{kind=link}
{kind=link}
{kind=link}
{kind=link}
序列多智能体强化学习算法
[史腾飞1  , 王莉
, 王莉1 , 黄子蓉1 ]
, 王莉, 黄子蓉]
|
|



作者简介:

史腾飞,硕士研究生,主要研究方向为强化学习.E-mail:373321502@qq.com.

黄子蓉,硕士研究生,主要研究方向为强化学习.E-mail:453774012@qq.com.
针对当前多智能体强化学习算法难以适应智能体规模动态变化的问题,文中提出序列多智能体强化学习算法(SMARL).将智能体的控制网络划分为动作网络和目标网络,以深度确定性策略梯度和序列到序列分别作为分割后的基础网络结构,分离算法结构与规模的相关性.同时,对算法输入输出进行特殊处理,分离算法策略与规模的相关性.SMARL中的智能体可较快适应新的环境,担任不同任务角色,实现快速学习.实验表明SMARL在适应性、性能和训练效率上均较优.
AboutAuthor:
SHI Tengfei, master student. His research interests include reinforcement learning.
HUANG Zirong, master student. Her research interests include reinforcement lear-ning.
The multi-agent reinforcement learning algorithm is difficult to adapt to dynamically changing environments of agent scale. Aiming at this problem, a sequence to sequence multi-agent reinforcement learning algorithm(SMARL) based on sequential learning and block structure is proposed. The control network of an agent is divided into action network and target network based on deep deterministic policy gradient structure and sequence-to-sequence structure, respectively, and the correlation between algorithm structure and agent scale is removed. Inputs and outputs of the algorithm are also processed to break the correlation between algorithm policy and agent scale. Agents in SMARL can quickly adapt to the new environment, take different roles in task and achieve fast learning. Experiments show that the adaptability, performance and training efficiency of the proposed algorithm are superior to baseline algorithms.
本文责任编委 陈恩红
Recommended by Associate Editor CHEN Enhong
在多智能体强化学习(Multi-agent Reinforce-ment Learning, MARL)技术中, 智能体与环境及其它智能体交互并获得奖励(Reward), 通过奖励得到信息并改善自身策略.多智能体强化学习对环境的变化十分敏感, 一旦环境发生变化, 训练好的策略就可能失效.智能体规模变化是一种典型的环境变化, 可造成已有模型结构和策略失效.针对上述问题, 需要研究自适应智能体规模动态变化的MARL.
现今MARL在多个领域已有广泛应用[1], 如构建游戏人工智能(Artificial Intelligence, AI)[2]、机器人控制[3]和交通指挥[4]等.MARL研究涉及范围广泛, 与本文相关的研究可分为如下3方面.
1)多智能体性能方面的研究.多智能体间如何较好地合作, 保证整体具有良好性能是所有MARL必须考虑的问题.Lowe等[5]提出同时适用于合作与对抗场景的多智能体深度确定性策略梯度(Multi-agent Deep Deterministic Policy Gradient, MADDPG), 使用集中训练分散执行的方式让智能体之间学会较好的合作, 提升整体性能.Foerster等[6]提出反事实多智能体策略梯度(Counterfactual Multi-agent Policy Gradients, COMA), 同样使用集中训练分散执行的方式, 使用单个Critic多个Actor的网络结构, Actor网络使用门控循环单元(Gate Recurrent Unit, GRU)网络, 提高整体团队的合作效果.Wei等[7]提出多智能体软Q学习算法(Multi-agent Soft Q-Learning, MASQL), 将软Q学习(Soft Q-Learning)算法迁至多智能体环境中, 多智能体采用联合动作, 使用全局回报评判动作好坏, 一定程度上提升团队的合作效果.上述算法在一定程度上提升多智能体团队合作和对抗的性能, 但是均存在难以适应智能体规模动态变化的问题.
2)多智能体迁移性方面的研究.智能体的迁移包括同种环境中不同智能体之间的迁移和不同环境中智能体的迁移.研究如何较好地实现智能体的迁移可提升训练效率及提升智能体对环境的适应性.Brys等[8]通过重构奖励实现智能体策略的迁移.虽然可解决智能体策略的迁移问题, 但在奖励重构的过程中需要耗费大量资源.Taylor等[9]提出在源任务和目标任务之间通过任务数据的双向传输, 实现源任务和目标任务并行学习, 加快智能体学习的进度和智能体知识的迁移, 但在智能体规模巨大时, 训练速度仍然有限.Mnih等[10]通过多线程模拟多个环境空间的副本, 智能体网络同时在多个环境空间副本中进行学习, 再将学习到的知识进行迁移整合, 融入一个网络中.该方法在某种程度上也可视作一种知识的迁移, 但并不能直接解决规模变化的问题.
3)多智能体可扩展性和适应性方面的研究.在实际应用中, 智能体的规模通常不固定并且十分庞大.当前一般解决思路是先人为调整设定模型的网络结构, 然后通过大量再训练甚至是从零训练, 使模型适应新的智能体规模.这种做法十分耗时耗力, 根本无法应对智能体规模动态变化的环境.Khan等[11]提出训练一个可适用于所有智能体的单一策略, 使用该策略(参数共享)控制所有的智能体, 实现算法可适应任意规模的智能体环境.但是该方法未注意到智能体规模对模型网络结构的影响.Zhang等[12]提出使用降维方法对智能体观测进行表征, 将不同规模的智能体的观测表征在同个维度下, 再将表征作为强化学习算法的输入.该方法本质上是扩充模型网络可接受的输入维度大小, 但当智能体规模持续扩大时, 仍会超出模型网络的最大范围, 从而导致模型无法运行.Long等[13]改进MADDPG, 使用注意力机制进行预处理观测, 再将处理后的观测输入MADDPG, 使用编码器(Encoder)实现注意力网络.该方法在一定程度上可适应智能体规模的变化, 但在面对每次智能体规模变动时, 均需要重新调整网络结构和进行再训练.
针对智能体规模动态变化引发的MARL失效的问题, 本文提出序列多智能体强化学习算法(Sequence to Sequence Multi-agent Reinforcement Learning Algorithm, SMARL).SMARL中的智能体可较快适应新的环境, 担任不同任务角色, 实现快速学习.
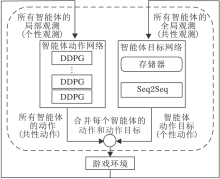
SMARL的核心思想是分离模型网络结构和模型策略与智能体规模的相关性, 具体框图见图1.
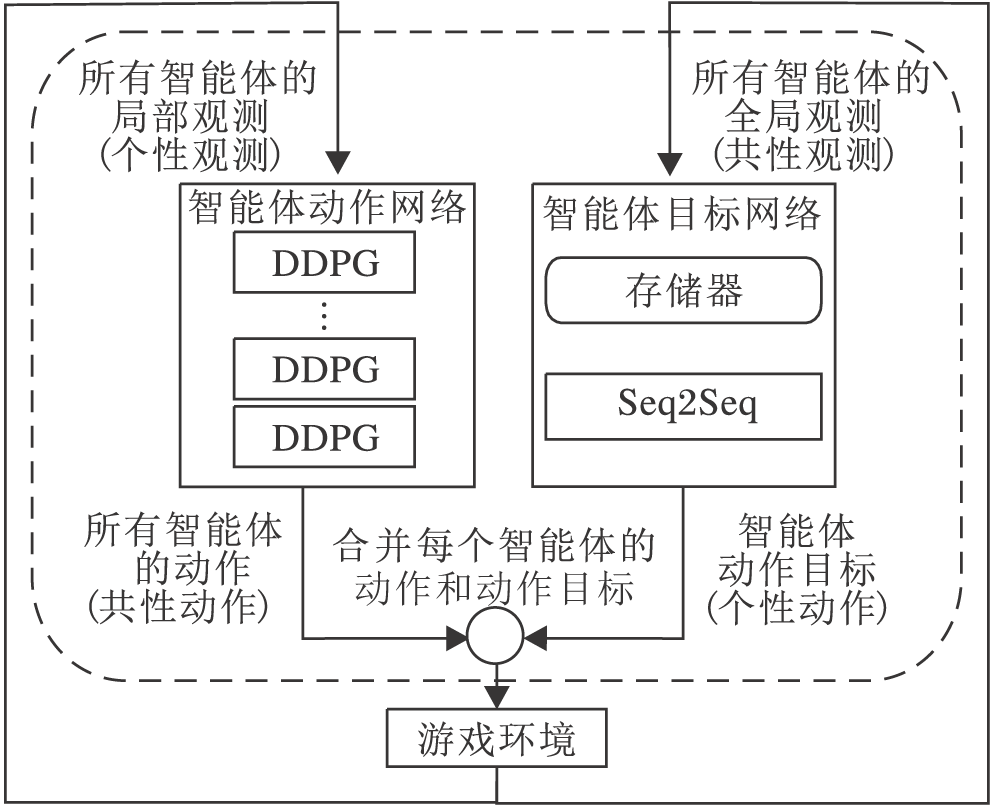 | 图1 SMARL框图Fig.1 Framework of SMARL |
首先在结构上, 将智能体的控制网络划分为2个平行的模块— — 智能体动作网络(图1左侧)和智能体目标网络(图1右侧).每个智能体的执行动作由这两个网络的输出组成.为了适应算法结构, 划分智能体的观测数据和动作数据.智能体的观测分为每个智能体的局部观测和所有智能体的全局观测, 本文称为个性观测和共性观测.个性观测不会随智能体规模变化而变化.同理, 算法中对智能体动作也分成智能体的共性动作和个性动作, 所有智能体动作集的交集为共性动作, 某智能体的动作集与共性动作的差集为该智能体的个性动作.共性动作为智能体的执行动作, 个性动作为智能体执行动作的目标.共性动作不会随智能体规模变化而变化.每个智能体执行的动作由共性动作和个性动作共同组成.
举例说明, 在二维格子世界中存在3个可移动且能相互之间抛小球的机械手臂.它们的共性观测是统一坐标系下整个地图的观测, 个性观测是以自身为坐标原点的坐标系下的观测.它们的共性动作为上、下、左、右抛.个性动作由智能体ID决定:0号智能体的个性动作为1号、2号; 1号智能体的个性动作为0号、2号; 2号智能体的个性动作为0号、1号.
经过上述分割, 算法将与智能体规模相关和无关的内容分割为两部分.考虑到深度确定性策略梯度(Deep Deterministic Policy Gradient, DDPG)网络[14]在单智能强化学习上性能较优, 本文在对智能体观测和动作进行分割之后, 将所有智能体的动作策略视作同个策略, 选取DDPG网络作为智能体动作网络的内部结构.Khan等[11]证明使用单智能体网络和单一策略控制多个智能体的有效性.考虑到序列到序列(Sequence-to-Sequence, Seq2Seq)网络[15, 16]对输入输出长度的不敏感性, 本文选取Seq2Seq作为智能体目标网络的内部结构, 将智能体规模视作序列长度.
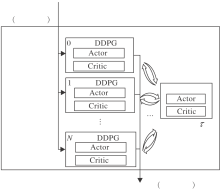
智能体动作网络输入为智能体的个性观测, 输出为智能体的共性动作, 详细框图见图2.
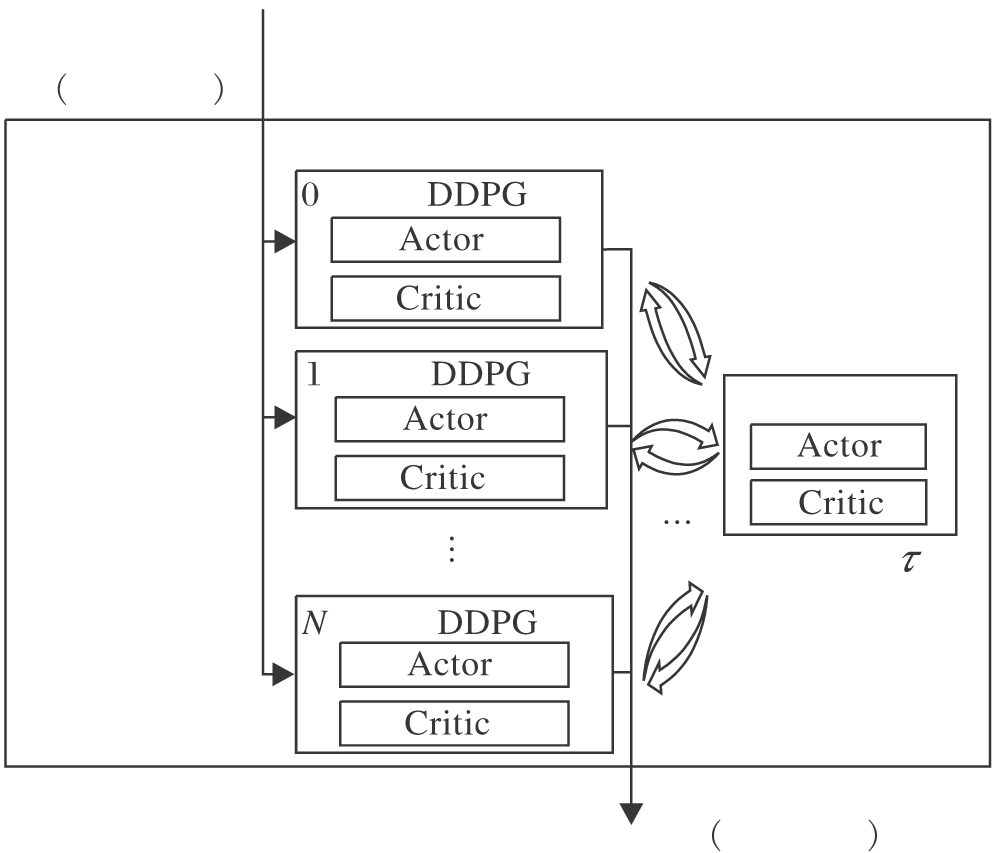 | 图2 智能体动作网络框图Fig.2 Framework of agent action network |
智能体动作网络由多个DDPG网络组成, 每个智能体均有各自的DDPG网络, 其中, Actor网络参数为θ i, Critic网络参数为Qi, Actor-target网络参数为θ 'i, Critic-target网络参数为Q'i, i=0, 1, …, N-1.单个的DDPG网络仅接收其对应的智能体以自身作为“ 坐标原点” 的局部观测.此时, 使用单一策略(参数共享)控制所有智能体的动作是有意义的.
另外, 为了实现参数共享, 本文参考异步优势演员评论家(Asynchronous Advantage Actor-Critic, A3C)的做法[10], 在智能体动作网络中额外设置一个不进行梯度更新的中心参数网络, Actor网络参数为θ N, Critic网络参数为QN.网络接收其它DDPG网络的参数进行软更新(软更新超参数τ =0.01), 再使用软更新更新其它DDPG网络, 最终使所有DDPG网络的参数达到同个单一策略.智能体动作网络更新方式如下.
令
达到最小以更新Critic网络, 其中, Qi为Critic网络的参数, Q(· |· )为网络评估, B_DDPG为算法批次(Batch Size)数量, oib、aib、rib、oib+1为抽取样本,
yib=rib+γ Q'(sib+1, μ '(sib+1|θ 'i)|Q'i),
γ 为折扣因子.
Actor网络更新如下:
$\nabla_{\theta_{i}} J \approx \frac{1}{B_{-} D D P G} \cdot \sum_{i b}\left(\left.\left.\nabla_{a} Q\left(o, a \mid Q_{i}\right)\right|_{o=o_{i b}, a=\mu\left(o_{i b}\right)} \nabla_{\theta_{i}} \mu\left(o \mid \theta_{i}\right)\right|_{o_{i b}}\right)$
其中, θ i为Actor网络的参数, μ (· |· )为网络策略.
中心参数网络和其它网络相互更新如下:
θ N← τ θ i+(1-τ )θ N, QN← τ Qi+(1-τ )QN, θ i← τ θ N+(1-τ )θ i, Qi← τ QN+(1-τ )Qi.
其中:中心参数网络的Actor网络参数为θ N, Critic网络参数为QN; 其它DDPG网络的Actor网络参数为θ i, Critic网络参数为Qi, i=0, 1, …, N-1; τ 为软更新超参数.
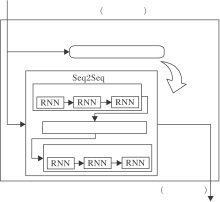
智能体目标网络输入为智能体的共性观测, 输出为智能体的个性动作, 框图如图3所示.网络由一个Seq2Seq网络和一个存储器组成, Seq2Seq网络参数为δ .Seq2Seq网络由编码器和解码器组成, 这两部分内部结构均为循环神经网络(Recurrent Neural Network, RNN).编码器负责将输入序列表征到更高的维度, 由解码器将高维表征进行解码, 输出新的序列.Seq2Seq网络负责学习和预测智能体间的合作关系.智能体目标网络使用强化学习的思想, 存储器起到强化学习中Q的作用, 负责记录某观测(序列)到动作(序列)的映射及相应获得的奖励.Seq2Seq部分相当于强化学习中的Actor, 负责学习最优观测序列到动作序列的映射及预测新观测序列的动作序列.
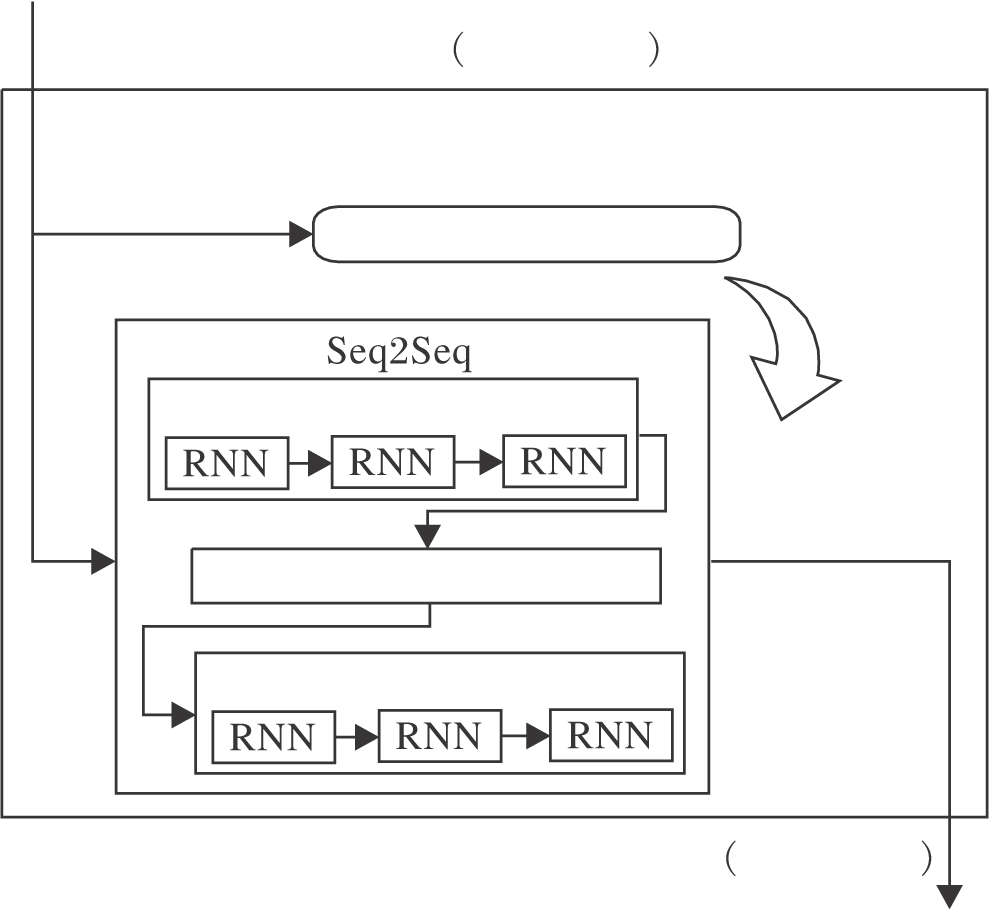 | 图3 智能体目标网络框图Fig.3 Framework of agent target network |
智能体目标网络输入的序列长度为智能体规模, 序列中的元素维度为每个智能体的观测.输出序列的长度同样为智能体规模, 序列中的元素是智能体编号.输入序列和输出序列的顺序均按照智能体的编号排序, 每当智能体规模发生变化时, 智能体重新从0开始编号.
具体如下:先定义Seq2Seq的奖励函数, 通过强化学习的思想筛选奖励最大的观测序列到动作序列的映射, 将该映射视作一种翻译, 再由Seq2Seq网络进行学习.网络输出表示智能体间的合作关系.另外, 本文在Seq2Seq网络中引入Attention机制, 提升Seq2Seq网络性能[17].
Seq2Seq的核心公式如下:
$\begin{aligned} \max _{\delta} L_{\text {seq }} & =\\ & \frac{1}{N} \sum_{n=0}^{N-1} \ln \left(a_{0}^{s}, a_{1}^{s}, \cdots, a_{N-1}^{s} \mid o_{0}^{s}, o_{1}^{s}, \cdots, o_{N-1}^{s}, \delta\right), \end{aligned}$
其中, δ 为Seq2Seq的参数,
在SMARL中, 一个智能体的执行动作是由智能体动作网络和智能体目标网络共同决定的.在训练时, 智能体动作网络和智能体目标网络交替进行, 智能体动作网络在每步都会训练, 此时的智能体目标网络停止更新, 仅进行数据收集, 以此保证环境的平稳性.智能体目标网络每隔一定的回合(Episode)才进行一次翻译训练, 在智能体目标网络训练时, 智能体目标网络停止更新.
SMARL参数汇总如表1所示.
| 表1 算法参数说明 Table 1 Description of algorithm parameters |
SMARL伪代码如下.
算法 SMARL
Initialize N actor networks and N critic networks with θ i and Qi, i=0, 1, …, N-1
Initialize N target actor networks and N target critic networks with θ 'i← θ i, Q'i← Qi, i=0, 1, …, N-1
Initialize actor central parameter network with θ N
Initialize critic central parameter network with QN
Initialize sequence to sequence network with δ
Initialize replay buffer M_DDPG and M_Seq
Set episode number E_max, max step of every epi-sode S_max and batch size B_DDPG
for k=0 to E_max do
for j=0 to S_max do
Receive individual-observation of every agent
Input
for i=0 to N-1 do
Sample a random minibatch of B_DDPG
transitions (oib, aib, rib, oib+1) from M_DDPG
Compute
yib=rib+γ Q'(sib+1, μ '(sib+1|θ 'i)|Q'i)
Update the critic network for agent i using
Update the actor network for agent i using
if j mod 100==0 then
θ 'i← τ θ i+(1-τ )θ 'i,
Q'i← τ Qi+(1-τ )Q'i
θ N← τ θ i+(1-τ )θ N,
QN← τ Qi+(1-τ )QN
θ i← τ θ N+(1-τ )θ i,
Qi← τ QN+(1-τ )Qi
end if
end for
Receive universal-observation of all agents
Input
and get
Execute actions Aj=
Receive new observations and rewards
Process
Store transition (
M_DDPG
Store transition (
end for
if kmod 25==0 then
Select (
RSeq, and then generate collection M
Train the sequence to sequence network by data
set M
The core formula
end if
end for
为了验证算法的有效性, 本文设定含有个性动作的智能体合作的场景.在这类场景中, 往往存在多个同构智能体, 这些智能体在不同情况下会变成具有不同功能的角色个体, 不同角色的智能体相互合作, 完成特定任务并获得奖励.本文设定并建立机械手臂敲钉子的游戏场景作为典型实验环境, 游戏规则如下.
1)游戏中存在多个机械手臂, 每个机械手臂可持有锤子或钉子, 但同一时刻只能持有一种, 即机械手臂有3种状态:空手、持有锤子、持有钉子.
2)持有锤子的机械手臂可瞄准另一个机械手臂, 执行敲击动作.
3)持有钉子的机械手臂可执行扶钉子动作.
4)只有当持有锤子的机械手臂执行敲击动作、敲击的目标为持有钉子并执行扶钉子动作的机械手臂时, 才算成功完成一次合作.当执行步数达到事先设定最大值时一局游戏结束.
5)一次合作完成后, 给予完成合作的两个机械手臂奖励.将完成合作的机械手臂设置为空手状态, 其它机械手臂的状态不变.
6)在游戏中, 每个时间步所有机械手臂均可执行一个动作, 总共有如下7种动作:休息、拿钉子、放钉子、扶钉子、拿锤子、放锤子、敲击某目标.其中, 当机械手臂执行敲击动作时, 需要同时确定敲击目标和敲击动作.
在游戏场景中, 机械手臂表示同构的智能体, 休息、拿钉子、放钉子、扶钉子、拿锤子、放锤子和敲击表示智能体的共性动作, 敲击的某目标表示智能体的个性动作, 游戏中任务的完成表示智能体间的合作.
相类似的场景如下.
1)宠物店猫咪洗澡游戏.游戏中存在两种工具:猫粮和毛刷, 每个店员同个时刻只能持有一种工具.持有猫粮的人可执行喂食动作, 吸引猫咪注意力.持有毛刷的人趁机完成对某只猫咪的洗澡任务.游戏中智能体动作如下:休息、拿猫粮、拿毛刷、喂食、洗刷某猫咪、放下猫粮、放下毛刷.
2)多人栽树游戏.游戏中存在3种物品:锄头、树苗、水壶, 每人同个时刻只能持有一种物品.持有锄头的人可以挖坑, 当锄头离开时该坑洞会垮塌(土自动填埋回去).持有树苗的人可将树苗栽种进某个坑洞中.持有水壶的人可以对某棵树苗进行浇灌.游戏中智能体动作如下:休息、拿锄头、拿树苗、拿水壶、挖坑、栽种某个坑、浇灌某棵树苗、放下锄头、放下树苗、放下水壶.
虽然上述游戏环境不同, 但本质完全相同.
为了验证本文算法的适应性、性能和训练效率, 设计如下实验.
1)性能和适应性实验.对比本文算法和基线算法在智能体规模动态变化环境中的运行效果.
2)性能实验.对比本文算法和基线算法在智能体规模不变的环境中的运行效果.
3)算法性能稳定性和训练效率分析.对比本文算法在2种情况下的表现.
基线算法如下:典型单智能体强化学习算法DDPG、典型多智能体强化学习算法MADDPG、本文简化后的COMA-DNN(COMA with DNN).COMA为一种多智能体强化学习算法, 算法内部使用RNN作为Actor网络, 考虑到本文实验环境较小, 因此Actor网络使用深度神经网络(Deep Neural Network, DNN)替代RNN.
为了保证公平性, 所有算法均使用相同的超参数.另外, 为了保证DDPG、MADDPG、COMA-DNN可顺利运行, 在智能体规模动态变化的环境中, 使用环境中智能体规模最大数量构建3种算法的网络结构.
本文对奖励函数做出如下设定:
1)完成任务时, 给予完成任务的智能体5分的奖励.
2)持有锤子的智能体敲击不成功或持有钉子的智能体执行扶钉子但未被敲击, 给予智能体-0.2分的奖励.
3)持有锤子的智能体执行拿钉子、放钉子或扶钉子的动作视为错误姿态变化, 给予-0.01分的奖励.
4)持有钉子的智能体执行拿锤子、放锤子或敲击的动作视为错误姿态变化, 同样给予-0.01分的奖励.
5)空手状态的智能体执行拿钉子或拿锤子动作视为正确姿态变化, 给予0.001分的奖励.
本文使用算法的平均奖励作为算法性能的评估指标.
在智能体规模动态变化的环境中, 每种算法在环境中总共进行9 000回合训练, 每回合256步, 智能体规模随回合的变化而变化, 规模
n=⌊
其中E=0, 1, …, 8 999, 表示当前回合数, 即每300回合进行1次智能体规模变化, 智能体规模依次为2, 3, 4.每种算法在环境中独立训练5次, 获得奖励平均值如表2所示.表中最优均值使用黑体数字表示, 最小波动使用斜体数字表示.
| 表2 各算法获得的奖励平均值 Table 2 Mean reward of different algorithms |
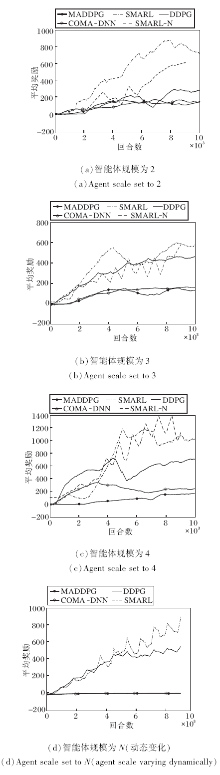
图4为4种算法在智能体规模不同时平均训练奖励曲线.在智能体规模不变的环境中, 每种算法在智能体规模固定但不同环境中进行10 000回合训练, 每回合256步.各算法在环境中独立训练5次.
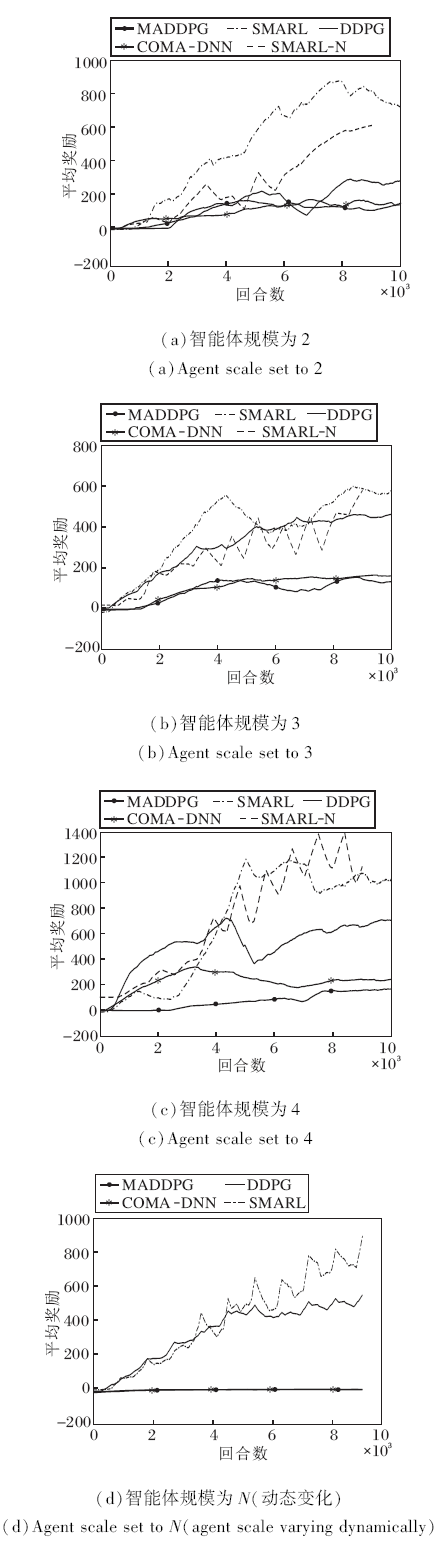 | 图4 智能体规模环境不同时各算法的平均训练奖励曲线Fig.4 Mean training reward curves of each algorithm in different agent scale environments |
实验结果见表2和图4(a)~(c).实验表明, 在智能体规模不变的环境中, SMARL性能表现(Reward)分别是DDPG的2倍、MADDPG的5倍和COMA-DNN的4倍, 并且SMARL表现的波动相对较稳定.
从图4(d)和表2中可看出, 在智能规模动态变化的环境中, SMARL的性能表现(Reward)分别是DDPG的3倍、MADDPG的14倍和COMA-DNN的21倍, 并且SMARL表现的波动相对较稳定.由于MADDPG和COMA-DNN在智能体规模动态变化的环境中并未达到收敛, 因此此处这两种算法的性能是按照它们在环境中的最大奖励进行评估.
综上所述, 不论在智能体规模动态变化的环境中, 还是在智能体规模不变的环境中, SMARL性能均最优.
为了对比本文算法在两种环境中的性能稳定性, 将本文算法在智能体规模动态变化的环境中的训练奖励按照智能体规模分类并单独抽出, 使用插入均值的方式将其补充为9 000回合的训练奖励曲线, 见图4(a)~(c)中SMARL-N曲线.由图可看出, 不论是在智能体规模动态变化的环境中还是在智能体规模不变的环境中, 相同规模时, SMARL均会收敛到当前智能体规模下相同的最优解.
另外, 在同样的9 000回合下, SMARL得到可用于3种智能体规模环境下的模型, 其它算法仅可得到用于一种智能体规模环境下的模型.因此, SMARL在训练效率上优于基线算法, 可节约训练成本.
综上所述, SMARL在适应性、性能及训练效率上较优.
Lillicrap等[14]通过一系列的实验指出:DDPG可实现稳步学习; DDPG在实验中比深度Q网络(Deep Q Networks, DQN)更快找到问题的解.SMARL中, 智能体动作网络内部使用相互独立的DDPG网络, 不同DDPG网络的输入向量、输出向量的维度含义相同, 因此训练过程可看作是同个DDPG网络在相同环境下的多次训练, 即DDPG是SMARL中智能体动作网络的核心, DDPG的稳定学习性质在一定程度上保证SMARL中智能体动作网络的稳步学习和较好性能.
Seq2Seq[15, 16]可学习从一个任意长度的序列到另一个任意长度序列的映射.在SMARL中, Seq2Seq是智能体目标网络的核心, 鉴于Seq2Seq可实现任意长度的序列到序列映射, SMARL将智能体规模大小视作序列长度, Seq2Seq可用于建模所有智能体的观测到动作目标的映射.因此, SMARL的智能体目标网络可较好地实现从智能体观测到智能体目标映射的学习.
基于DDPG的动作网络和基于Seq2Seq的目标网络构成SMARL的要件, 稳步的学习性和良好的性能在一定程度上保证本文算法的有效性.实验结果表明算法的有效性.
本文研究智能体规模对强化学习算法的影响, 提出序列多智能体强化算法(SMARL).实验证实, 本文算法对智能体规模动态变化具有较好的适应性, 在学习效率和算法性能上均较优.本文算法虽然可自动适应智能体规模的动态变化, 但在算法训练阶段仍需要一个短期的智能体规模不变的环境进行数据收集.因此, 进一步提升算法对智能体规模动态变化环境的适应性和促进智能体间合作是今后的研究方向.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|