




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于三维卷积神经网络和峰值帧光流的微表情识别算法
[张学森1  , 贾静平
, 贾静平1 ]
, 贾静平]
|
|



作者简介:

张学森,硕士研究生,主要研究方向为计算机视觉.E-mail:1250025178@qq.com.
针对现有微表情识别技术未能有效利用峰值帧前后时间空间特征的缺点,文中提出基于三维卷积神经网络和峰值帧光流的微表情识别算法.首先,提取峰值帧前后相邻帧间的光流场,在保留微表情重要时间、空间信息的同时,去除冗余信息,减少计算量.然后,利用三维卷积神经网络,从光流场中提取增强的时空特征,实现微表情的分类识别.最后,通过在3个微表情数据库上的对比实验证实文中算法准确度较高.
AboutAuthor:
ZHANG Xuesen, master student. His research interests include computer vision.
The existing micro-expression recognition technologies cannot make full use of the spatiotemporal features near the apex frame. Aiming at this problem, a micro-expression recognition algorithm based on 3D convolutional neural network and optical flow fields from the neighboring frames of the apex frame is proposed. Firstly, the optical flow fields between the adjacent frames before and after the apex frame are extracted. The important spatiotemporal information of micro-expressions are retained while the redundant information is removed and the computation load is reduced. Then, a 3D convolutional neural network is employed to extract the enhanced spatiotemporal features from the optical flow fields and thus the classification is completed. Finally, experiments on three spontaneous micro-expression databases show the proposed algorithm produces a better accuracy.
本文责任编委 汪增幅
Recommended by Associate Editor WANG Zengfu
微表情是一种细微而不自觉的面部表情, 反映人类真实的情感.不同于普通的面部表情, 微表情通常发生在1/25~1/3 s内[1], 只出现在面部的几个小区域内.由于微表情的发生是无意识的, 却反映一个人隐藏的真实情绪, 所以微表情识别/分类在国家安全、金融信贷、临床医学等多个领域具有重要的应用价值[2, 3].
最初, 微表情的识别由心理学家或训练有素的专家人工完成, 完全依赖于个人经验判断, 准确率不高.在识别过程中, 至少需要2人, 分别逐帧检查视频图像, 费时费力.因此, 研究能自动检测微表情并对其分类识别的算法成为近年来的研究热点.然而, 由于微表情持续时间较短、动作幅度较小, 经典的普通面部表情识别算法难以用于微表情识别.
目前, 按照提取特征的时刻位置不同, 可将现有的微表情识别算法分为2类[4].1)基于序列的方法.从微表情图像序列中的每帧或部分采样帧中提取特征[5, 6, 7, 8].2)基于峰值帧(Apex)的方法.以起始帧(Onset)作为参照帧, 从峰值帧中提取特征[9, 10].起始帧、峰值帧、结束帧(Offset)是每个微表情图像帧序列都有的3个重要时刻位置.从起始帧开始, 面部肌肉开始收缩, 到峰值帧时, 微表情最显著, 结束帧后肌肉重新放松, 微表情消失.生理学研究表明, 峰值帧能传达最多的面部表情表达的情感.基于峰值帧的方法在减少所需处理帧数的同时, 保留最显著的微表情信息, 明显优于基于序列的方法.然而, 已有基于峰值帧的方法[9, 10]只使用峰值帧这一单一图像内的空间信息, 却忽略峰值帧附近的时间信息, 未利用峰值帧附近的时空连续变化信息.
按照提取的特征, 可将现有的微表情识别算法分作4类:基于梯度特征的方法、基于纹理特征的方法、基于运动信息特征的方法、基于深度学习技术提取特征的方法.
最早用于微表情识别的人工设计的特征是基于梯度的特征.Polikovsky等[11]提出基于方向梯度直方图特征的识别算法.随后基于纹理特征的方法, 尤其是基于局部二进制模式(Local Binary Pattern, LBP) 的方法大量出现.Pfister等[7]提出三正交平面的LBP(LBP from Three Orthogonal Planes, LBP-TOP).Qu等[12]利用LBP-TOP提取特征, 使用支持向量机(Support Vector Machine, SVM)分类器进行微表情分类识别.Wang等[8]提出基于6个交叉点的LBP(LBP with Six Intersection Points, LBP-SIP), 减少LBP-TOP的冗余信息.为了减少特征提取的计算量, Wang等[13]提出平均正交平面LBP(LBP Mean Orthogonal Planes, LBP-MOP)特征提取方法.Esmaeili等[14] 提出从水平、垂直和对角3个平面提取LBP, 组合成立方体LBP(Cubic LBP)的方法.Li等[15]组合LBP-TOP、定向梯度直方图和图像梯度方向直方图, 生成单个特征向量进行识别.基于纹理特征的方法除了基于LBP的方法以外, 还包括基于Gabor滤波器[16, 17]的方法.
基于运动信息的特征主要是光流技术和光应变技术.基于光流技术的方法包括:Liu等[18]提出计算面部肌肉运动的主方向平均光流(Main Directional Mean Optical Flow, MDMO)技术和Xu等[19]提出面部动态图(Facial Dynamics Map, FDM)方法, 它们都取得一定的识别效果.光应变是基于光流计算得到的反映物体变形情况的特征[20].Shreve等[21]计算人脸关键区域内的光应变, 实现微表情的检测.Liong等[22]提出利用光流强度局部加权、光应变全局加权的双加权方向光流直方图(Bi-weighted Oriented Optical Flow, Bi-WOOF).
上述算法都基于人工设计的特征, 性能不及基于深度学习技术的算法[23].根据提取微表情时空信息的方式, 基于深度学习的算法可分作2类:1)单独提取空间特征的方法.利用卷积神经网络(Convolutional Neural Network, CNN)[5, 18, 23, 24]从微表情序列的离散帧中提取空间特征, 经过特征选择处理后识别.Patel等[24]利用在宏观表情数据库上训练的CNN作为特征提取器, 使用遗传算法对提取的特征信息进行选择, 再使用传统的分类器进行分类.Khor等[25]将空间特征提取器和用于收集时间信息的时间模块组成的长期递归卷积网络用于微表情识别.Peng等[6]将在宏观表情数据库上得到的残差网络-10(Residual Network-10, ResNet-10)和迁移学习应用到微表情识别任务中.Gan等[10]提出峰值帧光流特征网络(Optical Flow Features from Apex Frame Network, OFF-ApexNet), 提取起始帧与峰值帧之间的光流图像, 作为CNN的输入, 从该光流场中提取空间特征进行识别.2)联合提取时间空间特征的方法.同时提取空间特征随时间变化的信息在识别性能上优于单独提取空间特征的方法, 这类方法包括基于长短期记忆网络(Long Short Term Memory, LSTM)的方法[24], 以及将CNN的空间域卷积拓展到时域的三维卷积神经网络(3D-CNN)的算法.Reddy等[26]提出2种基于3D-CNN的模型.Peng等[5]提出双时间尺度卷积神经网络(Dual Tem-poral Scale CNN, DTSCNN).Li等[27]提出3D-CNN.
上述算法将序列中所有帧都用于模型训练, 忽略微表情信息主要集中于峰值帧附近这一特点, 导致部分帧中的眨眼、头部倾斜等干扰动作影响识别性能.针对这一缺陷, 本文提出基于3D-CNN和峰值帧光流的微表情识别算法(Micro-expression Recog-nition Algorithm Based on 3D CNN and Optical Flow Fields from Neighboring Frames of Apex Frame, 3D-Apexflow).利用3D-CNN, 从峰值帧前后相邻帧序列的光流中, 提取微表情最高强度及其前后发生、舒展、最显著的时空联合特征, 从而提高微表情识别的性能.相比已有算法, 本文方法在保留关键信息的同时, 去除冗余, 减少计算量.
本文提出基于三维卷积神经网络和峰值帧光流的微表情识别算法, 首先对微表情样本中的人脸区域进行对齐和裁剪, 然后定位其中的峰值帧, 计算峰值帧前后帧中的光流场, 最后使用3D-CNN, 从光流场中提取时空特征, 分类样本.
为了减少原始数据集图像中非面部区域的噪音影响, 需从微表情样本的图像序列中裁剪并对齐人脸区域.本文首先定位眼睛区域的2个中心点[28],
确定面部的初始位置.然后通过主动形状模型(Active Shape Model, ASM)[29]拟合人脸形状的准确位置, 裁剪面部区域.最后使用局部加权平均(Local Weighted Mean, LWM)[7]变换将序列中所有面部区域逐帧与参考帧中的区域对齐, 具体过程如图1所示.
 | 图1 本文算法的预处理过程Fig.1 Preprocessing of the proposed algorithm |
为了从微表情峰值帧及邻近帧的光流中提取时空特征, 在计算光流之前需先定位峰值帧.微表情数据库可看作微表情样本的集合
S={s1, s2, …, sn},
其中n为微表情样本的数量.每个样本都是由若干帧微表情图像构成的序列, 如第i个样本
si={fi, j|i=1, 2, …, n; j=1, 2, …, Fi},
其中Fi为第i个样本中的图像帧的总数.每个微表情样本都包含1个峰值帧fi, α , 它可能是位于起始帧fi, 1和结束帧
定位峰值帧fi, α 后, 通过包括fi, α 在内的前后相邻帧计算光流场.由于微表情最短持续时间为1/25 s, 而目前微表情数据库中样本的帧率最高为200帧/秒, 可换算得到最短的微表情持续的图像为8帧, 所以计算峰值帧fi, α 前后各4帧、共9帧的光流场.由于微表情的动作幅度很小, 所以本文使用文献[30]方法计算稠密光流场, 作为微表情的特征表示.
受文献[5]、文献[26]和文献[27]的启发, 本文提出3D-Apexflow, 提取微表情序列中的时空特征, 并实现微表情的分类.不同于上述工作, 3D-Apexflow不是从原始像素值中提取特征, 而是从光流场中提取特征, 由于光流场仅保留与微表情相关的运动信息而舍弃无关的亮度信息, 所以可在较小的模型复杂度下, 取得较高的准确率.
3D-Apexflow是一个具有3D卷积层和3D池化层的神经网络, 框架如图2所示.这是一个19层的网络结构, 有8个3D卷积层, 5个3D池化层, 2个完全连接层, 1个展开层, 2个失活层, 输出Softmax层.网络参数如表1所示.
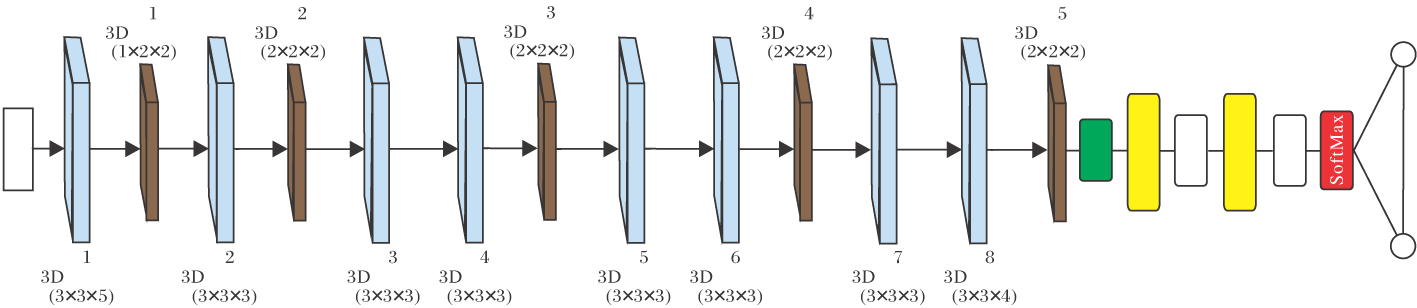 | 图2 3D-Apexflow框架图Fig.2 Framework of 3D-Apexflow |
| 表1 3D-Apexflow参数设置 Table 1 Parameter setting of 3D-Apexflow model |
与典型的2D-CNN中的卷积层或池化层不同, 3D-Apexflow中的3D卷积层和3D池化层的卷积核大小为k× k× l, 其中, k为空间尺寸大小, l为时间深度大小.
在3D-Apexflow中输入的微表情光流场的大小为d× w× h× c, 其中w、h分别为每帧光流场的宽度、高度, c为通道数, d为微表情样本中的帧数, 由于光流场为单通道, 所以c=1.在一个典型的2D-CNN的输入层中, 每帧图像都会被当作一个待识别对象, 但3D-Apexflow是将多帧光流场组成的序列作为一个待识别对象输入到网络中进行识别.
在3D卷积层中, 使用一个尺寸为mx× my× mt的3D卷积核提取时空特征信息.例如, 3× 3× 3卷积核将时间维度设置为3, 这意味着它将处理空间窗口大小为3× 3的连续3帧.图3说明3D卷积在具有6帧的序列中的工作过程.为了便于直观理解, 图中以图像帧作为卷积输入, 3D-Apexflow实际的输入为光流场帧.标记为3× 3× 3的3D卷积核对每相邻的3帧进行卷积运算, 从前3帧一直滑动到最后3帧, 大小为3× 3的空间窗口从左到右、从上到下滑动.设W为卷积核矩阵, Ii表示第i帧, fi为第i个卷积输出.由于每3个Ii产生一个f输出, 3D卷积输出的尺寸大小为(h-mx+1)× (w-my+1)× (l-mt+1), 其中, h、w分别为帧的高度、宽度, l为序列长度.在3D卷积运算后, 6个帧产生4个f输出映射:
fi=IiW1+Ii+1W2+Ii+2W3.
 | 图3 3× 3× 3的3D卷积核在6个微表情视频帧上的运行示例Fig.3 Illustration of 3D convolution on six-frame ME sample using 3× 3× 3 kernel |
为了更全面地提取特征, 使用多个3D卷积核.因此, 在网络第i层的第j个特征映射上, 坐标为(x, y, z)的像素,
$v_{ij}^{xyz}=relu\left( {{b}_{ij}}+\underset{m}{\mathop{\sum }}\, \overset{{{p}_{i}}-1}{\mathop{\underset{p=0}{\mathop{\sum }}\, }}\, \overset{{{Q}_{i}}-1}{\mathop{\underset{q=0}{\mathop{\sum }}\, }}\, \overset{{{R}_{i}}-1}{\mathop{\underset{r=0}{\mathop{\sum }}\, }}\, w_{ijm}^{pqr}v_{\left( i-1 \right)m}^{\left( x+p \right)\left( y+q \right)\left( z+r \right)} \right), $
其中, w为3D卷积核的权重,
将3D池化层应用于三维时空数据, 方式与3D卷积类似, 考虑X、Y、T轴.池化过程精简同一特征映射中相邻神经元组的输出, 减少其在下一层的维数.实验表明, 最大池化操作在微表情识别任务中的表现优于平均池化操作, 3D-Apexflow中也采用最大池化操作, 这与其它研究[31, 32]一致.为了加速训练过程, 在进入后续池化层之前, 将批归一化(Batch Normalization)技术应用于每个卷积层.为了避免卷积运算造成信息丢失, 在进入后续卷积层之前, 将零填充应用于每个池化层.输出层为softmax多分类器, 类别数等于微表情的分类数.
为了捕捉微表情微小的时空变化, 使用3× 3× 3的小型3D卷积核, 因为这对应着较小的感受野.网络中间层卷积核的尺寸大小设置为3× 3× 3, 而池化尺寸大小除第1层为1× 2× 2以外, 其余都为2× 2× 2.第1个卷积层使用3× 3× 5的3D卷积核, 设置1个相对较大的时间步长, 主要是为了减少初始层的冗余信息, 节省内存, 同时为了避免可能产生的更多时间不确定因素.
评价微表情识别算法的性能, 需要基于统一的微表情数据库.早期的微表情数据库[21]中包含摆拍的微表情, 是由被拍摄者模仿的微表情, 而不是自发流露的微表情, 这并不符合微表情无意识发生的特点, 不适合微表情识别算法[33].所以本文将依据目前3个应用最广泛的自发微表情数据库CASME II[34]、SMIC[35]和SAMM[36]验证算法性能.
SMIC数据库包括微观表情和宏观表情, 只选取微观表情样本, 即来自16名受试者的164个微表情样本, 帧速率为100 帧/秒, 分辨率为640× 640, 人脸区域的分辨率约为190× 230.数据库包括3个微表情类别:积极、消极、惊讶.CASME II数据库收集26个受试者的256个微表情样本, 帧速率为200 帧/秒, 样本分辨率为640× 480, 人脸区域分辨率为280× 340.数据库包含7个微表情类:厌恶、快乐、压抑、惊讶、悲伤、恐惧、其它.SAMM数据库包含32个受试者的159个微表情样本, 帧速率为200 帧/秒.参与者来自13个种族, 平均年龄33.24岁, 样本分辨率为2 040× 1 088, 人脸区域分辨率约为400× 400.数据库包含7种微表情类型:快乐、惊讶、厌恶、压抑、愤怒、恐惧、蔑视.
每个数据库微表情样本的类别分布不平衡, 因此实验使用MEGC 2019跨数据库挑战[37]中的策略评估算法.将来自这3个数据库的大部分样本合并成一个复合数据库— — 3DB, 采用的方法是将它们各自的情感类别映射成3个通用的情感类别:积极、消极、惊讶.具体来说, 快乐样本被给予积极的标签, 惊讶样本的标签不变, 厌恶、压抑、愤怒、蔑视、恐惧、悲伤的样本归为消极.3个数据库中样本情感的分布情况如表2所示.合并后的数据库共有442个样本.在3DB数据库中, 共有68位受试者, 来自SMIC的16位, 来自CASME II的24位, 来自SAMM的28位.
| 表2 各数据库微表情样本分布情况 Table 2 Distribution of samples with different emotions in different databases |
CASME II、SAMM数据库已提供峰值帧的标注信息, 至少由2名经验丰富的专家标注.由于SMIC数据库缺少峰值帧标注信息, 因此采用基于频域的方法[9]对SMIC数据库上的样本进行峰值帧定位.利用三维快速傅里叶变换(3D Fast Fourier Trans-form, 3D-FFT)将微表情图像变换为频域信号表示, 并根据最高的频率振幅定位峰值帧fi, α , 该方法速度快于基于空间域的方法[22, 38, 39].
在将峰值帧及其邻近帧的光流场输入网络之前, 缩放至64× 64.
所有实验都是在Ubuntu 16.04, NVIDIA GeForce GTX960 GPU, Python 3.6.2, Keras 2.2.4和Tensorflow 1.11.0平台上训练和测试.在训练模型时, 使用交叉熵损失函数和随机梯度下降(Stochastic Gradient Descent, SGD)优化, 学习率设置为0.01, 批大小设置为3.所有的对比实验都基于留一交叉验证(Leave-One-Subject-Out Cross Validation, LOSOCV)进行评估, 即将一位受试者的样本用作测试, 别的受试者的样本用作训练.
3D-Apexflow在不同训练集遍历次数下宏平均准确率和宏平均F1值如图4所示.由图可见, 当训练集遍历次数为100时, 识别性能最优.
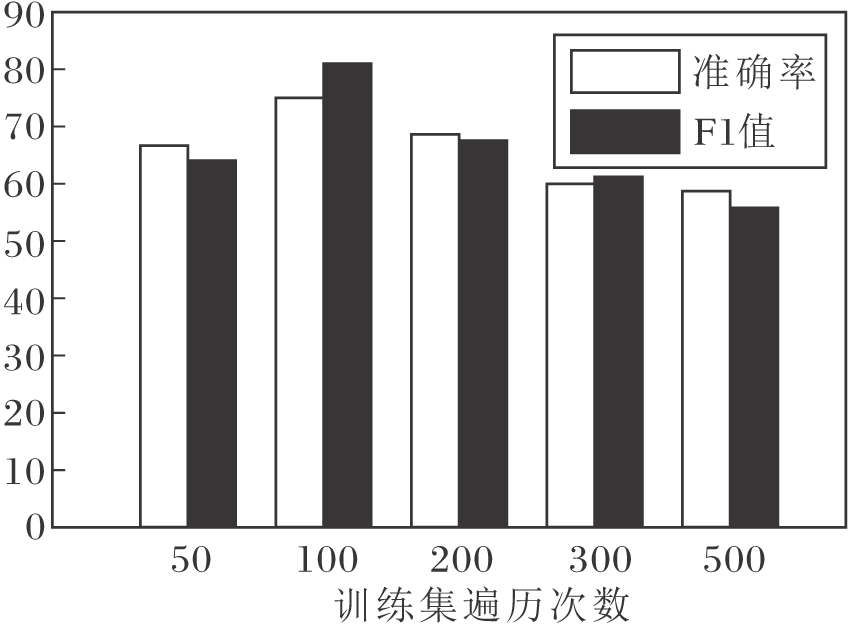 | 图4 3D-Apexflow在不同训练集遍历次数下的性能对比Fig.4 Performance comparison of 3D-Apexflow model on training set with different number of training times |
实验选择如下对比算法:LBP-TOP, LBP-SIP[8], Bi-WOOF[22], 基于微注意机制的残差网络(Residual Network with Micro-Attention, Micro-Attention)[40], 基于3D-CNN的视觉几何研究组模型(Visual Geo-metry Group with 3D CNN, VGG3D)[41], 胶囊网络(Capsule Networks, CapsuleNet)[42].
各算法在三分类场景下的性能对比如表3所示.由表可见, 3D-Apexflow在数据库上的准确率最高.相比LBP-TOP, 在3DB、SAMM、CASME II、SMIC数据库上准确率分别提高34.4%、14.3%、21.6%、17%.更重要的是, 3D-Apexflow在3DB数据库上准确率最高(0.776).
| 表3 三分类场景下各算法的性能对比 Table 3 Performance comparison of different algorithms in scenarios of three classes |
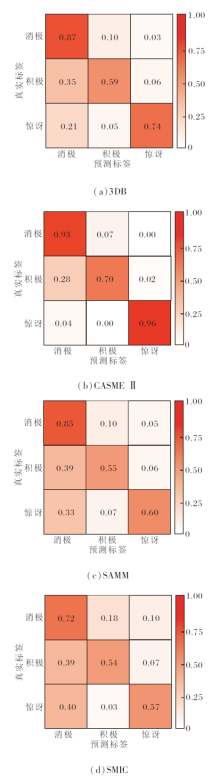
为了全面分析算法性能, 图5分别给出3D-Apexflow在各数据库上的混淆矩阵.由图可看出, 数据库中3类样本数目不均衡, 消极类样本在数据库中占多数.实验结果表明微表情识别的性能距离宏观表情的识别性能有很大差距, 一个重要的原因就是微表情的运动微弱的特性.宏观表情动作幅度较大, 人类每分钟15次左右的正常眨眼, 对于识别影响不大, 却会对微表情的识别带来很大干扰.在SMIC数据库上, 受试者眨眼的微表情视频序列约32个, CASMEⅡ 数据库上约20个, SAMM数据库上约18个(由于有的个别眨眼动作幅度较小, 难以准确界定).这对于有限的数据集, 比例很大, 尤其在SMIC数据库上, 眨眼序列占比最高, 这部分解释3D-Apexflow在SMIC数据库上的识别性能低于CASME II数据库的原因, 另外, SMIC数据库没有人工标注峰值帧, 定位峰值帧的步骤可能引入潜在的误差.由于数据库样本的帧率较低(100 帧/秒), 在峰值帧附近, 无法像高帧率摄像机那样, 捕捉更细微的表情运动, 此外还受到图像分辨率较低、人脸面积及阴影、高光等噪声的影响.而在SAMM数据库上, 受试者的年龄和种族差异较大, 类不均衡问题最明显, 消极类样本占比为3个数据库中最高.
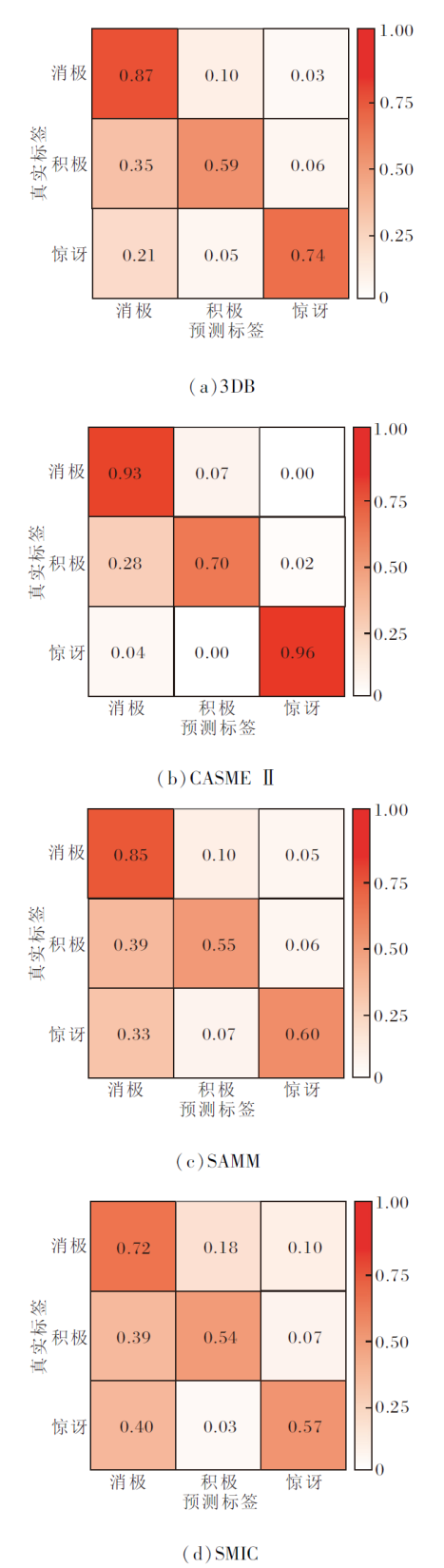 | 图5 3D-Apexflow在4个数据库上的混淆矩阵Fig.5 Confusion matrix of 3D-Apexflow on 4 databases |
由图5(c)、(d)可见, 3D-Apexflow在SAMM数据库上的性能与SMIC数据库相当.3D-Apexflow在CASME II数据库上的准确率最高, 这是因为CASME II数据库样本精确的峰值帧标注及高帧率提供更准确的光流计算, 更好地表征微表情的运动变化.
为了验证3D-Apexflow的鲁棒性和有效性, 在SAMM、CASMEⅡ 数据库上进行五分类场景下的识别对比实验, 各算法性能对比如表4所示.
| 表4 五分类场景下各算法性能对比 Table 4 Performance comparison of different algorithms in scenarios of five classes |
由于个别微表情样本非常少(如CASMEⅡ 数据库上恐惧类别只有2个样本), 因此在实验中会忽略这些类别.在CASMEII、SAMM数据库上均采取5种类别(厌恶、快乐、压抑、惊讶、其它).由于厌恶微表情和压抑微表情样本较类似, 同时由于其它类别样本较多且受试者表现各异, 因此识别准确率整体下降, 但3D-Apexflow在五分类场景下依然取得最高准确率.
各算法对测试集中样本进行分类所需的平均时间对比如表5所示.由表可见, 3D-Apexflow对样本分类的速度在所有算法中排第二, 平均每个微表情样本只需0.277 s, 仅次于LBP-SIP, 快于LBP-TOP.3D-Apexflow的速度提升是因为算法仅从峰值帧前后邻近帧的光流场中提取显著特征, 而不是处理所有帧, 计算量较小.虽然3D-Apexflow较深的网络在处理每帧图像时需要较大的计算量, 但由于每个微表情样本只需处理峰值帧前后共9帧, 总计算量仍小于其它算法处理样本所有帧需要的计算量.
| 表5 在测试集上各算法对每个样本消耗的平均时间 Table 5 Comparison of average time consuming per sample of different algorithms |
本文没有对比各算法在训练时的速度, 这是因为各算法利用训练样本中帧的方式不同, 提取特征也不同, 使训练时间不具可比性, 而且学习率、优化算子等参数设置的不同也会影响算法收敛的速度.
为了寻求最佳网络, 改变3D-Apexflow网络中卷积层和池化层的数量及相对位置, 进行消融对比实验.对比网络框图如图6所示.
 | 图6 对比网络框图Fig.6 Illustration of network models with different layer configurations |
各网络在3DB数据库上的性能对比如表6所示.由表可见, 图6(a)网络、图6(d)网络的卷积层和池化层都少于3D-Apexflow, 性能都差于3D-Apexflow, 但卷积层和池化层都更少的图6(a)网络性能却好于图6(d)网络, 这说明识别性能与网络层数并不呈简单的线性关系, 而是与微表情变化复杂微小的属性及3D-CNN对于运动变化区域的敏感性有关, 需要通过大量实验找到性能最优的网络.
| 表6 各网络在3DB数据库上的性能对比 Table 6 Performance comparison of different networks on 3DB databases |
图6(b)网络卷积层更少, 虽然训练速度显著提升, 但对微表情泛化识别能力明显下降, 这说明更浅层的网络无法更好地捕捉微表情微小复杂的变化.
图6(c)网络的初始卷积层多于3D-Apexflow, 但性能更差, 这是由较多的卷积层产生的较大初始层感受野引起的.3D-Apexflow初始层为1层3D卷积层结合1层3D池化层的结构, 更容易突出有价值的特征信息, 去除噪声干扰.
图6(d)网络性能优于图6(b)网络, 说明中间层采用2层卷积层和1层池化层的结构能更平衡地提取特征和去除冗余.图6(e)网络结构与3D-Apexflow类似, 只是深度有所增加, 但性能下降, 这说明更深的网络会导致过度拟合.通过对比实验最终选择3D-Apexflow现在的架构.
为了验证从峰值帧相邻帧中提取的光流场在算法性能方面优于原始图像, 将峰值帧及其左右4帧原始图像的像素缩至64× 64后, 在不提取光流的情况下, 直接输入至后续的网络模型中, 结果如表7中3D-Apex所示.由表可看出, 提取峰值帧相邻帧的光流, 相比原始图像帧, 为3D-Apexflow性能提供约10%的显著提升.
| 表7 两种场景下各算法的性能对比 Table 7 Performance comparison of different algorithms in 2 scenarios |
为了说明峰值帧的重要性, 将从完整微表情视频序列中提取的光流缩至64× 64后, 直接输入后续网络中, 结果如表7中3D-Flow所示.由表可看出, 提取峰值帧临近帧的光流, 相比完整微表情视频序列的光流, 性能提升约20%.峰值帧附近的光流场取得优于完整序列的光流场及峰值帧相邻的图像帧的识别性能.
在图6中分别以峰值帧附近的光流场和完整序列的光流场为输入时, 各网络的性能对比如表8所示.由表可见, 以峰值帧相邻帧光流场为特征的3D-Apexflow取得最高的准确率和F1值.
| 表8 输入不同时各网络在3DB数据库上的性能对比 Table 8 Performance comparison of different network models with different inputs on 3DB database |
本文提出基于三维卷积神经网络和峰值帧光流的微表情识别算法(3D-Apexflow).算法重点关注峰值帧, 通过换算得到微表情最短持续帧数为8帧, 采用峰值帧及其左右4帧(共9帧)图像表示微表情完整的发生过程, 计算光流输入以3D-CNN为基础的网络模型, 提取表达重要时空细节, 去除噪音冗余的特征.3D-Apexflow结合提取的空间特征与时间特征, 完成微表情分类.实验表明, 3D-Apexflow在SMIC、SAMM、CASME II数据库和基于这3个数据库的复合数据库上都取得较优的识别性能, 尤其是在复合数据库上三分类场景中性能最优, 这说明3D-Apexflow的先进性.由于现有微表情数据集样本规模较小, 3D-Apexflow的网络架构受到限制, 识别精度离实用要求仍有较大差距, 今后将考虑寻找更大规模的数据集, 进一步提高算法的性能.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|