



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于异质网络表示学习的姓名消歧
[唐正正1, 2  , 洪学海
, 洪学海2, 3 , 汪洋1, 2 , 李玉轩1, 2 ]
, 洪学海, 汪洋, 李玉轩]
|
|



作者简介:

唐正正,博士研究生,主要研究方向为机器学习、数据挖掘、图表示学习.E-mail:tangzhengzheng@cnic.cn.

汪洋,博士,高级工程师,主要研究方向为信息化发展战略研究、大数据分析、态势感知系统等.E-mail:wangyang@cnic.cn.

李玉轩,硕士研究生,主要研究方向为机器学习、信息检索等.E-mail:liyuxuan@cnic.cn.
在系统中搜索某一姓名时,会返回该同名作者的所有文档(如论文、网页),严重影响用户体验,姓名消歧可提高检索精度.因此,文中提出基于异质网络表示学习的姓名消歧方法.首先为每个歧义姓名构造一个论文异质网络.然后使用异质网络表示学习并结合词向量化语义表征学习方法,获取网络中每个论文节点的表征向量.最后使用具有噪声的基于密度的聚类方法与规则匹配结合的聚类方法将论文划分给不同的作者实体.文中方法在OAG-WholsWho比赛数据集上的性能较优,结果验证方法的有效性.
About Author:
TANG Zhengzheng, Ph.D. candidate. His research interests include machine learning, data mining and graph representation lear-ning.
WANG Yang, Ph.D., senior engineer. His research interests include informatization development strategy research, big data analysis and situational awareness system.
LI yuxuan, master student. His research interests include machine learning and information retrieval.
During the search for the name of an author in the system, the return of all documents of the author deteriorates the user experience. Name disambiguation can improve the retrieval accuracy. Therefore, a name disambiguation method based on heterogeneous network representation learning is proposed. Firstly, a paper heterogeneous network is constructed for each ambiguous name. Then, the representation vector of each paper node in the network is obtained based on the heterogeneous network and the Word2Vec. Finally, papers are divided up and assigned to different author entities via rule matching and a clustering method based on density with noise. The proposed method generates better performance on OAG-WholsWho competition dataset, and its effectiveness is verified.
本文责任编委 马少平
Recommended by Associate Editor MA Shaoping
近年来, 学者们越来越多地通过数字图书馆等搜索同行或著名研究人员的最新工作.这些数字图书馆收藏大量的论文集, 由于姓名歧义问题, 导致检索服务效率较低.随着模糊匹配和逻辑检索功能在数字图书馆中的普及与强化, 文献检索的效率得到提升.但是, 对于外文数据库的作者检索, 即准确获取指定作者的论文信息上, 进步依然缓慢.监督方法[1, 2]把作者姓名歧义问题看作是对同名作者的分类, 但需要标注数据.Qiao等[3]通过多个特征学习论文表示, 测量论文之间的相似性, 确定是否属于同一作者.然而, 基于表示学习解决姓名歧义问题存在3个难点.
1)多类型特征融合.如何提取组合如文本语义信息和离散特征(如作者、地点)等不同类型特征以学习论文的表示在现阶段是难点.高质量的表示在量化论文之间的区别和相似性研究方面起到关键作用[1].大多数现有解决方案是利用论文特征, 如标题、摘要、作者等, 以及关系特征, 如引用、被引等, 学习论文表示.通过这些特征抽取论文之间的关系, 构建论文网络, 再使用基于图的方法[4, 5, 6]或启发式的方法[7, 8]学习论文之间的相似性.一些方法[5, 9, 10, 11]依据论文内容中词共现信息定义论文之间的关系, 丢失语义信息.有些监督算法[3]侧重内容信息, 通常无法衡量论文之间的高阶关系.此外, 还有些方法可解决同构网络上的问题, 方法或为每种类型的关系构建网络, 或结合不同的关系构建一个论文网络.这些策略忽略论文之间的异质性关系.
2)聚类簇数量未知.当不确定同名作者的数量时, 如何有效地进行论文分配是问题所在.一些研究[6, 12]假设歧义姓名的聚类数K预先知道, 但一般情况下并不知道聚类数.还有些研究[5, 9]提出不同的估计策略.然而, 在这些策略中通常有预定义的参数.此外, 随着数字库中数据的不断增加, 聚类过程也越来越耗时, 需要更有效的聚类策略进行姓名消歧.
3)论文的增量消歧, 即如何有效处理潜在的歧义姓名新发表论文.许多方法[4, 6, 7, 13, 14]都是基于数据库上的静态集合实现的.在添加新记录时需要对整个集合进行姓名消歧, 这种更新的解决方案会丢弃现有的论文表示和聚类结果.此外, 由于数据库的尺寸越来越大, 计算成本越来越高.一个理想的解决方案是使用增量消歧方法, 结合现有的聚类结果和学习的模型参数生成新论文的表示, 不需要对整个集合进行再处理.
鉴于姓名歧义问题的重要性, 相关研究方法不断被提出, 从监督方法、非监督方法到概率模型.各类姓名消歧方法一般都包括特征抽取、相似性计算及聚类三个步骤.根据特征抽取的不同方法, Tang等[9]提出基于马尔可夫随机场的框架, 提取论文数据库上多种类型的特征和关系.Zhang等[1]使用全局度量学习和局部链接图自动编码器算法学习论文的表示, 但需要大量的人工标记数据以训练模型.Lin等[10]提出基于共同作者和标题属性的分层聚类方法.还有的学者尝试利用图的拓扑和连接解决问题.Fan等[4]仅通过合著者关系构建论文网络, 设计相似性度量, 利用亲和传播聚类算法对结果进行聚类.Wang等[14]引入双因子图模型, 引入各种特征扩展.
如今的姓名消歧解决方法大多基于静态数据集.为了解决新发表论文的姓名歧义, 一些学者设计增量式姓名消歧方法, Zhao等[15]提出概率模型, 使用一组丰富的元数据, 并将新论文分类到现有的作者实体.Santana等[16]组合几个特定领域的启发式方法, 自动创建和更新论文集群, 确定每篇论文的姓名实体.
网络表示学习被应用到各种网络挖掘任务中, 由此针对网络表示的相关研究也愈发成熟.深度游走(DeepWalk)[17]和节点向量化表示(Node to Vec-tor, Node2Vec)[18]使用网络上的随机游走策略和跳字模型(Skip-gram)[19, 20], 学习网络中每个节点的表示.当应用于异质网络时, 这种随机漫步忽略关系的类型, 生成的节点路径对大概率可见的关系类型和节点具有倾向性[21].大规模信息网络嵌入(Large-Scale Information Network Embedding, LINE)[22]旨在学习保持一阶和二阶近似的节点嵌入.用于学习图表示的深度神经网络方法(Deep Neural Networks for Learning Graph Representations, DNGR)[23]捕获图结构信息, 学习每个顶点的低维向量表示.元路径向量化(Meta-Path to Vector, Metapath2Vec)[24]是基于元路径的异构网络嵌入方法.还有些方法为网络嵌入提供不同解决方案.图卷积神经网络(Graph Convo-lutional Network, GCN)[25]、图样本和集合(Graph Sample and Aggregate, GraphSAGE)[26]使用图卷积神经网络获得节点表示.Zhang等[27]提出兼顾节点类型和异构属性的异构图神经网络模型.
在姓名消歧方面, 学者们试图利用网络嵌入的方法, 构建论文网络以学习论文嵌入.Zhang等[6]在3个匿名网络上利用基于网络表示学习的方法, 在论文之间构建5个关系网络, 并使用网络嵌入算法通过邻居学习论文的表示.Schlichtkrull等[28]引入关系图卷积网络, 实现链接预测任务和实体分类任务.Zhang等[29]提出简单的同构网络随机游走策略和图嵌入方法, 并使用层次聚类(Hierarchical Agglo-merative Clustering, HAC)[30]对论文进行划分.但是, 这些方法缺乏更深层次的模型以学习论文表示.
针对姓名消歧的难点, 本文提出基于异质网络表示学习的姓名消歧方法.通过同名作者的论文集构建包含多种类型关系的论文异质网络(Publica-tion Heterogeneous Network, PHNet), 针对网络设计基于异质网络表示学习方法, 结合自定义关系权值和元路径引导的随机游走策略, 学习每篇论文的向量表征.在此基础上, 提出不需要指定簇数的有效聚类方法.
定义1异质网络 定义异质网络G=(V, E, N, R), 其中, 每个节点v∈ V都与一个节点类型映射函数ϕ (v):V→ N关联, 而每个关系e∈ E都与一个关系类型映射函数ϕ (e):E→ R关联.这说明G有多个节点类型和关系类型, 即|N|+|R|> 2.
定义2加权异质网络 加权异质网络Gw=(V, E, N, R)为每个关系都带有权重的异构网络, 对于每个关系e∈ E, |e|表示权重值.
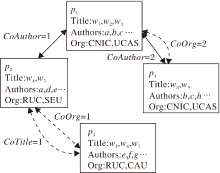
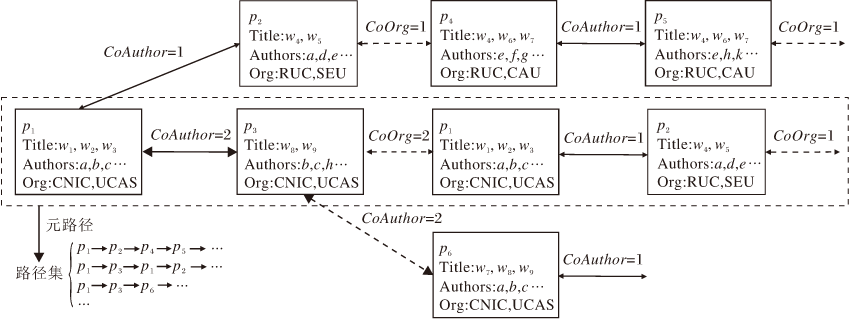
定义3论文异质网络 本文构造的论文异质网络(PHNet)可看作是一种特殊的加权异构网络, 具有一种节点和三种关系.对于每个歧义名字a, PHNet可表示为Ga=(V, E, R).如图1所示, 每个论文都表示为PHNet中单个节点.
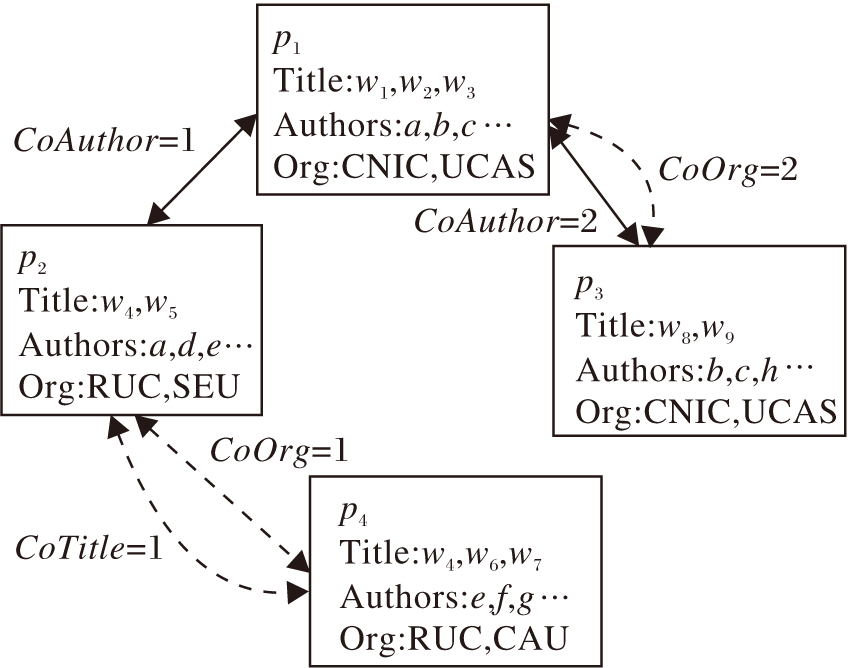 | 图1 论文异质网络示意图Fig.1 Sketch map of heterogeneous network |
网络的关系集合R包括CoAuthor(A)、CoOrg(O)、CoTitle(T), 分别表示论文之间的3种无向关系, 具体定义如下:
1)CoAuthor.每篇论文有一个作者列表, 由多个作者共同创作.对于任何要消除歧义的作者名称a, 假设它的2篇论文为
2)CoTitle.标题总是包含大量的主题词, 用于概括论文的主要内容.对于每篇论文pi的标题, 首先去掉停用词, 然后将每个词转换为词干, 标题被处理成一个词集Ti.2篇论文p1、p2, 如果 T1∩ T2≠ Ø ,
3)CoOrg.论文的共同作者所属机构名称经过如标题一样处理后得到词集O1、O2, 如果O1∩ O2≠ Ø , p1、p2之间存在CoOrg关系.CoOrg关系的权值为|O1-O2|.
论文的其它属性如果可用, 也可在PHNet中使用.考虑到一些数据库可能存有隶属关系、引文等信息不可用或不完整, 特别是隶属关系信息通常存在同义词[31]问题, 难以清理, 本文仅使用上述3个常见属性.除有歧义的名称a之外, 用于构造PHNet论文的属性可能也有歧义.例如, 如果2篇论文由a合著, 在同一时间, 它们都有另一个作者b, 这2个作者b实际上是2个不同的人.但根据经验, 这种巧合发生的概率非常小, 可忽略这些噪声对下游模型训练的影响.
在一个PHNet中, 2个节点pi、pj可通过多个无向关系连接.这些关系连接的节点序列可看作是pi到pj的一条路径.例如, 在图1中, p1和p3之间有一个路径
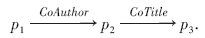
这意味着p3、p1的作者所写的另一篇论文有相同的标题词.
定义4元路径 在异质网络G=(V, E, N, R)中, 元路径定义为路径的形式为

其中, ri∈ R, ni∈ N, 关系序列r=r1☉r2☉…☉rl表示复合关系, 包括类型r1到类型rl的关系集合.
例如, 设计元路径的组成关系:
r=CoAuthor☉CoTitle☉CoOrg.
在PHNet中, 如图2所示, 基于r生成一条路径
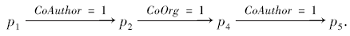
 | 图2 基于元路径随机游走生成的路径集Fig.2 Path set generated by random walk of metapath |
定义5姓名消歧问题 对于要消除歧义的作者姓名a, 定义Da={
每篇论文都包含诸如作者列表、标题、机构(如研究所或学校)等属性.假设命名为a的不同作者数量为Ka, 本文目标是通过使用这些论文的属性信息自动将它们区分为不同的作者实体, 即希望将Da中的论文聚类到Ka个不相交的集群
Ca={
因此, 同一集群中的所有论文由同一个人撰写, 不同集群中的每两篇论文都有姓名为a的作者.
任意一个需要消歧的作者名字, 抽取其所属的全部论文之间的关系, 构建论文异质网络.这个异质网络包含一种类型的节点(论文(每篇论文表示一个节点))和3种类型的边(CoAuthor, CoOrg, CoTitle).
CoAuthor表示2个论文之间有共同作者(不包含待消歧的作者姓名), 边上的权重表示拥有共同作者的个数.例如, 如果2篇论文之间有共同作者, 在它们之间构建一条关系名为CoAuthor的边, 同时这条边具有共同作者数目的属性.如果有1个共同作者, 关系权重为1, 如果有2个共同作者, 关系权重为2, 以此类推.
CoOrg表示2篇论文中待消歧姓名的机构的相似性关系, 边上的权重表示2个机构共词的数量.例如, 2篇论文的作者机构名称中出现相同的词, 且这个词不是停用词, 在它们之间构建1条CoOrg类型的边, 该类边也具有权重属性.如果有1个共现词, 权重值为1, 如果有2个共现词, 权重为2, 以此类推.
需要注意的是, 本文只使用待消歧姓名的机构信息.通过同样的方式可构建CoTitle边关系.
受网络嵌入方法DeepWalk[17]和Metapath2-Vec[24]的启发, 使用随机游动策略和skip-gram模型学习网络中的节点表示.本文提出加权异质网络路径采样的元路径和权重关系引导随机游走策略.元路径遍历可通过异构关系捕获节点之间的相关性, 广泛应用于异构网络嵌入中[3].此外, 采样路径时考虑PHNet中关系的权重.在每步游走选择下一个路径节点时, 与当前节点边权值越大, 越有可能被采样.
具体来说, 给定PHNet G=(V, E, R), 元路径方案
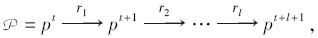
其中, pt∈ V, ri∈ R, l为pt和pt+l+1之间复合关系的长度.定义游走在第t 步时的跃迁概率:
p(pt+1|pt, P)=
其中, ri∈ R为下一个关系类型ϕ (pt-1, pt) 按照预定义方案P确定的, 如果pt为路径的第一个节点, ri=r1, |pt, pt+1|为pt与pt+1之间关系的权重, ‖ Et(ri)‖ 为所有连接pt且类型为ri的边权重之和.依据式(1)计算得到每步的转移概率, 结合预定义方案P, 在G中递归采样元路径, 组合拼接成最后的路径集合.
针对本文数据, 首先, 依次在PHNet中选择一个论文节点作为路径的第一个节点, 生成一个长度为l的元路径.然后选择最后一个节点作为另一个元路径的初始节点.这样, 每次随机递归地在网络中生成一条由P引导的采样路径, 直到满足固定长度, 即
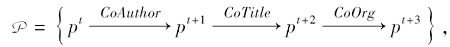
缩写为-A-T-O-.如图2所示, 如果游走者正在采样下一个节点, 当前节点为p1, P引导的下一个关系类型为合著者, 则与p1连接的具有合著者类型关系的所有节点构成候选样本集.假设集合中只有p2和p3节点, 根据它们与p1连接的合著者类型关系的值, 游走者采样节点p2的概率为1/3, 节点概率为2/3.
图2给出路径采样过程, 箭头大小表示步行到下一个节点的概率.当游走者遇到当前节点缺少某个关系的情况发生时, 它会跳过这个关系并转到元路径中的下一个关系.相比随机漫步, 随机游走策略通过元路径[24]的有序引导, 避免中心节点造成的偏置影响和不同关系量的偏差.此外, 本文设计的随机游走策略考虑一条路径的多种排列可能性、路径中节点之间的多种关系及这些关系的权重, 使生成的路径能较好地保留节点之间的异构关系.
基于1.3节生成的路径, 本文提出加权异构Skip-gram模型, 用于学习加权异质网络上论文节点的表示.给定PHNet G=(V, E, R), 本文目标是通过最大化节点pi连接其邻居节点pc的概率, 学习有效节点表示:
arg
其中, Nr(pi)表示pi的邻接节点集合, ∀ pc∈ Nr(pi), (pc, pi)∈ r, θ 表示网络模型的参数.函数中的关系权值|(pc, pi)|是使与pi关系值较大的邻居具有较高概率输出.定义 p(pc|pi, θ )为softmax函数:
p(pc|pi, θ )=
其中ui表示式(2)中由pi的随机初始化特征经编码得到的最终嵌入表示.采用文献[32]的负抽样方法对负节点进行抽样, 提高优化效率.概率可近似定义为
p(pc|pi, θ )≃ log2σ (ui, uc)+
其中, σ (x)=
给定元路径方案P和网络中的关系权值, 可选择不同节点作为路径的开始节点, 由此生成一组节点游走路径集合RWP.相邻节点在目标节点上下文中出现的频率与它们之间的关系的紧密程度成比例.因此, 使式(4)中的目标最大化可转化为求解
LP=-
使损失函数最小化.其中, k为上下文窗口的尺寸,
网络嵌入方法的整体框架如图3所示.对比其它基于元路径和Skip-gram的异构网络嵌入方法, 本文方法主要区别如下:1)本文方法可应用于加权异质网络, 并能捕获节点之间的关系权重信息和异构关系, 生成节点表示; 2)本文方法可同时结合语义信息和结构信息进行编码.
 | 图3 姓名消歧方法框图Fig.3 Framework of name disambiguation |
利用加权异构Skip-gram模型学习每篇论文的结构表示, 并且使用文件向量化(Document to Vector, Doc2Vec)[33]获取每篇论文的语义表示(标题、摘要).结合学习的两种向量表征进行预聚类, 目的是将论文分配到不相关的集群中, 每个集群属于不同的作者实体(如图3所示).
基于预聚类得到一些已划分好的簇, 里边包含已聚类好的论文, 把这些论文集合称为预聚类论文集, 还有一个离群论文集, 这2个集合不相交.将这些离群论文集里的论文使用阈值匹配的方法重新分配给已聚类好的簇或新的簇中.
具体操作如下.首先, 对于离群论文集中的每篇论文a, 对比a与所有预聚类论文集中的论文, 得到与其相似度最高的一篇论文.如果2个相似度不小于阈值α , 把前者分配到后者所在的簇中; 否则单独归为新的一个簇.然后, 对于离群论文集中的每篇论文, 对比其与离群论文集中其它每篇论文的匹配相似度.如果两者的相似度不小于阈值α , 把后者分配到前者所在的簇中; 否则不变.
详细过程如算法1所示, 算法中ξ 为一个可学习的权重参数, tanimoto(pi, pj)为2个序列的tanimoto相似度, 定义如下:
tanimoto(A, B)=
算法1 聚类算法
输入 Da, ε , min_samples, β
输出 C={c1, c2, …, ck}
initialize: Mark all node label[i:N]=unvisited;
while(∀ unvisited(p)) do
label(p)=visited;
if ε -neighbors(p)≥ min_samples then
newCluster C=[]; C=C+p;
for p' in ε -neighbors(p) do
if label(p')=unvisited then
label(p')=visited;
end if
if ε -neighbors(p')≥ min_samples then
C=C+ε -neighbors(p');
end if
if p∉∀ C then
C=C+p'
end if
end for
else label(p)=noise;
newCluster C* =[]; C* =C* +p;
end if
end while
for p in C* do
if MatchRules(C', p)> β then
C'=C'+p;
else newCluster C=[]; C=C+p;
end if
end for
return Set(C);
生成离群论文的原因是这部分论文特征缺失或不够明显, 造成与其它论文之间的相似度较小, 或这些论文本身就属于一个论文数较少的作者.实验显示处理这些情况的论文使用上述表征向量学习方法的效果不如直接使用特征匹配的方法.
经过聚类操作, 将离群论文集中的论文也分配到各自的簇中, 得到所有论文的聚类结果, 这个聚类结果就是本文算法框架对于某个待消歧名字的最终消歧结果.
基于SGNS(Skip-Gram Negative Sampling)的网络模型, 可有效处理新增论文集.首先将每次新增待消歧论文集的行为看作是不同t时刻的网络结构调整.对于一个姓名a需要消歧, 在t0时刻学习它的m篇现有论文集合
D0={p1, p2, …, pm},
得到聚类结果
C0={c1, c2, …, ck}.
假设需要对姓名a的新增m* 篇论文{pm+1, pm+2, …, pm+m* }进行消歧, 把它们分配给不同的作者.根据新增论文集|m* |的大小, 提出如下2种训练策略.
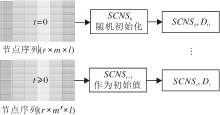
1)实时更新.将新论文作为节点, 添加到上一个时刻构建的PHNet Gt-1中, 根据定义3添加关系.基于新的PHNet Gt, 不需要对所有节点独立生成随机游动, 这是一个耗时的过程.只需要依次选择每个新论文节点作为初始节点生成新路径, 通过1.2节的随机游走策略生成用于训练每个节点嵌入的节点对(vi, vj).将上述修改后的DeepWalk, 即一种可伸缩的静态网络嵌入方法, 进一步扩展到如图4所示的动态方式[34], 形式化为
Dt=
其中, SGNSt-1为上一时间训练好的模型, Dt为通过索引直接从新训练好的SGNSt中获取的当前嵌入矩阵, Δ ξ t为Gt与Gt-1之间的差异, 即新增待消歧的论文集.
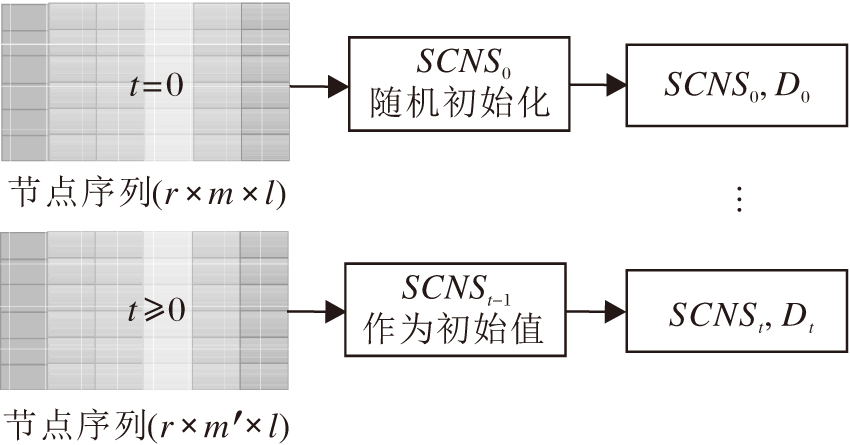 | 图4 实时训练策略Fig.4 Real-time training strategy |
2)增量训练.在此策略中, 更新PHNet Gt后, 通过依次选择Gt中的全部论文节点作为初始节点, 生成节点序列路径, 使用这些路径训练网络嵌入模型,
最大化概率p(pc|pi, θ ), 得到最新的论文表示:
Dt=f(SGNSt-1, Δ ξ , SGN
使用上一时间训练好的SGNSt-1与Gt-1中的节点进行初始化, 对Δ ξ t新增节点的初始化方法与SGN
这2种增量更新策略在实践中可交替使用.如果一次添加少量论文, 优先使用实时更新策略学习新论文的表示.如果新增论文的数量大于预先设定的阈值, 可选择增量训练策略, 即在更新的PHNet G上对新路径进行采样, 逐步训练模型, 到达合适的精度.
本文使用biendata竞赛平台的OAG-WholsWho比赛的真实数据集进行测试, 验证算法的有效性.OAG-WholsWho是biendata针对姓名消歧任务发布的竞赛, 竞赛提供两部分数据集, 分别是训练数据集(有标签, 221个歧义姓名, 205 498篇文献)和测试数据集(无标签, 50个歧义姓名, 41 052篇文献), 具体的数据格式如表1所示.
| 表1 OAG-WhoIsWho数据格式 Table 1 OAG-WholsWho data format |
参赛队伍需要利用训练数据集设计、训练和验证方法, 针对测试数据集提交一份消歧结果, 最终共有131支队伍提交有效结果.
所有实验均在Windows系统环境中完成, 具体配置为Inter Core i7-7700U CPU (3.6 GHz), 20 GB内存.
本文采用准确率(P)、召回率(R)和F1值评估姓名消歧算法的性能, 计算方法如下:
P=
R=
F1=
其中, P表示所有同名作者的论文被正确预测数量占有效聚类簇中论文的比例, R表示所有同名作者的论文正确预测占所有论文的比例.
每种方法只使用论文的3个特征(标题、作者、机构), 所以有些对比算法的性能略低于它们自己的论文.这些对比方法采用不同的聚类策略.为了公平对比, 假设簇数为实数, 选择具有噪声的基于密度的聚类方法(Density-Based Spatial Clustering of App-lications with Noise, DBSCAN)作为聚类方法.使用成对的F1评分[31]评价聚类结果.计算在每个数据集上的全局F1得分, 它是所有歧义姓名消歧结果的F1得分平均值.对比方法如下.
1)DeepWalk[17].基于随机漫步学习潜在节点表示的网络嵌入方法, 只适用于均匀非加权网络.
2)LINE[22].保持节点的一阶和二阶近似, 适用于均匀加权网络.
3)Metapath2Vec[24].适用于具有二进制边的异构网络.使用基于元路径的随机游走, 构建节点的异构邻域, 利用异构跃函数模型执行节点嵌入.
4)使用全局结构信息学习图表示(Learning Graph Representations with Global Structural Information, GraRep)[35].使用矩阵分解的方法解决网络嵌入问题, 可处理带权的网络, 在学习网络表示的过程中整合网络的全局结构信息.
5)GraphSAGE[26].通过不同的聚合函数学习节点嵌入, 形成节点的本地邻居, 这与本文设计的结构类似, 但不同的是无监督损失函数, 不能用于异构网络.使用GCN模块作为GraphSAGE的聚合器.
6)Doc2Vec[23].无监督算法, 能从变长的文本中学习得到固定长度的特征表示.具有一些优点, 例如, 不用固定句子长度, 接受不同长度的句子作为训练样本.Doc2Vec预测一个向量, 表示不同的文档, 模型结构潜在地克服词袋模型的缺点
本文方法中有一些可调参数:网络嵌入方法学习率为10-3, 正则化系数λ =10-4, 权异构Skip-gram模型下上下文k的窗口大小设置为2, 使用的元路径方案为“ A-T-A-O-” .所有方法学习的表示向量的维数设为100.
其它方法的参数设置基于默认值或它们自己在论文中指定的值.经过多次重复实验, 确保实验结果可反映方法的性能.DBSAED中参数ε -邻域的距离阈值表示距离中心样本超过ε 的样本点不在ε -邻域内.通过在训练集上的实验发现, ε =0.4时, F1值最优.min_samples为样本点要成为核心对象所需的ε 邻域内包含样本数阈值, 根据不同的歧义姓名, 选择值为4, 5, 6.
各方法在OAG-WholsWho数据集上的F1值对比如表2所示.由表可见, 本文方法在具体姓名和多个姓名上的F1值最高, 这表明本文方法在姓名消歧任务中存在明显优势.本文方法的F1值最优表明通过基于异质网络嵌入和语义表示能学习到更高质量的论文表示.
| 表2 各方法在OAG-WhoIsWho数据集上的F1值对比 Table 2 F1 value comparison of different methods on OAG-WhoIsWho dataset |
在对比方法中, Deepwalk、Metapath2-Vec根据论文之间的关系构造论文网络图, 并使用基于网络嵌入的方法学习论文节点的表示, 忽略文本信息及论文之间的不同关系信息.LINE学习论文关系结构信息, 未考虑不同的关系权重和语义信息.相比Deepwalk、Mathpath2vec, LINE设计关系权值和元路径引导, 基于Skip-gram和随机游走的网络嵌入模型, 性能具有较大提升.GraphSAGE使用基于图卷积网络的编解码器模型, 但在同构图上不能提取包含各种关系类型的多层关系.本文方法性能优于GraphSAGE, 表明本文方法可将论文属性和论文之间的异构关系集成到嵌入中, 更适合此类作者姓名消歧任务.
3个歧义姓名(feng gao, hong xiao, xiaoyang zhang)的论文集在嵌入空间的t-分布随机邻域嵌入(t-Distributed Stochastic Neighbor Embedding, t-SNE)可视化结果如图5所示.由图可知, 在本文方法生成的聚类结果中, 绝大多数表示节点分配到正确的聚类中.
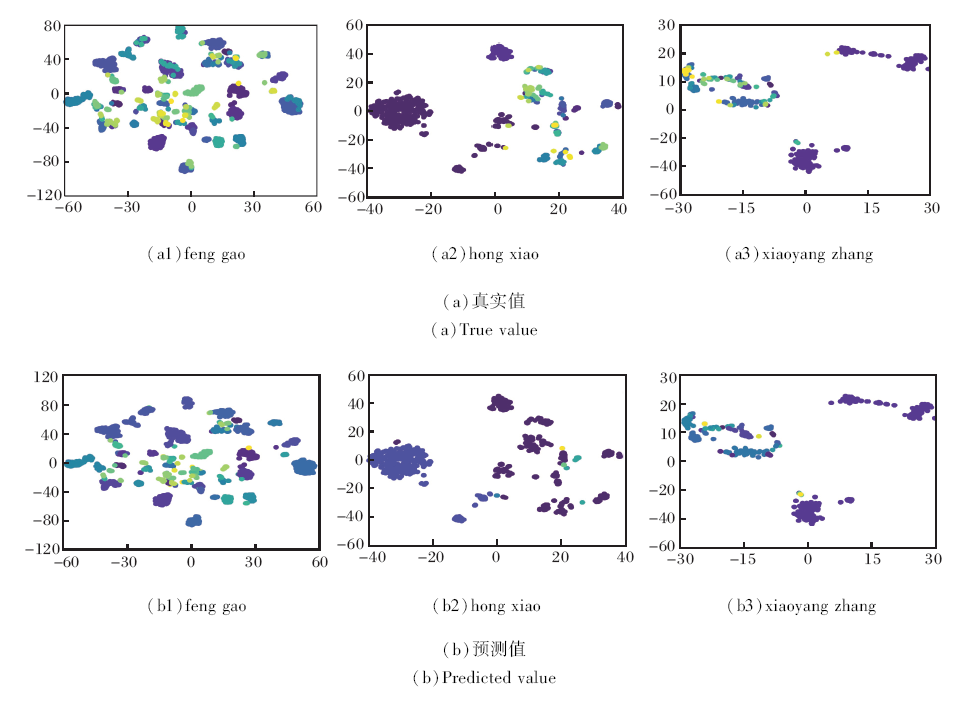 | 图5 三个歧义姓名的论文集在嵌入空间的t-SNE可视化Fig.5 t-SNE visualization of 3 essays with ambiguous names in embedding sapce |
为了验证本文方法各模块的有效性, 分别对不同模块的组合进行效果预测, 结果如图6所示.由图可知, 本文方法的每个模块对最终的预测都起到积极作用, 各模块之间融合效果较好, 说明模块之间的相容性.
 | 图6 本文方法中各模块的有效性分析Fig.6 Validity analysis of modules by the proposed method |
本文提出的聚类策略适用于不知道聚类数目的情况, 为了验证这一性质, 对比不需要预先指定聚类数的亲和传播、DBSCAN和Mean-Shift, 结果如表3所示.由表可见, 本文方法性能最优, 这是因为本文方法对论文的向量表示学习较优, 再结合基于规则匹配的DBSCAN, 可较好地从表示中提取论文之间的社区关系, 找到较好的论文划分结果.如表3所示, 本文方法的均方误差(Mean Square Error, MSE)为2.1, 平均绝对百分比误差(Mean Absolute Percentage Error, MAPE)为16.6%, 这说明对于大多数歧异姓名, 聚类簇K都在合理的错误范围内.
| 表3 不同聚类方法对比 Table 3 Comparison of different clustering algorithms |
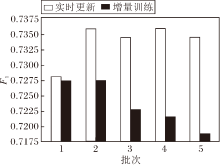
本文增量式消歧有2种策略:实时更新和增量训练.为了对比评价, 首先选择在OAG-WholsWho数据集上超过200篇论文的歧义名称, 将每个名称的论文集平均分成5批, 随机选择一批作为现有的论文, 使用本文方法获得聚类结果.分别采用2种增量式消歧策略, 按到达顺序分别处理剩余批次, 2种增量策略在2个数据集上F1值对比如图7所示.每次更新时计算均值.由图可见, 随着每批论文集的到来, 在实时更新策略下, F1值略有下降, 在增量训练中, 5个批次得分均保持在较高水平.结果表明, 对于一个小的新论文集, 实时更新比增量训练更省时, 是消除歧义的有效方法, 而增量训练策略在大的论文数据集上的效果更优.在实际应用中建议根据新增论文集的大小, 采用实时更新和增量训练两种策略的交替训练方法.
 | 图7 两种增量消歧策略的F1值对比Fig.7 F1 value comparison of 2 incremental disambiguation strategies |
本文提出基于异质网络表示学习的姓名消歧方法.首先, 根据歧义姓名的论文标题、合著作者、机构等信息, 为每个待消歧名称构建一个论文异质网络.然后, 通过自定义的加权异构Skip-gram模型结合Word2Vec语义表示学习对论文节点进行表征学习.最后, 通过规则聚类将论文划分给不同姓名实体.实验表明, 本文方法可同时考虑论文内容属性和相关网络结构, 学习到更高质量的论文节点表示, 针对动态增加的论文数据, 提出的增量消歧也是有效的.今后计划进一步改进方法, 为每篇论文提取更完整的信息, 如引用关系、邮件地址、从属关系等, 提高论文之间的相关性, 更准确地消除同名作者之间的歧义.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|