






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
复杂场景下基于CNN的轻量火焰检测方法
[李欣健1, 2  , 张大胜
, 张大胜3 , 孙利雷4 , 徐勇1, 2 ]
, 张大胜, 孙利雷, 徐勇]
|
|



作者简介:

李欣健,硕士研究生,主要研究方向为计算机视觉、目标检测.E-mail:894504231@qq.com.

张大胜,硕士研究生,主要研究方向为计算机视觉、目标检测.E-mail:2598768905@qq.com.

孙利雷,博士研究生,主要研究方向为模式识别、生物特征识别.E-mail:sunlileisun@163.com.
已有的火灾检测方法往往依赖高性能的机器,在嵌入式端和移动端检测速度较慢、误检率较高,尤其是无法解决小尺度火焰漏检问题.针对上述问题,文中提出基于YOLO的火焰检测方法.使用深度可分离卷积改进火焰检测模型的网络结构,并使用多种数据增强技术与基于边框的损失函数以提高精度.通过参数调优,在保证检测准确率的情况下,实现在嵌入式移动系统上21 ms的实时火灾探测.实验表明,文中方法在火焰数据集上的精度和速度都有所提高.
AboutAuthor:
SUN Lilei, Ph.D. candidate. His research interests include pattern recognition and biometric recognition.
LI Xinjian, master student. His research interests include computer vision and object detection.
ZHANG Dasheng, master student. His research interests include computer vision and object detection.
The existing fire detection methods rely on high-performance machines, and therefore the speeds on the embedded terminals and the mobile ones are not satisfactory. For most of the detection methods, the speed is low and the false detection rate is high, especially for small-scale fires missed detection problems. To solve these problems, a fire detection method based on you only look once is proposed. Depthwise separable convolution is employed to improve its network structure. Multiple data augmentation and bounding box based loss function are utilized to achieve a higher accuracy. The real-time 21ms fire detection on embedded mobile system is realized through parameter tuning with the detection accuracy ensured. Experimental results show that the proposed method improves accuracy and speed on the fire dataset.
本文责任编委 兰旭光
Recommended by Associate Editor LAN Xuguang
火灾是威胁人类社会的主要灾害之一, 对社会安全及人的生命财产危害巨大, 不起眼的一点火星也可能导致非常严重的火灾.目前广泛应用的火灾报警器都是基于传感器识别的, 如温度传感器、烟雾传感器等, 当温度或烟雾达到定值时, 才会触发报警[1], 这通常会错过灭火的最佳时间.随着深度学习和计算机视觉的迅速发展, 视频监控逐渐普及, 火灾视频监控技术[2]也相应出现.此技术精度较高, 不受温度、气流等因素影响, 但是现有大部分基于视频的火焰监测方法需要依赖高性能、高功耗、价格昂贵的服务器, 只有使用图形处理器(Graphics Proce-ssing Unit, GPU)才能达到实时监测的要求.因此, 将火焰检测应用在低成本、低功耗的嵌入式设备上具有重要意义.
传统的火焰检测技术主要依赖于特征.Chen等[3]提出使用颜色静态特征模型, 基于RGB三颜色通道, 结合火焰的无序度对火焰进行分析并检测.Wang等[4]除使用颜色静态模型, 同时使用火焰图像连续帧的相似性进行火焰识别.陈磊等[5] 使用帧间差分法分离火焰像素与背景, 使用分块处理的方法进行火焰判别.传统的火焰检测在一定程度上解决火焰检测的问题, 但在复杂的火焰场景中仍存在着疑似火焰物体误检率较高、火焰漏检率较高的问题.
基于深度学习的方法表达能力较强[6], 可学习到火焰图像的深、浅层信息.Muhammad等[7]提出卷积神经网络(Convolutional Neural Network, CNN)监控视频架构, 使用CNN进行火焰探测.邓军等[8]提出基于优化InceptionV1的视频火焰像素检测方法, 对火焰进行像素级检测.赵飞扬等[9]提出改进YOLOv3的深度学习网络结构, 用于火焰检测和提取.基于深度学习的火焰检测方法改善传统火焰检测技术存在的误检率和漏检率较高等问题, 具有较好的泛化性和鲁棒性.但是, 上述深度学习火焰检测技术需要依赖高性能的平台完成, 例如:基于YOLOv3的火焰检测框架[9]需要使用Titan Xp显卡才能达到25帧/秒的速度, InceptionV1火焰检测方法[8]同样依赖昂贵的计算资源完成实时火焰检测.
基于此问题, 本文基于性能优异的YOLO(You Only Look Once)系列框架[10, 11, 12, 13]进行网络结构改进, 提出基于YOLO的火焰检测方法(Improved-YO-LO).为了减少火焰检测网络存在参数量和计算量过大的问题, 使用深度可分离卷积[14]替换其中的部分卷积层.由于训练集样本较小, 为了增强方法的鲁棒性, 使用MS COCO数据集[15]进行预训练, 收敛后再将方法参数应用于火焰检测数据集.为了减少方法训练过程中的过拟合, 使用马赛克数据增强技术(Mosaic Data Augmentation, Mosaic)[13]、混类数据增强技术(Mixup Data Augmentation, Mixup)[16], 丰富火焰检测的背景, 增加数据的多样性和神经网络的鲁棒性.本文还使用CIoU(Complete Intersection over Union)[17]作为损失函数, 直接优化目标框之间的距离, 使目标框更贴近真实目标.综上所述, 本文方法的参数量和所需储存空间远小于YOLO系列方法, 精度与之相当, 能在嵌入式平台上实时运行, 使深度学习的火焰检测技术可应用在价格低廉的小型嵌入式设备中.
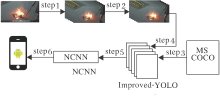
基于YOLO的火焰检测方法流程如图1所示, 主要步骤如下.
 | 图1 本文方法流程图Fig.1 Flowchart of the proposed method |
算法 基于YOLO的火焰检测方法
step 1 从原始火焰、火灾视频数据集等间距抽取10帧.
step 2 对抽取的帧图像保存在本地, 使用标注工具labelimage对火焰进行人工标注.
step 3 将Improved-YOLO在MS COCO数据集上进行预训练.
step 4 针对step 3中训练好的预训练模型提取前109层网络参数, Improved-YOLO加载此预训练参数, 使用step 2标注好的火焰数据集对Improved-YOLO进行训练.
step 5 将Improved-YOLO转换为深度学习框架NCNN(https://github.com/Tencent/ncnn).
step 6 将NCNN部署至嵌入式端.
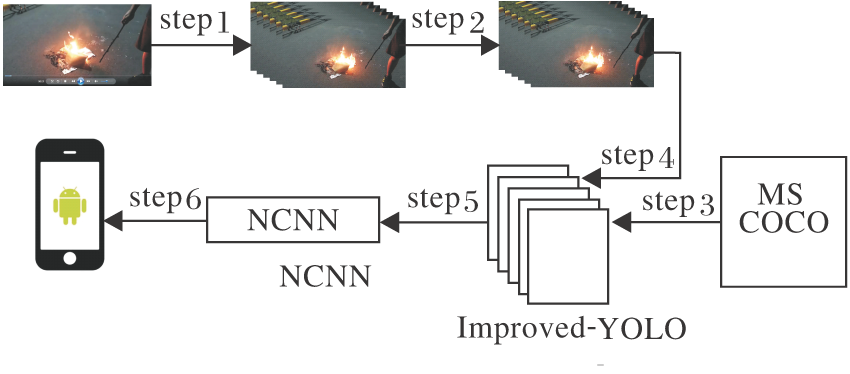
YOLO通用目标检测系列算法是当前性能最优的单阶段目标检测方法[18]之一.方法核心是目标检测的建模方法, 由分类问题转化为回归问题, 大幅提升检测速度.以YOLOv3为例, 使用较多性能表现较优的1× 1和3× 3卷积层保证目标检测算法的精度.借鉴残差网络(Residual Network, ResNet)[19]的残差块结构, 解决层数变深后带来的模型退化问题, 保证目标检测网络的深度.使用k-means算法预先计算不同尺度的先验框, 完成跨尺度的边框预测, 提升目标检测算法的性能.YOLOv3的结构见图2.
 | 图2 YOLOv3 网络结构图Fig.2 Network structure of YOLOv3 |
尽管YOLO系列模型推理速度在目标检测领域较优, 但模型复杂性及密集计算的特性使其无法在嵌入式平台达到实时效率.通过图2可发现, YOLO使用大量的卷积块提取相应特征, 计算量和参数量主要集中在卷积层, 因此减少卷积层的计算和参数, 是加速目标检测的关键.本文利用深度可分离卷积[14], 优化YOLO系列模型, 提出Improved-YOLO网络结构, 实现嵌入式端的实时火焰检测.
1.1.1 深度可分离卷积
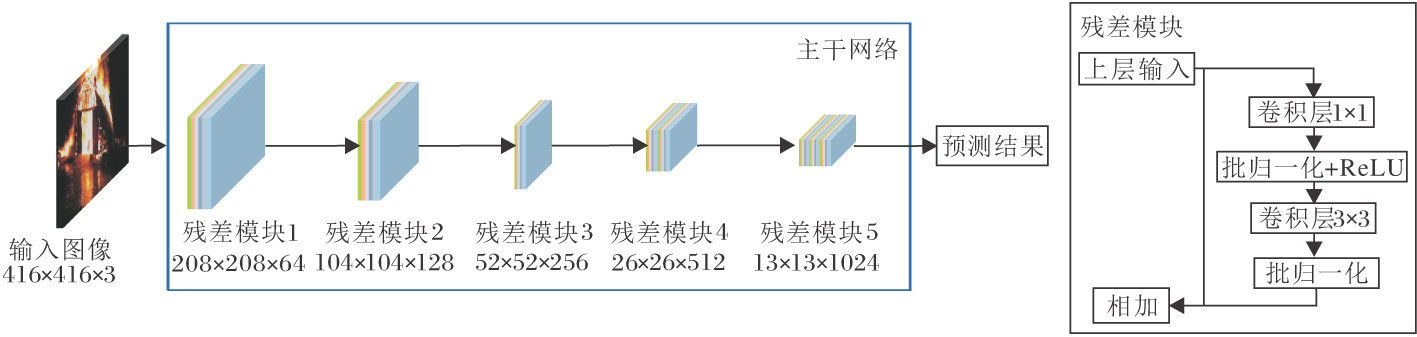
传统卷积是直接运算图像的色道、通道, 得出结果, 而深度可分离卷积拆分为深度卷积和逐点卷积两部分, 深度卷积使用单个二维卷积核对图像通道进行卷积操作, 逐点卷积使用1× 1卷积核对深度卷积后的特征图进行组合.深度可分离卷积的过程如图3所示.
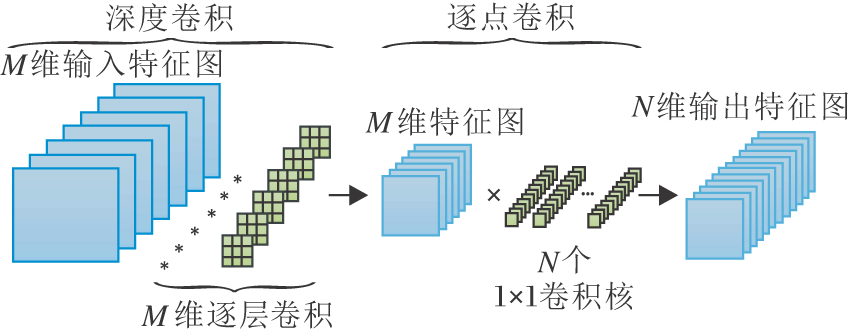 | 图3 深度可分离卷积过程Fig.3 Illustration of depthwise separable convolution process |
由图3可看出, 在深度卷积中, M个输入特征图分别使用单个二维卷积单元进行卷积, 输出依旧是M个特征图.对于逐点卷积过程, 主要关注深度卷积后特征图的组合, 使用N个1× 1卷积进行特征图组合, 用于空间像素级特征提取, 输出结果为N个特征图.相对传统卷积方式, 深度可分离卷积的过程只改变内部算法方式, 并未改变输入、输出尺寸.因此, 可使用深度可分离卷积替换部分传统卷积, 达到减少参数量、提升运算速度的效果.
假设图像输入为DF× DF× M, 卷积核的尺寸为DK× DK× M, 输出特征图的尺寸为DF× DF× N, 深度可分离卷积的参数量为(DK× DK× M)× N, 其中, DF表示输入特征图的尺寸, DK表示卷积核的大小, M表示输入特征图的数量, N表示输出特征图的数量.若使用深度可分离卷积, 深度卷积负责滤波, 尺寸为DK× DK× 1, 逐点卷积负责特征图组合, 尺寸为N× 1× 1× M, 则深度可分离卷积的参数量为DK× DK× M+M× N.使用深度可分离卷积与传统卷积的参数量差异比值为
以YOLOv3中使用最频繁的3× 3卷积为例, 如果N=32, 则深度可分离卷积的参数量约为传统卷积参数量的11%.
1.1.2 模型架构
YOLO系列模型使用DarkNet作为主干网络进行特征提取, 性能良好.本文借鉴YOLO系列模型的思路, 使用深度可分离残差块作为主干网络组件, 结构如图4所示.
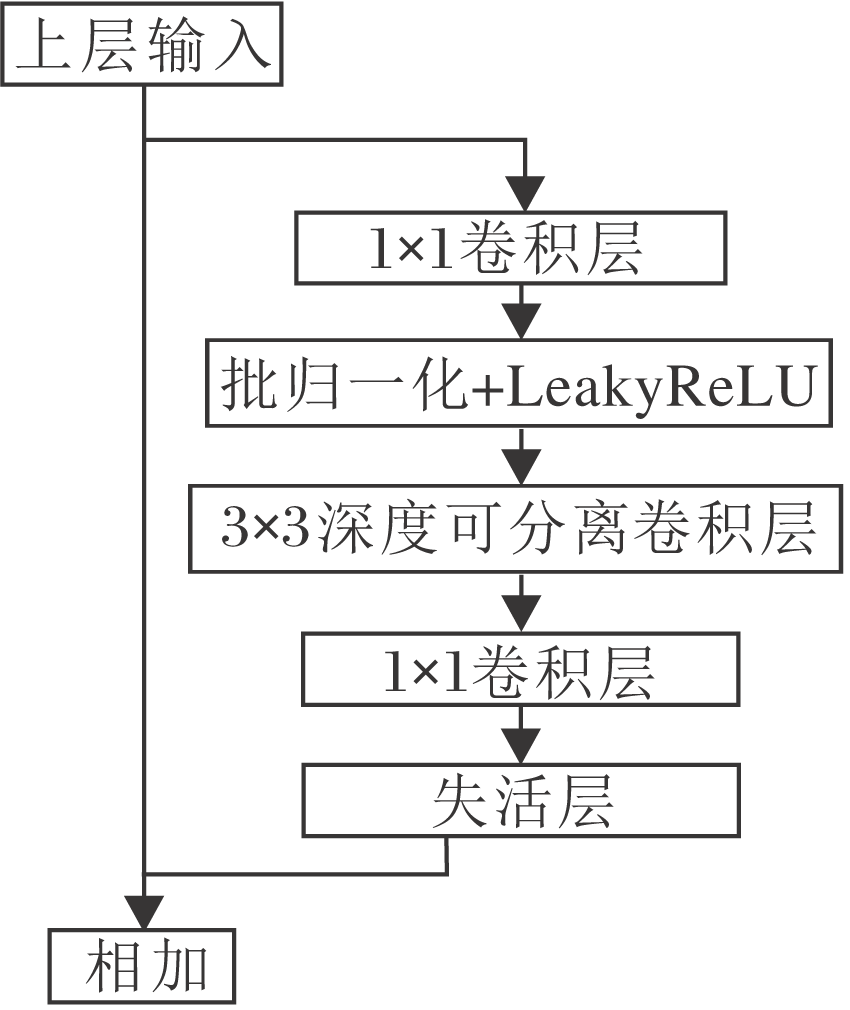 | 图4 深度可分离残差块结构图Fig.4 Structure of depthwise separable residual block |
相比DarkNet中的特征提取网络, 首先将原本的ReLU层更换为LeakyReLU, 原因是ReLU的思想来源于生物学启发, 即只有超出阈值的神经元才会被激活, 当输入权重为负值时, 使用ReLU会使当前的梯度为0, 从而使权重无法更新, 学习速度很慢, 甚至会出现神经元失效的结果.使用LeakyReLU可以较好解决这类问题, 当输入值为负值时, 具有较小的梯度, 能有效减少静默神经元的出现.在网络结构中, 将3× 3的卷积核替换为深度可分离卷积, 使用逐层深度卷积与点卷积完成卷积过程, 使模型参数量缩小至原来的11%.此外, 在深度可分离卷积后, 加入失活层[20], 对于神经网络层设定一个概率, 按照设定的概率随机舍弃部分神经元, 使模型参数不过度依赖训练集, 达到抑制过拟合的目的.
Improved-YOLO网络整体结构如图5所示.
 | 图5 Improved-YOLO网络结构图Fig.5 Network structure of improved-YOLO |
网络前109层使用深度可分离残差块, 用于特征提取.第109层至124层为YOLO层, 主要是用于对火焰图像提取的特征进行解码, 最终可以得到火焰图像预测尺寸边框的中心点坐标、宽高值, 完成火焰检测.
真实火焰数据较复杂, 不同场景、距离都会形成不同的火焰类型, 单纯使用有限的数据集训练的模型难以具有良好的泛化性, 只能较好地拟合已有数据集的类型, 对于从未出现的场景图像具有较低的辨识度.本文采用Mixup数据增强方法[16]对火焰样本进行数据增强, 提升火焰检测模型的泛化能力.Mixup数据增强方法计算公式为
$\tilde{x}=\lambda {{x}_{i}}+(1-\lambda ){{x}_{j}}, \tilde{y}=\lambda {{y}_{i}}+(1-\lambda ){{y}_{j}}$
其中:λ 控制图像融合比例, 取值范围是(0, 1)内的随机浮点数; xi、xj为输入的图像向量; yi、yj为编码过后的图像标签; $\tilde{x}$、$\tilde{y}$分别表示经过Mixup数据增强后的图像向量和标签向量.
Mixup数据增强方法从训练样本中随机抽取2个样本进行随机加权求和, 同时样本标签也进行对应加权求和, Mixup数据增强效果如图6(a)所示.采用对不同类别之间进行建模的方式实现数据增强, 有效增加模型的泛化性.
 | 图6 2种数据增强方法效果Fig.6 Illustration of 2 data augmentation methods |
Mosaic数据增强策略[13]是随机取出4幅图像进行基础数据增强, 例如翻转、色域变化、缩放等, 再将基础数据增强后的4幅图像进行组合拼接, 极大丰富火焰检测的背景, 让神经网络更好地学习火焰图像与背景的差异, Mosaic数据增强效果图如图6(b)所示.
在目标检测的任务中, 交并比(Intersection over Union, IoU)是应用广泛的图像目标检测损失函数, 不仅能确定正负样本, 还能评估输出预测框和实际标注框的距离.IoU计算公式如下:
其中, A∩ B表示A候选框与B候选框的交集区域, A∪ B表示A候选框与B候选框的并集区域.IoU损失函数存在多个明显的缺点:IoU不能反映预测框和实际标注框的距离, 假如两者直接没任何交集, 则IoU值为0, 没有梯度回传, 无法进行学习; 同样不能准确反映预测框和实际标注框重合度大小, 虽然有时IoU值是相同的, 但回归效果不同.
因此, 本文使用损失函数CIoU[17], 可有效解决上述问题.CIoU计算公式如下:
CIoU在IoU的基础上, 加入惩罚项
v作为衡量长宽比一致性的参数,
wgt、hgt表示真实框的宽、高, w、h表示预测框的宽、高.
本文使用迁移学习策略进行模型参数的初始化.首先在MS COCO数据集上进行训练, 训练收敛后将参数加载至模型中继续训练火焰数据集.使用模型预训练的方式, 弥补火焰数据集较少的问题, 提升模型的泛化性与鲁棒性.
YOLO系列模型使用锚机制(Anchor), 即训练前预设不同尺寸的候选框, 约束预测对象的范围, 有助于增加模型收敛的速度.针对火焰数据集, 使用k-means算法对火焰标注框的长宽比进行聚类计算, 计算得出6个尺寸的先验候选框, 先验候选框符合火焰本身的形态特征, 可避免模型盲目搜索预测框尺寸的问题, 达到提升精度、加快收敛速度的目的.
使用多尺度训练策略, 由于火焰数据存在不同的尺寸图像中, 设置多尺度训练策略能增强对不同尺寸火焰数据的鲁棒性, 尺寸以32为间隔, 在160× 160至480× 480内采样.
由于各大比赛与高校未开源火焰检测数据集, 因此作者进行数据集采集与标注.数据集使用Hü ttner等[21]公布火焰视频数据, 在各种场景下采集火焰视频数据, 对视频数据进行分帧, 每隔10帧将图像保存在本地.通过python代码从百度图库中得到400余幅火焰图像数据.使用人工标注火焰位置, 得到最后的火焰数据集.数据集共包含2 688幅火焰图像, 有3 273个火焰目标, 火焰数据包含较多复杂场景, 涵盖白天、夜间、室内、室外、森林、房屋等, 数据集中部分样本如图7所示.本文收集与标注的火焰数据集已开源(下载地址:http://www.yongxu.org/databases.html).
 | 图7 火焰数据集样本Fig.7 Samples of fire dataset |
由于火焰数据集数量较小, 为了提升火焰检测模型的泛化性与鲁棒性, 将本文方法在MS COCO数据集上进行预训练.MS COCO数据集是微软公司发布的大型数据集, 数据来源于日常生活场景, 超过30万幅图像, 其中超过20万幅图像有标注信息, 包含目标检测、实例分割等任务.
实验使用的评价指标包含准确率(Precision, P), 平均准确率(Average Precision, AP), 多类别AP的平均值(mean AP, mAP), 召回率(Recall, R), 准确率与召回率加权均值(F1-score, F1).具体指标计算公式如下:
$P=\frac{{{T}_{P}}}{{{T}_{P}}+{{F}_{P}}}R=\frac{{{T}_{P}}}{{{T}_{P}}+{{F}_{N}}}, {{F}_{1}}=2\times \frac{P\times R}{P+R}, AP={{S}_{pr}}, mAP=\widetilde{AP}$
其中:TP为真实标签为正样本、预测结果为正样本的数量; FP为真实标签为负样本、预测结果为正样本的数量; FN为真实标签为负样本、预测结果为负样本的数量; Spr为不同阈值下组成的准确率-召回率(Precision-Recall, P-R)曲线的面积; $\widetilde{AP}$为不同类别的AP均值.
本文方法复杂度使用的评价指标为每秒浮点运算次数(Floating-Point Operations per Second, FLO-Ps), 表示模型的计算量与计算次数.
本文方法训练时使用的参数如下.动量参数为0.949, 权重衰减正则项为0.000 5, 学习率为0.01, 输入图像尺寸为320× 320.设置饱和度为1.5、曝光率为1.5、色调为0.1进行数据增强.Mixup选取文献[16]中设置的参数.迭代次数为20 000, 保存Loss值最低时对应的方法.
实验使用如下对比方法:轻量级的简化版YOLO目标检测器(简记为YOLO-tiny)[11]、轻量级的YOLOv3目标检测器(简记为YOLOv3-tiny)[12]、轻量级的YOLOv4目标检测器(简记为YOLOv4-tiny)[13]、高度紧凑的目标检测卷积神经网络(简记为YOLO-Nano)[22]、Improved-YOLO-large.其中, Im-proved-YOLO-large是将本文方法卷积核的数量扩大为2倍后的模型.
各方法在MS COCO数据集上的性能对比如表1所示.由表可见, Improved-YOLO的mAP值与YOLOv2-tiny相差无几, 模型大小由42.9 MB降至3.3 MB, 计算量由5.41 GFLOPs降至0.23 GFLOPs, 意味着Improved-YOLO在只有1/13的存储空间和1/23的计算量的情况下, mAP和YOLOv2-tiny相当.Improved-YOLO-large与YOLOv3-tiny的mAP值保持一致, 储存空间与计算量分别降低至1/9和1/8.Improved-YOLO占用更少的存储空间, 具有更小的计算量, 更适合在功耗较低、价格低廉的机器上运行.
| 表1 各方法在MS COCO数据集上的性能 Table 1 Performance of different methods on MS COCO dataset |
Improved-YOLO使用深度可分离卷积改进3维卷积核, 并使用锚聚类对火焰数据进行预处理.Improved-YOLO的mAP值为58.41%.使用预训练参数后, Improved-YOLO的mAP值增至79.32%, 较大幅度提升方法性能.数据增强策略从数据源层面增加数据的多样性, 使方法的泛化能力得以提升, mAP值增至80.27%.使用CIoU损失函数, 使方法预测更有效地拟合真实结果, mAP值增至80.73%.结合数据增强技术与高效损失函数, 可使方法效果达到最佳, mAP值为82.58%.
各方法在火焰数据集上的性能对比如表2所示.由表可知, 使用大型数据集的预训练参数能增强方法的精度和泛化性.Improved-YOLO在火焰数据集上表现更优, 在使用更少的储存空间与计算量的情况下, mAP和F1值优于YOLOv2-tiny和YOLOv3-tiny, 接近于YOLOv4-tiny.
| 表2 各方法在火焰数据集上的性能对比 Table 2 Performance comparison of different methods on Fire dataset % |
各方法在性能较低的嵌入式设备上的推理时间对比如表3所示.在表中, M1表示机器1, 为win-dows机器, 推理使用的CPU型号为i7-8700K; M2表示机器2, 为小米10手机, 使用NCNN进行推理, CPU型号为骁龙865处理器; M3表示机器3, 为华为Mate30, 使用NCNN进行推理, CPU型号为麒麟990.由表可知, Improved-YOLO不论在windows设备上, 还是在安卓设备上, 速度都最优.
| 表3 各方法的推理时间对比 Table 3 Inference time comparison of different methods |
Improved-YOLO火焰检测效果如图8所示.从整体来看, Improved-YOLO可在保持良好性能的前提下, 达到更快的速度, 拥有更高的效率.
 | 图8 Improved-YOLO火焰检测效果图Fig.8 Results of improved-YOLO fire detection |
本文使用深度可分离卷积构建网络主干, 结合一系列数据增强方法和一个鲁棒性较强的损失函数, 设计基于YOLO的火焰检测方法(Improved-YOLO), 有效提升性能.实验表明, 本文方法在火焰数据集上实现准确性和速度的提升, 将其移植到嵌入式平台后可实现实时检测功能.今后将考虑探究更轻量、更高效的火焰检测方法.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|