

{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于深度学习的X线胸片肺部描述自动生成
[黄欣1, 2  , 顾梦丹
, 顾梦丹2 , 易玉根1 , 曹远龙1 ]
, 顾梦丹, 易玉根, 曹远龙]
|
|



作者简介:

黄欣,博士,讲师,主要研究方向为机器学习、生物信息、多模态数据融合.E-mail:xinhuang@jxnu.edu.cn.

顾梦丹,硕士研究生,主要研究方向为机器学习、医学信息.E-mail:1732953@tongji.edu.cn.

易玉根,博士,副教授,主要研究方向为人工智能、计算机视觉、机器学习.E-mail:yiyg510@jxnu.edu.cn.
X线胸片报告的自动生成是计算机辅助诊断研究的热点,X线胸片中65%以上的疾病与肺部相关.针对肺部描述中文报告生成,提出基于语义标签的层级长短期记忆网络模型.首先,分析异常胸片报告,提取高频关键词作为图像语义标签.再加入异常二分类模块,用于修正语义标签分类结果.最后,融合语义标签与图像特征,加强二者的关联映射.实验表明,文中模型在通用和领域指标的评价上均较优,能有效提高胸片报告生成的性能.
About Author:
HUANG Xin, Ph.D., lecturer. His research interests include machine learning, bioinformatics and multi-modal data fusion.
GU Mengdan, master student. Her research interests include machine learning and medical information.
YI Yugen, Ph.D., associate professor. His research interests include artificial intelligence, computer vision and machine lear-ning.
The chest X-ray report automatic generation is a hot research topic in computer-aided diagnosis. More than 65% of diseases in chest X-rays are related to the lungs. For the generation of Chinese reports on lung descriptions, a hierarchical long short term memory model based on semantic labels is proposed. Firstly, the abnormal chest X-ray reports are analyzed, and high-frequency keywords are extracted as semantic labels. Then, the abnormal binary-classification module is introduced to correct the semantic label classification results. Finally, semantic labels and image features are fused to enhance the association mapping between them. Experimental results show that the proposed model is superior to the baseline method in both general and domain metrics, and it improves the performance of chest radiograph report generation effectively.
本文责任编委 林鸿飞
Recommended by Associate Editor LIN Hongfei
在中国, X线胸片体检是常规项目, 也是胸部尤其是肺部初期疾病筛查的重要诊疗手段.使用计算机对X线胸片进行疾病辅助诊断可较好地减轻放射科医生的工作强度[1, 2, 3, 4], 但只能判断被观察的X线胸片某种或几种疾病是否存在, 缺少疾病的程度、位置等关键信息.为了更好地描述X线胸片包含的病理信息, 研究X线胸片的报告自动生成具有实际意义.
X线胸片中文报告与英文报告除语种本身有差别之外, 在书写上也存在明显差异.1)英文报告描述接近自然语言, 对于观测的部位描述无明显的主次先后关系; 中文胸片报告整体结构工整, 基本都是按照固定的顺序描述每个观测部位的正常状态或异常状态.2)英文报告的描述句式灵活, 无明显的规律可循; 中文报告的描述句式呈现模板化, 规律性较强.3)对于无异常的X线胸片, 英文报告描述多样, 中文报告基本相同.上述差异的存在导致基于英文报告的算法无法直接用于中文报告生成的研究中.
Vinyals等[5]受到机器翻译中编码器-解码器的启发, 使用卷积神经网络(Convolutional Neural Net-work, CNN)作为编码器提取图像特征, 循环神经网络(Recurrent Neural Network, RNN)作为解码器, 根据图像特征生成一句自然语言描述.He等[6]提出基于注意力机制(Soft Attention, Hard Attention)的图像描述生成模型, 对于每个时间步的输入能给予图像不同区域的关注.Yao等[7]提出使用高级语义信息代替之前的图像特征作为RNN的输入, 使用描述中词频最高的256个词作为属性标签, 训练多标签分类器, 多标签分类器的结果被用于生成描述.与之类似的工作采用不同的方式从图像中提取高级语义信息, 用于生成描述[8, 9, 10].
X线胸片报告生成的研究方法沿用通用领域的图像文本描述生成的方法, 在其基础上根据X线胸片影像的医学属性及报告的撰写特点进行优化.Shin等[11]在胸片疾病分类的基础上, 设计可生成包含疾病位置、严重性等关键信息的短文本的深度模型, 根据Open-I数据集的样本分布特征, 使用级联的训练方式, 明显改善文本生成的效果.Wang等[12]提出文本图像嵌入网络(Text-Image Embedding Net-work, TieNet), 基于CNN-RNN的模型架构, 在模型中加入层级注意力机制, 突出包含医学意义的文本单词和图像区域, 可同时对胸片进行疾病分类及生成报告, 但报告生成质量不佳.Jing等[13]采用联合注意力机制(Co-attention), 更好地结合图像与标签的特征.Li等[14]根据报告的模板特性, 采用检索和强化学习混合的方法, 对于句子解码器生成的句子主题, 使用模板库(Template Database)或生成模式(Generation Module)进行强化学习训练.Xue等[15]考虑到医生写报告的习惯, 首先生成报告的诊断部分, 然后根据上一句诊断的语义特征, 结合注意力机制生成完整的报告.Li等[16]提出知识驱动编码检索解释模型(Knowledge-Driven Encode Retrieve Model, KERP), 将医疗报告生成分解为医学异常图学习和自然语言建模两部分, 动态地转换多个域的图形结构数据(如知识图、图像、序列)之间的高级语义.Huang等[17]提出融合多注意机制和背景信息的层次模型, 多注意机制可同时关注图像的通道信息及空间信息, 并与解码器的句子主题进行映射, 获得较优性能.
在统计不同的X线胸片数据集后发现, 出现在肺部的疾病比例超过其它部位疾病之和.在ChestX-ray14数据集[18]上, 肺部疾病比例为69.31%, 在CheXpert数据集[19]和MIMIC-CXR[20]数据集上, 统计的过程剔除辅助器具(Support Devices), 肺部疾病比例分别为59.14%和57.53%.在Tongji数据集[21]上, 肺部疾病比例超过70%.由此可见, 把研究的目标聚焦在报告的肺部描述文本上, 既可覆盖大部分的疾病症状, 又可更快地应用到临床辅助诊断中.
基于上述分析, 本文针对中文报告的特点, 提出基于语义标签的层级长短期记忆网络(Long Short-Term Memory, LSTM)模型.首先, 分析异常报告, 提取高频的关键词作为图像语义标签.然后, 针对中文报告模板化的特点, 加入异常二分类模块, 用于修正语义标签的结果.最后, 融合语义标签与图像特征, 加强二者的关联映射.实验表明文中模型可有效提高报告生成的性能.
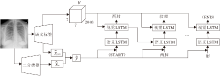
基于语义标签的层级长短期记忆网络模型为编码器-解码器结构, 对于X线胸片图像I, 本文目标是生成肺部描述的单词序列{S1, S2, …, ST}.模型的编码器包含一个以残差网络(Residual Network, ResNet)[22]为主体的图像语义标签生成模块, 图像语义标签生成模块由一个多标签分类器和一个检测异常的二分类器组成.解码器包含一个融合语义标签与图像特征的层级LSTM[23]模块.模型框图如图1所示.
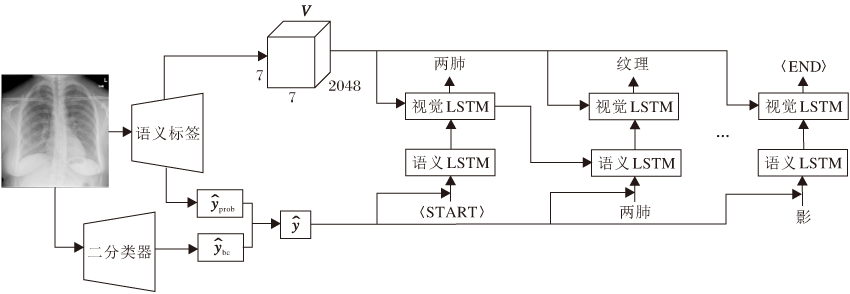 | 图1 本文模型框图Fig.1 Architecture of the proposed model |
图像语义标签生成模块的多标签分类器将输出一个固定维度的概率向量
对于语义标签向量
y=[y1, y2, …, yc]T,
c表示语义标签的数量, 当胸片标注语义标签j时, yj=1, 否则yj=0.当语义标签向量全为0, 即y=[0, 0, …, 0]T时, 表示样本正常.
多标签分类模块框图如图2所示.对于A部分, 输入为B部分中ResNet的“ res4b22_relu” 层提取的特征图, 通过注意力机制学习语义标签之间的关系.这两部分产生的向量
 | 图2 多标签分类模块框图Fig.2 Flow chart of multi-label classification module |
对于每幅输入的X线胸片I, B部分的输出为
其中θ res表示ResNet内部参数.
A部分主要由2个子模块fatt和fsr构成, fatt负责生成语义标签的注意力图, fsr负责根据已生成的注意力图捕获语义标签间的空间关系.由于每个语义标签都与X线胸片的某个区域相关, 因此在推断某个标签是否存在时, 需要对相关的图像区域给予更多的关注.fatt采用注意力机制, 通过图像级别的监督学习预测每个语义标签的相关图像区域, 由3个卷积层组成, 这3个卷积层分别采用512个1× 1的卷积核, 512个3× 3的卷积核和c个3× 3的卷积核.在前两个卷积层之后连接ReLU激活函数.将ResNet模型生成的14× 14× 1 024维的特征图X输入fatt, 得到语义标签的注意力值:
Z=fatt(X; θ att),
其中, Z∈ R14× 14× c, 表示fatt生成的未归一化的语义标签注意力值, 每个通道的值分别对应一个标签.使用Softmax函数对Z进行空间归一化, 得到最终的语义标签注意力图:
at
其中, at
经过Sigmoid函数处理后, 将特征图S的值映射到[0, 1]内, 与注意力图A进行乘积操作, 得到加权注意力图:
U=σ (s)A,
其中, σ 表示Sigmoid函数, 表示乘积.将加权注意力图U输入由3个卷积层构成的fsr, 前两个卷积层采用512个1× 1的卷积核, 最后一个卷积层采用2 048个14× 14的卷积核.前两个卷积层用于捕获标签间的语义关系, 第三层用于捕获语义标签的空间关系, 最终得到fsr的输出向量为
其中θ sr表示fsr的参数.则概率向量为
$\begin{array}{l}\hat{y}_{\mathrm{avg}}=0.5 \hat{y}_{\mathrm{res}}+0.5 \hat{y}_{\mathrm{sr}}, \\\hat{y}_{\mathrm{prob}}=\sigma\left(\hat{y}_{\mathrm{avg}}\right),\end{array}$
其中σ 表示Sigmoid函数.
异常的二分类器用于修正多标签分类结果, 其中ybc∈ {0, 1}, 0表示正常, 1表示异常.具体地, 对于输入的X线胸片I, 二分类的输出为
其中σ 为Sigmoid的函数.
通过设置阈值λ 控制最后的输出, 当pbc≥ λ 时, 令B=1, 否则B=0.λ 值根据实验结果设定.语义标签向量如下所示:
语义标签虽然可较好地表示图像特征, 但标签之间缺失相互关系.具体来说, 假设生成的语义标签为“ 右肺” 、“ 左肺” 、“ 模糊” 、“ 阴影” 等, 将无法判断“ 阴影” 出现在“ 左肺” 还是“ 右肺” , 这在多个部位出现异常时尤为明显.仅使用无序的语义标签无法确定部位与异常表现的对应关系, 对此本文提出语义标签和图像特征融合的层级LSTM, 包含一个语义LSTM(Semantic LSTM)和一个视觉LSTM(Vi-sual LSTM).语义LSTM通过语义标签学习高级语义表达, 视觉LSTM通过注意力机制加强异常图像特征与语义标签的对应关系.融合语义标签与图像特征的层级LSTM的结构图如图3所示.
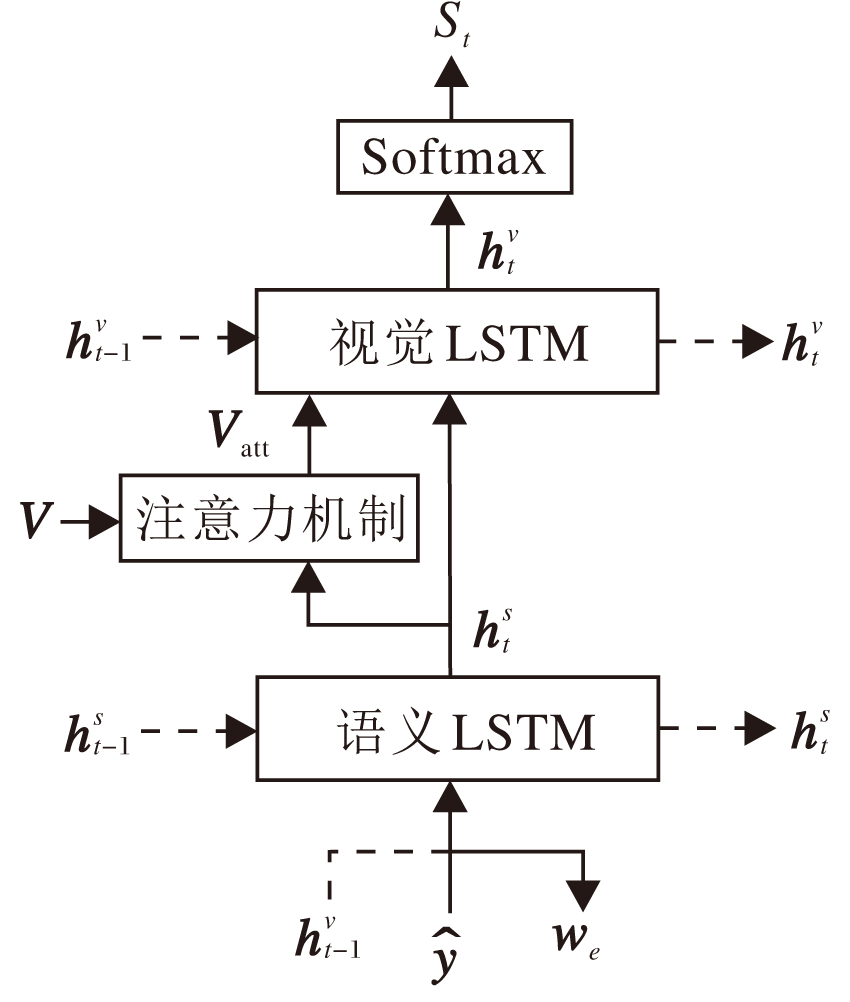 | 图3 层级LSTM模块框图Fig.3 Flow chart of hierarchical LSTM module |
对于时间步t, 语义LSTM输入
其中,
为了加强标签与图像的映射关系, 首先获取语义标签生成模块, 提取中间特征图, 再结合语义LSTM的输出结果计算注意力权重, 图像的不同区域被赋予不同权重, 使模型能更好地关注与当前生成单词相关的图像特征.具体地, 获得从语义标签生成模块的包含L个D维的中间特征向量
V=[v1, v2, …, vL], vi∈ RD.
针对图像特征向量vi, 生成注意力权重
ai, t=
其中, Wa、Wva、Wha均为权重矩阵, t为时间步.结合注意力的图像特征向量为
Vatt=
对于时间步t, 视觉LSTM的输入
S1:t-1表示需要模型输出的单词序列{S1, S2, …, ST}, 对于每个时间步t, 输出单词的条件分布概率:
p(St|S1:t-1)=SOFTMAX(Wp
其中, Wp、bp分别为权重和偏差.
最后, 通过每个时间步输出单词条件分布概率的乘积, 得到输出完整的肺部描述语句:
p(S1:T)=
整个模型采用端到端的训练方式, 模型的损失函数由3部分组成.多标签分类模块的损失函数Lmtl为语义标签yl与向量
$\begin{array}{l}L_{\mathrm{mtl}}= \\\quad \sum_{l=1}^{c} y^{l} \ln \left(\sigma\left(\hat{{y}}_{\mathrm{avg}}^{l}\right)\right)+\left(1-y^{l}\right) \ln \left(1-\sigma\left(\hat{{y}}_{\mathrm{avg}}^{l}\right)\right).\end{array}$
异常二分类损失函数Lbc为二分交叉熵损失函数:
Lbc=-ybcln(pbc)+(1-ybc)ln(1-pbc).
层级LSTM的损失函数表示如下:
Lvs=-
其中, T表示真实描述的长度, yt表示描述中的每个单词, V表示图像特征向量,
Loss=Lmtl+Lbc+Lvs.
实验使用来自同济大学同济附属医院的Tongji数据集[23].
图像预处理分为2步:1)剔除侧位、不清晰及婴儿的胸片.2)使用Dcm2jpg(https://github.com/dcm4che/dcm4che/tree/master/dcm4che-tool/dcm4che-tool-dcm2jpg)工具将dicom格式胸片转换为jpg格式.
文本预处理也分为2步:1)使用“ .” 或“ ; ” 分隔报告, 筛选包含“ 肺” 这个字的语句, 作为肺部描述.2)使用jieba(https://pypi.org/project/jieba)工具对肺部描述分词.
考虑到不存在疾病的报告描述基本相同, 本文对分词后的异常肺部描述进行词频统计, 并将高频词汇作为语义标签的候选词.对于统计完的候选标签词, 首先剔除所有肺部描述中均会出现的描述词, 如“ 两肺纹理增多” .再合并同义词, 如“ 两肺尖” 和“ 两肺上野” .然后具象描述.例如, “ 模糊” 这个词, 在不同的语句中非具象为“ 肺纹理阴影” 和“ 模糊影” 两类.其中合并同义词及具象描述的工作在专业影像科医生的指导下完成.最后选取40个高频词作为语义标签, 包含13个与异常部位相关的标签及27个与异常表现相关的标签.
异常二分类标签由1位二进制表示, 正常肺部描述标注为0, 异常肺部描述标注为1, 共包含19 985份样本, 每份样本包括1幅正面X线胸片及对应的语义标签和二分类标签.在所有样本中, 异常样本为10 213份, 正常样本为9 772份.在实验中, 上述样本将按照8:1:1的比例将数据集随机划分成训练集、验证集和测试集.
本文选取具有代表性的方法为基线方法.具体如下.1)通用领域的图像文本生成方法:文献[5]方法、文献[24]方法、文献[25]方法、文献[26]方法、文献[27]方法.2)X线胸片报告生成领域方法:文献[13]方法、文献[17]方法.
同时, 为了更好地验证不同模块对于整体效果的影响, 进行消融实验.MLC_LSTM为仅使用语义标签模块, 不包含异常二分类模块及层次LSTM模块.MLC_BC_LSTM为包含语义标签模块和异常二分类模块, 不包含层次LSTM模块.MLC_VSLSTM为包含语义标签模块和层次LSTM模块, 不包含层次异常二分类模块.MLC_BC_VSLSTM为本文完整模型.
为了综合评价模型性能, 本文分别从通用的自然语言生成任务指标和X线胸片报告生成领域指标两方面度量结果.采用通用指标为BLEU(Bilingual Evaluation Understudy)、ROUGE(Recall-Oriented Understudy for Gisting Evaluation)-L和METEOR.领域指标为文献[15]的关键词准确率(Keyword Accuracy, KA)和文献[28]的临床准确率(Clinical Accuracy, CA).KA和CA指标的原理都是考察生成报告中包含关键信息的比重, 不同的是KA使用统计后的关键词, 而CA为临床疾病描述词.但KA和CA指标都是针对英文数据集提出的, 考虑到语言与书写习惯的差异, 本文仅借鉴其思想而并非直接套用.具体地, 本文选用KA指标的关键词为语义标签, 数量为40, CA指标为在语义标签中进一步剔除位置信息, 最终得到27个临床疾病描述词.
模型使用随机梯度下降方法, 初始学习率设置为5× 10-4, 学习率的衰减率设置为0.8, 批度大小为24.在语义标签与图像特征融合的层级LSTM模块中, 词向量维度设置为256, LSTM单元的隐层状态和记忆单元维度均设置为256, 词向量和隐藏层均采用随机初始化.由于λ 决定异常二分类器预测的结果取值为0或1, 所以对异常二分类器进行预训练以获得最佳性能.
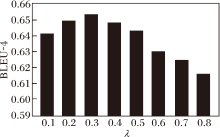
将λ 的取值设置在0.1~0.8, 分别计算λ 不同时生成肺部描述的BLEU-4得分, 如图4所示.由图可知, λ =0.3时, BLEU-4得分最高, 所以λ 设定为0.3.
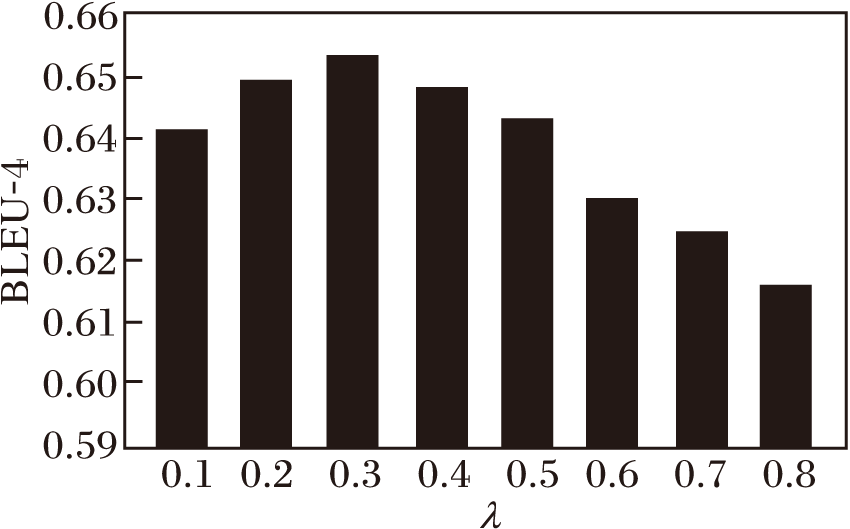 | 图4 λ 不同时的BLEU-4得分Fig.4 λ value setting |
各方法的多个指标值对比结果如表1所示.
| 表1 各方法的指标值对比 Table 1 Index value comparison of different methods |
从通用指标的度量来看, 采用语义标签与图像特征融合的MLC_BC_VSLSTM的BLEU-4、METOR、ROUGE-L值分别为66.2、49.6、81.1, 虽然METOR、BLEU-4值略低于文献[26]方法和文献[27]方法, 但总体上性能优于基线方法.从领域指标上看, MLC_BC_VSLSTM的KA、CA值分别为0.913、0.938, 均为最优.
首先, 通过与文献[5]方法、 文献[24]方法和文献[25]方法对比发现, 注意力机制可通过关注图像的局部特征提高文本生成的质量, 文献[5]方法直接从CNN的编码器提取图像特征输入解码器的方式过于简单, 在各项度量指标上的评分都是最低.在不同注意力机制的对比中, 文献[24]方法和文献[25]方法都是直接将图像特征输入解码器生成最后的描述语句, 融合不佳.文献[26]方法和文献[27]方法代表图像文本生成的最优水准.文献[26]方法采用包括图语义注意力和图流向注意力的图注意力机制, 文献[27]方法采用X线性注意机制, METEOR、BLEU-4值最高.但从领域指标上看, MLC_BC_VSLSTM优于文献[26]方法和文献[27]方法, 这是由于MLC_BC_VSLSTM针对中文报告特点进行分析, 并在模型中通过注意力加强图像与语义标签的映射, 注意力集中于与语义标签相关的区域, 更好地学习到胸片与语义标签之间的关系.这也印证语义标签模块可有效提升报告生成的性能.
在与应用国外数据集验证的X线胸片英文报告生成的文献[13]方法和文献[17]方法的对比中, 在通用指标上, 文献[13]方法、文献[17]方法的BLEU-4值分别为0.613和0.629, 比MLC_BC_VSLSTM减少约4%.在领域指标上, 文献[13]方法、文献[17]方法同样低于MLC_BC_VSLSTM.从这点上来看, 中英文语言的差异及医生书写习惯会影响报告生成的质量, 也进一步验证本文所述直接使用国外数据集的方法用于中文X线胸片报告生成是不合适的.
MLC_BC_LSTM和MLC_LSTM对比结果显示, MLC_BC_LSTM的BLEU-4值更高, 这说明针对中文报告模板化特性加入异常二分类器, 可修正语义标签的生成结果.由于MLC_BC_LSTM生成的语义标签向量中不包含关联性, 当有多个部位出现异常时, 解码器无法从语义标签向量中学习到异常表现对应的异常部位, 因此在处理出现多个异常的样本时, 存在明显缺陷.而MLC_BC_VSLSTM采用双层LSTM的结构, 在生成描述阶段既使用语义标签具有的高级语义信息, 又使用图像特征包含的低层次的图像信息, 弥补语义标签缺失的关联性, 因此生成的肺部描述质量更高.
最后对比分析VSLSTM模块的加入对模型实际效果的影响.个例对比结果如表2所示, 表中黑体字表示模型正确生成的关键描述.在个例1中, MLC_BC_LSTM虽然生成“ 两肺野” 和“ 左肺下野” 这2个异常部位描述, 但这2个部位对应的异常表现出现描述错误, 而MLC_BC_VSLSTM正确生成“ 两肺野” 和“ 左肺下野” 分别对应的“ 透亮度增高” 及“ 片絮状影” 异常表现.在个例2中, MLC_BC_VSLSTM生成更细致的“ 结节状” 的描述.在个例3中, MLC_BC_LSTM错误生成异常“ 高密度影” 对应的区域“ 两肺上野” , 这是语义标签直接缺乏逻辑关系的缺陷导致, 而加入图像特征融合后, MLC_BC_VSLSTM准确地将异常区域对应在“ 两肺上野” .同样地, 在个例4中, 相比MLC_BC_LSTM生成的“ 左肺野” , MLC_BC_VSLSTM生成的“ 左肺上野” 更准确.
上述个例可清晰展示融合图像特征语义标签弥补的低层次图像信息, 有效提高报告生成的质量.
| 表2 融合语义标签及图像特征的报告生成个例 Table 2 An example of report generation combining semantic tags and image features |
本文针对性地提出适用中文报告肺部描述生成的基于语义标签的层级LSTM模型.模型使用语义标签, 加强解码器对图像的理解.在编码器中加入异常二分类模块, 用于修正语义标签的结果.解码器为融合语义标签与图像特征的双层LSTM模型.实验表明, 异常二分类的加入可有效提高正常样本的判定和模型性能, 融合语义标签与图像特征可有效提高生成文本的质量.
本文发现通用的文本生成指标并不能完整地评估X线胸片报告生成性能的问题.领域指标虽然可在一定程度上客观评估报告生成性能, 但缺乏统一的权威性.今后将考虑一种客观且得到多方认可的领域评价指标, 并在此基础上结合强化学习, 优化生成报告的质量.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|