






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于结构约束生成对抗网络的书法汉字生成
[俞书世1  , 赵杰煜
, 赵杰煜1, 2 , 叶绪伦1 , 唐晨1 , 郑阳1 ]
, 赵杰煜, 叶绪伦, 唐晨, 郑阳]
|
|



作者简介:

俞书世,硕士研究生,主要研究方向为生成对抗网络、模式识别.E-mail:1811082062@nbu.edu.cn.

叶绪伦,博士,讲师,主要研究方向为贝叶斯学习、凸优化.E-mail:yexulun@nbu.edu.cn.

唐 晨,硕士研究生,主要研究方向为图神经网络、模式识别.E-mail:952304255@qq.com.

郑 阳,硕士研究生,主要研究方向为三维卷积网络、模式识别.E-mail:424536312@qq.com.
目前书法汉字的生成研究在汉字生成过程中需要大量先验汉字组成信息,不仅对前期数据收集工作的要求较高,而且影响研究成果的扩展性.针对此问题,文中提出基于结构约束的条件堆叠生成对抗网络的书法汉字生成方法.将源汉字图像直接提取的汉字笔迹作为结构约束条件,通过条件堆叠生成对抗网络模型生成高质量的书法汉字.同时提出通过伪目标样本的半监督学习方法,用于解决书法汉字数据集较少的问题,也可生成训练不可见的书法汉字.实验表明,在使用少样本的特定风格的书法汉字数据集的前提下,文中方法可生成更高质量的书法汉字.
AboutAuthor:
YU Shushi, master student. Her research interests include generative adversarial networks and pattern recognition.
YE Xulun, Ph.D., lecturer. His research interests include Bayesian learning and convex optimization.
TANG Chen, master student. His research interests include graph neural networks and pattern recognition.
ZHENG Yang, master student. His research interests include three dimensional con-volutional networks and pattern recognition.
A large amount of prior composition information of Chinese characters is required for the generation of calligraphic Chinese characters. Moreover, the previous data collection is demanding work, and the scalability of the research results is easily affected. To solve this problem, a method of Chinese calligraphy characters generation based on structure constraint using conditional stack generative adversarial networks is proposed. The Chinese character handwriting extracted directly from the source Chinese character image is considered as the structure constraint condition. High-quality calligraphic Chinese characters are generated by the condition stack generative adversarial network model. A semi-supervised learning method based on pseudo target samples is proposed for the dataset lacking of calligraphic Chinese characters. Furthermore, the unseen calligraphic Chinese characters during training are generated as well. Experiments show the proposed method can generate higher-quality calligraphy Chinese characters under the premise of using a few samples of a specific style of calligraphic Chinese character dataset.
本文责任编委 桑农
Recommended by Associate Editor SANG Nong
中国书法是以汉字为基础、用毛笔书写的抽象符号艺术, 书法不仅具有文字的书写性, 而且融入创作者的观念、思维、精神, 激发审美对象的审美情感.从最初的甲骨文到各种现代字体, 中国书法出现在文物和历史遗迹上.但是, 由于自然或人为因素的影响, 大部分已经受到一定程度的破坏, 文物不再完整.通过深度学习的方法对文物进行修复, 近乎真实地展示和修复书法家的作品, 具有重要的历史文化意义[1].此外, 还可通过书法汉字生成技术, 深入研究不同时期著名人物的书法风格, 高质量地生成书法家风格的书法汉字, 为广大书法学习者提供高质量的临摹样本, 具有重要的现实意义.
书法汉字的生成任务实际上是汉字风格迁移任务的变形.图像风格迁移是一种视觉与图形问题, 目的在于学习输入图像和输出图像之间的映射.该技术的应用范围广泛, 如边缘/轮廓提取[2, 3]、语义分割[4, 5]、艺术风格迁移[6, 7, 8]、图像着色[9, 10].Pix-2pix[11]是基于条件生成对抗网络(Conditional Gen-erative Adversarial Networks, CGAN)[12]的网络模型, 使用U型网络(U-Net)[13]作为生成器.生成器由图像编码器和解码器组成, 编码器和解码器之间存在短连接, 以保留所有层的可视信息, 其中基于生成对抗网络(Generative Adversarial Networks, GAN)[14]的对抗性损失可防止输出图像模糊, 并且图像质量优于大多数基于编码器/解码器的方法[15].Pix2pix的局限性之一是需要大量的成对数据进行训练.为了缓解获取数据对的问题, 学者们提出不成对的图像到图像转换框架.Liu等[16]提出共享潜在空间的假设, 可将不同域中的一对对应图像映射到共享潜在空间中的相同潜在表示, 并扩展到无监督的图像到图像翻译问题[17].Zhu等[18]提出循环一致生成对抗网络(Cycle-Consistent GAN, CycleGAN), 使用2个GAN同时学习2组不成对的图像分布, 在视觉和图形任务中表现良好, 但只能处理一个目标域.
汉字风格迁移任务的本质是将汉字风格与汉字内容分别提取再重新组合的过程, 问题的关键点在于寻找风格与内容的表示方法, 即从图像中提取风格特征与内容特征, 再根据风格特征与内容特征生成新的图像.近年来, 已有部分学者尝试生成简单字符, 如英文字符[19, 20], 但汉字的生成尚未被广泛探究.相比英文字符, 汉字字符存在单词量较大、字形复杂多变、风格样式繁多、结构多样等问题, 使汉字生成技术仍面临巨大挑战.同时, 每个中国书法家都有自己的风格, 形成各异的书法笔触和形状.相比普通汉字字符图像, 毛笔书写的汉字图像更加不规则.著名书法大家的传世墨迹可能仅数百至数千字, 导致书法汉字研究的数据集量较小, 研究困难重重.
Zi2zi是首个使用GAN生成汉字字符的开源项目, 它在Pix2pix的基础上引入AC-GAN(Auxiliary Classifier GAN)[21]的辅助分类器和域传输网络的常量损失函数, 实现将印刷字体的字符图像转换为多种目标字体图像.Zi2zi的输出字体风格受一个类参数控制, 该类参数是一个独热矢量(One-Hot Vector), 并通过嵌入转换为潜矢量.Zi2zi实现使用单个模型将源汉字图像转换为多种目标风格的汉字图像, 但生成的训练不可见的书法汉字图像质量不高.
Lyu等[22]提出将自编码器引入GAN的方法(Auto-Encoder Guided GAN), 实现从标准印刷体汉字图像中生成具有指定样式的书法汉字图像.该方法基于Pix2pix引入额外的编码器-解码器网络, 在训练过程中提供监督信息, 实现单类书法汉字的生成.该方法同样只能生成训练可见的汉字, 所需数据集的数据量较大.
Lian等[23]提出手写汉字笔画提取算法, 从给定的手写汉字中提取笔画, 并学会为相同样式的其它书写汉字生成相应的笔画, 但需手动指定笔画的书写轨迹, 无法适用于普通的书法汉字数据集.Azadi等[24]提出MC-GAN(Multi-content GAN), 通过2个CGAN堆叠生成字体轮廓和字体纹理, 根据少量的示例英文字形的图像合成相同样式的其它字符, 但主要用于艺术英文字符的生成, 不适用于生成大量的汉字字符.
Sun等[25]提出SA-VAE(Style-Aware Variational Auto-Encoder), 将内容和风格样式分离为2个不相关的域, 并使用2个独立的编码器对其进行建模, 通过内容编码器的特征结合先验汉字结构信息组成内容向量, 通过风格样式编码器提取风格特征向量, 结合内容向量与风格向量, 生成汉字字符.SA-VAE将风格汉字进行解耦合, 生成多种风格的汉字字符, 然而仍需要大量的先验汉字结构组成信息.Wu等[26]将汉字的部件组成信息通过递归神经网络编码成内容向量并引入Zi2zi, 使用单个网络模型生成多种目标风格的书法汉字图像, 然而方法要求大量的汉字部件组成信息, 对前期数据收集工作的要求较高.
由此, 本文提出基于结构约束的条件堆叠生成对抗网络的书法汉字生成方法, 仅使用源汉字的结构约束条件, 不需要收集大量的先验汉字信息, 就能生成质量较高、结构正确的书法汉字.同时针对书法汉字数据集规模较小导致结果泛化能力较弱的问题, 提出通过伪目标样本的半监督学习方法, 增加书法汉字的学习样本, 提高网络模型的学习效率.通过伪目标样本的生成扩充模型的训练集, 迭代学习优化模型, 实现生成质量较优的训练不可见的书法汉字的目标.
本文的研究目标为书法家颜真卿的楷体书法风格的书法汉字, 给定标准印刷体的汉字字符图像, 通过本文方法生成书法家颜真卿的楷体书法风格的书法汉字图像.假设有N个样本的数据集D, 其中一部分数据集是成对的图像对:
$D_{t}=\left\{\left(x_{i}, y_{i}\right)\right\}_{i=1}^{N_{t}}$,
即标准印刷体的汉字字符图像和与之对应的目标风格的书法汉字图像对, 其中, xi∈ XD表示给定的标准印刷体的汉字字符图像, yi∈
$D_{u}=\left\{\left(x_{i}\right)\right\}_{i=1}^{N_{u}}$.
本文方法不需要收集大量的先验汉字知识信息, 仅将源印刷体图像直接提取的汉字笔迹作为结构条件即可训练生成结构正确的高质量书法汉字字符.本文方法框图如图1所示, xsc为标准印刷体的汉字字符图像, xsk为源汉字的骨架图像, ys为结构样式生成的书法汉字图像, yc为细节样式生成的书法汉字图像.
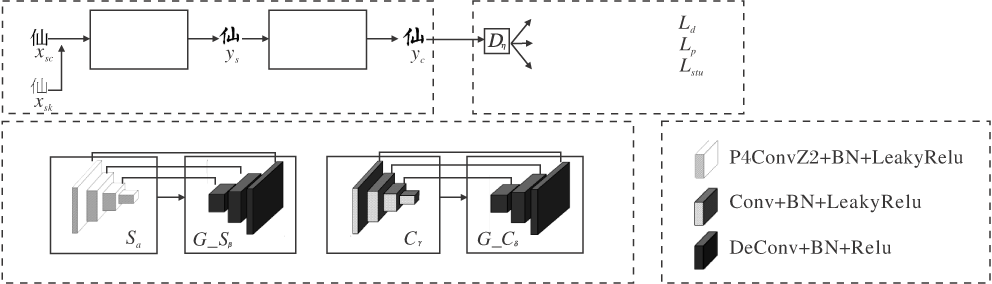 | 图1 本文方法框架图Fig.1 Architecture of the proposed method |
本文方法主要由3部分构成:结构样式生成器、细节样式生成器、判别器Dη .结构样式生成器由结构特征提取器Sα 与结构样式解码器G_Sβ 构成.细节样式生成器由细节特征提取器Cγ 与细节样式解码器G_Cδ 构成.源印刷体汉字图像在结构约束的条件下通过结构样式生成器生成书法汉字图像, 使汉字图像具有正确的汉字结构.细节样式生成器对该汉字图像进行优化, 最终生成结构正确、质量较优的书法汉字图像.
1.2.1 结构样式生成器
书法汉字的数据集较小, 为了学习更多的汉字结构特征, 本文在结构特征提取器中引入群等变卷积结构.因为群等变卷积结构中的卷积核带4个旋转的滤波器, 导致结构样式解码器生成的图像结构不正确, 存在旋转扭曲等问题, 因此本文提出引入汉字结构图作为结构约束条件, 用于引导模型生成结构正确的书法汉字.
本文通过汉字骨架提取算法[27]提取标准印刷体汉字的结构图, 不仅作为汉字的结构监督信息, 同时也作为汉字的结构约束条件以引导模型生成结构完整正确的书法汉字.目前对于书法汉字生成的研究大多将汉字结构的先验知识进行编码后引入模型, 生成书法汉字, 而这些汉字先验信息往往导致前期数据收集工作量增大.本文引入的汉字结构图仅根据标准印刷体汉字通过汉字骨架提取算法得到, 因此本文使用的结构约束条件对前期数据收集工作影响不大, 方便实验结果的扩展.
首先将输入的印刷体汉字图像xsc和该汉字对应的结构图xsk通过结构特征提取网络经群等变卷积操作[28]得到结构特征.然后使用反卷积层逐步对特征进行上采样, 同时每个反卷积层的输出与结构特征提取器中的对应层进行跳跃连接, 用于传输低级结构特征.最终通过结构样式生成器生成结构正确的书法汉字图像ys.
结构样式生成器的结构框架如表1所示, 其中结构特征提取器Sα 的4层网络层均使用相同的5× 5的群等变卷积核, 激活函数LeakyRelu的斜率为0.2, 批量归一化层且步幅为4.结构样式解码器G_Sβ 的4层网络层均使用相同的5× 5反卷积内核、Relu激活函数及批量归一化层.
| 表1 结构样式生成器的结构框架 Table 1 Architecture of structural style generator |
1.2.2 群等变卷积网络
由于书法汉字是由书法家用毛笔书写, 相比标准印刷体, 汉字图像更不规则, 并且书法家书写的书法汉字即使是相同的部首也各有差别, 因此本文将群等变卷积网络引入结构特征提取器中, 提高结构特征提取能力.群等变卷积网络的P4ConvZ2卷积操作中包含带有4个旋转的滤波器, 因此引入群等变卷积网络相当于对数据进行数据增强操作, 某种程度上解决数据集较小的问题.
P4群是由绕方形网格的中心以90° 进行旋转和平移变换组成的群.这个群的元素采用3个整数r、u、v, 定义为
g(r, u, v)=
其中, 0≤ r< 4 , (u, v)∈ Z2 表示二维图像Z2上的像素点坐标.P4群的二元操作是矩阵乘法.P4群作用在Z2上的像素点等于将矩阵g(r, u, v)与点(u', v')的齐次坐标特征向量a(u', v')相乘, 表示为
ga≃
1.2.3 细节样式生成器
印刷体汉字图像xsc和该汉字对应的结构图xsk通过结构样式生成器生成图像ys, ys虽然是具有正确汉字结构的书法汉字图像, 但仍存在图像中的书法汉字笔画扭曲、笔画边界模糊等问题, 如图2所示.因此本文通过细节样式生成器优化图像ys, 提高生成图像的质量.
 | 图2 结构样式生成器生成的图像中存在的问题Fig.2 Problems in images generated by the structure style generator |
首先将生成图像ys通过细节样式特征提取器经卷积操作得到内容特征, 然后使用反卷积操作上采样至目标分辨率, 生成书法汉字图像yc.细节特征提取器Cγ 的4层网络层均使用相同的5× 5的卷积核, 激活函数LeakyRelu的斜率为0.2, 批量归一化层且步幅为4.细节样式解码器G_Cδ 的4层网络层均使用相同的5× 5反卷积内核、Relu激活函数及批量归一化层.
编码器-解码器体系结构能保持输入图像与输出图像的属性一致[29], 细节样式生成器使用编码器-解码器体系结构, 保持细节样式生成器生成图像yc的汉字结构不变, 使汉字图像yc的汉字结构完整、正确.在结构样式生成器生成的图像ys中, 书法汉字存在笔画扭曲、笔画边界模糊的问题, 如图2所示, 对比图像ys与图像ytg后发现, 图像ys出现笔画扭曲位置的像素值高于图像ytg相应位置的像素值, 图像ys出现笔画边界模糊位置的像素值低于图像ytg相应位置的像素值.L1损失函数是将2个图像逐像素对比后取绝对值, 使用L1损失函数(像素性损失函数)有利于指导细节样式生成器细化图像ys, 使其生成的图像yc中汉字笔画平滑, 笔画边界清晰.结构相似性(Structural Similarity, SSIM)损失函数[30]是使用2个图像的均值作为亮度估计, 标准差作为对比度估计及协方差作为结构相似程度的度量, 使用SSIM损失函数有利于指导细节样式生成器优化图像ys的细节, 使生成的图像yc更符合人类视觉感知, 提高图像yc的图像质量.因此细节样式生成器通过对抗性损失函数、像素性损失函数及结构性损失函数组成的优化目标函数, 优化结构样式生成器的生成图像ys, 细化书法汉字的笔画细节, 提高书法汉字字符图像的质量, 最终得到结构完整正确的高质量目标书法汉字图像yc.
1.2.4 损失函数
研究目标是为了尽可能逼真地生成目标书法汉字图像, 该任务既要求像素重建的精度, 也要求汉字字符笔画的平滑程度和汉字字符结构的完整程度.因此本文使用如下3种损失函数训练网络模型.
1)对抗性损失函数.该函数使模型尽可能逼真地生成目标书法风格的汉字字符图像.
结构样式生成器相关的对抗性损失函数为
Lds=
细节样式生成器相关的对抗性损失函数为
Ldc=
总对抗性损失函数为
Ld(G_Sβ , G_Cδ , Dη )=λ 1Lds+λ 2Ldc.
其中:xsc为给定的标准印刷体源汉字字符图像, xsk为源汉字字符的骨架图像, ys=G_Sβ (xsc, xsk)为结构样式生成器生成的字符图像, yc=G_Cδ (ys)为细节样式生成器生成的字符图像, ytg为目标书法汉字字符图像, (xsc, ytg)为真实图像对, (xsc, ys)为结构样式生成器生成的虚假图像对, (xsc, yc)为细节样式生成器生成的虚假图像对, E(· )表示函数的期望值, ln(Dη (xsc, ytg))表示判别器将真实图像对判别为真的概率, ln(1-Dη (xsc, ys))、ln(1-Dη (xsc, yc))表示判别器将虚假图像对判别为假的概率, λ 1、λ 2表示加权超参数.
2)像素性损失函数.该函数使模型尽可能地生成与目标书法汉字字符内容相似的字符图像, 提高生成的字符图像中像素的重建精度和汉字字符笔画的平滑程度.总像素性损失函数为
$L_{p}\left(G_{-} S_{\beta}, G_{-} C_{\delta}\right)=\lambda_{3} \underset{y_{t g} \sim Y}{E}\left\|y_{t g}-y_{s}\right\|_{1}+\lambda_{4} \underset{y_{t g} \sim Y}{E}\left\|y_{t g}-y_{c}\right\|_{1}$
其中, ys=G_Sβ (xsc, xsk)表示结构样式生成器生成的字符图像, yc=G_Cδ (ys)表示细节样式生成器生成的字符图像, ytg表示目标书法汉字字符图像, E(· )表示函数的期望值,
3)结构性损失函数.该函数使模型尽可能地生成与目标书法汉字字符结构相似的字符图像, 保证生成的字符图像汉字结构的完整正确.为了度量生成图像z与目标图像t的结构相似性, 引入SSIM量化2个图像的结构相似度.给定图像z、t, 结构相似度定义为
SSIM(t, z)=
其中, μ t表示t的平均值, μ z表示z的平均值,
c1=
表示维持稳定的常数, V表示像素值的动态范围, k1=0.01, k2=0.03.
因此总结构性损失函数为
$\begin{aligned} L_{s t u}\left(G_{-} S_{\beta}, G_{-} C_{\delta}\right)=& \lambda_{5} \underset{y_{t g} \sim Y}{E}\left[\frac{1}{2}\left(1-\operatorname{SSIM}\left(y_{t g}, y_{s}\right)\right)\right]+\\ & \lambda_{6_{y_{t g} \sim Y}} E\left[\frac{1}{2}\left(1-\operatorname{SSIM}\left(y_{t g}, y_{c}\right)\right)\right] \end{aligned}$
其中,
因此方法的总损失函数为
Ltotal(G_Sβ , G_Cδ , Dη )=Ld(G_Sβ , G_Cδ , Dη )+ω 1Lp(G_Sβ , G_Cδ )+ω 2Lstu(G_Sβ , G_Cδ ),
其中ω 1、ω 2为加权超参数.
模型的总优化目标可概括为
由于目标样本的训练数据集较少, 导致将训练不可见的标准印刷体汉字图像通过已训练的生成模型生成的书法汉字图像存在模糊、汉字结构不正确等问题.因此本文提出通过伪目标样本的半监督学习方法, 用于解决书法汉字数据集较少的问题.本文的伪目标样本的半监督学习方法中对汉字进行自动拆分后重组是为了增加学习样本, 提高半监督学习效率.对于不能进行拆分的其它汉字, 基于结构约束的条件堆叠生成对抗网络模型依然能完整学习生成结构正确的高质量书法汉字图像.
1.3.1 伪目标样本生成
首先将标准印刷体汉字xsc通过水平垂直投影法自动分割汉字的部件
 | 图3 伪目标样本的生成流程图Fig.3 Flowchart of generating pseudo target sample |
当上述得到的图像y'p与图像y″p的相似度高于设置阈值时, 图像y″p才被认为是有效的伪目标样本ypt.
1.3.2 半监督学习训练策略
本文的本监督学习训练集包括成对的图像对
$D_{t}=\left\{\left(x_{i}, y_{i}\right)\right\}_{i=1}^{N_{t}}, y_{i} \in Y_{t g}$,
和只有标准印刷体的汉字字符图像
$D_{u}=\left\{\left(x_{i}\right)\right\}_{i=1}^{N_{u}}$.
因此本文需选择有效的伪目标样本, 得到伪目标样本的图像对
$D_{u}=\left\{\left(x_{i}, y_{i}\right)\right\}_{i=1}^{N_{u}}, y_{i} \in Y_{p t}$.
本文工作能对左右结构的汉字进行自动拆分, 目前尚无法对上下结构的汉字实现自动拆分, 因此在训练模型前, 对左右结构的汉字进行标记, 用于判断是否对该汉字自动进行左右拆分.
首先, 本文仅使用成对的图像对数据图像训练方法(图1).当方法训练一遍后, 通过伪目标样本生成技术, 在数据集
$D_{u}=\left\{\left(x_{i}\right)\right\}_{i=1}^{N_{u}}$
中根据标记筛选左右结构的标准印刷体汉字生成图像y'p与图像y″p.仅当图像y'p与图像y″p的相似度高于设置阈值时, 图像y″p为对应有效的伪目标样本ypt.然后结合无伪目标样本的图像对数据集
$D_{t}=\left\{\left(x_{i}, y_{i}\right)\right\}_{i=1}^{N_{t}}, y_{i} \in Y_{t g}$
和有伪目标样本的图像对数据集
$D_{u}=\left\{\left(x_{i}, y_{i}\right)\right\}_{i=1}^{N_{u}}, y_{i} \in Y_{p t}$,
形成新的训练集, 该训练集用于训练方法(图1).这个过程将会在训练集中逐步添加有可靠的伪目标样本的图像对.同时, 迭代训练能逐渐提高未成对数据集的生成图像质量.本文重复此迭代训练过程50次.
据调查所知, 目前尚无明确定义的书法汉字字符图像数据集D.因此本文在书法作品网站上收集筛选颜真卿楷体书法汉字图像, 共1 014幅.本数据集已开源(下载网址:https://github.com/QiangZiBro/kai_character_dataset).由于书法汉字作品大部分使用毛笔和黑色墨水书写, 因此假设汉字字符图像是灰度图, 数据集预处理中将图像的通道数修改为1, 同时将图像大小统一为128× 128, 方便实验的进行.
随机初始化网络模型的权重.使用β 1=0.5, β 2=0.999的自适应矩估计(Adaptive Moment Estimation, Adam)优化器训练网络模型, 批处理大小(Batch Size)为16.由于判别器的学习速率快于生成器的学习速率, 因此在更新判别器Dη 一次后, 更新生成器G_Sβ 、G_Cδ 两次.模型训练200次, 将前100次的初始学习速率设置为0.001, 而后100次的衰减速率设置为0.01.
实验使用如下指标值:L1损失(L1 loss)、均方误差(Mean Square Error, MSE)、SSIM.L1 loss、MSE指标值越小表示生成图像与目标图像越相似, SSIM指标值越大表示生成图像与目标图像的结构越相似.
本文对比如下汉字字符风格迁移方法.
1)Pix2pix.Pix2pix是基于CGAN的图像风格迁移网络, 并通过L1距离损失和对抗性损失进行优化.
2)CycleGAN.CycleGAN学习从输入图像到输出图像的映射, 不需要配对的数据.
3)Zi2zi.Zi2zi是Pix2pix对汉字的一种应用和扩展, 带有类别嵌入功能.
将4种方法在数据集D上进行训练, 本文选取10个结构多样的代表性汉字(选取的汉字结构包括独体字、左右结构、上下结构、上中下结构、品字结构、全包围结构和半包围结构), 实验结果如图4所示.由图可见, 本文方法生成的书法汉字图像质量最优.
 | 图4 各方法生成的书法汉字图像Fig.4 Calligraphic Chinese character images generated by different methods |
分别对4种方法的生成图像与目标图像进行数值定量分析, 结果如表2所示.由表可知, 本文方法生成的书法汉字图像的数值性能指标最优.
| 表2 各方法的定量分析结果 Table 2 Numerical quantitative analysis of different methods |
由于Pix2pix仅使用对抗性损失函数和像素性损失函数, 生成的书法汉字图像与目标图像相似, 但是书法汉字数据的训练集较小, 导致生成的书法汉字图像质量较差.Zi2zi在Pix2pix的基础上嵌入类别向量, 是对汉字的扩展应用, 从而实现单模型生成多类别风格汉字图像, 但也不适用于训练集较小的汉字生成任务, 生成的书法汉字图像与Pix2pix相似, 但图像质量不高.CycleGAN通过不成对的数据集学习源汉字和书法汉字的风格, 生成的书法汉字图像并未改变源汉字周正的轮廓, 只是在源汉字的基础上改变汉字的笔画风格, 与目标汉字图像不太相似且存在结构缺失的问题.本文方法扩充书法汉字数据的训练集, 基于结构约束的条件堆叠网络模型生成结构完整正确、质量较优的书法汉字图像.
将4种方法在数据集D中进行训练后, 生成训练不可见的书法汉字图像.本次选取11个训练不可见的汉字生成图像, 结果如图5所示.Pix2pix、CycleGAN的生成书法汉字图像存在结构不完整、笔画细节模糊的问题, Zi2zi的生成书法汉字图像存在笔画扭曲、图像质量不高的问题, 而本文方法生成书法汉字图像汉字结构正确、图像质量较高.由此表明, 本文方法可实现生成训练不可见的书法汉字图像.
 | 图5 各方法生成的训练不可见书法汉字图像Fig.5 Unseen calligraphy Chinese characters generated by different methods |
针对可能影响方法性能的因素, 包括结构约束针对可能影响方法性能的因素条件(Structure Constraint, SC)、堆叠生成网络(Stack Network, SN), 本文通过消融实验进行分析.实验选取10个结构多样的代表性汉字, 结果如图6所示, 定量分析结果如表3所示.使用SN生成图像的L1 loss、MSE、SSIM指标高于Baseline, 表明使用SN可提高生成书法汉字的图像质量, 但可能丢失汉字的结构信息, 导致生成图像结构不正确(如佇、烦、炎、冀、压), L1 loss、MSE指标偏高.引入SC后生成图像的L1 loss、MSE指标低于Baseline, SSIM指标高于Baseline, 表明引入SC不仅可学习到更多的汉字结构特征, 而且可提高生成书法汉字的图像质量.这表明引入SC及使用SN可更有效地学习更多汉字特征, 生成字符结构完整正确、图像质量更高的书法汉字图像.
 | 图6 不同因素加入后生成的汉字图像Fig.6 Chinese character images generated by adding different factors |
| 表3 不同因素加入后的定量分析结果 Table 3 Quantitative analysis results after adding different factors |
本文方法中结构样式生成器的主要作用是生成结构完整正确的书法汉字图像, 细节样式生成器的主要作用是将结构样式生成器生成的图像进行优化, 使汉字笔画更平滑, 最终生成结构完整正确的高质量书法汉字图像.在实验中对比结构样式生成器和细节样式生成器的生成汉字图像可视化结果, 如图8所示.由图可直观发现, 结构样式生成器生成的汉字图像得到大致的汉字结构, 而细节样式生成器对该汉字图像进行细节优化, 生成结构正确质量较优的书法汉字图像.
 | 图7 2个生成器的生成汉字图像Fig.7 Chinese character images generated by 2 generators |
 | 图8 本文方法生成行书书法汉字图像Fig.8 Calligraphic Chinese character images of running script generated by the proposed method |
本文主要通过调整超参数λ 3、λ 4、λ 5、λ 6的取值控制损失函数, 确保结构样式生成器和细节样式生成器的性能, 使结构样式生成器生成的汉字图像得到正确的汉字结构, 细节样式生成器对该汉字图像进行优化生成结构完整的高质量书法汉字图像.超参数λ 3、λ 4、λ 5、λ 6取值不同时, 实验结果如表4所示.由表可得, 本文实验选取的部分超参数取值为λ 3=0.2, λ 4=0.8, λ 5=0.8, λ 6=0.2.
| 表4 在不同超参数取值下的结构样式生成器和细节样式生成器的生成汉字结果对比 Table 4 Comparison of Chinese characters generated by structure style generator and detail style generator with different hyperparameter values |
本文在书法作品网站上收集筛选书法家王羲之行书书法汉字图像, 共486幅.相比楷体, 行书书法结构更不规则, 数据集量更少, 因此行书书法的生成任务更困难.使用本文方法也能生成行书书法汉字, 结果如图8所示.由图可见, 本文方法生成的行书书法汉字仍存在部分汉字笔画模糊、结构不完整等问题, 生成效果低于楷体书法汉字的生成效果, 后续仍需针对行书书法汉字的生成工作优化模型.
书法是中国特有的艺术, 中国书法成为一个民族符号, 代表中国文化博大精深和民族文化的永恒魅力, 书法汉字的生成研究具有重要的历史文化意义和现实意义.目前对书法汉字的生成研究大多在汉字生成过程中引入汉字的知识信息, 研究成果的扩展性不高, 本文提出基于结构约束的条件堆叠生成对抗网络的书法汉字生成方法, 仅引入源汉字的结构图作为结构约束条件和汉字结构监督信息, 将源汉字图像通过基于结构约束的条件堆叠生成对抗网络模型生成目标风格的书法汉字, 目标书法汉字图像结构正确、质量较好.本文研究的书法家颜真卿楷体风格的书法汉字数据集存在数据量较少的问题, 由此提出伪目标样本的半监督学习方法, 通过迭代学习优化模型, 生成训练不可见的目标书法汉字.目前本文方法可生成有效的楷体书法汉字, 但由于行书风格的书法汉字比楷体书法汉字更不规则, 行书风格的书法汉字的生成效果较不理想.因此, 今后工作将针对行书风格的书法汉字的特点设计有效的目标函数, 优化模型结构, 最终生成质量较高的行书风格的书法汉字图像.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|