






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
融合人群密度的自适应深度多目标跟踪算法
[刘金文1, 2, 3  , 任卫红
, 任卫红4 , 田建东1, 2 ]
, 任卫红, 田建东]
|
|



作者简介:

刘金文,硕士研究生,主要研究方向为图像处理、目标跟踪.E-mail:liujinwen@sia.cn.

任卫红,博士,助理教授,主要研究方向为图像处理、模式识别.E-mail:renweihong@hit.edu.cn.
多目标跟踪技术不能较好地解决目标严重遮挡场景下的多目标跟踪问题,因此文中提出融合人群密度的自适应深度多目标跟踪算法.首先,融合人群密度图和目标检测结果,利用人群密度图的位置和计数信息修正检测器结果,消除漏检、误检.然后,使用自适应三元组损失改进行人重识别模型的损失函数,提高对重识别特征的辨别能力.最后,使用外观和运动信息进行目标关联,得到最终的跟踪结果.实验验证文中算法可有效解决目标严重遮挡场景下的多目标跟踪问题.
AboutAuthor:
LIU Jinwen, master student. His research interests include image processing and object tracking.
REN Weihong, Ph.D., assistant profe-ssor. His research interests include image pro-cessing and pattern recognition.
Multi-object tracking technology cannot well solve the problem of multi-object tracking in the scenarios with objects severely occluded, and therefore an adaptive deep multi-object tracking algorithm fusing crowd density is proposed. Firstly, the crowd density maps and object detection results are fused, and the location and the count information of crowd density maps are utilized to correct the detector results to eliminate missing and false detections. Then, adaptive triplet loss is employed to improve the loss function of the re-identification model and thus the discrimination of the algorithm for the re-identification feature is enhanced. Finally, final tracking results are obtained using the appearance and motion information for objects association. It is verified through the experiments that the proposed algorithm effectively solves the problem of multi-object tracking in severely occluded scenes.
本文责任编委 徐勇
Recommended by Associate Editor XU Yong
目标跟踪包括单目标跟踪与多目标跟踪.相对单目标跟踪, 多目标跟踪需要解决更复杂的问题, 不仅需要解决单目标跟踪遇到的所有问题, 还需要解决如下问题[1]:轨迹的起始与终止, 即如何处理新出现的目标及如何判定跟踪轨迹的结束; 数据关联与相似性度量, 即准确区分每个目标, 正确匹配跟踪轨迹和检测目标; 跟踪目标之间外观的相似性及严重遮挡问题; 目标消失再出现问题, 当目标再次出现时需要准确识别身份并进行正确的数据关联.多目标跟踪任务需要解决比单目标跟踪任务更多的问题和难点, 尽管近几年研究具有一定的进展, 但对于严重遮挡、目标外观剧烈变化、相机移动等困难场景, 跟踪效果仍然较差.因此, 有效解决上述问题对多目标跟踪算法具有重要意义.
目前的多目标跟踪算法大都基于检测-跟踪框架, 检测器结果对此类跟踪系统的性能影响较大.目标检测方法使用带有正负样本标记的输入图像有监督地训练单个目标滑动窗口检测器.但是, 对于大多数目标检测方法, 低分辨率的小目标会导致检测器性能较差.因为相比高分辨率目标, 小目标尺寸较小, 许多有分辨性的细节和特征被模糊或隐藏.检测方法将学习到的检测器应用于图像上的滑动窗口以形成置信度图.由于检测器可能会在同一目标上多次标记位置, 因此非极大值抑制通常应用于置信度图.但是, 当几个目标彼此靠近, 非极大值抑制可能会减少召回率.因此, 在目标之间频繁发生遮挡的场景下, 这种检测器往往精度较低.不同的姿势和视点会使目标外观看起来非常不同.上述这些因素对于目前的大多数目标检测方法都是非常具有挑战性的.
另一方面, 因为计数方法不同于以个体为中心的检测方法, 为避免个体级别的检测, 在图像级别上将所有对象作为一个整体建模, 或在局部图像块级别上对一小组对象进行建模, 所以目标计数方法在目标较小、频繁遮挡、外观剧烈变化等困难场景下的目标总数估计往往更优.目标计数方法旨在估计目标总数, 仅输出整幅图像[2, 3]或局部图像块[4]的目标总数, 却不知道单个目标的位置信息.感兴趣区域(Region of Interest, ROI)的目标总数只能显示人群的宏观描述, 忽略单个目标的微观信息.通常, 目标在ROI中的分布并不均匀, 单个目标的位置描述会提供更多信息, 以便进一步地分析目标.例如, 在多目标跟踪的实际应用中, 单个目标的精确位置描述要比图像中的目标总数更重要.
典型的目标计数方法使用回归模型或神经网络学习图像特征到图像中目标总数的映射[2, 3, 4].这些方法着重于目标计数而不是目标的位置信息, 尽管在目标计数方面取得较优结果, 但却失去目标的位置信息.Idrees等[5]结合头部检测器、傅立叶分析和兴趣点计数估计极端拥挤场景下局部图像块中的目标总数, 但仅改善局部图像块的计数结果.Lempttsky等[6]从输入图像的特征向量回归每个像素处的人群密度, 使用像素级的密度图估计目标数量.密度图指示图像内目标分布, 在密度图中对ROI进行积分, 得出ROI内目标计数的估计值.
SORT(Simple Online and Realtime Tracking)[7]是一种简单的在线实时跟踪算法, 利用卡尔曼滤波预测当前帧所有跟踪目标在下一帧的位置, 利用预测结果与下一帧所有检测结果之间的交并比(Intersection over Union, IoU)作为度量指标, 通过匈牙利指派算法关联检测结果和跟踪目标.尽管SORT速度较快, 但不能解决目标消失后再出现的问题, 导致ID切换次数过高.为了弥补SORT的不足, Wojke等[8]提出多目标跟踪算法(SORT with Deep Association Metric, Deep-SORT), 在SORT的基础上引入在大规模行人数据集上训练的行人重识别深度学习模型, 提取目标的表观特征, 结合目标运动信息和表观特征信息, 改善目标消失再出现情况下的跟踪效果, 减少跟踪目标ID切换次数.但是, Deep-SORT使用余弦Softmax分类器(Cosine-Softmax Classifier)[9]训练行人重识别模型, 未对样本使用采样策略, 训练过程过于简单, 导致准确性和鲁棒性较低.它的应用仅限于单个轻量级卷积神经网络(Convolutional Neural Networks, CNN)架构.
目前大多数多目标跟踪系统由检测器和跟踪器组成, 跟踪系统的性能在很大程度上取决于检测器的性能, 对于目标被严重遮挡的场景, 检测器存在不少漏检和误检.为了提升多目标跟踪算法在目标被严重遮挡场景下的跟踪性能, 本文提出融合人群密度的自适应深度多目标跟踪算法(Adaptive Deep Multi-object Tracking Algorithm Fusing Crowd Densi-ty, MOT_FCD).融合人群密度图和检测器结果, 利用人群密度图的位置和计数信息消除漏检和误检, 得到更精确的检测结果.同时利用自适应三元组损失(Triplet Loss)[10]训练行人重识别深度学习模型, 对训练样本使用有效的采样策略, 同时引入自适应机制对样本进行权重分配, 有效提升重识别特征的辨别能力.利用表观和运动信息进行目标关联, 得到精确的跟踪结果.
针对目前的多目标跟踪算法在困难场景下跟踪效果不佳的问题, 受文献[11]和文献[12]启发, 本文提出融合人群密度的自适应深度多目标跟踪算法, 具体跟踪流程如图1所示.首先融合人群密度图和检测器的输出结果, 得到更精确的检测结果.然后利用行人重识别模型和卡尔曼滤波逐帧地关联目标.
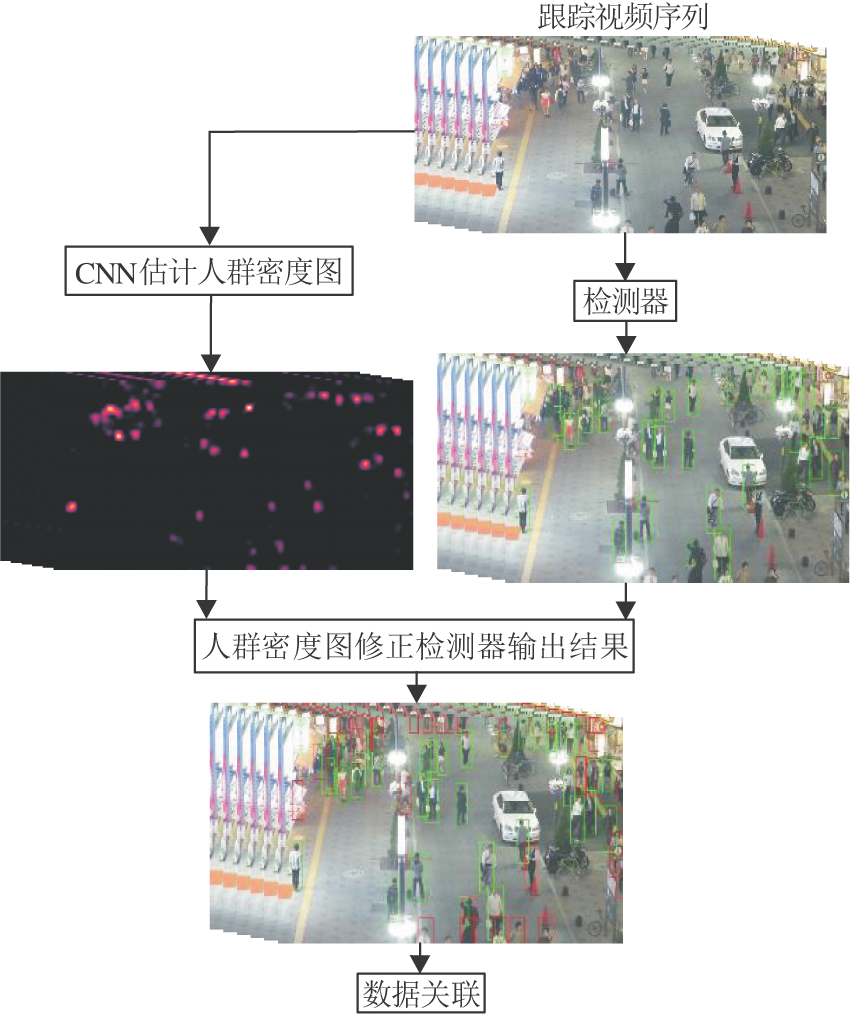 | 图1 本文算法流程图Fig.1 Flow chart of the proposed algorithm |
目前多目标跟踪算法大都基于检测-跟踪框架, 即跟踪系统包含检测器和跟踪器2个子系统, 检测器首先检测视频序列中每帧的目标, 然后跟踪器将目标进行关联形成轨迹.因此, 检测器精度影响跟踪系统的性能.一方面, 大多数目标检测方法会受目标较小、频繁遮挡、外观剧烈变化等因素影响; 另一方面, 目标计数方法在这些困难场景下往往更优.这是因为目标检测方法通常使用带有正负样本标记的图像对检测器进行有监督的训练, 从而进行个体检测.不同于以个体为中心的检测方法, 计数方法避免个体级别的检测, 在图像级别上将所有对象作为一个整体建模, 或在局部图像块级别上对一小组对象进行建模.典型的目标计数方法使用回归模型或神经网络学习图像特征到目标总数的映射[2, 3, 4].这些方法着重于目标计数而不是目标的位置信息, 尽管在目标计数方面取得较优结果, 但却失去目标的位置信息.
为了解决人群计数问题, 人群密度图[6]根据输入图像的低级特征回归每个像素处的人群密度, 使用密度图估计目标数量.密度图指示图像内目标的分布, 在密度图中对ROI进行积分, 得到目标计数的估计值.这样, 密度图既包含目标的位置信息又包含目标的计数信息.
通常将人群密度估计看作一个回归问题, 方法主要集中在特征提取和损失函数设计[5, 6, 13], 使密度估计对场景的变化具有更强的鲁棒性.近年来, 随着深度学习的发展, CNN在人群密度估计任务中得到应用[14, 15, 16], 性能良好.尽管人群密度图最初是为了人群计数, 但包含图像中人物目标的位置信息, 有利于人群的检测和跟踪.本文利用密度图的位置和计数信息修正检测器结果, 得到更精确的检测结果, 提升跟踪系统的性能.
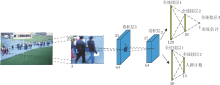
本文利用CNN估计人群密度图, 网络结构如图2所示.结构包含2个卷积层和5个全连接层, 执行人群计数和密度估计2个任务.
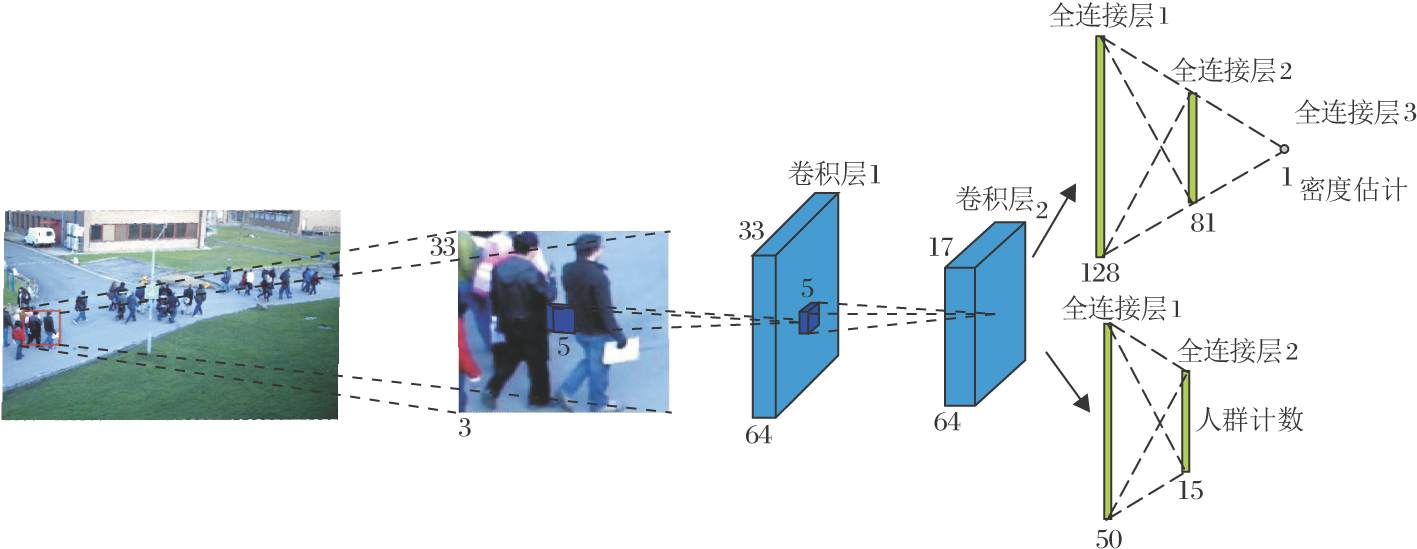 | 图2 人群密度估计卷积神经网络框架Fig.2 Framework of CNN for crowd density map estimation |
为了得到高分辨率的人群密度图, 本文采用滑动窗口的方式逐个估计每个像素处的人群密度.网络输入33× 33的图像块, 输出该图像块中心点像素的人群密度估计值.网络包含2个卷积层和5个全连接层, 第1个卷积层包含64个5× 5× 3的滤波器, 第2个卷积层包含64个5× 5× 64的滤波器.每个卷积层后紧跟1个窗口大小为2× 2的最大池化层, 步长为2× 2.在每个卷积层或全连接层后都使用线性激活函数ReLU.
如今, 已有更复杂的人群密度估计模型[17, 18, 19, 20], 但本文主要是证实人群密度图可提升跟踪器的性能, 即使不使用复杂的网络结构, 本文算法仍可取得较优的跟踪结果, 并获得较高的跟踪速度.
在训练人群密度估计模型时, 通过标注的二值图和高斯模糊核的卷积得到真实的人群密度图:
$D(d)=\underset{{{\mu }_{i}}\in P}{\mathop{\sum }}\, N(d; {{\mu }_{i}}, {{\sigma }^{2}}I), $
其中, d表示像素位置, P表示图像中标注点的集合, N(d; μ i, σ 2I)表示均值为μ i、方差为σ 2I的高斯核.方差σ 需要根据不同的场景选择不同的值.
本文同时对人群密度估计网络的人群计数和密度估计任务进行训练, 人群计数任务可辅助人群密度估计网络提取最好的特征以进行人群密度估计.网络密度估计任务的损失函数为逐像素平方误差:
${{l}_{density}}=\frac{1}{\text{N}}\overset{\text{N}}{\mathop{\underset{\text{j}=1}{\mathop{\sum }}\, }}\, \left\| \left. {{\overset{}{\mathop{\text{D}}}\, }_{\text{j}}}\text{-}{{\text{D}}_{\text{j}}} \right\| \right._{2}^{2}$
其中,
${{l}_{count}}=\frac{1}{\text{N}}\overset{\text{N}}{\mathop{\underset{\text{j}=1}{\mathop{\sum }}\, }}\, \overset{\text{K}}{\mathop{\underset{\text{k}=1}{\mathop{\sum }}\, }}\, {{p}_{jk}}ln{{\hat{p}}_{\text{jk}}}$
其中:K表示类别数目, 即计数范围; pjk表示图像块j为类别k的真实概率; ${{\hat{p}}_{\text{jk}}}$表示网络预测的概率.将密度估计任务和人群计数任务的损失函数组合为一个加权损失函数:
$l=\gamma {{l}_{density}}+{{l}_{count}}$
本文通过调节γ 值获得最优的人群密度估计结果, 最终设置γ =100.
图3为不同场景下的输入图像得到的人群密度图.
 | 图3 不同场景下由输入图像得到的人群密度图Fig.3 Crowd density maps obtained from input images in different scenarios |
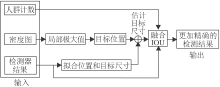
本文利用人群密度图的位置和计数信息修正检测器结果, 得到更精确的检测结果, 具体流程如图4所示.首先利用人群密度图得到每个目标的精确位置, 然后估计每个目标的大小, 最后融合人群密度图的检测结果和检测器的结果, 得到更精确的检测结果.
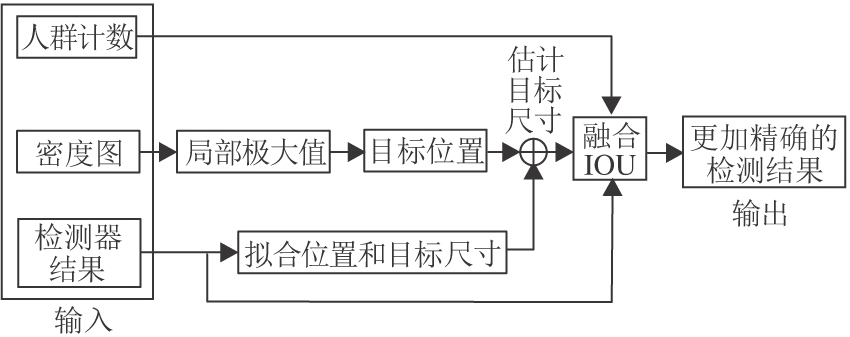 | 图4 人群密度和检测器结果融合流程图Fig.4 Fusion process of crowd density and detector results |
由于真实的人群密度图由高斯核得到, 所以通过人群密度图的局部极大值确定目标的精确位置.为了消除噪声影响, 在寻找局部极大值前先对人群密度图进行平滑滤波.局部区域大小根据不同的场景选取不同的值, 确定局部区域大小后, 通过观察密度图局部峰值的大小分布初步确定阈值的大小, 根据阈值确定局部极大值是否有效.当局部极大值小于阈值时视为噪声.阈值大小根据人群密度图的计数信息自适应调节, 当目标个数小于计数信息时降低阈值, 否则, 增大阈值.
根据置信度、检测框高度、IoU筛选检测器的检测结果, 得到有效的检测结果.由于距离相机越远目标越小, 所以沿图像纵轴对目标的宽度和高度进行线性回归.根据回归结果和位置信息估计目标的大小.为了解决估计存在的偏差问题, 在数据关联阶段融合卡尔曼运动估计结果, 得到更精确的目标大小.
筛选由人群密度图得到的每个检测结果, 计算其与检测器有效检测结果的IoU值.如果最大IoU值大于阈值, 认为此目标已被检测器成功检测, 丢弃人群密度图对应的检测结果, 其中阈值需要自适应调节.如果最终检测的目标数小于人群密度图的计数结果, 增大阈值, 否则, 减小阈值.最后合并保留人群密度图检测结果和有效的检测器检测结果, 得到更精确的检测结果.
图5为利用人群密度图对检测器结果进行修正的效果图.由(b)可看出, 当目标被其它目标或物体遮挡时, 检测器很难将其成功检测, 同时, 由于目标尺度和光照的影响, 检测器存在不少的漏检和误检.由(c)中检测结果可看出, 融合人群密度图后, 被遮挡的大部分目标被成功检测, 有效消除漏检和误检, 得到更精确的检测结果.由此可见, 利用人群密度图的位置和计数信息可弥补检测器的不足, 有效消除检测器结果中存在的漏检和误检.
 | 图5 修正检测器后的效果图Fig.5 Results after detectors being corrected |
在多目标跟踪算法中, 目标关联十分重要, 行人重识别模型可利用目标的表观信息对目标进行精准关联.对于当前帧的某个行人, 行人重识别模型会计算其与下一帧所有被检测行人的相似度, 进而根据相似度正确匹配当前帧行人与下一帧检测结果.对于由于目标因遮挡等原因在场景中消失后又重新出现的情况, 更需要行人重识别模型对重新出现的目标进行重识别, 进而继续跟踪重出现的目标.本文使用自适应Triplet Loss[10]作为行人重识别模型的训练损失函数, 对训练样本使用更有效的采样策略, 有效提升行人重识别模型的匹配精度, 提高跟踪器的性能.
行人重识别模型的损失函数应确保对于任意一幅查询图像, 其特征与所有正样本特征之间的最大距离要小于与所有负样本特征之间的最小距离, 确保对于任意给定的查询图像可得到正确的特征排列.Triplet Loss作为行人重识别模型的损失函数, 可使相同身份特征之间的距离尽可能小, 不同身份特征之间的距离尽可能大.对于锚点样本xa, 对应的正样本为与xa具有相同身份的样本xp∈ P(a), 对应的负样本为与xa具有不同身份的样本xn∈ N(a), Triplet Loss的广义形式如下:
$L={{[\text{m}+\underset{{{\text{x}}_{\text{p}}}\in \text{P}\left( \text{a} \right)}{\mathop{\sum }}\, {{\text{w}}_{\text{p}}}\text{d}\left( {{\text{x}}_{\text{a}}}, {{\text{x}}_{\text{p}}} \right)-\underset{{{\text{x}}_{\text{n}}}\in \text{N}\left( \text{a} \right)}{\mathop{\sum }}\, {{\text{w}}_{\text{n}}}\text{d}({{\text{x}}_{\text{a}}}, {{\text{x}}_{\text{n}}})]}_{+}}$ (1)
其中, m表示给定的间隔距离, d表示特征间距离, wp表示正样本对应的权值, wn表示负样本对应的权值, [· ]+=max(0, · ).Schroff等[22]提出的Triplet Loss对应到公式为均匀权值Triplet Loss, 即所有正样本或负样本的权值相同.Hermans等[23]提出不同的Triplet Loss, 对应于公式为二值化权值Triplet Loss, 即只考虑最难正样本(距离锚点样本最远的正样本)和最难负样本(距离锚点样本最近的负样本)的作用.
二值化权值Triplet Loss[23]突出困难样本的重要性, 但对于最难样本为离群点的情况, 缺少鲁棒性, 而均匀权值Triplet Loss[22]可弥补这一缺点, 因为离群点不能影响权值.Ristani等[10]提出的自适应权值Triplet Loss综合二值化权值Triplet Loss和均匀权值Triplet Loss的优点, 既突出困难样本的重要性, 又解决离群点问题, 并根据公式和进行权值分配:
${{w}_{p}}=\frac{exp\left( \text{d}\left( {{\text{x}}_{\text{a}}}, {{\text{x}}_{\text{p}}} \right) \right)}{\underset{\text{x}\in \text{P}\left( \text{a} \right)}{\mathop{\sum }}\, exp\left( \text{d}\left( {{\text{x}}_{\text{a}}}, x \right) \right)}$,
${{w}_{n}}=\frac{exp\left( -\text{d}\left( {{\text{x}}_{\text{a}}}, {{\text{x}}_{\text{n}}} \right) \right)}{\underset{\text{x}\in \text{N}\left( \text{a} \right)}{\mathop{\sum }}\, exp\left( -\text{d}\left( {{\text{x}}_{\text{a}}}, x \right) \right)}$.
自适应权值通过公式和分配较小的权值给容易样本, 以此突出困难样本的重要性.当几个困难样本同时存在时, 自适应权值将对它们进行公平的权值分配, 这对最困难样本为离群点的情况具有较好的鲁棒性, 因为还有其它的困难样本可使用.
为了增强行人重识别模型的泛化能力, 本文对训练样本使用更有效的采样策略.在训练行人重识别模型时, 对于一批输入图像(Batch)构建使用PK Batchs[23]思想, 每个Batch包含P个ID, 每个ID选择K幅样本图像.但是, 随着训练集规模的增大, 对于给定的ID, 如果剩余的P-1个ID被随机采样, 那么挑选的可能是简单的样本组合, 即与给定ID的外观很不像的负样本, 而让网络一直学习简单样本, 限制网络的泛化能力.
为了增强网络的泛化能力, 本文通过对训练样本集使用更有效的采样策略增加困难负样本(和给定ID外观很相似的负样本)被选择的概率.为了增加困难负样本被选择的可能性, 在网络训练几代之后或使用预训练的网络, 通过计算样本之间的相似度对每个ID构建困难样本集和随机样本集.对于某个特定的ID, 与之最相似的H个ID构成困难样本集, 剩余的ID构成随机样本集.构建某个特定ID的Batch时, 剩余的P-1个ID在困难样本集和随机样本集中等概率采样.困难样本集的构建可有效增加困难负样本被选择的概率, 使网络通过对困难样本的学习增强泛化能力.
实验分为两部分:第1部分验证自适应Triplet Loss[10]对跟踪器重识别能力的提升作用; 第2部分验证人群密度图可显著消除漏检、误检, 融合人群密度图和检测器的输出结果能得到更精确的检测结果.
训练行人重识别模型所用数据集为Market-1501数据集[24]和MARS数据集[25].Market-1501数据集为一个大型行人重识别数据集, 包含6个摄像机观察到的1 501位不同身份的行人, 共有32 668幅图像.MARS数据集由小视频段组成, 这些视频段已手动分组为不同行人, 包含1 261位行人的1 191 003幅图像.
训练行人重识别模型时根据文献[10]进行参数设置, 每个Batch的ID个数P=18, 每个ID的样本个数K=4, 式(1)中m=1, 输入图像大小为128× 256(宽× 高), 前15 000代学习率为3× 10-4, 在25 000代时学习率衰减到10-7, 困难样本集大小H=50.
多目标跟踪所用数据集为MOT16数据集[26]和MOT17数据集[26], 这2个数据集为多人跟踪量化常用的数据集, 收集固定或移动摄像机在各种复杂场景下拍摄的具有挑战性的视频序列.MOT16数据集包括7个训练视频序列和7个测试视频序列, 为每个视频序列提供生成的目标检测结果[27].MOT17数据集是MOT16数据集的修正与扩展, 在MOT17数据集上MOT16数据集的7个视频训练序列和7个视频测试序列全部被使用, 并且被更精确地标注.在MOT17数据集上每个视频测试序列被提供3种行人检测结果, 分别为DPM(Deformable Part Model)、Faster-RCNN(Faster Region-Based CNN)和SDP(Scale-Dependent Pooling).
多目标跟踪一般采用如下指标评估跟踪效果.1)多目标跟踪精度(Multi-object Tracking Accuracy, MOTA).根据FP(False Positives)、FN(False Nega-tives)和ID得到的总体跟踪精度的概况[28], 是多目标跟踪整体排名中重要指标.2)多目标跟踪一致性(Multi-object Tracking Precision, MOTP).根据检测框和真实框之间的重叠度得到总体跟踪一致性的概况[28].3)MT(Mostly Tracked Targets).不低于80%的位置得到正确匹配的轨迹占所有轨迹的比例.4)ML(Mostly Lost Targets).不超过20%的位置被正确匹配的轨迹占所有轨迹的比例.5)ID.跟踪轨迹的身份切换次数.6)FM(Number of Fragments).跟踪过程中轨迹被中断的次数.MOTA、MT指标值越高越好, ML、ID、FM、FP、FN指标值越低越好.
本节验证自适应Triplet Loss[10]对跟踪器重识别能力的提升作用.已知Deep-SORT在MOT16数据集上测试跟踪性能, 使用的目标检测结果由文献[29]提供.为了公平起见, 本次实验在MOT16数据集上评估MOT_FCD的跟踪性能并同样使用由文献[29]提供的检测结果.
2种算法的评估结果如表1所示, 表中实验所用检测结果由文献[29]提供, 在MOTChallenge官网可查到更加详细的结果.由表可看出, MOT_FCD性能更优.相比Deep-SORT, MOT_FCD在MT、ML指标上具有明显改善, 这表明MOT_FCD可对大多数目标进行更持续稳定的跟踪.同时, 相比Deep-SORT, MOT_FCD提供更好的漏检目标和更少的轨迹中断次数, 这表明MOT_FCD引入自适应Triplet Loss, 增强帧与帧之间的关联精度, 提升跟踪器的重识别能力.
| 表1 两种算法在MOT16数据集上的指标值对比 Table 1 Index value comparison of 2 algorithms on MOT16 dataset |
再结合定性分析进一步检测MOT_FCD的跟踪性能.MOT_FCD和Deep-SORT在MOT16-08、MOT-16-12数据集上的跟踪结果分别如图6和图7所示.MOT_FCD可持续跟踪行人目标, 而Deep-SORT却跟丢目标, 目标在第163帧被遮挡后, 开始一段新的轨迹.由图7可见, MOT_FCD在第677帧之前便开始对目标持续稳定地跟踪, 而Deep-SORT在第685帧之后才开始跟踪目标.图6和图7的对比结果表明MOT_FCD跟踪器具有更强的重识别能力, 能更精确地关联帧与帧之间的目标.当目标由于遮挡消失若干帧再出现后, MOT_FCD可正确重识别目标, 继续跟踪.当目标由于遮挡等原因只具有局部表观信息时, MOT_FCD仍然可对帧与帧之间的目标进行精确关联.
 | 图6 两种算法在MOT16-08数据集上的跟踪结果Fig.6 Tracking results of 2 algorithms on MOT16-08 dataset |
 | 图7 两种算法在MOT16-12数据集上的跟踪结果Fig.7 Tracking results of 2 algorithms on MOT16-12 dataset |
本节在MOT17数据集上验证人群密度图可显著消除漏检、误检, 得到更精确的检测结果, 提升跟踪器的性能.同时采用消融实验进一步验证自适应Triplet Loss[10]对跟踪器重识别能力的提升作用.
对比算法如下:TLMHT(Tracklet-Level Multiple Hypothesis Tracking)[30], GMPHDOGM17(Online Multi-object Tracking with Gaussian Mixture Probability Hy-pothesis Density Filter and Occlusion Group Manage-ment)[31], OTCD_1(Online Multi-object Tracker in Com-pressed Domain)[32], DMAN(Dual Matching Attention Networks)[33], HISP_DAL17(Hypothesized and Inde-pendent Stochastic Population Filter with Discrimina-tive Deep Appearance Learning)[34], HISP_T17(Tracking Using a Hypothesized and Independent Stochastic Popu-lation Filter)[35], TBC3(Tracking-by-Counting Mo-del)[36].各算法在MOT17数据集上的指标值结果如表2所示.
| 表2 各算法在MOT17数据集上的指标值对比 Table 2 Index value comparison of different algorithms on MOT17 dataset. |
由表2可看出, MOT_FCD性能较优.从MOTA指标上看, MOT_FCD的表现优于大多数跟踪算法.MOT_FCD也有较低的FN值, 说明它可利用人群密度恢复漏检目标.从MT、ML指标上看, MOT_FCD明显更优, 虽然MOT_FCD的MOTA值只略高于TLMHT, 但MT值提升2.7%, ML值降低6.8%.这说明MOT_FCD利用人群密度有效消除漏检和误检, 成功地对目标持续跟踪.
TBC3将目标检测、计数和跟踪建模在同一框架中, 模型既是检测器又是跟踪器, 输入只需要人群密度.TBC3对低分辨率的小目标有效, 但在大尺度场景下性能会受到影响, 在MOT17数据集上, 从MOTA指标上看, MOT_FCD的跟踪结果略差于TBC3, 这主要是因为TBC3是离线跟踪, 即对每帧图像的处理可使用整个视频序列的信息, 而MOT_FCD是在线跟踪, 即只使用当前帧及之前帧的图像信息进行跟踪.但是, MOT_FCD的跟踪速度明显优于TBC3.
此外, 本文采用消融实验证实自适应Triplet Loss[10]和人群密度图对MOT_FCD跟踪性能的贡献率, 进一步证实自适应Triplet Loss对跟踪器重识别能力的提升作用.同时, 对比MOT_FCD和MOT_FCD(Triplet Loss)可发现, 人群密度图的作用使跟踪器性能得到大幅提升, 而计算复杂度只是略微增加.
MOT_FCD和FRCNN(Faster Region-Based Convolutional Neural Networks)在MOT17-06数据集上的跟踪结果如图8所示.由图可知, FRCNN在第315帧和第326帧时由于遮挡, 产生漏检.
 | 图8 MOT_FCD和FRCNN在MOT17-06数据集上的跟踪结果Fig.8 Tracking results of MOT_FCD and FRCNN on MOT17-06 dataset |
MOT_FCD成功恢复目标并继续跟踪.MOT_FCD和DPM(Deformable Part Model)在MOT17-03数据集上跟踪结果如图9所示, 图中DPM保留置信度大于0的结果.由图可看出, 对于高密度、遮挡频繁发生的场景, DPM的检测结果存在不少漏检和误检, 而MOT_FCD能利用人群密度图有效消除漏检、误检, 并成功地对目标进行跟踪.
 | 图9 MOT_FCD和DPM在MOT17-03数据集上的跟踪结果Fig.9 Tracking results of MOT_FCD and DPM on MOT17-03 dataset |
图8和图9的结果表明, 对于因遮挡等原因较难检测的目标, MOT_FCD可利用人群密度图有效消除漏检、误检, 成功地对目标进行检测和跟踪.
MOT_FCD的定性跟踪结果如图10所示.
 | 图10 MOT_FCD定性跟踪结果Fig.10 Qualitative tracking results by MOT_FCD |
本文针对目前的多目标跟踪算法在目标严重遮挡场景下的跟踪效果不理想的问题, 提出融合人群密度的自适应深度多目标跟踪算法.目前, 多目标跟踪器的性能在很大程度上取决于检测结果的精确程度, 但是由于遮挡、目标尺度和光照的影响, 目前的检测器存在不少的漏检和误检.与此同时, 基于密度图的目标计数方法不仅可在这些困难场景下表现出良好性能, 而且密度图同时包含目标的位置信息和计数信息.本文算法融合人群密度图和检测器结果, 利用人群密度图的位置和计数信息修正检测器结果, 有效消除漏检和误检, 得到更精确的检测结果.在此基础上, 本文使用自适应Triplet Loss改进行人重识别模型的损失函数, 提高重识别特征的辨别能力, 提升多目标跟踪算法的性能.在MOT16、MOT17数据集上的实验表明本文算法可较好地解决目标严重遮挡场景下的多目标跟踪问题, 能够对目标进行持续稳定的跟踪.虽然本文算法性能较优, 但对视频帧的处理速度还不能满足实时性的要求.在后期的研究中可改进人群密度图和目标检测结果的融合方式, 尝试使用卷积神经网络的方式进行融合.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|