

{kind=link}
{kind=link}
{kind=link}
基于特征优选和字典优化的组稀疏表示表情识别
[谢惠华1, 2  , 黎明
, 黎明1, 2 , 王艳2 , 陈昊1, 2 ]
, 黎明, 王艳, 陈昊]
|
|



作者简介:

谢惠华,硕士研究生,主要研究方向为图像处理、模式识别.E-mail:xiehuihua97@126.com.

王 艳,博士,讲师,主要研究方向为图像处理、模式识别.E-mail:vicie414@126.com.

陈 昊,博士,副教授,主要研究方向为进化算法、图像处理、模式识别等.E-mail:chenhaoshl@nchu.edu.cn.
针对在小样本人脸表情数据库上识别模型过拟合问题,文中提出基于特征优选和字典优化的组稀疏表示分类方法.首先提出特征优选准则,选择相同类级稀疏模式、不同类内稀疏模式的互补特征构建字典.然后对字典进行最大散度差优化学习,使字典在不失真重构特征的同时具有较高鉴别能力.最后联合优化后的字典进行组稀疏表示分类.在JAFFE、CK+数据库上的实验表明,文中方法对样本减少具有鲁棒性,泛化能力较强,识别精度较优.
AboutAuthor:
XIE Huihua, master student. Her research interests include image processing and pattern recognition.
WANG Yan, Ph.D., lecturer. Her research interests include image processing and pattern recognition.
CHEN Hao, Ph.D., associate professor. His research interests include evolutionary algorithms, image processing and pattern recognition.
To solve the over-fitting problem of recognition model on small sample facial expression database, a group sparse representation classification method based on feature selection and dictionary optimization is put forward. Firstly, the feature selection criterion is proposed, and the complementary features of same class-level sparse mode and different intra-class sparse mode are selected to build a dictionary. Then, the dictionary is learned by maximum scatter difference optimization to reconstruct features without distortion and acquire a high discriminative ability. Finally, the optimized dictionary is combined for group sparse representation classification. Experiments on JAFFE and CK+ databases show that the proposed method is robust to sample reduction with high generalization ability and recognition accuracy.
本文责任编委 叶东毅
Recommended by Associate Editor YE Dongyi
表情识别提供一种行为方式, 用于评估情绪和社交互动, 广泛应用于机器人技术、人机界面、情绪处理、疲劳检测等领域.
Corneanu等[1]指出, 面部表情大致可分为6类:生气、厌恶、恐惧、高兴、伤心、惊奇.识别过程包括3个关键部分:人脸检测定位、表情特征提取、分类器设计.Poursaberi等[2]和Wang等[3]使用K近邻(K-Nearest Neighbor, KNN)进行表情识别, 此分类器衡量测试样本与训练集上各类样本的距离并进行分类.为了解决遮挡表情的识别, Jiang等[4]和Ouyang等[5]采用稀疏表示分类(Sparse Representation Classification, SRC), 对遮挡表情进行建模, 完成分类.SRC模拟生物视觉感知系统的工作机制, 从一个超完备的字典中找到尽可能少的原子对目标样本进行线性表示, 因此对遮挡具有鲁棒性.Lekdioui等[6]、Zhang等[7]和Vasanth等[8]提出支持向量机(Supp-ort Vector Machine, SVM)分类器, 通过非线性变化将样本从原始的低维不可分空间映射到高维可分空间, 在高维空间中进行分类.近来关于深度学习的表情识别研究受到越来越多的关注, Mellouk等[9]和Lopes等[10]提出深度学习架构, 融合特征提取与分类器设计, 进行表情识别.
尽管上述表情识别技术取得一定效果, 但是在小样本数据集上进行表情识别时, 数据量不足以支撑模型, 容易出现模型过拟合问题.解决过拟合常用的方法是增加样本的数据量, 然而这却难以实现.
多任务学习是联合多个任务同时学习, 用于增强模型表示和泛化能力.组稀疏表示分类(Group SRC, GSRC)[11, 12]通过添加正则化约束, 可有效缓解小样本中模型过拟合问题.组稀疏表示的关键因素之一是字典, 字典的好坏直接影响模型性能.Sun等[13]和Xie等[14]联合由图像构建的公共字典和由表情图像与中性图像间差异构建的误差字典, 进行表情识别.Huang等[15]联合基于不同表情构建的稀疏网络字典进行识别.Dapogny等[16]通过联合静止图像构建的字典和不同帧之间的时间间隔信息进行表情识别.
上述方法虽然取得较优结果, 但因其直接基于图像构建字典, 字典存在信息冗余、噪声及不利于分类的信息等问题.针对这些问题:Moeini等[17]联合表情特征字典和原始图像字典进行表情识别; Zhang等[18]提取图像纹理特征和几何特征, 基于这些特征构建字典, 并联合特征字典进行表情识别; Jia等[19]联合不同表情强度的局部二值模式(Local Binary Pattern, LBP)特征字典进行表情识别.此类方法提取特征字典, 虽然在一定程度上消除由原始图像构建字典的冗余, 但字典不具有较高鉴别能力, 表情识别效果不佳.
针对上述问题, 本文提出基于特征优选和字典优化的组稀疏表示分类方法.对组稀疏表示的特征字典进行最大散度差优化学习(Maximum Scatter Difference Optimization Learning, MSDOL), 在有监督的情况下对字典逐类优化, 使其具有不失真的重构特征能力, 并对稀疏系数添加最大散度差准则约束, 使同类样本的字典更靠近, 异类样本字典之间的区别更大, 提高字典的鉴别能力.同时, 现有的组稀疏表示表情识别方法缺乏一个特征筛选准则, 因此难以评估参与联合的特征字典是否适合此模型, 以及特征字典间是否能够提供互补信息.本文提出特征优选准则, 对参与联合的特征进行预筛选, 选择具有相同类级稀疏模式、类内存在不同稀疏模式的互补特征构建字典.
对于利用C类训练样本判断一个测试样本类别问题, 先给定字典
D=[D1, D2, …, DC]∈ Rm× N,
训练样本总数
y=Dw+nε ∈ Rm,
其中, w为y在字典D上的编码系数, nε 为y本身存有缺陷产生的噪声.w越稀疏, 表明字典D稀疏重构y需要的原子越少, 编码效率越高.
理想情况下, 若y属于类别j, j=1, 2, …, C, w中只有与j同类的幅值不为0, 其余项均为0, 即
实际情况并非如此, 因此需对w添加稀疏约束l0范数, 使其在不失真重构y的同时尽可能稀疏, 接近理想情况, 数学定义如下:
$\hat{w}=\min {{\left\| \left. w \right\| \right.}_{0}}, s.t.{{\left\| \left. y-Dw \right\| \right.}_{2}}\le \varepsilon , $
其中ε 为极小值.可将上式转化为拉格朗日算子进行求解:
$\hat{w}=\underset{w}{\mathop{\min }}\, {{\left\| \left. y-Dw \right\| \right.}_{2}}+\lambda {{\left\| \left. w \right\| \right.}_{0}}.$
因为${{\left\| \left. w \right\| \right.}_{0}}$非凸, 求解上式是个NP-hard问题, 不适合直接求解.Zhang等[20]指出如果解足够稀疏, 可用l1范数代替l0, 即
$\hat{w}=\underset{w}{\mathop{\min }}\, {{\left\| \left. y-Dw \right\| \right.}_{2}}+\lambda {{\left\| \left. w \right\| \right.}_{1}}.$ (1)
求解式(1)得到编码系数
$identify(y)=\underset{j=1, 2, \ldots , C}{\mathop{\text{min}}}\, {{\left\| \left. y-D{{{\hat{w}}}_{j}} \right\| \right.}_{2}}.$
GSRC是把稀疏表示扩展到组字典, 将目标样本在组字典上进行稀疏表示.K个字典构成的组稀疏表示分类模型如下:
其中, yi表示测试样本在任务i=1, 2, …, K下的输出向量, Nε 表示噪声矩阵.组稀疏表示是将按行合并K个任务的输出向量
在组字典上联合稀疏表示, 联合编码系数
其中
$\widehat{W}=\underset{w}{\mathop{\text{min}}}\, \left\{ \frac{1}{2}\overset{K}{\mathop{\underset{i=1}{\mathop{\sum }}\, }}\, \left\| \left. {{y}^{i}}-{{D}^{i}}{{w}^{i}} \right\| \right._{2}^{2} \right\}$ (3)
拟合联合编码系数.由SRC可知, l1范数可保证系数的稀疏性, l2范数可防止模型过拟合, 提高模型的泛化能力.本文在l1范数的基础上, 对系数添加l2范数, 即混合范数l1, 2, 既保证系数的稀疏性, 也可避免模型过拟合问题.因此, 式(3)转化为
$\widehat{W}=\underset{w}{\mathop{\text{min}}}\, \left\{ \frac{1}{2}\overset{K}{\mathop{\underset{i=1}{\mathop{\sum }}\, }}\, \left\| \left. {{y}^{i}}-{{D}^{i}}{{w}^{i}} \right\| \right._{2}^{2}+\lambda {{\left\| \left. W \right\| \right.}_{1, 2}} \right\}.$ (4)
通过交替方向乘子法(Alternating Direction Method of Multipliers, ADMM)[21]求解式(4), 求得
$identify(y)=\underset{j=1, 2, \ldots , C}{\mathop{\text{min}}}\, \frac{1}{2}\overset{K}{\mathop{\underset{i=1}{\mathop{\sum }}\, }}\, \left\| \left. {{y}^{i}}-{{D}^{i}}w_{j}^{i} \right\| \right._{2}^{2}.$ (5)
组稀疏表示模型具有对样本数量鲁棒的优势, 其中, 用于组稀疏表示的字典在图像分类中具有关键作用.黎明等[22]指出基于表情特征构建的字典比直接基于图像信息构建的字典更适合表情分类, 但如何选择有效的特征构建字典及从这些特征中挖掘本质的分类信息构建字典是问题的关键, 因此本文从特征优选和字典优化两方面改进组稀疏表示分类方法.
为了选取合适的特征, 首先分析影响组稀疏表示分类方法精度的主要因素.Zhang等[20]指出, 在由单个特征构建字典的稀疏表示模型中, 若编码系数的非零项越集中在某一类, 判为这一类的可能性越高, 识别效果越优.扩展到多特征字典, 还需满足不同特征能提供互补信息, 即在同个测试样本下, 不同特征的编码系数应具有相同的类级稀疏模式、不同的类内稀疏模式, 也就是说不同特征的编码系数在正确类应尽可能交叉互补.因此选择特征的编码系数需具备如下条件.
1)相同的类级稀疏模式.编码系数的非零项是否集中在正确类(测试样本的类别)c中, 以及集中程度, 可通过稀疏集中指数(Sparsity Concentration Index, SCI)判断, 系数wi的稀疏集中指数定义如下:
$SCI({{w}^{i}})=\left\{ \begin{array}{* {35}{l}} \frac{C}{C-1}\left[ \underset{j=1, 2, \ldots , C}{\mathop{\text{max}}}\, \left( \frac{{{\left\| \left. w_{j}^{i} \right\| \right.}_{1}}}{{{\left\| \left. {{w}^{i}} \right\| \right.}_{1}}} \right)-1 \right], & j=c \\ 0, & j\ne c \\ \end{array} \right.$
2)不同的类内稀疏模式.在正确类中, 编码系数的非零项分布在不同的位置上, 说明由这2个特征构建的字典交叉互补.衡量2个向量之间的分布关系最简单的操作就是对2个向量进行逻辑运算, 其中逻辑或具有从左向右的关联性, 最符合需求, 因此本文通过对正确类的编码系数进行或运算, 获得2个编码系数的分布差异度, 以此探究特征的互补性.为了消除幅值的影响, 统一将系数中非零值替换成1.具体步骤如下.
算法 1 特征优选算法
输入 备选目标集合F={f1, f2, …, fK},
测试样本的特征向量Y=[y1, y2, …, yK].
输出 最优特征组合ffinal
for i=1 to K do
基于特征fi, 构建独立字典Di;
通过式(1)求取测试样本yi在字典Di上的编码系数wi;
计算wi稀疏集中指数value1=SCI(wi);
Fvalue1(i)=value1;
end for
Fvalue1降序排列, 选择前一半构成候选特征集fcandidate;
for i1=1 to
计算系数的分布差异度value2=or(
Fvalue2(i1, i2)=value2;
end for
Fvalue2降序排列, 选择最大值作为ffinal;
return ffinal
如何从选定的特征中构建最适合表情分类的字典, 需从字典的不失真重构力和分类判别力这2个方面进行约束.
若要保证分类正确性, 首先应保证字典能不失真重构特征.特征A在字典D上的稀疏表示为
$[{{A}_{1}}, {{A}_{2}}, \ldots , {{A}_{C}}]=[{{D}_{1}}, {{D}_{2}}, \ldots , {{D}_{C}}]\left[ \begin{matrix} X_{1}^{1} & \begin{matrix} X_{2}^{1} & \cdots \\ \end{matrix} & X_{C}^{1} \\ X_{1}^{2} & \begin{matrix} X_{2}^{2} & \cdots \\ \end{matrix} & X_{C}^{2} \\ \begin{matrix} \vdots \\ X_{1}^{C} \\ \end{matrix} & \begin{matrix} \begin{matrix} \vdots \\ X_{2}^{C} \\ \end{matrix} & \begin{matrix} {} \\ \cdots \\ \end{matrix} \\ \end{matrix} & \begin{matrix} \vdots \\ X_{C}^{C} \\ \end{matrix} \\ \end{matrix} \right]+{{N}_{\varepsilon }}, $
其中,
本文利用标签对每类特征单独进行学习.例如, 从第a类特征Aa中学习字典Da包括如下3个部分:由所有类重构特征Aa的总误差
$\left\| \left. {{A}_{a}}-\overset{C}{\mathop{\underset{b=1}{\mathop{\sum }}\, }}\, {{D}_{b}}X_{a}^{b} \right\| \right._{2}^{2}, $
由相同类系数
$\overset{C}{\mathop{\underset{\underset{b\ne a}{\mathop{b=1}}\, }{\mathop{\sum }}\, }}\, \left\| \left. {{D}_{b}}X_{a}^{b} \right\| \right._{2}^{2}.$
因此在不失真重构特征集的目的下, 字典优化的目标函数表示如下:
$r({{D}_{a}})=\left\| \left. {{A}_{a}}-\overset{C}{\mathop{\underset{k=1}{\mathop{\sum }}\, }}\, {{D}_{b}}X_{a}^{b} \right\| \right._{2}^{2}+\left\| \left. {{A}_{a}}-{{D}_{a}}X_{a}^{a} \right\| \right._{2}^{2}+\overset{C}{\mathop{\underset{\underset{b\ne a}{\mathop{b=1}}\, }{\mathop{\sum }}\, }}\, \left\| \left. {{D}_{b}}X_{a}^{b} \right\| \right._{2}^{2}.$(6)
为了使字典更具鉴别力, Yang等[23]提出将Fisher判别准则tr(Sw(X))-tr(SB(X))用于编码系数的判别性约束, 但由于类内散布矩阵的奇异性, tr(SW(X))-tr(SB(X))存在非凸且不稳定等问题, 因此本文对系数添加采用最大散度差[24]
p(X)=tr(SW(X)-∂ SB(X))
约束, 使同类字典样本更紧密、异类字典之间区别更大, 其中, ∂ 为非负常数, 用于平衡类内散度矩阵SW(X)和类间散度矩阵SB(X), 上述散度矩阵数学定义如下:
${{S}_{W}}(X)=\overset{C}{\mathop{\underset{j=1}{\mathop{\sum }}\, }}\, \underset{x\in {{X}_{j}}}{\mathop{\sum }}\, (x-mj){{(x-{{m}_{j}})}^{T}}, $
${{S}_{B}}(X)=\overset{C}{\mathop{\underset{j=1}{\mathop{\sum }}\, }}\, u{{m}_{j}}({{m}_{j}}-m){{({{m}_{j}}-m)}^{T}}, $
其中, mj为Xj中样本的均值, x为Xj中的样本点, m为所有样本的均值, numj为j类中的样本数目.
为了保证系数的稀疏性, 对其添加l1范数:
$f(X)=p(X)+{{\lambda }_{1}}{{\left\| \left. X \right\| \right.}_{1}}.$ (7)
结合式(6)和式(7), 字典优化的目标函数为
$J(D, X)=min\left\{ \overset{C}{\mathop{\underset{a=1}{\mathop{\sum }}\, }}\, ({{D}_{a}})+{{\lambda }_{2}}f(X) \right\}.$ (8)
求解式(8)可获得优化后的字典.具体算法步骤如下.
算法 2 MSDOL
输入 特征A, 迭代次数n, 最小误差ε
输出 字典Dfinal
从特征A中随机选M列, 构成初始字典D0;
iter=1;
while (iter< n||J(D, X)< ε ) do
固定字典D0, 迭代拟合式(7), 求得初始系数X0;
固定字典X0, 迭代拟合式(6), 求得字典Diter;
将Diter、Xiter代入式(8), 计算J(D, X);
for m=1 to M do
如果Diter(∶ , m)的幅值小于1e-6, 删除该列;
end for
iter=iter+1;
end while
return Dfinal
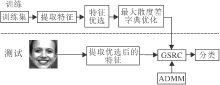
本文方法具体流程如图1所示.各部分介绍如下.
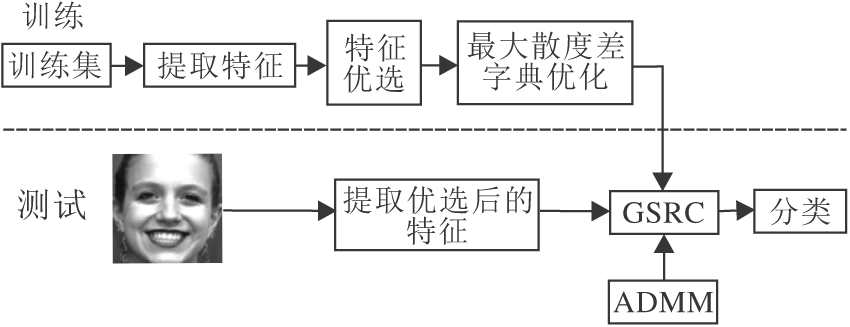 | 图1 本文方法流程图Fig.1 Flow chart of the proposed method |
1)提取表情特征.表情特征包括纹理特征和几何特征.纹理特征使用图像的强度信息, 根据提取的部位不同可细分为全局纹理特征和局部纹理特征.几何特征通过测量距离、形变等几何分量得到, 可分为全局几何特征和局部几何特征.
为了验证方法的全面性, 本文提取人脸表情的全局纹理特征(灰度共生矩阵(Gray-Level Co-occur-rence Matrix, GLCM)), 局部纹理特征(局部相位量化(Local Phase Quantization, LPQ)和LBP), 全局几何特征(主动形状模型(Active Shape Model, ASM)), 局部几何特征(方向梯度直方图(Histo- gram of Oriented Gradient, HOG)).
2)特征优选.若直接将特征集内所有特征进行组稀疏表示分类, 会增大计算负担, 因此需要先对特征进行优选, 选择最适合且能提供互补信息的特征组合.本文通过十折交叉验证, 选取各数据库最合适的特征组合, 具体为从1)中提取训练样本和测试样本特征, 组成特征集
f={fLBP, fLPQ, fGLCM, fASM, fHOG}
和测试样本向量
y=[yLBP, yLPQ, yGLCM, yASM, yHOG],
根据算法1选择最优特征组合ffinal.
3)基于最大散度差准则优化字典.为了提高编码效率和分类性能, 利用算法2对从2)中优选得到的特征进行优化增强, 获得字典Dfinal, 构建组字典.
4)组稀疏表示分类.提取待测样本的相关特征, 基于3)构建的组字典, 使用ADMM求解式(4), 获得联合系数, 最后根据式(5)求得待测样本的类别.
实验采用JAFFE、CK+数据库.JAFFE数据库包含213个面部表情图像, 包括愤怒、厌恶、恐惧、幸福、悲伤、惊奇、中性表情, 分别包含30、29、32、31、31、30、30幅图像.CK+数据库包含来自123位年龄在18~30岁的受试者的593个图像序列, 包括7类基本表情.选择每个序列的第一帧作为中性图像, 使用每个序列的最后一帧作为面部表情图像.
除分析不同训练样本数对方法的影响以外, 使用十折交叉验证, 重复实验10次, 取平均值作为最终结果.在验证之前, 对人脸图像进行预处理, 基于2只眼睛的位置, 将数据库上面部图像裁剪为64× 64纯人脸图像.采用Sun等[13]提出的人脸比例图进行裁剪, 具体做法为:假设两眼之间的距离为d, 从眼睛到嘴巴的垂直距离为d, 以眼睛为中心, 向上切0.5d, 向下切1.5d.再分别以左眼、右眼为中心向左向右各切0.5d.基于这些位置关系, 确定图2的人脸比例切割图.由此切割的人脸区域包括眼睛、眉毛、嘴巴这些持久表达表情信息部位和额头脸颊这些瞬时表达表情信息的部位.
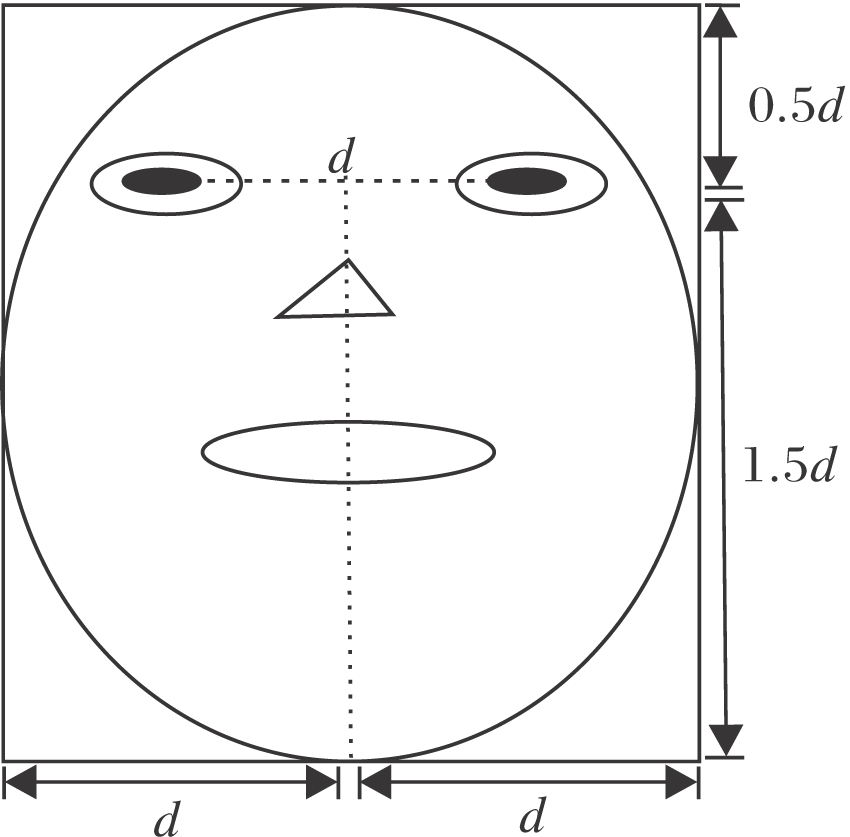 | 图2 人脸比例切割图Fig.2 Face scale cutting map |
对比方法包括SVM、KNN和SRC.SVM采用线性核.KNN中K=10.SRC中关于编码系数的约束参数λ =0.01.本文方法参数λ 1=λ 2=0.01.
所有实验都是在PC(Intel Core i7-8700 CPU, 3.20 GHz)和Matlab2018b上进行的.
根据特征优选算法, 从表情识别的5个常见特征(HOG、LBP、LPQ、GLCM、ASM)中选择JAFFE数据库上最优特征组合.
首先考虑特征稀疏集中指数.在JAFFE数据库上, 各特征稀疏集中指数如下:HOG为0.773 0, LBP为0.693 5, LPQ为0.849 5, GLCM为0.475 9, ASM为0.152 5.HOG、LBP、LPQ的编码系数的稀疏集中指数远超过其它特征, 因此再考虑这3个特征间的互补指数, 具体如表1所示.
| 表1 特征间的互补指数 Table 1 Complementary index between features |
由表1可知, LBP和LPQ间的互补指数最高, 可提供最大互补信息.因此本文选择LBP和LPQ作为JAFFE数据库上的最优特征组合, 基于这2个特征构建字典, 进行组稀疏表示.
此外, 为了验证特征优选算法的有效性, 将特征集上任意2个特征经过字典优化后按照式(2)中的组字典构建的方式组合, 通过组字典稀疏表示进行表情分类, 在JAFFE数据库上的识别精度如表2所示.由表可知, 在JAFFE数据库上, 识别精度最高的特征组合与使用特征优选算法挑选的特征组合一致, 这表明本文特征优选算法在JAFFE数据库上的有效性.另外, HOG、LBP、LPQ任意两者组合的识别精度都高于其它组合, 这是因为这3个特征自身的识别性能较高, 这一点从特征稀疏集中指数也可看出.
| 表2 JAFFE数据库上不同特征组合的识别率对比 Table 2 Comparison of recognition rate of different feature combinations on JAFFE % |
LBP和LPQ组合中一次表情识别精度的混淆矩阵如表3所示.
| 表3 JAFFE数据库上表情识别精度的混淆矩阵 Table 3 Confusion matrix of expression recognition accuracy on JAFFE % |
采取同样的方式, 选择最适合CK+数据库的特征组合、特征的稀疏集中指数和特征间的互补指数.
与JAFFE数据库类似, 在CK+数据库上, 特征稀疏集中指数如下:HOG为0.806 9, LBP为0.722 4, LPQ为0.801 7, GLCM为0.298 3, ASM为0.077 0.HOG、LBP、LPQ编码系数的稀疏集中指数较高, 再考虑这3个算子任意两者间的互补指数, 如表4所示.
| 表4 特征间的互补指数 Table 4 Complementary index between features |
同样地, 将特征集中任意两个特征组合识别精度进行对比, 如表5所示.由表可知, 在CK+数据库上, 识别精度最高的特征组合与使用特征优选算法挑选的特征组合一致.
| 表5 CK+数据库上不同特征组合的识别率对比 Table 5 Comparison of recognition rate of different feature combinations on CK+ dataset % |
HOG和LPQ组合中一次表情识别精度的混淆矩阵如表6所示.
| 表6 CK+数据库上表情识别精度的混淆矩阵 Table 6 Confusion matrix of expression recognition accuracy on CK+ dataset % |
对比表2和表5可知:1)在JAFFE数据库上的识别精度高于CK+数据库, 这是因为在JAFFE数据库上, 备选特征间的互补指数更高(见表1和表4).因此, 讨论如何选择最优特征组合时, 要综合考虑特征自身的性能和特征间的互补性能.2)数据库不同, 最优特征组合也不同, 在JAFFE数据库上, 最优的特征组合是LBP和LPQ, 在CK+数据库上, 最优特征组合是LPQ和HOG, 这表明影响特征组合识别精度的因素不仅是特征本身, 与所选的数据库也有很大的关联.
CK+数据库上的样本是在不同光照环境下采集的, 光照不均匀.为了验证本文方法对光照的鲁棒性, 采用直方图均衡手段均匀光照, 将HOG特征与本文方法应用在均匀前后的数据库上进行实验, 具体识别精度如表7所示.
| 表7 CK+数据库上光照均匀前后不同方法识别精度对比 Table 7 Accuracy comparison of different methods before and after illumination uniformity on CK + dataset % |
由表7可知, HOG特征在光照均匀化后的CK+数据库上, 识别精度提升约3%, 而本文方法识别精度前后差别不到1%.这表明本文方法在光照均匀和不均匀的条件下识别精度相差很小, 小于 HOG特征, 光照鲁棒性更强.
为了探究方法的泛化能力, 使用不同数量的样本训练方法, 探究其对识别精度的影响.SVM、KNN、SRC均属于单个特征的分类器.为了使实验对比更准确, 采用特征融合中常用的融合方法串联, 在JAFFE数据库上融合LBP与LPQ, 在CK+数据库上融合HOG与LPQ.各方法识别精度结果如图3所示.
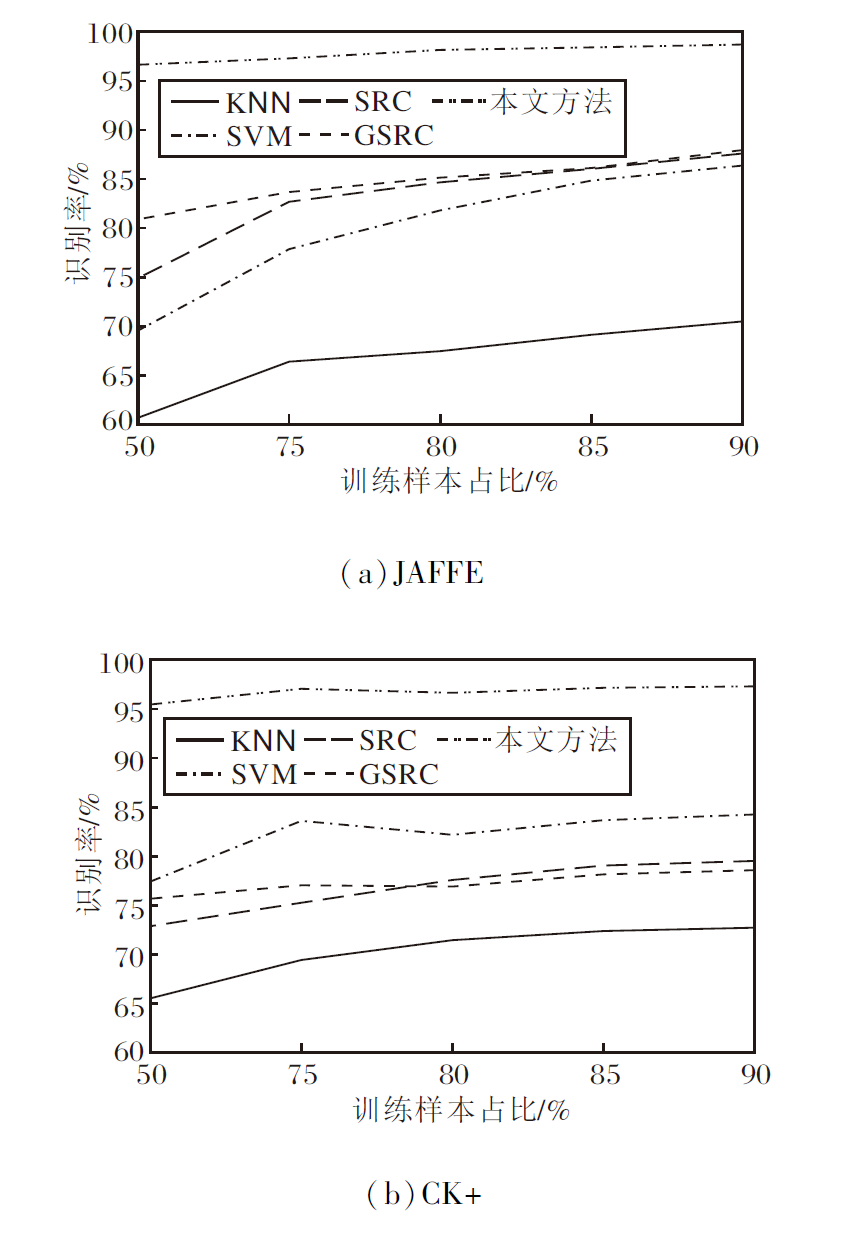 | 图3 不同训练样本对各方法识别精度的影响Fig.3 Influence of different training samples on recognition accuracy of different methods |
由图3可知, 随着训练样本数目的减少, 本文方法和组稀疏表示模型识别精度稳定, 而KNN、SVM、SRC性能急剧下降.由此验证组稀疏表示在小样本问题上避免过拟合的有效性.另外, 从本文方法与组稀疏表示模型的结果对比可看出MSDOL的有效性, 它从特征中学习到本质的表情信息用于分类, 大幅提升识别精度.
从分类精度和耗时两方面进行对比.在JAFFE数据库上各方法的识别精度如下:文献[13]方法为65.61%, 文献[15]方法为94.01%, 文献[17]方法为97.30%, 文献[25]方法为94.37%, 文献[26]方法为95.20%, 文献[27]方法为97.18%, 本文方法为98.71%.在CK+数据库上各方法的识别精度如下:文献[14]方法为94.51%, 文献[16]方法为96.10%, 文献[18]方法为91.90%, 文献[26]方法为95.40%, 文献[28]方法为96.92%, 本文方法为97.27%.由此可知, 本文方法在2个数据集上的识别精度都最优.特别地, 在JAFFE数据库上, 相比次优方法(文献[27]方法), 本文方法的识别精度提高超过1%.
各方法的耗时对比如表8所示.
| 表8 各方法的耗时对比 Table 8 Time consumption comparison of different methods |
在表8中, 文献[13]方法、文献[17]方法与本文方法属于同类方法, 都是利用多个字典进行表情识别.文献[15]方法和文献[27]方法是基于深度学习的方法, 分别利用自动编码的稀疏网络和CNN构建表情识别系统.由表8可知, 本文方法与同类方法的训练时间相当, 识别时间略短.相比基于深度学习的方法, 本文方法虽识别时间较长, 但训练时间远小于两者.
本文提出基于特征优选和字典优化的组稀疏表示分类方法, 可有效避免在小样本数据集上分类模型过拟合的问题, 更适用于实际场景.首先提出有效的特征优选准则, 针对不同的数据库选择最适合的特征组合.再针对现有的组稀疏表示方法中字典鉴别能力不高的问题, 对需要联合的特征字典进行优化增强.在JAFFE、CK+数据库上的实验表明, 本文方法识别精度较高.由于多个模态能从更全面的角度挖掘表情信息, 因此今后可考虑引入多个模态, 联合多个模态、多个特征进行表情识别.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|