
{kind=link}
{kind=link}
{kind=link}
基于潜层向量对齐的持续零样本学习算法
[钟小容1  , 胡晓
, 胡晓2 , 丁嘉昱1 ]
, 胡晓, 丁嘉昱]
|
|



作者简介:

钟小容,硕士研究生,主要研究方向为计算机视觉、零样本学习.E-mail:2112007067@e.gzhu.edu.cn.

丁嘉昱,硕士研究生, 主要研究方向为人工智能、计算机视觉、零样本学习.E-mail:386315953@qq.com.
在持续学习多任务过程中,持续零样本学习旨在积累已见类知识,并用于识别未见类样本.然而,在连续学习过程中容易产生灾难性遗忘,因此,文中提出基于潜层向量对齐的持续零样本学习算法.基于交叉分布对齐变分自编码器网络框架,将当前任务与已学任务的视觉潜层向量对齐,增大不同任务潜层空间的相似性.同时,结合选择性再训练方法,提高当前任务模型对已学任务判别能力.针对不同任务,采用已见类视觉-隐向量和未见类语义-隐向量训练独立的分类器,实现零样本图像分类.在4个标准数据集上的实验表明文中算法能有效实现持续零样本识别任务,缓解算法的灾难性遗忘.
About Author:
ZHONG Xiaorong, master student. Her research interests include computer vision and zero shot learning.
DING Jiayu, master student. His research interests include artificial intelligence, computer vision and zero shot learning.
Continual zero-shot learning aims to accumulate the knowledge of seen classes and utilize the knowledge for unseen classes recognition. However, catastrophic forgetting can easily occur in continual learning. Therefore, a continual zero-shot learning algorithm based on latent vectors alignment is proposed. Based on the cross and distribution aligned variational auto-encoder network, the visual latent vectors of current tasks and learned tasks are aligned to enhance the similarity of latent space of different tasks. Selective retraining is adopted to improve the discrimination ability of the current task model for learned tasks. For different tasks, the independent classifiers are trained with visual-hidden vectors of the seen classes and semantic-hidden vectors of the unseen classes to achieve zero-shot image classification. Extensive experiments on four standard datasets show that the proposed algorithm completes the continual zero-shot recognition task effectively and alleviates the catastrophic forgetting.
本文责任编委 高阳
Recommended by Associate Editor GAO Yang
现有监督学习算法利用大规模、强标记的数据拟合神经网络模型, 在图像处理领域取得显著进展.然而, 随着新类别的不断涌现, 收集大量带标签的新类别样本需要耗费大量的时间及精力.
为了解决监督学习算法的局限性, 零样本学习(Zero Shot Learning, ZSL)[1, 2]获得广泛关注.ZSL旨在依据类别的语义特征, 将训练集中学习的已见类知识转移到测试集的未见类上, 识别未见类样本.在ZSL中, 测试集合只包含未见类样本.然而在现实世界中, 数据往往是以长尾分布的形式存在, 即头部(已见类)数据比尾部(未见类)数据更常见.因此, 学习可同时识别已见类样本和未见类样本的算法更具有现实意义.为此, 研究者们引入更具挑战性的广义零样本学习(Generalized ZSL, GZSL)[3, 4, 5, 6].
深度学习(Deep Learning, DL)[7]的发展促进ZSL的发展.其中, 嵌入方法[3]和生成方法[4, 5, 6]均有效解决单一任务的零样本学习任务.具体地说, 嵌入方法通过学习映射函数, 联系视觉特征和语义特征, 识别未见类样本.生成方法旨在借助具有判别性的语义特征辅助生成模型, 如变分自编码器(Variatio-nal Auto-Encoder, VAE)[8]或生成对抗网络(Gene-rative Adversarial Networks, GAN)[9], 生成未见类的视觉特征, 解决ZSL在训练阶段中未见类视觉特征缺失的问题.上述方法在解决特定任务的零样本分类问题上具有较优的识别性能.然而, ZSL不具备持续学习能力, 即学习完单一任务后, 学习过程终止.为了应对现实中持续到来的新任务, ZSL需要借助持续学习算法的优势, 在多任务中持续学习新知识, 并有效识别不同任务的未见类样本.
为了提高ZSL的多任务泛化能力, Wei等[10]提出持续学习(Continual Learning, CL)[11, 12, 13, 14, 15, 16, 17]与ZSL结合的持续零样本学习(Continual ZSL, CZSL)[18, 19, 20], 即通过持续学习多个零样本学习任务过程中积累的已见类知识, 识别所有任务的未见类样本.然而, CZSL要不断学习记忆多任务知识, 这通常会引起算法的灾难性遗忘[21, 22], 即算法因新任务知识的载入而干扰对已学任务知识的记忆, 甚至完全遗忘已学任务知识.灾难性遗忘容易导致算法偏向于最近学习的任务, 降低算法的综合识别率.
为了有效缓解CZSL面临的灾难性遗忘, Chaudhry等[18]提出基于平均梯度情景记忆方法(Averaged Gradient Episodic Memory, A-GEM), 约束各个任务模型的优化方向, 缓解遗忘问题.Chandan等[19]提出经验重放策略, 将已学任务数据和新任务数据一起训练模型, 促使模型重复记忆已学任务数据.然而, 此策略容易引发模型的过拟合问题.Ghosh等[20]利用生成模型, 为已学任务生成重放样本, 同时结合动态体系结构, 为不同的任务构建不同的记忆空间, 提高模型的泛化能力.
然而, 生成数据并不能有效替代原始数据的表达, 故模型性能仍受到限制.Wei等[10]提出知识蒸馏策略, 旨在通过约束相邻任务在潜层空间高斯分布的约束减小任务之间数据分布的差异性, 提高模型的多任务泛化能力.此方法虽然取得一定成效, 却忽略潜层空间中同样具有表达输入特征分布能力的隐向量[8]约束, 导致方法在约束潜层空间分布上略显不足.并且, 在训练分类器阶段, 由于样本的视觉空间和语义空间存在明显的域差异[23], 采用已见类和未见类的语义特征训练分类器, 容易使分类器难以全面学习样本的视觉信息, 进而在测试阶段, 分类器在识别已见类视觉样本和未见类视觉样本过程中性能难以提升.
针对上述算法的不足之处, 本文提出基于潜层向量对齐的持续零样本学习算法, 用于强化模型在不同任务上的知识传递能力.在潜层空间中将当前任务模型与已学任务模型的潜层向量进行对齐, 加强不同任务潜层空间的相似性, 缓解灾难性遗忘.利用已见类视觉特征和未见类语义特征联合训练分类器, 促使分类器学习有关已见类样本的视觉信息, 提高分类器的综合识别能力.在4个标准数据集上的实验表明本文算法的有效性.
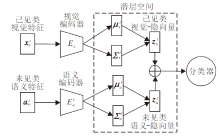
本文提出基于潜层向量对齐的持续零样本学习算法, 网络架构及训练过程如图1所示.假设当前学习任务为t, 首先, 采用交叉分布对齐变分自编码器(Cross and Distribution Aligned Variational Auto-Encoder, CADA-VAE)[8], 为视觉模态特征和语义模态特征构建统一的潜层分类空间.其中, 视觉编码器
 | 图1 本文算法的网络架构和训练过程Fig.1 Network architecture and training process of the proposed method |
在当前任务t中, 训练集包含已见类数据
及未见类数据
其中, X
GZSL的目的是学习识别未见类和已见类数据的分类器, 即f
针对不同任务, 本文将对不同的任务构建独立的分类器, 对每个任务进行广义零样本分类.
CADA-VAE[8]是本文的主要网络框架.CADA-VAE包含两组VAE, 每个VAE遵循编解码结构范式, 如图1所示.编码器将特征x编码为均值为μ 和方差为Σ 的高斯分布, 再利用参数化技巧[8]从高斯分布中采样, 得到隐向量z.解码器将z表示为x的概率分布.假设编码器qθ (z|x)、解码器pϕ (x|z)分别是以θ 和ϕ 为学习参数的神经网络, VAE的损失函数表示为对数似然函数的变分下界:
LVAE=
其中, 第1项是特征重构损失, 第2项是Kullback- Leibler散度, 促使后验概率qθ (z|x)与先验概率p(z)尽可能相似, p(z)=η (0, 1), λ 为超参数, t为当前任务.
针对GZSL存在两种不同的模态特征, 本文采用两组VAE分别处理视觉模态特征和语义模态特征.故总的VAE损失为
LVAE=
其中,
VAE构建视觉模态特征和语义模态特征的共享潜层空间.然而, 视觉特征和语义特征存在域差异[23], 为了对齐相同类别不同模态特征, 本文采用交叉对齐方法(Cross Alignment, CA)和分布对齐方法(Distribution Alignment, DA).CA旨在将特定模态的隐向量通过其它模态的解码器重构原始特征.交叉对齐损失为
LCA=|at-
其中, t表示当前任务, xt表示视觉特征,
DA用于最小化视觉模态和语义模态在潜层空间的高斯分布, 更好地对齐不同模态特征.分布对齐损失如下所示:
LDA= (‖
其中,
综上所述, 训练CADA-VAE的损失函数可表示为
LCADA-VAE=LVAE+LDA+LCA.
LCADA-VAE有利于同一任务中的视觉模态特征和语义模态特征在潜层空间中对齐, 促使模型可通过学习隐向量到重构输入数据的映射, 获得生成目标数据的能力.CADA-VAE网络在解决单一零样本学习任务中性能较优.然而, 当模型面临多任务学习时, 并不能有效缓解模型在参数更新后面临的灾难性遗忘, 降低网络性能.为了缓解此问题, 本文提出潜层向量对齐策略.
CADA-VAE为零样本学习任务构建潜层空间.在此空间中, 潜层向量的概率分布表达输入数据的概率分布.不同任务的潜层向量分布不同.然而, 当模型学习新任务时, 参数更新容易破坏已学任务的潜层空间, 产生灾难性遗忘.为了缓解此问题, Wei等[10]约束同一任务数据经过相邻任务模型生成的潜层高斯分布, 增大相邻任务在潜层空间分布的相似性.此方法虽然取得一定成效, 但是在约束力上仍存在不足.
VAE的特点在于利用编解码范式, 通过编码器将输入特征x编码为高斯分布η (μ , σ 2), 再利用参数化技巧从η (μ , σ 2)中采样得到隐向量z, 具体参数化过程可归结为
z=μ +ε σ , ε ~η (0, 1),
其中, ε 表示从均值为0、方差为1的高斯分布中采样的参数.
解码器将z重构为输入特征x的概率分布.从VAE处理数据过程可得到, 隐向量z的概率分布携带有关输入特征x的概率分布信息.因此, 约束不同任务之间的隐向量分布同样具备强化任务之间潜层分布相似的作用.故本文提出潜层向量对齐策略, 即通过约束已学任务模型与当前任务模型在潜层空间中的潜层表示, 促进增加不同任务潜层空间的相似性, 缓解灾难性遗忘.
潜层向量对齐策略具体过程如下.在当前任务t中, 将视觉特征xt同时输入当前任务的视觉编码器
LVA=
当t> 1时, 网络的目标函数为
LVA-VAE=LCADA-VAE+γ LVA.
其中:第1项为CADA-VAE的损失函数, 用于构建不同任务的潜层空间, 实现不同模态特征对齐; 第2项为潜层向量对齐损失函数, 用于缩小不同任务潜层空间的差异性, 缓解模型的灾难性遗忘; γ 为潜层向量对齐损失的超参数, 本文γ =1.
潜层向量对齐策略有利于保护已学任务的潜层空间.然而, 参数更新仍是灾难性遗忘的主要原因.为此, 在训练过程中, 本文引入选择性再训练的方法[10], 通过控制参数更新的数量, 进一步缓解遗忘问题.具体方法如下:首先利用前一任务的视觉编码器
当VAE顺序学习完所有任务之后, 针对不同任务, 训练不同的分类器, 实现对应的广义零样本图像分类[24, 25, 26]任务.在训练过程中, Wei等[10]采用已见类语义特征和未见类语义特征, 用于训练分类器, 并将训练好的分类器用于测试已见类视觉样本和未见类视觉样本.然而, 由于样本的视觉空间和语义空间存在明显的域差异[23], 语义特征无法全面表示视觉特征的所有视觉信息, 甚至忽略视觉特征中携带有关判别的关键信息, 因此, 采用语义特征训练分类器容易使分类器难以全面学习视觉样本的信息, 导致识别能力不足.
鉴于在训练阶段不可获得未见类的视觉特征, 需要借助语义特征, 获取有关未见类的相关信息.为此, 本文利用已见类的视觉特征和未见类的语义特征联合训练分类器, 在训练分类器阶段提供已见类的视觉信息, 促使分类器在测试阶段可更好地对视觉样本进行分类, 综合提高分类器的识别能力.
训练分类器的具体过程如图2所示.首先, 将任务t中的视觉特征
Lcls=
其中, t表示当前任务, y表示隐向量z对应的类标签, f
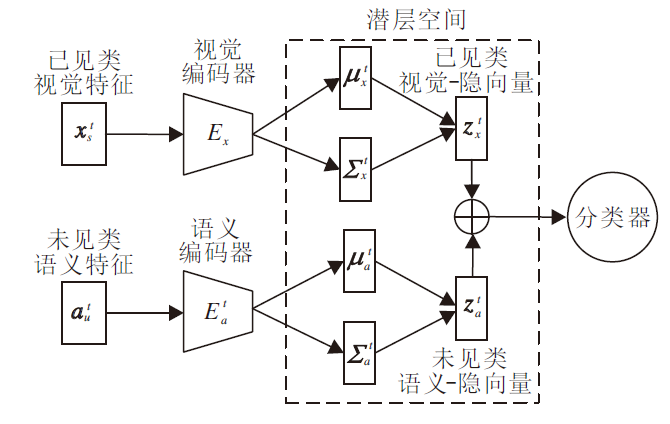 | 图2 分类器训练过程Fig.2 Process of training classifier |
CZSL的最终目的是将学习好的模型及分类器用于识别每个任务中的已见类样本和未见类样本.因此, 在测试阶段, 首先利用视觉编码器Ex将每个任务中的测试样本编码为隐向量, 然后利用独立的任务分类器对特定任务的隐向量进行识别.通过对比识别结果和标签值, 得到最终的识别精度.
本文在APY[27]、AWA1[1]、CUB(www.vision.caltech.edu/visipedia/CUB-200.html)、SUN[28]4个标准数据集上进行实验, 每个数据集作为一个任务.APY数据集由PASCAL VOC 2008数据集和Yahoo搜索引擎中的图像类别组成.AWA1数据集是有关动物的粗粒度数据集.CUB数据集是关于鸟类的细粒度数据集.SUN数据集是有关环境场景和内部的细粒度数据集.4个数据集的统计数据如表1所示.
| 表1 实验数据集的统计数据 Table 1 Statistics of experimental datasets |
本文使用预先由ResNet-101网络的最后池化层提取的2 048维特征作为图像的视觉特征, 利用数据集本身提供的语义属性作为语义特征.
采用Wei等[10]的评估方式评估本文算法, 包括Accu、Accs、Acc, 数值越大表示模型性能越优.
1)Accu.预测每个未见类样本的标签, 取所有未见类别的平均正确识别率.
2)Accs.预测每个已见类样本的标签, 取所有已见类别的平均正确识别率.
3)Acc.调和均值, 综合考虑未见类识别率和已见类的识别率.此指标更能表现模型的综合性能.
Acc与Accu、Accs的关系可记为
Acc=
文中算法学习任务的顺序为APY、AWA1、CUB、SUN.实验基本参数设置如下:VAE学习率为0.000 15, 分类器学习率为0.001, 迭代次数为100, 潜层空间维度为75, 批量大小为64.在网络结构中, 本文采用的两组VAE均是多层感知机.在模型优化方面, 本文统一采用自适应矩估计(Adaptive Mo-ment Estimation, Adam)优化器训练VAE及分类器.所有实验均在Ubuntu16.04系统, NVIDIA GeForce RTX 2080Ti显卡和python3.6环境上进行.
为了验证本文算法的有效性, 选择如下对比算法:Original、Base、SFT、L1、L2、Baseline.Original是由Schö nfeld等[6]提出以CADA-VAE为框架, 用于解决单一零样本学习任务的GZSL.Base是指算法顺序学习多个零样本学习任务, 且无添加持续学习策略的CZSL.SFT表示以当前任务模型参数初始化前一任务模型参数的CZSL.L1和L2在SFT的基础上分别进行参数L1正则化和L1正则化的CZSL.Baseline是由Wei等[10]提出的CZSL.
各算法在4个数据集上的指标值对比如表2所示, 表中黑体数字为最优结果.由表可知, 由于Original用于学习单一零样本学习任务, 未遭遇其它任务数据的干扰及连续学习多任务下的灾难性遗忘.因此, 根据Original和Base的性能对比, 可得到Base存在严重的遗忘问题, 导致对已学任务几乎无识别能力.SFT、L1、L2在Base的基础上, 均添加参数传递策略, 提高模型保留已学任务知识的能力.然而, 由于CZSL在不同任务上的知识传递能力不足, 识别性能存在局限性.Baseline是本文的核心对比算法.Baseline在CADA-VAE的基础上添加选择性再训练和知识蒸馏策略的持续学习策略, 大幅提高模型性能.在Baseline的基础上, 本文提出潜层向量
| 表2 各算法的指标值对比 Table 2 Index value comparison of different algorithms% |
对齐的持续学习策略, 同时, 使用已见类的视觉特征和未见类的语义特征联合训练分类器, 性能显著优于Baseline.此外, 在所有CZSL中, 本文算法性能最接近Original.
具体地说, 针对Accu、Accs、Acc指标, 相比Base-line:本文算法在APY数据集上分别提高2.28%, 11.83%, 5.19%; 在AWA1数据集上, 分别提高2.09%, 7.55%, 4.12%; 在CUB数据集上, 分别提高6.26%, 6.56%, 6.42%.在SUN数据集上, 相比Baseline, 本文算法在Accs、Acc指标上分别提高2.41%和0.76%, 这是由于SUN数据集是实验中模型最后学习的任务, 免受参数更新之后面临的遗忘问题, 故在所有算法的尝试下, 均能达到较稳定的识别性能.
综上所述, 通过对比多种CZSL发现, 本文算法性能最优.
为了进一步验证本文算法的有效性, 以Wei等[10]算法为Baseline, 通过对比实验评估本文算法的有效性.
各算法在4个数据集上的指标值对比如表3所示, 表中黑体数字为最优结果, Baseline+VA表示Baseline结合潜层向量对齐策略的方式, Baseline+CLS表示Baseline结合改进的训练分类器的方式, Baseline+VA+CLS表示Baseline结合潜层向量对齐策略及改进的训练分类器的方式.根据表中结果可得如下结论.
| 表3 消融性实验结果 Table 3 Results of ablation experiment % |
1)Baseline+VA的指标值明显高于Baseline, 这表明潜层向量对齐策略有效强化任务之间知识的正向传递.值得注意的是, 在第一个学习任务APY的表现上, 综合指标Acc具有显著进步(提升2.8%), 这表明此策略在缓解模型的灾难性遗忘方面具有明显作用.
2)相比Baseline, Baseline+CLS各任务的Accs指标均得到显著提升(平均提升8.52%).这表明相比利用已见类的语义特征训练分类器, 利用已见类视觉特征训练分类器有利于提高分类器学习已见类样本的视觉信息, 从而有效提高分类器对于已见类的识别性能.并且, 在Accu指标上, 4个任务的未见类识别精度也得到提高, 表明以已见类视觉特征和未见类语义特征联合训练的方式的效果优于仅采用已见类和未见类的语义特征训练分类器的方式.
3)Baseline+VA+CLS的指标值最优.综上所述, 本文算法不仅能有效缓解模型的灾难性遗忘, 而且在提高分类器的识别能力上具备一定优势.
下面研究参数对本文算法性能的影响.为了验证选择性神经元再学习的数量对于算法性能的影响, 设置不同的神经元参数阈值ω 进行实验, 结果如图3(a)所示.在4个顺序学习的任务中, 从整体上看, ω 设置在e-5和e-4之间时, 性能较优, 这表明算法在保留旧知识及学习新知识之间达到动态平衡.将ω 设置为大于e-4时, 性能将随着ω 的增大而降低, 这表明过多选择神经元再学习不利于算法保留已学任务知识, 从而加剧算法灾难性遗忘.
潜层空间维度D对算法性能的影响如图3(b)所示.4个任务对D的敏感度不同, APY和AWA1受D的影响较大, CUB和SUN对于D的敏感度较小.综合4个任务的识别精度可知, 当D=75时, 算法对4个任务的识别性能达到较优状态.当D< 75时, 容易导致过拟合问题.当D> 75时, 容易导致泛化能力不足.故本文将所有任务的潜层空间维度D设置为75.
目标函数的超参数γ 对于算法性能影响如图3(c)所示.综合4个任务的识别精度, 当γ =1时, 性能表现最稳定.这表明, CADA-VAE的优化函数和本文的潜层向量对齐优化函数的结合有利于算法的正优化, 同时验证潜层向量对齐策略有利于缓解算法的灾难性遗忘.经过多组实验结果对比之后, 本文将γ 值设置为1.
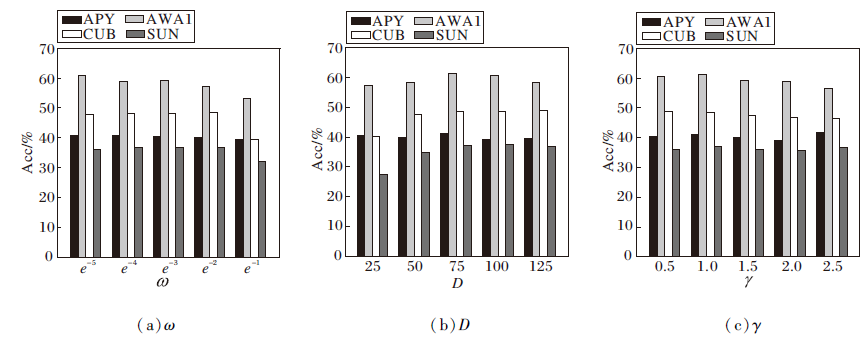 | 图3 超参数敏感度分析Fig.3 Hyperparameters sensitivity analysis |
针对目前CZSL面临的灾难性遗忘问题, 本文提出基于潜层向量对齐的持续零样本学习算法, 缓解模型的灾难性遗忘问题.同时, 本文使用已见类的视觉-隐向量和未见类的语义-隐向量联合训练分类器, 促使分类器学习有关视觉样本的视觉信息, 综合提高分类器的识别能力.在与现有CZSL的对比中, 本文算法获得最佳性能.今后将继续研究CZSL, 并尝试将正则化方法应用于CZSL, 在缓解模型的灾难性遗忘上进一步提高算法性能.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|