{kind=link}
{kind=link}
{kind=link}
融合Copulas理论和关联规则挖掘的查询扩展
[黄名选1, 2  , 胡小春
, 胡小春2 ]
, 胡小春]
|
|



作者简介:
胡小春,硕士,副教授,主要研究方向为区块链、数据分析.E-mail:huxch999@163.com.
将Copulas理论引入文本特征词关联模式挖掘,提出融合Copulas理论和关联规则挖掘的查询扩展算法.从初检文档集中提取前列 n篇文档构建伪相关反馈文档集或用户相关反馈文档集,利用基于Copulas理论的支持度和置信度对相关反馈文档集挖掘含有原查询词项的特征词频繁项集和关联规则模式,从这些规则模式中提取扩展词,实现查询扩展.在NTCIR-5 CLIR中英文本语料上的实验表明,文中算法可有效遏制查询主题漂移和词不匹配问题,改善信息检索性能,提升扩展词质量,减少无效扩展词.
AboutAuthor:
HU Xiaochun, master, associate professor. His research interests include blockchain and data analysis.
The Copulas theory is introduced into the association pattern mining of text feature terms, and a query expansion algorithm combining Copulas theory and association rules mining is proposed. Firstly, top n documents of the document set returned by the query are extracted to construct the pseudo-relevance feedback document set (PRFDS) or user relevance feedback document set(URFDS). Then, the support and the confidence based on Copulas theory are applied to mine the feature term frequent itemsets and association rule patterns with the original query terms in PRFDS or URFDS, and the expansion terms are obtained from the patterns to realize query expansion. The experimental results on NTCIR-5 CLIR Chinese and English corpus show that the proposed expansion algorithm effectively restrains the problems of query topic drift and word mismatch, and enhances the performance of information retrieval with the quality of expansion terms improved and the invalid expansion terms reduced.
本文责任编委 林鸿飞
Recommended by Associate Editor LIN Hongfei
查询主题漂移和词不匹配问题长期困扰信息检索系统, 导致检索性能降低.查询扩展(Query Ex-pansion, QE)是解决该类问题的关键技术之一, QE改造原查询权重, 或添加与原查询语义相关的其它特征词, 弥补原查询语义信息不足的缺陷, 达到改善信息检索性能的目的.近年来, 学者们从不同的视角对查询扩展模型及算法展开研究, 取得丰富的研究成果.随着数据挖掘技术的发展, 相关反馈机制下基于关联规则挖掘的查询扩展受到学者们的重视和讨论, 成为该领域的一个研究热点, 其中, 基于关联规则挖掘的伪相关反馈扩展和用户相关反馈扩展研究目前已成为主流.
基于关联规则挖掘的伪相关反馈扩展对伪相关反馈文档集进行特征词关联规则模式挖掘, 从规则模式中抽取扩展词, 实现查询扩展, 改善扩展检索性能.伪相关反馈扩展假定初检结果前列n篇文档与用户查询相关.通常将初检前列n篇文档称为伪相关反馈文档集.伪相关反馈扩展简单高效, 不需要人为交互, 受到学者们的关注和讨论[1, 2, 3, 4].Lü 等[1]提出改善伪相关反馈的Boosting方法.Vaidyanathan等[2]利用词频和词频-逆文档频率(Term Frequency-Inverse Document Frequency, TF-IDF)改善伪相关反馈扩展.Keikha等[3]利用在维基百科语料库中检索得到的伪相关反馈文档集训练分类器, 选择最佳特征的扩展词.Pan等[4]将査询词与候选词的共现语义信息融入传统的Rocchio模型, 改善伪相关反馈扩展性能等.实验表明, 这些成果是有效的.
伪相关反馈扩展的缺陷是扩展词的质量严重受限于伪相关反馈文档的质量和数量.文档质量不高(即与原查询相关度不大), 或与原查询不相关的文档数量较多, 这些将导致查询主题漂移和词不匹配现象, 检索性能不升反而降低.现有研究表明[5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15], 将关联规则挖掘技术引入伪相关反馈扩展, 在一定程度上可缓解上述问题.Latiri等[5]提出基于关联规则挖掘的伪相关反馈扩展方法, 基于Galois 连接理论的冗余关联规则发现方法, 减少冗余关联规则数量, 提高挖掘效率和扩展词质量.Bouziri等[6, 7, 8]对伪相关反馈文档集挖掘关联规则模式, 对关联规则模式进行监督学习[6]或排序学习[7, 8], 试图排除那些冗余关联规则, 找出与原查询更相关的关联规则, 改善扩展词质量.Jabri等[9, 10]利用伪相关反馈文档构造查询语义图, 使用关联规则甄别语义图中虚假扩展词[9], 或使用关联规则建立扩展词关联图, 以此排除那些冗余和虚假的关联规则模式[10].黄名选等[11]提出基于加权关联规则挖掘的伪相关反馈查询扩展方法, 在相同查全率水平级别下平均查准率高于基于无加权模式挖掘的查询扩展.实验验证上述方法可改善信息检索性能.
用户相关反馈扩展[12, 13, 14, 15, 16, 17, 18, 19, 20]是重要的查询扩展方法, 得到学者们深入研究, 王旭阳[12]提出基于本体和用户相关反馈的查询扩展方法.Rahimi等[13]提出基于相关反馈和潜在语义分析的查询扩展.Singh等[14]提出基于波达计数和语义相似性的相关反馈扩展方法.Colace等[15]使用加权词对改善相关反馈扩展, 取得良好的扩展效果.
近年来, 研究人员在用户相关反馈扩展中使用关联规则挖掘技术, 使查询扩展性能得到良好改善.基于关联规则挖掘的用户相关反馈扩展[16, 17, 18, 19, 20]由用户对初检前列n篇文档进行相关性判断, 构建用户相关反馈文档集, 挖掘扩展词, 实现查询扩展, 改善信息检索性能.黄名选提出基于加权关联模式挖掘的越-英跨语言查询扩展[16]、基于项权值排序挖掘的跨语言查询扩展[17]、完全加权模式挖掘与相关反馈融合的印尼-汉跨语言查询扩展[18]、基于矩阵加权关联规则的跨语言查询译后扩展[19]和基于完全加权正负关联模式挖掘的越-英跨语言查询译后扩展[20].实验表明, 上述用户相关反馈扩展检索性能均得到良好改善.
基于关联规则挖掘的相关反馈查询扩展核心问题是关联模式支持度和置信度的设置.当前, 面向查询扩展的关联模式支持度和置信度设置可归纳为三类:1)以项集频度为计算因子[5, 6, 7, 8, 21], 忽略项集权重, 导致冗余和虚假的关联模式增多, 扩展词质量难以保证; 2)设置只考虑项集权重[16], 忽略项集频度, 得到的关联模式难以全面反映特征词间固有关联; 3)设置同时考虑项集频度和项集权重[17, 19, 20, 22], 克服上述缺陷, 取得较好的扩展词挖掘效果, 扩展检索性能得到改善, 但是, 支持度设置只是将项集频度和项集权重简单组合, 缺乏理论依据, 需进一步探讨扩展性能潜力.
事实上, 文本特征词项集在文本事务数据库中存在以项集频度为度量的古典概型分布和以项集权值为度量的概率分布, 在进行关联模式支持度和置信度设置时应考虑这些概率分布, 才能设置更合理的支持度和置信度.针对上述问题, 本文借鉴Copulas理论[23], 融合上述两种概率分布, 给出基于Copulas理论的关联模式支持度与置信度, 提出融合Copulas理论和关联规则挖掘的查询扩展算法(Query Expansion Based on Copulas Theory and Asso-ciation Rules, QE_CTAR), 解决信息检索领域中长期困扰的查询主题漂移和词不匹配问题.
假设初检文档集(Document Set, DocSet)表示为{d1, d2, …, dn}, 其中, n为文档数, di (i=1, 2, …, n)为DSet中的第i篇文档, 每篇文档di表示为特征词项集合{
Sklar[23]提出Copulas函数理论, 用于描述变量间相关性, 将任意形式的分布合并连接为有效的多元分布函数, 在信息检索领域得到应用[24, 25], 取得良好效果.假设二维随机向量Y=(y1, y2), 具有连续的边缘分布函数H(y1)、H(y2), 由Sklar's定理[26]可知, 存在一个Copula函数C(H(y1), H(y2)), 使得二维联合分布函数
H(y1, y2)= C(H(y1), H(y2)),
及Copulas统一描述二维随机向量的累积分布函数[24]:
C(H(y1), H(y2))=exp(lg(H(y1))+lg(H(y2))).
在特征词关联规则挖掘中, 本文将一篇文档作为事务, 特征词作为项目, 文档数据库即为文本事务数据库.以特征词项集(T1∪ T2)出现的频度为度量的概率, 记为Pcount(T1∪ T2); 以项集权重为度量的概率, 记为Pweight(T1∪ T2).
根据古典概型思想,
pcount(T1∪ T2)=
其中, Count(T1∪ T2)表示项集(T1∪ T2)在文本事务数据库中出现的频度, DocCount表示文本事务数据库总文档数量.
借鉴几何概型计算方法,
pweight(T1∪ T2)=
其中, Weight(T1∪ T2)表示项集(T1∪ T2)在文本事务数据库中拥有的项集权重, ItemsWeight表示文本事务数据库中全体特征词项目的权重累加和.
借鉴Copulas统一描述二维随机向量的累积分布函数, 基于 Copulas理论的特征词项集(T1∪ T2)支持度CopSup(Copulas Based Support)和关联规则(T1→ T2)置信度CopCon(Copulas Based Confi-
dence)定义如下:
CopSup(T1∪ T2)=exp(lg(Pcount(T1∪ T2))+lg(Pweight(T1∪ T2))),
CopCon(T1→ T2)=
给定最小支持度阈值ms和最小置信度阈值mc, 本文将
CopSup(T1∪ T2)≥ ms
的项集(T1∪ T2)称为频繁项集, 将CopSup(T1∪ T2)≥ ms且CopCon(T1→ T2)≥ mc的特征词关联规则T1→ T2称为强关联规则.
查询扩展的目的是为了获得与原查询高度相关的扩展词, 在相关反馈中, 这些扩展词都来自初检伪相关反馈文档集或用户相关反馈文档集.文档集中的特征词与原查询越相关, 检索到该特征词的初检文档数量应该越多, 该特征词的重要性越大, 应该获得越高的权重.为此, 本文在计算文档集特征词权值时采用文献[17]的特征词权值wij计算方法:
wij=
其中, dfj表示含有特征词tj的初检伪相关文档数量, tfj, i表示特征词tj在文档di中的出现次数, 即词频, max(tfi)表示初检伪相关文档di中出现的最大词频值, wij表示初检伪相关文档di中特征词tj的权值.
为了提高扩展词的挖掘效率, 在挖掘过程中, 只挖掘含有原查询词项的频繁项集和关联规则, 因此, 项集剪枝策略是:在挖掘到特征词2_项集时, 剪除那些不含原查询词项的候选2_项集.
本文扩展词来源于基于Copulas理论的关联规则后件, 并且该关联规则的前件必须是查询词项集, 以及支持度CopSup()≥ ms和置信度CopCon()≥ mc.由于关联规则置信度反映查询词项和扩展词项之间的确定性和可信程度, 值越高, 表明查询词与扩展词越相关, 因此, 本文将置信度值作为扩展词的权值wEt的计算依据:
wEt=MAX(
其中, MAX()表示关联规则置信度的最大值, 即当多个关联规则模式中同时出现相同的扩展词时, 取置信度值最大的作为该扩展词的权值.
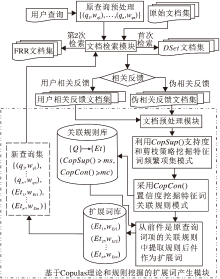
融合Copulas理论和关联规则挖掘的查询扩展的基本思想是:首先将原始查询检索原始文档集, 得到初检前列文档集(DSet文档集), 再根据相关反馈类型(伪相关反馈或用户相关反馈)从DSet文档集构建初检伪相关反馈文档集或初检用户相关反馈文档集.然后, 利用CopSup()支持度和剪枝策略挖掘初检伪相关反馈文档集(或初检用户相关反馈文档集)中含有原查询词项的特征词频繁项集模式, 采用CopCon()置信度从特征词频繁项集中挖掘含有原查询词项的关联规则模式, 从前件是原查询词项的关联规则模式中提取规则后件作为扩展词, 实现查询扩展.最后, 合并扩展词和原查询, 再次检索原始文档集, 得到最终检索结果(Final Retrieval Results, FRR).
根据上述思想, 本文给出融合Copulas理论和关联规则挖掘的查询扩展算法(QE_CTAR), 具体步骤如下.
算法 QE_CTAR
输入 ms, mc, Q, n, Litem
输出 NewQ, FRR
Begin
DSet← RetrievalOriginalDS(Q, n);
//原始查询Q检索原始文档集, 根据相关反馈类型
提取初检相关文档集DSet
{DSetIndexDB, AllTermDB}←
Pretreatment-DocSet(DSet);
//对初检相关文档集DSet进行预处理
L1← MiningFIS(DSetIndexDB, AllTermDB, ms, 1);
//挖掘1_频繁项集L1
CoFIS← CoFIS∪ L1;
//1_频繁项集L1添加到频繁项集集合CoFIS
for(k=2;
//挖掘k_频繁项集Lk(k> 1)
{
Ck← Ck∪ Lk-1;
if(k=2)then
C2← PruningNotQ(C2, Q);
//剪枝不含原查询词项Q的2_候选项集C2
Lk←
Mining FIS(DSetIndexDB, AllTermDB, ms, k);
CoFIS← CoFIS∪ Lk;
//挖掘k_频繁项集Lk, 添加到频繁项集集合CoFIS
if(k> Litem) then Break;
}
For each itemset Lkin CoFIS do
//挖掘含有原查询词项qi的关联规则qi→ Eti
For each itemset(qi, Eti) in Lkdo
If ((CopCon(qi→ Eti)> =mc)and
(qi∪ Eti =Lk)and(qi∩ Eti=Ø )
and(qi⊆Q))then
CoAR← CoAR∪ {qi→ Eti };
// CoAR为关联规则集合
(Et, wEt)← GetExpansionTerm(CoAR);
//从关联规则集合中提取扩展词Et及其权值wEt
NewQ= Q∪ Et;
//扩展词与原查询组合构成新查询NewQ
FRR← RetrievalOriginalDS(NewQ);
//新查询NewQ检索原始文档集得到最终检索结果
FRR
Return NewQ, FRR;
End
QE_CTAR中函数描述如下:
函数 RetrievalOriginalDS(Q, n)
//原始查询Q检索原始文档集, 根据相关反馈类型
提取初检相关文档集DSet
输入 Q, n
输出 DSet
Begin
Q预处理后检索原始文档集, 得到初检结果文档;
If 相关反馈类型为PRF then
DSet← {从初检结果文档中提取前列n篇初检
文档, 得到初检伪相关反馈文档集};
Else
DSet← {用户对初检前列n篇文档进行相关性
判断, 得到初检用户相关反馈文档集};
Return DSet;
End
函数 PretreatmentDocSet(DSet)
//预处理初检相关文档集DSet
输入 DSet
输出 DSetIndexDB, AllTermDB
Begin
对文档集DSet去除停用词(中文:分词, 英文:词
干提取);
提取特征词和计算特征词权值;
构建文档集DSet索引库(DSetIndexDB)和全体
特征词库(AllTermDB);
Return DSetIndexDB, AllTermDB;
End
函数 Mining FIS(DSetIndexDB, AllTermDB, ms, k)
//对初检相关文档集DSet挖掘k_频繁项集Lk
输入 DSetIndexDB, AllTermDB, ms, k
输出 Lk
Begin
if(k=1)then
从AllTermDB库中提取特征词作为1_候选项
集C1;
扫描DSetIndexDB库, 统计k_候选项集Ck的频度
及其权值, 计算Ck的CopSup(Ck);
Lk={Ck |CopSup(Ck)> = ms};
Return Lk;
End
函数 PruningNotQ(C2, Q)
//剪枝不含原查询词项Q的2_候选项集C2
输入 C2, Q
输出 含原查询词项的C2
Begin
if(C2不含原查询词项Q)then Delete C2;
Return含原查询词项的C2;
End
函数 GetExpansionTerm(CoAR);
//从关联规则集合中提取扩展词Et及其权值wEt
输入 CoAR
输出 Et, wEt
Begin
Et← {从CoAR中提取关联规则qi→ Eti的后件
项集Eti};
wEt← {从CoAR中提取关联规则qi→ Eti的
置信度CopCon(qi→ Eti)};
Return Et, wEt;
End
在算法中, Litem表示候选项集长度阈值, Q={q1, q2, …, qs}表示原查询, NewQ表示扩展词和原查询Q组合后得到的新查询, FRR表示最终检索结果, n表示初检前列文档数, PRF表示伪相关反馈(Pseudo Relevance Feedback), URF表示用户相关反馈(User Relevance Feedback).
本文算法框图如图1所示.
 | 图1 本文方法框图Fig.1 Framework of the proposed method |
本文选择NTCIR-5 CLIR(http://research.nii.ac.jp/ntcir/ data/ data-en.html)中文文本语料(共计342 586篇中文文档)和英文文本语料(共计42 685篇英文文档)作为实验数据, 具体如表1所示.
| 表1 实验数据集 Table 1 Experimental datasets |
除文档集外, NTCIR-5 CLIR语料有查询集和结果集.查询集有50个查询, 每个查询有4种类型查询主题.结果集有Rigid和Relax标准, Rigid 表示与查询高度相关和相关的情况, Relax表示与查询高度相关、相关和部分相关情况.本文采用TITLE和Descrip-
tion(为DESC)查询主题进行检索实验, 其中, TITLE查询以名词和名词性短语简要描述查询主题, DESC查询以句子形式简要描述查询主题.
实验将文档集和查询集的繁体中文全部转换为简体中文.中文语料预处理采用盘古分词(https://archive.codeplex.com/?p=pangusegment), 对文档集和查询集进行分词, 去除中文停用词.英文语料预处理采用Porter程序(http://tartarus.org/~martin/PorterStemmer)进行词干提取, 去除英文停用词.
本文实验分为伪相关反馈扩展实验和用户相关反馈扩展实验, 前者在中文语料集上进行, 后者在英文语料集上进行.开源的全文检索引擎开发包Lucene.Net(http://lucenenet.apache.org)作为基础检索环境, 在此基础上编写本文算法和对比算法的实验源程序, 验证本文算法的伪相关反馈扩展和用户相关反馈扩展性能及有效性.
本文将原始查询提交到Lucene.Net进行初次检索, 得到的检索结果作为基准检索(Baseline Retrieval, BLRetrieval)结果, 并根据Lucene.Net提供的查询与文档相似度值, 提取初检前列n篇文档作为伪相关反馈文档集和用户相关性判断.为了简便, 将初检前列n篇文档中含有已知结果集上的相关文档视为用户相关性判断结果文档, 构建初检用户相关反馈文档集.检索评价指标是平均查准率均值(Mean Average Precision, MAP)和P@5.伪相关反馈中n=20, 用户相关反馈中n=50.
选择如下对比算法.
1)QE_ARM(QE Based on Association Rules Mining).采用文献[10]的基于关联规则挖掘的查询扩展方法.参数定义如下.在PRF中:候选项集长度阈值Litem=2, ms=0.2, mc=0.3, 提升度为0.1, Jaccard相似系数为0.45, 信息增益为0.2.在URF中:ms=0.25, 0.3, 0.35, 0.4, 0.45, mc=0.1, 提升度为0.1, Jaccard相似系数为0.45, 信息增益为0.2, Litem=2.
2)QE_MWARM(QE Based on Matrix-Weighted Association Rules Mining).采用文献[19]的矩阵加权关联规则挖掘技术挖掘扩展词, 实现查询扩展.参数定义如下.在PRF中:ms=0.1, 0.12, 0.14, 0.16, 0.18, mc=0.1, mi=0.1, Litem=3.在URF中:mc=0.1, mi=0.1, ms=0.35, 0.4, 0.45, 0.47, 0.5, Litem=2.
3)QE_AWPNAPM(QE Based on All-Weighted Positive and Negative Association Patterns Mining).采用文献[20]的完全加权正负关联模式挖掘技术挖掘加权正负扩展词, 在正扩展词中去除负扩展词后得到最终扩展词.参数定义如下.在PRF中:ms=0.09, 0.1, 0.11, 0.13, 0.15, mc=0.1, α =0.3, 最小正项集关联度阈值为0.1, 最小负项集关联度阈值为0.01, Litem=3.在URF中:ms=0.1, 0.15, 0.2, 0.25, 0.3, mc=0.1, α =0.3, 最小正项集关联度阈值为0.1, 最小负项集关联度阈值为0.01, Litem=2.
4)QE_WMMSM(QE Based on Weighted Multiple Minimum Supports Mining).采用文献[22]的基于多支持度阈值的频繁模式挖掘技术挖掘规则前件为原查询词项的加权关联规则, 将规则后件作为扩展词.参数定义如下.在PRF中:mc=0.1, 最小支持度的下界为0.2, 上界为0.25, 项集加权阈值为0.1, ms=0.2, 0.25, 0.3, 0.35, 0.4, Litem=3.在URF中:ms=0.4, 0.5, 0.6, 0.7, 0.8, mc=0.1, 最小支持度的下界为0.2, 上界为0.25, 项集加权阈值为0.1, α =0.1, β =0.5, Litem=2.
3.3.1 各算法的扩展检索性能对比
实验源程序以及Lucene.Net运行后得到各算法的MAP和P@5的平均值, 如表2~表9所示, 表2~表5为伪相关反馈扩展实验结果, 表6~表9为用户相关反馈扩展实验结果.表中平均增幅是指QE_CTAR相对于其它算法的平均增幅, 具体如下:先计算QE_CTAR在各数据集上的增幅, 然后累加这些增幅再除以4, 得到总的平均增幅.例如, QE_CTAR相对基准BLRetrieval的平均增幅如下:
平均增幅=(((0.4834-0.4278)÷ 0.4278+
(0.2657 -0.1992)÷ 0.1992+
(0.3521-0.3049)÷ 0.3049+
(0.3762-0.3144)÷ 0.3144)× 100)÷ 4=
20.38%,
其余类似.
QE_CTAR实验参数设置如下.在PRF中:ms=0.008, 0.009, 0.01, 0.011, 0.012, mc=0.1.在URF中:ms=0.008, 0.009, 0.01, 0.011, 0.012, mc=0.1.
由表2~表9可知, QE_CTAR在中英文本语料上的检索结果都得到改善, MAP和P@5平均值都为最高值, 具体如下.
1)对比BLRetrieval, QE_CTAR伪相关反馈扩展MAP平均增幅最低可达17.39%, P@5平均增幅最低可达13.32%, 而用户相关反馈的MAP平均增幅最低可达47.06%, P@5平均增幅最低可达47.42%, 扩展检索性能改善效果显著.
| 表2 各算法TITLE查询的伪相关反馈检索的MAP值 Table 2 MAP values of PRF retrieval of TITLE queries for different algorithms |
| 表3 各算法DESC查询的伪相关反馈检索的MAP值 Table 3 MAP values of PRF retrieval of DESC queries for different algorithms |
| 表4 各算法TITLE查询的伪相关反馈检索的P@5值 Table 4 P@5 values of PRF retrieval of TITLE queries for different algorithms |
| 表5 各算法DESC查询的伪相关反馈检索的P@5值 Table 5 P@5 values of PRF retrieval of DESC queries for different algorithms |
| 表6 各算法TITLE查询的用户相关反馈检索的MAP值 Table 6 MAP values of URF retrieval of TITLE queries for different algorithms |
| 表7 各算法DESC查询的用户相关反馈检索的MAP值 Table 7 MAP values of URF retrieval of DESC queries for different algorithms |
| 表8 各算法TITLE查询的用户相关反馈检索的P@5值 Table 8 P@5 values of URF retrieval of TITLE queries for different algorithms |
| 表9 各算法DESC查询的用户相关反馈检索的P@5值 Table 9 P@5 values of URF retrieval of DESC queries for different algorithms |
2)对比其余算法, QE_CTAR伪相关反馈扩展MAP平均增幅范围为4.40%~18.76%, P@5平均增幅范围为2.41%~12.98%, 用户相关反馈扩展MAP平均增幅范围为-0.41%~34.97%, P@5平均增幅范围为0.00%~31.16%.以上数据说明QE_CTAR扩展检索性能高于同类的对比算法, 用户相关反馈扩展的平均增幅高于伪相关反馈扩展.
3)QE_CTAR的DESC查询的检索结果的MAP平均增幅高于TITLE查询.伪相关反馈扩展DESC查询MAP平均增幅范围为6.13%~18.76%, TITLE查询MAP平均增幅范围为4.40%~15.04%; 用户相关反馈扩展DESC查询的P@5平均增幅范围为2.84%~34.97%, TITLE查询的P@5平均增幅范围为-0.41%~33.62%.上述结果说明QE_CTAR对DESC查询整体扩展性能的提升更有效.
4)对比算法的伪相关反馈扩展存在少量MAP和P@5值小于BLRetrieval的情况, 说明对比算法存在严重的查询主题漂移, 导致检索性能下降, 而QE_CTAR检索结果的MAP值都高于BLRetrieval, 没有出现上述情况, 说明QE_CTAR更能改善检索性能, 遏制查询主题漂移.例如, 表2的对比算法QE_ARM(伪相关反馈扩展)在CM0数据集上检索的MAP平均值(TITLE查询)低于基准检索, 降幅为2.4%(Relax)和13.98%(Rigid), 说明出现严重的查询主题漂移现象.本文以No.24 TITLE查询为实例说明该问题.
No.24 TITLE查询原文是:“ 经济舱、综合症候群、航班” , 经盘古分词和预处理后为:“ 经济舱、综合症候群、航班” .No.24 TITLE查询的对比算法QE_ARM在CM0数据集上挖掘得到的扩展词如下:“ 包括、报导、表示、大、都、飞机、飞行、航、航空、航空公司、后、会、活动、机场、机票、记者、来回、两、旅客、旅游、免费、名、日、上、说、台北、台湾、推出、小时、新、行程、英国、元、早餐、增加、住宿” , 经扩展词有效性测试发现, 有效的扩展词(即能提高MAP值)是飞行、后、名等扩展词, 其余扩展词都是无效扩展词(即不能提高MAP值), 由此可见, QE_ARM对比算法得到的扩展词大部分都是无效的, 大量无效扩展词的存在导致查询主题漂移, 扩展后的检索性能降低, 即No.24 TITLE查询的所有扩展词和原查询组合为新查询后的检索结果的MAP值为0.116 7(Relax)和0.110 4(Rigid), 比其对应的基准检索结果的MAP值0.716 4(Relax)和0.714 3(Rigid)低很多.
由表6和表8可知, 本文算法用户相关反馈扩展TITLE查询的MAP值低于QE_WMMSM, 降低0.41%, P@5平均增幅没有增长, 说明QE_CTAR用户相关反馈扩展检索性能存在不稳定因素, 还需进一步研究.
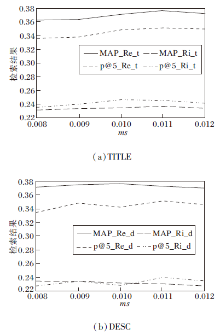
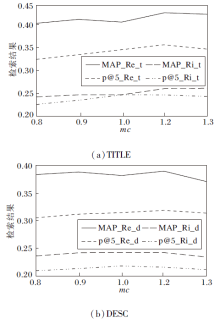
3.3.2 参数ms和mc设置对检索性能的影响
本节以伪相关反馈扩展为例, 分析和对比QE_CTAR参数ms和mc的设置对扩展检索性能的影响.设置mc=0.1, ms=0.008, 0.009, 0.010, 0.011, 0.012, QE_CTAR伪相关反馈扩展实验在4个中文文本数据集上进行, MAP和P@5平均值如图2所示.同理, 设置ms=0.008, mc=0.8, 0.9, 1.0, 1.2, 1.3, 扩展检索结果如图3所示.图中后缀Re_t表示TITLE查询检索结果按Relax标准统计, 后缀Re_d表示DESC查询检索结果按Relax标准统计, 后缀Ri_t表示TITLE查询检索结果按Rigid标准统计, 后缀Ri_d表示DESC查询检索结果按Rigid标准统计.
 | 图2 ms不同时本文算法两类查询的检索结果Fig.2 Retrieval results of 2 kinds of queries of the proposed algorithm with different ms values |
 | 图3 mc不同时本文算法两类查询的检索结果Fig.3 Retrieval results of 2 kinds of queries of the proposed algorithm with different mc values |
由图2和图3可知, 随着ms阈值的逐渐增大, 检索结果评价指标值大部分上呈现缓慢上升的趋势, 说明随着支持度阈值的提高, 本文算法挖掘的扩展词质量得到提高, 扩展检索性能得到改善.而随着mc阈值增大, 大部分指标值开始呈现缓慢上升趋势, mc到1.2时变为缓慢下降.
综上所述, ms和mc对QE_CTAR检索结果的各个指标值的影响不尽相同, 变化规律还需进一步研究.
3.3.3 查询实例扩展词的有效性分析
本节以No.8查询DESC主题实例为实例, 分析该查询实例扩展词的有效性, 进一步说明本文算法能有效遏制查询主题漂移和词不匹配问题.首先, No.8查询DESC主题实例在CE0数据集上运行QE_CTAR(伪相关反馈扩展)和QE_WMMSM、QE_AWPNAPM, 得到扩展词及其权值, 然后, 对各个扩展词进行有效性测试.本文将测试后能提升检索性能MAP值的扩展词称为有效扩展词, 否则, 称为无效扩展词.
扩展词有效性测试方法是:将原始查询和要测试的扩展词组合为新查询进行扩展检索, 看检索结果MAP值是否高于基准检索值, 如果高于, 该扩展词为有效扩展词, 否则, 为无效扩展词.
表10列举各算法No.8查询有效扩展词和无效扩展词实例.对应的扩展词数、MAP和P@5值在表11中列出, 其中MAP列的括号值为本文算法或对比算法相对于基准检索的提高幅度(+表示提升, -表示降低).本次实验参数如下.在QE_CTAR中:ms=0.008, mc=0.8.在QE_WMMSM中:ms=0.35, mc=0.1.在QE_AWPNAPM中:ms=0.09, mc=0.1.No.8查询实例原文是:“ 查询电脑病毒「我爱你」造成个人电脑大瘫痪的相关报导” .盘古分词结果为:电脑病毒 我爱你 造成 个人电脑 大 瘫痪.去除DESC查询主题描述都存在的词:查询、相关、报导.
由表10和表11可知, 从No.8查询DESC主题实例的检索结果看出, QE_WMMSM和QE_AWPNAPM获得的扩展词数量较多, 其中, 无效扩展词也很多, 占扩展词数分别为64.47%和73.85%.另外, 对比BLRetrieval, QE_WMMSM的MAP值提高9.41%(Relax)和5.24%(Rigid), QE_AWPNAPM下降17.23%和32.06%, 说明对比算法存在的无效扩展词数量较多, 导致扩展检索过程中发生查询主题漂移现象, 检索性能下降.而QE_CTAR的扩展词数量明显减少, 无效扩展词也很少, 仅占21.43%, MAP值高于对比算法, 比基准检索提高32.91%和16.52%, 说明本文算法的扩展词质量得到提升, 提高信息检索性能, 有效遏制查询主题漂移和词不匹配问题.
综上所述, 本文算法可改善信息检索性能, 遏制查询主题漂移和词不匹配问题, 因此是有效的.实验结果表明, 本文算法伪相关反馈扩展和用户相关反馈扩展的MAP和P@5平均值较高, 扩展词质量得到有效提升, 无效扩展词明显减少, 用户相关反馈扩展的MAP和P@5平均增幅高于伪相关反馈扩展, 对DESC查询整体扩展性能的提升更有效.
本文算法的有效性主要原因分析如下:1)本文借鉴Copulas统一描述二维随机向量的累积分布函数, 将文本特征词的两种重要概率分布统一表示为关联模式支持度, 使特征词关联模式的评价更合理和更能反映特征词固有的关联.2)提出融合Copulas理论和关联规则挖掘的查询扩展算法, 采用支持度和置信度评价关联模式, 获得的扩展词质量得到改善, 即扩展词噪音减少, 与原查询关联程度较高的有效扩展词增多.上述两个方面共同作用, 使本文算法优于基准检索和近年来同类的对比扩展算法, 遏制查询主题漂移和词不匹配问题, 有效改善信息检索性能.
查询主题漂移和词不匹配问题一直是信息检索领域中学者们关注的问题, 本文针对该问题, 将Copulas理论引入关联模式挖掘, 提出基于Copulas理论的支持度与置信度, 在此基础上提出融合Copulas理论和关联规则挖掘的查询扩展算法.利用提出的支持度和置信度对初检伪相关反馈文档集或用户相关反馈文档集挖掘高质量的扩展词, 实现查询扩展.实验表明, 本文算法有效, 扩展词质量得到有效提升, 无效扩展词明显减少, 可遏制查询主题漂移和词不匹配问题, 改善信息检索性能, 检索性能高于基准检索和同类对比算法.本文算法可用于跨语言查询扩展, 支持度和置信度可用于其它文本挖掘任务和推荐系统, 以提高其性能.下一步的研究是继续优化关联模式参数, 将本文算法应用到实际的信息检索系统中.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|