


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于上下文保持能力的方面级情感分类模型
[何丽1  , 房婉琳
, 房婉琳1 , 张红艳1 ]
, 房婉琳, 张红艳]
|
|



作者简介:
房婉琳,硕士研究生,主要研究方向为自然语言处理、情感分析等.E-mail:fangwanlin1997@126.com.
张红艳,硕士研究生,主要研究方向为计算机视觉、图像分割等.E-mail:zhy16622553596@163.com.
方面级情感分类可发现语句在不同方面隐藏的情感特征.文中基于特定方面的图卷积网络的框架,构建基于上下文保持能力的方面级情感分类模型.在图卷积层中引入上下文门控单元,整合前一层输出中的有用信息.在基于图卷积网络的模型中加入多粒度注意力计算模块,描述方面词与上下文在情感表达上的相互关系.在5个公开数据集上的实验表明,文中模型在分类准确率和F1宏平均指标上均表现较优.
AboutAuthor:
FANG Wanlin, master student. Her research interests include natural language processing and sentiment analysis.
ZHANG Hongyan, master student. Her research interests include computer vision and image segmentation.
Hidden emotional characteristics of the statement in various aspects can be discovered by aspect-level sentiment classification. Based on the framework of aspect-specific graph convolutional network, an aspect-level sentiment classification model based on context-preserving capability is proposed. A context gating unit is introduced into the graph convolution layer to reintegrate the useful information in the output of the previous layer. A multi-grained attention computing module is added to the proposed model to describe the interrelation in emotional expression between aspect words and their context. Experimental results on five public datasets show the advantages of the proposed model in classification accuracy and macro-F1.
本文责任编委 林鸿飞
Recommended by Associate Editor LIN Hongfei
由于社交网络的迅速发展, 基于文本的情感分类[1]已成为自然语言处理(Natural Language Proce-ssing, NLP)领域的一个重要研究方向.方面级情感分类[2]属于细粒度情感分类, 研究目标是根据给定的方面词(单一词语或多词短语)对文本的情感极性进行判断.细粒度情感分类在电子商务和舆情分析领域具有重要的应用价值[3].
近年来, 基于深度学习[4]的方面级情感分类模型性能表现较好.这些模型主要以长短期记忆网络(Long Short-Term, LSTM)和双向长短期记忆网络(Bi-directional LSTM, Bi-LSTM)为基础网络, 并引入注意力机制、位置权重等以提高模型的分类性能.
在LSTM基础网络方面, Tang等[5]采用两个LSTM网络, 分别从方面词的左右两侧对语句进行编码.Ruder等[6]采用多层Bi-LSTM网络对语句和方面词进行拼接建模.Li等[7]提出特定目标的转换网络-自适应缩放(Target-Specific Transformation Net-works-Adaptive Scaling, TNET-AS), 基于Bi-LSTM建立上下文转换单元, 利用卷积神经网络(Convolutional Neural Networks, CNN)从其输出中提取特征.但是, 由于LSTM具有时间依赖性, 在处理复杂长句时可能无法准确识别距离较远的描述性词语和方面词间的潜在关联.而且, 当多个情感极性不一致的方面词同时出现时, LSTM可能错误地将某些具有明显情感色彩的形容词或短语识别成方面词的修饰词, 从而产生语义混淆.
图卷积网络(Graph Convolutional Networks, GCN)[8]可看作是对传统CNN编码非结构化数据的一种改进.虽然CNN可处理语义丰富的文本结构且容易并行, 但是卷积操作会将多个词语的特征视为连续词, 无法准确识别多个不连续词语描述的情感.而GCN能在一定程度上解决LSTM和CNN在处理文本数据时存在的问题, GCN通过对输入语句及其语法依赖图进行图卷积, 可将距离较远的描述性词语与方面词聚集到较小的范围内, 更好地结合语句的语法信息, 发现长程多词之间复杂的依赖关系, 故在方面级情感分类问题中具有一定优势.Zhang等[9]利用GCN构建特定方面的图卷积网络(Aspect-Specific GCN, ASGCN), 使用Bi-LSTM捕获上下文信息, 利用多层图卷积提取方面词特征, 将方面词特征反馈给Bi-LSTM的隐藏层.Tang等[10]针对依赖图中每条边的方向设计双向GCN, 结合Transformer网络结构建立依赖图增强的双Transformer网络(Dependency Graph Enhanced Dual-Transformer Network, DGEDT), 有效解决语句依赖图的不稳定性和噪声问题.
为了使模型重点关注与方面词相关的语义信息, 近年来, 大部分模型引入注意力机制.Tang等[11]和Chen等[12]分别利用词向量和Bi-LSTM隐藏向量迭代地计算注意力.曾义夫等[13]在分段解码时同时使用词向量和隐藏向量计算注意力.张新生等[14]利用多头注意力机制改进记忆网络, 缓解模型的选择性偏好.注意力机制的引入可进一步提升分类性能.但是, 上述注意力机制没有关注到特定方面与其上下文应具有双向影响关系, 即特定方面的语义是基于所在上下文的, 上下文的情感表达也是基于特定方面的.在语句中, 有些词语可独立表达语义和情感(细粒度), 另一些需要与相邻词语形成短语才能具有完整语义(粗粒度).基于此种情况, Ma等[15]提出交互注意力网络(Interactive Attention Networks, IAN), 从粗粒度的角度计算方面词和语句的相互影响.Huang等[16]提出双重注意力(Attention-over-Atten-tion, AOA)神经网络, 从细粒度的角度计算方面词和语句的相互影响.Fan等[17]提出多粒度注意力网络(Multi-grained Attention Network, MGAN), 其中的多粒度注意力机制采用两组对称的结构, 为各词语训练注意力权重, 可分别从词级别和短语级别捕获方面词和上下文之间的相互影响关系, 并利用方面对齐损失描述具有相同上下文的方面词间的影响关系.
双向Transformer的表征编码器(Bidirectional En-coder Representation from Transformers, BERT)[18]是基于多层双向Transformer编码部分构建的预训练语言模型, 在文本的语义表达方面具有明显优势.Song等[19]提出基于预训练的BERT模型的注意力编码器网络.Gao等[20]利用BERT模型对语句进行编码, 并利用池化后的方面词向量对语句进行情感分类.方面信息的融合使BERT预训练模型更适用于文本的细粒度情感分类任务.
本文在文献[9]提出的ASGCN的基础上构建基于上下文保持能力的方面级情感分类模型(Context-Preserving GCN with Multi-grained Attention, CPGCN-MultiATT).为了减少GCN在前向传播过程中的有用信息丢失, 在GCN的每个图卷积输出后加入一个可动态分配输出比例的上下文门控单元(Context Gating Unit-Proportional Distribution, CGU-PD), 构建具有上下文保持能力的图卷积网络(Context-Preserving GCN, CPGCN), 有效整合上一层的输出, 更完整地保留网络传输过程中的上下文信息.提出由细粒度和基于双分支的粗粒度注意力计算方法组成的多粒度注意力计算方法.将Bi-LSTM提取的语句特征和CPGCN提取的方面特征作为输入, 利用向量乘积的方法计算细粒度注意力权重, 同时利用平均池化和最大池化的方法计算基于双分支的粗粒度注意力权重.在多粒度注意力机制的基础上减少向量中噪声信息的影响, 无需引入额外的训练参数.最后, 在数据集上的实验表明, CPGCN-MultiATT在主要评价指标上具有明显优势.
CPGCN-MultiATT主要由4部分组成:语句特征向量生成模块、方面特征向量生成模块、多粒度注意力计算模块、融合方面级特征的情感分类模块.具体框图如图1所示.
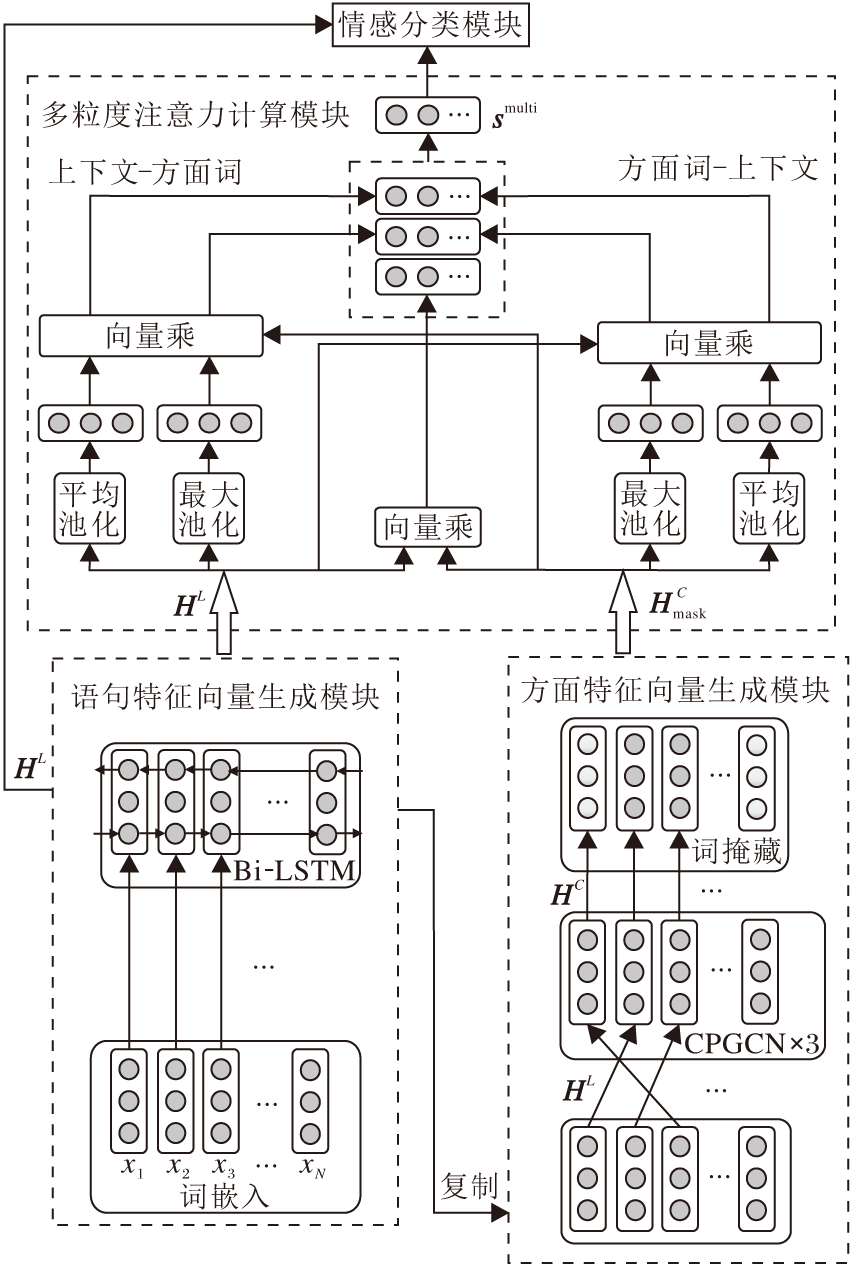 | 图1 本文模型框图Fig.1 Flow chart of the proposed model |
图1中语句特征向量生成模块采用Bi-LSTM网络获得包含词序信息的语句特征向量.方面特征向量生成模块使用本文构建的CPGCN层, 通过词掩藏的方式得到融合上下文信息的方面特征向量.多粒度注意力计算模块使用上述两模块的输出作为输入, 通过向量乘积和池化的方法交叉计算细粒度注意力和基于双分支的粗粒度注意力, 并通过对两种粒度注意力计算结果进行拼接和归一化, 得到多粒度注意力权重.语句情感分类模块利用语句的特征向量和多粒度注意力权重计算语句的最终情感表达, 利用全连接层和softmax分类器得到方面级情感分类结果.
本文采用2种词向量生成方法:基于斯坦福大学预训练的全局词频统计表征模型(Global Vectors for Word Representation, GloVe)[22]生成的静态词向量和基于谷歌预训练的BERT语言模型生成的动态词向量.BERT分词器将单词拆分为子单词标记, 本文对BERT模型的最后4个隐藏层向量求和, 得到子单词向量, 使用平均子单词的嵌入向量为原始单词生成一个近似的向量.
使用
x=[x1, …, xτ +1, …, xτ +M, …, xN]
表示长度作为N的语句逐词映射到低维空间中的固定实值向量, x的子序列[xτ +1, xτ +2, …, xτ +M]表示长度为M的方面词.xi∈ Rd表示词语i的词向量, d表示词向量的维数.
本文采用Bi-LSTM网络得到整合词序信息的语句特征向量.Bi-LSTM隐藏层的输出表示为
HL=[
子序列[
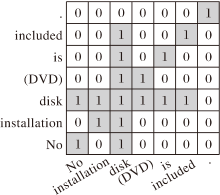
图卷积使用图结构中节点之间的邻接关系描述词语之间的依赖关系.无向图G中的一个节点表示一个词语, 节点之间的边表示两个词语的依赖关系, G的邻接矩阵A作为语法依赖图.若输入语句为“ No installation disk(DVD) is included.” , 该语句对应的依赖图如图2所示.A的副对角线上的值均为1; 若节点i与节点j描述的2个词语之间存在直接的依赖关系, 表示这2个节点在图G中存在边, 则Aij=Aji=1; 否则, Aij=Aji=0.
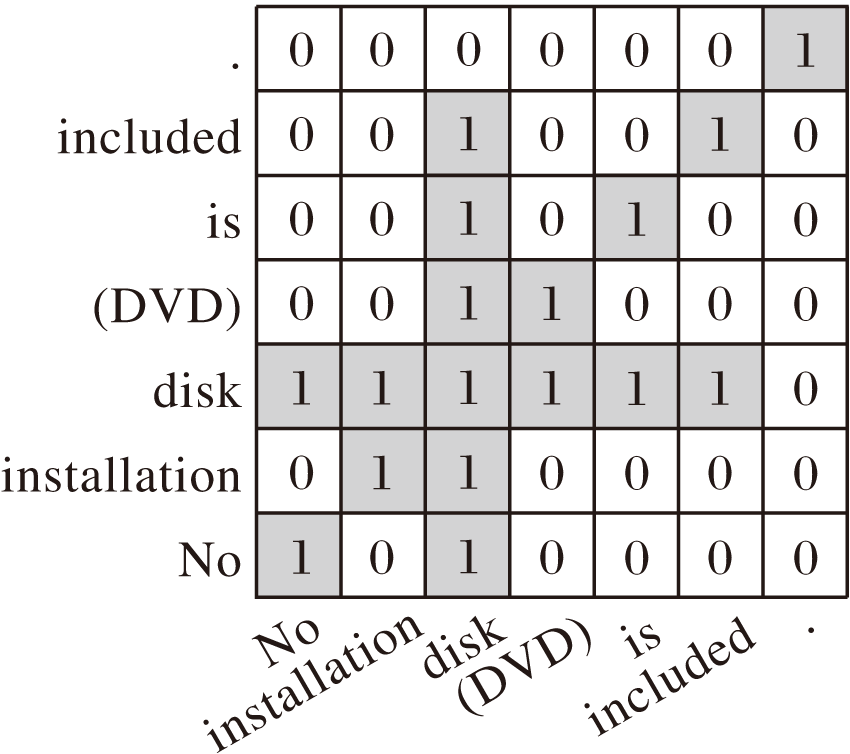 | 图2 “ No installation disk (DVD) is included.” 的依赖图Fig.2 Dependency graph of “ No installation disk (DVD) is included.” |
ASGCN单纯使用GCN提取融合上下文信息的方面词特征.但是, 由于包含语句语义、语法信息的特征向量的均值和方差在图卷积的非线性变换后会发生改变, 所以, 在GCN的前向传播过程中存在上下文信息丢失问题.为了进一步减少每层图卷积的输出中遗失的部分输入信息, 本文使用自适应缩放策略[7], 在方面特征向量生成模块中的GCN后加入CGU-PD单元, 构建CPGCN层, 从而对本层GCN和上一层CPGCN的输出进行整合训练.CPGCN层内部结构如图3所示.
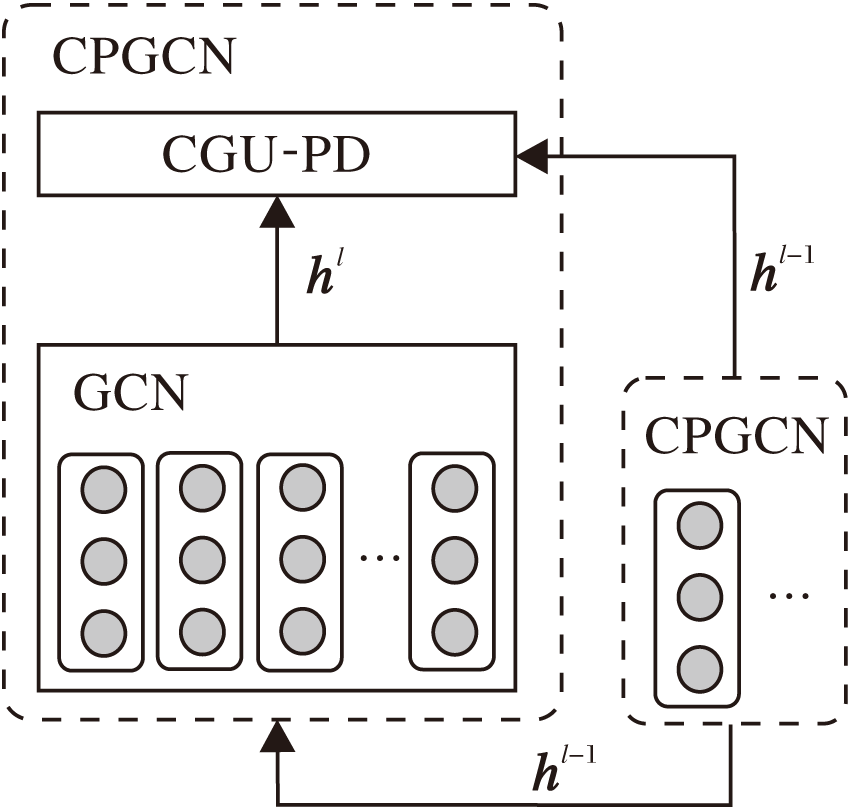 | 图3 CPGCN层的内部结构Fig.3 Internal structure of CPGCN layer |
图3中hl为本层GCN的输出.若本层CPGCN为首层, 则hl-1为Bi-LSTM隐藏层的输出; 否则, hl-1为前一层CPGCN的输出.
基于CGU-PD和GCN构建的CPGCN层可动态调整输入向量和经过GCN变换后的向量在本层输出中的权重.第l层CPGCN的输出向量为:
其中:
HC=[
其中,
CPGCN通过整合GCN和其上一层CPGCN的输出, 有效减少网络传播过程中的信息丢失, 更完整地保留语句的上下文信息.相比常用的LSTM基础网络, 在CPGCN的最终输出向量中, 每个词语都可融合到更大范围内节点的综合语义、语法信息及相互依赖信息.最后通过屏蔽CPGCN最终输出中的非方面词, 获得融合上下文信息的方面特征向量:
本文从词语和短语两个层次考虑特定方面和上下文间的协调, 引入多粒度注意力计算方法(Multi-grained Attention Computing Method, MultiATT), 在不引入训练参数的同时, 计算特征向量间的语义相关性, 为各词语分配多粒度注意力权重, 提升情感分类模型的准确率.
1.3.1 基于双分支的粗粒度注意力计算方法
基于双分支的粗粒度注意力计算方法(Coarse-Grained Attention Computing Method, CATT)主要关注特定方面与上下文在短语级别上的相互影响, 由两组(CATT-avg/CATT-max)结构对称的方面词-上下文和上下文-方面词组成.在CATT中, 使用平均池化的方式分别提取特定方面和完整语句的综合信息, 使用最大池化的方式分别提取两者的代表性信息, 最后使用向量乘积为完整语句或特定方面中的词语分配注意力.最大池化的使用可进一步减少特征向量中冗余信息和噪声的影响.
方面词-上下文侧重描述不同上下文词对特定方面的关注程度, 用于计算各词语特定于某方面的粗粒度注意力.由于特定方面可能涵盖多个词语, 所以对融合上下文信息的方面特征向量采用平均池化的方式生成平均语义向量, 集成其中所有词语的特征, 同时使用最大池化的方式生成主要特征向量, 并利用向量乘积计算特定方面的平均语义向量、主要特征向量分别和语句中各词语间的语义相关性, 从而为所有词语分配注意力.方面词-上下文粗粒度注意力的计算方法如下:
(
其中,
上下文-方面词侧重描述语境对特定方面中各词语的语义表达的影响, 用于计算特定方面中各词语在具体语境中的粗粒度注意力.本文对包含词序信息的语句特征向量采用平均池化的方式生成平均语义向量, 用于整合全句的语义信息, 同时使用最大池化的方式生成主要特征向量, 并使用向量乘积计算语句的平均语义向量、主要特征向量分别和特定方面中各词语间的语义相关性, 从而为特定方面中的各词语分配注意力.上下文-方面词粗粒度注意力的计算方法如下:
(HL)avg=
(HL)max=
其中, HL∈
1.3.2 细粒度注意力计算方法
细粒度注意力计算方法(Fine-Grained Atten-tion Computing Method, FATT)重点关注特定方面与上下文在词级别上的相互影响.粗粒度注意力计算时采用池化的方式计算平均语义向量和主要特征向量, 会导致部分信息丢失, 而基于方面的细粒度注意力计算方法利用方面和语句的特征向量乘积计算语句和方面中词语之间的语义相关性, 从而为所有词语分配注意力, 弥补粗粒度注意力计算产生的信息损失.基于方面的细粒度注意力计算方法如下:
其中, (
本文通过对基于双分支的粗粒度注意力和细粒度注意力进行拼接并求平均, 得到情感分类模型的多粒度注意力.最后通过对多粒度注意力进行归一化操作, 得到多粒度注意力权重:
[
α i=
其中,
CPGCN-MultiATT的情感分类模块根据多粒度注意力权重α i从语句的Bi-LSTM隐藏状态向量HL中筛选与特定方面相关的情感特征.语句的方面级情感表达为
e=
采用交叉熵损失函数和L2正则化作为优化目标:
Loss=-
其中, C表示数据集, si表示语料i,
为了验证模型有效性, 本文采用细粒度情感分析领域的5个公开数据集进行实验.Twitter数据集[21]包含社交软件中用户的评论信息, 情感标签为积极、中性、消极.Lap14、Rest14数据集来源于国际语义测评比赛(International Workshop on Semantic Evaluation, SemEval) 2014, Rest15、Rest16数据集分别来源于SemEval 2015、SemEval 2016, 情感标签为积极、中性、消极、冲突.本文实验所用数据集均移除冲突样本和方面不明确样本.实验数据集的相关信息说明见表1.
| 表1 实验数据集 Table 1 Experimental datasets |
本文实验采用2种词嵌入方法:GloVe和BERT.GloVe词向量的维数为300.不区分大小写的BERT英文预训练模型包含12个隐藏层, 词汇表包含30 522个字符, 生成词向量的维数为768.Bi-LSTM和GCN的隐藏层输出向量的维数均设为300.初始化时将门控权值计算过程中的偏差设为0, 其余可训练的权重和偏差采用均匀分布.CPGCN层数选择3, 实验表明CPGCN层数为3时可取得最优分类性能.在实验中, 批输入顺序随机, 批大小设置为32.对不满32条语料的批次, 从该批次的第1条语料开始依次循环选取已有语料, 使该批语料达到32条.采用标准梯度下降算法对模型进行训练, 优化器使用自适应矩估计(Adaptive Moment Estima-tion, Adam).以分类准确率(简记为Acc)和F1宏平均(简记为F1)作为评价指标.
实验在每个数据集上的迭代次数设为100.为了缓解过拟合, 若实验中连续5次训练结果的F1宏平均没有改善, 终止训练.学习率的取值范围为[0.000 1, 0.01], L2正则化系数的取值范围为[0.000 005, 0.000 05].实验中对学习率和L2正则化系数在相应范围内随机生成, 并在集合{0, 0.1, 0.2, 0.3}中随机选择dropout比例.取最优结果作为最终实验结果.
为了对模型性能进行全面评估, 选取本领域近期的经典模型进行对比实验, 对比模型如下.
1)IAN[15].利用方面词和语句的Bi-LSTM隐藏向量及平均向量计算两者的相互影响.
2)AOA[16].计算方面词和语句的Bi-LSTM隐藏向量的相似矩阵, 使用行和列刻画两者的相互影响.
3)MGAN[17].在IAN和AOA的基础上, 使用方面对齐损失描述具有相同上下文的方面词间的相互影响.
4)TNET-AS[7].基于Bi-LSTM建立上下文转换单元, 生成各词语基于特定方面的语义向量, 并利用CNN从中提取特征.
5)ASGCN[9].利用GCN提取方面词特征, 反馈给Bi-LSTM的隐藏层, 构建基于检索的注意力机制.
6)DGEDT[10].构建双向GCN和双向仿射模块, 使基于图卷积和Transformer的表示学习可以互相强化.
各模型均采用GloVe静态词向量, 在各数据集上的分类准确率和F1宏平均如表2所示, 表中黑体数字表示最优结果.
| 表2 各模型在数据集上的实验结果对比 Table 2 Experimental result comparison of different models on 5 datasets % |
由表2可看出, CPGCN-MultiATT在大部分数据集上的分类准确率和F1宏平均均最优, 这主要是因为CPGCN-MultiATT在GCN层中加入上下文门控单元, 更大程度地整合GCN输出中包含的上下文信息.另外, 本文使用的多粒度注意力计算方法不仅能从词级别和短语级别考虑方面词和上下文之间的相互影响, 还能有效减少噪声信息的影响.相比DGEDT, CPGCN-MultiATT在Rest14、Rest16数据集上的分类准确率分别降低0.95%和0.63%.在Twitter数据集上, TNET-AS获得最优结果, CPGCN-MultiATT在分类准确率和F1宏平均上分别降低0.25%和0.35%, 这主要与Twitter数据集的语料结构松散和语法性能较差的特点有关.TNET-AS利用Bi-LSTM网络构建语句和方面词的语义信息提取单元, 对语法逻辑强且远程词语间关系密切的语句分析能力弱于基于GCN的模型, 因此, 在语法规则不明显的Twitter数据集上分类性能相对较优.
为了验证上下文门控单元和多粒度注意力计算方法对模型分类性能的影响, 在所有数据集上对CPGCN-MultiATT进行消融实验, 得到的分类准确率和F1宏平均如表3所示, 表中w/o表示在完整CPGCN-MultiATT的基础上删除某组成部分, 黑体数字表示最优结果.
| 表3 CPGCN-MultiATT的消融实验结果 Table 3 Ablation experiment results of CPGCN-MultiATT % |
由表3可看出, 使用CGU-PD的模型在所有实验数据集上的准确率和F1宏平均总体上优于不使用CGU-PD的模型, 这说明使用CGU-PD构建的CPGCN可有效减少网络传播过程中的有用信息丢失.由于不同数据集中的语料具有各自的表达特点, 多粒度注意力计算方法中的各组成部分(FATT、CATT-avg、CATT-max)对模型分类性能的影响存在一定程度的差异, 但总体上, FATT、CATT-avg、CATT-max的引入对模型的分类性能提升有明显的促进作用.在Lap14、Rest15、Rest16数据集上, 大多数具有明显情感色彩的词语的独立性较强, 而FATT侧重独立词语在情感表达上的相互影响, 擅长处理用词简练、词语间独立性强且语法相对规范的语句, 所以删除FATT后模型分类性能下降较明显.在Twitter、Rest14数据集上, 大多数词语需要形成短语才能表达完整语义和情感, 而CATT更侧重于综合语义信息的提取, 擅长处理复杂的长句, 所以删除CATT后模型分类性能下降相对明显.另外, 若语料中冗余信息和噪声信息较多, 如Twitter数据集, 而CATT-max采用的最大池化可减少这部分无用信息对模型分类效果的消极影响, 所以删除CATT-max会使模型性能产生较大幅度的下降.
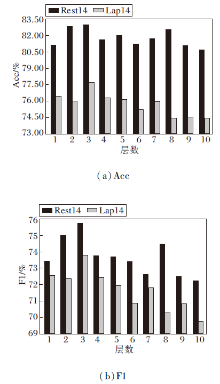
为了观察CPGCN层数对模型分类性能的影响, 为实际应用场景选择合适的神经网络层数, 本文设定CPGCN层数的取值范围为[1, 10].Rest14、Lap14数据集是SemEval在该项任务中提供的结构合理、表达规范、规模适中的系列经典数据集.本文在这2个具有代表性的数据集上对不同网络层数下的CPGCN-MultiATT进行实验, 各层次上的分类准确率和F1宏平均变化趋势如图4所示.
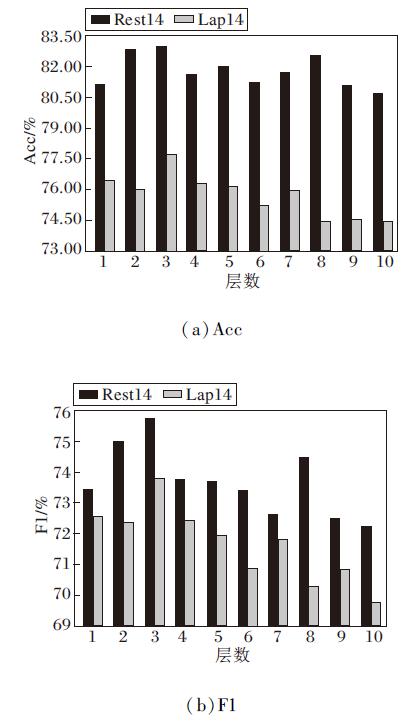 | 图4 CPGCN层数对分类性能的影响Fig.4 Effect of CPGCN layers on classification performance |
由图4可看出, 随着CPGCN层数的增加, 准确率和F1宏平均都呈上升趋势, 当CPGCN层数为3时, 模型分类性能达到最优.随后, 增加CPGCN层数, 两指标整体呈下降趋势, 在层数为7或8时出现波动, 但差于层数为3时的指标.这主要是因为网络深度的增加会使模型训练参数增加, 但是数据集的规模有限, 容易产生过拟合.
利用实验中训练得到的模型及其变体预测具体语料特定于某方面的情感类别, 以可视化的方式展示词语的注意力权重.同句中注意力权重之和为1.颜色越深, 表示词语的注意力权重越高, 对分类结果的影响程度越大.
为了更清楚地展示各粒度注意力对模型分类性能的影响, 随机抽取Rest15数据集上的一条语料, 分别利用CPGCN-MultiATT、CPGCN-CATT、CPGCN-FATT预测方面级情感极性.语料的注意力权重可视化结果如图5所示.
 | 图5 各模型的注意力权重可视化Fig.5 Attention weight visualization on different models |
由图5可看出, CPGCN-MultiATT得出正确的情感分类结果(中性).这条语料的方面词为“ Indian food” , CATT侧重从短语级别分析语句的情感表达, 所以CPGCN-CATT将主要注意力分布在短语“ done really well” 上, 将该语句的情感极性判定为积极.
FATT侧重从词级别分析语句的情感表达, 所以, CPGCN-FATT识别描述性词语“ normal” 和反映程度的“ really” , 将情感积极判定为消极.实际上, “ really well” 描述的对象是方面词“ done” .MultiATT可有效综合两者获取的有用信息, 因此, CPGCN-MultiATT赋予“ normal” 最大的注意力权重, 虽然“ but” 引导的语句后半段的注意力强度仅次于“ normal” , 但并未像CPGCN-CATT、CPGCN-FATT那样给予过分关注, 最终得到正确的情感分类结果.
通过上述分析可得, MultiATT可有效识别主导语句情感的形容词, 并均衡影响程度适中的词语的权重, 准确筛选表达语句情感的关键信息.
BERT预训练语言模型在词嵌入过程中可更好地理解上下文语义, 生成的词向量可更准确表达词语在特定语境中的含义.为了将BERT预训练模型应用于CPGCN-MultiATT, 进一步提升模型的分类性能, 验证BERT预训练模型与CPGCN-MultiATT整合的有效性, 这里在CPGCN-MultiATT中使用BERT预训练模型进行词嵌入, 并进行相关消融实验, 得到的分类准确率和F1宏平均如表4所示.在表中, w/o表示在完整BERT-CPGCN-MultiATT模型的基础上删除某组成部分, 黑体数字表示最优结果.
| 表4 BERT-CPGCN-MultiATT的消融实验结果 Table 4 Results of ablation experiment of BERT-CPGCN-MultiATT % |
由表4可看出, 删除上下文门控单元(w/o CGU-PD)会导致模型在所有数据集上的分类性能下降, 这进一步验证门控单元在减少信息损失方面的有效性.
对比表3和表4的实验结果可发现, 多粒度注意力计算方法中的各组成部分(FATT、CATT-avg、CATT-max)对模型分类性能影响程度的差异基本一致, 并且使用BERT预训练模型进行词嵌入可获得更好的分类准确率和F1宏平均值, 这说明BERT预训练模型可和CPGCN-MultiATT有效整合, 对提升模型的分类性能具有促进作用.在Twitter数据集上, 删除FATT后模型获得最佳性能, 这主要是因为Twitter上的语料主要以口语表述为主, 常包含俗语、比喻、省略等用户习惯性用语, 结构松散、语法性能较差, 所以CATT更适用于Twitter这类语料.
针对方面级情感分类任务, 本文结合自然语言中短文本的特点与GCN的独特性能, 构建基于上下文保持能力的方面级情感分类模型(CPGCN-MultiATT).CPGCN-MultiATT中的CPGCN层具有一定的上下文保持的能力, 可减少GCN在前向传播过程中的信息丢失.同时, 多粒度注意力计算模块通过计算特征向量间的语义相关性, 描述方面词和语句在词级别和短语级别上的相互关系, 使模型分配给各词语的关注强度更合理和均衡, 并控制模型参数的增加, 能在大多数实验数据集上获得更优的分类性能.今后将结合数据集的语料特点, 研究模型结构、门控单元和注意力机制的优化, 进一步提升模型对数据集语料特点的适应性.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|