
{kind=link}
{kind=link}
{kind=link}
融合事实文本的知识库问答方法
[王广祥1, 2  , 何世柱
, 何世柱3 , 刘康3 , 余正涛1, 2 , 高盛祥1, 2 , 郭军军1, 2 ]
, 何世柱, 刘康, 余正涛, 高盛祥, 郭军军]
|
|



作者简介:

王广祥,硕士研究生,主要研究方向为自然语言处理.E-mail:1918697933@qq.com.

何世柱,博士,副研究员,主要研究方向为知识图谱、自然语言处理.E-mail:shizhu.he@nlpr.ia.ac.cn.

刘 康,博士,研究员,主要研究方向为知识图谱、自然语言处理.E-mail:kliu@nlpr.ia.ac.cn.

高盛祥,博士,副教授,主要研究方向为自然语言处理.E-mail:gaoshengxiang.yn@foxmail.com.

郭军军,博士,副教授,主要研究方向为自然语言处理.E-mail:guojjgb@163.com.
在自然语言问题中,由于知识库中关系表达的多样化,通过表示学习匹配知识库问答的答案仍是一项艰巨任务.为了弥补上述不足,文中提出融合事实文本的知识库问答方法,将知识库中的实体、实体类型和关系转换为事实文本,并使用双向Transformer编码器(BERT)进行表示,利用BERT丰富的语义模式得到问题和答案在低维语义空间中的数值向量,通过数值计算匹配与问题语义最相近的答案.实验表明,文中方法在回答常见的简单问题时效果较优,鲁棒性较强.
AboutAuthor:
WANG Guangxiang, master student. His research interests include natural language pro-cessing.
HE Shizhu, Ph.D., associate professor. His research interests include knowledge graph and natural language processing.
LIU Kang, Ph.D., professor. His research interests include knowledge graph and natural language processing.
GAO Shengxiang, Ph.D., associate professor. Her research interests include natural language processing.
GUO Junjun, Ph.D., associate professor. His research interests include natural language processing.
In natural language problems, the relationship expression in the knowledge base is diversified. Therefore, matching the answers of the knowledge base question and answer through representation learning is still a challenge. To make up the shortcomings, a knowledge base question answering method incorporating fact text is proposed. Entities, entity types and relationships in the knowledge base are converted into fact text. A pre⁃trained language model(BERT) is employed for representation. The vector of question and answers in low dimensional semantic space is obtained using the rich semantic mode of BERT. The answer with the closest semantic similarity to the question is matched by calculation. Experiments show that the proposed method is effective and robust in answering common simple questions.
本文责任编委 林鸿飞
Recommended by Associate Editor LIN Hongfei
随着Freebase[1]、DBpedia[2]和YAGO[3]等大规模知识库的快速发展, 知识库问答受到越来越多研究者的关注.典型的知识库多采用“ 头实体-关系-尾实体” 三元组为基本单元, 组成图结构, 每个三元组称为一个事实.知识库中三元组数以千计, 用户难以获得有价值的信息.知识库问答可根据知识库中的事实直接给出自然语言问题答案, 提供直接访问知识库的方式.知识库问答按照技术方法大致可分为两类:基于语义解析的方法和基于检索排序的方法.
基于语义解析的知识库问答方法首先把自然语言问题转化为可在知识库中检索的结构化查询语句, 例如组合范畴文法(Combinatory Categorial Gra-mmar, CCG)[4, 5]、依存组合语义(Dependency-Based Compositional Semantics, DCS)[6]、Lambda表达式[7], 再在知识库中查询得到实体集合作为答案返回.
基于检索排序的知识库问答方法首先根据自然语言问题从知识库中快速找到少量候选答案, 再按照与问题的匹配程度对候选答案排序, 选择排在前面的候选答案作为答案.Yao等[8]提出基于特征工程的方法, 分别从问题和候选答案中提取特征, 并利用它们进行匹配程度的计算.随着深度学习的发展, 学者们提出更多基于表示学习的神经网络方法.Bordes等[9]在知识库问答中应用神经网络, 将问题和知识库中的候选实体及其相关实体、关系和属性都映射到低维空间中, 再计算问题和候选答案的匹配程度.Dong等[10]采用3个不同参数的卷积神经网络(Con-volutional Neural Network, CNN), 从答案实体类型、答案实体与主题实体的关联路径及其它相关属性3个维度生成3个不同的答案向量.Hao等[11]提出基于交叉关注机制的神经网络模型, 根据不同的答案及其不同侧面动态表示问题的语义.Yin等[12]在CNN中融入注意力机制, 匹配问题和知识库中关系.Golub等[13]提出使用字符级别的表示和基于注意力机制的自编码模型, 用于学习句子的表示.Lukovnikov等[14]利用字符级门控递归单元神经网络将问题和谓词、实体投影到同个空间中.上述方法的核心是把自然语言问题和知识库中的知识都映射到一个低维向量空间中, 可使用向量间的相似度反映问题和知识(三元组)之间的语义相关性.
尽管上述方法已取得较优效果, 但知识库问答远未得到解决, 最主要的问题是自然语言问题与知识库中的三元组存在语义鸿沟, 具体表现为三元组的关系在自然语言中有多种表达.为了改善语义鸿沟, Huang等[15]提出将问题的文本空间向量转化成知识库空间向量, 包括实体向量和关系向量, 通过这两个向量在预训练的知识表示空间中查找最相似的实体和关系, 最终根据该实体和关系得到答案.预训练的知识表示有TransE[16]、TransH[17]和TransR[18].这些方法将问题单独映射成实体表示和关系表示, 忽略问题本身的一些语义信息, 即实体和关系间的关联信息.这即为问题中的实体和关系存在一定的语义约束, 不是任意的实体都可以和任意的关系搭配.
双向Transformer编码器(Bidirectional Encoder Representations from Transformers, BERT)[19]在文本表示学习中表现较优, 学者们考虑将其用于表示学习, 融入知识库问答中, 改善文本与三元组间的语义鸿沟.受Berant等[20]通过逻辑形式模板, 直接利用知识库中谓词的文本描述生成规范语句的启发, 本文提出融合事实文本的知识库问答(Question An-swering over Knowledge Base, KBQA), 将三元组中的实体、实体类型及关系通过设计的模式转换为事实文本, 转换时融入疑问词和尾实体类型, 转换后的文本为自然语言, 更适用于知识库问答任务.这样知识库三元组的知识表示学习就转换为文本表示学习.首先将自然语言问题经过文本表示学习映射成一个低维空间中的数值向量, 同时将经过转换的三元组通过同样的文本表示学习映射为同一语义空间中的数值向量, 本文使用BERT进行文本表示学习.再计算数值向量间的相似度, 并取出最相似的三元组作为知识库问答的答案.
在知识库问答中, 简单问题, 即可通过知识库中单一事实回答的问题, 占大部分.在简单问题中, 如果正确识别单个头实体和谓词, 则机器可直接回答每个问题[15].本文专注于回答简单问题, 在简单问题数据集(SimpleQuestion)[21]上的实验既表明本文方法取得较优效果, 又验证BERT对方法的提升作用.
知识库问答的目标是给定自然语言问题Q, 系统根据知识库返回实体集A作为答案.本文方法主要解决简单问题, 基本流程如图1所示.
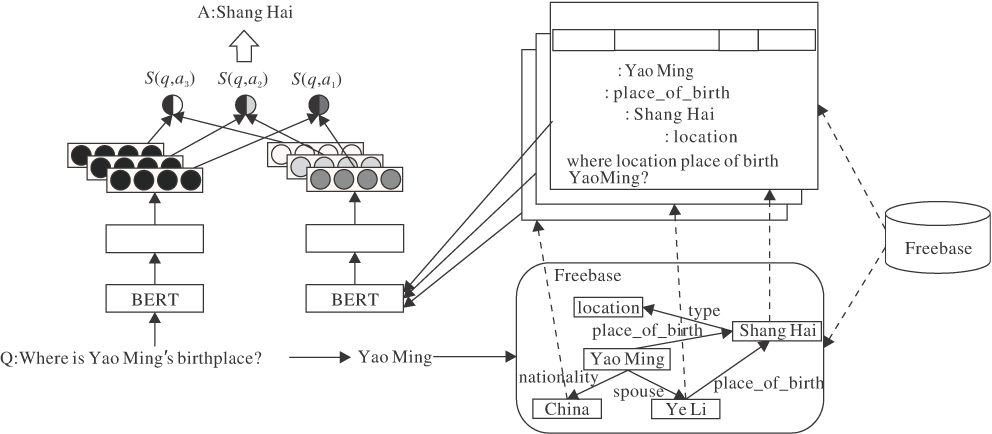 | 图1 本文方法框图Fig.1 Framework of the proposed method |
首先, 通过主题实体识别模型识别输入系统自然语言问题中的主题实体.然后, 根据主题实体在Freebase[1]中检索候选答案, 并将每个候选答案转换成可进行文本表示的事实文本.最后, 采用BERT将问题和候选答案表示成数值向量, 计算向量间的相似度得分, 选择得分最高的候选答案作为最终答案.
主题实体是指自然语言问题Q中提到的知识库实体.例如在问题
Where is Yao Ming's birth-place?
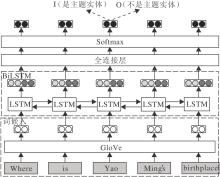
中, “ Yao Ming” 在知识库中对应的实体是该问题的主题实体.本文方法采用双向长短期记忆网络(Bi-directional Long Short-Term Memory, Bi-LSTM)[15]执行主题实体识别任务.
模型框图如图2所示, 给定一个包含n个单词的自然语言问题Q=w1, w2, …, wn, 首先将n个单词经过一个预先训练好的GloVe模型[22]映射成词向量{xj}, j=1, 2, …, n.使用BiLSTM学习前向隐状态(
$i_{j}=\sigma\left(W_{x i} X_{j}+W_{h i} \overleftarrow{h}_{j+1}+b_{i}\right)$
$f_{j}=\sigma\left(W_{x f} X_{j}+W_{h f} \overleftarrow{h}_{j+1}+b_{f}\right)$
$o_{j}=\sigma\left(W_{x o} X_{j}+W_{h o} \overleftarrow{h}_{j+1}+b_{o}\right)$
$\tilde{c}_{j}=\tanh \left(W_{x c} X_{j}+W_{h c} \stackrel{\leftarrow}{h}_{j+1}+b_{c}\right)$
$c_{j}=i_{j} \circ \tilde{c}_{j}+f_{j} \circ c_{j+1}$
$\overleftarrow{h}_{j}=o_{j} \circ \tanh \left(c_{j}\right)$
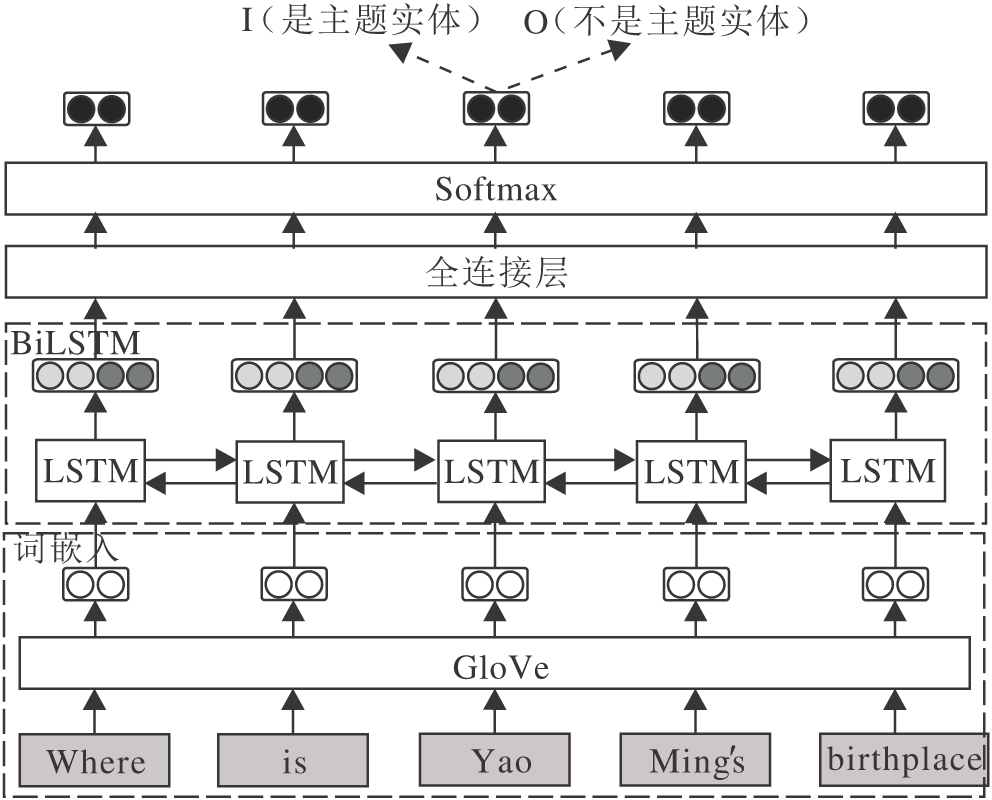 | 图2 主题实体识别框图Fig.2 Framework of model of subject entity recognition |
其中:ij为输入门, 决定长短期记忆网络(Long Short-Term Memory, LSTM)存储哪些信息; fj为遗忘门, 决定LSTM丢失哪些信息; oj为输出门, 决定LSTM单元需要输出的信息; σ 表示sigmoid函数; $\circ$表示哈达玛(Hadamard)积.
串联前向隐状态和后向隐状态, 得
$\boldsymbol{h}_{j}=\left[\vec{h}_{j} ; \overleftarrow{h}_{j}\right]$
hj进入全连接层再经过Softmax后得到一个二维向量Vj=R2× 1, 第1维表示这个单词是一个主题实体单词的概率, 第2维表示不是主题实体单词的概率.通过识别的主题实体单词或短语在知识库中进行关联, 返回知识库中与主题实体单词(短语)相同或包含主题实体单词(短语)的实体作为主题实体.
直观上, 给定一个自然语言问题, 知识库中所有的实体都是候选答案.但是, 知识库中的实体数量通常较大, 如Freebase[1]中的实体有6 800万之多, 将所有实体作为候选答案既耗费计算资源又使效率低下.在实践中, 通常根据主题实体识别模型识别的实体, 从知识库中查找满足约束条件的事实作为候选答案.本文方法主要解决的问题是简单问题, 所以约束条件为:如果知识库中三元组的头实体属于问题的主题实体, 将该三元组列为候选答案.
通过分析三元组的信息可知, 头实体、关系及尾实体类型包含的信息和其对应的自然语言问题包含的信息重合度很高.例如:
Where is Yao Ming's birthplace?
中“ Yao Ming” 对应三元组中头实体“ Yao Ming” ; “ birthplace” 对应三元组中的关系“ place_of_birth” ; “ Where is” 是对地点提问, 对应三元组中尾实体“ Shang Hai” 的类型是“ city town” .所以本文将每个候选三元组经过模式
疑问词+尾实体类型+关系+头实体
构建成一个事实文本, 上述例子对应的事实文本为
Where city town place of birth Yao Ming?
这样的事实文本从语法看或许是不准确的, 但却能很大程度地保留候选三元组包含的信息.
候选答案转换为事实文本后, 知识库问答转换成一个句子间的语义匹配问题.把每个事实文本及对应的问题编码成向量表示, 对向量间的相似度进行计算并排序, 取出相似度最高的事实文本对应的三元组作为问题的最终答案.
本文使用BERT进行句子的表示学习, 可更好地获取文本的语义信息, 计算过程如下:
XiWem=Ei,
Q, K, V=fqkv(Ei),
$h_{i}=\operatorname{Attention}(\boldsymbol{Q}, \boldsymbol{K}, \boldsymbol{V})=\operatorname{softmax}\left(\frac{\boldsymbol{Q K}^{\mathrm{T}}}{\sqrt{d_{k}}}\right) \boldsymbol{V}$
其中, Wem为嵌入矩阵, dk为K向量的维度, hi为包含上下文信息的特征向量.对BERT的输出层采用平均策略进行池化[21], 得出固定大小的问题向量Vq和事实文本向量Va.
使用余弦相似度对问题与事实文本的向量表示进行相似度计算:
$S\left(\boldsymbol{V}_{q}, \boldsymbol{V}_{a}\right)=\cos \theta=\frac{\boldsymbol{V}_{q} \cdot \boldsymbol{V}_{a}}{\left\|\boldsymbol{V}_{q}\right\|\left\|\boldsymbol{V}_{a}\right\|}= \frac{\sum_{i=1}^{n} V_{q i} V_{a i}}{\sqrt{\sum_{i=1}^{n} V_{q i}^{2}} \sqrt{\sum_{i=1}^{n} V_{a i}^{2}}}$
其中, Vqi表示问题向量Vq的第i个特征值, Vai表示事实文本向量Va的第i个特征值.
S(Vq, Va)的取值范围为[0, 1], 0表示问题与事实文本语义完全不相关, 1表示问题与事实文本语义相同.计算每个事实文本与其对应的问题余弦相似度S(Vq, Va)作为候选答案的分数, 对分数进行数值排序, 分数最高的候选答案就是最终答案.
将自然语言问题和事实文本作为BERT的输入, 输出经过平均池化[23]后计算余弦相似度, 以此形成端到端的模型以微调所有参数, 初始化采用预训练的参数.由于候选的事实文本数量通常较大, 在模型中采用孪生网络体系结构[24], 使模型可高效进行语义相似性搜索.孪生网络体系结构如图3所示, 每个分支网络结构相同, 参数更新在2个子BERT上共同进行.使用均方差损失作为训练的目标函数.
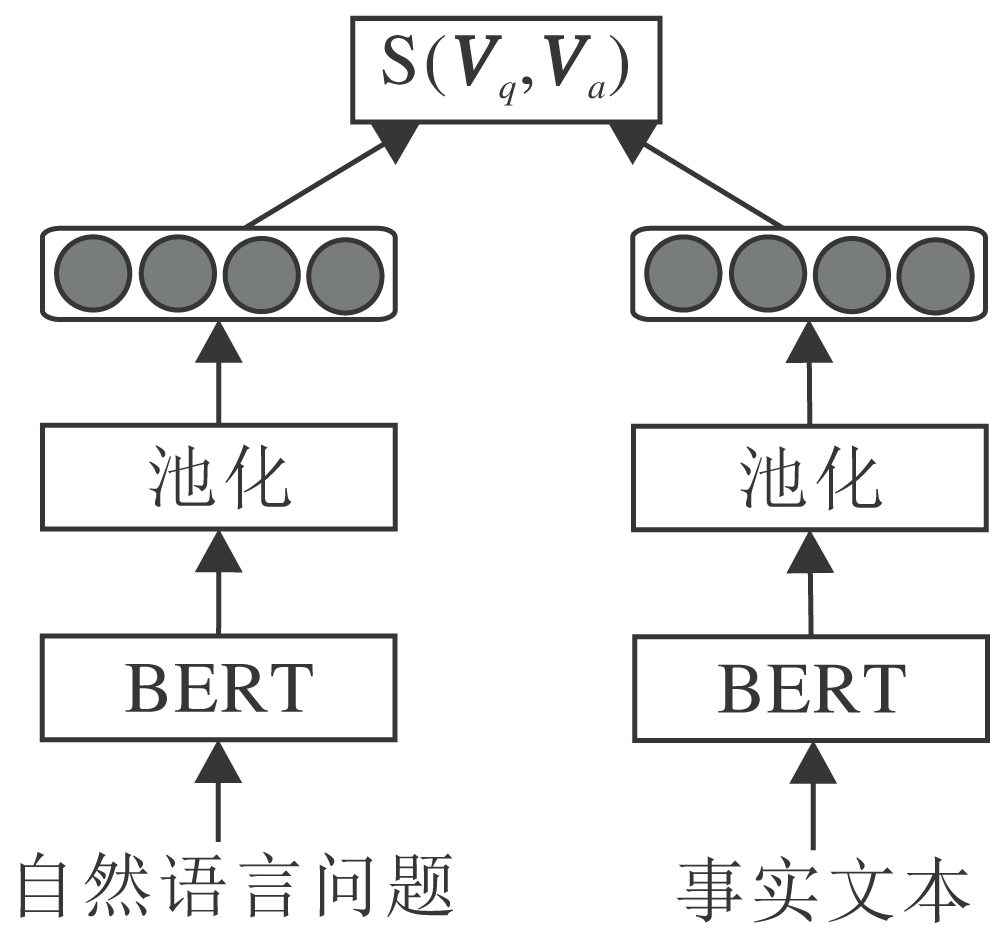 | 图3 基于孪生网络体系的BERT微调结构图Fig.3 BERT fine-tuning structure based on twin network |
在公共简单问题数据集SimpleQuestion[21] 上验证本文方法的有效性.数据集包括10万多个与相应事实相关的简单问题, 这些事实都属于Freebase[1]的子集FB2M.数据集分为75 910条训练数据, 10 845条验证数据, 21 687条测试数据, 涵盖1 837个关系, 131 681个实体, 词表大小为61 336.SimpleQuestion对应的知识图谱FB2M有14 174 246个事实, 包括6 701个关系和1 963 130个实体, 词表大小为733 278.
在Freebase中, 三元组中的关系分为3个层级的, 例如关系“ people. person. place_ of_ birth” .为了有效选择关系层级生成事实文本, 本文设置2种策略生成事实文本.
1)Strategy1.只选择关系的最后一个层级, 如“ Where city town place of birth Yao Ming?” .
2)Strategy2.选择关系的全部层级, 如“ Where city town people person place of birth Yao Ming?” .
为了更好地选择微调BERT的数据, 首先将自然语言问题对应的答案事实转换为事实文本, 然后对“ 自然语言问题-事实文本” 对进行0~5分的标注, 不需要人工标注, 而是对事实文本中“ 尾实体类型、关系、头实体” 的一部分进行随机替换操作, 生成不同分数的“ 自然语言问题-事实文本” 对.下文用实例说明.
自然语言问题:Where is Yao Ming's birthplace?
答案事实:(Yao Ming, place of birth, Shang Hai). “ Shang Hai” 的类型:city town.
每个分数替换的部分如表1所示.
| 表1 “ 自然语言问题-事实文本” 对标注方法示例 Table 1 Example of annotation methods of "natural language question-fact text" pairs |
在替换后:5分表示该事实就是问题答案; 4分表示该事实头实体、关系正确但尾实体错误; 3分表示该事实关系正确但尾实体、头实体错误; 2分表示该事实尾实体、头实体正确但关系错误; 1分表示该事实头实体正确但尾实体、关系错误; 0分表示该事实尾实体、关系、头实体均错误.
最终, 通过随机替换操作生成0~5分总共455 460条训练数据, 65 070条验证数据, 各分数的数据量相同.
每条数据表示为
分数 自然语言问题 事实文本.
0~5分对应的情况在问答过程中均有可能发生, 所以设置训练数据比例为
5分∶ 4分∶ 3分∶ 2分∶ 1分∶ 0分= 1∶ 1∶ 1∶ 1∶ 1∶ 1
的实验, 训练的总数据量为455 460条, 但是通过随机替换生成的数据可能让方法学习到更多的信息, 也可能带来噪声影响方法性能.
为了探究如何组合各分数使方法训练效果最佳, 本文设置
5分∶ 0分=4∶ 1, 5分∶ 0分=2∶ 1,
5分∶ 0分=1∶ 1,
训练的总数据量均为151 820条.同时在分数比例一致的情况下设置探究两种关系选择策略的实验.本文所有的实验评价指标都采用准确率, 当自然语言问题的头实体和关系都预测准确则正确, 测试数据包含21 687条, 微调BERT的迭代次数设置为4.
训练数据比例不同时的实验结果如表2所示.分析表2可知, 当选择Strategy2, 即事实文本中选择关系的全部层级, 按照
5分∶ 4分∶ 3分∶ 2分∶ 1分∶ 0分= 1∶ 1∶ 1∶ 1∶ 1∶ 1
组合训练数据时, 本文方法性能最佳.
| 表2 训练数据比例不同时的实验结果 Table.2 Experimental results of different training data settings |
为了验证本文方法的有效性, 选用近期提出的最优方法作为基线进行对比, 所有方法都在SimpleQuestion数据集上验证.具体对比方法如下:Yin等[12]提出的CNN; Golub等[13]提出的基于注意力(Attention)的编解码(Encoder-Decoder)方法; Lukovnikov等[14]提出的门控递归单元神经网络(Gated Recurrent Unit, GRU)方法; Huang等[15]将问题的文本空间向量转化到知识库空间向量, 使用预训练的知识表示学习模型(如TransE); Bordes等[21]提出的基于记忆网络(Memory Network)的方法; Mohammed等[25]将关系预测视为分类问题, 使用不同的神经网络求解.
各方法准确率如下:文献[12]方法为68.3%, 文献[13]方法为70.9%, 文献[14]方法为71.2%, 文献[15]方法为75.4%, 文献[21]方法为62.7%, 文献[25]方法为73.2%, 本文方法为76.3%.由结果可看出, 本文方法准确率最高.
使用BERT实现本文方法的文本表示学习, 为了验证BERT对方法性能的提升作用, 分别使用CNN[26]和BiLSTM[15]对BERT进行替换并进行实验, 迭代次数上限均设置为10.
KBQA使用CNN的准确率为69.5%, 使用BiLSTM的准确率为68.0%, 使用BERT的准确率为76.3%.相比使用CNN和BiLSTM, 使用BERT的准确率分别有9.78%和12.21%的提升, 说明使用BERT对于本文方法具有较大的性能提升作用.
下面进一步验证本文方法的鲁棒性, 为了保证测试阶段出现的关系类型在训练验证阶段从未出现, 在训练阶段不使用任何与SimpleQuestion数据集相关的数据, 采用语义相似性任务的公共数据集SNLI[27]和STS benchmark(STSb)[28].
SNLI数据集包含570 000个句子, 带有con-tradiction、entail-ment和neutral标签.STSb数据集包含来自字幕、新闻和论坛3个类别的8 628个句子对, 每个句子对标注0~5分之间的相似性得分.
对于SNLI数据集, 采用交叉熵损失作为目标函数微调BERT, 使用SNLI数据集微调的结果作为BERT的初始化参数, 在STSb数据集上以方差损失作为目标函数继续微调.选用文献[15]方法作为基线, 不同于本文方法, 文献[15]方法根据关系的类型重新组合划分SimpleQuestion数据集, 使测试阶段的关系类型在训练验证阶段从未出现过.
本文方法在处理训练阶段从未出现过的关系类型时准确率达到51.3%, 相比文献[15]方法的41.8%, 提升22.72%.
从上述所有实验可得出:1)本文方法结果更优, 准确率达到76.3%; 2)本文方法具有较强的鲁棒性, 很大程度上改善自然语言问题与知识库中的三元组存在的语义鸿沟; 3)BERT是本文方法提升有效性和鲁棒性的关键.
本文提出融合事实文本的知识库问答方法, 通过设计的模式将知识库三元组的表示学习转换成与自然语言问题一样的文本表示学习, 并采用BERT进行文本表示学习, 不仅很大程度上编码三元组的信息, 还利用BERT丰富的语义模式改善自然语言问题与知识库三元组之间的语义鸿沟, 有效提高知识库问答的有效性和鲁棒性.本文方法旨在解决简单的问题, 并在简单问题数据集上取得较优性能.今后将进一步研究如何融入BERT进行表示学习的方法, 解决复杂问题.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|