, ☉表示矩阵的逐元素相乘.OL强调近距离情感词的重要性, 而全局特征处理远距离的依赖关系.
1.4.2 全局特征提取
全局信息作为对局部特征的补充, 由注意力编码层得到的文本-方面hg经过多头自注意力编码(MHA)计算后得到, 自动学习文本和方面之间的关系, 可表示为
Og=MHA(hg, hg, hg).
输出层需要对获得的全局特征和局部特征进行融合学习, 首先对OL和Og进行拼接, 通过线性层映射到
OLg=WLg· [OL; Og]+bLg,
其中, WLg∈
O=MHA(OLg, OLg, OLg).
接下来, 对O进行池化操作:
x=POOL(O).
抽取它第一个位置上对应的特征作为最终的向量表示x.将x通过一个全连接层映射到维度为C的向量空间中:
x'=W· x+b.
其中W∈
y=softmax(x')=
其中C表示情感的类别数.
模型采用交叉熵损失函数计算预测值与真实值之间的误差, 并使用L2正则化作为优化项.定义如下:
L(θ )=-
其中, yi表示输出层预测的情感极性值,
本文实验选用英文数据集和中文评论数据集[28].英文数据集包括3个在文献中常用的基准数据集, 即SemEval 2014任务4中餐厅的评论数据集(Restaurant)、笔记本电脑的评论数据集(Laptop)、通用ACL14推特社交数据集(Twitter).中文评论数据集包括手机(Phone)、汽车(Car)、笔记本(Notebook)、照相机(Camera)4个领域的评论数据集.
英文数据集上每篇评论都包含句子、评价方面和情感极性.这些数据集被标记为3种情绪极性:积极、中性和消极.每个类别中的训练和测试示例的数量如表1所示.
| 表1 英文数据集信息 Table 1 Information of English datasets |
中文评论数据集由Peng等[28]在文献[29]的基础上, 通过手动标注评价文本中方面的情感极性得到, 有积极和消极两种情感.实验中发现一些错误数据(标签缺失、评论中标记有误等), 经过处理后, 中文评论数据集的统计信息如表2所示.
| 表2 中文评论数据集信息 Table 2 Information of Chinese review datasets |
实验具体参数设置如下:BERT词嵌入维度为768, 基于BERT模型的学习率为2e-5, 通用词嵌入维度为300, 基于通用词嵌入模型的学习率为0.001, L2正则化系数为1e-5, 批处理大小为16.采用自适应矩估计(Adaptive Moment Estimation, Adam)优化器.中、英文数据集在语言表述上存在明显差异, 因此分别设置如下参数:英文数据集上评论文本最大长度为70, 语义距离为4, 5, …, 8; 中文评论数据集上评论文本最大长度为50, 语义距离为5.
基于BERT使用BERTbase预训练模型.在基于通用词嵌入模型中, 英文使用GloVe(Global Vectors for Word Representation)预训练词向量, 中文使用文献[30]中训练得到的字向量.模型中参数使用均匀分布进行初始化.
为了评估FFLN的性能, 与如下深度神经网络模型进行对比实验.
1)交互注意力网络(Interactive Attention Net-works, IAN)[16].在2个LSTM上获取上下文和方面的隐藏向量, 经过平均池化操作后, 通过注意力机制交互学习方面和上下文的表示.
2)RAM[12].含有多层架构, 每层由聚合词汇特征的注意力机制和学习句子表示的非线性网络组成.
3)MGAN[10].结合粗粒度注意力和细粒度注意力, 捕获方面词和上下文之间的多重交互关系.
4)ASGCN[20].利用多层图卷积提取方面特征后, 与上下文隐藏状态进行注意力计算, 检索与方面相关的特征信息.
5)BERT-SPC[17].利用预训练的BERT模型处理ASC任务.
6)AEN-BERT[17].提出注意力编码器网络解决RNN不能并行处理的问题, 利用标签平滑, 解决训练集中标签不可靠性问题.
7)CAJLN[18].建立上下文和方面词的多种注意力机制, 获取特定的上下文表示, 与句子对隐藏特征联合学习.
8)FFLN消融模型.
(1)FFLN-GloVe.使用GloVe作为词向量嵌入.
(2)w/o AST.FFLN中缺少AST模块.
(3)w/o global.FFLN中缺少全局特征.
(4)w/o local.FFLN中缺少局部特征.
(5)position-weighted.将FFLN中SD的计算方式替换为位置权重(position-weighted)[9, 12].
position-weighted将距离定义为上下文和方面之间的单词数:
Vi=
其中, i表示单个词汇在上下文中的位置, m0表示方面词首次出现的位置.
本文采用准确率(Accuracy, Acc)和Macro-F1指标评价方法性能.
各方法在英文数据集上的实验结果如表3所示.
| 表3 各方法在英文数据集的实验结果 Table 3 Experimental results of different methods on English datasets |
由表3可知, FFLN在3个数据集上取得最优结果.在基于RNN的模型中, IAN、RAM、MGAN都运用注意力机制, 在Restaurant、Laptop数据集上, 效果依次提升, MGAN达到较优效果, 因为MGAN融合粗粒度注意力机制与细粒度注意力机制, 获取方面与文本间深层的意义, 更准确捕获方面的相关意见词, 证实注意力机制的有效性.ASGCN将图卷积网络应用到ASC任务中, 达到与MGAN相近的结果, 表明图卷积网络的作用.在非RNN模型中, AEN-BERT采用注意力编码网络获取隐藏特征, 取得不错结果.CAJLN基于BERT并通过多种注意力建立方面词和上下文的联系, 性能略差于AEN-BERT.FFLN和AEN-BERT一样, 使用注意力编码器获取输入的隐藏状态, 性能优于AEN-BERT.
由表3还可看出, 添加AST模块后, 模型效果有所提升, 说明加强方面词的信息对情感预测是有帮助的.缺失全局特征后, Acc下降约2%, 说明仅使用局部特征会损失信息, 而全局特征对于方面情感预测不可或缺.在缺失对局部特征提取的实验中, Acc降低1%~2%, 说明局部特征可帮助模型识别方面词的情感修饰词.相比position-weighted, 本文使用的语义距离可让模型完全保留距离方面词为α 个位置的特征, 更灵活.可通过调整α 值, 增加模型性能.此外, FFLN-GloVe效果远不如FFLN, 验证BERT可建立上下文与方面词之间的语义联系.
为了验证FFLN的普适性, 将其应用到中文评论数据集上进行实验.采用Acc和F1作为评价指标.
各方法在中文评论数据集上的实验结果如表4所示, 表中FFLN-GloVe表示使用通用词嵌入的模型.由表可看出, FFLN在Camera数据集上达到最优效果, 在另外三个中文数据集上, 接近于最优结果.中文评论数据集上的评论语句大多较简单, 因此BERT-SPC取得不错的效果, 相比FFLN-GloVe, 在2个指标上提升均超6%, 表明预训练模型强大的特征表示能力, 特别是在Notebook、Car数据集上, 因为这2个数据集较小, 更需要知识的补充.但是在中文数据训练集上, 37%以上的评价目标包含的字符至少为4个, 因此, 对多字符的评价目标的特征提取较重要, FFLN通过AST结构, 强化方面的信息, 并采用position-weighted模块, 获取与方面邻近的上下文特征.表4的实验数据表明这些策略的有效性.
| 表4 各方法在中文评论数据集的实验结果 Table 4 Experimental results of different methods on Chinese review datasets |
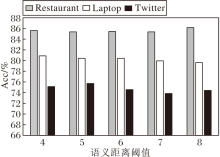
对于不同的英文数据集, 为了找到在FFLN上最佳的语义距离α , 进行一系列实验, 评估不同情况下效果最好的α .在对比实验中, 相应数据集的SD范围是4~8, 除了阈值α 以外, 所有的超参数都与FFLN一致.
α 不同时FFLN在3个英文数据集上的Acc值对比如图2所示.
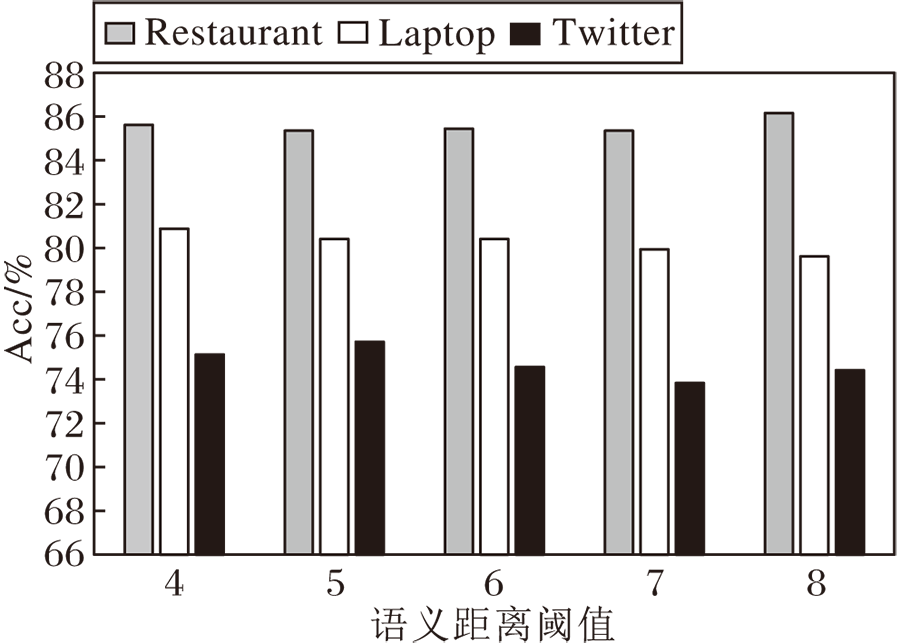 | 图2 α 不同时FFLN在英文数据集上的Acc值Fig.2 Acc value of FFLN with different α on English datasets |
由图2可看出, 不同的语义距离使FFLN在3个数据集上的性能有所波动, 因为不同领域的评论惯用的表达方式略有差异, 导致和方面相关的情感词的位置不同.在Restaurant数据集上, 随着α 值的增加, 效果逐渐提升, 最佳阈值为8.在Laptop、Twitter数据集上, Acc较早就达到最高值, 最佳阈值分别为4、5.
在英文数据集上进行一系列的实验, 评估AST层数对FFLN的影响.除了AST的层数以外, 所有的超参数都与FFLN一致, 具体结果如表5所示, 表中黑体数字表示最优结果.
| 表5 英文数据集上不同AST层的实验结果 Table 5 Experimental results of different AST layers on English datasets |
由表5可看出, 在Restaurant、Laptop数据集上, AST层数为1时效果最佳, 相比AST层数为2时, Macro-F1值提升约1%, 说明兼顾到数据集上类别样本不均衡的情况.在Twitter数据集上, AST层数为2时效果较优, 可能是因为该数据集上, 中性情感的训练数据数量达到总体的50%, 而中性情感容易让模型产生混淆, 那么通过AST强化方面词的信息就显得十分重要, 但是由于数据集整体还是较小, 在AST层数为3时, 模型没有能力拟合更复杂的情况.
针对方面级情感分类任务中存在的未有效利用方面信息、局部特征提取不充分的问题, 本文提出面向方面级情感分类的特征融合学习网络(FFLN).利用AST模块强化方面信息, 并融合方面局部特征和句子全局特征预测方面情感, 增加模型对方面信息的感知能力, 获取全面信息, 使模型可明确预测的目标, 提升情感分类效果.在英文数据集和中文评论数据集上, FFLN的性能明显提升, 验证FFLN的有效性.今后将考虑引入图卷积, 使模型融入语法知识, 提供更好的语义分析, 增强模型的理解能力.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|