


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于图卷积神经网络的网络节点补全算法
[刘臣1  , 李自然
, 李自然1 , 周立欣1 ]
, 李自然, 周立欣]
|
|



作者简介:

刘臣,博士,副教授,主要研究方向为web数据挖掘、互联网用户行为分析、深度学习.E-mail:chenliu@usst.edu.cn.

李自然,硕士研究生,主要研究方向为网络补全、链接预测.E-mail:nature_liii0920@163.com.
网状数据结构通常获取的网络数据不完整,存在缺失节点.对此,文中提出基于图卷积神经网络的网络节点补全算法.首先对可观测网络进行成对采样,构造目标节点对的封闭子图和特征矩阵.然后利用图卷积神经网络提取子图及特征矩阵的表征向量,用于推断子图中的目标节点对之间是否存在缺失节点,同时判断不同目标节点对间的缺失节点是否为同一节点.最后,在真实网络数据集及人工生成的网络数据集上的实验表明,文中算法可较好解决网络补全问题,在缺失节点比例较大时仍能有效补全网络.
About Author:
LIU Chen, Ph.D., associate professor. His research interests include web data mi-ning, internet user behavior analysis and deep learning.
LI Ziran, master student. Her research interests include network completion and link prediction.
Aiming at the incomplete network data and missing nodes in graph data structure, a network node completion algorithm based on graph convolutional network is proposed. Firstly, the observed network is sampled in pairs to construct the closed subgraph and feature matrix of the target node pair. Then, the graph convolutional neural network is employed to extract the representation vectors of subgraphs and their feature matrices for two purposes. One is to infer whether there are missing nodes between target node pairs of each subgraph, and the other is whether the missing nodes between different target node pairs are the same node. Finally, experiments on real network datasets and artificially generated network datasets show that the proposed model can solve the problem of network completion well and recover the network even when half of the nodes in the network are missing.
本文责任编委 王士同
Recommended by Associate Editor WANG Shitong
从生物、社会、技术和信息系统中提取的网络数据通常不完整, 存在缺失的节点和边[1].这些不完整的数据资源会严重降低信息检索、用户行为分析和计算生物学等领域数据分析方法的性能[2, 3, 4].因此, 如何补全可观测网络中的缺失数据成为目前网络分析领域的关键问题之一.
目前, 学者们已对网络缺失数据的补全进行深入研究.根据缺失数据类型的不同, 研究可划分为网络边的补全(也称为链接预测)和网络节点的补全.链接预测问题的研究相对较多.Sarukkai[5]利用马尔科夫链进行链接预测和路径分析.Zhu等[6]在Sarukkai的基础上改进马尔科夫链, 提高链接预测的效率.Liben-Nowell等[7]采用启发式(Heuristic)方法, 计算节点相似性得分, 衡量节点间存在链接的可能性.Zareie等[8]基于公共邻居数和邻接矩阵之间的相关性推断网络中用户间的链接是否存在.网络中缺失节点的补全难度相对较高, 原因在于在补全缺失节点的同时还需要补全与已知节点间的缺失边.Kim等[9]提出KronEM, 结合Kronecker图模型与期望最大化(Expectation Maximization, EM)框架估计模型中的参数, 并推断网络缺失的节点和边.Guimerà 等[10]提出利用随机块模型捕获复杂网络中的结构特征, 识别网络中缺失部分.Eyal等[11]提出基于谱聚类的缺失节点识别算法(Missing Node Identification by Spectral Clustering, MISC), 利用链接预测中的节点相似性解决缺失节点识别问题.Forsati等[12]提出将转导阶段与补全阶段解耦(Decoupling)的算法, 利用节点的相似度信息和观测子网的大小补全网络.
随着人工智能的兴起, 学者们开始将图神经网络模型引入网络数据补全中, 尤其是图卷积神经网络(Graph Convolutional Network, GCN)[13, 14, 15, 16]的提出, 缓解补全算法时间复杂度较高、准确率较低的问题.Zhang等[17]将目标节点对的封闭子图按一定顺序编码为邻接矩阵, 将邻接矩阵输入神经网络模型, 推断目标节点对间存在链接的概率.Fan等[18]提出基于深度学习的矩阵补全方法, 补全网络中的缺失数据.Zhang等[19]提出将目标节点对的封闭子图和节点信息矩阵作为图神经网络的输入, 学习一般的图结构特征, 再根据图结构特征预测链接.Wei[20]基于深度度量学习, 提出利用节点属性与底层网络结构的相关性补全网络.Wang等[21]提出改进的空间图卷积网络模型, 对异构信息网络进行链接预测.Gao等[22]通过多输出图神经网络框架, 构造用户之间的新特征, 提高链接预测的性能.
网络节点补全的关键问题之一是如何判断哪些缺失节点实际上是同一节点的问题.在节点信息完全缺失的情况下, 大多数网络补全方法采用邻居节点的信息及节点之间的相似性推断缺失节点及缺失节点的特征信息.由于缺失节点的邻接节点数目未知, 通过不同数目的邻接节点推断得出的缺失节点并不相同, 即当一个缺失节点与多个已知节点之间存在边时, 通过不同数目的已知节点推断的缺失节点信息不同, 无法将各自推断的缺失节点认定为同一节点.这种情况的出现严重降低网络补全的准确性.
为了解决上述问题, 本文提出基于图卷积神经网络的网络节点补全算法(Network Completion Based on GCN, NCGCN).首先, 对可观测网络进行成对采样, 构造以目标节点对的封闭子图和特征矩阵为样本的训练数据集.然后, 将封闭子图及特征矩阵批量输入GCN, 学习图结构特征, 根据得到的图结构特征推断各子图中的目标节点对内是否存在缺失节点, 同时判断各不同目标节点对间的缺失节点是否是同一节点.在随机生成网络和真实网络上的实验表明, NCGCN具有良好的网络补全性能, 在缺失节点比例较大时仍能有效补全网络.
假设可观测网络GO=(VO, EO)为潜在完整网络GT=(VO∪ VM, EO∪ EM)的一个子集.VO={v1, v2, …, vn}为可观测网络中的节点集, n为可观测网络的节点数量, EO⊆VO× VO为已知节点间边的集合, VM为缺失节点的集合, EM为缺失边的集合.网络GO中已知节点间不存在缺失边, 缺失边仅为已知节点与缺失节点之间的链接, GO和GT是无自循环和重复边的无向网络.
网络补全通过可观测网络GO, 补全缺失的节点VM和相关的边EM, 使推断的网络
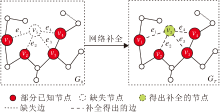
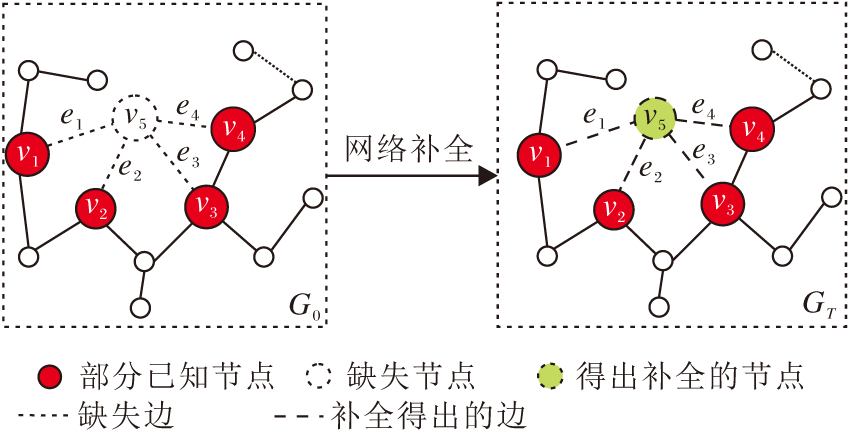 | 图1 网络节点补全问题示例Fig.1 Example of network node completion |
由图1可观测到网络GO中存在一个缺失节点v5, v5与已知节点v1、v2、v3、v4间有缺失的边e1、e2、e3、e4.为了补全网络中缺失的部分, 首先通过GO中可观测节点的信息推断节点对(v1, v2)、(v2, v3)、(v3, v4)、(v1, v4)间均存在一个缺失节点.然后进一步推断(v1, v2)、(v2, v3)、(v3, v4)、(v1, v4)间缺失的节点是同一节点v5, 补全网络中缺失的边e1、e2、e3、e4, 得到完整的网络GT.
本文提出基于图卷积神经网络的网络节点补全算法(NCGCN), 补全网络中缺失的节点和边.NCGCN包含如下4个步骤:
1)采样.构建封闭子图和特征矩阵.2)特征提取.
获取各封闭子图的图表征.3)学习.实现目标节点对内缺失节点的分类.4)节点合并.推断各目标节点对间缺失节点的关系.
NCGCN框图如图2所示.在生成的随机样本中, 黄色节点表示正例目标节点对, 蓝色节点表示正例节点对的一阶邻接节点, 绿色节点表示反例目标节点对, 灰色节点表示反例节点对的一阶邻接节点, 黑色节点表示经过NCGCN补全的缺失节点.
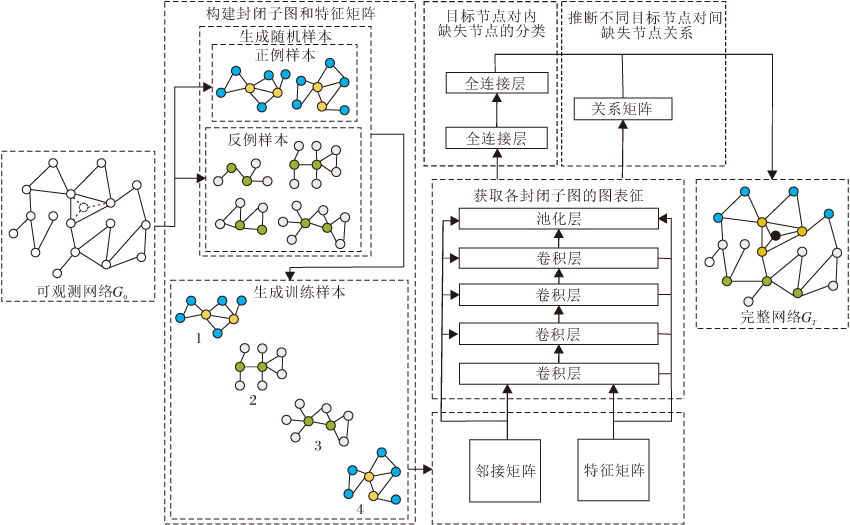 | 图2 NCGCN框图Fig.2 Flowchart of NCGCN |
给定一个网络, 本文目标是解决缺失节点数量未知情况下的网络补全问题.基于网络补全的相关研究, NCGCN以目标节点对的封闭子图和特征矩阵为输入, 经过GCN的训练, 输出缺失节点存在的概率.节点对的h-hop封闭子图为网络中由节点
{i|d(i, x)≤ h or d(i, y)≤ h}
组成的子图, 其中, (x, y)为目标节点对, d(i, x)、d(i, y)表示节点i到目标节点x, y的最短距离[19].
NCGCN的伪代码如算法1所示.因此, 网络补全的第1步是生成包含目标节点对的封闭子图和特征矩阵的训练集.
算法1 NCGCN
输入 可观测网络GO中随机采样得到的m对节点对的h-hop封闭子图Gh的邻接矩阵Ah, 图Gh的节点特征矩阵X, 卷积层的层数k
输出 各节点对内缺失节点的概率H',
节点对间关系矩阵P
初始化 t=0, k=4, Z0=X
Begin
while t< k do
Zt+1=f(
t=t+1
Z1:t:=「X, Z1, …, Zt⌉ //将X与各卷积层得出的结果横向拼接, 得到新的图表征
end while
ZAP=gnn.AvgPooling(Gh, Z1:t) //池化
H=f(ZAPW5+b1)
H'=f(HW6+b2) //利用2个全连接层进行分类运算
ZAP'=f(ZAPW7+b3)
P=f((ZAP')· (ZAP')T) //计算关系矩阵
输出H', P
end
1.2.1 各封闭子图的图表征获取
GCN以封闭子图的邻接矩阵Ah和特征矩阵X作为输入, 通过多层图卷积抽取各封闭子图的结构特征:
Zt+1=f(
其中:
再将Gh的特征矩阵X及各卷积层的输出结果横向拼接, 得
Z1:t:=「X, Z1, …, Zt⌉, Z1:t∈
将Z1:t和Gh作为最大池化层的输入, 得出图表征张量ZAP∈
1.2.2 目标节点对内缺失节点的分类
为了对目标节点对内的缺失节点进行分类, 推断节点对内是否存在缺失节点, 本文对经过卷积层、池化层得出的图表征张量ZAP进行两层连续的全连接运算, 计算各节点对内缺失节点的概率:
H'=f(HW6+b2), H=f(ZAPW5+b1).
其中:W5∈
1.2.3 不同目标节点对间缺失节点的关系推断
推断不同目标节点对之间的缺失关系, 实际上是判断不同节点对之间的缺失节点是否同一节点.首先构造目标节点对间的关系矩阵, 矩阵中的数值表示其所在行、列的节点对之间存在的缺失节点是同一节点的概率.在已知图表征ZAP的前提下, 关系矩阵
P=f(ZAP· (ZAP)T),
但上式中存在一个问题, ZAP的维度会随抽取节点对个数和节点的特征维数的增加而倍数增长, 这使模型的计算效率和准确性随之迅速下降.为此, 本文进一步对图表征ZAP的特征维度进行线性变换:
ZAP'=f(ZAPW7+b3),
其中, W7∈
P=f((ZAP')· (ZAP')T), (1)
其中, P∈ [0, 1]m× m, f为非线性激活函数.在表示节点对关系的矩阵中, Pi, j越大, 表示i表示的节点对和j表示的节点对间的缺失节点为同一节点的概率越大, Pi, j=0表示i表示的节点对和j表示的节点对间的缺失节点非同一节点.推测不同节点对间的缺失节点是否是同一节点实际上是一个二分类问题, 没有最终求得的概率总和为1的条件限制.因此, 这里采用sigmoid激活函数对不同节点对间的缺失节点是否是同一节点进行分类.
关系矩阵P的结果示例如图3所示, 将正负例样本按左图中的顺序送入连续四层GCN中训练, 得出图表征ZAP∈
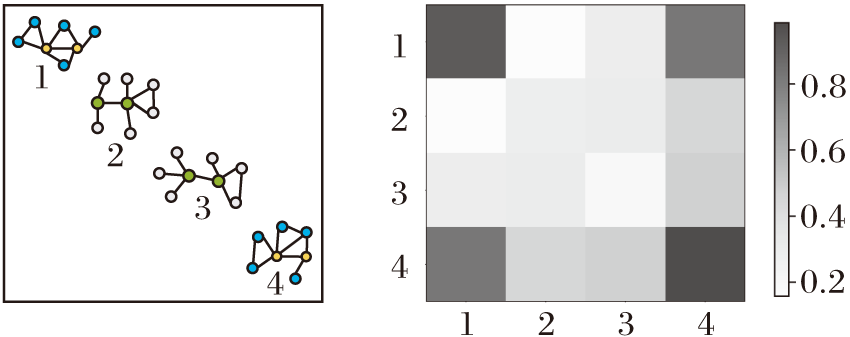 | 图3 关系矩阵P结果示例Fig.3 Example of relationship matrix P |
然后根据式(1)计算得出关系矩阵P∈ [0, 1]4× 4, 关系矩阵P各项数值如右图所示, 矩阵对角线上(1, 1)、(4, 4)颜色较深, (2, 2)、(3, 3)颜色较浅, 表明1表示的节点对和4表示的节点对内存在一个缺失的节点, 而2表示的节点对和3表示的节点对内不存在缺失的节点.(1, 4)、(4, 1)中的颜色深于其它非对角线, 表明1表示的节点对和4表示的节点对中缺失的节点是同一个节点, 即(a)中排序为1和4的封闭子图中的目标节点对间缺失同一节点.
本文通过随机采样的方法构造正例数据集和反例数据集.正例数据集由要去除的节点、去除节点的邻接节点对、封闭子图的节点特征矩阵组成.负例数据集由负例目标节点对、封闭子图的节点特征矩阵组成.
正例数据集的构造分为5步:1)从可观测网络GO中随机选择互不相连且邻接节点数大于1的n(满足条件的节点数量可能会小于n)个节点.2)记录选择的n个节点的邻接节点的集合后, 在可观测网络GO中去除这n个节点.3)从每个节点的邻接节点集合中最多选择k对节点, 以每对节点为目标分别构造h-hop封闭子图.在封闭子图中, 确保目标节点对中2个节点的序号分别为0号和1号.4)构造封闭子图的节点特征矩阵.5)生成N个正例样本的数据集.
节点的特征矩阵由每个节点的标签和属性向量组成.节点标签表示节点在封闭子图中的相对位置与重要性, 使不同子图中的节点在结构上尽可能对齐.本文采用双半径节点标记(Double-Radius Node Labeling, DRNL)[19]的节点标签方法.首先将目标节点对(x, y)的标签均标记为1, 重复更新节点的标签直至收敛, 即
f=1+min(dx, dy)+ d/2[(d/2)+(d%2)-1], (2)
其中,
dx:=d(i, x), dy:=d(i, y), d:=dx+dy,
d(i, x)表示节点i到目标节点x的最短距离, d(i, y)表示节点i到目标节点y的最短距离, f(i)表示序号为i的节点标签, (d/2)、(d%2)分别为d除以2的整数商和余数.
对于封闭子图中与目标节点对不连通的节点标签的计算, 本文提出改进方法.先假设其连通, 此时的不连通子图变成连通子图.再根据式(2)计算节点标签, 将计算得出所有节点到目标节点对的最大值加1表示子图不连通时的节点标签.
负例数据集的构造分为4步:1)随机选择2N个节点对集合, 同时需确保每对节点均不在正例数据集的目标节点对中.选择2N个节点对的目的是得到充足反例数据样本.2)以每对节点为目标构造h-hop封闭子图, 目标节点的序号分别为0号和1号.3)构造封闭子图的节点特征矩阵, 构建方法与正例样本一致.4)生成2N个负例样本的数据集.
最后, 整合得到的正例数据集与反例数据集, 划分为训练集、验证集和测试集.在数据量不大(万级别及以下)的情况下进行深度学习模型训练时, 训练集和测试集的划分比例通常为7:3, 若存在验证集, 则训练集、测试集、验证集的划分比例为6:2:2.本文采用的数据集节点数目在万级以下, 因此, 将正例数据集与反例数据集分别按各自总比例的60%、20%、20%划分为训练集、验证集与测试集.
本文采用交叉熵损失和focal loss[23]结合的损失函数计算NCGCN的损失.交叉熵损失函数用于计算各目标节点对内缺失节点的向量H'的损失.Focal loss损失函数用于计算不同目标节点对间的缺失节点关系矩阵P的损失.关系矩阵P的损失计算如下:
L2i, j=
L2'=
其中, P'∈ {0, 1}m× m为P进行四舍五入处理后的矩阵, P″为原缺失节点对间的真实关系矩阵, α 为平衡正负样本的超参数, γ =2, 用于调节简单样本权重降低的速率.
NCGCN输出向量H'对关系矩阵P的影响较深, 当向量H'中某行为0时, P中与之相对应的行列均为0, 即当某节点对内不存在缺失节点时, 该节点对必然不会与其它节点对间缺失同一节点.因此, 在计算关系矩阵P的损失时, 为了使运算结果偏向于计算那些向量H'中数值较高的值, 即重点关注向量H'中较高概率存在缺失节点的目标节点对的相互关系, 本文为其赋予权重W8=H'· H'T∈ Rm× m, W8数值大小是由向量H'决定.于是, 关系矩阵P的损失进一步变化为
L2″=L2· W8.(3)
由于向量H'的取值均在0~1之间, 在经过矩阵内积之后得出的权值矩阵W8的数值普遍偏小, 使其失去应有的作用.为此, 本文将权值矩阵W8进行数值放大处理.结合式(3), 关系矩阵P的损失最终为

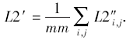
综上所述, NCGCN的损失函数表示如下:
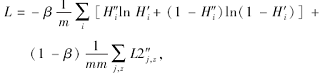
其中 β 为交叉熵损失函数占总损失函数的比重.
实验采用4个网络数据集, 包括随机生成的小世界网络(Small World Network, SWN)、路由器网络(Router Network, RN)和经过数据处理后的真实网络.随机生成的完整网络中分别包含1 000个节点及由节点生成的随机边.真实网络数据集分别为Facebook数据集、NS数据集[24].Facebook数据集包含4 039个节点和88 234条边.NS数据集是发表网络科学论文的研究人员组成的协作网络数据集, 包含1 589个节点和2 742条边.在所有的实验中将网络视为无向连通网络.
为了评估NCGCN性能, 采用精度(Precision)、召回率(Recall)和F1值作为评价指标, 计算公式如下:
Precision=
F1=
其中, n1为缺失节点被正确预测个数, n2为不存在缺失节点却被错误预测个数, n3为缺失节点被错误预测个数.
为了验证本文算法的有效性, 构造如下基线算法.
1)CN_NN.共同邻居节点数量是链路预测中常用的一种指标.基于两节点间的共同邻居数越多, 它们之间存在链接的可能性越大的假设[25, 26], 本文将该思路用于网络节点补全, 构造基线算法CN_NN.在CN_NN中, 若节点对的共同邻居数越多, 存在缺失节点的可能性越大, 且不同节点对间的共同邻居数越多, 存在同一缺失节点的可能性越大.
2)JACCARD_NN.Jaccard方法[27]是共同邻居节点方法的改进, 本文将基于Jaccard方法的基线算法称为JACCARD_NN.在JACCARD_NN中, 两节点间的共同邻居数占两节点总邻居数的比重越大, 两节点间存在缺失节点的可能性越大, 不同节点对间的共同邻居数占邻接节点总数的比重越大, 存在同一缺失节点的可能性越大.
3)PA_NN.将基于节点相似性的Preferential Attachment(PA) 链接预测方法[28, 29]用于节点补全, 得到基线算法PA_NN.在PA_NN中, 网络中节点更可能与距离较近且度矩阵较大的节点间存在缺失节点, 并假设节点间至多有一个缺失节点.
4)NCGCN_VAL.相比NCGCN, 基线算法NCGCN_VAL不进行节点对内缺失节点的推断, 直接判断不同节点对间的缺失节点是否是同一节点, 进而补全网络.
5)NCGCN_DRNL.将NCGCN中节点特征矩阵的计算方法改换成DRNL[19], 得到基线算法NCGCN_DRNL.
所有实验均运行5次, 结果取平均值.各算法在4个数据集上的精度和F1值对比如表1和表2所示.本文根据采用的Ranking方法, 计算各算法在每个数据集上的精度和F1值排名.由表1和表2可看出, NCGCN在4组数据集上精度和F1值均为最高分, 平均排名最佳.NCGCN对NS数据集上缺失数据的补全效果最优, 精度达到71.1%, F1值达到72.5%.由此可见, NCGCN能较好地恢复网络中的缺失数据.此外, 由表1和表2的平均排名可看出, 相比传统算法, 采用深度学习模型的算法可更好地恢复网络中的缺失数据.这表明深度学习在网络补全方面具有较高的应用潜力.
| 表1 各算法在4个数据集上的精度对比 Table 1 Precision comparison of different algorithms on 4 datasets |
| 表2 各算法在4个数据集上的F1值对比 Table 2 F1 comparison of different algorithms on 4 datasets |
值得注意的是, NCGCN_VAL在RN数据集上的效果远优于2个真实数据集, 而在SWN数据集上, NCGCN_VAL的补全效果不及Facebook、NS数据集.原因在于, 本文认为随机生成的网络数据集不含任何有效信息, 当数据集提取的图结构特征越符合原网络拓扑结构时, 补全效果越优, 而大多数随机生成的网络数据集的补全效果不及真实数据集.相比NCGCN_VAL, NCGCN在各数据集上的表现较优, 真实数据集的补全效果均优于随机生成数据集.这从侧面表明NCGCN的合理性.对比NCGCN与NCGCN_DRNL可发现, NCGCN在精度和F1值上均有不同程度的提高.在NS数据集上, NCGCN精度提高3%, F1值提高14%.这表明对封闭子图中节点标签的算法改进是有效的.
网络中缺失节点比例是影响NCGCN可靠性的重要因素.本文通过改变网络中节点数目, 改变网络中缺失节点的比例.因此, 本节通过改变数据集上节点数量, 测量NCGCN补全网络的精度和F1值, 验证NCGCN的可靠性.
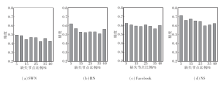
不同缺失比例下NCGCN的实验结果如图4、图5所示.
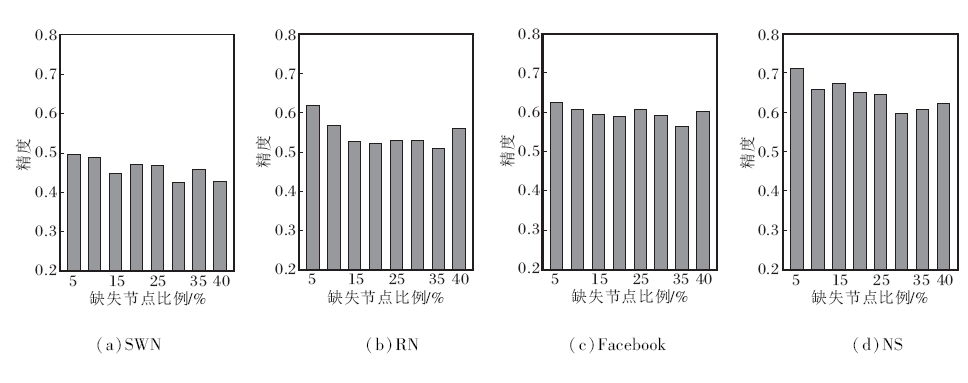 | 图4 缺失节点比例对精度的影响Fig.4 Effect of missing node ratio on precision |
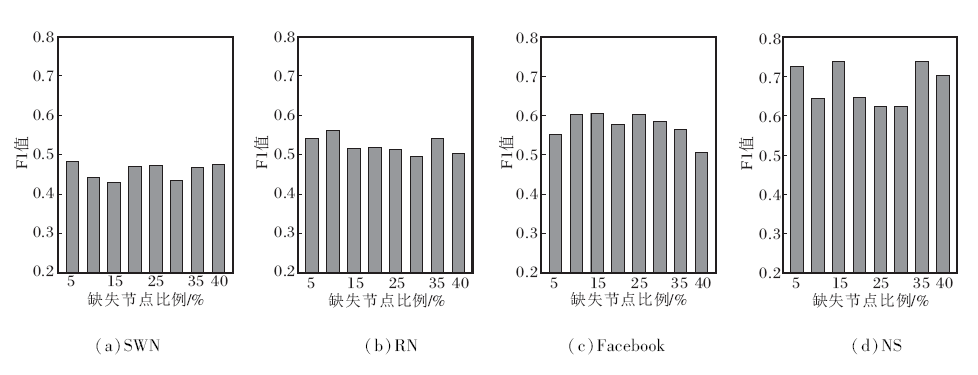 | 图5 缺失节点比例对F1值的影响Fig.5 Effect of missing node ratio on F1 |
由图可知, 网络中缺失节点的比例对NCGCN的影响不大, 当网络中缺失40%的节点时, NCGCN仍能可靠地恢复网络缺失的部分.需要注意的是, SWN、RN数据集上的精度和F1值低于2个真实数据集, 这是由于SWN、RN数据集上的数据是随机生成的, 数据中没有任何有效信息.NS数据集上的精度和F1值均在0.6以上, 这是因为NS数据集是由发表网络科学论文的研究人员组成的引文网络数据集, 研究人员的研究方向大致相关, 这使网络中的节点相似程度较高.
现有网络中获取的网络数据大都不完整, 存在缺失节点.补全缺失节点的关键问题之一是判断哪些缺失节点实际上是同一节点.为此, 本文提出基于图卷积神经网络的网络节点补全算法(NCGCN), 分析可观测网络节点对间的节点缺失情况, 用于补全网络.首先, 根据可观测网络进行成对采样, 构造目标节点对的封闭子图和特征矩阵作为训练样本.然后, 将封闭子图及其特征矩阵批量输入GCN, 学习图表征, 根据得到的图表征推断各子图中的目标节点对内是否存在缺失节点, 同时判断各不同目标节点对间的缺失节点是否为同一节点.在随机生成网络和真实网络上的实验表明, NCGCN具有良好的网络补全性能, 在缺失节点比例较大时仍能有效补全网络.
本文在采用GCN学习可观测网络的图表征时, 只利用网络的结构信息, 未考虑边的属性信息.今后将考虑设计特征提取模型, 结合社交网络的结构、各种用户特征及边的属性特征, 为网络补全工作提供更多的辅助信息.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|