



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于注意力机制的多尺度空洞卷积神经网络模型
[汪璟玢1  , 赖晓连
, 赖晓连1 , 雷晶1 , 张璟璇1 ]
, 赖晓连, 雷晶, 张璟璇]
|
|



作者简介:

赖晓连,硕士研究生,主要研究方向为知识图谱、关系推理、知识表示.E-mail:2668136613@qq.com.

雷晶,硕士研究生,主要研究方向为知识图谱、关系推理、知识表示.E-mail:1084961608@qq.com.

张璟璇,硕士研究生,主要研究方向为知识图谱、关系推理、知识表示.E-mail:980807745@qq.com.
现有的时间知识图谱表示方法不能较好地捕获四元组内的复杂关系,而基于神经网络的模型大都无法建模随时间变化的知识,不能捕获丰富的特征信息,实体和关系间的交互性也较差.因此,文中提出基于注意力机制的多尺度空洞卷积神经网络模型.首先利用长短期记忆网络获得时间感知的关系表示.再利用多尺度空洞卷积神经网络提高四元组的交互性.最后,使用多尺度注意力机制捕获关键特征,提高模型的补全能力.在多个公开时间数据集上的链路预测实验表明,文中模型性能较优.
About Author:
LAI Xiaolian, master student. Her research interests include knowledge graph, relation reasoning and knowledge representation.
LEI Jing, master student. Her research interests include knowledge graph, relation reasoning and knowledge representation.
ZHANG Jingxuan, master student. Her research interests include knowledge graph, relation reasoning and knowledge representation.
The existing temporal knowledge graph representation methods cannot capture the complex relationships within quadruple well. Most of the neural network based models are unable to model time-varying knowledge and capture rich feature information. Moreover, the interaction between entities and relations in these models is poor. Therefore, a multi-scale dilated convolutional neural network model based on attention mechanism(MSDCA) is proposed. Firstly, a time-aware relation representation is obtained using long short-term memory. Secondly, a multi-scale dilated convolutional neural network is employed to improve the interactivity of the quadruple. Finally, a multi-scale attention mechanism is utilized to capture critical features to improve completion ability of MSDCA. Link prediction experiments on multiple public temporal datasets show the superiority of MSDCA.
本文责任编委 林鸿飞
Recommended by Associate Editor LIN Hongfei
知识图谱(Knowledge Graph, KG)是由节点和边组成的语义网络, 节点表示实体, 边表示实体间的关系.虽然知识图谱中存储着大量的知识, 但这些知识并不是完全正确的, 因为它们仅在特定的时间段内才有效.时间信息是提高知识补全性能的重要因素, 由此产生时间知识图谱(Temporal KG, TKG).
时间知识图谱以四元组的形式存储事实, 四元组中变量分别表示实体、关系和时间.目前常用的时间知识图谱有综合危机预警系统(Integrated Crisis Early Warning System, ICEWS)[1]、有关事件、位置和音调的全球数据(Global Data on Events, Location and Tone, GDELT)[2]、社区创建的维基百科知识库(The Community-Created Knowledge Base of Wiki-pedia, Wikidata)[3]、多语言维基百科的知识库(A Knowledge Base from Multilingual Wikipedias, YAGO3)[4]等.虽然知识图谱中包含大量知识, 但是知识图谱仍然是不完备的, 需要补全知识图谱.
知识图谱补全(KG Completion, KGC)旨在利用已有的知识补全知识图谱中缺失的信息(实体或关系).为了补全知识图谱, 知识表示学习(Knowledge Representation Learning, KRL)也可称为知识图谱嵌入(KG Embedding, KGE), 这是一种可靠、有效的知识补全技术, 将实体和关系映射到低维向量空间中.Bordes等[5]提出平移嵌入模型(Translating Embe-dding, TransE), 将关系看作头实体到尾实体的一个平移变换.Yang等[6]提出DistMult, 将实体和关系看作张量或矩阵, 并把关系简化为对角矩阵, 解决参数过多问题, 再将实体与关系相乘的结果作为三元组的得分.Kazemi等[7]认为规范的多元(Canonical Polyadic, CP)分解为每个实体学习的2个嵌入向量应是相互依赖的, 由此提出简单嵌入模型(Simple Embedding, SimplE), 在计算三元组得分时同时考虑实体和关系的2个向量.在欧拉恒等式的启发下, Sun等[8]提出旋转嵌入模型(Rotation Embedding, RotatE), 将关系看作复数空间中从头实体到尾实体的旋转.上述模型都建立在静态知识图谱上, 不考虑时间信息, 因此无法建模随时间变化的知识.
近年来, 学者们开始关注卷积神经网络(Con-volutional Neural Network, CNN).CNN学习非线性特征, 用于捕捉复杂的关系.受CNN的启发, 学者们将其应用于KGC, 如卷积二维知识图嵌入(Con-volutional 2D KGE, ConvE)[9], 交互嵌入(Interaction Embedding, InteractE)[10]等, 将卷积核作用于关系和实体拼接的矩阵中, 获取特征信息, 在静态知识图谱补全任务中取得较优结果.但上述方法仍存在一些问题:1)模型不考虑时间, 不能有效建模随时间变化的知识.2)模型使用单个尺度卷积核, 不能从不同感受野(即特征映射上的一个点对应输入图上的区域大小)中获取信息, 只能提取局部特征, 不可避免地丢失一些重要信息, 导致模型不能获取丰富的特征信息, 实体与关系之间的交互性较差.
现有的时间知识图谱嵌入模型(Temporal KGE, TKGE)能建模随时间变化的知识, 在时间知识图谱补全任务中表现出较优性能.Jiang等[11]提出时间感知的平移嵌入模型(Time-Aware TransE, TTransE), 在TransE的基础上, 增加时间的一致性约束.Dasgupta等[12]提出基于超平面的时间感知知识图嵌入模型(Hyperplane-Based Temporally Aware KGE, HyTE), 为每个时间定义一个时间超平面, 将实体和关系投影到时间超平面上.Garcí a-durá n等[13]提出通用的时间感知框架— — TA模型(Temporal-Aware Model), 通过长短期记忆网络(Long Short-Term Memory, LSTM)将时间信息融合到关系嵌入中, 得到时间感知的关系嵌入, 利用得到的嵌入表示, 运用到各种模型中.代表模型是时间感知的DistMult(Temporal-Aware DistMult, TA-DistMult), 在时间知识图谱补全任务中取得一定效果.Goel等[14]在历时词的启发下提出基于历时词嵌入的模型(Model Based on Diachronic Embedding, DE-模型), 这是一种历时实体嵌入的方法, 将时间信息融合到实体嵌入中.代表模型是基于历时词嵌入的SimplE模型(SimplE Based on Diachronic Embedding, DE-SimplE).Xu等[15]提出时间旋转模型(Temporal Rotation, TeRo), 将实体嵌入的时间演化定义为实体在复数空间中从初始时间到当前时间的旋转, 模型结合RotatE的优势, 可建模实体间的复杂关系(如自反关系), 也可处理各种形式的时间戳.
现有的时间知识图谱中的关系可根据头尾实体的数量划分为一对一(1-to-1)、一对多(1-to-N)、多对一(N-to-1)和多对多(N-to-N)4种关系类型.在时间知识图谱中, 后3种关系类型占据大部分, 这说明知识图谱中存在许多语义相似的实体.TKGE大都基于平移模型或语义匹配模型, 利用简单、快速的平移变换或乘法操作建模实体、关系和时间之间的关系, 只能学习到较浅层的特征信息, 导致模型不能较好地捕获实体、关系和时间三者间的复杂关系, 无法正确辨别语义相似的实体, 造成模型整体表现力下降.
针对上述问题, 本文在模型中引入时间信息, 令模型可建模随时间变化的知识.考虑到CNN在捕捉复杂关系上具有一定的优越性, 能有效缓解平移模型和语义匹配模型只能学习到较浅层特征的问题, 同时受“ 在我们的视觉皮层中, 同一区域中神经元的感受野大小是不同的, 这使得神经元可在同一处理阶段收集多尺度空间信息[16]” 的启发, 本文使用多尺度CNN获取多尺度特征信息, 扩大实体、关系和时间之间的交互性, 捕获三者间的复杂关系, 获得深层次特征信息, 提升模型性能.虽然多尺度CNN可捕获不同感受野的信息, 但不同尺度卷积核捕获的特征信息对模型的作用并不相同.因此, 本文引入注意力模块, 调整不同尺度卷积核获取的特征权重, 为模型捕获关键特征.另外, 在多尺度CNN中, 随着卷积核大小的增大, 不同尺度卷积核数量增多, 模型参数量和计算量剧增.为了解决这一问题, 本文引入空洞卷积代替标准卷积, 允许模型有效扩大感受野, 几乎不增加参数量和计算量.
综上所述, 本文提出基于注意力机制的多尺度空洞卷积神经网络模型(Multi-scale Dilated CNN Model Based on Attention Mechanism, MSDCA).首先, 将时间融入模型, 利用LSTM将时间信息编码到关系表示中, 得到融合时间信息的关系表示, 并将二维变换后的实体和关系进行拼接, 作为多尺度空洞卷积神经网络的输入.然后, 利用多尺度空洞卷积神经网络获取多尺度特征信息, 增强四元组内部的交互性.最后, 通过注意力机制调整不同尺度卷积核提取的特征映射的权重, 为模型捕获关键有效的特征, 提高模型性能.在5个公开的时间数据集上进行的链路预测实验表明, 本文模型性能较优.
本文将时间知识图谱TKG定义为G={E, R, T, F}, 其中, E为实体的集合, R为关系的集合, T为时间戳的集合, F为知识的集合.对于四元组(s, r, o, t)∈ F, s∈ E表示头实体, o∈ E表示尾实体, r∈ R表示关系, t∈ T表示时间戳.使用r∈
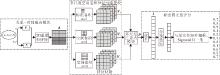
基于注意力机制的多尺度空洞卷积神经网络模型(MSDCA)总体框架如图1所示.
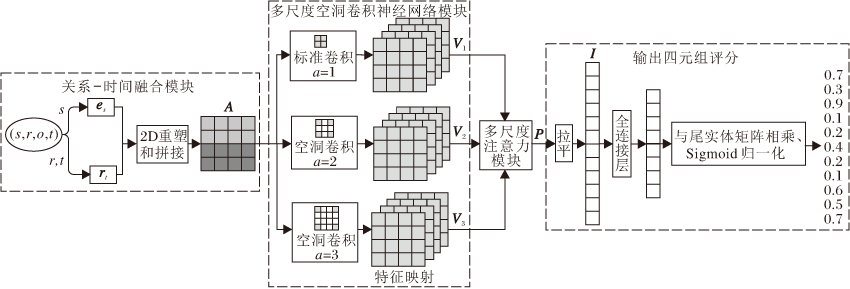 | 图1 MSDCA整体框图Fig.1 Overall framework of MSDCA |
MSDCA主要由4部分组成.1)关系-时间融合模块.对于输入的四元组(s, r, o, t), 将r的初始化特征向量r和时间戳t的时间序列向量(τ 1, τ 2, …, τ m)输入LSTM中, 学习时间感知的关系表示rt, 将rt与头实体的向量表示es进行2D重塑, 拼接得到矩阵A.2)多尺度空洞卷积神经网络模块.将A输入多尺度空洞卷积神经网络中, 调整卷积核的空洞率, 获取不同尺度的卷积核, 将不同尺度的卷积核作用于输入A, 得到多尺度特征映射V1、V2、V3.3)多尺度注意力模块.将多尺度特征映射输入多尺度注意力模块中, 计算不同尺度卷积核提取的特征映射的权重, 经过一系列操作后得到加权后的特征映射P.4)输出四元组评分.将得到的带有权重的特征映射P拉平成向量I, 经过全连接层, 映射到实体嵌入维度, 最后与尾实体矩阵进行点积, 并经过Sigmoid函数进行归一化, 得到四元组的评分.
LSTM在建模序列数据时具有一定优势, 因此本文使用LSTM建模时间序列和关系之间的特征表示.给定四元组(s, r, o, t), 时间戳t将根据年月日划分成时间序列.时间戳t有时间点和时间段2种形式.如果t是一个时间点, 如“ 2020-12-29” , t被划分成长度为3的时间序列, 即seq={2020, 12, 29}.如果时间戳t是一个时间段, 如“ [2010-05-12, 2020-##-##]” , t被划分成长度为6的时间序列, 即seq={2010, 05, 12, 2020, ##, ##}.时间序列的向量表示为
tseq={τ 1, τ 2, …, τ m}∈ Rd× m,
τ i∈ Rd, i=1, 2, …, m,
其中, m表示时间序列的长度, d表示时间序列的嵌入维度.将关系表示和时间序列的向量表示组合成LSTM的输入序列, 即X={r, τ 1, τ 2, …, τ m}.
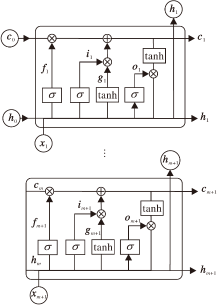
将X输入LSTM中, 得到融合时间信息的关系表示rt, LSTM结构如图2所示.
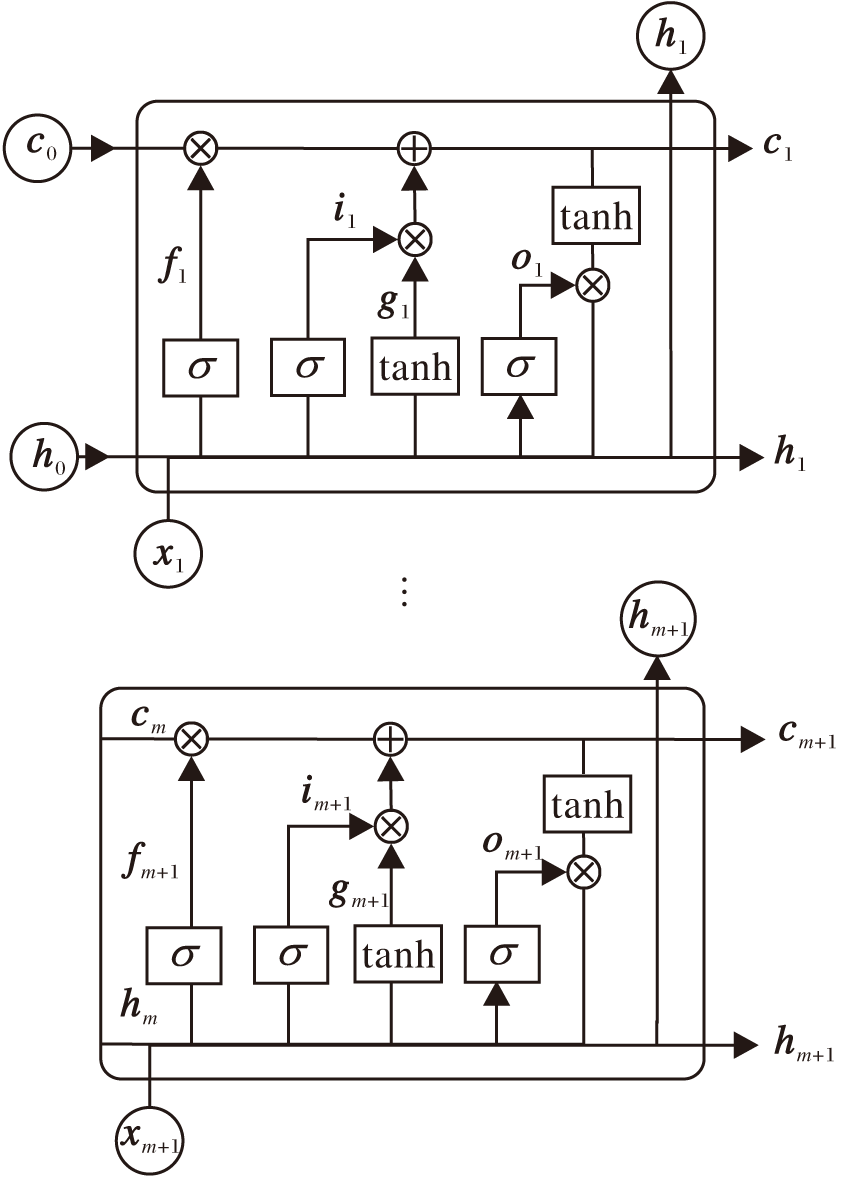 | 图2 LSTM结构图Fig.2 Structure of LSTM |
本文采用与文献[13]相同的公式:
in=σ (hn-1Ui+xnWi),
fn=σ (hn-1Uf+xnWf),
on=σ (hn-1Uo+xnWo),
gn=tanh(hn-1Ug+xnWg),
cn=fn°cn-1+in°gn,
hn=on°tanh(cn).
其中:xn为输入序列X的第n个元素的表示; in、 fn、on分别为第n个元素的输入门、遗忘门、输出门; gn为中间变量; Ui、Uf、Uo、Wi、Wf、Wo为变换矩阵; cn、hn分别为第n个元素的单元表示和隐藏状态表示; c0、h0初始化为0; σ 为激活函数.将LSTM最后一层的隐藏状态表示作为最终关系的表示, 即rt=hm+1.
此后, 将融合时间信息的关系嵌入rt与头实体嵌入es进行形状变换操作(Reshape), 得到2D嵌入表示
A=[
关系-时间融合模块的框图如图3所示.
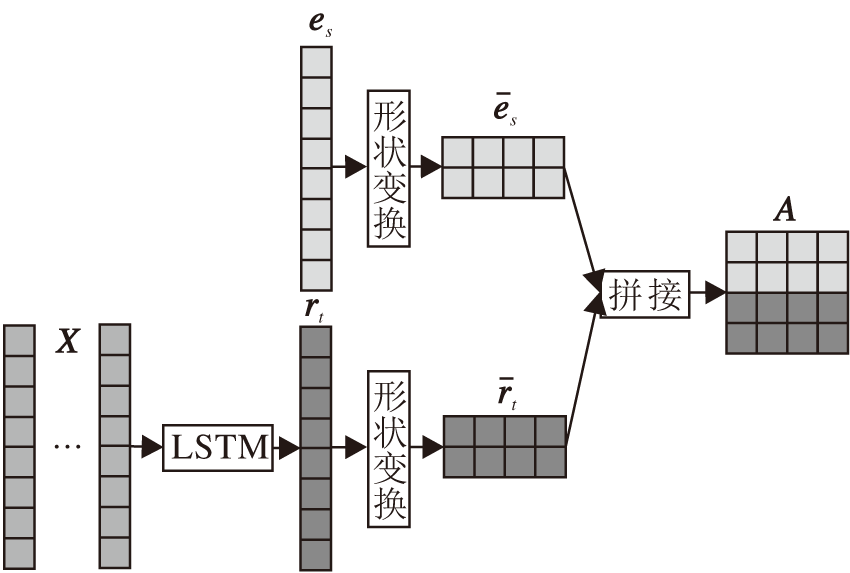 | 图3 关系-时间融合模块Fig.3 Relation-time fusion module |
多尺度卷积神经网络需要在同阶段使用不同尺度的卷积核, 为了避免由此带来的参数量和计算量过多的问题, 本文使用空洞卷积获取多尺度信息.
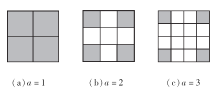
空洞卷积通过设置空洞率, 即卷积核中填充的空格数, 增大卷积核的大小.如图4所示, 对于一个2× 2的卷积核:(a)为空洞率a=1的空洞卷积, 即标准卷积, 标准卷积是空洞卷积的一个特例; (b)为空洞率a=2的空洞卷积, 此时卷积核大小放大为3× 3, 图中白色部分为填充的空洞部分, 填充内容为0.同理, (c)的卷积核扩大为4× 4.文献[17]中定义空洞卷积的等效卷积核大小:
k'=k+(k-1)(a-1),
其中, k为标准卷积核的大小, a为空洞率.
 | 图4 不同空洞率的卷积核Fig.4 Convolution kernels with different dilation rates |
空洞卷积通过设置空洞率改变卷积核的大小, 但由于填充部分数值为0, 实际参与计算的仍是图4中的灰色部分, 因此计算量和参数量没有增大, 但是感受野会随空洞率的变化而变化, 通过改变空洞率可获取不同感受野的信息.
给定四元组(s, r, o, t), 通过1.1节方式, 得到融合时间信息的矩阵A=[
V
其中, * 为卷积操作, f(· )为激活函数, 如Relu等, bi为偏置.由此得到输入A经过不同尺度卷积核提取的特征映射:
V1∈
考虑到不同尺度卷积核提取的特征信息对模型的作用不同, 如果不加区分地使用这些特性信息, 可能会给模型带来噪声, 因此本文引入注意力机制, 帮助模型自适应地调整多尺度特征信息的权重.基于选择性核心网络(Selective Kernel Network, SKNet)[16]的多尺度注意力模块框图如图5所示, 主要包括特征聚合和特征选择两个部分.其中, 特征聚合部分将1.2节得到的多尺度特征映射V1、V2、V3经过一系列操作得到聚合后的特征映射z.特征选择部分根据z生成多尺度特征映射对应的权重, 为模型选择最关键有效的特征信息.
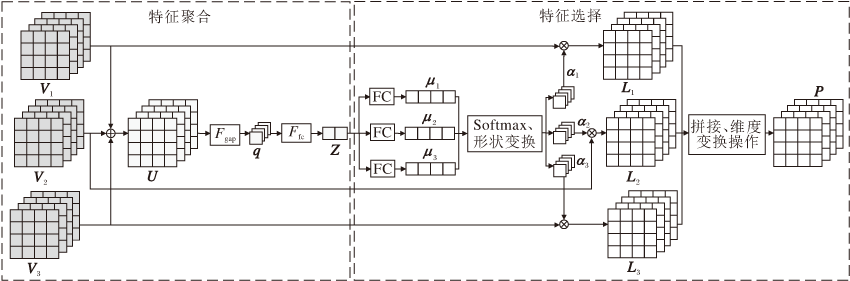 | 图5 多尺度注意力模块框图Fig.5 Framework of multi-scale attention module |
1.3.1 特征聚合
如图5所示, 输入有3个分支, 表示3种不同尺度的卷积核提取的特征映射, 将3个分支上的特征映射按位相加, 得到聚合后的特征映射
U=V1⊕V2⊕V3.
在每个通道使用全局平均池化Fgap获取全局信息q∈ RC× 1× 1, C表示特征映射的通道个数.q的第c(c=1, 2, …, C)个元素表示为
qc=Fgap(Uc)=
其中, Uc系特征映射U的第c个通道的表示.
将获取的全局信息q通过全连接层Ffc, 得到压缩的特征表示:
z=Ffc(q)=W1(reshape(q))+b1∈
其中:reshape(· )为形状变换函数, 将q变为C× 1大小以便于乘法操作; C1为压缩后的维度; W1∈
1.3.2 特征选择
将压缩后的特征表示z经过全连接层FC映射到压缩前的维度:
μ 1=W2z+b2, μ 2=W3z+b3, μ 3=W4z+b4.
其中:W2∈
将μ 1、 μ 2、 μ 3经过Softmax函数, 得到特征映射V1、V2、V3对应的权重:

其中, reshape(· )函数将归一化后, 形状为C× 1的权重变为C× 1× 1.将得到的权重与对应特征映射进行元素乘法操作, 得到特征映射:
Li=Viⓧα i, i=1, 2, 3.
加权后的特征映射通过简单的拼接, 经过变换矩阵映射到指定维度, 得到最终的多尺度融合特征:
P=σ (W5[L1; L2; L3]+b5)∈
其中, σ 为激活函数, W5为变换矩阵, b5为偏置.
将多尺度注意力模块计算得到的特征映射P经过拉平操作变成向量I=vec(P)∈ R2dC.经过全连接层, 将拉平后的向量映射到指定维度.与尾实体嵌入进行点积, 得到四元组的得分.MSDCA的得分函数定义为
F(s, r, o, t)=f(IW6+b6)eo,
其中, f(· )为激活函数Relu, W6∈ R2dC× d为全连接层的变换矩阵, b6为偏置, 利用Sigmoid函数(将得分映射到[0, 1]区间), 得到候选实体的概率分布:
p(o|s, r, t)=sigmoid(F(s, r, o, t)).
本文使用交叉熵损失函数训练模型, 损失函数定义如下:
Loss=-

其中, N为实体个数, G为正确的四元组的集合, G'为通过随机替换头尾实体得到的不正确的四元组的集合.
本文在如下5个时间数据集上进行实验:Garcí a-Durá n等[13]生成的ICEWS14、ICEWS05-15数据集; Trivedi等[18]生成的GDELT数据集; Das-gupta等[12]生成的YAGO11k、Wikidata12k数据集.各数据集统计信息如表1所示.
| 表1 实验数据集 Table 1 Experimental datasets |
在模型训练过程中, 本文使用自适应低阶矩估计优化器(Adaptive Estimates of Lower-Order Mo-ments, Adam)并利用网格搜索策略为模型寻找合适的参数大小.
为了防止模型过拟合, 在卷积之前添加dropout1, 卷积完成后添加dropout2, 全连接层之后添加dropout3.本文利用符合正态分布的随机数对模型参数初始化.MSDCA的参数设置范围与最终调参结果如表2所示.
| 表2 模型参数范围和调参结果 Table 2 Model parameter ranges and tuning results |
本文对比的基线模型可划分为2种类型:1)未融合时间信息的知识表示模型, 包括平移模型TransE、语义匹配模型DistMult和SimplE、复数模型RotatE、神经网络模型InteractE; 2)融合时间信息的知识表示模型, 包括基于平移模型的TTransE和HyTE、时间融合框架的代表模型TA-DistMult和DE-SimplE、基于RotatE的TeRo.
本文使用链路预测[19]评估模型性能, 包括头实体预测和尾实体预测.头实体预测即给定尾实体、关系和时间, 预测头实体, 表现为(?, r, o, t).同理, 尾实体预测即给定头实体、关系和时间, 预测尾实体, 表现为(s, r, ?, t).对于每个四元组(s, r, o, t), 本文采用文献[5]策略:通过随机替换头实体或尾实体生成新的四元组, 并过滤新生成的四元组集合中已存在于训练集、验证集和测试集的四元组.在测试和验证过程中, 使用1-n的评分策略, 提高模型测试和验证的效率.
本文将广泛使用的4种评估指标用于评估模型的有效性:平均倒数排名(Mean Reciprocal Rank, MRR), 测试集正确实体排名前1的比例(Top 1 Ratio, Hits@1), 测试集上正确实体排名前3的比例(Top 3 Ratio, Hits@3), 测试集上正确实体排名前10的比例(Top 10 Ratio, Hits@10).采取文献[10]策略, 结果是5次实验的平均值.
各模型的链路预测结果如表3和表4所示, 表中黑体数字表示最优结果, 斜体数字表示次优结果.表3中TransE、DistMult、SimplE、TTransE、HyTE、TA-DistMult、DE-SimplE结果取自文献[14]; 在ICEWS14、ICEWS05-15数据集上, RotatE、TeRo结果取自文献[15], InteractE是将源码应用于新的数据集的结果; 在GDELT数据集上, InteractE、TeRo是将源码应用于新的数据集的结果.在表4中, TransE、DistMult、RotatE、TTransE、HyTE、TA-DistMult、TeRo结果取自文献[15], InteractE的结果是将源码应用于新的数据集.
| 表3 各模型在3个数据集上的链路预测结果 Table 3 Link prediction results of different models on 3 datasets |
| 表4 各模型在2个数据集上的链路预测结果 Table 4 Link prediction results of different models on 2 datasets |
由表3、表4可得到如下结论.MSDCA总体上最优, 有效验证MSDCA在补全任务上的优势.具体地说, 在GDELT数据集上, 对比DE-SimplE、TeRo, MSDCA在MRR值上分别提高35.7%, 28.9%, 在Hits@1值上分别提高52.5%, 40.5%, 在Hits@3值上分别提高39.1%, 31.7%, 在Hits@10值上分别提高25.1%, 21.2%.这是因为MSDCA使用的多尺度空洞卷积神经网络能有效捕获实体、关系和时间三者之间的复杂关系, DE-SimplE、TeRo将融合时间信息的实体表示与关系表示进行乘法操作和平移变换, 不能较好地捕获它们之间的非线性特征.
MSDCA在各数据集上的实验效果显著优于同样利用CNN的InteractE.这是因为, MSDCA的多尺度空洞卷积神经网络能有效增加四元组内的交互, 捕获更丰富的特征信息, 多尺度注意力模块能提取更关键有效的特征信息.此外, MSDCA融合时间信息, 能建模随时间变化的知识.
考虑到YAGO11k、Wikidata12k数据集上存在大量时间信息缺失或时间信息不完整的数据, 本文将时间戳简化为[开始年份, 结束年份]的格式, 即仅考虑年份信息, 此模型简记为MSDCA(-md).由表4可看出, 在Wikidata12k数据集上, MSDCA(-md)性能优于MSDCA, 这是因为Wikidata12k数据集的237个时间戳都不包含月和日信息, 仅考虑年份信息, 可避免在LSTM编码阶段输入无用的月、日信息, 不会为模型添加噪声.在YAGO11k数据集上, MSDCA(-md)的性能略低于MSDCA, 这是因为YAGO11k数据集的一些时间戳包含月、日信息, 填充缺失的时间信息虽然会给模型带来一定的噪声, 但充分使用数据中的时间信息为模型带来的效益大于噪声的影响.在YAGO11k数据集上, MSDCA各项指标值低于TeRo, 这是因为LSTM对输入较敏感, 而YAGO11k数据集的时间信息缺失较严重, 这就意味着填充的数据较多, 噪声加得越多, 对模型的影响就越大.TeRo将一个或多个时间戳通过时间粒度表示为一个时间表示, 这在很大程度上减轻模型对缺失时间的敏感程度.虽然在YAGO11k数据集上, MSDCA效果不如TeRo, 但也优于其它基线模型.
为了进一步分析模型性能, 在不同类型的关系上进行实验.使用文献[5]方法对数据集中的关系进行统计分类:计算每个关系的平均头尾实体个数, 如果一个关系的平均头实体(平均尾实体)个数小于1.5, 标记为1, 否则标记为N.由此将测试集划分成4个子集:1-to-1关系、1-to-N关系、N-to-1关系、N-to-N关系.
在ICEWS05-15数据集上进行不同关系类型的链路预测实验, 不同关系类型链路预测结果如表5所示, 表中黑体数字表示最优结果, 斜体数字表示次优结果.由表可见, 在N-to-N复杂关系类型实验上, 相比TeRo, MSDCA的MRR值提高12.6%, Hits@1值提高20.7%, Hits@3值提高8.4%, Hits@10值提高4.2%.
| 表5 ICEWS05-15数据集上不同关系类型的链路预测结果 Table 5 Link prediction results of different relationship types on ICEWS05-15 dataset |
从实验结果可看出, MSDCA在各种关系类型上的链路预测效果都最优, 这得益于模型的多尺度空洞卷积神经网络和多尺度注意力模块, 有效增大四元组内部的交互性, 捕获关键的特征信息, 提高模型的表达能力.实验结果也证实TA-DistMult、DE-SimplE、TeRo由于只能捕获四元组表层特征, 无法辨别语义相似的实体, 效果不佳, 而MSDCA能学习更深层的特征信息, 捕获实体、关系和时间三者间的复杂关系, 有效提高模型的区分能力, 提升模型性能.
为了进一步验证MSDCA能捕获深层特征, 具有较强的辨识能力, 对于2个相似的四元组(s1, r1, o1, t1)和(s1, r1, o2, t1), 分析不同模型中o1和o2嵌入的相似性.参照文献[15], 将实体间的相似性定义为2个实体向量表示的绝对差:
similarity=
similarity越小表示两个实体表示越相似, 模型对这2个实体的区分能力就越差.
ICEWS14数据集上“ 日本” 和“ 菲律宾” 2个实体在TeRo、DE-SimplE、MSDCA中相似性的可视化结果如图6所示.由于不同模型具有不同的嵌入维度d, 将实体的向量表示重塑为不同大小的矩阵.TeRo中d=1 000, 重塑为50× 20矩阵.DE-SimplE中d=136, 重塑为17× 8矩阵.MSDCA中d=200, 重塑为20× 10矩阵.
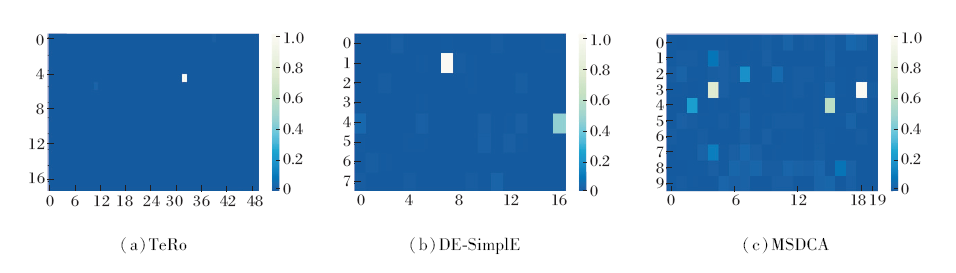 | 图6 各模型的相似性可视化结果Fig.6 Similarity visualization results for different models |
由图6可见, MSDCA能较好地区分“ 日本” 和“ 菲律宾” , 而DE-SimplE、TeRo中这2个实体的向量表示基本相同, 在进行补全任务时容易混淆这2个实体, 导致效果不佳.
为了验证MSDCA中每个模块的重要性, 在ICEWS14、ICEWS05-15数据集上进行实验.将移除关系-时间融合模块的模型记为MSDCA(-Time), 移除多尺度注意力模块的模型记为MSDCA(-A), 移除多尺度空洞卷积神经网络模块的模型记为MSDCA(-MSA).由于MSDCA(-MSA)去除多尺度空洞卷积神经网络, 此时的模型仅使用单尺度的卷积核, 所以多尺度注意力模块也随之消失, 此时的模型退化为最基础的模型, 等效于融合时间信息的ConvE.
为了确保评估的合理性, MSDCA(-Time)、MSDCA(-A)、MSDCA(-MSA)均采用与MSDCA相同的参数.
消融实验结果如表6所示, 表中黑体数字表示最优结果.
| 表6 消融实验结果 Table 6 Ablation experiment results |
由表6可看出, 时间-关系融合模块、多尺度注意力模块和多尺度空洞卷积神经网络模块都是MSDCA的重要模块, 尤其是时间-关系融合模块对模型影响很大.这是因为消除该模块后模型不能建模随时间变化的知识, 导致性能降低, 这进一步说明时间信息是提高知识图谱补全性能的一个不可或缺的重要信息.多尺度空洞卷积神经网络模块为模型带来的效益也较显著, 这是因为它能有效增强实体、关系和时间的交互, 从不同感受野中获取特征信息.多尺度注意力模块可区分多尺度特征的重要性, 使模型捕获对预测任务更有帮助的特征.
为了进一步验证多尺度注意力模块的作用, 在ICEWS05-15数据集上分析四元组中不同尺度卷积核提取的特征映射的权重, 结果如图7所示.图中横坐标表示四元组的编号, 考虑到四元组数量过于庞大, 任意选取其中的50个四元组.纵坐标a表示卷积核的空洞率, 横纵坐标对应的方块表示该四元组在此空洞率的卷积核作用下得到的特征映射的权重.颜色越深表示特征映射的权重越大.
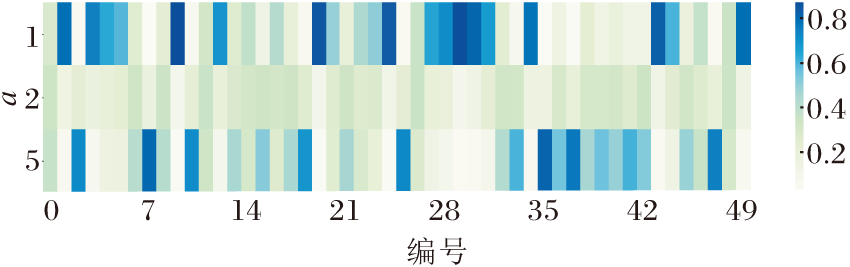 | 图7 不同尺度卷积核提取的特征映射权重Fig.7 Weights of feature maps extracted by different scale convolution kernels |
由图7可看出, 不同四元组间相同大小卷积核提取的特征映射权重不同, 同一四元组中不同大小卷积核提取的特征映射权重也不同.这说明模型可根据输入, 为多尺度特征信息动态分配权重, 让模型捕获关键特征.由图还可发现, a=1和a=5的卷积核提取的特征映射权重区分度较大, 说明这2个空洞率的卷积核学习每个四元组特有的信息, 对四元组较敏感.
为了验证时间融合策略的有效性, 将TA-DistMult、DE-SimplE处理时间的方法应用到MSDCA中, 记为TA-MSDCA和DE-MSDCA.实验结果如表7所示, 表中黑体数字表示最优结果.由表可见, 在ICEWS14、ICEWS05-15数据集上, MSDCA都取得较优效果, 表明MSDCA时间融合策略的有效性和合理性.TA-MSDCA结果低于MSDCA的原因是:TA-MSDCA将时间戳划分为“ 2y-0y-2y-0y-12m-2d-9d” 这种形式的token序列, 破坏年份和日期自身的整体性, 而MSDCA根据年月日对时间戳进行划分, 最大程度地保留它们的内在语义信息.另外, TA-MSDCA和DE-MSDCA的效果都优于TA-DistMult和DE-SimplE, 进一步表明基于注意力机制的多尺度空洞卷积神经网络的有效性.
| 表7 不同时间融合策略的结果 Table 7 Results of different time fusion strategies |
此外, 虽然DE-SimplE效果优于TA-DistMult, 但TA-MSDCA效果却优于DE-MSDCA.这是因为DE-MSDCA将时间信息融合到实体中, 但是MSDCA的输入不包含尾实体, 导致DE-MSDCA不能做到完全的实体感知时间, 而TA-MSDCA将时间信息融合到关系中, 能做到完全的关系感知时间.这些原因导致TA-MSDCA效果优于DE-MSDCA.
各模型在各数据集上的参数统计如表8所示.在ICEWS14、ICEWS05-15数据集上, MSDCA参数量会略多于DE-SimplE, 这是因为MSDCA使用CNN.参数量在各个数据集上与去除多尺度空洞卷积神经网络的MSDCA(-MSA)的参数量极其相近, 说明使用空洞卷积神经网络获取多尺度信息并不会过分增大模型的参数, 空洞卷积神经网络是模型获取多尺度信息的一种有效技术.相比TeRo, MSDCA除在YAGO11k数据集上参数量较多, 在其它数据集上都显著低于TeRo.MSDCA在YAGO11k数据集上的参数较多是因为不同尺度卷积核的数量过多, 在通过网格搜索策略获得的模型最优参数中C=160, 模型总体的卷积核数量高达480个.总体上, MSDCA以较少的参数获得更优结果.
| 表8 模型参数统计结果 Table 8 Statistical results of parameters M |
最后分析各模型的时间复杂度.基于静态知识图谱的知识表示模型TransE、DistMult、SimplE、RotatE的时间复杂度为O(d), d为嵌入维度.Inter-actE由于使用CNN, 时间复杂度为O(dk2C), 其中, k为标准卷积核的大小, C为卷积核的数量.基于时间知识图谱的知识表示模型TTransE、HyTE、DE-SimplE、TeRo的时间复杂度为O(d).TA-DistMult由于内部LSTM操作, 时间复杂度为O(d2).MSDCA由于内部LSTM及卷积操作, 时间复杂度为O(d2k2C).相比现有的TKGE, MSDCA时间复杂度较高.
本文提出基于注意力机制的多尺度空洞卷积神经网络模型(MSDCA).首先利用LSTM融合时间信息, 让关系感知时间.然后利用多尺度空洞卷积神经网络增加实体、关系和时间三者之间的交互性, 提取深层次语义特征.最后利用多尺度注意力模块提高特征质量, 为模型捕获更关键有效的特征, 提高模型表达能力.实验表明, MSDCA在链路预测任务上具有较好的鲁棒性.今后将进一步改进关系-时间融合方法, 进而改进模型在稀疏数据集上的表现.同时, 将进一步优化模型, 降低时间复杂度.另外, 将尝试在模型中融入外部信息, 如文本信息、图像信息等, 增强知识表示.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|