




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于关键点表示的语音驱动说话人脸视频生成
[年福东1, 2  , 王文涛
, 王文涛1 , 王妍1 , 张晶晶1 , 胡贵恒3 , 李腾1 ]
, 王文涛, 王妍, 张晶晶, 胡贵恒, 李腾]
|
|



作者简介:

王文涛,硕士研究生,主要研究方向为图像生成.E-mail:18755124416@163.com.

王妍,博士研究生,主要研究方向为卷积神经网络、多模态融合.E-mail:ywanglt@gmail.com.

张晶晶,博士,副教授,主要研究方向为计算机视觉.E-mail:fannyzjj@ahu.edu.cn.

胡贵恒,硕士,讲师,主要研究方向软件技术、人工智能.E-mail:545572406@qq.com.

李腾,博士,教授,主要研究方向为计算机视觉、多媒体计算.E-mail:liteng@ahu.edu.cn.
针对现有语音生成说话人脸视频方法忽略说话人头部运动的问题,提出基于关键点表示的语音驱动说话人脸视频生成方法.分别利用人脸的面部轮廓关键点和唇部关键点表示说话人的头部运动信息和唇部运动信息,通过并行多分支网络将输入语音转换到人脸关键点,通过连续的唇部关键点和头部关键点序列及模板图像最终生成面部人脸视频.定量和定性实验表明,文中方法能合成清晰、自然、带有头部动作的说话人脸视频,性能指标较优.
About Author:
WANG Wentao, master student. His research interests include image generation.
WANG Yan, Ph.D. candidate. Her research interests include convolution neural network and multimodal fusion.
ZHANG Jingjing, Ph.D., associate professor. Her research interests include compu-ter vision.
HU Guiheng, master, lecturer. His research interests include software technology and artificial intelligence.
LI Teng, Ph.D., professor. His research interests include computer vision and multimedia computing.
The speaker's head motion is ignored in the existing speech driven talking face video generation methods. Aiming at this problem, a speech driven talking face video generation method based on facial landmarks representation is proposed. The speaker's head motion information and lip motion information are represented by facial contour landmarks and lip landmarks, respectively. The speech is converted to facial landmarks through a parallel multi-branch network. The final talking face video is synthesized by continuous lip landmark sequence, head landmark sequence and template image. The corresponding quantitative and qualitative experiments are conducted. Experimental results show that the talking face video with head action synthesized by the proposed method is clear and natural, and its performance is better.
本文责任编委 陈松灿
Recommended by Associate Editor CHEN Songcan
语音驱动的说话人脸视频生成是指输入任意一段语音数据, 由计算机自动生成一段特定人的说话人脸视频, 要求生成的视频清晰并且与输入的语音对齐、嘴型匹配.此项技术在实际生活中具有广泛应用场景, 如电影制作、虚拟新闻播报、虚拟演讲、虚拟交互等.
语音驱动的说话人脸视频生成最初源于计算机图形学领域[1].早期的工作旨在找到或学习一个可从语音信号映射到嘴部动作的转换模型.Cudeiro等[2]通过语音预测3D人脸模型系数, 用于驱动三维人脸模型.此外, 端到端的学习方式也被广泛研究, Pham等[3]和Karras等[4]通过深度模型对语音信息进行特征提取, 直接驱动3D人脸模型.
随着卷积神经网络(Convolutional Neural Network, CNN)[5]、循环神经网络(Recurrent Neural Network, RNN)[6]和生成对抗网络(Generative Adversarial Net-works, GAN)[7]技术的发展, 语音驱动的说话人脸视频生成工作取得巨大进展[8, 9].现有方法一般采用端到端训练的编码-解码框架, 即利用CNN和RNN将输入语音数据编码为特定长度的向量, 再采用RNN对向量进行解码, 生成说话人脸视频帧序列.Chen等[10]将关键点作为中间变量, 生成说话人脸视频, 采用注意力机制提升说话人脸的质量, 但忽略说话人脸的头部动作.Mittal等[11]通过深度学习的方法, 把语音信息分解成语义信息和情感信息, 用于合成人脸视频.Yi等[12]和Song等[13]从2D人脸图像直接重构3D人脸信息, 结合三维变形模型(3D Morphable Model, 3DMM)[14]的方式, 使用纹理特征、角度、表情参数构建3D人脸模型, 再通过GAN生成在二维投影的人脸图像.但是, 3D人脸建模的方法依赖3DMM人脸建模模型和视频重定时算法, 导致生成的人脸视频不自然.
虽然现有方法都取得一定效果, 但主要关注生成人脸的质量[10]和生成唇部动作的准确性[15, 16, 17], 大都忽略生成说话人脸视频的头部动作, 使生成的说话人脸视频基本只有面部表情和唇部动作时序变化, 头部姿态极少发生改变.
然而说话人的头部动作随语言的内容发生变化是日常交流中常见的自然现象, 人的视觉系统对于任何不自然的因素都非常敏感, 因此在语音驱动的说话人脸视频生成任务中, 使生成的说话人脸视频的说话人的头部动作随语音内容发生自然的改变极为重要, 否则会导致整个生成视频视觉效果较差.
根据一段语音信号生成具有自然、高准确性的唇部动作和头部动作的说话人脸视频是一项非常困难的工作.首先, 需要从语音模态中编码语义信息并转换到视觉模态, 存在模态转换导致的语义信息损失问题.然后, 从语义信息预测说话人的头部运动信息是一个非常复杂的问题, 需要考虑语调、场景、性别等因素, 如人的头部可能在说出相应的话语之前或之后发生移动等.最后, 对于同一段语音编码得到的语义信息, 需要将其解耦成唇部动作信息和头部动作信息, 生成自然的说话人脸视频.
为了解决上述问题, 本文提出基于关键点表示的语音驱动说话人脸视频生成方法.分别利用人脸的面部轮廓关键点和唇部关键点表示说话人的头部运动信息和唇部运动信息, 通过并行多分支网络将输入语音转换到人脸关键点, 通过连续的唇部关键点和头部关键点序列及模板图像最终生成面部人脸视频.定量和定性实验表明, 本文方法能合成清晰、自然、带有头部动作的说话人脸视频, 性能指标较优.
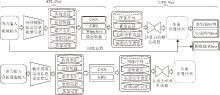
本文算法的总体框架如图1所示, 主要特点是将人脸关键点信息作为语音驱动说话人脸视频生成的中间状态.框架由2部分组成:语音序列到人脸关键点转换网络(Audio to Landmark Transform Net-work, ATL-Net)和人脸关键点到说话人脸视频转换网络(Landmark to Video Transform Network, LTV-Net), 具体定义如下:
R{t}=Φ (A{t}),
V{t}=Ψ (R{t}, P),
V{t}=Ψ (Φ (A{t}), P),
其中, A{t}表示输入语音信号, P表示给定的特定人面部图像, R{t}表示生成的人脸关键点序列, V{t}表示生成的说话人脸图像序列, Φ 表示ATL-Net, Ψ 表示LTV-Net.
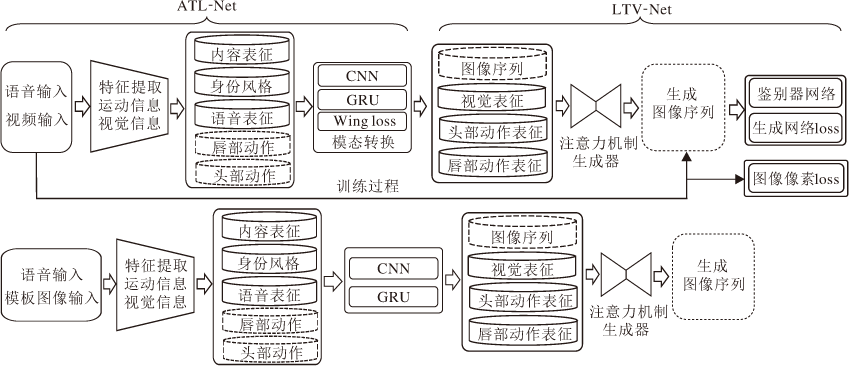 | 图1 本文方法框图Fig.1 Framework of the proposed method |
对于任意输入的一段语音信号, ATL-Net通过由CNN和门控循环单元(Gated Recurrent Unit, GRU)[18]结构组成的2个并行网络, 将语音信号分别转换成时序变化的脸部轮廓关键点和唇部轮廓关键点, 再结合特定人面图像P, 作为由具有注意力机制的GAN结构组成的LTV-Net的输入, 最终生成高质量的说话人脸视频.
本文采用开源人脸检测与关键点提取工具DLIB库(http://dlib.net)获取每幅人脸图像的68个关键点坐标.关键点坐标中蕴含人脸的唇部运动信息和头部运动信息, 同时语音信号A{t}、特定人面部图像P(在接下来的介绍中等同于模板图像)、说话人脸图像序列V{t}为已知信息.为了消除人脸位置与尺度带来的干扰, 本文以模板图像的人脸关键点坐标作为参考, 对唇部关键点进行归一化, 同时保证头部关键点不变.
对于说话人脸图像序列中的每幅人脸图像, 本文利用唇部所有关键点和一个鼻尖关键点(简称唇部关键点)表示唇部运动信息, 利用面部所有外部轮廓点和左右两个嘴角点(简称头部关键点)表示头部动作信息, 提出基于ATL-Net的说话人脸关键点序列生成方法.方法输入为语音信号、模板图像的唇部关键点和头部关键点, 输出时序变化的唇部关键点序列和头部关键点序列.本文采用2个相同结构的并行子网络(分别表示唇部子网络和头部子网络)对同个语音信号分别生成唇部关键点序列和头部关键点序列, 在每个子网络中, CNN用于提取语音特征, 全连接层用于建模模板图像关键点, 通过拼接操作融合语音信息和模板图像关键点信息, 通过GRU预测对应的关键点序列.具体定义如下:
其中, Φ 1表示ATL-Net唇部子网络, Φ 2表示ATL-Net头部子网络, Rtemplate_mouth表示模板图像的唇部关键点, Rtemplate_head表示模板图像的头部关键点,
为了生成一组完整的唇部运动信息和头部运动信息人脸关键点, 本文通过两侧嘴角和鼻尖三个关键点构建仿射矩阵, 将嘴部每个关键点通过仿射矩阵映射到头部关键点空间中, 构建一组完整的人脸关键点.
在唇部子网络中, 将语音信息通过卷积层、归一化层和ReLu激活函数编码成512维的语音特征向量, 模板图像唇部关键点通过全连接层和ReLu激活函数编码成256维的特征向量.2组特征向量通过拼接操作拼接成786维的融合向量.再通过GRU和全连接网络预测42维的唇部关键点(21个点).头部分支网络和唇部分支网络结构相似, 使用256维模板图像头部关键点特征和512维语音特征作为输入, 预测100维的头部轮廓关键点(50个点).
为了获得更优效果, 本文采用Wing loss[19]作为ATL-Net的损失函数.相比Wing loss, 传统的均方误差损失函数(Mean Squared Error loss, MSE loss)在训练一段时间后出现过拟合效应, 不利于网络优化.实验证实, Wing loss保证网络训练更稳定.Wing loss的定义如下:
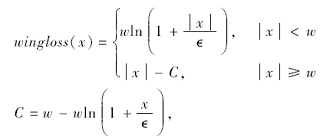
其中, w=10.0, ∈ =2.0, C值由w、∈ 共同决定, x表示基于关键点的预测值与其对应的真实值的差值.
在本文的说话人脸视频生成任务中, 考虑2个问题.1)面部信息和背景信息混合在一起, 需要在保留背景信息的同时合成高质量的面部信息.2)虽然运动信息和背景信息无关, 但对于生成视频的连续性至关重要, 直接决定生成的说话人脸视频的视觉效果.
为了解决上述问题, 本文提出基于U型网络(U-Net)[20]的GAN, 采用注意力机制, 在获得更优面部信息和运动信息的同时保留背景信息不变, 并命名为LTV-Net.GAN网络中的生成器为
V{t}=G((R{t})☉fimg, fimg).
判别器为
L{t}=D(V{t}),
其中, R{t}表示由ATL-Net生成的完整人脸关键点序列, V{t}表示待生成的说话人脸视频帧序列, fimg表示用于指导合成的人脸及背景参考的模板图像, ☉操作表示将关键点特征与模板图像特征按位置相乘计算以产生脸部的预期结果, 即通过连续的关键点和模板图像合成面部人脸视频, L{t}表示判别器预测的生成人脸图像序列的真假性结果, G表示生成器网络, D表示鉴别器网络.
生成器网络结构如图2(a)所示, 相比原始的U-Net, 本文使用并行的网络对关键点信息进行编码, 再使用通道注意力机制[21]获得权值矩阵, 与模板图像特征点乘获得人脸信息, 并引入全局信息将人脸图像信息和关键点信息进行特征融合, 生成高质量的说话人脸视频.(a)中图像操作部分的参数设置与U-Net保持一致, 人脸关键点坐标建模部分设置反卷积层, 输出特征图的维度与通道注意力机制卷积层的参数维度匹配.
 | 图2 LTV-Net的网络结构Fig.2 Architecture of LTV-Net |
判别器网络结构如图2(b)所示, 通过卷积网络对输入图像进行卷积操作, 提取特征, 进而判断输入图像的真假性, 其中非线性映射层采用Leaky ReLu激活函数, 池化层为最大值池化.
为了优化LTV-Net参数, 本文结合生成器损失、判别器损失和图像逐像素相似度损失, 通过总损失对整体网络进行优化, 总损失函数如下所示:
LGAN=Ld+Lg+Lpix,
其中, Ld表示判别器的交叉熵损失函数, Lg表示生成器的交叉熵损失函数, Lpix表示生成器的逐像素L1 loss.
本文实验数据由2个数据集组成.1)GRID公开数据集[22], 由34位说话者组成的大型视听说话句子数据集.2)由于GRID数据集不存在明显头部姿态变化, 另收集新闻联播语料并对其进行说话人脸视频标注(后文称为私有数据集), 数据集同时包含男女主播, 具有不同的姿态和口音, 总时长约10 000 s.这种数据设计更方便与当前主流算法进行对比验证.
对于每个数据集, 按8:2的比例划分为训练集和测试集.对于从视频中分离的音频数据, 采用16 000 Hz的采样频率提取梅尔频率倒谱(Mel-Frequency Cepstrum, MFCC)特征.此外, 对于私有数据集, 本文利用DLIB库检测人脸区域并定位人脸关键点, 再将所有图像区域统一缩放至300× 300.
利用开源深度学习框架PyTorch在TITAN V100 GPU上进行算法实现与训练, 与文献[10]一样, 使用自适应矩估计(Adaptive Moment Estima-tion, Adam)优化器并固定学习率为2e-4.所有的网络层参数都采用随机方式进行初始化.
使用峰值信噪比(Peak Signal-to-Noise, PSNR)和结构相似性(Structural Similarity, SSIM)[23]评估生成说话人脸视频的质量, 使用关键点距离(Land-mark Distance, LMD)[17]计算生成视频与真实视频之间的关键点坐标值距离, 评估说话人脸的姿态与动作的自然程度.PSNR、SSIM值越大表明生成的说话人脸视频质量越高.LMD值越低表示生成的说话人脸视频姿态与动作准确性越好、越自然.
为了验证本文方法性能, 选择如下对比算法:文献[8]方法、声音到视频生成网络(Audio to Video Generation Network, ATVGnet)[15]、文献[17]方法、文献[24]方法.
在GRID数据集上, 各算法的LMD、SSIM、PSNR值对比结果如表1所示, 黑体数字表示最优结果.
| 表1 各方法在GRID数据集上的定量实验结果 Table 1 Experimental results of different methods on GRID dataset |
由表1可知, 本文算法除在PSNR值上略低于ATVGnet, 其它效果最优, 可有效完成语音驱动的说话人脸生成任务.此外, 本文方法的LMD值远低于对比方法, 说明本文方法在生成说话人脸视频的唇部动作与头部动作准确性方面远优于对比方法.ATVGnet的PSNR值优于本文算法, 说明其生成的人脸图像的质量较优, 原因在于ATVGnet只根据语音合成唇部区域, 面部其它区域像素根据原有或历史图像经融合拼接而成.但是, 本文方法中的人脸所有像素都由生成网络以端到端的方式自动生成, 适用性更强.
在私有数据集上基于ATL-Net的输入语音预测人脸关键点, 结果示例如图3所示.由图可知, 基于ATL-Net的输入语音预测人脸关键点序列与相应的真实视频帧中提取的关键点相比, 嘴型几乎相同, 头部姿势却有所不同.这种现象符合常识, 即人类在正常说话时嘴部运动应与语音对齐较精准, 但头部可能会产生一些随机运动.
 | 图3 在私有数据集上ATL-Net预测的人脸关键点示例Fig.3 Samples of facial landmark predicted by ATL-Net on private dataset |
在私有数据集上, LTV-Net根据人脸关键点序列生成说话人脸视频, 结果示例如图4所示.由图可知, 相比对应的真实人脸视频帧, LTV-Net输出的说话人脸图像序列头部姿势和面部表情非常接近真实视频帧, 同时背景除了具有人的发型、衣服、领带等多种变化以外, 基本保持不变.由此表明本文的具有注意力机制的GAN网络能获得更优的面部信息和运动信息, 并保留背景信息.
 | 图4 LTV-Net在私有数据集上生成的说话人脸视频帧示例Fig.4 Examples of talking face video frames generated by LTV-Net on private dataset |
本文方法和文献[11]方法在GRID数据集上由语音生成说话人脸图像序列的对比如图5所示.由图可明显看出, 本文方法不仅在唇部的细节, 如唇部动作张合等方面, 具有更优效果, 同时在图像整体纹理、色泽等方面更符合视觉感知常识. 例如, 在面部的红润程度方面, 本文方法生成的说话人脸图像在面部都带有明显的红润; 在唇部颜色方面, 本文方法在女性角色上有明显的口红颜色, 但是在男性角色上几乎没有出现口红颜色.对应地, 文献[11]方法生成的图像中无论男女, 嘴唇都带有口红颜色.此外, 在图5(b)第一行中女性角色的眼部出现噪声区域, 表明文献[11]方法的细节建模能力弱于本文方法.
 | 图5 在GRID数据集上2种算法生成的说话人脸图像Fig.5 Talking face images generated by 2 methods on GRID dataset |
本文方法在GRID数据集上更多的生成效果示例如图6所示.由图可知, 本文方法具有较优的鲁棒性.
 | 图6 本文算法在GRID数据集上的生成效果示例Fig.6 Talking face generation examples of the proposed method on GRID dataset |
2.4.1 ATL-Net损失函数分析
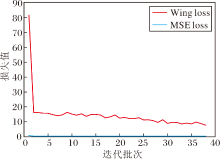
ATL-Net在度量生成的人脸关键点序列与真实人脸关键点时采用Wing loss 而非点回归任务中常用的MSE loss.在Wing loss中有2个可选参数w, ∈ .w表示把非线性部分的范围限制在区间[-w, w]内, ∈ 为一个非常小的参数, 用于平滑非线性和线性之间连接部分.经过遍历搜索, 当w=10, ∈ =2时, ATL-Net在不同数据集上表现最优.图7为最优参数条件下ATL-Net训练过程中的损失函数变化曲线, 表2为ATL-Net收敛后的LMD值.
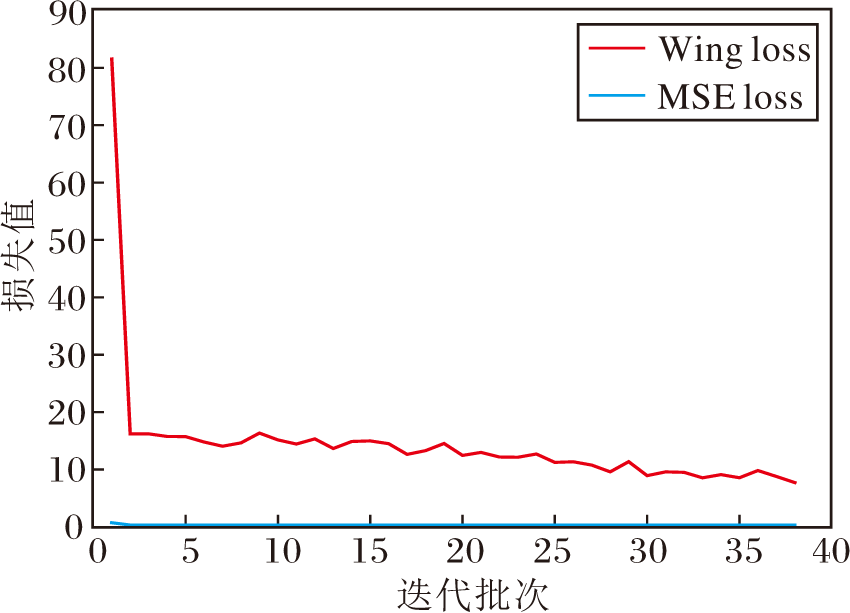 | 图7 在GRID 数据集上ATL-Net训练过程中损失函数变化曲线Fig.7 Loss curves of ATL-Net training process on GRID dataset |
| 表2 MSE loss和Wing loss在不同数据集上的LMD值对比 Table 2 LMD comparison of MSE loss and Wing loss on different datasets |
由图7和表2可看出, 虽然在训练集中MSE loss值小于Wing loss, 但在测试集中使用Wing loss的模型的唇部关键点与头部关键点的预测精度远高于使用MSE loss的模型, 即在ATL-Net中使用Wing loss作为损失函数可有效降低过拟合, 提高模型的泛化性能.
2.4.2 ATL-Net网络并行结构有效性分析
ATL-Net在依据输入语音生成人脸关键点时, 是在利用并行网络分别生成唇部关键点和头部关键点后, 对两组关键点进行融合.为了验证这种策略的有效性, 在GRID数据集上进行消融实验, 定量结果如表3所示.由表可知, 相比无并行结构网络, 本文方法在ATL-Net中使用的并行结构可显著提高人脸关键点定位的准确性, 其原因是唇部关键点与语音的关联度要大于头部关键点与语音的关联度, 并行结构通过对2组关键点进行解耦, 提升关键点定位的精度.
| 表3 ATL-Net是否含有并行结构的定量实验结果 Table 3 Quantitative results of ATL-Net with and without parallel structure |
2.4.3 LTV-Net注意力机制分析
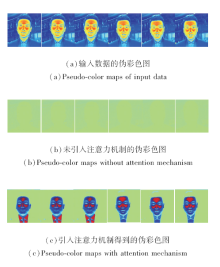
本文通过定性与定量的消融实验验证与分析注意力机制的有效性.LTV-Net有无注意力机制的效果对比如图8所示.由图可见, (a)中可清晰分辨背景信息和人脸信息, 人脸信息和背景信息具有清晰的轮廓.(b)中几乎看不清人脸信息和背景信息, 没有清晰的轮廓.(c)中可清晰区别人脸信息和背景信息, 存在清晰的轮廓信息.
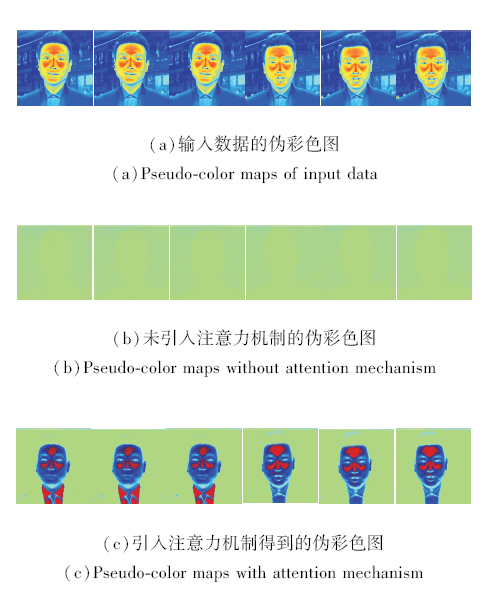 | 图8 LTV-Net是否采用注意力机制的效果对比Fig.8 Result comparison of LTV-Net with and without attention mechanism |
由图8可知, 引入注意力机制可分离背景信息和人脸信息, 这表明引入注意力机制可有效地使网络集中关注人脸部分, 从而提升生成人脸的质量.由图8(a)~(c)第3列到第6列可发现, 即使引入头部的动作信息, LTV-Net仍可准确定位到人脸区域.因此, 通过注意力机制, LTV-Net能有效解决在包含头部动作的说话人脸视频生成中因无法定位人脸区域而导致的生成说话人脸视频质量较差的问题.
GRID数据集上LTV-Net有无注意力机制的定量实验结果如表4所示.结果表明本文方法使用注意力机制后有效性更高.
| 表4 LTV-Net有无注意力机制的定量实验结果 Table 4 Quantitative results of LTV-Net with and without attention mechanism |
本文提出基于关键点表示的语音驱动说话人脸视频生成方法.将输入语音信息分解为说话人的头部动作和唇部动作, 以人脸关键点为中间媒介, 利用Wing loss提升生成动作的准确性, 最后利用注意力机制将不同部位特征整合到生成网络中, 输出说话人脸视频序列.定量与定性实验表明, 本文方法不仅可生成高质量的面部表情、准确的唇部动作, 还可生成自然的头部动作.同时, 大量的消融实验也证实本文方法中不同模块的有效性.今后将考虑与人像分割技术结合, 实现背景不敏感的语音驱动说话人脸视频自动生成.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|