






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于认知度与兴趣度的好友推荐反馈算法
[尹云飞1, 2  , 孙敬钦
, 孙敬钦1 , 黄发良3 , 白翔宇1 ]
, 孙敬钦, 黄发良, 白翔宇]
|
|



作者简介:
孙敬钦,硕士研究生,主要研究方向为推荐系统.E-mail:hcheng@cqu.edu.cn.
黄发良,博士,副教授,主要研究方向为数据挖掘、社交媒体处理.E-mail:huangfl@fjnu.edu.cn.
白翔宇,本科生.E-mail:xiangyubai@outlook.com.
针对现有的好友推荐算法在好友关系刻画上丢失重要信息的现状,受用户对物品认知行为的启发,文中提出基于认知度与兴趣度的好友推荐反馈算法,使用混合相似度研究网络好友关系,探索在线社交网络中的交友问题.针对好友推荐过程中“开环”的问题,提出基于历史推荐信息的正负反馈优化调整策略,使用用户相似度修正公式研究好友反馈动态推荐,证明好友推荐是一个逐步修正的复杂过程,揭示在线社交网络中好友关系刻画的心理学认知问题和推荐的动态变化问题.实验表明,文中算法提高推荐质量,实现用户相似度矩阵的动态调整,在准确率、召回率、鲁棒性、可扩展性等方面性能较优.
SUN Jingxin, master student. His research interests include recommendation system.
HUANG Faliang, Ph.D., associated professor. His research interests include data mining and social media processing.
BAI Xiangyu, undergraduate.
In the existing friend recommendation algorithm, important information is lost in the portrayal of the friend relationship. Inspired by the user's cognitive behavior of the item, a friend recommendation feedback algorithm based on cognition and interest is proposed in this paper. Hybrid similarity is utilized to conduct online friend relationship research and explore friendship issues in online social networks. Aiming at the open loop problem of the friend recommendation process, a positive and negative feedback optimization adjustment strategy based on historical recommendation information is proposed. The user similarity correction formula is employed for friend feedback dynamic recommendation, and it is proved that friend recommendation is a complex process of gradual correction. The psychological and cognitive problems portrayed by friend relationships in online social networks and the dynamic changes of recommendations are presented. The experiments show that the proposed algorithm improves the recommendation quality and realizes the dynamic adjustment of the user similarity matrix and it is superior in accuracy, recall, robustness and scalability.
本文责任编委 陈恩红
Recommended by Associate Editor CHEN Enhong
随着移动互联网的发展, 各种社交网络平台的用户数量迅速增长[1].海量的社交信息造成信息过剩, 因为大多数用户只喜欢浏览自己感兴趣的内容, 他们每天能够看到的社交信息只占总信息量的很小一部分.研究计算机辅助好友推荐, 让用户在推荐的好友中进行选择是解决这个问题的重要方法.如何从大量的社交信息中给目标用户推荐一些感兴趣的好友是当前社交网络研究的热点话题[2].
社交网络的应用通常分为两类:1)基于熟人的社交网络应用, 如微信、QQ等; 2)基于陌生人的社交网络应用, 如豆瓣、百度贴吧等.在不同类型的社交网络应用中, 好友推荐算法有不同的侧重点.
在基于熟人的社交网络应用中, 好友推荐算法侧重于根据用户的社交关系进行好友推荐[3].Chen等[4]对比的算法都是通过用户社交关系网络进行好友推荐, 即通过共同好友的数量进行推荐.李慧等[5]提出基于好友间信任关系的社交网络推荐算法, 利用推荐特性进行用户相似度计算, 再通过矩阵分解技术实现社会网络推荐.
在基于陌生人的社交网络应用中, 可先根据用户的属性特征对用户进行分类, 得到分类结果后, 再结合用户的交友偏好进行好友推荐.也可通过分析用户的行为数据得到用户的兴趣偏好, 再根据兴趣偏好的相似度为用户推荐好友[6].
学者们现已开始研究用户间的兴趣相似度, 为用户推荐志同道合的好友.Yang等[7]提出挖掘在线社交网络用户兴趣相似度的方法, 可用于预测新用户的兴趣度或访问数据发生修改的非活动用户的兴趣度.Chen等[8]提出同时采用微博内容和社交结构信息计算用户兴趣相似度的算法.Hu等[9]提出随机游走算法, 计算用户之间兴趣相似度.Chen等[10]通过用户对项目打分的标签进行建模, 提出隐藏的语义信息推荐方法.Zhou等[11]对用户标签图进行社区发现, 构建用户兴趣模型, 提出用户推荐模型(User Recommendation, UserRec), 计算KL距离(Kullback-Leibler Divergence), 得到不同用户之间的相似度.Jain等[12]研究稀疏矩阵, 提出使用主动学习、改进用户之间相似度的方法, 其中Cosin标签法(Cosin Tag, CosTag)是计算用户相似度的方法.Chang等[13]研究用户重排序算法和用户双向重排序方法, 构建人员重新识别算法(Person Re-iden-tification, PR).扩散标签图协同过滤(Diffusion Tag Graph Collaborative Filtering, DTGCF)[14]与用户项目标签图协作过滤(User Item Tag Graph Collabora-tive Filtering, UITGCF)[15]是典型的基于兴趣偏好的推荐算法.DTGCF利用物质的扩散过程获得用户间的相似度, 计算用户-物品和用户-标签的二部图关系, 用于计算用户之间的兴趣相似度.UITGCF在DTGCF的基础上对用户兴趣进行建模, 构建用户的兴趣标签图, 挖掘用户的兴趣主题, 根据用户的兴趣主题进行推荐.
UITGCF和DTGCF针对用户打标签的行为存在处理不合理的地方.由于在推荐过程中未使用反馈控制技术, 即在计算当前的推荐结果时未考虑用户对历史推荐结果的认可情况, 因此这种“ 开环式” 的推荐必定会影响推荐结果的有效性.
认知在心理学中是指通过形成概念、知觉、判断或想象等心理活动获取知识的过程.认知度就是大众对某件事物或人等客观对象的认识和了解程度.思考与推理在人类大脑中的运作与计算机软件在计算机里的运作相似, 涉及输入、表征、计算、处理和输出等.可通过对用户行为的分析达到理解用户对物品的认知.这种以行为推理心智的模型已在不同领域中得到广泛应用.Davis等[16]基于用户认知, 实现即兴创作系统, 可进行实时的即兴创作.Kiefer等[17]研究视觉注意与认知过程的联系, 认知研究空间中视觉跟踪.Paul等[18]结合车联网与认知智能, 提出用于车联网的集中式和分布式协同频谱感应模型, 可有效管理认知无线电和车载通信中的频谱.
因此, 本文提出基于认知度与兴趣度的好友推荐反馈算法(Friend Recommendation Feedback Algo-rithm Combining Cognition and Interest, FCIC).一方面给出用户认知度与用户兴趣度的融合策略, 另一方面引入反馈机制, 利用历史推荐信息分析用户对认知相似度与兴趣相似度的偏向性, 动态调整用户相似度, 使推荐模型更符合个人偏好.实验表明, 本文算法提高推荐质量, 实现用户相似度矩阵的动态调整, 在准确率、召回率、鲁棒性、可扩展性等方面性能较优.
兴趣度表明用户对哪些物品感兴趣.因此, 可使用兴趣相似度衡量不同用户之间的关系.
认知度表示用户对一个物品或时间的认知程度或看法.认知度在兴趣度的基础上细分用户的行为.
假设物品总数为n, 用户数目为m, 构建关系矩阵An× m=[aij]和权重矩阵Wn× m =[wij].其中:aij表示用户j对物品i是否产生交互行为(打上标签、点击、收藏、购买、写评语等).如果用户j曾经对物品i产生交互行为, aij = 1, 否则aij = 0.wij表示用户j对物品i产生交互行为的强度, 一般通过点击、收藏、购买等的总次数度量.当aij = 1且wij = 1时, 表示用户j对物品i产生兴趣.
基于用户对物品产生的兴趣, 定义用户u、v的兴趣相似度:
Su, v=
其中:I(u)表示用户u关注的物品集合, I(v)表示用户v关注的物品集合; Iu, v=I(u)∩ I(v), 表示用户u、v共同关注的物品集合; wiu表示用户u对物品i关注的强度, 一般使用关注次数度量, 称为用户u对物品i的兴趣度; 同理, wiv表示用户v对物品i的兴趣度; U(i)表示所有关注过物品i的用户的集合;
记
U(i) = {j|1≤ j≤ m且aij=1}
表示所有与物品i有过交互行为(如关注等)的用户的集合;
I(j)={i|1≤ i≤ n且aij=1}
表示用户j关注的物品集合, 即与用户j发生交互行为的物品集合.假设用户之间通过共同关注的物品建立联系, 当计算用户u、v兴趣相似度时, 需要考虑用户u、v共同关注的物品集合, 即Iu, v, 同时也需要考虑用户u、v各自关注的物品集合, 即I(u)、I(v).对于用户u, 共关注|I(u)|个物品, 每个物品对用户兴趣度的贡献平均为1/|I(u) |.因此, 在计算用户u、v兴趣相似度时, 通过1/|I(u)|对Iu, v中的每个物品进行加权.
式(1)中1/|U(i)|用于防止物品的热门程度差异给兴趣相似度计算带来影响.例如已知物品i1、i2, 其中, i1的热门程度低、i2的热门程度高.关注i1的用户只有u、v, 即U(i1)={u, v}, 则|U(i1)|=2.关注i2的用户包括u、v等10 000个人, 则|U(i2) |=10 000.因此, 在计算u、v的兴趣相似度时, i1和i2的作用不相同.i1的作用大于i2的作用, 前者称为癖好相同的物品, 后者称为大众感知相同的物品.
式(1)中(wiu+wiv)/
用户u、v之间的兴趣相似度不满足对称性, 即用户u、v的兴趣相似度Su, v不等于用户v、u的兴趣相似度Sv, u.
为了计算用户之间的认知相似度, 需要评估用户对物品的认知度.通过用户对物品打上的标签计算用户对物品的认知度.
设物品总数为n, 用户总数为m, 构建标签记录矩阵Pn× m=[pij]和标签标记矩阵Bn× m=[bij].其中:pij表示用户j对物品i打上的标签信息; bij表示用户j是否成功对物品i打上标签, 如果bij=1, 表示用户j成功对物品i打上标签, 如果bij=0, 表示用户j没有成功对物品i打上标签.
令qij=[lij, tij], 其中, lij表示用户j对物品i打上的标签集合, tij表示用户j对物品i打上标签的时间集合.设
lij=[
表示用户j对物品i在
基于用户对物品的认知度, 定义用户之间的认知相似度:
Ru, v=
其中:Iu, v表示被用户u、v共同打上标签的物品集合;
式(2)中|
用户u、v之间的认知相似度不满足对称性, 即用户u、v的认知相似度Ru, v不等于用户v、u的认知相似度Rv, u.
为了融合兴趣相似度和认知相似度, 需要综合考虑二者对好友推荐的影响.设λ 为FCIC的兴趣相似度度与认知相似度的调节因子, λ 决定兴趣相似度和认知相似度的组合比例.令λ 的取值范围为[0, 1], 则λ 和1-λ 可作为权重因子.
对兴趣相似度Su, v和认知相似度Ru, v进行加权处理, 得到用户u、v最终的混合相似度:
Simu, v=λ Su, v+(1-λ )Ru, v, (3)
其中λ 表示兴趣相似度和认知相似度调节因子.λ 作为超参数, 通过实验选取合适的值.
为了对用户之间的相似度进行动态调节, 需要引入用户相似度修正公式, 用于调整用户之间的相似度, 提高推荐效果.
假设向用户u推荐用户v时, 推荐成功, 即用户v成为用户u的好友, 那么, 与用户v相似度较高的用户在未来成为用户u好友的可能性会增大.这种情况称为正反馈.
令
S(v) = {v1, v2, …, vi, …},
表示与用户v具有较高相似度的用户集合.基于正反馈的用户相似度修正公式表示如下:
Si
其中, kp表示正反馈调节因子, 根据领域经验取值, 约为1, 2.Simu, vi表示用户u、vi的相似度, vi在S(v)中取值.
假设向用户u推荐用户v时, 推荐不成功, 即用户v未与用户u成为好友.那么, 与用户v相似度较高的用户在未来成为用户u好友的可能性就会很低, 这种情况称为负反馈.
基于负反馈的用户相似度修正公式如下:
Si
其中, kn表示负反馈调节因子, 根据领域经验取值, 一般约取1.0, vi在S(v)中取值.
在反馈调节过程中, 如果涉及调用式(3), 保持参数λ 不变.
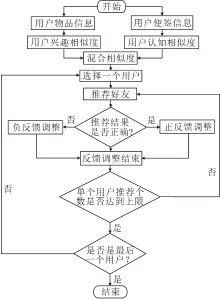
图1为基于认知度与兴趣度的好友推荐反馈算法(FCIC)框图.在图1中, FCIC首先遍历用户物品信息与用户标签信息, 分别得到不同用户之间的兴趣相似度和认知相似度.在计算混合相似度后, 选择一个混合相似度最高的用户进行推荐.如果推荐结果正确, 进行正反馈修正, 即增大相关用户之间的相似度; 如果推荐结果错误, 进行负反馈修正, 即减小相关用户间的相似度.当得到所有用户的好友推荐列表后, 算法结束.
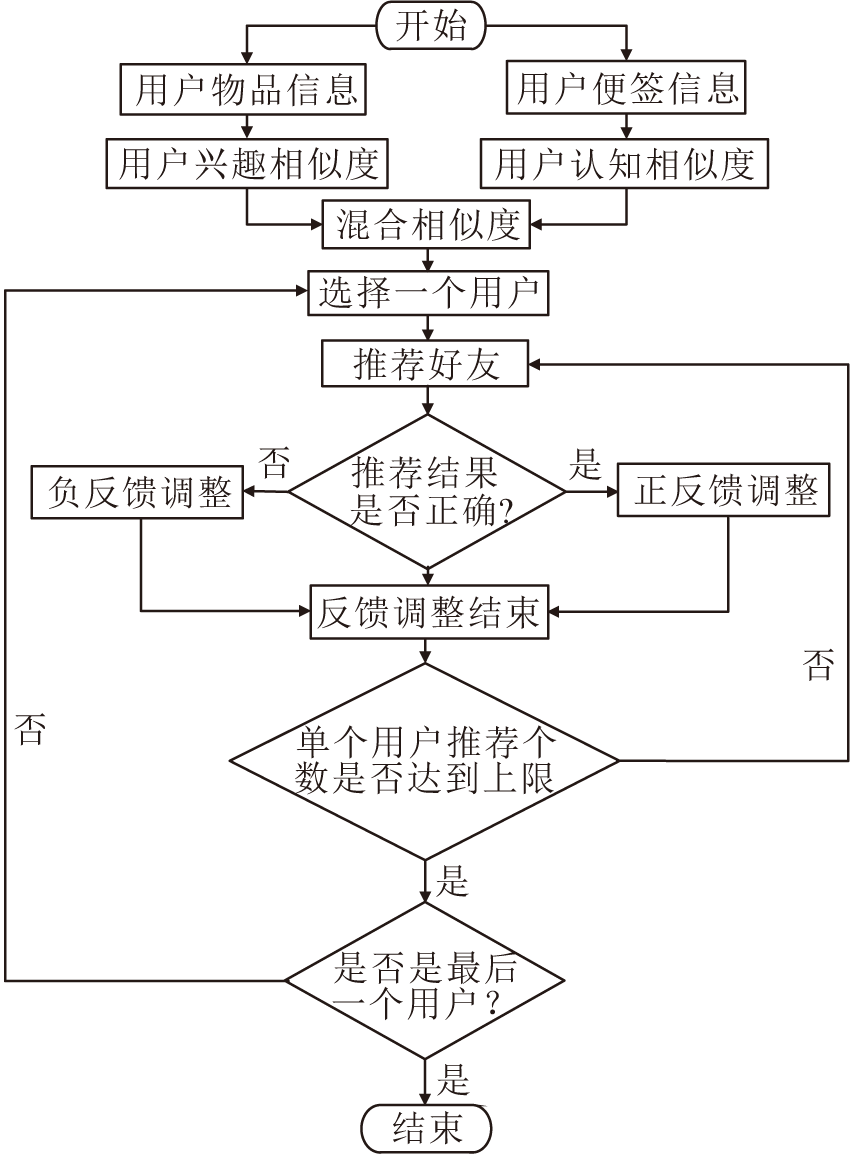 | 图1 FCIC框图Fig.1 Flow chart of FCIC |
FCIC具体步骤如下.
算法1 FCIC
FCIC(UserFile uList, TagFile tList, ArticleFile aList,
IFile, iList, double λ , int N).
输入 uList, user data file; tList, tag data file; aList, articles/commodities data file; iList, interest data file; λ , regulators of interest similarity and cognitive similarity; N, Maxi-mum number of friends recommended; fList, friends list
输出 rList, friends recommendation list
uL← uList, tL← tList, aL← aList, iL← iList;
// data read
for any (u, v) in uL & & i in aL {
S← calUsrSim(u, v, i, uL, iL, aL);
//User similarity calculation, see Eq.(1)
}
for any (u, v) in uL & i in aL{
R← calArcSim(u, v, uL, i, aL, tL);
// Eq.(2)
}
Sim=λ S+(1-λ )R;
//Mixed similarity, see Eq.(3)
for each u in uL{
while k++ ≤ N {
//Recommended count
rList← friendPair(u, vk, Sim); //Recommend a friend
if(check(rList, fList) == True) //Successful recommendation
Sim← update Sim(u, vk, kp); //Positive feedback, see Eq.(4)
else
Sim← update Sim(u, vk, kn); //Negative feedback, see Eq.(5)
}
}
return rList
在FCIC中, 为了计算两两用户之间的兴趣相似度, 需要读取用户信息、物品信息、兴趣度信息等.vk表示第k个用户, 其中k表示用户序号.为了计算两两用户之间的认知相似度, 需要读取用户信息、物品信息、标签信息等.为了计算用户之间的混合相似度, 式(1)~式(3)参与算法计算过程.为了进行反馈式用户好友推荐, 基于正负反馈机制的相似度修正公式, 即式(4)和式(5), 参与算法的计算过程.算法最后返回好友推荐列表.
FCIC主要分为两部分:兴趣相似度和认知相似度的计算、算法推荐.
假设用户数量为m, 物品数量为n, 标签数量为t.
在兴趣相似度计算过程中, 遍历每位用户与其他用户共同关注的物品, 对每个物品赋予权重并进行计算.因为用户数量为m, 每位用户与其他用户共同关注的物品至多为n个, 所以, 计算一位用户与其他用户兴趣相似度的时间复杂度为O(m2n).
在认知相似度计算过程中, 需要遍历每个物品被哪些用户关注, 并进一步遍历他们打上的标签.因为用户数目为m, 每位用户与其他用户共同关注的商品至多为n个, 两位用户对同个物品最多打上t个相同的标签, 所以认知相似度的时间复杂度为O(m2nt).
在推荐过程中, 需要针对每位用户, 计算该用户与哪位用户的相似度最高, 并基于此进行推荐.设每位用户的最大好友推荐个数为k, 因为用户数目为m, 所以推荐过程的时间复杂度为O(mk).
综上所述, FCIC的时间复杂度为O(m2nt + mk).在实际的社区用户好友推荐过程中, 并不是所有用户都对每个物品打上标签, 用户也不是对一个物品在每一时刻都会打上标签, 所以真实的数据集是个非常稀疏的矩阵.考虑一个成熟的在线社交网络NC, 它的用户数目为m, 物品数目为n, 两位用户最多有t个标签相同, 为每位用户推荐的最大好友个数为k.m> n≫t, m> n≫k, FCIC的实际复杂度约等于O(m2n), 即FCIC的效率主要取决于社交网络NC的用户数目和物品数目.
实验选取如下数据集.
1)last.fm数据集.记录用户收听音乐的信息, 是英国的一家音乐电台网站的用户数据集.本文使用该数据集验证基于认知度与兴趣度的好友推荐算法.last.fm数据集包含用户收听音乐的信息、双向的朋友关系信息、艺术家信息、用户对艺术家的tag等, 有1 892位用户、17 632首歌曲、12 717个< user_i, user_j> 对、92 834个< user, artist, listening-Cunt> 对、11 946个tag、186 479个< user, tag, artist> 对.该数据集发布在第五届ACM推荐系统会议(RecSys)和第二届国际推荐系统信息异构与融合研讨会(HetRec)上.
2)delicious-2k数据集.记录用户对图书的评价, 是一个网上书城的用户数据集.数据集包含用户对图书的tag信息、用户关系信息、书签的title、书签的url等, 有1 867位用户、69 226本图书、7 688个< user_i, user_j> 对、10 799个< user, URL> 对、53 388个tag、437 539个< user, tag, URL> 对.此数据集适用于图书tag的推荐.
3)eMall.food数据集.记录用户对餐厅服务的评价, 是一个美食电商平台的模拟经营数据集.数据集包含用户对美食的tag信息、用户关系信息、评价信息等, 有2 387位用户、525家美食餐厅、7 446种美食、62 257个标签、26 176个< user, friend> 对、16 625个< user, foodshop> 对、789 170个< user, foodshop, tag, time> 对.此数据集用于分析美食电商的服务.
4)eComsumer.health数据集.记录用户对健康产品的评价, 是一个大健康产业的电商模拟经营数据集.数据集包含用户对健康产品的tag信息、用户关系信息、评价信息等, 有4 962位用户、197家健康电商、36 926种健康项目、79 302个标签、55 176个< user, friend> 对、34 597个< user, healthshop> 对、9 268 371个< user, healthshop, tag, time> 对.此数据集用于对大健康产业的电商进行服务分析.
为了评估FCIC的有效性, 对比算法如下:用户协同过滤(User Collaborative Filtering, UserCF)、DTGCF、CosTag、PR.另外, 由于UserRec的性能低于UserCF、DTGCF、CosTag, 所以通过与后三种算法的对比可间接地实现与UserRec的对比.
在实验中, 使用Top-N推荐方式, 采用准确率(Precision, P)、召回率(Recall, R)和F1值作为算法推荐效果的评价指标.设用户集合为U, 算法为用户u推荐的好友列表为P(u), 用户u真正的好友列表为T(u), 准确率
P=
召回率
R=
F1值是准确率和召回率的加权调和平均:
F1=
设置Top-N推荐个数N在5~100之间, 推荐个数以5为步长递增.在4个数据集上的实验结果如图2~图5所示.FCIC的兴趣度与认知度调节因子λ =0.5.
 | 图2 各算法在last.fm数据集上的实验结果Fig.2 Experimental results of different algorithms on last.fm dataset |
 | 图3 各算法在delicious-2k数据集上的实验结果Fig.3 Experimental results of different algorithms on delicious-2k dataset |
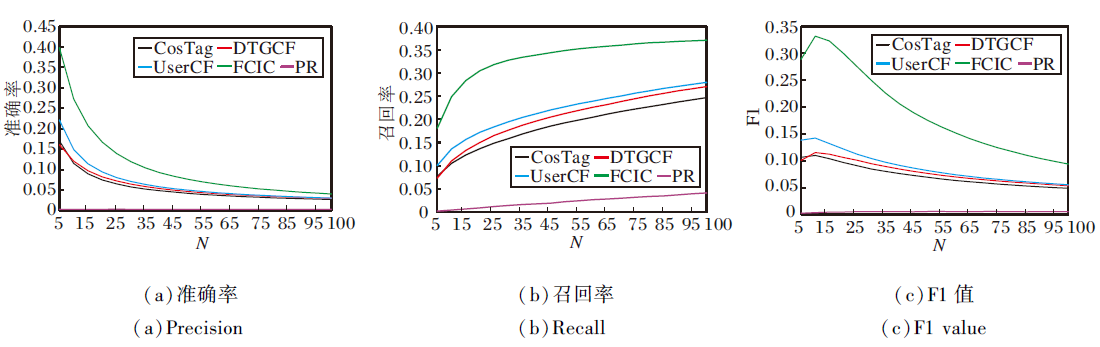 | 图4 各算法在eMall.food数据集上的实验结果Fig.4 Experimental results of different algorithms on eMall.food dataset |
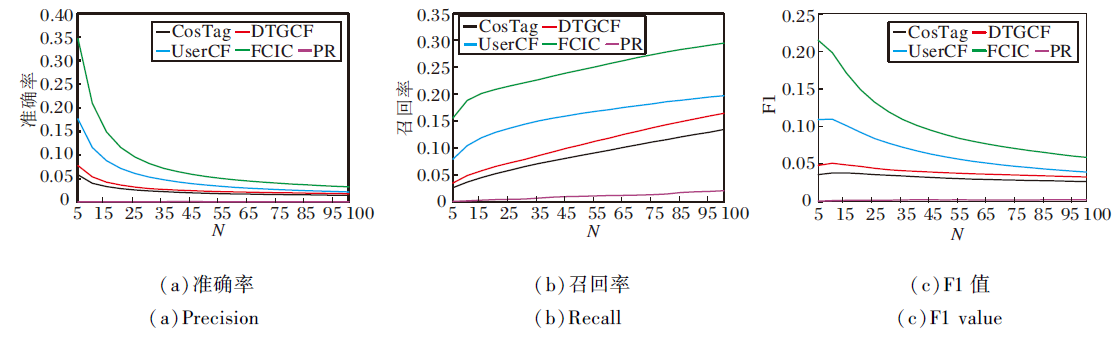 | 图5 各算法在eComsumer.health数据集上的实验结果Fig.5 Experimental results of different algorithms on eComsumer.health dataset |
由图2可知, 在last.fm数据集上, 各算法得到的准确率随推荐个数N的增加而降低, FCIC的准确率最高, CosTag的准确率最低.各算法的召回率随推荐个数N的增多而升高, FCIC的召回率最高, CosTag的召回率最低.随着推荐个数的增多, FCIC的召回率优势越来越明显.各算法的F1值随推荐个数N的增加先增长, 而后趋于平稳, FCIC的F1值最高, UserCF和DTGCF次之, CosTag最差.
由图3可知, 在delicious-2k数据集上, 当推荐个数N较小时, FCIC和DTGCF取得相近的准确率, 但是当推荐个数增多时, FCIC的准确率逐渐高于DTGCF.UserCF和CosTag在不同推荐个数下的准确率都远低于FCIC和DTGCF, 随着推荐个数的增多, UserCF的准确率下降程度较大.FCIC在不同推荐个数下都能取得较高的准确率、召回率和F1值.
由图4可知, 在eMall.food数据集上, 随着推荐个数N的增大, 各算法的准确率降低, 但FCIC的准确率始终保持最高.FCIC的召回率优势明显, 超过各算法2倍以上.各算法的F1值随推荐个数的增加先增长, 而后趋于平稳, FCIC最优, UserCF和DTGCF其次, PR最差.
由图5可知, 在eComsumer.health数据集上, 随着推荐个数N的增加, FCIC的准确率、召回率和F1值最优.FCIC对现有算法的性能提升明显.
综上可得, FCIC的准确率、召回率和F1值都最优.随着推荐个数的增加, FCIC优势越来越突出.相比DTGCF和UserCF:FCIC在准确率上平均提高15%以上; 在召回率上平均提高15%以上; 在F1值上平均提高15%以上.与其它算法相比, FCIC在准确率、召回率、F1值上的提高比例更大, 平均可达到30%以上.
算法的鲁棒性是指兴趣度与认知度调节因子λ 的不同取值对FCIC准确率、召回率和F1值的影响.为了验证算法的鲁棒性, 需要研究λ 在0~1取值时, FCIC的准确率和召回率的变化情况.实验中令推荐个数N=5.
图6为FCIC在不同λ 下, 对应的准确率、召回率和F1值的变化情况.由图可知, 在4个实验数据集上, 随着λ 取值的增大, FCIC的准确率、召回率和F1值基本趋于平稳, 在λ =0.6附近准确率、召回率和F1值有一个极值点.λ =0表示当前只使用认知相似度; λ =1表示当前只使用兴趣相似度.在这两种边界情况下的准确率、召回率和F1值都不是最好的.这种结果说明, 相比传统算法, 融合认知度与兴趣度的推荐算法可提高推荐效果.
 | 图6 FCIC在4个数据集上的鲁棒性实验结果Fig.6 Experimental results of robustness for FCIC algorithm on 4 datasets |
为了验证FCIC在不同数据规模下的效果, 以last.fm数据集规模变化为例(其它数据集类似)验证4种算法.本文取原始数据集的20%、40%、60%、80%、100%验证数据规模对算法性能的影响.实验中令推荐个数N=5.
4种算法的实验结果如图7所示.在图中, 横坐标是不同的数据集规模, 0.2表示last.fm数据集的20%, 0.4表示last.fm数据集的40%, 以此类推.
分析图7可知, 在推荐个数相同的条件下, 随着数据集规模的扩大, 算法的准确率、召回率和F1值逐渐增大.
这说明, 随着在线社交网络用户数量的增多, 推荐算法越来越有效.因此, FCIC的效果最优, 在准确率、召回率、F1值等评价指标上高于UserCF、DTGCF、CosTag.
 | 图7 数据集规模的变化对算法性能的影响Fig.7 Effect of different dataset sizes on algorithm performance |
为了验证FCIC反馈机制的有效性, 对比反馈前后的准确率、召回率和F1值的变化.
设置参数kp=1.2, kn=1, λ =0.5, 推荐个数N在5~100之间.在last.fm数据集(其它数据集类似)上进行实验, 实验结果如图8所示.
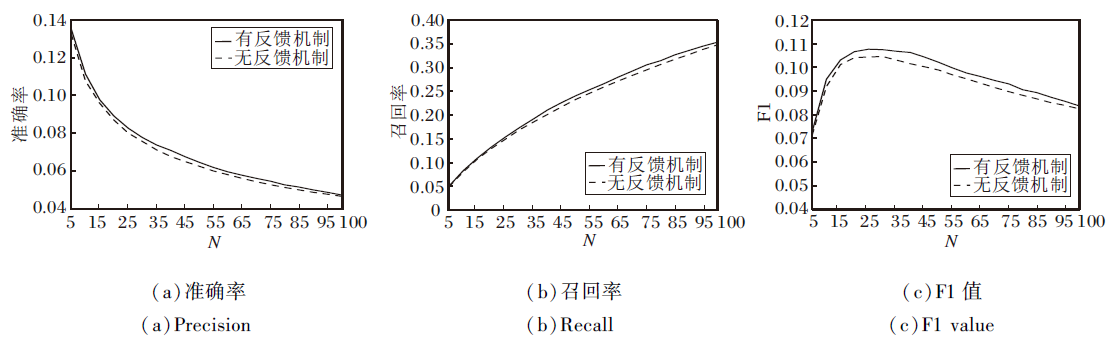 | 图8 反馈算法对推荐质量提升的效果Fig.8 Improvement of feedback algorithm on recommendation quality |
由图8可知, 使用反馈机制的FCIC, 准确率、召回率和F1值均得到提升.准确率提升1.97%~4.04%, 召回率提升2.04%~4.21%, F1值提升1.5%~4.7%.这说明使用反馈机制可提高在线社交网络好友推荐的质量.
本文提出基于认知度与兴趣度的好友推荐反馈算法.通过反馈控制方法, 研究基于正负反馈相似度修正公式的动态推荐算法.阐明在好友推荐过程中进行认知心理学刻画的原理和进行动态推荐过程.实验表明, 结合用户间的共同兴趣与用户对物品的认知, 会提高好友推荐质量, 与其它经典的好友推荐算法相比, 本文算法性能提升明显.这意味着深度挖掘社交网络交友心理学特征和潜在规律可提高好友推荐的准确率、召回率和F1值.算法适用于存在用户对物品评分和打标签的场景, 如音乐、影评等社交网络平台.随着推荐算法在诸多领域的深度应用, 基于认知度和兴趣度的推荐方法必将引起学术界和工业界的广泛关注.未来的推荐方法将朝着自适应、自反馈、智能化的方向发展.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|