

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于多支路残差深度网络的跨视角步态识别方法
[胡少晖1  , 王修晖
, 王修晖1 , 刘砚秋1 ]
, 王修晖, 刘砚秋]
|
|



作者简介:

胡少晖,硕士研究生,主要研究方向为计算机视觉、模式识别.E-mail:1577597405@qq.com.

刘砚秋,硕士,副教授,主要研究方向为模式识别、计算机图形学.E-mail:lyq@cjlu.edu.cn.
针对基于卷积神经网络的步态识别模型不能充分利用局部细粒度信息的问题,提出基于多支路残差深度网络的跨视角步态识别方法.将多支路网络引入卷积神经网络中,分别提取步态轮廓序列图中不同粒度的特征,并利用残差学习和多尺度特征融合技术,增强网络的特征学习能力.在公开步态数据集CASIA-B和OU-MVLP上的实验证实文中方法的识别准确率较高.
AboutAuthor:
HU Shaohui, master student. His research interests include computer vision and pattern recognition.
LIU Yanqiu, master, associate professor. Her research interests include pattern recognition and computer graphics.
Convolution neural network based gait recognition cannot make full use of local fine-grained information. To solve the problem, a cross-view gait recognition method based on multi-branch residual deep network is proposed. The multi-branch network is introduced into convolutional neural network to extract features with different granularity in gait contour sequences. Residual learning and multi-scale feature fusion technology are utilized to enhance the feature learning ability of the network. Experimental results on open-accessed gait datasets CASIA-B and OU-MVLP show that the recognition accuracy of the proposed method is higher than that of the existing algorithms.
本文责任编委 张军平
Recommended by Associate Editor ZHANG Junping
人体步态是人在行走过程中姿态的规律性变化, 每个人的步态都存在一定差异, 可用于身份识别.步态特征是生物特征领域中一种新型的人体特征, 相比人脸、指纹等人体特征, 具有非侵犯性、不可察觉、远距离识别等[1]突出优势.摄像头等设备的飞速更新换代给步态识别的发展带来巨大的推动力, 使步态识别在各种人体身份识别技术中越来越突出.然而步态识别过程中也存在许多影响因素[2], 如服装变化、步行速度和视角等, 造成一定困难.
近年来, 基于计算机视觉的步态识别受到广泛关注, 很多研究方向和方法被不断提出.在传统的图像识别算法中, 通常需要人们手动设置参数提取步态特征, 并且传统方法对训练图像的质量要求较高, 质量不佳的图像可能会使识别精度下降.相比传统的识别方法, 基于深度学习的图像识别方法不仅不需要手动选取特征, 而且通过大量样本训练深度网络, 能有效提取内在特征信息.
卷积神经网络(Convolutional Neural Network, CNN)发展迅速, 在图像分类问题上也取得不错效果, 具有代表性的卷积神经网络有GoogleNet[3]、AlexNet[4]、VGGNet(Visual Geometry Group Net)[5]、残差网络(Residual Network, ResNet)[6]等.Zhang等[7]将CNN应用在人脸识别领域, 获得较高的识别率.Xue等[8]将CNN应用在合成孔径雷达(Synthetic Aperture Radar, SAR)图像分类上, 达到98.98%的识别率.
在步态识别领域, 学者们也开始使用CNN.Wolf等[9]使用3D CNN获取步态时域和空间特征, 并利用光流图缓解穿戴与颜色对分类结果的影响.Chao等[10]提出跨视角步态识别方法, 利用深度卷积VGG-D(Visual Geometry Group Net-D)进行特征提取, 联合贝叶斯进行步态分类.Wu等[11]提出利用反馈权重对CNN架构进行优化的步态识别模型, 并通过提出的感受野权重提高特征的判别能力.Chen等[12]提出应用于步态识别的时空深度神经网络(Spatial-Temporal Deep Neural Network, STDNN).STDNN包括时间特征网络(Temporal Feature Network, TFN)和空间特征网络(Spatial Feature Network, SFN), 分别提取步态的时序特征和空间特征, 使步态特征更丰富.Shiraga等[13]提出步态能量图网络(Gait Energy Image Net, GEINet), 以步态能量图(Gait Energy Image, GEI)作为输入样本, 由2个卷积层、1个池化层、1个归一化层和2个全连接层组成, 最后使用softmax进行步态分类.Wu等[14]利用深度卷积神经网络(DeepCNNs)直接学习一对GEI或序列间的相似度, 识别率高达94.1%.Chao等[15]提出GaitSet, 以视频序列作为集合输入, 利用集合池化操作融合序列特征, 还使用金字塔池化操作处理融合后的特征, 提升步态特征的判别力.Chao等[16]在GaitSet的基础上加入像素级注意力和帧级注意力, 结合原来的三元组损失与交叉熵损失, 进一步提升效果.汪堃等[17]提出基于双流步态网络的跨视角步态识别方法:通过数据增强的方式提取全局特征和局部特征, 并进行融合, 得到更具判别性的步态特征; 同时改进三元组损失函数, 加快网络模型的收敛速度.
受GaitSet[15, 16]的启发, 本文根据CNN的自适应特征提取能力、平移不变性、局部感知能力等优点, 提出基于多支路残差深度学习网络的跨视角步态识别方法.利用多尺度网络提取不同细粒度的步态特征, 同时按卷积核大小对卷积网络进行分流处理, 并加入残差学习和多尺度特征提取等操作, 使提取的步态特征更具有代表性和区分度.在公开步态数据集CASIA-B和OU-MVLP上的实验表明本文方法明显提升步态分类效果.
步态识别问题就是通过步态属性判断身份.给定1个数据集, 共有N个人, 每人有若干幅步态轮廓图, 每幅步态轮廓图的步态属性与人的身份一一对应.因此, 同个步态的属性一致.若给出一幅未知身份的步态轮廓图, 应该首先进行步态属性判断, 然后与已知的身份属性进行匹配, 最后判断身份.
本文的样本集被分成训练集、参考样本集(Gallery Set)和查询样本集(Probe Set).训练集的样本用于训练网络和调整模型参数, 得到表现较优的模型.参考样本集和查询样本集供测试时使用, 需要从参考样本集样本中检索与查询样本集样本身份相同的样本集.具体操作如图1所示.
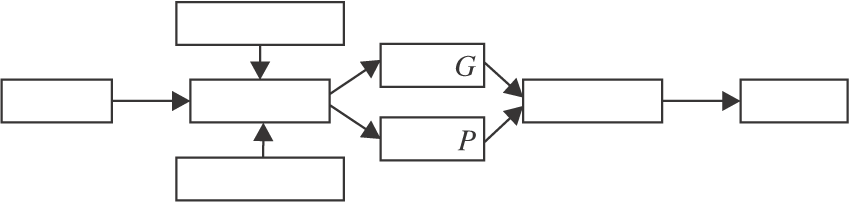 | 图1 步态识别流程图Fig.1 Flow chart of gait recognition |
操作中先将训练集的样本进行训练, 得到一个具体的网络模型.测试时给定查询样本集的一个样本xp, 经过网络模型特征提取, 获得查询步态特征f(xp), 同样参考样本集中的样本集合{xq}, 经过网络模型特征提取, 获得参考步态特征集合{f(xq)}, 目标是针对查询步态特征f(xp)在某一特征空间上找到步态特征集合{f(xq)}中相似度最高的特征, 并验证它们的身份是否相同.
本文采用欧氏距离作为标准距离度量方式:
$d(f({{x}^{p}}), f({{x}^{q}}))=\|f({{x}^{p}})-f({{x}^{q}}){{\|}_{2}}=\sqrt{f{{({{x}^{p}})}^{2}}-f{{({{x}^{q}})}^{2}}}.$
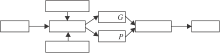
本文方法网络框架如图2所示.首先步态轮廓图每帧经过注意力残差网络初步提取特征.然后分为2个分支.2个分支结构高度相似, 只有第1个卷积层的卷积核大小不同, 这样可保持提取的特征在保证基本信息的基础上进一步细化.2个分支的后续部分是1个多尺度特征融合网络, 由不同阶段卷积层的前端出现1个小分支, 融合所有分支.经过不同卷积核大小的CNN处理提取不同细粒度的步态特征.最后, 经过水平金字塔映射(Horizontal Pyramid Mapping, HPP), 2分支合并成1分支, 经过全连接层, 分别进行三元组损失训练和步态识别.HPP是将特征图在水平方向进行不同尺度的分割, 再进行平均池化和最大池化的一种特征图像处理方法, 在行人重识别[18]和步态识别[15, 16]上均取得显著效果.
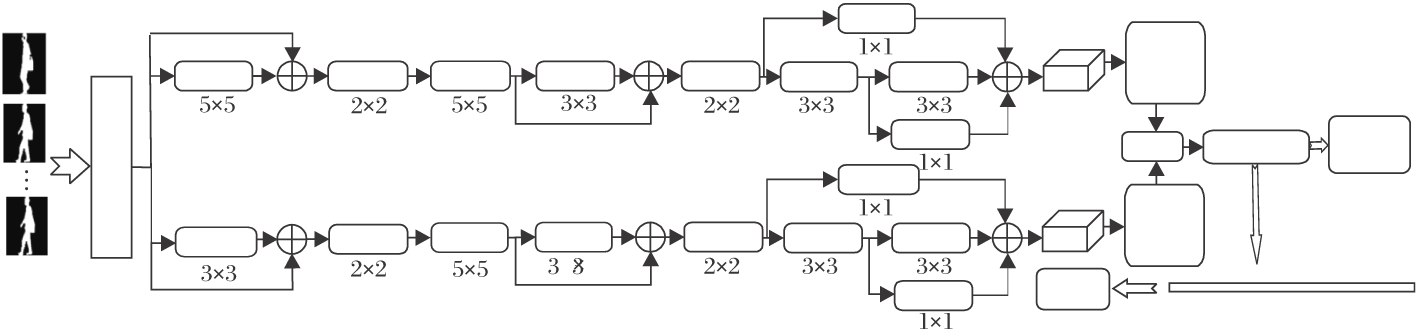 | 图2 本文方法网络框架Fig.2 Framework of the proposed method |
为了获得更精确有效的特征, 本文设计注意力残差网络, 如图3所示.
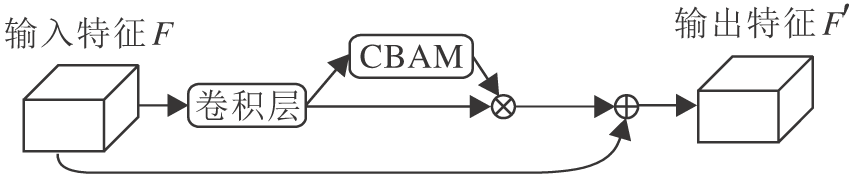 | 图3 注意力残差网络结构Fig.3 Structure of attention residual network |
网络由1个卷积层和基于卷积块的注意力机制模块(Convolutional Block Attention Module, CBA-M)[19]构成.首先输入特征经过卷积层, 输出特征经过注意力机制处理后与原来特征进行融合, 作为输出特征, 过程表示为
F'=F(1+MCBAM[f5× 5(F)]),
其中, F表示输入特征, MCBAM表示注意力机制CBAM, f5× 5表示网络卷积核大小为5× 5.
CBAM结合通道和空间的注意力机制, 分别从通道和空间2个维度计算注意力特征图, 并与底层特征图相乘, 实现特征的自适应学习.同时, CBAM是一个轻量级的结构, 集成在网络中产生的额外开销可忽略不计.加入网络可较好提升网络的表现力.
虽然加入注意力机制对于步态分类有很大作用, 但是单纯的叠加注意力模块可能会导致性能下降.一方面, CBAM以sigmoid激活函数作为结尾, 输出结果会被归一化到0~1之间, 再与原特征进行点乘, 这会使特征图的输出响应变弱, 最后输出的特征图每个点的值变小.另一方面, 经过CBAM的特征相对原特征来说可能会损失一些原有特性, 而且该网络结构处于浅层位置, 对深层网络影响很大.
为了解决上述问题, 本文采取注意力特征与原特征进行残差的形式, 在保留注意力机制优点的同时有效减少其造成的不利影响.
为了获得更精准有效的特征, 提高分类效果, 本文引入多支路残差网络.通过多次实验及计算量等因素的综合考虑, 选择将注意力残差网络分为2条支路, 2条支路分别使用不同尺寸的卷积核提取不同深度的信息.单支路是以经典的VGGNet网络作为基础的CNN框架, 主要包含卷积层和池化层.具体网络结构如图2所示.网络还通过局部残差学习和跳跃连接等方法减少信息损失, 提升步态识别的效果.
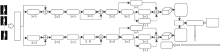
特征金字塔网络(Feature Pyramid Networks, FPN)[20]利用CNN融合不同尺度特征, 生成表现力更强的特征图.受此影响, 本文也提出融合多尺度特征的残差结构, 如图4所示.主干路是2个3× 3的卷积层, 分支的1× 1卷积层从主干路的2个卷积层不同深度对特征进行采样, 得到2个特征图, 最后利用残差将主干路和分支的特征图进行融合输出.
 | 图4 融合多尺度特征的残差网络结构Fig.4 Structure of multi-scale feature fusion network |
单独从多尺度特征融合网络这个角度上看, 从输入特征到输出特征有3条通路:第1条经过卷积核为1× 1的卷积层; 第2条经过2个卷积核为3× 3的卷积层; 第3条先经过1个卷积核为3× 3的卷积层, 再经过1个卷积核为1× 1的卷积层.每个卷积层后面跟一个激活函数Leaky ReLU.因此生成特征:
F1=f1× 1(LeakyReLU(F)),
F2=f3× 3(LeakyReLU(f3× 3(LeakyReLU(F)))),
F3=f1× 1(LeakyReLU(f3× 3(LeakyReLU(F)))),
F'=F1+F2+F3,
其中, F为输入特征, F'为输出特征, F1、F2、F3分别为3条通路输出特征, f1× 1、 f3× 3分别为卷积核大小为1× 1和3× 3的卷积层.
不同尺度的特征包含不同粒度的特征, 粒度较大、采样较浅的特征可看到整体趋势, 而粒度较小、采样较深的特征可看到更细节的信息.步态识别不仅需要整体的粗粒度特征, 同时也需要微小的细粒度信息.如果单用一条支路进行特征采样, 只能得到粗粒度特征和细粒度特征中的一种, 这样的特征是不具有代表性的.
本文使用CASIA-B数据集和OU-ISIR-MVLP数据集作为实验数据集.CASIA-B数据集是目前视角跨度最广泛的步态数据集之一, 由中国科学院自动化研究所建立, 包括11个视角(0° , 18° , 36° , …, 180° ), 124个人的步态数据.每人在每个视角下又拍摄10个步态视频, 分别是6组正常行走的视频(NM01~NM06)、2组背包行走的视频(BG01、BG02)、2组穿大衣行走的视频(CL01、CL02).OU-ISIR-MVLP数据集是目前最大的跨视角步态数据集, 由日本大阪大学科学与工业研究所建立, 包括14个视角(0° , 15° , …, 90° , 180° , 195° , …, 270° ), 10 307个人的步态数据.每人在每个视角下拍摄2组视频, 分别为01、02.这2个数据集是目前步态识别领域的经典数据集, 具有代表性.
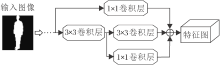
实验中步态轮廓图预处理过程如图5所示, 框出二值图中的行人, 缩放到同一大小.选择的损失函数是三元组损失, 间隙参数为0.2, 实验选择的优化器是Adam, 学习率为1e-4.激活函数选择Leaky ReLU.在PyCharm上利用PyTorch深度学习框架编写代码, Python版本为3.6.0, 使用的GPU型号为NVIDIA GeForce GTX TITAN X.
 | 图5 步态轮廓图预处理过程Fig.5 Pre-processing of gait silhouette |
在CASIA-B数据集上的批尺寸为8× 16, 即在所有人中随机抽取8人, 在每人的轮廓序列图中随机抽取16幅轮廓序列图, 共进行80 000次迭代.实验采用如下对比方法:GaitSet[15]、非周期步态识别模型(Aperiodic Gait Recognition, AGR)[21]、相关运动协同聚类(Correlated Motion Co-clustering, CMCC)[22]、视角不变判别投影(View-Invariant Discriminative Projection, ViDP)[23]、Deep CNNs[14]、注意力时空融合网络模型(Attentive Spatial-Temporal Summary Networks, ASTSN)[24].
在CASIA-B数据集上以少量训练样本进行实验, 少量训练样本的划分方式如下:将数据集上编号为1~24的行人样本划分为训练样本, 将编号为25~124的行人样本划分为测试样本.
各方法在CASIA-B数据集上使用少量训练样本时的Rank1识别准确率如表1所示, 参考样本集为NM01~NM04, 查询样本集为NM05、NM06.表中对比方法的数据均来自于原论文实验结果, 在小训练样本时选择0° , 54° , 90° , 126° 进行对比, 原因是部分对比方法只给出这4个角度的结果.为了便于对比, 本文也只对这4个角度做出讨论.
| 表1 各方法在CASIA-B数据集上使用少量训练样本时的Rank1识别准确率 Table 1 Rank1 recognition accuracy of different methods using a small number of training samples on CASIA-B dataset |
由表1可知, 在54° 和126° 视角下的识别率明显高于0° 和90° 视角下的识别率, 可能是因为侧面视角的步态特征相对来说更容易分辨, 而正面视角相对来说特征信息不是那么明显, 识别会困难一些.总体上, 本文方法的识别率均高于对比方法, 说明本文方法在少量训练样本情况下的提取能力相对较强.
各方法在CASIA-B数据集上分别以中量训练样本和大量训练样本方式进行实验.中量训练样本的划分方式为:1~62号行人作为训练样本集, 63~124号行人作为测试样本集.大量训练样本的划分方式为:1~73号行人作为训练样本集, 74~124号行人作为测试样本集.
中量训练样本时的对比方法如下:GaitSet[15], 自动编码器(Auto-Encoder, AE)[25], 基于生成对抗网络的步态识别(Gait Recognition Based on Genera-tive Adversarial Network, GaitGAN)[26], 基于多任务生成对抗网络的步态识别(Gait Recognition Based on Multi-task Generative Adversarial Network, MGA-N)[27].大量训练样本时的对比方法如下:Deep CNNs[14]、GaitSet[15].
各方法在这2种划分方式下的Rank1识别准确率如表2所示, 参考样本集为NM01~NM04.由表可见, 正常条件下行走的识别准确率最高, 其次是背包状态, 效果最差的是大衣状态.原因可能是普通行走状态下的步态特征较明显, 背包状态对步态有一定遮挡, 而大衣状态对步态的遮挡更明显, 步态识别的难度增大, 导致识别准确率降低.
| 表2 各方法在CASIA-B数据集上使用中量/大量训练样本时的Rank1识别准确率 Table 2 Rank1 recognition accuracy of different methods using medium or large number of training samples on CASIA-B dataset % |
表2中的实验数据是11个视角Rank1识别准确率的平均值.在中量训练样本时能达到较高水准的是GaitSet, 正常条件下的识别准确率达到92.0%, 背包条件和大衣条件下的识别准确率相对较低, 分别达到84.3%和62.5%.相比GaitSet, 本文方法在正常条件、背包条件、大衣条件下识别准确率分别增加0.5%、1.0%、1.7%.在大量训练样本情况下, 本文方法在正常条件下的识别准确率比GaitSet降低0.1%, 在背包状态和大衣状态下的识别准确率比GaitSet分别增加1.0%、1.7%.由于GaitSet在正常状态下的识别准确率已达到一个较高的水平, 本文方法在正常状态下未超过GaitSet, 但是在背包条件和大衣条件下还是有一定提升.
本文通过在OU-ISIR-MVLP数据集上的跨数据集实验验证本文方法的泛化能力.在该数据集上的训练样本划分方式是将5 153个行人样本作为训练样本, 5 154个行人样本作为测试样本(具体以数据集给出的划分规则为准).由于大多数实验未给出全部视角的实验数据, 为了方便实验对比, 本文也只考虑0° , 30° , 60° , 90° 视角.对比方法如下:GEI-Net[13], Deep CNNs[14], 卷积神经网络的输入输出架构(In-put/Output Architectures for Convolutional Neu-ral Network, Input/Output)[28], 判别式步态生成对抗网络(Discriminant Gait Generative Adversarial Net-work, DigGAN)[29].
各方法在OU-ISIR-MVLP数据集上的Rank1识别准确率如表3所示, 参考样本集为0° , 30° , 60° , 90° .由表可知, 在OU-ISIR-MVLP数据集上, 本文方法存在一定优势, 但相比在CASIA-B数据集上的实验结果, 还是有一定差距.原因可能是OU-ISIR-MVLP数据集的数据量比CASIA-B数据集大很多, 数据量的增加对步态识别效果有一定影响.总体上看, 本文方法的步态识别率较优, 但是受到样本数据量大小的影响较明显, 需要进一步进行研究.
| 表3 各方法在OU-ISIR-MVLP数据集上的Rank1识别准确率 Table 3 Rank1 recognition accuracy of different methods on OU-ISIR-MVLP dataset |
本节验证注意力残差网络和多尺度特征融合网络的效果.实验使用CASIA-B数据集, 采用大量训练样本划分方式.
实验分成如下5种情况进行对比:1)不包含残差注意力网络; 2)只用注意力网络, 不加入残差的情况; 3)2条支路中都只有主路3× 3卷积, 去除支路1× 1卷积; 4)单支路, 只保留3× 3卷积支路; 5)本文方法.第1种和第2种情况是为了判断残差注意力网络各部分结构对识别率的影响, 而第3种和第4种情况是为了判断多支路多尺度特征对识别率的影响.
不同情况下的识别率对比如表4所示, 参考样本集为NM01~NM04.由表中第1种情况和第2种情况与本文方法识别率对比可看出, 在不包含残差注意力网络时识别率最低, 使用注意力网络后识别率具有微小提升, 在注意力网络中加入残差结构之后, 各状态下的识别率都有一定提升, 尤其是背包状态和大衣状态.这说明在注意力网络中加上残差结构是有必要的.加入注意力机制后虽然可提高有用信息的权重, 但还是会损失部分有用信息, 而残差结构相当于在提高有用特征权重的同时减少其它信息的损失, 实验结果也表明该结构是有效的.从第3种情况和第4种情况与本文方法识别率对比可看出, 多尺度特征融合网络和多支路残差结构对提升识别结果都具有一定作用, 多尺度特征融合可融合深层特征和浅层特征, 多支路网络可融合不同细粒度的特征, 融合后的特征更有利于步态识别.
| 表4 不同情况下的Rank1识别准确率对比 Table 4 Rank1 recognition accuracy comparison in different cases % |
在CASIA-B数据集上不同视角差的Rank1识别准确率如表5所示, 对比实验依旧是5种情况.由表可知, 视角差越小, 识别准确率越优.以外, 在不同视角时, 本文方法都可稳定取得不错效果.
| 表5 不同视角差下的Rank1识别准确率对比 Table 5 Rank1 recognition accuracy comparison in the views of different angles |
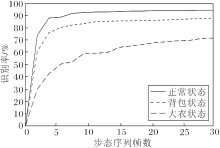
为了探究步态数据集上的视频帧数对步态识别率的影响, 分别在CASIA-B数据集上基于3种不同条件进行实验, 观察步态识别能力的强弱, 结果如图6所示.由图可知, 随着步态帧数的增加, 步态识别率也在不断提升.正常状态下很快就趋向稳定, 其次是背包状态, 最后是大衣状态.正常状态达到最佳识别率需要的步态序列帧数最少, 约在6帧左右.这说明不是数据量越大得到的效果越优, 可能在一个周期内就能获取大多数的步态信息, 在此基础上增加的信息对效果的提升就很微小.
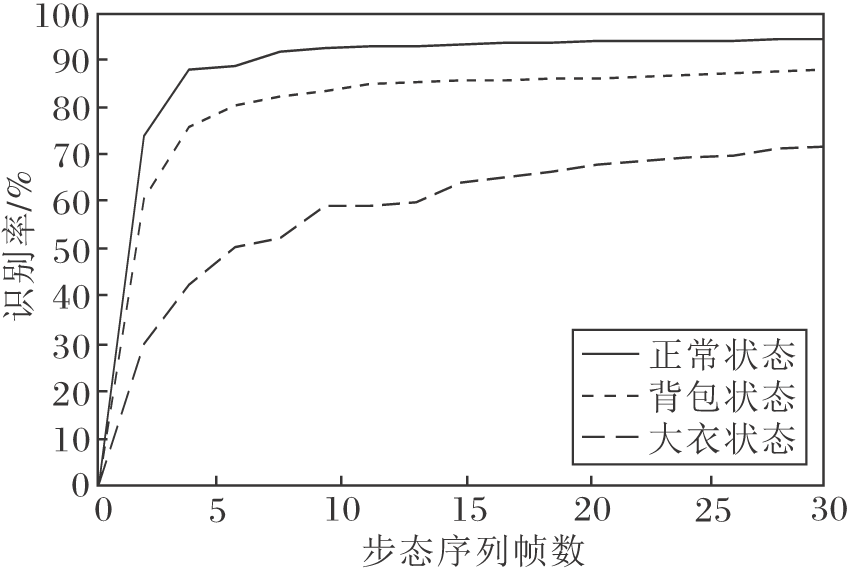 | 图6 CASIA-B数据集上帧数对识别准确率的影响Fig.6 Effect of the number of frames on recognition rate on CASIA-B dataset |
为了更好地利用步态图像的细粒度信息, 本文提出基于多支路残差深度网络的跨视角步态识别方法.在卷积神经网络的基础上加入残差学习、多支路结构和多尺度特征融合等方法, 增强网络的特征提取能力.在CASIA-B、OU-ISIR-MVLP步态数据集上的实验表明, 本文方法具有较优的步态识别效果, 尤其在背包条件和大衣条件下.
但是, 目前的识别准确率距离实际场景应用还远, 为了进一步提高步态识别的精度, 一方面可从数据集方面考虑, 对训练样本进行处理扩充, 增强模型的泛化能力, 另一方面, 网络结构也还有很大的改进空间, 值得进一步研究.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|