
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于图像序列的车道线并行检测网络
[朱威1  , 欧全林
, 欧全林1 , 洪力栋1 , 何德峰1 ]
, 欧全林, 洪力栋, 何德峰]
|
|



作者简介:
欧全林,硕士研究生,主要研究方向为智能视觉处理.E-mail:1145893246@qq.com.

洪力栋,硕士研究生,主要研究方向为智能机器人系统.E-mail:267310301@qq.com.

何德峰,博士,教授,主要研究方向为智能驾驶与安全控制.E-mail:hdfzj@zjut.edu.cn.
现有车道线检测神经网络主要采用相互独立的单帧图像进行检测,无法较好地处理包含车道线短时遮挡、地面明暗变化等复杂因素的实际应用场景.针对上述问题,文中根据车辆在正常行驶过程中可获得连续图像的场景特点,提出基于图像序列的车道线并行检测网络.首先设计并行的特征提取结构,一方面使用精度较高的单帧网络提取当前帧图像的特征,另一方面设计轻量级的多帧网络提取低分辨率的多帧时序图像的特征,并采用循环神经网络模块融合提取的时序特征,得到多帧特征.再设计单帧特征与多帧特征融合模块,通过上采样网络输出车道线特征图.实验表明,文中网络在客观检测精度和主观效果上都具有明显提升.
AboutAuthor:
OU Quanlin, master student. His research interests include intelligent visual proce-ssing.
HONG Lidong, master student. His research interests include intelligent robot system.
HE Defeng, Ph.D., professor. His research interests include intelligent driving and safety control.
The existing lane detection neural networks mainly adopt independent single frame image for detection, and therefore they cannot handle the complex and practical application scenarios, such as short-term occlusion of lane and light and shade changes of ground. To solve these problems, a parallel lane detection network based on image sequence is proposed according to the scene characteristics that the continuous images can be obtained in the normal driving process of vehicles. Firstly, a parallel feature extraction structure is designed. A single frame network with high accuracy is employed to extract the features of the current frame image. A lightweight multi-frame network is designed to extract the features of low resolution multi-frame sequential images. The cyclic neural network module is utilized to fuse the extracted sequential features to obtain multi-frame features. Then, the fusion module of single frame feature and multi-frame feature is designed, and the feature map of the lane line is output through upsampling network. The experimental results show that the objective detection accuracy and subjective effect of the proposed network are significantly improved.
本文责任编委 高隽
Recommended by Associate Editor GAO Jun
随着以深度神经网络为代表的人工智能理论与技术的不断突破, 自动驾驶及高级辅助驾驶已进入快速发展的时期, 实际应用中不仅能有效减少因人为因素导致的驾驶事故, 保障人们的生命安全, 还能大幅提高交通效率, 是智能交通的必然发展趋势.车道线检测作为全自动驾驶和高级辅助驾驶的重要实现环节, 对车辆的环境感知能力及车道保持系统都有重要意义.目前虽然已有一些商用的车道线检测应用, 但使用场景受限, 无法适用于诸如车道线短时遮挡、路面明暗变化等复杂场景.因此, 针对复杂场景下的车道线检测是自动驾驶领域重要的研究方向.
由于神经网络在图像分割研究中的优异性能, 学者们提出各种车道线检测网络.目前大部分车道线检测网络主要是从基于单帧图像的语义分割网络发展而来.Badrinarayanan等[1]提出经典的语义分割网络(Semantic Segmentation Network, SegNet), 采用对称式的网络结构, 通过特殊设计的池化索引记录池化值在特征图中的位置索引, 并在上采样时将该值直接赋给相应的位置, 从而恢复图像分割信息.Ronneberger等[2]提出U型网络(U-shaped Network, U-Net), 加入反卷积与横向连接, 使上采样操作变得可学习, 同时上采样网络通过融合高层特征还原细节信息, 使预测结果更平滑.
除了传统的语义分割网络以外, 现有网络也会依据车道线特征进行结构设计.Neven等[3]提出端到端的车道线实例分割网络(Lane Detection Net-work, LaneNet), 利用车道线具有多车道实例的特征, 将车道线检测看作实例分割问题, 额外增加一个实例分割网络分支, 将所有车道线像素区域分割成不同的车道线实例.Lee等[4]提出基于消失点原理和端到端的车道线消失点引导网络(Vanishing Point Guided Network, VPGNet), 可同时处理车道线和道路标记, 并利用消失点提供的全局信息提高在复杂天气环境下的检测精度.Pan等[5]提出针对车道线结构的空间卷积神经网络(Spatial Convolutional Neural Network, SCNN), 将原始的卷积模型修改为适合对长条形结构进行预测的片结构卷积, 使行和列像素之间的信息流得以在卷积网络中传递, 从而增加车道线结构在网络中的权重.Garnett 等[6]提出端到端的三维多端车道线检测网络(3D Multiple Lane Detection Network, 3D-LaneNet), 利用车辆多摄像头系统提供的前视图和经过变换后的顶视图进行车道线预测, 前视流处理和保持图像信息, 顶视流提供平移不变性的特征并输出最终三维车道线信息.虽然上述网络可有效检测车道线, 但仅使用当前时刻图像检测车道线, 忽略过去时序上的车道线特征, 在一些突发车道遮挡、视角变换、地面光线明暗变化的场景下, 由于缺乏时域上下文的信息, 存在检测准确度不高的问题.
目前将视频流作为网络输入实现车道线检测的研究还较少, Zou等[7]提出结合卷积神经网络(Convolutional Neural Network, CNN)和循环神经网络(Re- current Neural Network, RNN)进行车道线检测的方法, 比仅采用CNN的车道线检测效果更优.虽然网络引入循环网络模块, 提高检测与分割效果, 但对时序上的每帧图像都使用相同网络结构进行特征提取, 会使网络弱化最关键的当前帧的特征信息, 将计算资源消耗在有大量冗余的多帧特征.此外, 一旦对网络结构进行修改会对全局特征产生巨大影响, 不利于网络结构优化.
为了弥补基于单帧图像的车道线检测网络在时域信息上的缺失, 并兼顾检测速度和准确率, 本文提出基于图像序列的车道线并行检测网络.在单帧图像分割网络的基础上增加基于RNN的多帧网络, 将包括当前帧在内的过去时刻的多帧图像作为该网络输入, 采用卷积长短期记忆循环神经网络(Convo-lutional Long-Short Term Memory, ConvLSTM)门机制[8]将多帧图像中依时序变化的目标特征信息和环境上下文信息进行融合提取.为了减少因多帧网络而新增的计算量, 采取低分辨率输入策略, 并选取轻量级网络作为多帧网络的骨架网络, 有效降低多帧网络的参数量和计算复杂度.为了有效融合多帧网络提取的多帧时域特征与单帧网络提取的全局语义特征, 设计采用通道连接的特征融合模块, 使单帧特征能有效融合全部的多帧时域信息, 让融合特征同时具备表征空域信息和时域信息的能力.最后通过上采样网络输出车道线特征图.
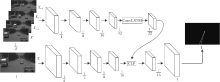
本文的基于图像序列的车道线并行检测网络结构如图1所示, 主要由2个网络模块构成:多帧网络和单帧网络.多帧网络用于提取多帧时序图像中的时域特征, 单帧网络基于编码-解码模型, 用于提取当前时刻图像的全局语义特征, 并通过融合模块和上采样模块输出最终结果.由于采用并行结构设计, 单帧网络与多帧网络赋予不同的信息流, 使多帧网络可学习多帧时域特征, 单帧网络可学习单帧图像中的空域语义特征, 连接这些特征, 更全面地表达车道线信息.此外, 相对独立的并行网络结构也方便进行针对性的结构调优.
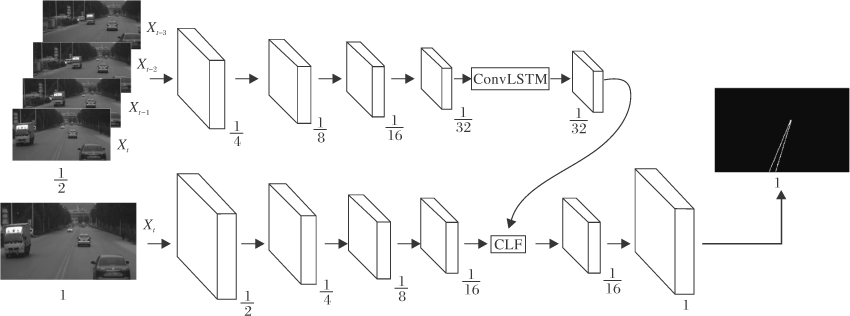 | 图1 本文网络架构Fig.1 Architecture of the proposed network |
本文的多帧网络采用轻量级的骨架网络, 将包括当前帧在内的过去时刻的多帧图像作为网络输入.由于引入多帧网络会带来较大的计算复杂度, 所以采取低分辨输入策略, 通过降低多帧图像的输入分辨率, 明显降低网络计算量和缩短网络计算时间.在提取不同时域下的每幅图像经骨架网络输出的特征后, 如何有效融合通过每幅图像提取的特征成为主要问题.对此本文采用ConvLSTM网络模块处理这些特征, 在利用长短期记忆网络(Long Short-Term Memory, LS-TM)[9]处理多帧特征序列中关键的目标特征信息的同时遗忘不重要的特征信息, 得到最终的多帧时域特征.
本文的单帧网络选取比多帧网络更复杂的骨架网络.这是由于在现实情况中, 相比过去其它时刻的图像帧, 当前时刻的图像帧包含更准确的语义信息, 而高复杂度的网络结构常具有对语义信息更强的泛化学习能力和表征能力, 因此单帧网络采用更复杂的网络结构和更深的网络层次, 用于学习更高层的抽象特征, 并通过金字塔模块结构整合不同尺寸的特征信息, 得到单帧特征.为了融合单帧网络与多帧网络的特征信息, 设计单帧特征和多帧特征(ConvLSTM)融合模块(ConvLSTM Fusion, CLF), 采用通道连接的方式使单帧特征能融合完整的多帧时域特征, 从而弥补单帧特征在时域信息上的缺失, 并且单帧特征在融合特征中占据更多的特征维度, 确保单帧特征可作为融合特征中的主导特征.该融合特征通过上采样网络输出最终融合特征图.
1.1.1 低分辨率输入策略
为了减少多帧网络因处理连续的多帧图像增加的计算量, 本文采用多分辨率策略, 以低分辨率的连续图像作为多帧网络的输入, 以高分辨率的单帧图像作为单帧网络的输入.下文表征图像输入分辨率在逐步增大的情况下, 对于神经网络中的网络计算量产生的影响.以经典的50层残差网络(Residual Network with 50 Layers, ResNet50)[10]作为测试对象, 选取3种常规分辨率图像作为输入, 图像输入分辨率以320× 180为基准按倍数进行线性增长.图像输入分辨率对网络计算量和帧数影响如表1所示.
| 表1 图像输入分辨率对网络计算量和帧数的影响 Table 1 Influence of input resolution on network computation and frames per second |
从表1可知, 图像输入分辨率的增长对于网络计算量的增长并不是等价的线性增长关系, 而是按照指数的趋势增长.同时进一步研究发现, 网络层的通道数越多, 计算量的增长幅度越大.因此通过减少图像输入分辨率, 可有效减少网络计算量, 将这些节约的计算量换取应用更复杂、更深层次的网络结构, 从而弥补分辨率产生的图像细节上的损失.在聚焦于车道线这类语义分割问题时, 降低分辨率也可淡化一些不重要的背景细节, 更凸显车道线与背景的差别.因此, 一定程度上降低分辨率是合理可取的.
1.1.2 骨架网络
由于本文在单帧网络中并行一个多帧网络, 为了减少引入多帧网络带来的计算量, 并拥有较优的网络性能, 本文分析现有轻量级神经网络后, 选取第二版高效空间金字塔网络(Second Edition of Effici-ent Spatial Pyramid Network, ESPNetV2)[11]作为多帧网络的骨架网络.相比图像级联网络(Image Cascade Network, ICNet)[12]、高效残差分解卷积网络(Efficient Residual Factorized Convolutional Net-work, ERFNet)[13]和第二版移动视觉卷积网络(Second Edition of Mobile Vision Convolutional Network, Mobile-NetV2)[14]等轻量级网络, ESPNetV2的每秒浮点运算次数(Floating-Point Operations per Second, FLOPs)降低至1/9~1/12, 准确率仅下降2%~4%.ESPNetV2网络是对高效空间金字塔网络(Effi-cient Spatial Pyramid Network, ESPNet)[15]的改进, 进一步优化ESPNet的卷积方式, 通过逐点群卷积[16]和空洞深度可分离卷积[17]减少网络的训练参数量, 同时保持原有类似于空间金字塔的网络结构[18], 提出高效空间金字塔模块(Extremely Efficient Spatial Pyramid, EESP).
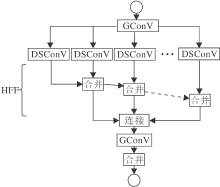
EESP模块主要基于分组卷积原理和空间金字塔理论, 首先通过逐点分组卷积(Group Convolution, GConV)对输入特征进行降维, 然后使用不同尺度的卷积核对低维特征进行深度可分离卷积(Depthwise Separable Convolution, DSConV)运算, 最后采用逐元素求和的方式拼接融合特征.模块具体结构如图2所示.
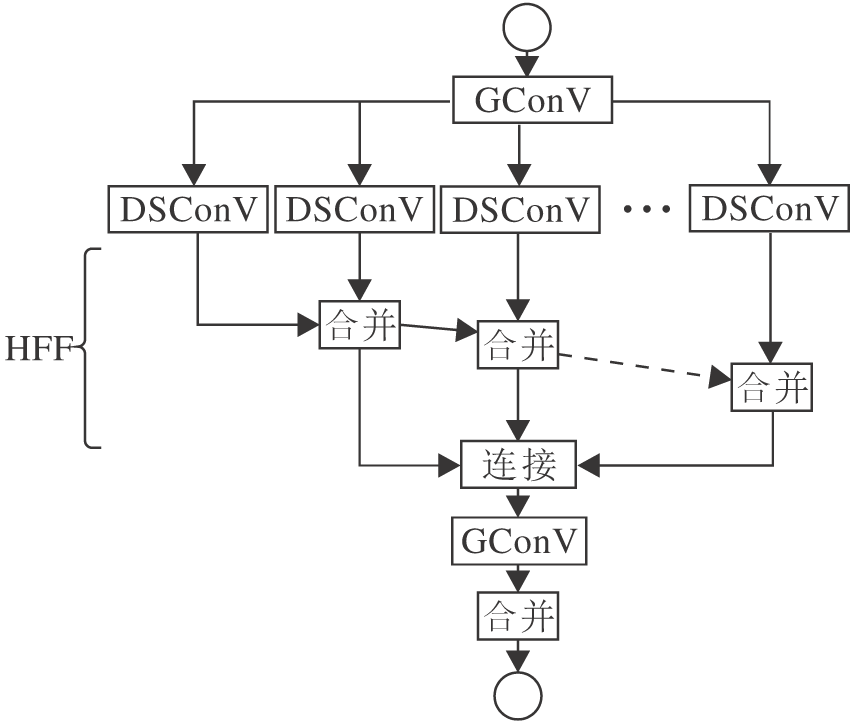 | 图2 EESP模块的结构Fig.2 Structure of EESP module |
EESP模块分别通过分组卷积和深度可分离卷积取代常规的卷积, 有效降低卷积运算的计算量.在层次特征融合模块(Hierarchical Feature Fusion, HFF)模块中采用不同尺度的膨胀卷积核, 对特征进行卷积操作, 并通过逐元素求和的方式融合不同感受野下的局部特征信息和全局特征信息, 扩大整个网络的信息接收域, 从而有效提升检测效果.同时EESP整体的模块网络结构类似于空间金字塔结构, 使网络具有更强的语义信息, 并丰富感受野[19].
基于EESP网络模块构建ESPNetV2骨架网络, 在经过初始卷积后, 将骨架网络结构划分为4个空间级别, 每个空间级别都采用一个或多个EESP网络模块.本文在分析原网络结构后发现, 原始的骨架结构在第2部分和第3部分对同一尺度运用多个EESP模块, 大量重复的卷积操作会重复性地提取特征信息, 造成一定的信息冗余.因此本文进一步压缩骨架网络中第2部分和第3部分的EESP模块数量, 最终分别采用2个和4个EESP模块数量, 进一步减少多帧网络的计算量.最终的多帧网络的骨架网络结构如表2所示, 每个时序图像都会经过该骨架网络提取特征, 得到多帧特征序列.
| 表2 多帧网络骨架网络结构 Table 2 Backbone network structure of multi-frame network |
1.1.3 多帧特征融合模块
当通过多帧网络获得特征序列时, 如何从特征序列中提取时域变化的目标特征信息, 有效忽略变化不大的背景特征, 即如何有选择性地抽象特征对分割目标来说十分重要.为此本文研究RNN的特点, 引入LSTM网络模块, 选择性地获取目标特征信息.LSTM作为一个特殊形式的RNN, 利用3种不同的门函数提取长时特征, 分别为控制新信息加入的输入门、控制信息通过的遗忘门及决定信息输出的输出门.
本文采用LSTM的门机制处理多帧特征序列, 提取多帧特征序列中依时域变化的目标特征信息, 同时遗忘不重要的特征信息.然而LSTM是全连接形式的网络模型, 会导致额外耗时, 对此本文采用He等[10]提出的ConvLSTM结构, 运用卷积运算取代每个门函数中矩阵乘法运算, 并以此捕捉时序特征中潜在的时空特征.通过卷积也更有效和易于理解图像的特征提取, 有效提升图像特征处理速度及对特征图的适应性.一个常规的ConvLSTM记忆单元在t时刻的计算如下:
其中,
1.2.1 骨架网络
由于当前时刻的单帧特征需要作为主导特征, 所以单帧网络的骨架网络需要使用复杂度更高的网络结构, 用于提升特征的泛化学习能力和表征能力.本文选取ResNet[10]、VGG16-BN[20]、GoogleNet[21]等经典神经网络作为单帧网络的骨架网络, 去除网络结构中的全连接层.
由于不同骨架网络的输出特征图的通道数有所不同, 为了保持单帧网络的输出特征图与多帧网络的输出特征图有相同尺度及等比的通道数, 同时强化单帧特征在不同尺度下的特征信息, 在单帧骨架网络之后增加多尺度特征增强结构[18], 在3个不同尺度上进行特征信息增强.使用该增强结构后, 每个空间位置能在不同尺度空间查看局部环境, 进一步扩大整个网络的信息接收域, 提升车道检测效果.
1.2.2 单帧特征与多帧特征融合模块
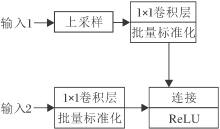
为了有效融合通过并行网络提取的单帧特征与多帧特征, 本文设计ConvLSTM融合模块(CLF).如图3所示, CLF首先将多帧特征图进行上采样, 使特征图尺寸恢复到与单帧特征相同的大小.再分别对单帧特征与多帧特征使用1× 1的卷积核, 用于平滑特征.然后使用通道连接的方式融合多帧特征与单帧特征, 其中单帧特征将在融合特征中占据更多的特征维度, 并作为主导特征.最后对融合特征使用一个线性整流函数(Rectified Linear Unit, ReLU)[22]进行激活, 减少参数之间的相互依存关系.
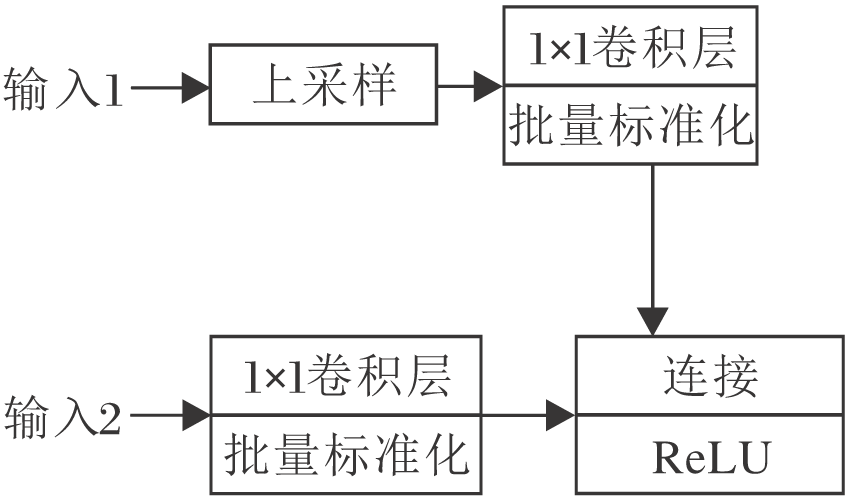 | 图3 CLF融合模块的结构Fig.3 Structure of CLF fusion module |
上采样网络作为解码网络, 利用底层特征通过上采样的方式恢复目标信息.本文的上采样网络采用与LaneNet[3]相同的解码结构.LaneNet由4层卷积层和1个上采样层组成.上采样层通过双线性插值的上采样算法对采样后的特征图进行平滑处理, 最终将融合特征图放大到与输入特征图相同的尺寸, 并将此特征映射作为结果特征输出.
本文网络训练以TuSimple道路数据集为基础, 并对数据集进行相应的数据增强.TuSimple道路数据集共包含6 570组车道线图像序列, 每组序列包含在1 s之内采集的20幅连续帧图像, 所有图像都是基于车的前景视角采集而来.每帧图像原始分辨率为1 280× 720, 对于每组图像序列, 只有最后的第20帧图像标记真实车道线标签.TuSimple数据集将其中3 626组图像序列作为训练集, 2 944组图像序列作为测试集, 都包含白天的不同时间段、不同的车道数量及各种交通状况, 在一定程度上符合现实的道路情况.
为了避免过拟合现象, 同时提升数据集的表现, 对数据集进行数据增强处理.依据本文的网络结构, 针对每组图像序列, 使用不同的间隔在这20幅连续帧图像上采样4幅图像, 并结合标签图像组成1组训练数据.通过不同间隔的采集可模拟车辆在不同车速下摄像头采集的道路图像.本文分别采用1、2、3、4、5帧为间隔作为采样基准, 以此标准应用于每组图像序列, 连续帧图像的采样方式如表3所示.
| 表3 连续帧图像的采样方式 Table 3 Sampling method of continuous frame image |
经过上述处理, 得到原数据集5倍的图像序列数据.为了进一步提升训练数据的多样性, 运用图像水平翻转进行数据增强.针对原数据集上训练集与测试集中0.55∶ 0.45的比例情况, 采用更常用的0.8∶ 0.2的比例构建训练集与测试集.最终构建包括51 260组图像序列的训练集以及包含12 820组图像序列的测试集.
为了测试本文网络是否有效应对车道遮挡、光线阴影等复杂场景, 进一步从测试集挑选540组复杂图像序列作为后续实验的复杂测试集, 包含435组车道遮挡的图像序列和105组光线阴影的图像序列.此外, 为了提高训练速度, 最终选取640× 360作为基础分辨率.
在本文的并行网络结构确立之后, 设计合理的训练策略也是神经网络训练的一个关键环节.为了使网络参数通过不断更新、学习, 有效提取车道线模型特征, 逐渐缩小与真实标签的误差值, 最终达到车道线与背景分离的效果, 本文制定训练策略如下.
1)考虑网络参数初始化问题.网络参数初始化的方法主要有网络预训练参数初始化、随机参数初始化和固定值参数初始化.由于本文网络采用并行网络结构设计, 在初始化参数策略上也会有所不同.对于单帧网络的骨架网络, 采用该网络模型在ImageNet数据集上的预训练参数进行参数初始化.对于多帧网络中的卷积层, 应用文献[23]中的kaiming正态分布初始化算法对卷积层参数进行初始化.对于多帧网络结构中的批量标准化(Batch Normalization, BN)层, 依据文献[22]的初始化方法, 对权重值和偏置值分别使用固定1填充和固定0填充.
2)本文网络采用随机梯度下降算法(Stochastic Gradient Descent, SGD)作为优化算法, 将初始学习率设置为0.03, 权值衰减设置为5e-5, 动量参数设置为0.9.学习率策略选择Poly作为调整学习率的方式, 对数函数使学习率按照周期数进行衰减, 避免在神经网络训练后期出现因学习率过大导致难以收敛的问题.
3)本文网络的损失函数采用加权交叉熵损失函数(Weighted Cross-Entropy), 交叉熵损失函数在图像分类和分割问题上都有可观的效果.交叉熵损失函数按照分类的思想先对分割图像的每个像素进行类预测, 然后将预测结果与标签像素通过对比计算得到单一像素的损失值, 最后对所有像素的总损失值求取平均值.由此每个像素都能被网络学习并不断改善输出结果, 但这样的损失函数并不能直接用于处理车道线分割问题.这是由于在实际图像中, 背景像素远多于车道线像素, 导致在学习过程中类别不均衡, 使最终的损失值由背景这一类别主导, 车道线特征很难能被网络学习.针对这一问题, 对不同类别通过加权的方式可以明显改善学习效果.对背景类的损失值乘上一个较小权重值, 可极大地减少背景类对于损失值的影响, 否则, 对目标类乘上一个较大权重值, 增加目标类被学习的概率.损失函数的定义如下:
其中, x表示分割的目标类别, w(x)表示当前类别的加权值,
本文网络基于Pytorch1.1实现, 运行环境为64位的Ubuntu18.04系统.在计算机硬件配置方面:处理器为Intel9700KCPU@4.50 GHz; GPU为GeForce GTX-1080Ti; 显存为11GB.
为了全面评估本文网络性能, 实验采用的评价指标如下.
准确率(Accuracy).测量正确分类的像素数占总体像素数的比例关系值:
其中, TP表示正确预测为道路标签的像素数量定义为真实正样本, TN表示正确预测为道路标签的像素数量定义为真实负样本, FN表示错误地将道路标签预测为背景标签的像素数量定义为虚假负样本, FP表示错误地预测背景标签为道路标签的像素数量定义为虚假正样本.
准确率无法准确描述实际情况下的车道线检测精度, 这是由于在普通的道路环境中, 绝大多数为背景像素而非车道线像素, 这种类别的极度不平衡导致在预测车道线像素较少的图像中, 即使全部预测为背景标签, 也会出现较高准确率.所以针对车道线这单一类别, 本文应用F1度量测算网络模型的综合性能.F1度量(F1-measure)作为一种衡量模型精确度指标, 将精确率(Precision)和召回率(Recall)通过加权平均评价网络的综合性能, 具体计算如下:
3.3.1 骨架网络选择
为了进一步验证本文网络在使用其它单帧骨架网络情况下依然发挥作用, 选取VGG16-BN、GoogleNet、ResNet32、ResNet50作为单帧网络的骨架网络, 并进行对比实验, 实验结果如表4所示.由表可知, 不同骨架网络对于检测效果有一定程度的影响, ResNet50的各项指标值最高, VGG16-BN和Res-Net32次之, GoogleNet最低.
| 表4 不同骨架网络的实验结果对比 Table 4 Experimental result comparison of different backbone networks |
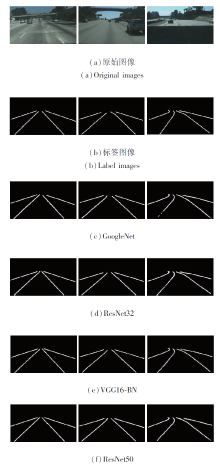
图4为不同骨架网络的主观检测结果, 由图可知, ResNet50、VGG16-BN的主观检测效果较优, Res-Net50的边缘更精细.GoogleNet检测效果较差, 边缘较粗糙, 出现车道线断裂的情况.
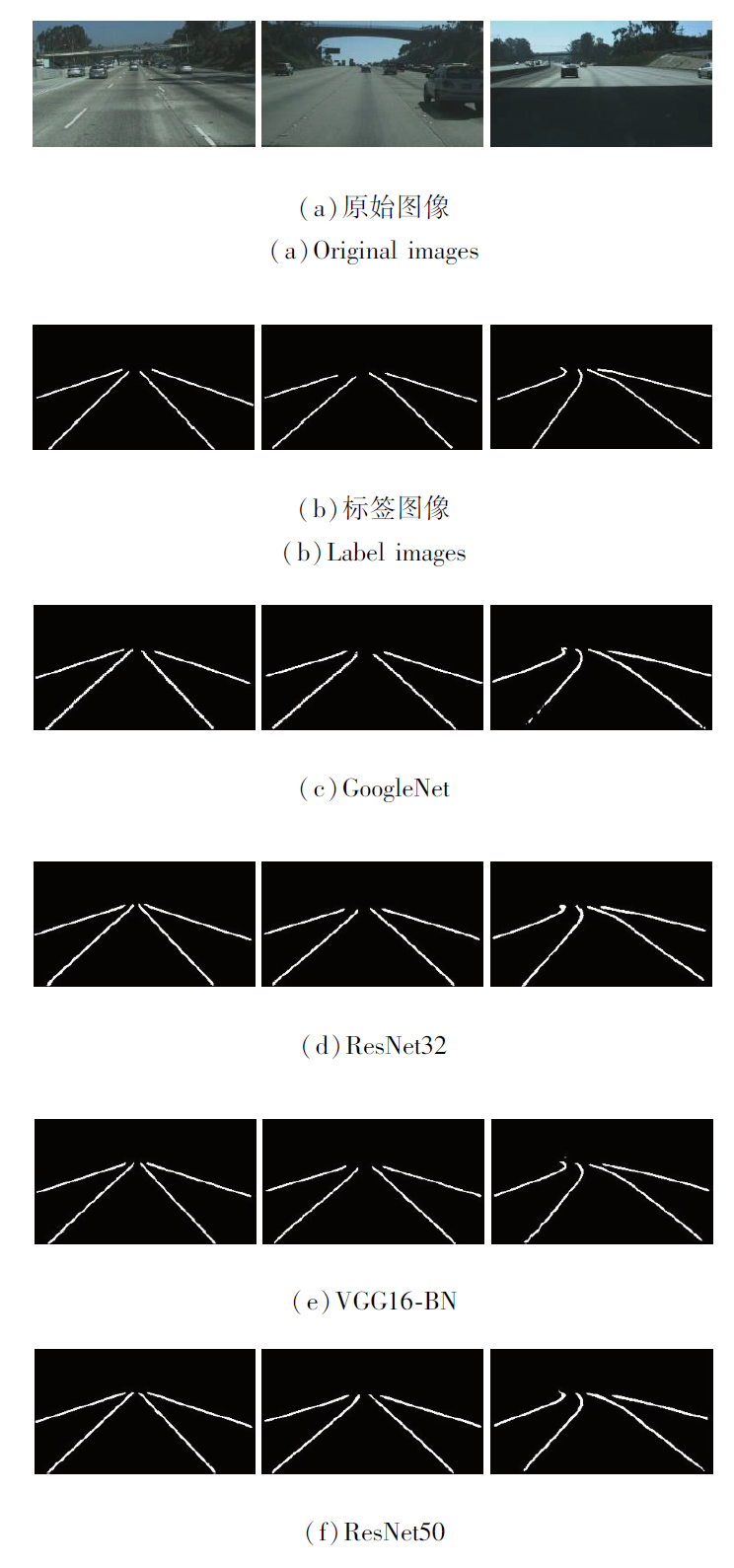 | 图4 不同骨架网络的主观检测结果Fig.4 Subjective results of different backbone networks |
由此可见, 骨架网络选取会影响本文网络的整体性能, 相比VGG16-BN, ResNet50效果提升并不是特别明显且帧率较低, 所以最终本文选择使用VGG16-BN作为单帧网络的骨架网络.
3.3.2 网络结构测试
本文针对TuSimple数据集进行增强处理, 按照0.8∶ 0.2的比例随机划分数据集, 但随机划分存在一定的偶然性.为了消除偶然性, 实验采用5折交叉验证的方式进行多次测试.将原始数据集分为5组, 每组子集数据分别作为1次测试集, 其余的4组子集数据作为训练集, 最终得到5个模型结果.通过计算这5个模型在各自测试集上的结果并求平均值, 以此作为本文网络的性能指标.在交叉验证时, 选择640× 360作为单帧网络的输入图像分辨率, 320× 180作为多帧网络的输入图像分辨率.
本文网络交叉验证结果如表5所示, 实验数据相对稳定, 各项参数的浮动范围都在0.005以内, 表明本文网络的稳定性.
| 表5 本文网络的交叉验证结果 Table 5 Cross validation results of the proposed network |
为了测试本文多帧网络对单帧网络的性能影响, 进一步采用消融实验对网络结构进行综合测试, 分别测试仅使用单帧网络、仅使用多帧网络、使用本文网络, 测试结果如表6所示.
| 表6 不同网络结构在测试集上的实验结果 Table 6 Results of different network structures on test set |
由表6可见, 相比多帧网络和单帧网络, 本文网络在各个参数上都取得更优结果, 这客观验证本文网络结构的有效性, 表明单帧网络在增加多帧网络后可有效提高网络性能.
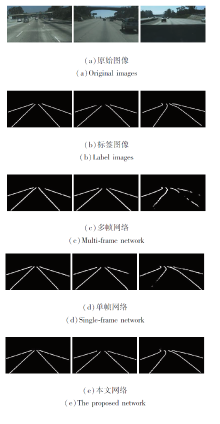
图5为3种网络在无车道线被遮挡、存在车道线被遮挡、光线阴影这3种不同场景下的主观检测结果.
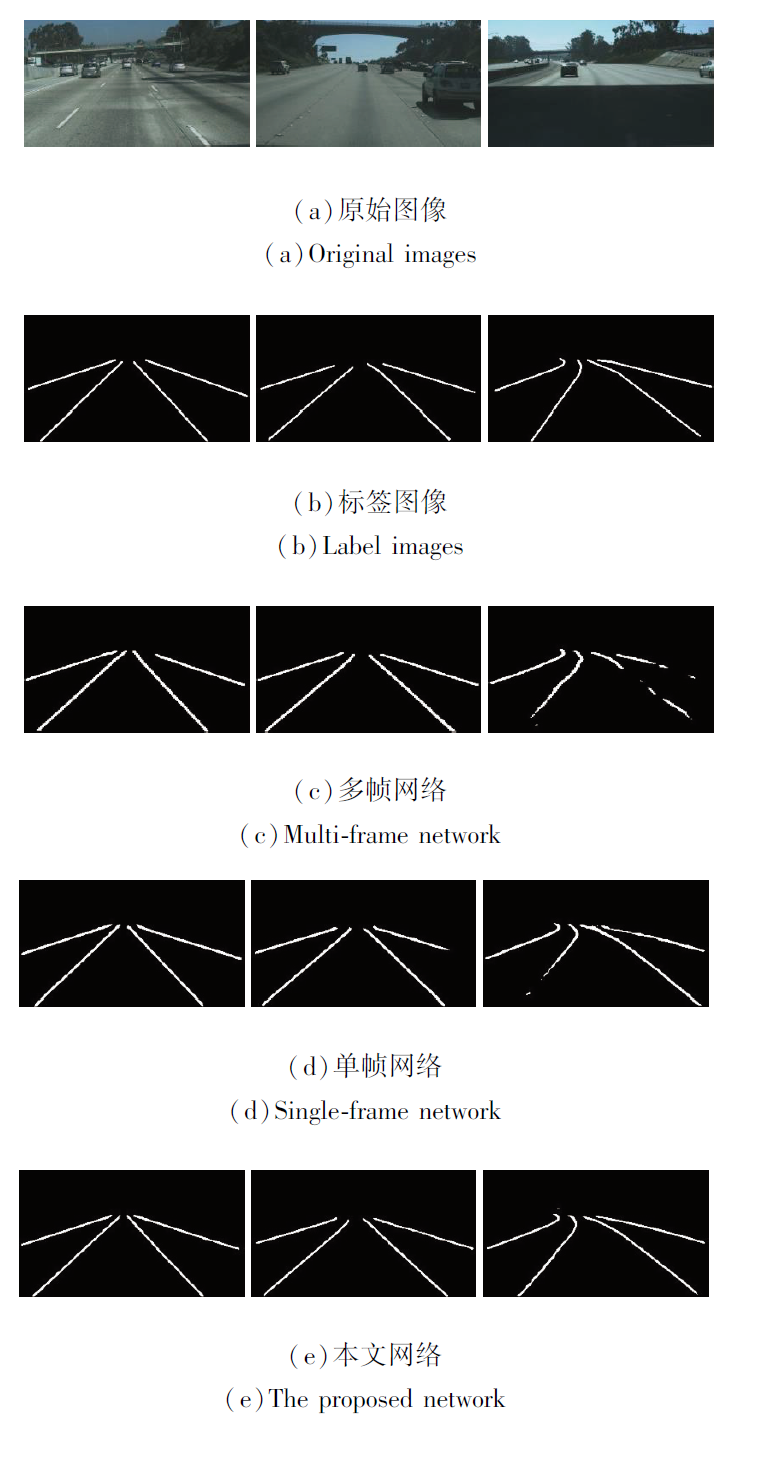 | 图5 不同网络结构的主观检测结果Fig.5 Subjective results of different network structures |
如图5所示在左侧无车道线被遮挡的图像中, 3种网络结构都有效检测车道线, 但本文网络的边缘细节更顺滑.在中间存在车道线被遮挡的图像中, 多帧网络和本文网络因为图像序列的优势有效检测被遮挡的车道线, 而单帧网络在遮挡处出现车道线断裂.在右侧光线阴影的图像中, 多帧网络和单帧网络都出现车道线不连续的情况, 本文网络依然能有效检测车道线.
依据上述的实验数据, 由于多帧网络采用轻量级的骨架网络, 对车道线特征学习的能力不强, 导致车道线不连续, 边缘质量较差.单帧网络虽然各项参数优于多帧网络, 但在车道遮挡、光线阴影等复杂场景下, 缺乏对车道线特征的时域感知能力, 在遮挡处出现车道线不连续的情况.本文网络在单帧网络的基础上增加多帧网络模块, 不仅加强单帧网络对复杂场景的泛化学习能力和表征能力, 而且融合多帧网络赋予的时域上下文特征, 在短时遮挡的情况下, 依据RNN特征得到被遮挡的车道线特征.
从上述实验结果可看出, 相比独立的单帧网络和多帧网络, 本文网络在主客观评价上都取得更优的检测效果.
在网络计算时间上, TuSimple数据集是一个片段连续但整体离散的图像序列集, 在获取多帧时域特征时需要计算全部多帧时序图像.计算全部多帧图像的特征耗时54.4 ms.在现实情况下, 多帧网络中前3帧的特征信息可经过上一次网络推导得到, 所以除第1次需要对全部多帧时序图像计算特征以外, 之后仅需计算当前帧的特征.在图像序列是整体连续的情况下需要的计算时间仅为42.1ms, 相比独立的单帧网络所需的计算时间增加9 ms, 不到26%.
3.3.3 多分辨率选择
在多帧网络中使用低分辨图像输入策略以降低网络计算量.为了测试不同的输入图像分辨率对整体网络的性能造成的影响, 在保持单帧网络输入图像分辨率为640× 360的情况下, 选取3种不同的分辨率作为多帧网络的输入图像分辨率, 具体结果如表7所示.
| 表7 不同输入分辨率的实验结果对比 Table 7 Experimental result comparison with different input resolutions |
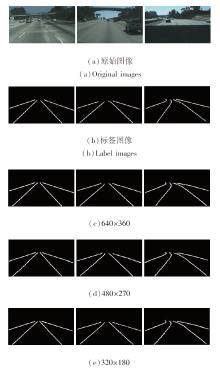
由表7可知, 降低多帧网络的输入分辨率会略微降低网络检测效果, 但有效减少多帧网络的运行时间, 提升网络计算帧数.降低输入分辨率会使边缘采样精细程度下降, 较远距离的车道线边缘更粗糙, 导致整体精度稍微下降.
图6为不同输入分辨率下的主观检测结果.由图中检测图像对比可看出, 主观视觉差距并不明显.鉴于主客观评价, 所以最终本文选择320× 180作为多帧网络的输入分辨率.本节实验也进一步说明多帧网络的性能优劣对整体并行网络具有一定程度的正向影响力, 优化多帧网络性能也能提升本文的并行网络性能.
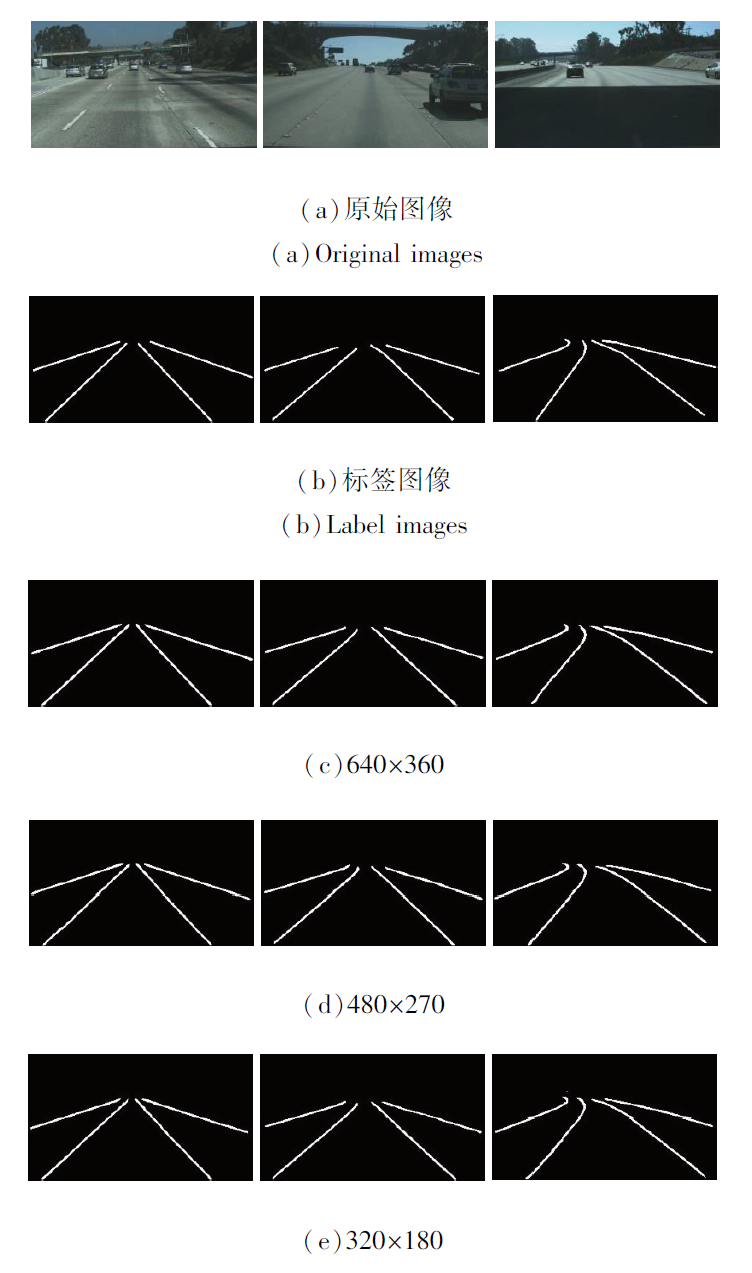 | 图6 不同输入分辨率下的主观检测结果Fig.6 Subjective results with different input resolutions |
为了进一步评估本文网络, 选取多个同样采用VGGNet作为骨架网络的现有神经网络进行性能对比, 包括SegNet[1]、UNet[2]、LaneNet[3]、采用Conv-LSTM的SegNet(SegNet-CL)[7]和采用ConvLSTM的UNet(UNet-CL)[7].排除骨架网络的性能因素, 以便能够更好地评估本文网络与其它基于单帧检测的神经网络和基于多帧检测的神经网络的性能.上述网络都采用相同的训练集进行训练, 并分别使用相同的整体测试集及带有车道线遮挡的复杂测试集进行测试, 实验结果分别如表8和表9所示.
| 表8 各网络在TuSimple测试集上的性能对比 Table 8 Performance comparison of different networks on TuSimple test set |
| 表9 各网络在复杂测试集上的性能对比 Table 9 Performance comparison of different networks on complex test set |
由表8可知, 对比现有多个单帧检测的神经网络, 在时间复杂度少量增加的情况下, 本文网络在精确率、召回率和F1度量上提高2%左右.由表9可看出, 在数据集难度增大的情况下, 各网络的性能指标都有一定程度的下降, 但本文网络的精确率依然较高, 这进一步说明本文网络的优势.其原因在于图像序列中车道线信息相对连续且变化较小, 但整体的背景变化却更动态、更复杂.面对遮挡, 单帧检测较难准确检测其中的车道线特征, 通过多帧网络, 针对车道线这类连续且变化较小的特征将有更高的概率被检测到.
图7为各网络的主观检测结果对比.由实际检测效果分析可得, 本文网络在图7中第2列到第6列这类包含车道线突发被遮挡的情况下, 依然可有效去除遮挡的影响.对于图7中第4列和第6列这类明暗场景变化的复杂场景, 由于多帧特征增强单帧特征的语义信息, 因此也取得更优的检测效果.
 | 图7 各网络的主观检测效果Fig.7 Subjective result comparison of different networks |
基于视频流的车道线检测网络SegNet_ConvLSTM[7]、UNet_ConvLSTM[7]由于对每帧图像都使用相同网络结构进行特征提取, 弱化最关键的当前帧的特征信息, 产生较多的冗余特征, 在使用RNN融合特征时需要处理过多的冗余特征, 这导致精确率下降.本文网络通过赋予单帧网络与多帧网络不同的信息流并采用不同复杂度的骨架网络, 使多帧网络学习多帧时域语义特征, 单帧网络学习单帧图像的空域语义特征, 不仅有效减少冗余特征, 也加强网络的解释性, 更有效地提取车道线特征.由表8和表9的结果可知, 相比基于视频流的车道线检测网络, 本文网络在整体测试集上的精确率、召回率和F1度量都有1%左右的提升, 在只包含车道线遮挡的复杂测试集上, 本文网络的性能提升更明显.
本文提出基于图像序列的车道线并行检测网络.在基于原有的单帧网络的基础上增加并行的多帧图像提取网络, 利用RNN模块对包含当前帧及过去多帧图像的序列进行时域特征、环境上下文特征的提取和融合, 不仅有效弥补单帧网络对时域上下文信息的缺失, 也辅助增强车道线语义信息.由于当前帧图像是作为最重要的时序帧, 所以相对多帧网络, 单帧网络采用复杂度更高的骨架网络, 提升当前帧特征的泛化学习性能和表征能力.实验表明, 本文网络引入多帧网络模块, 相比仅使用单帧网络的性能指标更优, 由于对多帧网络采用低分辨率策略、轻量级的网络结构及复用过去帧的特征图, 使增加多帧特征模块的耗时仅增加25%左右.本文网络虽能在一定程度上弥补单帧网络缺失的时序特征信息, 但仍无法适用于车道线长时间被遮挡、路面光线阴影较多等情况.在后续研究中, 将在多帧网络与单帧网络的特征提取融合及优化长时遮挡等复杂实际场景上展开进一步研究, 使单帧目标的空域特征信息与图像序列的时域信息更加互补.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|