
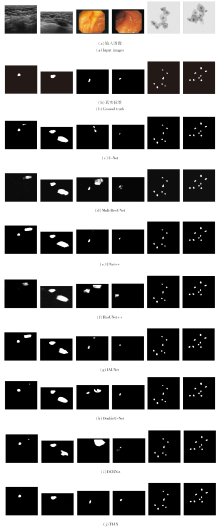
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于三重交互关注网络的医学图像分割算法
[高程玲1  , 叶海良
, 叶海良1 , 曹飞龙1 ]
, 叶海良, 曹飞龙]
|
|



作者简介:

高程玲,硕士研究生,主要研究方向为深度学习、图像处理.E-mail:chl_gao@126.com.

叶海良,博士,讲师,主要研究方向为深度学习、图像处理.E-mail:yhl575@163.com.
深度学习由于强大的特征提取能力,在克服类不平衡问题上具有一定优势,但分割精度和效率仍需提升.针对此问题,文中提出基于三重交互关注网络的医学图像分割算法.设计三重交互关注模块,并嵌入特征提取过程,通过对特征的通道维度和空间维度联合关注,充分捕获跨维度交互信息,有效聚焦重要特征,突出目标位置.此外,采用像素位置感知损失,进一步缓解类不平衡影响的作用.在医学图像数据集上的实验表明文中算法性能较优.
AboutAuthor:
GAO Chengling, master student. Her research interests include deep learning and image processing.
YE Hailiang, Ph.D., lecturer. His research interests include deep learning and image processing.
Deep learning produces advantages in solving class imbalance due to its powerful ability to extract features. However, its segmentation accuracy and efficiency can still be improved. A medical image segmentation algorithm via triplet interactive attention network is proposed in this paper. A triplet interactive attention module is designed and embedded into the feature extraction process. The module is focused on features in the channel and spatial dimensions jointly, capturing cross-dimensional interactive information. Thus, important features are in focus and target locations are highlighted. Moreover, pixel position-aware loss is employed to further mitigate the impact of class imbalance. Experiments on medical image datasets show that the proposed method yields better performance.
本文责任编委 兰旭光
Recommended by Associate Editor LAN Xuguang
医学图像分割是医学图像分析中的一个重要领域, 旨在从图像中较好地分割目标区域, 为后续的诊断和治疗提供有效帮助.随着计算机性能的迅速提高和深度学习技术的快速发展, 结合深度学习的医学图像分割算法已逐渐成为医学分割领域的主流算法[1].特别地, 卷积神经网络(Convolutional Neural Networks, CNN)在医学图像分割任务中已被越来越多的学者关注并取得显著进展.Long等[2]提出全卷积网络(Fully Convolutional Network, FCN), 将CNN中的全连接层替换为卷积层, 并对输出特征进行上采样, 实现端到端的医学图像分割, 输入图像尺寸不受限制, 但是, 该方法容易丢失细节信息, 分割精度也有待提高.Ronneberger等[3]在FCN的基础上提出U型网络(U Network, U-Net).它是一个对称的编解码网络, 通过跳跃连接合并编码和解码对应阶段的特征, 丰富细节信息.近年来, U-Net网络架构在医学图像分割领域发展迅速, 大量U-Net结构的变形被构造并在医学图像分割中得到较好应用.Ibtehaz等[4]借鉴残差思想, 改造U-Net的卷积块和跳跃连接, 提出多尺度残差U型网络(MultiResUNet).Azad等[5]在跳跃连接中加入双向的卷积长短时记忆(Convolutional Long Short-Term Memory, ConvLSTM)网络[6], 进一步结合编码和解码特征.Zhou等[7]构造UNet++, 引入密集连接和深度监督, 大幅提升分割精度.
然而, 医学图像分割任务存在类不平衡问题, 即图像中的目标区域, 如病变、器官等, 占据整幅图像的比例很小, 导致背景区域在训练阶段占主导地位, 降低模型的优化质量[8], 而一般的分割方法难以较好地解决这个问题.目前, 解决分割任务中类不平衡问题大致有3种方案:模型级联、注意力机制和设计损失函数.
模型级联策略[9, 10]通过2个模型进行逐步分割, 第1个模型定位目标区域, 第2个模型在目标区域中实现精准分割, 但这种方式需要训练多个深度模型, 复杂性和空间消耗较高[11].
注意力机制可突出图像特征中的有用信息, 同时抑制不相关的信息, 不需要大量参数和计算开销[12].对于类不平衡问题, 可使网络只关注图像中感兴趣的区域, 减少大面积背景的干扰.目前, 在计算机视觉领域, 注意力机制大致可分为通道关注和空间关注.通道关注旨在重新校准通道维度的特征响应, Hu等[13]提出挤压激励模块(Squeeze-and-Excitation, SE), 简单高效.空间关注旨在评估空间维度各像素的重要性.Li等[14]提出基于注意力的嵌套U型网络(Attention-Based Nested UNet, ANUNet), 采用加性空间, 突出有意义的目标像素.然而, 空间关注忽略不同特征通道的信息差异, 对每个通道一视同仁, 相反, 通道关注直接池化全局信息, 忽略每个通道中的局部信息.因此, 为了充分突出特征中的重要信息, 一些学者同时使用这两种注意力模块, 有的采用串并联的形式叠加使用[15, 16], 有的根据低级特征和高级特征的特有性质, 分别使用空间关注和通道关注[17].但是, 这些研究仍分开考虑通道维度和空间维度的校准.为了解决这个问题, Pereira等[18]设计分割挤压激励模块(Segmentation SE, SegSE), 为每个像素生成一个通道描述符, 得到的注意力系数同时校准空间和通道, 与输入特征具有相同大小.虽然SegSE对通道和空间的关注进行有效融合, 但仍未考虑到跨维度交互信息的重要性.
另外, 设计合适的损失函数是缓解类不平衡影响的有效策略之一.常见的方法是采用加权的交叉熵损失函数[3, 19], 但通常人为设置方法的权重, 交叉熵损失函数是像素级的损失, 无法考虑全局情形.Milletari等[20]和Rahman等[21]分别直接优化Dice相似性系数(Dice Similarity Coefficient, DSC)和交并比(Intersection over Union, IoU)这两项分割指标.当背景和前景像素数量不平衡时, 使用这两种全局约束的损失函数, 不需要对样本重新加权, 但可能存在训练不稳定的情形.
为了有效解决上述问题, 本文提出基于三重交互关注网络(Triplet Interactive Attention Network, TIAN)的医学图像分割算法.构造三重交互关注模块(Triplet Interactive Attention, TIA), 对特征的通道维度和空间维度进行联合关注, 充分利用跨维度交互信息, 有效突出有意义的特征, 并通过跳跃连接融合关注前后特征, 避免重要细节的遗漏.因此, TIAN可更准确地捕获目标位置, 减少背景区域的干扰.同时, 在给出的TIAN中引入深度监督(Deep Supervi-sion, DS)机制[22], 在解决训练过程中梯度消失问题的同时提升分割精度.本文采用像素位置感知损失(Pixel Position Aware, PPA)[23], 融合交叉熵损失和IoU损失, 充分考虑局部约束和全局约束, 侧重于难分像素, 进一步缓解类不平衡的影响.
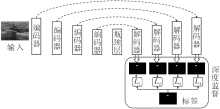
本文的三重交互关注网络整体结构如图1所示.
 | 图1 三重关注网络结构Fig.1 Network architecture of TIAN |
TIAN的主框架包括编码器、瓶颈层和解码器.编码器的4个阶段均由特征提取块和最大池化层组成.瓶颈层为一个特征提取块.解码器由反卷积层和特征提取块组成, 可逐步恢复图像分辨率.特别地, 每个特征提取块包含多个卷积层和一个三重交互关注模块, 在提取特征时有效突出目标区域, 可避免网络被大面积的背景分散注意力.同时, 为了保留图像的空间细节信息, 将编码器得到的特征输入解码器的对应阶段.对解码器各阶段的输出特征通过双线性插值上采样至输入图像大小, 再使用1× 1卷积和sigmoid归一化后, 实行深度监督.特别地, 解码器最后阶段得到的分割图作为网络的最终输出.
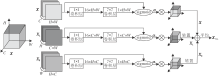
假定一组含有C个通道, 大小为H× W的特征可表示为一个张量X∈ RC× H× W, 三重交互关注由3个平行的分支组成, 通过转置的方式分别捕捉(H, W)、(C, W)、(H, C)维度之间的依赖关系, 如图2所示.
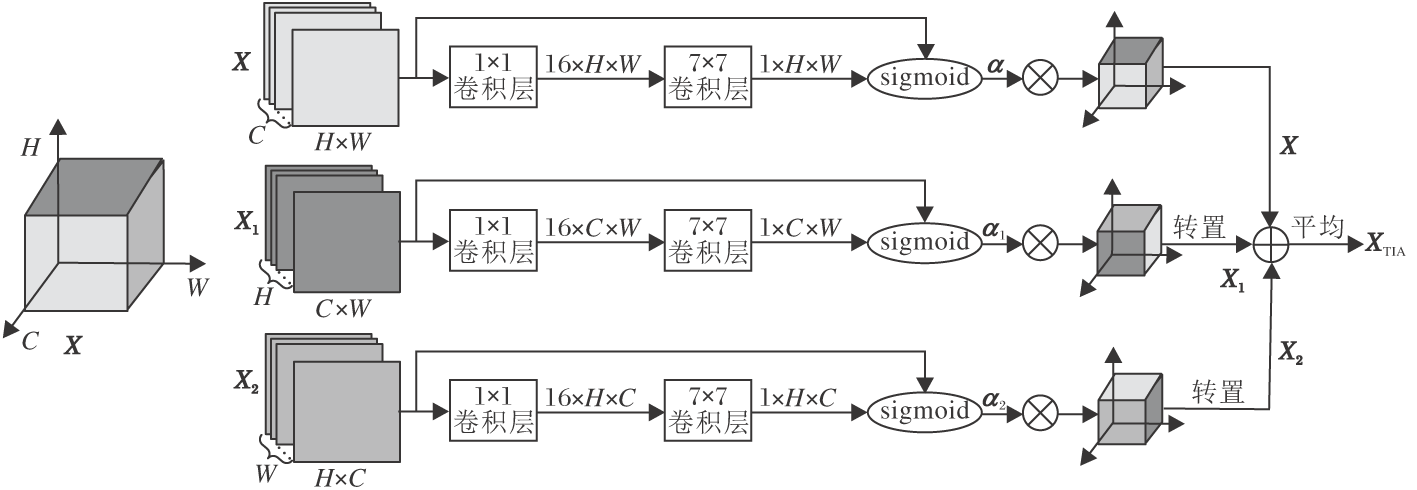 | 图2 三重交互关注模块示意图Fig.2 Illustration of triplet interactive attention module |
图2中的第1个分支用于捕捉空间维度的重要信息, 可直接对输入特征进行关注操作.首先, 对输入特征X进行降维, 减少参数量, 这里采用1× 1卷积层实现特征的加权融合, 通过学习得到的权重使网络尽可能保留完整的信息.再由卷积核大小为7× 7及输出通道数为1的卷积层生成关注特征.采用sigmoid函数将其归一化至[0, 1], 得到(H, W)维度的关注权重矩阵:
α =δ (W2* σ (W1* X)),
其中, W1表示1× 1的卷积, W2表示7× 7的卷积, * 表示卷积操作, σ (· )表示ReLU函数, δ (· )表示sigmoid函数.将X与所得权重矩阵α 相乘可得到空间维度的关注特征:
$\tilde{X}=X\otimes \alpha \in {{R}^{C\times H\times W}}$
其中$\otimes $表示哈达玛积.
第2个分支需要先对输入特征X进行转置, 得到X1∈ RH× C× W.再对转置特征X1采用1× 1卷积融合特征, 采用7× 7卷积及sigmoid函数生成关注权重矩阵:
${{\alpha }_{1}}=\delta (W_{1}^{2}* \sigma (W_{1}^{1}* {{X}_{1}}))\in {{R}^{1\times C\times W}}$,
其中, $W_{1}^{1}$表示1× 1的卷积核, $W_{1}^{2}$表示7× 7的卷积核.最后, 将X1与所得权重矩阵α 1进行哈达玛积, 并转置(Trans)回原始的输入维度, 即可得到(C, W)跨维度关注的结果:
${{\tilde{X}}_{1}}=Trans({{X}_{1}}\otimes {{\alpha }_{1}})\in {{R}^{C}}^{\times H\times W}$.
从而实现通道维度和空间维度的交互关注.
类似地, 第3个分支将输入特征X转置得到X2∈ RW× H× C, 并对转置特征进行相似操作, 得到(H, C)维度的关注权重矩阵:
${{\alpha }_{2}}=\delta (W_{2}^{2}* \sigma (W_{2}^{1}* {{X}_{2}}))\in {{R}^{1\times C\times W}}$,
其中, $W_{2}^{1}$表示1× 1的卷积核, $W_{2}^{2}$表示7× 7的卷积核.将X2与关注权重矩阵α 2相乘, 并转置回输入维度, 得到(H, C)跨维度关注的结果:
${{\tilde{X}}_{2}}=Trans({{X}_{2}}\otimes {{\alpha }_{2}})\in {{R}^{C}}^{\times H\times W}$.
最后, 有效融合3个分支生成的关注特征, 得到最终的关注特征:
${{\tilde{X}}_{TIA}}=f(\tilde{X}, {{\tilde{X}}_{1}}, {{\tilde{X}}_{2}})$,
其中f(· )表示融合算子.
本文采用最大化、拼接、相乘和平均4种方式实现关注特征的融合.
1)最大化.取三组关注特征对应通道对应像素位置的最大值:
${{\tilde{X}}^{m}}_{TIA}=\max (\tilde{X}, {{\tilde{X}}_{1}}, {{\tilde{X}}_{2}})$.
2)拼接.按通道维度拼接三组关注特征, 通过1× 1卷积减少通道数:
$\tilde{X}_{TIA}^{c}=W*\left[ \begin{matrix} {\tilde{X}} & {{{\tilde{X}}}_{1}} & {{{\tilde{X}}}_{2}} \\ \end{matrix} \right]$.
3)相乘.将三组关注特征的对应元素相乘:
${{\tilde{X}}^{t}}_{TIA}=\tilde{X}\otimes {{\tilde{X}}_{1}}\otimes {{\tilde{X}}_{2}}$.
4)平均.将3组关注特征的对应元素取平均:
${{\tilde{X}}^{a}}_{TIA}=\frac{1}{3}(\tilde{X}+{{\tilde{X}}_{1}}+{{\tilde{X}}_{2}})$..
为了充分提取具有更好表示能力的特征, 本文构建特征提取块, 即在2个3× 3卷积层后加上三重交互关注模块.另外, 为了避免在关注过程中丢失重要信息, 采用跳跃连接融合关注前的特征与关注特征, 采用如图3所示的通道维度拼接及3× 3卷积的方式进行操作.
 | 图3 特征提取块结构Fig.3 Structure of feature extraction module |
为了进一步提升网络的学习能力, 本文采用深度监督策略对解码器部分的隐藏层实行监督, 加强早期层的训练, 同时可缓解梯度消失的问题.深度监督的操作流程如图1所示.
首先, 将解码器中每个阶段的最后一个卷积层分别连接到上采样操作, 这里采用双线性插值将特征图恢复至输入图像大小.需要注意的是, 解码器最末阶段的输出特征已具有与输入图像相同的分辨率, 故此阶段不需要接上采样.
然后, 对这4个阶段的特征图分别使用卷积核大小为1× 1、输出通道数为1的卷积层, 采用sigmoid函数归一化至[0, 1], 可得到4个分割图S1、S2、S3、S4.特别地, 最末阶段得到的分割图作为整个网络的最终输出.
最后, 将这4个预测的分割图均与分割标签图计算损失, 即得到4个损失L1、L2、L3、L4, 并在训练阶段对其进行优化.
本文引入在显著性目标检测领域提出的像素位置感知损失[23]:
$L=L_{\text{BCE}}^{w}+L_{\text{IoU}}^{w}$ (1)
其中, $L_{\text{BCE}}^{w}$表示用于局部约束的加权交叉熵损失, $L_{\text{IoU}}^{w}$表示用于全局约束的加权交并比损失.
像素位置感知损失为每个像素分配不同的权重, 根据中心像素与其周围环境之间的差异计算该权重, 因此, 难分像素会得到更多关注.由于$L_{\text{IoU}}^{w}$旨在优化全局结构, 不受类不平衡的影响, 因此, 该损失也可在一定程度上缓解类不平衡对网络的负面作用.
本文对解码器各阶段输出的分割图S1、S2、S3、S4进行深度监督, 结合式(1), 该网络的总损失为
${{L}_{total}}=\overset{4}{\mathop{\underset{k=1}{\mathop{\sum }}\, }}\, L(G, {{S}_{k}})$,
其中G表示分割标签图.
本文在BUS-B[24], CVC-ClinicDB[25]、ISBI-2014[26]这3个不平衡的医学图像数据集上进行实验, 它们分别是乳腺超声图像、结肠镜图像和宫颈细胞显微镜图像.实验均在相同环境(NVIDIA RTX 2080Ti GPU)上, 采用Pytorch深度学习框架.由于GPU内存的限制, 所有输入图像大小统一调整为256× 256, 采用翻转、旋转、缩放、直方图匹配等方式进行数据增强.实验采用自适应矩估计(Adaptive Moment, Ad-am)算法训练100轮, 初始学习率为0.000 1, 以每30轮降低20%进行衰退.使用Dice相似性系数(DSC)和交并比(IoU)作为分割性能的评价指标.
在BUS-B数据集上, 讨论三重交互关注模块(TIA)的融合策略和使用位置, 及特征提取块的跳跃连接方式, 并在不同设置下进行消融实验, 验证各模块的有效性.
首先讨论三重交互关注模块的融合方式.采用最大化、拼接、相乘、平均4种方式, 实验结果如表1所示.由表可发现, 效果相差不大, 但取平均的方式分割精度相对较高, 因此采用平均的策略融合3个关注分支.
| 表1 不同融合策略的效果对比 Table 1 Result comparison of different fusion strategies % |
在特征提取块中, 关注前的特征通过跳跃连接添加到关注特征中, 常用的跳跃连接方式一般是相加和拼接, 但直接拼接会使通道数加倍, 导致后续的卷积层需处理更多的通道特征, 增加模型的复杂性.因此, 本文在拼接操作后增加一个卷积层, 减少通道数.为了使参数量尽可能少, 这里采用1× 1和3× 3两种卷积核进行实验.
不同跳跃连接方式的效果对比如表2所示.由表可见, 直接相加的效果最差, DSC值仅为85.55%, IoU值仅为77.35%.拼接加卷积的方式更有效, 特别地, 拼接与3× 3卷积的效果最优, 因此, 本文所有特征提取块的跳跃连接均采用此方式进行.
| 表2 不同跳跃连接方式的效果对比 Table 2 Result comparison of different skip connection methods % |
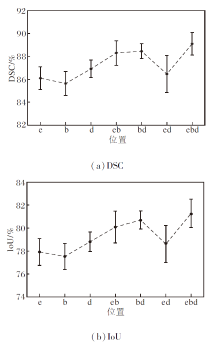
事实上, 需要重点考虑三重交互关注模块(TIA)添加到网络中的最佳位置.本文的主干网络由编码器、瓶颈层和解码器组成, 对这3部分是否添加关注模块分别进行讨论, 若不使用关注模块, 其特征提取块仅为2个3× 3卷积层.具体结果如图4所示.图中的e表示在编码器添加TIA, b表示在瓶颈层添加TIA, d表示在解码器添加TIA.
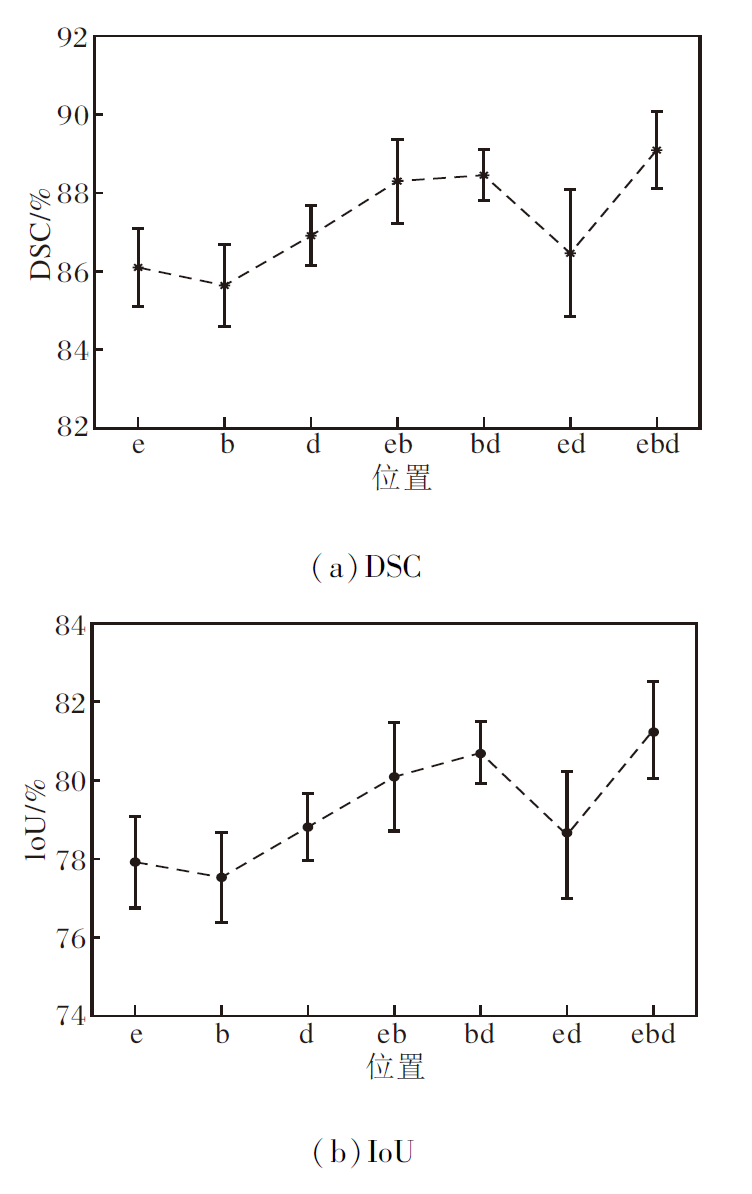 | 图4 在不同位置使用TIA的结果图Fig.4 Results of triple interactive attention module in different positions |
由图4可清楚观察到, 在网络的编码器、瓶颈层和解码器3部分都使用TIA的效果最优, 用在其中两部分的效果优于只用在一个部分, 这也表明TIA对特征提取有积极作用.另外还发现, 将TIA用在瓶颈层的效果优于单独用在编码器或解码器上.同样地, 若用在其中两个部分, 包含瓶颈层的效果也优于只用在编码器和解码器上.因此, 本文网络在编码器、瓶颈层和解码器都添加TIA, 即采用1.2节中提出的特征提取块.
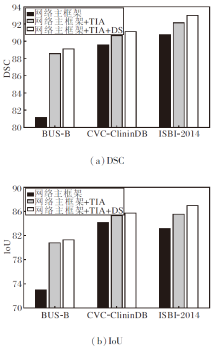
为了验证TIA和深度监督(DS)对类不平衡的医学图像分割的有效性, 进行消融实验, 结果如图5所示.
 | 图5 各数据集上的消融实验结果Fig.5 Results of ablation experiment on different datasets |
由图5可知, 在3个数据集上, TIA和DS都有积极作用.这是由于TIA有效突出有意义的特征, 并抑制不相关的背景区域, 使网络能更清楚地识别到目标位置, 实现更精准的分割.而DS机制为隐藏层提供直接监督, 可提高隐藏层学习的直接性和透明度, 提升网络的学习能力.
为了验证三重交互关注网络(TIAN)的有效性, 从定量评估的角度, 与如下算法进行对比:U-Net[3]、MultiResUNet[4]、UNet++[7]、残差U型网络2(Resi-dual UNet++, ResUNet++)[27]、改进的注意力U型网络(Improved Attention UNet, IAUNet)[28]、双重U型网络(Double U-Net)[29]、双重上下文关系网络(Du-plex Contextual Relation Network, DCRNet)[30].为了公平起见, DCRNet未使用在ImageNet数据集上经过预训练的ResNet34网络参数进行初始化.
各算法在3个数据集上的DSC和IoU值对比如表3所示.由表可见, TIAN在3个数据集上的性能都最优, 表明TIAN在类不平衡的医学图像上可得到更准确的分割结果.特别地, TIAN对乳腺超声图像分割的提升效果最优.在BUS-B数据集上的图像分割中, TIAN的DSC和IoU值分别提高超过2.54%和3.18%.原因可能是由于乳腺超声图像本身的模糊度较高, 分割难度较大, 而本文的TIA可准确定位病灶区域, 有效避免将正常组织误判为病变, 提升分割精度.
| 表3 各算法在3个数据集上的定量结果对比 Table 3 Quantitative comparison of different algorithms on 3 datasets % |
各算法在3个数据集上的视觉结果对比如图6所示.在图6中, 左起第1幅和第2幅图像取自BUS-B数据集, 左起第3幅和第4幅图像取自CVC-Clinic DB数据集, 左起第5幅和第6幅图像取自ISBI-2014数据集.
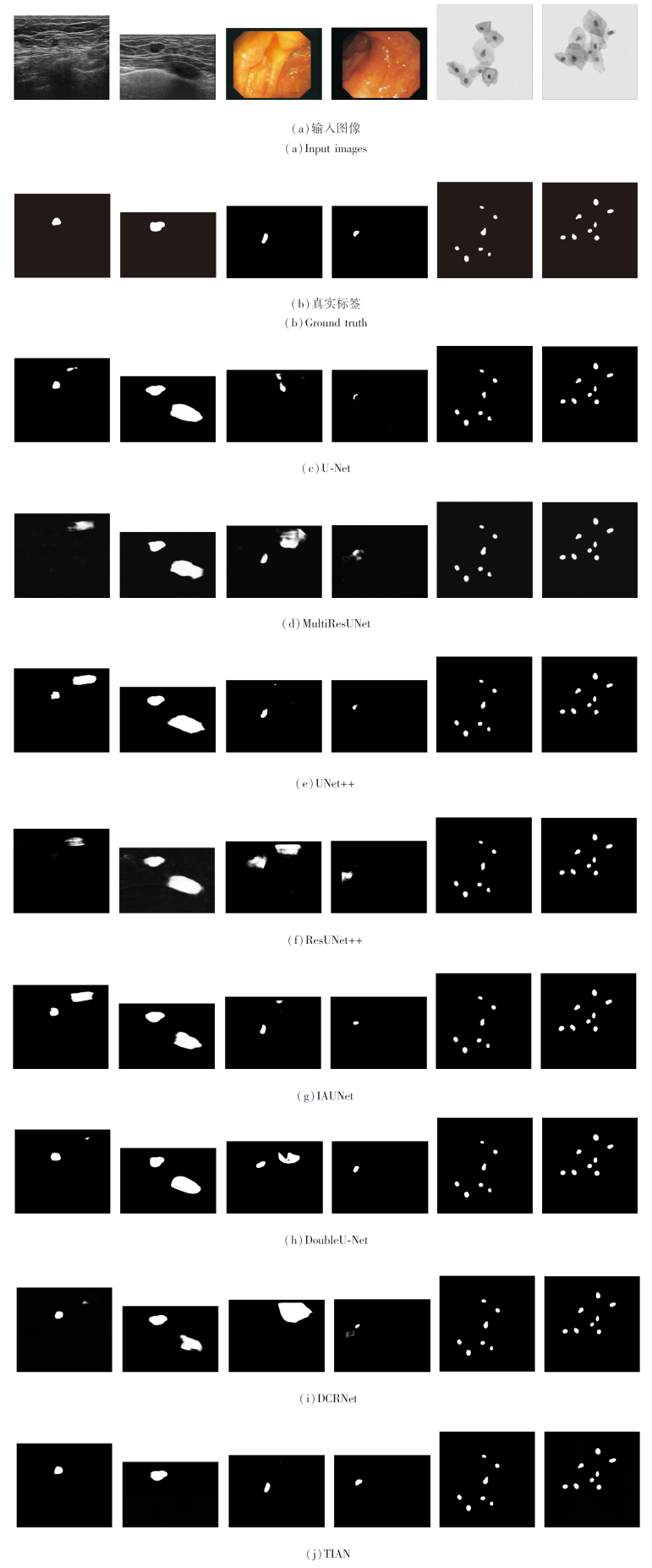 | 图6 各算法的视觉效果对比Fig.6 Visual effect comparison of different algorithms |
由图6可见, TIAN可更准确地定位目标, 而其它算法不能完全检测到病灶或错误地将正常组织识别为病变.另外, TIAN能捕捉更完整的轮廓信息, 分割更准确的边界.这也证实TIA的有效性, 既能充分突出重要特征, 又能抑制无用的特征.
本文提出基于三重交互关注网络的医学图像分割算法, 可较好地解决类不平衡问题.算法关键在于设计三重交互关注模块, 不仅可挖掘通道维度和空间维度的有效信息, 还能捕捉跨维度特征的重要信息, 使网络学习到更具有代表性的特征, 改善分割精度.此外, 本文采用的深度监督机制可对隐藏层直接监督, 提高网络的学习能力.算法利用像素位置感知损失, 对像素赋权, 进一步缓解类不平衡问题, 提高难分像素的分割准确率.在3个数据集上的结果表明, 本文算法性能较优.然而, 本文算法仍有进一步发展空间.一方面, 对于三重交互关注模块中的卷积核大小, 本文根据经验采用预定义的方式确定, 今后可设计自适应的方法对其进行选择.另一方面, 如何将本文算法推广到三维类不平衡医学图像分割中也是一个值得进一步研究的问题.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|