

{kind=link}
{kind=link}
{kind=link}
{kind=link}
融合地理信息、种类信息与隐式社交关系的兴趣点推荐算法
[董婵娟1  , 李胜
, 李胜1 , 何熊熊1 , 马悦1 ]
, 李胜, 何熊熊, 马悦]
|
|



作者简介:
董婵娟,硕士研究生,主要研究方向为数据挖掘、推荐系统.E-mail:2237462096@qq.com.
何熊熊,博士,教授,主要研究方向为信号处理、医疗图像处理、推荐系统等.E-mail:hxx@zjut.edu.cn.
马 悦,硕士研究生,主要研究方向为图像处理、推荐系统.E-mail:1285788475@qq.com.
针对现有大多数兴趣点推荐算法都存在签到数据稀疏、社交关系难以获取、用户个性难以考虑等问题,文中提出融合地理信息、种类信息与隐式社交关系的兴趣点推荐算法.首先考虑用户签到种类信息,同时分解用户签到地点矩阵和用户签到种类矩阵,减小签到数据稀疏带来的影响.再在显式社交关系的基础上,使用信息熵的方法度量用户的隐式社交关系,缓解社交网络稀疏的问题,并通过正则化的方法在矩阵分解模型中加入该隐式社交关系.最后,使用自适应核密度估计方法个性化建模地理信息对用户签到行为的影响,提高推荐的准确性.在Foursquare、Yelp数据集上的实验验证文中算法的有效性.
AboutAuthor:
DONG Chanjuan, master student. Her research interests include data mining and re-commendation system.
HE Xiongxiong, Ph.D., professor. His research interests include signal processing, medical image processing and recommendation system.
MA Yue, master student. Her research interests include image processing and reco-mmendation system.
Aiming at the problems in the existing point of interest recommendation algorithms, such as check-in data sparsity, difficulties in obtaining social relation and lack of consideration of user individuality, a point of interest recommendation algorithm integrating geo-category information and implicit social relationship is proposed. Firstly, user check-in category information is considered, and user check-in location matrix and category matrix are decomposed simultaneously to reduce the impact of data sparsity. On the basis of explicit social relations, the method of information entropy is employed to measure user implicit social relations to alleviate the sparse problem of social networks, and then the user implicit social relations are added to the matrix factorization model by regularization method. Finally, the adaptive kernel density estimation method is adopted to personalize the impact of geographic information on user check-in behavior to improve the accuracy of recommendation. Experiments on Foursquare and Yelp datasets verify the effectiveness of the proposed algorithm.
本文责任编委 杨健
Recommended by Associate Editor YANG Jian
现阶段移动和无线通信领域快速进步, 同时也使基于位置的社交网络(Location-Based Social Net-works, LBSNs)得到迅速发展, 如 Facebook、Yelp、Gowalla和Foursquare等.对于全球数百万用户来说, 使用这种媒体已经成为他们日常生活的一部分[1, 2, 3, 4].LBSNs服务积累了大量的用户数据, 为开发个性化的兴趣点(Point of Interest, POI)推荐系统提供良好的契机.事实上, 准确和个性化的POI推荐是LBSNs业务的关键需求[1, 5, 6].由于地理位置信息庞大, 用户容易忽略潜在感兴趣的POI, 需要在海量数据中进行搜索, 而个性化的推荐系统可帮助用户轻松找到相关的POI.而且, 由于用户之间的差异性, 商家向不同的用户精准推荐他们想要的POI非常困难, 个性化的推荐系统可帮助商家发现潜在客户, 提高利润.
POI推荐的主要方法之一是协同过滤技术[2], 它通过用户POI签到矩阵计算用户对未访问的POI的偏好评分.然而, 由于用户只访问LBSNs中较小的一部分POI, 用户签到矩阵高度稀疏, 协同过滤技术难以发挥作用.因此, 上述方法的推荐质量通常较低.
自Netflix大奖竞赛后, 基于矩阵分解(Matrix Factorization, MF)技术的推荐算法[7]因其良好的可扩展性及处理大规模数据的准确预测能力, 受到学术界和工业界的广泛关注.近年来, 随着对矩阵分解的深入研究, 人们研究得到更复杂的模型.例如, 基于隐式信息的矩阵分解(Singular Value Decompos-ition++, SVD++)[8], 基于核密度估计的偏好模型[9], 基于双正则化的矩阵分解模型[10]等.相比传统的矩阵分解, 更复杂的矩阵分解都加入上下文信息, 如类别信息、社交信息、地理位置信息.类别信息是指每个地点都有所属的类别, 地点类别表示所属服务类型, 如果用户喜欢访问某些类别的地点, 他可能访问更多属于该类别的地点.社交信息是指在LBSNs中, 一个人可能更喜欢他的朋友高度推荐的POI, 即朋友比陌生人更倾向于有更多的共同兴趣.因此一些学者[3, 11]认为可通过研究用户之间的朋友关系提高推荐性能.地理位置信息是指在LBSNs中, POI编码为经纬度, 将POI推荐与传统推荐系统中的书籍、音乐、电影等其它物品推荐区分.POI推荐的研究[2, 5]表明, 人们更倾向于访问他们去过地点附近的POI, 导致基于用户选择的POI空间聚类现象.
在LBSNs中, POI通常有多个层次类别, 这些类别信息表示位置的语义含义, 因此用户在给定位置的签到反映他对相应类别的偏好.为了缓解用户签到数据的稀疏性, 在一些研究[12, 13, 14]中加入种类信息, 取得较好的效果.Liu等[12]提出类别感知POI推荐模型, 对用户类别转移矩阵使用矩阵分解, 得到用户访问的下一个地点种类, 再结合幂律分布得到用户的推荐列表.He等[13]通过个性化贝叶斯排序预测用户可能会去的下一个地点种类, 根据空间影响力和类别影响力对类别预测筛选的候选POI进行排序.Chen等[14]建立用户类别转移的三阶张量, 使用张量分解得到用户可能访问的下个类别, 使用距离加权的超文本敏感主题搜索(Hypertext Induced Topic Search, HITS)计算用户可能访问的地点.
但是上述方法通常需要经过两步向用户推荐感兴趣的地点:1)构造用户种类转移矩阵、用户种类转移三阶张量或用户时间种类张量, 用于预测用户最有可能会去的K1个地点种类.2)利用一些地理位置信息或其它上下文信息, 在每个种类中选择用户最有可能会去的K2个地点.最后推荐K1K2个地点给用户.但是上述方法都不能直接选出用户感兴趣的地点, 在1)中选择用户感兴趣的种类个数K1时, K1的值也会对最后的推荐结果产生明显的影响, 因此在top K(K=K1K2)推荐时需要掌握好K1和K2的取值.
目前一些学者在试图提高推荐质量时, 将用户的社交关系作为最重要的社会信息类型之一并融入推荐系统中[15, 16, 17, 18], 取得一定的成果.为了有效整合社交信息与传统的矩阵分解模型, 学者们从不同的角度进行建模.Ma等[19]提出基于联合矩阵分解的社交推荐(Social Recommendation Using Probabilistic Matrix Factorization, SoRec)模型, 在概率矩阵分解的基础上, 加入社交关系矩阵, 共享用户特征矩阵, 建立用户偏好与好友之间的关系.Ma等[20]提出基于矩阵分解的社交关系正则化推荐模型(Recommender Systems with Social Regularization, SoReg), 通过物品相似度计算用户和朋友之间喜好的差异.然而, 上述方法只是基于用户特征共享, 并未从社交关系的角度进行深入分析.Yang等[21]分别从信任者和被信任者的角度提出基于信任的矩阵分解(Trust-Based MF, TrustMF)模型.Yang等[22]提出基于信任的概率矩阵分解(Trust Based Probability MF, TrustPMF)模型, 为TrustMF提供概率解释.
但是, 上述基于社交关系的推荐系统仍存在局限性.在LBSNs中, 用户只和少数其他用户建立社交关系, 用户之间留下大量模糊稀疏的关系, 即从LBSNs收集的数据并不平衡, 用户之间的显式社交关系形成非线性关系.此外, 现有研究大多只考虑用户的显式社交关系值, 忽视许多有价值的隐式社交关系及其特点.值得注意的是, 已经建立社交关系的朋友不可能有完全相似的兴趣.可见, 显式社交关系可能包含过多的噪声和干扰, 从而影响推荐系统的性能.而拥有相似兴趣的用户之间会存在隐式社交关系, 如用户u1、u2访问过相同的地点l, 那么用户u1、u2之间可能存在隐式社交关系.
现有POI推荐算法通常根据地理学第一定律(Tobler's First Law of Geography)进行地理信息的建模.Liu等[23]假设用户对POI的偏爱与这个POI到用户访问过的POI的距离之间成反比关系.Ye等[24]研究用户签到活动中表现的空间聚类现象, 利用幂律分布对其建模.在现实生活中, 用户访问的POI通常分布在几个中心附近, Cheng等[25]提出多中心高斯分布模型.上述研究普遍将所有用户的地理位置影响建模为共同的距离分布, 或认为所有用户对地点的偏好和位置的距离之间存在相同的反比例关系.但是, 多种因素(如其他用户过去的签到活动、用户性格等)同样可揭示地理位置对用户签到行为的实际影响.
基于上述分析, 本文提出融合地理信息、种类信息与隐式社交关系的兴趣点推荐算法(Point of Interest Recommendation Algorithm Integrating Geo-Category Information and Implicit Social Relationship, CSGWMF).首先考虑用户签到种类信息, 提出同时分解用户签到地点矩阵和用户签到种类矩阵的思路, 减小签到数据稀疏带来的影响.再在显式社交关系的基础上, 使用信息熵的方法度量用户的隐式社交关系, 缓解社交网络稀疏的问题, 并将该社交关系通过正则化的方法加入矩阵分解模型中.最后, 使用自适应核密度估计的方法个性化建模地理信息对用户签到行为的影响, 提高推荐的准确性.在Foursquare、Yelp数据集上的实验验证本文算法的有效性.
融合地理信息、种类信息与隐式社交关系的兴趣点推荐算法框架如图1所示, 整体框架分为三部分:数据预处理、矩阵分解建模和POI推荐.具体如下.
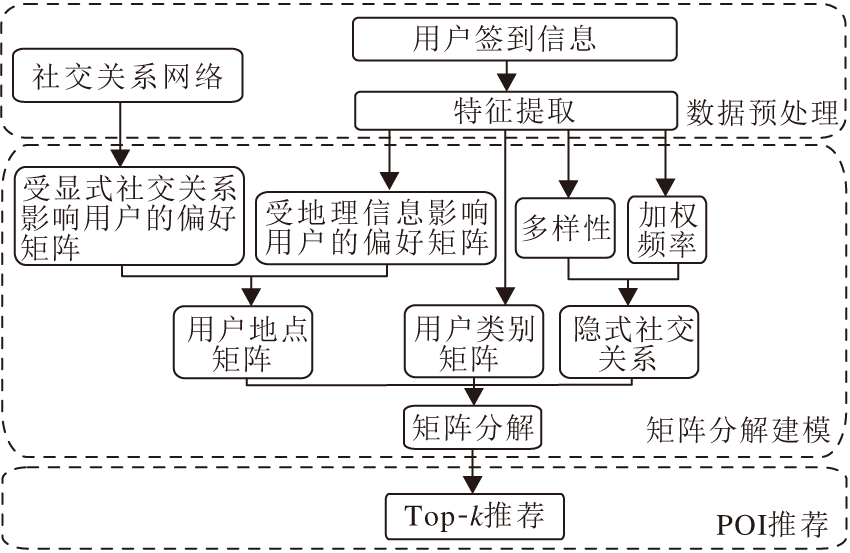 | 图1 本文算法框图Fig.1 Framework of the proposed algorithm |
1)构建用户签到地点矩阵和用户签到种类矩阵.构建好这两个矩阵后在用户签到种类矩阵的协助下分解用户签到地点矩阵.
2)挖掘用户的社交关系.用户的社交关系包括显式社交关系和隐式社交关系.计算显式社交网络中用户的相似度, 根据协同过滤方法计算用户对每个地点的偏好.提取用户隐式社交关系, 首先度量两位用户共同签到过的地点的多样性(两位用户共同签到过的地点越多, 多样性程度越高), 然后根据相应位置受欢迎程度分别度量每个共同访问地点的权重值(又称为加权频率), 最后基于用户共同签到过的地点的多样性和加权频率计算用户之间的隐式社交关系.最终将用户的隐式社交关系作为正则项加入矩阵分解中.
3)通过核密度估计的方法建模用户的地理位置信息, 得到用户对每个地点的偏好.融合用户的自身偏好和地理位置信息、显式社交信息.
矩阵分解是推荐系统里常用方法, 是为电影推荐典型场景中评分预测而设计的, 在这种情况下, 可直接得到用户评分矩阵.然而, 在POI推荐中, 只能得到用户的签到频率矩阵, 大量的用户和地点使用户签到矩阵更稀疏.为了解决类似问题, Hu等[7]提出加权矩阵分解(Weighted MF, WMF)模型.根据Lian等[26]的实验可知, 加权矩阵分解模型会使POI推荐准确率更高.WMF给签到矩阵中的缺失项分配一个较小的权重, 再根据用户地点的签到频率给未缺失项分配一个较大的权重, 签到频率越高, 权重越大.具体数学描述如下:
L=
其中:R表示用户签到地点, 是0, 1矩阵, 用户i访问过地点j, Ri, j=1, 否则Ri, j=0;
Wi, j=
ε 表示控制加权值随着签到频率增加的速率.
在日常生活中, 用户行为具有一定的目的性, 因此为了解决数据稀疏性问题, 可考虑POI的类别信息.在基于信任关系的矩阵分解(Trust Singular Value Decomposition, TrustSVD)[27]中, 同时分解用户评分矩阵和显式信任矩阵, 得到用户特征矩阵、物品特征矩阵和显式信任特征矩阵.类似地, 同时分解用户签到地点矩阵R和用户签到种类矩阵C, 得到用户特征矩阵U, 地点特征矩阵V, 种类特征矩阵P, 即
L=
其中:δ 用于调节POI与POI类别对建模用户偏好的比例; C表示用户签到种类矩阵, 如果用户i访问过某一类别k, Ci, k=1, 否则Ci, k=0; U为R、C分解后的共有矩阵, 即R和C通过U相互影响.
社交关系为推荐系统提供重要的上下文信息.具体地说, 可利用用户之间的社交关系获取用户相似性, 作为协同过滤模型的输入.因此, 一些POI推荐系统利用社交关系作为补充数据, 提高推荐性能.
研究表明, 社交关系对提高POI推荐的准确性影响显著[6].然而, 显式的社交关系数据通常是部分可用的, 甚至是不可用的.特别是在Foursquare数据集上, 社交关系网络更稀疏, 即使他们在社交网络上有社交关系, 但由于地域不同、距离较远, 他们可能对POI没有相似的选择.因此本文同时研究显式社交关系与隐式社交关系.
如果用户和朋友之间共同签到过的地点越多, 那么用户和朋友之间的兴趣越相似.这里使用Jaccard相似性计算用户和朋友之间的相似度:
其中, Li表示用户i签到过的地点的集合, Lf表示用户i的朋友f签到过的地点的集合.
使用ti, j表示受显式社交关系影响, 用户i对地点j的偏好程度:
ti, j=
其中, F表示用户i的朋友集合, If, j表示指示函数, 如果i的朋友f访问过地点j, If, j=1, 否则If, j=0.
如何测量用户之间的隐式社交关系是一个挑战.Pham等[28]通过分析用户的签到信息, 提出EBM(Entropy-Based Model), 通过两种独立的方法, 即多样性(度量用户之间关于共同签到地点个数的差异性)和加权频率(考虑共同签到地点的受欢迎程度, 分别度量每个共同签到地点的影响)测量隐式社交关系, 并通过实验验证此方法可用于推断用户的隐式社交关系, 但是并未把这种隐式社交关系应用到POI推荐中来.本文将EBM计算的隐式社交关系用于矩阵分解中, 作为正则项, 最后对用户推荐感兴趣的地点.
通过两位用户共同访问的地点个数测量用户之间共同签到地点的多样性, 推断用户之间建立社交关系的可能性.假设有3位用户u1、u2、u3, 不同的用户之间共同访问过的地点如下:
c12=[5, 0, 2, 3, 0], c13=[3, 2, 2, 1, 2], c23=[0, 6, 0, 0, 4].
其中:c12表示用户u1、u2共同访问的POI组成的向量, 每个元素表示用户u1、u2共同访问每个地点的次数, c13、c23类似.观察3个向量可发现用户u1和u2, 用户u1和u3, 用户u2和u3共同访问过地点的总次数都为10, 但是访问过的地点个数却不同.用户u1、u2共同访问过3个地点, 用户u1、u3共同访问过5个地点, 用户u2、u3共同访问过2个地点, 因此, c13比c12更多样化, 而c12比c23更多样化.当用户之间存在社交关系时, 通常会一起游览不同的地方, 反之, 用户之间访问更多相同的地点, 他们之间更可能存在社交关系, 因此, 本文认为共同签到地点的多样性有助于推断用户的隐式社交关系.这里使用Renyi熵[28]估计用户之间共同签到地点的多样性, 量化随机变量的不确定性.
基于Renyi的用户i、e共同签到地点的多样性估计表示如下:
Di, e=exp(
其中:cie, l表示用户i和e共同访问地点l的次数, 称为局部频率; fi, e=
经过计算用户u1、u2、u3, 得
D12=2.979, D13=4.971 6, D23=1.995 9.
由于用户u1、u3共同签到5个地点, 用户u2、u3共同签到2个地点, 所以用户u1、u3访问地点的多样性程度更高, 更有可能建立社交关系.
使用位置熵描述位置的受欢迎程度.Vu, l表示用户u在地点l的签到次数, Vl表示所有用户在地点l的总签到次数.从Vl中随机抽取一次签到, 属于用户u的概率Pu, l=Vu, l/Vl, 如果把这个事件定义为一个随机变量, 它的不确定性由香农熵给出, 即
Hl=-
位置熵的值越大表示这个地方越受欢迎, 反之, 位置熵的值越小意味着一个只有越少访客的私人场所, 如私人住宅.利用位置熵(地点的受欢迎程度)作为加权频率对cie, l进行加权:
Fi, e=
加权频率描述在受欢迎的地点发生的事件对隐式社交关系的影响.受欢迎的位置具有较高的位置熵Hl, 导致exp(-Hl)值较低, 从而受欢迎的地点加权值较小.另一方面, 对于不太受欢迎的地点或较隐私的地点, exp(-Hl)的值较高, 加权值较大.如果两位用户共同访问过的地点是私人住宅等不太受欢迎的小地方, 这两位用户之间的社交关系较强.
最后通过综合多样性和加权频率衡量用户之间的隐式社交关系.使用
本文需要把
为了在矩阵分解的过程中考虑隐式社交关系对用户行为的影响, 在式(1)的后面加上正则项
Tobler[29]认为世间万物都是息息相关的, 距离较近的两个物体之间的相关性强于距离较远的两个物体.幂律分布和高斯混合分布都基于用户的整体签到记录, 对地理信息进行建模, 虽然在一定程度上捕捉用户的签到行为, 但忽略用户签到行为存在个性化偏差的事实.因此为了更好地建模用户的签到行为, 使用核密度估计建模, 为了使核密度估计的参数更少, 采用自适应带宽.主要步骤如下.
1)距离样本收集.用户签到过的任意两个地点p、g之间的距离do=dis(p, g), 由于签到信息是经纬度信息, 如(41.485 499, -81.799 178), 需要通过球面半正矢公式计算地点之间的距离.
f(dx, o)=
其中:dx, o表示lx、lo之间的距离, lo表示用户ui签到过的地点, lx={l1, l2, …, ln}表示用户未签到过的地点; D表示收集到的距离样本信息; K(x)表示核函数, 这里使用最常见的高斯核函数[2, 6, 9],
K(x)=
h表示带宽, 使用的是自适应带宽[2],
3)计算用户ui对未签到过的地点lx的访问概率.文献[2]采用平均概率, 但是在现实生活中用户访问每个地点的次数都不一样, 因此本文根据用户访问地点的次数对核密度估计计算相关概率加权:
gi, x=
其中ri, o表示用户i访问地点o的次数.
在WMF的基础上融合种类信息、社交关系及地理位置信息后的目标函数如下:
L=
其中:
本文使用梯度下降法优化式(2)中的目标函数.
首先固定V、P, 对U求导:
固定U、P, 对V求导:
固定U、V, 对P求导:
本文算法的伪代码如下.
算法1 CSGWMF
输入 用户签到地点矩阵R, 用户签到种类矩阵C, 加权矩阵W1、W2,
受地理信息影响的偏好矩阵G,
受显式社交关系影响的偏好矩阵T,
基于信息熵的隐式社交关系矩阵SI
输出 Top-k POI推荐列表
step 1 初始化隐藏特征矩阵U, V, P.
step 2 迭代:
step 2.1 固定V、P, 通过式(3)更新Ui,
Ui← Ui-ξ
step 2.2 固定U、P, 通过式(4)更新Vj,
Vj← Vj-ξ
step 2.3 固定U、V, 通过式(5)更新Pk,
Pk← Pk-ξ
直至
迭代停止.
step 3 计算
step 4 对偏好预测矩阵
算法整体的时间复杂度由两部分组成.首先计算用户之间的隐式社交关系的时间复杂度, 基于用户显式关系的用户对地点的偏好的时间复杂度, 基于核密度估计的用户对地点的偏好的时间复杂度.再计算矩阵分解的时间复杂度.由于上下文信息的计算不参与矩阵分解的迭代计算, 属于离线执行, 未考虑复杂度和计算开销.因此这里主要考虑矩阵分解的时间复杂度.
矩阵分解的时间复杂度由代价函数的时间复杂度和潜在因子梯度下降时的时间复杂度组成.代价函数的时间复杂度为O(d(|R|+|C|)), 其中, |R|表示用户访问过的地点, |C|表示用户访问过的地点种类, d为隐藏特征的维度.Ui的时间复杂度为
O(d(|R|+|C|)+dk),
Vj的时间复杂度为O(d|R|), Pk 的时间复杂度为O(d|C|), 其中, k为Top-k隐式朋友数.矩阵分解的整体时间复杂度为
O(d(|R|+|C|)+dk).
实验使用在POI推荐算法中应用较广的2个数据集:Foursquare数据集和Yelp数据集.Foursquare数据集包括11 326位用户在182 968个地点的1 385 223条签到数据, 稀疏度为6.7× 10-4.Yelp数据集包括30 887位用户在18 995个地点的860 888条签到数据, 稀疏度为1.5× 10-3 .在这两个数据集中除了用户的签到数据以外还有用户地点种类信息和用户之间的社交关系, 数据集的具体信息如表1所示.
| 表1 实验数据集 Table 1 Experimental datasets |
在数据预处理时, Foursquare数据集上删除签到地点少于10个的人和签到人数少于10人的地点, Yelp数据集上删掉签到地点少于30个的人和签到人数少于30人的地点.在处理后的数据集中随机挑选80%的数据为训练集, 剩下的20%的数据为测试集.重复上述实验, 最终结果取5次实验的平均值.
本文采用准确率和召回率评估推荐的效果.
准确率
Precision@k=
召回率
Recall@k=
其中:m表示用户的总个数, k表示最后给每位用户推荐的地点个数,
参数δ 控制用户签到种类对矩阵分解的影响, 首先分析在矩阵分解模型中只有用户的自身偏好与种类影响时的效果, 即α =β =λ 2=0, λ 1=0.001, 绘制当δ =0, 0.2, 0.4, 0.6, 0.8, 1.0, k=5时的准确率和召回率.如图2所示, 在Foursquare、Yelp数据集上, 当δ =0.2时, 准确率和召回率均处于最高值, 说明在矩阵分解中加入种类信息可提高推荐性能.后面的实验均选择δ =0.2.
 | 图2 δ 对实验结果的影响Fig.2 Influence of parameter δ on experimental results |
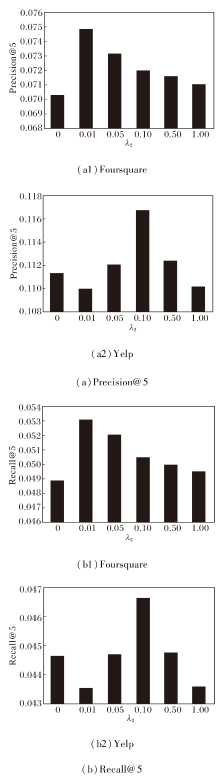
当隐式社交关系作为正则项加入矩阵分解时, 参数λ 2控制其对推荐性能的影响, 即α =β =0, δ =0.2, λ 1=0.001.绘制当λ 2=0, 0.01, 0.05, 0.10, 0.50, 1.00, k=5时的准确率和召回率曲线, 如图3所示.
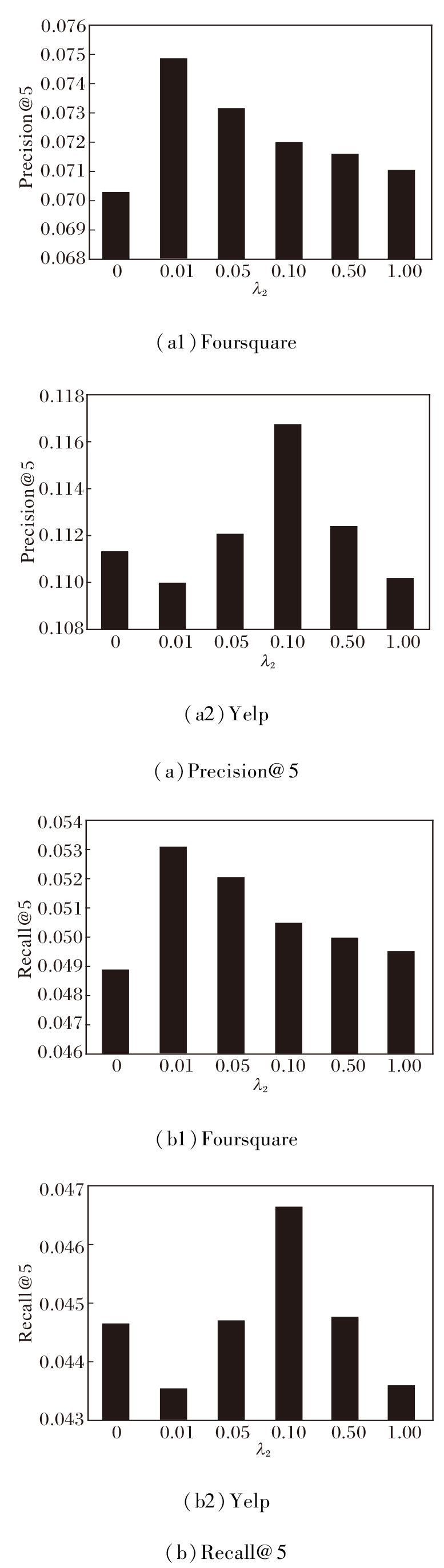 | 图3 参数λ 2对实验结果的影响Fig.3 Influence of parameter λ 2 on experimental results |
由图3可知, 在Foursquare数据集上, 当λ 2变大时, 准确率和召回率都变高, 当λ 2超过0.01后, 准确率和召回率开始下降, 即当λ 2=0.01时准确率和召回率同时达到最大值.在Yelp数据集上, 当λ 2取不同值时, 准确率和召回率的变化较大, 当 λ 2=0.1时, 准确率和召回率均处于最高点.由此说明在本文算法中加入隐式社交关系可提高推荐性能.
本节选择如下算法进行对比实验, 验证本文算法的有效性.
1)基于核密度估计的个性化地理位置推荐(Personalized Geo-Social Location Recommenda-tion, iGSLR)[2].采用核密度估计方法对地理位置信息建模, 将个性化地理影响与社会影响整合到统一的地理社会推荐框架中.
2)WMF[7].用于解决隐式反馈的一种有效方法, 根据用户的签到次数给用户签到矩阵分配不同的权重.
3)基于朋友签到信息的兴趣点推荐(the Aug-mented Square Error Based Matrix Factorization, ASMF)[4].利用签到信息、社交网络信息、地理位置信息定义3种朋友关系.利用2种不同的损失函数将3种类型的签到信息合并到矩阵分解模型中.
4)基于位置视角的邻居感知矩阵分解(Lo-cation Neighborhood-Aware Weighted Probabilistic Matrix Factorization, LWMF)[1].从位置角度探讨POI之间的地理关系, 提出位置邻域感知加权概率矩阵分解的方法.
各算法在2个数据集上的准确率和召回率对比如图4所示.在推荐长度k=5, 10, 15, 20时, 本文算法的准确率和召回率都最高.当k=5时, 在Fours-quare数据集上, 相比LWMF, 本文算法的准确率提高8.4%, 召回率提高11.3%.在Yelp数据集上, 相比LWMF, 本文算法的准确率提高5.8%, 召回率提高10.8%.
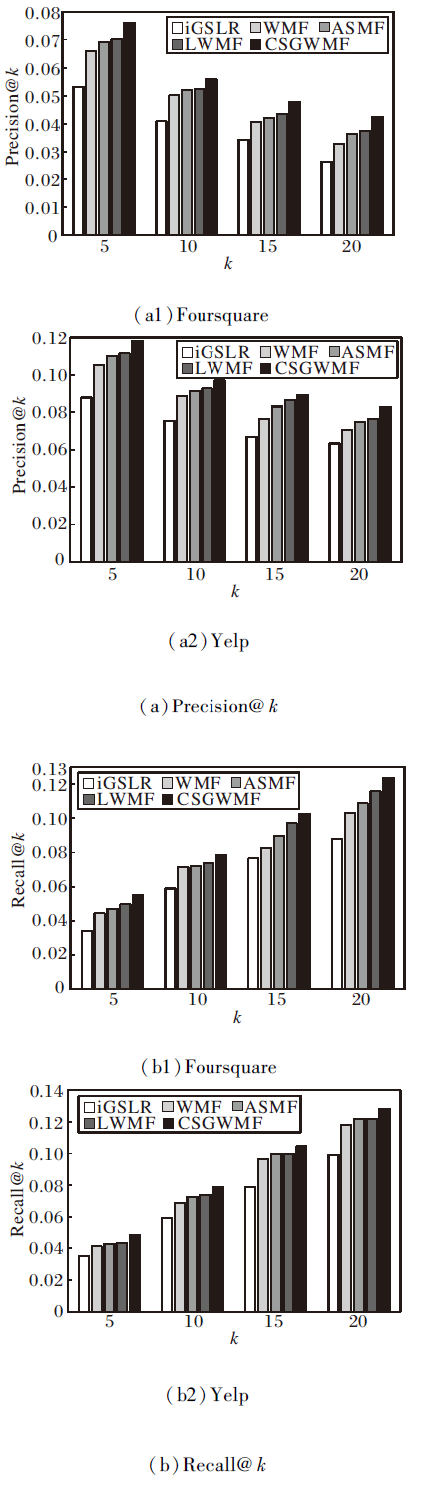 | 图4 各算法在2个数据集上的实验结果对比Fig.4 Experimental result comparison of different algorithms on 2 datasets |
iGSLR利用协同过滤的思想, 通过用户朋友之间居住距离的远近查找具有相似兴趣的用户, 用于预测用户对特定POI的偏好, 再和通过核密度估计计算用户对地点的偏好简单地进行线性融合.iGSLR的基本思想是最基础的基于用户的协同过滤, 性能不及WMF.本文算法和ASMF、LWMF都是在WMF的基础上融入上下文信息, 性能优于WMF, 说明加入上下文信息可有效改善数据的稀疏性问题, 提高推荐性能.本文算法性能优于ASMF、LWMF, 说明本文算法在WMF的基础上能更好融入各种上下文信息.相比WMF, 本文算法在用户的签到数据稀疏时具有以下优势:1)根据用户的签到种类信息更好地约束用户特征矩阵.2)不仅可根据用户在社交网络上拥有的显式社交朋友推断用户对未签到过的地点的偏好, 还可通过用户的签到信息找到用户的隐式社交朋友, 对用户进行推荐.3)通过个性化分析每个用户访问过的地点的分布关系预测用户对未访问过的地点的偏好.
本文还进行如下对比实验, 验证本文算法中的种类信息、社交关系及地理位置信息的有效性.具体对比算法如下.
1)WMF.只考虑用户的自身偏好, 没有加入上下文信息.
2)GWMF.本文算法只考虑用户的自身偏好和地理位置信息.
3)CWMF.本文算法只考虑用户的自身偏好和种类信息.
4)SWMF.本文算法只考虑用户的自身偏好和社交关系.
5)CGWMF.本文算法考虑用户的自身偏好、种类信息和地理位置信息.
6)SGWMF.本文算法考虑用户的自身偏好、社交关系和地理位置信息.
7)CSWMF.本文算法考虑用户的自身偏好、种类信息和社交关系.
8)CSGWMF.本文算法考虑用户自身偏好、种类信息、社交关系和地理位置信息.
在Foursquare、Yelp数据集上验证上下文信息的有效性, 具体结果如表2所示.
| 表2 上下文信息的有效性验证 Table 2 Validation of contextual information |
由表2可知, GWMF、CWMF、SWMF都只在WMF的基础上加入一种上下文信息, SWMF效果最优, 并且这3种算法的准确率和召回率均高于WMF.这说明分别加入这3种上下文信息都是有效的, 在显式社交关系的基础上, 通过信息熵的方法引入用户的隐式社交关系对实验结果的影响大于同时分解用户签到地点矩阵和用户签到类别矩阵、个性化建模用户的地理信息的影响.CGWMF、SGWMF、CSWMF都在WMF的基础上加入2种上下文信息, CSWMF效果最优, 并且这3种算法的准确率和召回率都高于GWMF、CWMF、SWMF, 说明相比融合一种上下文信息, 融合两种上下文信息能更好地解决数据稀疏的问题, 并且结合种类信息和社交关系能更好地发挥作用.CSGWMF在WMF 的基础上加入种类信息、社交关系、地理位置信息, 准确率和召回率最高, 说明本文算法能较好地融入上下文信息, 并且上下文信息考虑得越多, 效果越优.这与人们在实际生活中对地点的选择也是一致的, 用户在选择感兴趣的地点时不仅仅是对某个地点的偏好, 也反映用户对这类地点的偏好, 同时还会受朋友和地点距离的影响.
本文提出融合地理信息、种类信息与隐式社交关系的兴趣点推荐算法.在矩阵分解模型中同时分解用户签到地点矩阵和用户签到种类矩阵, 有效缓解签到数据稀疏性.在考虑显式社交关系的同时融入隐式社交关系, 以正则项的方式加入矩阵分解模型中, 缓解社交网络的稀疏性, 提高推荐性能.还使用自适应核密度估计方法个性化建模地理因素的影响, 提高推荐精度.由于用户的签到行为不仅和本文研究的几种上下文信息有关, 还和时间有关, 因此今后将继续研究时间对用户签到行为的影响, 更好地预测用户未来的访问地点.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|