


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于U-Net的特征交互分割方法
[孙君顶1, 2  , 惠朕堃
, 惠朕堃1 , 唐朝生1 , 毋小省1, 2 ]
, 惠朕堃, 唐朝生, 毋小省]
|
|



作者简介:

孙君顶,博士,教授,主要研究方向为图像处理、模式识别.E-mail:sunjd@hpu.edu.cn.

惠朕堃,硕士研究生,主要研究方向为医学图像分割.E-mail:923351352@qq.com.

唐朝生,博士,讲师,主要研究方向为医学图像处理.E-mail:tcs@hpu.edu.cn.
针对肝脏分割中存在误分割及小目标漏分割的问题,文中提出基于U-Net的特征交互分割方法,采用ResNet34作为主干网络.为了实现不同尺度间的非局部交互,设计基于转换器机制的特征交互金字塔模块作为网络的桥接器,获得具有丰富上下文信息的特征图.设计多尺度注意力机制替代U-Net中的跳跃连接,关注图像中的小目标,充分获取目标层的上下文信息.在公开数据集LiTS及3Dircadb和CHAOS组成的数据集上的实验证实文中方法能取得较好的分割效果.
About Author:
SUN Junding, Ph.D., professor. His research interests include image processing and pattern recognition.
HUI Zhenkun, master student. His research interests include medical image segmentation.
TANG Chaosheng, Ph.D., lecturer. His research interests include medical image processing.
To address the problems of mis-segmentation and missing segmentation of small targets in liver segmentation, a U-Net based feature interaction segmentation method is proposed using ResNet34 as the backbone network. To achieve non-local interactions between different scales, a transformer-based feature interaction pyramid module is designed as the bridge of the network to obtain feature maps with richer contextual information. A multi-scale attention mechanism is designed to replace the jumping connection in U-Net, considering the small targets in the image and sufficiently acquiring the contextual information of the target layer. Experiments on the public dataset LiTS and the dataset consisting of 3Dircadb and CHAOS demonstrate that the proposed method achieves good segmentation results.
本文责任编委 桑 农
Recommended by Associate Editor SANG Nong
肿瘤切除手术是治疗肝癌的常用手段, 在手术之前肝脏分割是手术中的重要步骤.传统的手动分割往往依赖于医生丰富的经验, 并且需要耗费大量的时间, 因此需要开发精确高效的肝脏自动分割方法.
针对图像分割问题, 研究人员进行大量有效工作.传统方法主要依赖图像的浅层特征, 受噪声和目标尺寸的影响较大, 无法满足高精度分割的需求[1, 2, 3].近年来, 随着深度学习技术研究的逐步深入, 卷积神经网络(Convolutional Neural Networks, CNN)在医学分割问题上得到广泛应用[4, 5, 6, 7].在这些方法中, 全卷积神经网络(Fully Convolutional Net-works, FCN)[8]将用于分类的全连接层替换为卷积层, 同时使用上采样确保特征图恢复为原图像大小, 解决像素级分类问题.
与FCN不同, Ronneberger等[4]提出U型网络(U-Net), 使用完全对称的编码器-解码器结构, 在编码器和解码器之间添加跳跃连接, 确保网络能得到编码器中不同尺度的特征, 获得较好的分割性能.尤其是针对医学图像领域内训练数据集较少的情况, U-Net依然能取得较优结果.鉴于U-Net的优良性能, 学者们提出多种改进模型[5, 6, 7].为了获取更深更抽象的语义信息及防止发生梯度消失问题, 残差连接U型网络(Residual Connection UNet, ResUNet)[5]和密集连接U型网络(Densely Connected UNet, Dense-UNet)[6]分别使用具有残差连接的残差模块(Res-block)[9]和密集连接的密集连接模块(Dense-block)[10]替换U-Net的每个子模块, 在解决梯度消失问题的同时得到网络更深层次的特征, 并使网络的训练变得更容易.为了增强网络对目标像素的敏感度, 注意力U型网络(Attention U-Net)[7]引入注意力机制, 提高网络精度.
此外, 在进行图像分割时, 往往采用上下文语义提高分割性能.如采用堆叠池化[11]、带有步长的卷积[12]或扩张卷积[13]等方法编码上下文语义, Lin等[14]采用特征金字塔网络(Feature Pyramid Networks, FPN)融合不同尺度语义信息, 获取更强的语义特征图.在此基础上, 受到非局部交互启发[15], Zhang等[16]提出特征金字塔转换(Feature Pyramid Trans-former, FPT), 设计3个转换器(Transformer), 使FPN的输出特征图实现不同尺度间的非局部信息交互.
虽然上述方法取得较好的分割效果, 但若肝脏图像中出现断裂区域时, 由于缺乏不同尺度间的非局部交互, 容易造成断开区域的背景被误检.其次, 小目标的分割难度较大, 如果只关注目标区域, 经验丰富的医生也很难识别这些目标.但如果考虑目标所在的背景, 根据背景中其它脏器的位置, 可较好地识别该目标.本文认为如果将小目标周围背景的上下文作为补充信息, 可更好地实现小目标的分割.
因此, 本文提出基于U-Net的特征交互分割方法(Feature Interaction U-Net, FIU-Net), 设计特征交互金字塔模块(Feature Interactive Pyramid Block, FIPB)和多尺度注意力机制模块(Multi-scale Attention Mechanism, MSAM).FIPB引入FPT中3个转换器[16], 建立不同尺度之间的非局部上下文语义联系, 同时融入图像全局信息, 得到具有丰富语义信息的特征图.MSAM设计一个简洁的U-Net代替原U-Net中的跳跃连接, 同时加入CBAM(Convolutional Block Attention Module)[17]注意力机制, 得到具有小目标周围丰富上下文且消除冗余信息的特征图.在LiTs数据集[18]及3Dircadb[19]和CHAOS[20]组成的数据集上进行实验, 结果表明本文方法能取得较好的分割效果.
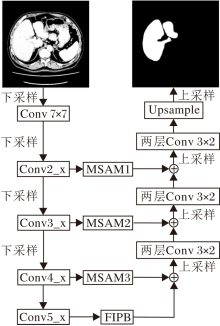
针对U-Net无法使跨越空间和尺度的信息进行交互且对较小目标难以检测的问题, 本文提出基于U-Net的特征交互分割方法(FIU-Net), 基本结构如图1所示, 图中Upsample表示最后一个上采样的操作.
 | 图1 FIU-Net结构图Fig.1 Structure of FIU-Net |
FIU-Net采用ResNet34作为编码器.图1中Conv 7× 7表示ResNet34中第1个7× 7的卷积, Conv2_x、Conv3_x、Conv4_x、Conv5_x分别表示ResNet34中4个模块.与ResNet34不同的是, FIU-Net将Conv5_x中的普通卷积替换为扩张率为2的扩张卷积, 目的是在增加感受野的同时保证特征图的尺寸是原图的1/16.经过编码器后的特征图送入FIPB模块, 使跨越空间和尺度的信息能进行交互, 输出的特征图和经过MSAM(MSAM1、MSAM2和MSAM3)变换的高层特征拼接, 拼接后的特征经过和U-Net相同的两层3× 2卷积进行降维和优化.
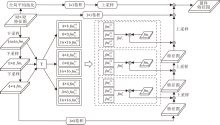
为了融合不同尺度下的特征, 基于FPT, 本文设计特征交互金字塔模块(FIPB), 结构如图2所示, 其中T表示3个转换器, 即渲染转换器(Rendering Transformer, RT), 接地转换器(Grounding Transformer, GT), 自转换器(Self-Transformer, ST).
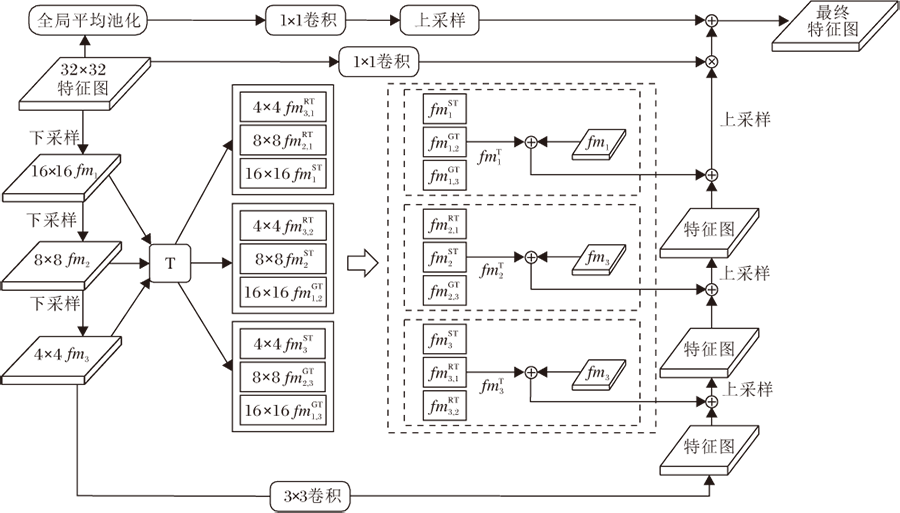 | 图2 FIPB结构图Fig.2 Architecture of FIPB |
首先, 从编码器输出的32× 32特征图依次经过卷积核大小为7× 7、5× 5、3× 3的卷积进行下采样, 得到特征图fm1、 fm2、 fm3.然后, 3幅特征图经过3个转换器处理, 共得到9幅特征图.将这9幅特征图进行特征重组, 拼接尺寸相同的特征图, 拼接后的特征图和尺寸对应的fm1、 fm2、 fm3分别进行拼接, 得到f
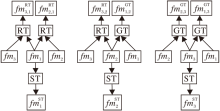
特征图fm1、 fm2、 fm3经过转换器的操作过程如图3所示.
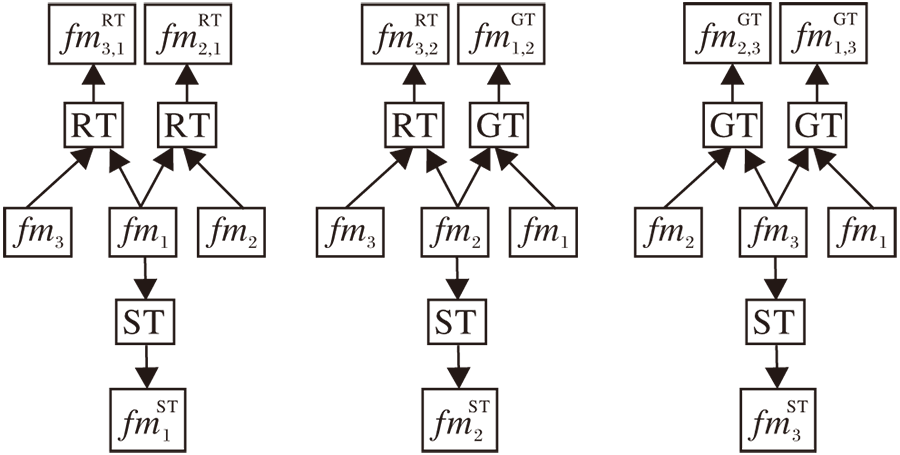 | 图3 转换器的操作过程Fig.3 Transformer operation process |
具体地说, fm1和 fm3、 fm1和 fm2经过RT得到f
U-Net中简单的跳跃连接可能会因为深度特征和浅层特征的语义差别过大而造成语义鸿沟的问题, 并且跳跃连接不足以学习到特征图中不同尺度的语义信息.为此, 本文设计多尺度注意力机制模块(MSAM).
在图1中, Conv2_x的输出结果经过MSAM1模块和解码器中对应层上采样后的特征图进行拼接操作, 之后采用和U-Net相同的两层3× 3卷积对融合不同尺度语义信息的上采样特征图进行降维和优化.Conv3_x和Conv4_x的输出经过MSAM2和MSAM3进行处理, 不同的是, MSAM1经过4次下采样, MSAM2经过3次下采样, MSAM3经过2次下采样.
MSAM1模块结构如图4所示, 具体如下.首先, 对来自编码器的特征图进行2次3× 3的卷积, 再采用2× 2的最大池化进行下采样, 下采样后的特征图经过一次3× 3的卷积进行优化, 重复此操作直到进行四次下采样, 将最后的特征图进行2次3× 3卷积后进行上采样, 上采样后的特征图和对应的编码器中经过CBAM注意力机制[17]的特征图进行拼接, 并使用一次3× 3的卷积降低通道.随后重复这样的操作, 直到得到最后的特征图.
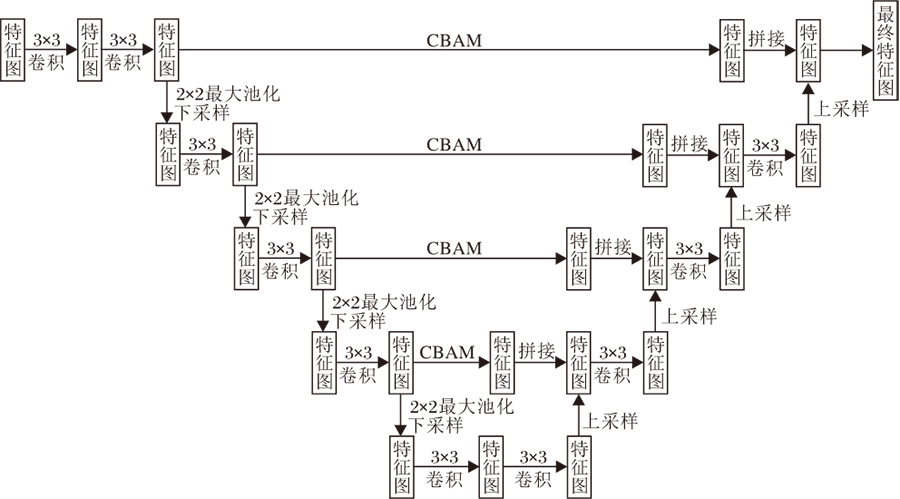 | 图4 MSAM1模块结构图Fig.4 Architecture of MSAM1 |
实验选择2个数据集:LiTs数据集[18]、3Dircadb数据集[19]和CHAOS数据集[20]的组合(简记为3D& C)数据集.LiTs数据集包含131组有标签的腹部电子计算机断层扫描(Computed Tomography, CT)图像和70组没有公开标签的腹部CT图像.3Dircabd数据集包含22组有标签的腹部CT图像, CHAOS数据集包括40组腹部CT图像(其中20组提供标签)及120组磁共振成像(Magnetic Resonance Imaging, MRI)图像.
实验时选择CHAOS数据集中提供标签的20组腹部CT图像和3Dircabd数据集中22组有标签的腹部CT图像组成3D& C数据集.
首先, 采用文献[21]的预处理方法对肝脏图像进行预处理.将肝脏的窗宽设为150, 窗位设为30, 之后将CT值转换为0~255的灰度值.腹部人体组织常用的窗宽窗位[22]如表1所示.
| 表1 腹部人体组织的常用窗宽窗位 Table 1 Common window width and window level of abdominal human tissue |
为了验证本文方法的性能, 采用分割模型中常用的评价指标Dice系数、准确率(Precision)和召回率(Recall)作为评价标准[23].
Dice系数定义为
Dice=
准确率和召回率定义为
Precision=
Recall=
其中, TP表示预测和标签全是正样本的数量, FP表示预测是正样本、但标签为负样本的数量, TN表示预测是负样本、但标签为正样本的数量.
实验选择Pytorch环境, 使用自适应矩估计(Adaptive Moment Estimation, Adam)优化器.GPU采用Nvidia GeForce RTX 2070S.
针对LiTs数据集, 将提供有标签的131组腹部肝脏图像平均分为5组, 每次将其中一组作为测试集进行训练, 重复5次.FIU-Net在LiTS数据集上的交叉验证结果如表2所示.
| 表2 FIU-Net在LiTS数据集上的交叉验证结果 Table 2 Results of cross-validation of FIU-Net on LiTS dataset % |
针对3D& C数据集, 同样将数据集上所有图像分为5组, 每次将其中一组作为测试集进行训练, 重复5次.FIU-Net在3D& C数据集上的交叉验证结果如表3所示.
| 表3 FIU-Net在3D& C数据集上的交叉验证结果 Table 3 Results of cross-validation of FIU-Net on 3D& C dataset % |
为了进一步验证本文的FIPB模块和MSAM模块的性能, 设计3组对比实验.同时对比去掉FIPB模块和MSAM模块的原网络(简记为原网络).
首先, 在LiTS、3D& C数据集上进行消融实验, 结果如表4所示.由表可看出, 在原网络分别加入FIPB模块和MSAM模块后, 指标值均有提升.将二者都加入到原网络(即FIU-Net)后, 指标值得到较大提升.
| 表4 消融实验结果 Table 4 Results of ablation experiment % |
其次, 为了验证MSAM模块的性能, 分别使用CBAM、选择性核网络(Selective Kernel Networks, SKNet)[24]、压缩和激励网络(Squeeze-and-Excita-tion Networks, SENet)[25]作为原网络的跳跃连接, 再将这些注意力机制分别加入MSAM结构中, 具体实验结果如表5所示.由表可看出, 相比直接使用这些注意力作为原网络的跳跃连接, 融合MSAM机制后取得更优性能.由表还可看出, 将CBAM加入MSAM后, 网络性能最优.
| 表5 注意力机制对方法性能的影响 Table 5 Effect of attention mechanism on method performance % |
最后对比FPN、FPT、FIPB对性能的影响. 在原网络分别加上FPN、FPT、FIPB进行对比, 结果如表6所示.由表可见, 原网络加入FIPB后, 网络性能最优.
| 表6 特征金字塔网络对方法性能的影响 Table 6 Effect of feature pyramid networks on method performance % |
实验中选择如下对比方法:U-Net[4]、ResUNet[5]、Attention U-Net[7]、嵌套U型网络(Nested U-Net, U-Net++)[26]、上下文编码网络(Context Encoder Network, CE-Net)[27]、密集特征选择U型网络(Dense Feature Selection U-Net, DFS U-Net)[28]、多尺度上下文嵌套U型网络(Multi-scale Context Nested U-Net, MSN-Net)[23].在LiTS数据集上的对比结果如表7所示, 由表可知, FIU-Net取得最优性能.
| 表7 各方法在LiTs数据集上的指标值对比 Table 7 Index value comparison of different methods on LiTs dataset % |
各方法在CT图像上的分割结果如图5所示.由图可见, 当目标尺寸较小时, 相比其它网络, FIU-Net不仅可较好地分割目标, 并且也较好地保留目标的边缘部分.当肝脏存在断开区域时, 对比网络会出现将断开区域误检为肝脏、断开区域的边缘会出现模糊的伪影、一部分肝脏区域被漏检的情况.在两个独立的肝脏区域且其中一个较小时, 对比网络往往会漏检较小的部分, ResUNet虽然未漏检, 但肝脏较小的部分也出现大量伪影并出现误检的情况.面对肝脏区域的边缘不规律的情况, 对比其它网络, FIU-Net可较好地保留边界的细节信息.
 | 图5 各方法在LiTs数据集上的分割结果对比Fig.5 Segmentation result comparison of different methods on LiTs dataset |
各方法在3D& C数据集上的指标值对比如表8所示.由表可知, FIU-Net取得最优结果.
| 表8 各方法在3D& C数据集上的指标值对比 Table 8 Index value comparison of different methods on 3D& C dataset % |
各方法在3D& C数据集上的分割结果如图6所示.由图6可知, 各方法在肝脏较小时都可较好分割肝脏, 但会出现背景被误分割为肝脏和伪影的情况.
 | 图6 各方法在3D& C数据集上的分割结果对比Fig.6 Segmentation result comparison of different methods on 3D& C dataset |
在肝脏存在断开且其中有一部分的尺寸很小时, 对比网络针对尺寸较小的部分容易漏分或分割不全.在肝脏出现多个独立目标时, FIU-Net能较好地分割图中3个独立的目标区域, 也能较好地分割最小的区域, 保留图像的边缘细节.
针对肝脏图像中因存在断开区域造成的误检及小目标漏检的问题, 本文提出基于U-Net的特征交互分割方法(FIU-Net).基于设计的特征交互模块, 建立不同尺度间的非局部交互.基于改进的多尺度注意力机制, 融合图像中的小目标信息和小目标周围上下文信息.在LiTS、3D& C数据集上的实验验证FIU-Net取得较好的分割效果.下一步将考虑在其它的脏器CT图像上进行实验, 测试本文方法在CT图像上的泛化能力.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|