
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于医学影像分割方法的多模态语料库构建
[林玉萍1  , 郑尧月
, 郑尧月2 , 郑好洁2 , 张栋3 , 王丛2 , 李小棉1 , 李颖玉1 , 田智强2 ]
, 郑尧月, 郑好洁, 张栋, 王丛, 李小棉, 李颖玉, 田智强]
|
|



作者简介: 
林玉萍,硕士,副教授,主要研究方向为语料库构建、二语习得.E-mail:linyouchen@xjtu.edu.cn. 
郑尧月,硕士研究生,主要研究方向为机器学习、医学影像分析.E-mail:1037268262@qq.com. 
郑好洁,硕士研究生,主要研究方向为图像分割.E-mail:825138603@qq.com. 
张 栋,博士研究生,主要研究方向为机器视觉、机器学习、医学图像处理.E-mail:dongzhangcv@gmail.com. 
王 丛,硕士研究生,主要研究方向为图像处理、视频内容分析.E-mail:297414042@qq.com. 
李小棉,硕士,讲师,主要研究方向为语言学、医学英语.E-mail:linlin@xjtu.edu.cn. 
李颖玉,博士,副教授,主要研究方向为语料库语言学、翻译学、外语教学.E-mail:hiwendy@xjtu.edu.cn.
电子文本病历语料库可提供相关医学影像的定性诊断结果,但缺乏直观影像和文本标注信息,不利于有效管理医学数据和医科学生自主学习相关医学知识.针对此问题,文中提出基于深度水平集算法的医学影像分割方法,对医学影像进行自动分割,给出感兴趣区域的轮廓结果及相关定量指标,并结合自然语言处理方法实现电子病历文本的标注,增强影像与文本病历多模态语料库的信息表征能力.在青光眼影像数据上的实验表明,文中方法可精准分割眼底图像中视盘和视杯,有效构建具有直观影像标记与对应病历文本的多模态语料库.
, ZHENG Yaoyue, ZHENG Haojie, ZHANG Dong, WANG Cong, LI Xiaomian, LI Yingyu, TIAN Zhiqiang
AboutAuthor:
LIN Yuping, master, associate professor. Her research interests include corpus constru-ction, second language acquisition.
ZHENG Yaoyue, master student. Her research interests include machine learning and medical image analysis.
ZHENG Haojie, master student. Her research interest includes image segmentation.
ZHANG Dong, Ph.D. candidate. His research interests include machine vision, machine learning and medical image proce-ssing.
WANG Cong, master student. Her research interests include image processing and video analysis.
LI Xiaomian, master, lecturer. Her research interests include linguistics and medical English.
LI Yingyu, Ph.D., associate professor. Her research interests include corpus lingui-stics, translation studies and TESOL.
Electronic medical records(EMRs) corpus provides qualitative diagnosis results of related medical images. However, the good management of medical data may be affected due to the lacking of labeled images and texts and it is hard for medical students to acquire the related medical knowledge independently. To solve this problem, a medical image segmentation method based on the deep level set algorithm is proposed to segment medical images automatically and output contour results of the interested area and related quantitative indicators. Electronic medical record text is annotated grounded on natural language processing methods. The information representation of medical record texts and images of multimodal corpus is enhanced. Experimental results on the glaucoma image dataset show that the proposed method segments the optic disc and the optic cup in the fundus image accurately and a multimodal corpus with self-evident labeled images and EMRs is constructed effectively as well.
本文责任编委 左炜亮
Recommended by Associate Editor ZUO Weiliang
生物医学语料库在医学研究中具有重要作用, 而我国现有医学语料库大多为基于文本的语料库[1, 2, 3].随着自然语言处理技术(Natural Language Processing, NLP)在电子化病历(Electronic Medical Record, EMR)的命名实体识别、实体修饰识别和实体关系抽取等关键信息抽取与分析中的广泛使用[4], 一些性能较优的NLP促使病历文本语料库的构建取得一定的成果.苏嘉等[5]利用NLP技术, 提出适应中文电子病历特点的心血管疾病风险因素标注方法, 构建关于心血管疾病风险因素的标注语料库.Li等[6]将EMR中单个实体的分类问题转换为序列分类问题, 利用双向长短期记忆神经网络组合条件随机场对词向量进行分类和关系预测, 获得较理想的F1指标.蒋志鹏等[7]针对中文EMR模式化强的子语言特征, 提出面向数据句法分析和层次句法分析融合模型, 有效改善中文电子病历句法分析效果, 具有较高的F1指标.然而, 单模文本病历语料库在进行案例分析和教学授课时, 缺乏直观影像的标记, 对医生积攒临床经验和向医科学生传授医学知识造成不便.
在实际的临床诊疗场景中, 医学影像与病历文本信息的关系是一一对应的.若利用医学影像分析技术, 通过直观可视的病理标记, 与文本病历相辅教学, 可以让学生更好地掌握与提升相关病例的判断能力, 提高学生的学习兴趣.魏微[8]针对医学英语的学习, 建立医学英语多模态语料库系统, 结合视频、音频等多媒体辅助教学, 有效提升医学教学质量.然而, 海量的医学影像数据和病历数据作为诊断疾病的重要依据却难以被二次利用.张成智[9]通过分析国内外多模态语料库的建设情况发现, 目前国内多模态语料库的构建仍处于起步阶段, 相关研究依然十分缺乏.因此, 如何通过一定的技术手段充分挖掘海量数据信息, 构建基于影像分析和文本病理结合的多模态医学语料库, 进行临床辅助诊断和教学管理, 具有重要的理论和实践意义.
现有的一些医学数据库中包含医学影像和相关的病例文本.病例文本一般都是直接给出诊断结果, 它可通过现有的NLP相关方法进行标注.然而, 直观的医学影像却大多缺乏标注的信息, 影像可视化理解存在一定困难, 不能有效地为医学数据的管理和医科学生自主学习相关医学知识提供帮助.例如, 青光眼是一种慢性、不可逆的眼部疾病[10, 11], 特点是视神经头的结构改变, 优先发生在视盘(Optic Disc, OD)的上、下极点, 而视杯(Optic Cup, OC)垂直方向增大的距离大于水平方向增大的距离.因此, 大的杯盘比(Vertical Cup-to-Disc Ratio, VCDR)被认为是青光眼的一个显著特征[12], 它的自动分割结果在临床诊断上具有重要意义.
近年来, 医学影像分析处理在自动分割方法研究方面做出大量工作, 一定程度上提高影像分割质量, 缩短模型预测时间.根据工作原理, 现有的影像分割方法主要分为三类:模板匹配的方法、基于变形模型的方法和基于机器学习的方法.
模板匹配的方法通过建立图像目标元素, 计算特征, 在图像中搜寻匹配的目标.Wong等[13]提出改进的水平集方法, 获得青光眼的OD边界, 拟合椭圆平滑OD边界.Zheng等[14]将先验信息与青光眼OC和OD整合, 利用基于图切割技术的一般能量函数完成分割任务.基于模板的方法容易实现, 但是需要大量的采样点, 匹配目标角度和尺度变化会严重影响算法的鲁棒性.
基于变形模型的方法需要对轮廓进行初始化, 根据各种能量项使目标边缘变形, 从而实现目标分割.此方法能量项通常由图像梯度、图像强度和边界平滑度[15]定义.Joshi等[16]使用分析像素附近的两个纹理特征空间和局部红色通道强度改进Chan-Vese模型, 采用改进的基于区域的活动轮廓模型分割OD边界.基于变形模型的方法可获得较好的病理区域分割结果, 但对初始化敏感, 导致模型不稳定.
基于机器学习的方法被证明是一种强大的影像分割工具[17, 18, 19, 20].Maninis等[21]采用基于VGG-16网络[22]的全卷积神经网络[18]和迁移学习算法, 实现较优的OD分割效果.大部分基于机器学习的方法都能实现自动分割OD和OC, 获得较优的分割结果.但是, 在医学影像方面, 此类方法还需进一步提升对病理区域的边界细节的分割精度.
针对上述问题, 本文提出基于深度水平算法的医学影像分割方法.对医学影像进行自动分割, 给出感兴趣区域(Region of Interest, ROI)的轮廓结果及相关定量指标, 并结合自然语言处理方法实现电子病历文本的标注, 增强影像与文本病历多模态语料库的信息表征能力.在青光眼影像数据上的实验表明, 本文方法可精准分割眼底图像中OD和OC边界, 为构建可视化医学影像标记和相应病历文本的多模态语料库提供可靠的自动化分割模型.本文方法可有效辅助医生临床诊断与案例分析, 帮助医科学生更好地掌握青光眼的病症知识, 促进教学管理, 提升教学质量.
基于深度水平算法的医学影像分割方法的网络结构由预测部分和演化部分组成.如图1 所示, 首先, 给定一个输入图像, 获取ROI顶部、底部、左边和右边的4个极值点, 对这4个极值点进行配对连接, 可得到2个相交的线段.再将2个相交的线段和4个极值点作为置信图, 与输入图像同时输入卷积神经网络(Convolutional Neural Network, CNN)编码模块.然后, 通过CNN编码器获得特征图, 经过预测模块可获得水平集演化参数和类概率图.预测模块由4个特征金字塔池化模块(Pyramid Pooling Mo-dule, PPM)组成, 其中, 3个PPM预测初始轮廓曲线D和水平集演化参数M、g, 1个PPM模块预测P作为概率图, 用于计算有效轮廓的损失.最后, 对预测的初始曲线进行T步演化, 得到最终的边界预测结果.
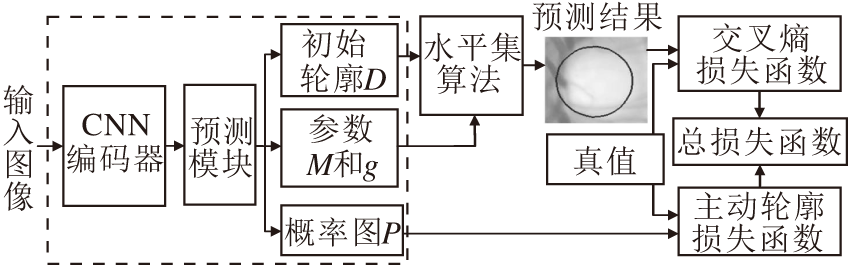 | 图1 本文方法框图Fig.1 Flow chart of the proposed method |
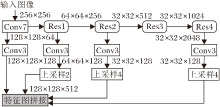
本文方法中CNN编码器是利用跃层连接方式和注意力机制模块[23]构建的101层残差网络模型(Residual Network101, ResNet-101)[24], 用于获取输入图像的多尺度特征和更具选择性的强表征特征.如图2所示, 灰色模块是多个特征张量的拼接操作, 输出作为预测块的输入.拼接特征分别来自7×7卷积、残差块Res1、Res2、Res4对前一层输出特征图分别进行3×3卷积编码, 然后采用尺度因子为2和4的双线性插值进行上采样操作, 使特征图具有相同的空间尺度(128×128).
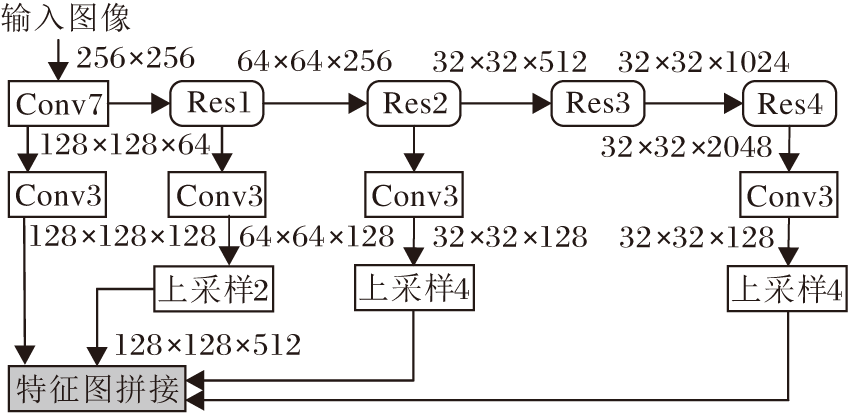 | 图2 CNN编码器框图Fig.2 Flow chart of CNN encoder |
由于内部能量避免过度平滑有时会损害大曲率的区域, 为了通过外部能量将初始曲线提升到所需的位置, 本文方法的预测模块采用4种不同尺度的PPM构成, 分别预测初始曲线D、外部能量M和内部能量g这3个水平集演化参数.
在水平集演化部分, 初始曲线使用距离函数D表示[25], 其中零距离集表示初始曲线.根据预测模块获得的参数由迭代方式对初始曲线进行演化.在经过T步进化后, 得到预测结果
为了提高分割性能, 本文方法基于极值点扩展先验知识, 主要思想是:利用4个极值点生成2个相交的线段, 并将线段和极值点作为置信图[26].具体来说, 图像中的每个像素与相交线段之间都有距离, 可使用距离生成一个置信度映射.该映射为图像域中的每个像素分配一个置信度评分.结合极值点与置信图后作为网络模型的附加通道, 将其与输入图像连接, 同时输入网络中进行训练学习.
极值点更可能位于ROI, 这是一个有用的训练信息.通过极值点可得到适合多数情况下的信息:1)4个极值点可配对连接成2个相交的线段s1和s2; 2)2条线段的交点o可能属于ROI; 3)图像Ω中的任意点x距离线段有一个距离值, 可假设x和2条线段之间的距离越小, x越有可能属于ROI, 反之亦然.将线段s1、s2和交点o作为坐标系, 置信图
ds1(x)=
其中, ds1(x)、ds2(x)分别表示点x到线段s1、s2的距离, dist(x, s)表示点x到线段s的距离, σ s粗略估计沿线段s的方差.置信图可通过
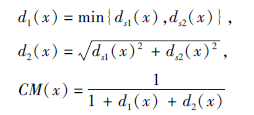
获得, 其中d1(x)、d2(x)测量x点到线段s1、s2的切比雪夫和马氏距离.同时, 为了让网络学习更多有区分性的特征, 提高分割性能, 受Chen等[27]的启发, 结合AC损失和加权的二值交叉熵损失, 并考虑内外面积和边界大小, 即
L=Lce+λ Lac,
其中, λ 为AC损失函数的权重, AC损失函数定义如下:
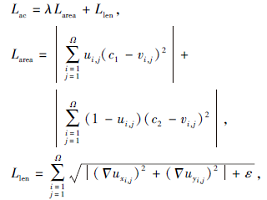
其中, u表示分割结果, v表示给定图像.c1表示物体曲线内部能量, c2表示曲线外部能量.源自
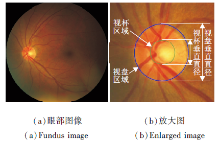
青光眼是不可逆失明的主要原因.青光眼的症状包括视网膜神经纤维层和视神经头的改变, 如视网膜神经边缘变薄, 视杯增大, 导致VCDR增加.VCDR的测量结合其它临床特征是青光眼分类的方法之一[28, 29, 30].由于OD和OC区域在形状、大小、颜色等方面的差异, 在影像中得到可靠、准确的分割结果是一项具有挑战性的任务.在临床实践中, 彩色眼底照相是检查视网膜疾病最具成本效益的成像方式[31].在彩色眼底影像中, OD和OC通常呈亮黄色.正常眼和青光眼眼底图像的示例如图3所示, (b)为局部增大的视盘区域, 其中视盘和视杯分别用外侧的蓝色线和内侧的绿色线标出, 垂直线是视盘和视杯的直径.
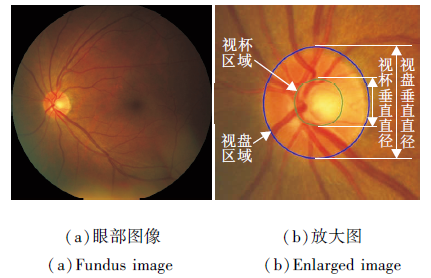 | 图3 REFUGE数据集上眼部图像示例Fig.3 Example of fundus image in REFUGE dataset |
本文利用公共眼底图像数据集REFUGE[31]进行OD和OC分割, 评价方法性能.ERFUGE数据集包括1 200幅彩色眼底图像, 其中120幅为青光眼患者的, 1 080幅为非青光眼患者的.所有眼底图像以每个颜色通道为8位的JPEG格式存储.数据集由官方划分为3个子集, 每个子集包含400幅眼底图像, 分别包含10%的青光眼病例和90%的非青光眼病例.图像分辨率为2 124×2 056和1 634×1 634.每幅图像中OD和OC的标注由专家手工标注.
本文采用的量化指标分别是戴斯相似系数(Dice Similarity Coefficient, DSC)、敏感度(Sensi-tivity, Sen)和特异度(Specificity, Spec)[17, 18, 19, 20].
DSC度量2个区域之间重叠的部分, 定义如下:
DSC=(
其中, Yk 和
Sen和Spec分别定义如下:
Sen=(
其中, TP表示真阳性, TN表示真阴性, FP表示假阳性, FN表示假阴性.
硬件环境为NVIDIA GTX 1080Ti的ubuntu16.04系统, 利用深度学习框架PyTorch和Python语言实现.训练过程设置迭代次数为70, 采用自适应矩估计(Adaptive moment, Adam)优化器进行迭代训练, 批处理大小(Batch Size)设置为5, 初始学习速率为3e-4, 重量衰减为0.000 5, 学习速率衰减因子为0.3.
对比方法如下:金字塔场景解析网络(Pyramid Scene Parsing Network, PSPNet)[17]、全卷积网络(Fully Convolutional Network, FCN)[18]、U-Net[19]、DeepLabV3+[20]、深度极值水平集演化(Deep Ex-treme Level Set Evolution, DELSE)[25]、深度极限切割(Deep Extreme, DEXTR)[32].在REFUGE数据集上, 各方法的实验结果如表1所示, 表中数据为均值±标准差, DSC、Sen和Spec值越大表示方法性能越优, 黑体数值为测试最佳值.由表可知, 对于视杯, DELSE的Sen值高于本文方法, 但方差较大, Spec值低于本文方法.对于视盘, PSPNet有过分割的倾向, 所以Sen值高于本文方法, 但Spec值低于本文方法.在整体评价指标上, 本文方法数值最高, 具有最优的分割精度.
| 表1 在REFUGE测试集上视杯和视盘分割结果对比 Table 1 Segmentation result comparison of OC and OD on REFUGE dataset % |
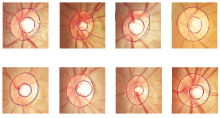
本文方法对青光眼影像中OD和OC在不同情景下的分割结果如图4所示, 图中红色线表示本文方法的分割结果, 蓝色线表示医生专家手工标记结果.由图可看出, 本文方法在大多数情况下都能较好地进行分割, 分割结果非常接近标注结果, 由此进一步验证本文方法具有可靠的精确性和鲁棒性.
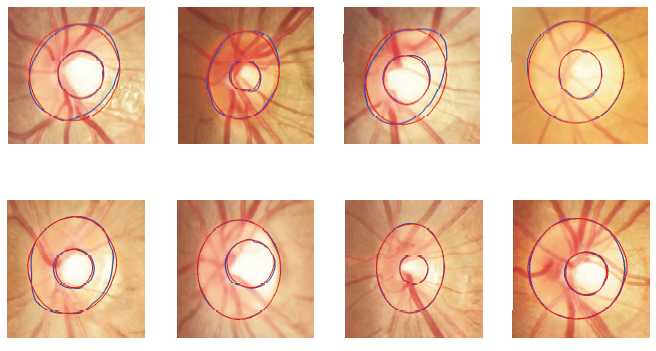 | 图4 本文方法在不同情景下的视盘和视杯可视化分割结果Fig.4 Visual segmentation results of OD and OC by the proposed method in different cases |
最后, 利用本文方法获得的精确分割结果, 结合现有NLP实现电子病历文本的标注[5, 7], 构建文本和影像的多模态语料库.对于构建好的多模态语料库, 可通过本文方法对医学影像进行自动分割, 通过特征信息匹配相应的医学影像, 也可通过文本病历的关键词匹配对应的文本病历.
这种信息对等互补模式可应用在如下多种医学工作任务中.1)本文方法构建的多模态语料库可在实际的临床中辅助医生诊断疾病, 即对当前的医学影像进行处理后, 与医学影像语料库中的医学影像进行对比分析, 结合相关文本病历对当前的患者进行疾病的诊断与治疗.2)可根据患者的病症描述匹配医学影像语料库中的文本病历和相关影像, 辅助医生进行诊断.3)医学影像多模态语料库可直接应用到医科学生的教学工作中.通过医学影像多模态语料库增强可视化影像分析与文本病历结合的模式, 促进医科学生对病症的掌握, 提升对病状的判断与分析能力.医科学生可通过多模态语料库, 对单一医学影像进行疾病的诊断, 模拟真实的病患诊断过程, 提高医科学生的自主学习能力, 激发医科学生学习的主动性和积极性, 进一步积累临床经验, 提高医疗水平.
本文提出基于深度水平集算法的医学影像分割方法, 对眼底图像中视盘和视杯进行区域分割, 得到有关青光眼的图像轮廓及量化结果.将所得结果结合文本病历信息, 构建多模态语料库, 充分利用信息对等互补模式, 有效辅助医生临床诊断治疗, 帮助医学生掌握有关青光眼的病症.
在多模态语料库的扩充方面, 将进行下一步的研究与开发.虽然本文方法可直接用于分割新的影像数据, 但也存在一定的局限性, 即由极值点构建的置信图并不适合非凸属性的分割目标, 这也是未来工作改进的方向.此外, 可考虑对新的没有病例文本的医学影像进行分割, 再根据分割结果及量化结果自动生成一个文本病历以匹配相关的医学影像.通过这种方式可继续扩充多模态的医学语料库, 使医生和医科学生获得足够多的研究样本以进行教学与学习.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|