







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于空洞卷积神经网络的噪声水平可调的高斯去噪方法
[金一凡1  , 余雷
, 余雷1 , 费树岷2 ]
, 余雷, 费树岷]
|
|



作者简介:

金一凡,硕士研究生,主要研究方向为视觉SLAM、深度学习、三维重建.E-mail:845646916@qq.com.

费树岷,博士,教授,主要研究方向为人工智能、非线性系统等.E-mail:smfei@seu.edu.cn.
基于深度学习的图像去噪方法在使用空洞卷积神经网络时,去噪后的图像容易在尖锐边缘生成伪像,并且为了处理不同的噪声水平,需要训练多个特定的去噪模型.对此文中提出基于空洞卷积神经网络的噪声水平可调的高斯去噪方法.加入噪声水平图,实现噪声水平可调性,并使用改善的空洞卷积及可逆的下采样技术,缓解由于传统空洞卷积带来的图像尖锐边缘的伪成像问题.将下采样的子图与相应的噪声水平图都输入到非线性映射模型中,并使用改善后的减小空洞率的神经网络进行训练.实验表明,文中方法在获得GPU加速的同时具有调节噪声水平的能力,能够改善尖锐边缘的伪像问题,保留更多图像细节.
About Author:
JIN Yifan, master student. His research interests include visual SALM, deep learning and 3D reconstruction.
FEI Shumin, Ph.D., professor. His research interests include artificial intelligence and nonlinear system.
Artifacts on sharp edges are easily generated when the dilated convolutional neural network(CNN) is utilized in the existing image denoising methods based on deep learning. Moreover, multiple specific denoising models are required to be trained to deal with different noise levels. Aiming at these problems, a Gaussian denoising method with tunable noise level based on dilated CNN is proposed. A noise level map is employed to make the noise level tunable. Besides, the improved dilated CNN and the reversible downsampling technology are employed, and thus the problem of artifacts on sharp edges caused by traditional dilated CNN is alleviated. The downsampled sub-images and corresponding noise level map are input into the nonlinear mapping model. Then, the model is trained by the improved CNN with the dilated rate reduced. Experiments show that the proposed method gains GPU acceleration and the ability of adjusting the noise level with the artifacts on sharp edges improved and more image details retained.
本文责任编委 郝志峰
Recommended by Associate Editor HAO Zhifeng
随着计算机视觉领域的飞速发展, 图像去噪技术在医学影像处理、摄像机成像、视频监控成像等方面的应用日益增多, 发挥越发重要的作用[1, 2, 3, 4, 5].图像去噪是典型的图像处理逆问题, 由于存在噪点, 无法直接求解该逆问题, 必须通过其它的额外条件信息.为了求解图像去噪问题, 从最早的设计滤波器[6], 发展到利用稀疏性约束图像[7], 再到利用模型对外部先验建模[8]等.以自适应加权中值滤波为例, 该方法属于空域去噪法, 本质上是使用快速傅里叶变换实现对图像的低通滤波[9].还有属于频域的小波去噪, 小波变换能根据信号特点和去噪的要求选择不同的小波基, 更好地保留图像的原始信息[10].虽然上述方法在一定程度上能达到良好的去噪效果, 但是传统方法需要人为调整参数, 在算法越来越复杂的情况下, 对其系统的优化将会耗费大量的人力计算成本, 并且不一定能得到最优解.
随着深度学习技术在计算机视觉领域的发展, 基于神经网络的去噪算法也获得较优性能[11, 12, 13, 14].Jain等[15]通过卷积神经网络(Convolutional Neural Network, CNN)训练一个模型作为约束器, 重塑去噪的结果, 实现端到端的图像去噪.Burger等[16]将多层感知器(Multilayer Perception, MLP)应用于模型中, 实现图像去噪, 效果较优.Mao等[17]提出卷积编码器网络, 利用反卷积和池化加深网络层数, 较好地提升模型性能.Chen等[18]提出可训练的非线性反应扩散模型(Trainable Nonlinear Reaction Diffu-sion, TNRD), 经过固定数量的梯度下降推理步骤后, 将其表示为一个前馈深层网络, 表现出较好的图像去噪效果.Zhang等[19]提出去噪卷积神经网络(Denoising CNN, DnCNN), 在图像去噪领域实现批量归一化(Batch Normalization, BN)和残差学习结合的优化训练.考虑到单纯的加深神经网络的层数并不能获得期望的优化效果, Lefkimmiatis等[20, 21]结合局部和非局部自相似性, 作为先验信息添加到深度学习的神经网络中, 得到更好的图像去噪模型.
真实生活中产生的噪声不仅限于实验仿真中的加性高斯白噪声(Additive White Gaussian Noise, AWGN), 往往更加复杂多变.Guo等[22]提出快速灵活的去噪卷积神经网络(Fast and Flexible Denoising CNN, FFDNet)[23], 训练具有盲去噪能力的盲去噪网络(Convolutional Blind Denoising Networks, CBD-Net), 应对真实场景中产生的各种噪声.
上述方法大多取得良好的去噪效果, 但还存在诸多不足, MLP、TNRD都是使用单个模型应对特定噪声水平, 在面对不同的噪声水平时, 需要使用不同的去噪模型.采用空洞神经网络的模型, 更会导致图像去噪后在尖锐边缘处产生伪像的问题.因此, 本文提出基于空洞CNN的噪声水平可调的高斯去噪方法.在噪声图像输入后, 加入一幅与之匹配的噪声水平图, 一同输入非线性映射部分, 减少空洞卷积时的空洞率.使用可逆的下采样技术, 在不增加参数和网络层数的情况下, 扩大卷积核的感受野, 获取更好的背景信息.每个空洞卷积层后都连接有修正线性单元(Rectified Linear Unit, ReLU)或批量归一化模块, 并与自适应矩估计(Adaptive Moment Estimation, Adam)优化器相互配合.由于网络层不深, 因此未使用残差学习.在训练模型的同时, 获得较快的收敛速度, 提高效率.最后在BSD68、Set12数据集上的实验表明, 本文方法在利用硬件GPU加速支持的同时, 能实现单个模型处理不同噪声水平的去噪问题, 具有较快的运行时间和较好的噪声水平可调性.
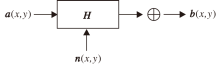
图像去噪属于图像恢复的一种, 本质上就是还原已退化的图像.图像质量退化的原因是多方面的, 包括:射线辐射、大气湍流造成的照片畸变, 镜头对焦不准而产生的散聚焦模糊, 成像系统中存在噪声干扰, 成像系统的像差、非线性畸变、有限带宽等.图像的退化过程如图1所示.
 | 图1 图像退化过程Fig.1 Process of image degradation |
在图1中, a(x, y)表示原始的二维图像, 在经过系统H并加入噪声n(x, y)后, 生成一幅退化的带有噪声的图像b(x, y).该过程可写为
b(x, y)=Ha(x, y)+n(x, y).
图像恢复的目的在于通过退化的图像b复原清晰图像a, 使用v表示标准偏差为σ 的加性高斯白噪声, H为退化矩阵.
a=F(b, H, v).
图像噪声的类型大致分为4种:加性噪声、乘性噪声、量化噪声、椒盐噪声.构建的噪声模型更是多样的, 包括高斯噪声、泊松噪声、脉冲噪声、均匀噪声等.高斯噪声模型是最常用的噪声模型, 由于分布规律的特性更容易进行数学分析, 若随机变量x满足高斯噪声分布, 那么它的概率密度函数为
p(x)=
其中, x表示图像的灰度值, μ 表示x的期望值或均值, σ 表示x的标准偏差.
图像去噪方法是多样的, 如卡尔曼滤波、神经网络、盲图像复原等.本文旨在利用非线性的神经网络, 在退化的图像的基础上, 根据一定的先验知识, 通过CNN训练反向的退化模型, 恢复原始的清晰图像.当似然已知时, 从贝叶斯的角度上看, 图像先验建模在图像去噪的过程中, 具有重要作用.为了获得原始图像a的解, 需要解决最大后验问题:
其中, lg p(b|a)表示b的对数似然性, lg p(a)传递a的先验值.为了解决这一问题, 大多数去噪方法都将上述等式改写成
其中:Φ (a)为正则项, 与图像先验相关; λ 为权衡参数, 控制保真度项和正则项之间的平衡, 当它过小时, 噪声无法去除干净, 过大会导致过分去噪而使图像损失原有的细节.式(1)能使噪声水平为σ 的保真度项
一般来说, 可使用基于模型的优化方法或判别式学习方法求解方程.例如, 基于块匹配的3D协同滤波(Block Matching and 3D Collaborative Filtering, BM3D)[24]和加权核范数最小化(Weighted Nuclear Norm Minimization, WNNM)[25]等都是典型的基于模型的方法, 可灵活处理各种水平的噪声问题, 但同时也存在明显的不足之处.一方面, 这些方法使用的手工制作的图像先验不足以表征复杂的图像结构.另一方面, 这些方法通常很耗时.而MLP和基于CNN的DnCNN等属于判别式方法, 旨在从退化图像和真实图像对的训练集中学习快速推断结果的能力, 并且DnCNN已具有强大的去噪能力.
Zhang等[26]利用半二次分裂(Half Quadratic Splitting, HQS)将保真度项和正则项进行解耦, 引入变量x=a将式(1)的问题改写成
(x=a)⇒ Lμ (a, x)=
其中, μ 为一个惩罚参数, 以非降序反复变化, 并通过迭代的方式将保真度项和正则化项独立成2个子问题, 得到方程的解:
ak+1=
在实现图像去噪的基础上, 将其集成到模型优化方法中, 解决其它逆问题, 如图像去模糊和单图像超分辨率.
本文为了实现更好的图像高斯去噪, 通过优化算法, 将式(1)定义为一个新的隐式函数:
其中, 将权衡参数λ 吸收进参数σ , 在这种情况下, σ 起到控制保真度项和正则项之间的平衡的作用, 即控制去噪程度和对原图像细节保留的权衡.
值得注意的是, 式(2)中的b和σ 存在维度不匹配的问题, 因此无法将它们直接引入CNN框架中.Zhang等[23]将噪声水平σ 扩展为噪声水平图M, 解决维度不同的问题.因此, 式(2)可进一步改写为
(σ |→ M)⇒
值得一提的是, 在引入噪声水平图M的同时, 本文对系统的输入图像进行可逆的下采样处理, 两者组合构成CNN中非线性映射部分的输入:
其中x表示下采样生成的子图像.采用下采样的目的是缓解空洞卷积产生的尖锐边缘的伪像问题.
为了训练具有良好去噪性能的模型, 在使用多层深度CNN的同时, 由于硬件性能的限制, 必须考虑整个模型在训练时需要的计算资源与损耗.最直接的方式就是减少卷积的数量和层数, 但会大幅影响整个模型的性能.因此考虑在不进一步增加网络层数的前提下, 使用空洞卷积扩大感受野, 在一定程度上提高模型的去噪能力.
但是, 直接使用空洞卷积训练神经网络会使训练好的模型在去噪时不能较好地保留原图细节, 去噪后的图像在尖锐边缘处会生成伪像[19, 22, 26].空洞卷积虽然在模型进行特征提取时能增大感受野, 但对像素点的操作是间隔式的, 可能这样的间隔方式使最终去噪后的图像存在边缘处的伪成像的问题.
为了解决这一问题, 本文尝试减小卷积的空洞率, 并使用可逆的下采样技术承担一部分扩大感受野的任务.使用的空洞率小于其它模型, 因此在提取特征时的间隔更小, 带来的负面影响也更小, 这在一定程度上可缓解边缘的伪成像问题.同时, 使用可逆的下采样技术, 相当于变相扩大感受野, 可在保证模型去噪能力的同时提高运行速度.
需要指出的是, 采用判别式学习方法代替手动设计的管道以实现自动先验基础颜色图像, 可加快运算速度, 节省时间.与此同时, 考虑到性能以及需要判别彩色图像的先验建模, 选择使用深度CNN学习判别式去噪模型, 原因如下:首先, CNN可利用图形处理器(Graphics Processing Unit, GPU)强大的并行运算能力, 提高学习效率.其次, CNN具有先验建模的能力和较深的网络构架, 能获得抽象的特征信息.最后, 随着计算机技术的飞速发展, CNN不断进步并取得许多成果, 有助于本文的图像处理.
为了能在获得快速性的同时, 保证模型处理不同噪声水平的图像具有较好的稳定性, 本文使用判别式的空洞CNN去噪模型[27], 框架如图2所示.整体过程如下:输入一幅带有高斯噪声的图像, 重塑为四幅子图像, 并加入相应的噪声水平图, 在进行一系列的非线性变换后输出四幅去噪后的子图像, 重塑为一幅清晰的去噪图像.
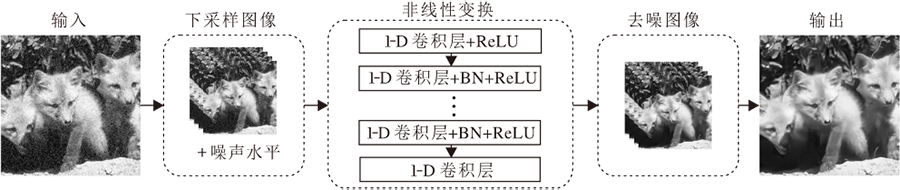 | 图2 判别式的空洞CNN去噪模型框架图Fig.2 Framework of discriminant dilated CNN denoising model |
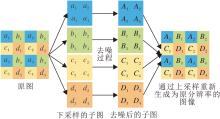
在输入一幅噪声图像后, 使用可逆的下采样方式, 如图3所示, 将原尺寸为H× W× C的输入图像改为4个尺寸为(H/2)× (W/2)× 4C的下采样子图像, 以便在去噪完成后, 使用上采样将低分辨率的子图重新还原为原始分辨率H× W× C.这样做的好处是, 对更小分辨率的子图进行去噪时可在减少网络参数的同时增大感受野, 使网络效率更高.C表示通道数, 对于灰度图像, C=1, 对于彩色图像, C=3.
 | 图3 下采样-上采样示意图Fig.3 Sketch map of downsampling-upsampling |
设可调噪声水平映射为M, 对于噪声水平为σ 的加性高斯白噪声(AWGN), M表示所有元素均为σ 的均匀映射.将下采样的子图像和可调噪声水平映射M组合后形成为一个(H/2)× (W/2)× (4C+1)的张量
将张量
 | 图4 完整的非线性映射过程结构图Fig.4 Structure of complete nonlinear mapping process |
具体来说, 第一层由一个空洞卷积层加一个ReLU构成, 中间五层由空洞卷积层、批量标准化及ReLU构成, 最后一层是一个单独的空洞卷积层.
在CNN的网络层中, 为了能更好地重建已损坏的像素, 背景信息起到很大作用.为了更好地追踪背景信息, 必须扩大感受野, 通常有2种方法:增加滤波器的尺寸和增加卷积层的深度.然而, 单纯的增加滤波器尺寸会引入过多参数, 导致模型更复杂, 运算量的增加必然也会导致模型运行缓慢.与此同时, 3× 3的滤波器已在CNN的网络设计中得到普及, 在此基础上, 利用空洞卷积可在增大感受野和增加网络深度之间进行权衡.因此, 使用空洞卷积, 在保留3× 3滤波器优势的同时又能增大感受野, 捕捉更好的背景信息.
为了缓解产生的尖锐边缘伪像效应, 在卷积前使用可逆的下采样方式, 并将空洞率分别设置为较小的1, 1, 2, 3, 2, 1, 1.简单来说, 一个尺寸为3× 3、空洞率为n的空洞卷积层, 可理解为大小为(2n+1)× (2n+1)的稀疏滤波器, 其中只有9个固定位置的输入可以是非零的.换句话说, 针对n=1, 2, 3的情况, 每个对应卷积层的有效感受野分别为3, 5, 7.
虽然一些梯度优化算法已能加快神经网络的训练并提高性能, 但是结构框架的设计也具有重要作用.为了能更快地训练CNN, 本文使用BN, 最终输出[28]如下:
y(k)=γ (k)
当得到归一化的
经验表明, 在网络层并不是很深时, 使用改进的 CNN训练和ReLU、BN及Adam的组合也能较好地训练无残差学习的网络.因此, 本文将不采用BN与残差学习的组合方法.
本文使用400幅180× 180的图像训练网络模型.为了在已知噪声水平下实现高斯去噪, 主要考虑5个噪声水平, 即σ =5, 15, 25, 35, 50.针对高斯去噪模型, 使用较大图像数量的数据集只会带来很小的改善, 因此本文选择数量较适宜的400幅.
针对训练好的灰度图像去噪模型, 本文使用BSD68、Set12数据集开展去除AWGN的实验.BSD68数据集是包含Berkeley分割的数据集, 本文选择这个数据集测试训练好的网络的性能.Set12数据集广泛用于测试图像的集合.
对于训练好的彩色图像去噪模型, 本文使用CBSD68、Set14数据集进行高斯去噪实验.CBSD68数据集是BSD68数据集的彩色版本, Set14数据集是图像处理中常用的测试数据集.
训练时需要将AWGN加入到原有图像中, 以此生成对应的训练集.选择使用AWGN:一方面, 因为现实世界的噪声与本地化的AWGN十分近似; 另一方面, 在噪声源无先验信息的情况下, AWGN可看作一种自然选择.
针对灰度图像和彩色图像的模型, 分别设置补丁为40× 40和60× 60, 并裁剪128× 1 600个补丁以训练网络.将噪声水平σ ∈ [0, 50]的AWGN加入干净的补丁中, 得到具有噪声的补丁, 因此, 噪声水平图是一致的.
本文使用Adam优化器, 通过最小化如下损失函数优化网络结构:
l(Θ )=
Adam的具体设置如下:
β 1=0.9, β 2=0.999, α =0.01, ε =10-8,
权值衰减为0.000 1.模型的批大小为128, 进行300个迭代周期.在网络训练前, 将学习率设置为10-3, 在训练误差不再减小时降低学习率为10-4, 降低学习率后训练误差会继续减小.
本次网络的训练是在Matlab(R2018a)环境中进行的, 使用MatConvNet包.计算机搭载Intel(R) Core(TM) i7-9700KF CPU 3.60 GHz和NVIDIA的RTX 2080 Super GPU.
本节利用训练好的模型进行大量的去除AWGN实验.由于本文训练的模型具有噪声水平可调的性能, 因此以下实验在分别处理灰度图像和彩色图像时都使用单个去噪模型.
一般地, 对于一幅去噪图像, 评判其质量好坏通常有两个方面, 即主观评价和客观评价.主观评价充分参考人本身的视觉特性, 通过人眼反映的主观感受对图像质量进行客观化表达, 国际上有ITU-T Recommendation P.910等标准, 但操作复杂、消耗大量人力及时间.因此一般采用客观评价, 通过建立数学模型实现对图像质量的评价.
选用的客观评价指标有均方误差(Mean-Square Error, MSE)、峰值信噪比(Peak Signal to Noise Ratio, PSNR)、结构相似度(Structural Similarity, SSIM).
MSE表示真实图像和失真图像的差异, 可评价相对失真程度:
MSE=
其中, l、w表示图像长、宽的像素格数量, f(i, j)表示真实图像在点(i, j)处的像素值, f'表示失真图像.MSE值越大, 差异越大; 否则, 差异越小, 越接近真实图像.
PSNR可理解为背景噪声对信号的破坏程度, 以MSE为基础, PSNR可表示为
PSNR=10lg〔
其中L表示图像中像素最大的值.PSNR值越大, 说明噪声对信号干扰越小, 图像的失真程度也越小; 否则, 说明图像严重失真.
SSIM在超分辨率和图像去模糊中得到广泛应用, 主要基于真实图像和失真图像两者间的3个方面的对比.
为了方便与其它方法对比, 本文主要使用PSNR作为评价去噪后图像质量好坏的标准.
使用训练好的模型, 分别在BSD68、CBSD68、Set12、Set14数据集上进行去噪实验.由于模型的可调性, 针对σ =5, 15, 25, 35, 50噪声水平进行灰度图像和彩色图像的去噪实验.
BSD68、CBSD68数据集上单幅图像的去噪结果如图5所示, 噪声水平为σ =25.以PSNR和SSIM表示模型性能.
 | 图5 灰度图像和彩色图像的高斯去噪结果Fig.5 Denoising results of grayscale and color images |
本文方法在BSD68、Set12、CBSD60、Set14数据集上进行高斯去噪实验的PSNR平均值如表1所示.由表可见, 针对灰度数据集和彩色数据集, 本文方法分别使用单个去噪模型进行大量的实验仿真.这表明本文方法能训练具有噪声水平可调的高斯去噪模型.
| 表1 本文方法在4个数据集上的PSNR平均值 Table 1 Average PSNR values of the proposed method on 4 datasets dB |
针对模型的去噪能力, 选择如下对比方法:MLP[16]、TNRD[18]、BM3D[24]、CBM3D(Color Version of BM3D)[24]、WNNM[25]、图像恢复卷积神经网络(Image Restoration CNN, IRCNN)[27]、基于边缘增强的深度网络(Deep Network Based on Edge Enhance-ment, EEDN)[29]、神经网络卷积(Neural Network Con-volution, NNC)[30]、梯度先验辅助卷积神经网络(Gradient Prior-Aided CNN, GPADCNN)[31].
各方法在BSD68灰度数据集上去噪后的PSNR值如表2所示, 表中黑体数字表示最优结果.由表可看到, 本文方法在3种不同级别的噪声上均取得最好的去噪效果.这说明使用本文方法能提高去噪图像的PSNR值, 在一定程度上表明本文方法有助于改进灰度图像的去噪问题.
| 表2 各方法在BSD68数据集上的PSNR平均值 Table 2 Average PSNR values of different methods on BSD68 dataset dB |
各方法在CBSD68彩色数据集上去噪后的PSNR指标值如表3所示, 表中黑体数字表示最优结果, CBM3D是BM3D针对彩色图像的模型.本文方法在面对不同的噪声水平时都能获得较好的去噪效果, 在噪声水平较高时更明显.但在面对较低的噪声水平, 如σ =15时, 虽然也能取得较满意的结果,
| 表3 各方法在CBSD68数据集上的PSNR平均值 Table 3 Average PSNR values of different methods on CBSD68 dataset dB |
但效果不如IRCNN和GPADCNN.这是深度学习在训练过程中保证全局最优的一种选择.总之, 本文方法在面对彩色图像的去噪问题时, 也能取得较为可观的PSNR值, 有助于改善彩色图像的去噪问题.
从定量分析的角度上看, 本文方法具有一定的竞争力, 因为在与当前效果较好的算法对比时, 都取得优异的结果.但也有一些研究表明, PSNR评判的标准往往会忽略更广泛的视觉感知层面的理解, 导致评判标准和人眼的直观感受有一定的出入.因此, 为了验证本文方法在去噪方面带来的的真实感受, 下面将进一步进行定性分析.
为了使对比更具说服力, 在进行客观评价的同时, 以另一种可视化的方式直观感受不同方法的去噪结果带来的差异性.
BM3D和本文方法在BSD68、Set12灰度图像数据集上的去噪效果对比如图6和图7所示, 图6中σ =25, 图7中σ =50.由图可明显看出, 相比BM3D, 本文方法在对图像去噪后, 结果更清晰, 事物周围的环境没有被模糊化.局部放大后可看出, 本文方法保留原图的细节部分, 如狼的面部细节和毛发质感及蝴蝶翅膀上的花纹纹路等.
 | 图6 两种方法在BSD68数据集上的去噪结果Fig.6 Denoising results of 2 methods on BSD68 dataset |
 | 图7 两种方法在Set12数据集上的去噪结果Fig.7 Denoising results of 2 methods on Set12 dataset |
CBM3D和本文方法在CBSD68、Set14彩色图像数据集上的去噪结果如图8和图9所示, 图8中σ =25, 图9中σ =50.
 | 图8 两种方法在CBSD68数据集上的去噪结果Fig.8 Denoising results of 2 methods on CBSD68 dataset |
 | 图9 两种方法在Set14数据集上的去噪结果Fig.9 Denoising results of 2 methods on Set14 dataset |
由图8和图9可见, 本文方法体现明显的优势的地方也同样是去噪图像的清晰度.不论是云朵还是花朵上的斑点部分, 相比CBM3D, 本文方法都能恢复图像原有的细节.这说明对输入的噪声图像使用可逆的下采样并采用改进的空洞卷积能在一定程度上缓解边缘的伪像问题, 获得视觉感知上更清晰的去噪结果.
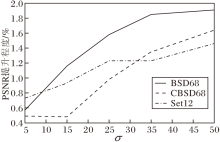
总之, 在去噪能力方面, 本文方法获得更可观的结果.不论是以PSNR为客观评价指标的定量分析, 还是直观可视化的定性分析, 本文方法都展现出更具竞争力的去噪结果.以BM3D/CBM3D为基准, 本文方法在BSD68、CBSD68、Set12数据集上不同噪声水平下的PSNR提升百分比如图10所示.
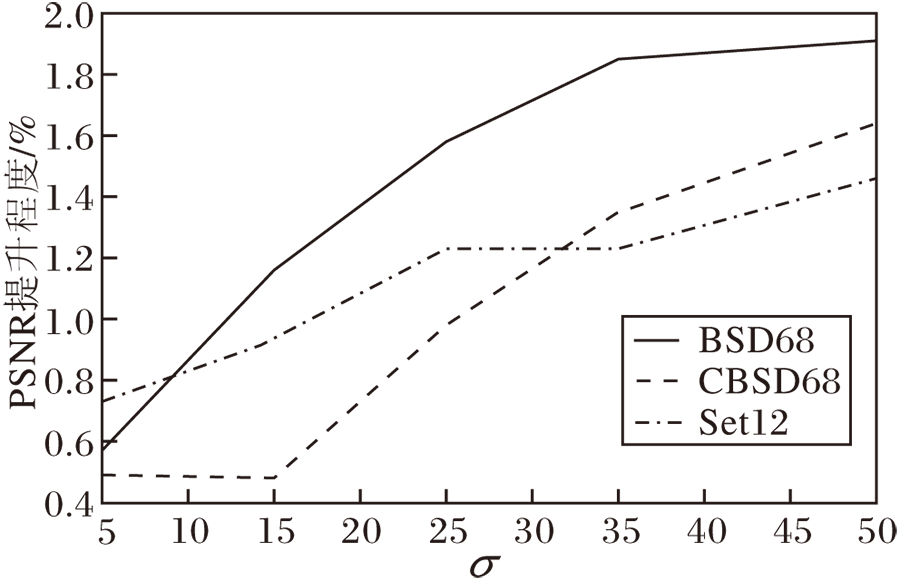 | 图10 本文方法对比BM3D/CBM3D的平均PSNR提升百分比Fig.10 Improvement percentage of average PSNR of the proposed method compared with BM3D/CBM3D |
在模型具有较可观的去噪能力后, 进一步对比模型去噪的运行时间.本文方法、BM3D、CBM3D的运行时间如图11所示, 针对256× 256、512× 512、1024× 1024尺寸, 分别在灰度图像与彩色图像上测试方法的运行时间.
 | 图11 不同方法的图像去噪运行时间对比Fig.11 Running time comparison of different methods for image denoising |
需要说明的是, BM3D/CBM3D只能在CPU上进行运算, 而本文方法采用CNN结构, 可得到GPU硬件的支持, 获得更快的运行速度.如果不使用GPU加速, 本文方法的运行时间和BM3D/CBM3D相近, 甚至在大多数情况下比BM3D/CBM3D更耗时.
不过, 正是因为GPU加速运算的独特优势, 使用CNN结构训练的图像去噪模型更具竞争力, 由图11可看出, 在使用GPU加速后, 本文方法的运行速度远超过BM3D/CBM3D.
综上所述, 通过去噪性能的定量分析与定性分析及运行时间的对比可看出:本文方法在使用GPU加速功能的同时, 具有噪声水平可调的功能, 在图像去噪时能得到更可观的PSNR值.在可视化的结果图中也能看到去噪图像较好地保留原图像的细节部分, 改善尖锐边缘的伪像问题.
本文提出基于空洞CNN的噪声水平可调的高斯去噪方法.首先, 加入一幅噪声水平图, 使其与噪声图像一同输入到非线性映射部分, 获得噪声水平可调的能力.然后, 使用可逆的下采样技术并减少空洞卷积时的空洞率, 在不增加参数和网络层数时, 扩大卷积核的感受野, 提高网络效率.对比实验表明, 本文方法在利用GPU加速运行的同时具有可调噪声水平的能力, 获得更高的PSNR值, 并较好地保留原图像的细节部分, 缓解生成伪像的问题.本文方法在面对较低的噪声水平时性能不如IRCNN和GPADCNN, 如何使其对各种噪声水平具有更高的宽容度是今后的研究方向.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|