



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于运动优化语义分割的变分光流计算方法
[葛利跃1, 2  , 邓士心
, 邓士心2 , 龚洁2 , 张聪炫2, 3 , 陈震2 ]
, 邓士心, 龚洁, 张聪炫, 陈震]
|
|



作者简介:

葛利跃,硕士,助教,主要研究方向为图像处理、计算机视觉.E-mail:lygeah@163.com.

邓士心,硕士研究生,主要研究方向为图像处理、计算机视觉.E-mail:deng969327@163.com.

龚 洁,硕士研究生,主要研究方向为图像检测、智能识别.E-mail:1014800063@qq.com.

陈 震,博士,教授,主要研究方向为图像理解与测量.E-mail:dr_chenzhen@sina.com.
针对光照变化和大位移运动等复杂场景下图像序列变分光流计算的边缘模糊与过度分割问题,文中提出基于运动优化语义分割的变分光流计算方法.首先,根据图像局部区域的去均值归一化匹配模型,构建变分光流计算能量泛函.然后,利用去均值归一化互相关光流估计结果,获取图像运动边界信息,优化语义分割,设计运动约束语义分割的变分光流计算模型.最后,融合图像不同标签区域光流,获得光流计算结果.在Middlebury、UCF101数据库上的实验表明,文中方法的光流估计精度与鲁棒性较高,尤其对光照变化、弱纹理和大位移运动等复杂场景的边缘保护效果较优.
About Author:
GE Liyue, master, teaching assistant. His research interests include image processing and computer vision.
DENG Shixin, master student. His research interests include image processing and computer vision.
GONG Jie, master student. Her research interests include image detection and intelligent recognition.
CHEN Zhen, Ph.D., professor. His research interests include image understanding and measurement.
To address the issues of edge-blurring and over-segmentation of image sequence optical flow computation under complex scenes,such as illumination change and large displacement motions, a variational optical flow computation method based on motion optimization semantic segmentation is proposed. Firstly, an energy function of variational optical flow computation is constructed via a image local region based zero-mean normalized cross correlation matching model. Then, the motion boundary information obtained from the computed optical flows is utilized to optimize the initial image semantic segmentation result, and a variational optical flow computation model based on the motion constraint semantic segmentation is constructed. Next, the optical flows of various label areas are fused to acquirethe refined flow field. Finally, experimental results on Middlebury and UCF101 databases demonstrate that the proposed method performs well in computation accuracy and robustness, especially for the edge-preserving with illumination change, textureless regions and large displacement motions.
本文责任编委 黄 华
Recommended by Associate Editor HUANG Hua
光流是指图像中运动物体表面像素点在观测平面的瞬时位移速度, 图像中所有像素点的光流构成光流场.光流场是一个二维矢量场, 不仅表示图像中所有像素点的运动趋势, 还包含图像中目标与场景的结构信息.因此, 光流计算被广泛应用于手势识别[1]、视觉定位[2]、微表情识别[3]、VR场景制作[4]等领域.
现阶段, 图像序列光流计算技术主要包括变分光流计算方法和深度学习光流计算方法.随着计算机软硬件水平和深度学习理论的快速发展, 基于深度学习的光流计算技术成为研究热点.该类方法首先利用卷积神经网络在多尺度空间提取图像特征, 然后根据图像特征建立相邻帧图像像素点的对应关系, 最后根据像素对应关系预测光流.Dosovitskiy等[5]使用卷积神经网络(Convolutional Neural Net-work, CNN)建立基于有监督学习的光流网络(Lear-ning Optical Flow with Convolutional Networks, Flow-Net), 验证利用通用U型网络(U Networks, U-Net)架构直接估计图像光流的可行性.针对 FlowNet 模型光流计算精度较低的问题, Iig等[6]在FlowNet模型上进行堆叠, 设计光流网络2.0(Evolution of Opti-cal Flow Estimation with Deep Network, FlowNet 2.0), 提高深度学习光流估计的精度, 但模型尺寸较大.为了减小模型尺寸和参数量, Sun等[7]提出紧凑型卷积神经网络光流估计方法(CNNs for Optical Flow Using Pyramid, Warping, and Cost Volume, PWC-Net), 在特征金字塔网络模型中引入变形层和成本层, 减小网络尺寸和参数量, 并使用多层CNN估计光流, 在减少模型尺寸、参数量的同时有效提高光流计算精度.针对特征金字塔网络模型中直接使用变形策略会出现重影的问题, Hofinger等[8]提出使用采样策略代替变形策略, 首先在金字塔每层图像中生成成本代价采样, 然后计算特征之间的距离, 用于填充成本代价, 有效避免变形策略引起的重影问题.针对运动遮挡区域光流估计的可靠性, Hur等[9]分别计算图像序列的前向光流与后向光流, 并将前、后向光流进行匹配提取遮挡信息, 提高运动遮挡图像序列的光流计算可靠性.Zhao等[10]设计可学习遮挡掩模的非对称特征匹配模块, 学习粗级遮挡掩摸, 在特征变形后过滤无用遮挡区域, 进一步提高遮挡区域光流估计.
然而, 上述方法需要大量标签数据训练模型参数, 训练过程较复杂[11], 难以应用于真实场景.为了减少对标签数据的依赖性, 基于无监督学习的光流计算方法成为研究的新方向[12].当前无监督学习光流计算方法主要通过一些正则化优化光度一致性[13]或梯度一致性[14]以避免对标签的需求.由于无监督学习方法仅依赖于损失函数的设计, 精度与鲁棒性远低于监督学习方法.
与深度学习光流计算技术不同, 变分光流计算方法以变分理论为基础, 通过最小化能量泛函获取图像序列的稠密光流估计[15], 具有计算精度较高、可拓展性较强等优点.根据研究侧重点的不同, 变分光流计算技术研究可大致分为两类:针对光流估计能量泛函的研究和针对光流计算策略的研究.
能量泛函是光流计算数值化的基础, 一般由数据项和平滑项组成.数据项主要由基于图像数据的守恒假设构成, 决定光流估计的精度与可靠性.针对数据项的研究, 主要是探讨如何通过改造数据项以提高光流估计的精度与准确性.例如, 当图像序列中包含光照变化与噪声时, 图像亮度守恒假设通常包含较大误差, 基于图像梯度、结构张量等[16]数据的高阶守恒假设逐渐成为数据项的重要组成部分.此外, 对结合亮度和梯度守恒的数据项执行附加约束归一化[17], 被证明可有效提高数据项抗光照变化能力.能量泛函中的平滑项主要由各种正则化策略构成, 决定光流扩散的方向和强度.由于传统平滑项采用的一致扩散策略容易造成图像边缘过于平滑, 基于图像梯度的自适应扩散策略通常用于解决图像边缘区域光流过度发散问题[18].鉴于图像驱动的平滑策略常导致光流估计结果出现过度分割现象, 基于运动驱动的平滑策略被用于控制光流在运动边界的扩散, 保护物体或场景的轮廓信息[19].由于场景中物体的图像边缘与运动边界并不一定完全重合, 基于图像与运动联合驱动的正则化策略成为现阶段解决光流扩散准确性的主要方法[20].
随着图像场景计算难度的增大, 仅依赖数据项和平滑项的能量泛函通常无法满足复杂场景下高精度光流估计的要求.因此, 针对光流计算策略及优化方法的研究逐渐成为变分光流计算研究的重点问题.为了消除光流计算过程中的异常值, 基于加权中值滤波的非局部优化模型(Classic+Non-local, classic+NL)成为现阶段变分光流估计的主流方法[21].针对大位移运动光流估计的准确性问题, 基于最近邻域场的计算策略[22]和基于匹配的计算策略[23]被用于提高大位移光流估计的精度和鲁棒性.Brox等[24]提出大位移光流(Large Displacement Optical Flow, LDOF), 在变分光流模型中引入特征匹配约束, 提高大位移光流估计精度.随后, 基于匹配的计算策略得到快速发展.Chen等[25]提出基于分段块匹配光流计算模型, 先生成不会因过度分割而丢失重要运动信息的稀疏种子, 再采用稀疏种子由粗到细块匹配以产生稀疏匹配, 从而增强全局正则化的鲁棒性, 有效提高大位移运动光流估计精度.Maurer等[26]提出运动感知块匹配方法, 构建刚性场景重建的三帧块匹配方法, 并将其与两帧块匹配方法结合, 大幅提高刚性物体大位移运动光流估计性能.
上述方法仅针对刚性运动场景, 而在非刚性运动场景下光流估计精度与可靠性仍然较差.针对该问题, Chen等[27]提出非刚性稠密匹配光流计算模型, 利用图像相邻块区域的相似性消除非一致性区域, 得到准确匹配结果, 提高非刚性运动场景光流估计精度和可靠性.由于不同运动边界间像素点的遮挡会导致光流计算模型在局部区域产生较大误差, 基于区域匹配对称的遮挡像素点检测模型能有效改善遮挡边界区域光流计算的准确性[28].针对复杂场景下图像和运动边缘区域容易产生的光流过度分割和边界模糊现象, 语义分割模型被用于约束光流在边缘区域扩散的强度, 保留光流估计的边缘特征[29].此外, 通过在金字塔分层优化过程中引入权重正则的方法也被证明是提高光流估计精度和鲁棒性的有效方法[30].
虽然变分光流计算方法在光流计算的精度和可靠性等方面取得一定提升, 但是在包含大位移与复杂场景的图像序列上, 该类方法的光流估计仍存在较大误差.针对上述问题, 本文提出基于语义分割优化的变分光流计算方法.首先设计基于归一化互相关的变分光流能量泛函, 改善大位移场景下光流计算的鲁棒性.然后构造基于语义分割优化的光流计算模型, 提升复杂场景下光流计算的准确性.实验表明, 本文方法具有较高的光流估计精度, 尤其对大位移和复杂场景具有较优的鲁棒性.
去均值归一化互相关(Zero-Mean Normalized Cross Correlation, ZNCC)[31]是一种图像匹配算法, 主要用于表示图像中2个对应块之间的相似程度, 包含灰度向量去均值和归一化互相关两个部分:
ZNCC(f, T)=
其中:N表示匹配块包含的像素数; f、T表示图像匹配块; μ f、 μ T表示匹配块的均值; σ f、σ T表示匹配块的标准差.在[-1, 1]绝对尺度范围之间衡量两者的相似性:ZNCC(f, T)越接近于1, 表示匹配块的相似度越高; 否则, 表示匹配块的相似度越低.
由于光照变化会导致像素点在相邻帧图像上不满足亮度守恒假设, 致使光流估计的鲁棒性较差.为了提高亮度变化场景下变分光流计算的准确性与鲁棒性, 本文采用ZNCC匹配计算相邻帧图像间的光流.根据ZNCC匹配公式, 当前帧图像I1中的任意局部块和下一帧图像I2中对应局部块的匹配误差定义为
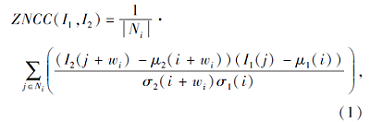
其中, Ni表示图像中以像素点i为中心的局部块区域, j表示该区域内的任意邻域像素点, wi表示像素i的光流.为了简化式(1), 使用C(· )表示图像归一化互相关变换.根据图像亮度守恒假设, 可定义基于图像局部区域归一化互相关匹配的数据项:
Edata(u, v)=
其中, i=(x, y)T表示像素点i的图像坐标, Ω 表示图像中所有像素点的集合,
为了计算图像序列稠密光流场, 引入基于局部运动平滑一致性假设的正则化项:
Esmooth(u, v)=
其中
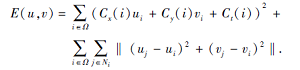
针对大位移运动场景光流估计的准确性, 本文在最小化变分光流能量泛函时引入金字塔分层变形计算策略[30].鉴于图像采样系数较大或金字塔层数较多会显著增加光流估计的耗时, 本文设置图像上采样系数为0.5, 金字塔层数为6, 在提高大位移光流估计鲁棒性的同时降低计算过程的耗时.在获取归一化互相关光流后, 提取光流中包含的运动信息, 实现对语义分割的优化.
基于归一化互相关的变分光流计算模型能提高大位移运动的光流计算精度, 但光流的一致性扩散容易导致计算结果出现边缘模糊现象.
为了克服光流估计中的边缘模糊问题, 本文提出基于运动优化语义分割的光流计算方法, 首先从归一化互相关光流中提取运动信息, 进一步优化语义分割结果.然后利用优化后语义分割图包含的边界信息优化图像不同区域的光流计算, 保护图像与运动边缘结构.
语义分割的基本思想是通过对图像中所有像素点赋予语义标签, 将原始图像转换为带有类别信息的语义标签图.本文使用DeepLabV3+[32]对输入图像进行语义分割, 将图像分为物体、平面和填充物3种语义类别, 分别定义如下.
1)物体.物体指图像场景中区别于背景的独立目标, 主要包括人、动物、飞机、汽车、轮船、摩托车、自行车等具有独立运动的目标.
2)平面.平面指图像场景中具有广泛空间范围的背景区域, 主要包括天空、道路、河流、湖泊等包含平面形态的图像区域.
3)填充物.填充物指除物体和平面类别以外的图像元素, 主要包括建筑、植物等图像场景元素.
图1给出DeepLabV3+的语义分割效果.虽然DeepLabV3+能根据语义标签类别将图像场景分割为不同区域, 然而语义分割图中不同物体或场景的图像边缘并不一定与运动边界完全重合, 因此直接将DeepLabV3+语义分割结果用于光流计算容易导致光流估计产生边缘模糊与过度分割现象.
 | 图1 DeepLabV3+图像语义分割效果Fig.1 Image semantic segmentation result by DeepLabV3+ |
为了克服光流计算中的边缘模糊与过度分割问题, 首先将DeepLabV3+初始语义分割结果中的语义标签按照运动模式分为运动前景和图像背景两类.
运动前景指初始语义分割的物体类别, 主要由具有明显运动的前景目标组成.图像背景由初始语义分割的平面和填充物类别组成, 包含无明显运动的大面积背景区域.
由于根据初始语义分割结果划分的运动前景和图像背景在连续帧图像间的运动边界区域会存在语义标签不匹配的问题, 导致分割结果并不准确.本文提出运动约束语义分割优化模型, 从归一化互相关光流中提取运动信息, 对语义分割进行优化, 准确获取图像中运动物体与背景的边界信息.
令gt、gt+1分别表示当前帧和下一帧图像的二值化语义标签图, 其中, 运动前景和图像背景区域的像素点语义标签分别赋值为{1, 0}.(u, v)T表示根据归一化互相关光流模型计算的图像帧间稠密光流场.符号
p=(x, y)T
表示参考帧图像中的运动前景区域内的任意像素点, 则该像素点在第二帧图像中对应像素点q的坐标可表示为
q=
其中,
为了获取完整前景运动区域运动信息, 本文提取前景运动区域所有像素点光流信息.同时, 为了避免同一目标区域的语义标签在运动前后发生改变, 造成运动信息提取存在较大错误, 本文构建时间约束项, 从时间方面约束前景运动区域像素点运动前后像素点标签的一致性.
假设参考帧图像像素点p与其下一帧图像对应像素点q的语义标签一致, 定义运动优化语义分割的时间约束项:
Etime(gt, gt+1)=
其中, F表示图像运动前景区域, ϕ (· )表示指示函数.当
ϕ (
否则, 运动前景像素点p与对应像素点q的语义标签不一致, 函数
ϕ (
利用式(4)中的像素点语义标签时间约束可分割连续帧图像间语义标签属性不匹配的运动前景像素点, 但是物体与场景的相互运动会导致边界区域像素点的语义标签属性不准确.通常, 前景运动区域的运动一般是均匀的, 所以, 运动区域对应的光流也分布均匀.
为了提高图像边界区域像素点运动优化语义分割的准确性, 本文利用图像局部区域像素点的亮度和距离相似性定义运动优化语义分割的空间约束项, 用于提高图像边界区域像素点运动优化语义分割的准确性.空间约束项
Espace(gt)=
其中:r表示以运动前景像素点p为中心点的图像局部区域Np中的任意邻域像素点.
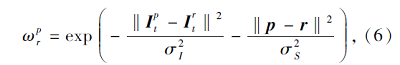
其中,
由式(5)和式(6)可知:当
根据定义的运动优化时间项和空间项, 可得本文运动优化语义分割模型如下:
Ess(gt)=Etime(gt, gt+1)+Espace(gt). (7)
对式(7)中的运动优化语义分割模型最小化, 获得当前帧图像中运动前景区域像素点与其下一帧图像对应的匹配像素点.如果当前帧像素点与下一帧匹配像素点的语义标签都是运动前景类别, 该像素点的语义标签为前景类别; 否则, 该像素点的语义标签为背景类别.
本文方法的运动前景与图像背景语义分割优化效果如图2所示.由图可看出, 本文方法可准确分割运动前景与图像背景, 尤其对运动边界具有较好的分割效果.
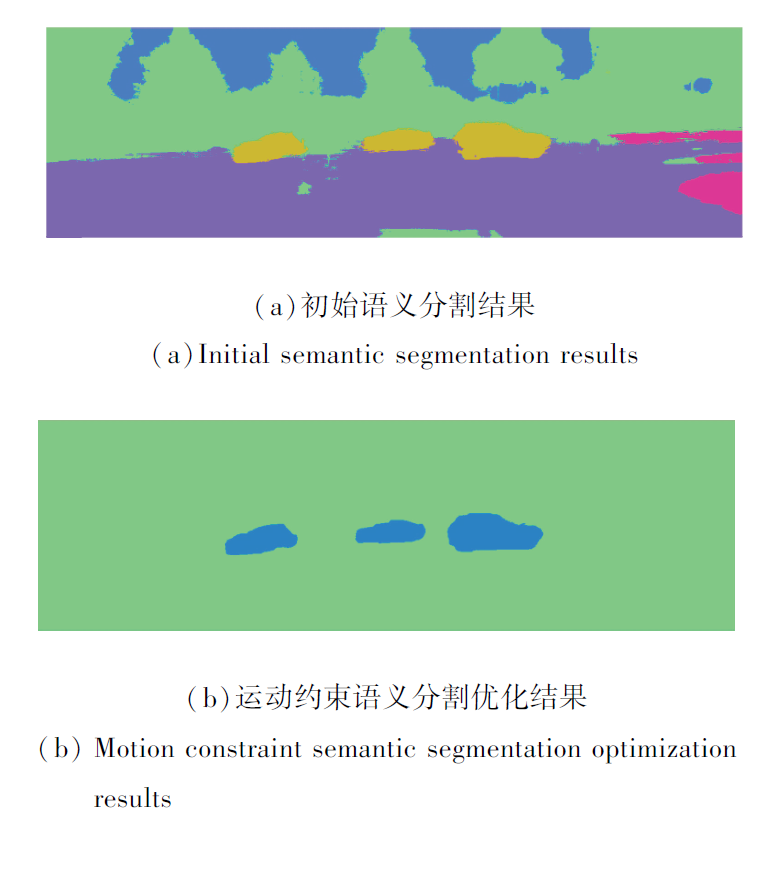 | 图2 运动约束语义分割优化效果Fig.2 Optimization results of motion-constrained semantic segmentation |
根据语义分割得到的连续两帧语义标签图gt和gt+1, 本文按照语义标签类别, 分别建立运动前景光流优化模型和图像背景光流优化模型, 再融合不同标签区域的光流, 得到最终的图像帧间光流结果.
令p=(x, y)T表示参考帧图像It中运动前景区域内的任意像素点, 则该像素点在第二帧图像It+1中对应像素点q的坐标可表示为
q=
其中
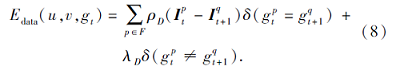
其中:F表示图像运动前景区域;
ρ D(x)=
表示非平方惩罚函数, τ =0.001; δ (x)表示指示函数, 当输入x为真时, δ (x)=1, 否则, δ (x)=0; λ D=0.01表示不同语义类别像素点的恒定惩罚常数.
鉴于图像中像素点的运动在局部区域内具有一致性, 可将前景区域内的像素点运动视为仿射运动.因此, 定义运动前景光流优化的运动正则化项
Emotion(u, v, gt)=
其中:r表示以运动前景像素点p为中心点的图像局部区域Np中的任意邻域像素点; wr=
ρ (x)=
联合式(7)式(9), 根据光流变分模型构建方法, 同时保持模型的通用性, 基于运动优化语义分割的运动前景光流估计能量泛函定义如下:
Efg(u, v, gt)= Edata(u, v, gt)+Emotion(u, v, gt)+Ess(gt, gt+1).
当图像像素点属于运动前景区域时, 通过最小化式中的能量泛函, 使前景运动区域的像素点光流趋近一致, 获得运动优化语义分割光流优化结果.
当图像像素点属于图像背景区域时, 像素点光流优化模型
wbg(x)=winitial(x),
其中, x表示图像背景区域内任意像素点, winitial(x)表示根据归一化互相关光流计算模型计算所得初始光流.
根据运动优化语义分割前景光流和图像背景光流, 通过融合算法[33]组合前景运动和图像背景区域光流, 可获得最终的稠密光流估计结果.
本文分别采用Middlebury、UCF101数据库提供的测试图像集进行综合测试分析.Middlebury数据库是光流评估的基准图像集, 提供真实光流值, 并采用平均端点误差(Average Endpoint Error, AEE)和平均角误差(Average Angle Error, AAE)评测光流计算的准确性.AEE反映光流估计结果与真实光流的绝对误差, AAE反映光流估计值与真实光流的角度偏离情况, 定义如下:
AEE=
其中, N表示图像像素点的数量,
UCF101数据库由现实场景图像序列组成, 不包含真实光流值.本文在计算UCF101数据库图像序列光流后, 根据光流估计结果和参考帧图像计算下一帧图像, 分别采用峰值信噪比(Peak Signal to Noise Ratio, PSNR)和图像锐度(Sharpness Measure, SM)对预测图像和真实的下一帧图像进行评测.PSNR反映预测图像与真实图像的相似度, SM反映预测图像的边缘保持情况, 定义如下:
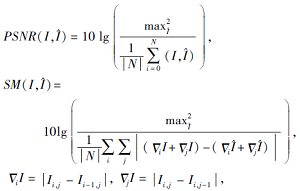
其中, I表示真实图像,
Δ =(∂ x, ∂ y)T
表示图像梯度算子.
为了验证本文方法光流估计的精度与鲁棒性, 分别选取FlowNet 2.0[6]、PWC-Net[7]、联合滤波(Re-fined TU-L'Optical Flow Estimation Using Joint Fil- tering, JOF)[16]、Classic+NL[21]、LDOF[24]变分模型和深度学习光流计算方法进行对比分析.
Classic+NL是经典的变分光流估计模型, 设计加权中值滤波后处理优化, 提高变分光流估计的鲁棒性.LDOF对变分光流能量泛函添加局部描述匹配约束, 提高大位移运动光流估计的可靠性.JOF设计联合中值滤波与相互结构引导滤波的多滤波协同优化策略, 改善光流估计的边缘模糊问题.FlowNet 2.0在光流估计CNN模型中增加专门针对大位移运动与小位移运动的估计模块, 用于提升深度学习光流估计的精度.PWC-Net采用特征金字塔网络, 从图像序列中提取较高置信度特征图, 采用多层扩张型CNN进行光流估计, 提高深度学习光流估计的鲁棒性.
为了验证本文方法对估计精度和鲁棒性的提升作用, 首先设计消融实验, 测试不同方法的有效性.各方法在Middlebury训练集上的光流估计误差结果如表1所示.在表中, Base表示传统的全变分L1范数光流估计方法, 为基准模型, Base+Z表示对传统的光流估计方法添加归一化互相关约束模型, Base+Z+S表示对Base+Z添加经典的语义分割优化.由表1可看出, 本文方法的光流估计精度最高, 说明本文方法可提高光流估计的精度与鲁棒性.
| 表1 各方法在Middlebury训练集上光流估计误差 Table 1 Optical flow estimation errors of different methods on Middlebury training set |
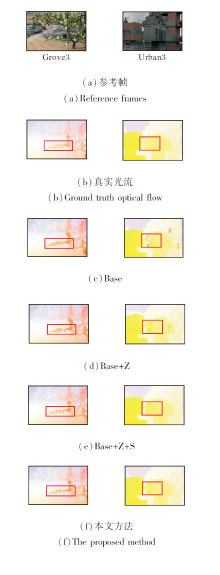
各方法针对Middlebury训练集上Grove3和Ur-ban3图像序列的光流估计结果如图3所示.图中红色方框为图像边缘和弱纹理区域.由图可看出, Base光流估计结果在弱纹理区域包含较多异常值, 图像与运动边界存在明显的边缘模糊现象.Base+Z由于使用归一化互相关约束, 有效提高弱纹理区域光流估计精度, 但由于图像局部区域的归一化, 导致光流估计结果存在边缘模糊现象.Base+Z+S使用语义分割优化策略, 改善光流估计的边缘模糊问题, 但由于图像边缘与运动边界并不完全重合, 导致针对Grove3等包含弱小边缘的图像序列光流估计容易产生边缘过度分割现象.本文方法采用归一化互相关约束和运动优化语义分割模型, 提升光流估计精度, 有效提高图像弱纹理区域光流估计的精度, 克服图像边缘模糊与过度分割问题.
 | 图3 各方法在Middlebury训练集上的光流估计结果Fig.3 Optical flow estimation results of different methods on Middlebury training set |
为了进一步验证本文方法对估计精度和鲁棒性的提升作用及对图像边缘的保护作用, 使用UCF101测试集上的8组运动视频图像集(BaseballPitch、Basketball、BenchPress、FieldHockey、TableTennis、TaiChi、TennisSwing、YoYo)进行消融实验.
由于UCF101测试集不包含真实光流, 本文利用光流估计结果与第一帧图像计算第二帧预测图像后, 采用预测图像和真实图像的PSNR、SM指标对光流估计结果进行量化评价.各方法针对UCF101测试图像集的PSNR、SM值对比结果如表2所示.由表可看出, 相比Base, Base+Z的PSNR、SM值具有明显提高, 说明在传统光流变分计算模型中增加归一化互相关约束模型可有效提高光流计算精度.相比Base+Z, Base+Z+S的PSNR、SM值进一步提高, 说明在变分模型中引入语义分割优化对光流计算可产生积极作用.本文方法的PSNR、SM值最高, 表明本文方法可提高光流估计的精度与鲁棒性, 并较好地保护图像边缘.
| 表2 各方法在UCF101测试集上的指标值对比 Table 2 Index values of different methods on UCF101 testing set |
为了验证本文方法的光流估计精度与鲁棒性, 首先在Middlebury测试集上进行定量测试与分析.各方法的光流估计误差对比结果如表3所示.由表可见, FlowNet 2.0的光流估计误差最大, 主要原因是Middlebury测试集上的训练数据较少, 无法满足FlowNet 2.0的网络训练需求.PWC-Net使用更精炼的网络结构, 提高深度学习模型的光流估计精度, 但受限于训练样本数较少, 在Middlebury测试集上的光流误差仍大于传统的变分光流模型.LDOF采用局部描述匹配项, 提高大位移光流估计的可靠性, 但光流估计的整体精度较差.Classic+NL、JOF的光流估计整体精度较高, JOF采用结合加权中值滤波与相互结构引导滤波的联合滤波策略, 提高变分光流模型在复杂边缘结构和弱纹理场景图像序列的光流估计精度.本文方法的光流估计精度最高, 尤其针对Army、Grove、Schefflera、Wooden这些包含复杂场景和弱纹理区域图像序列, 取得较优的光流估计结果, 这说明本文方法具有较优的光流估计精度和鲁棒性.
| 表3 各方法在Middlebury测试集上的光流估计误差 Table 3 Optical flow estimation errors of different methods on Middlebury testing set |
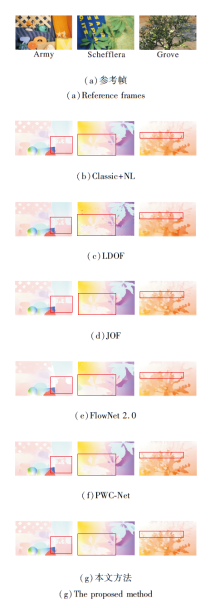
各方法在Army、Schefflera、Grove图像序列上的光流估计结果如图4所示.图中红色方框为复杂边缘和弱纹理区域.
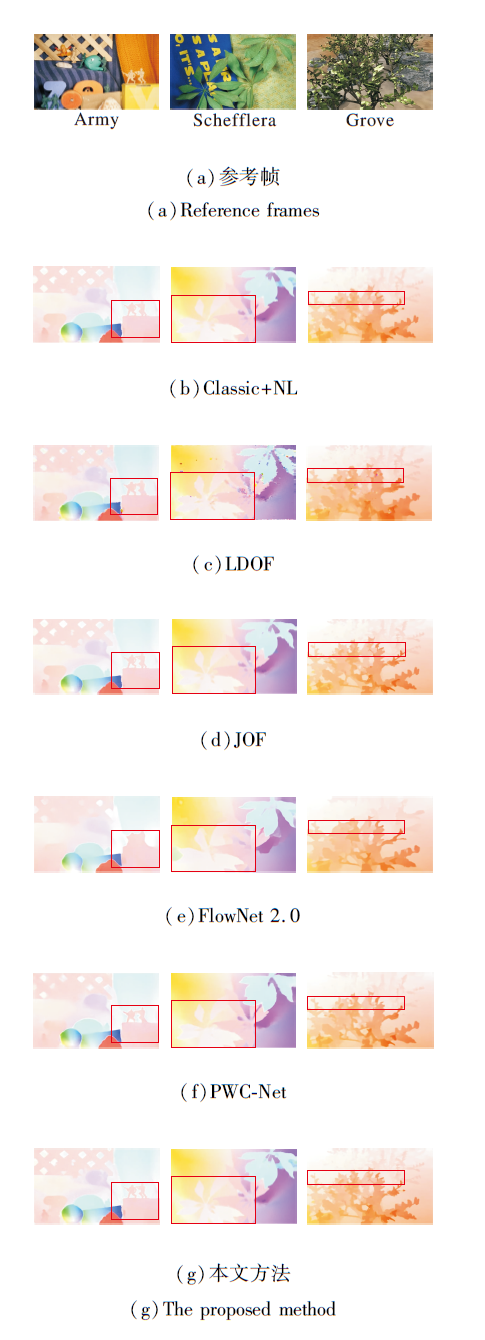 | 图4 各方法在Middlebury测试集上的光流估计结果Fig.4 Optical flow estimation results of different methods on Middlebury testing set |
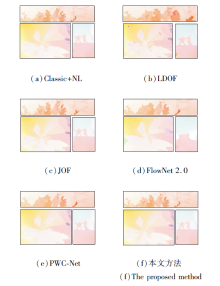
为了直观展示本文方法对图像边缘和弱纹理区域光流估计的提升效果.图5分别列出红色方框区域的细节放大图.由图可看出, FlowNet 2.0和PWC-Net的光流估计结果存在明显的边缘过度平滑现象.LDOF的光流估计结果存在较多异常值.Classic+NL和JOF的边缘区域光流估计效果相对较优, 但仍存在小范围的过度平滑现象, 这是由于中值滤波的平滑特性导致.本文方法估计结果更接近真实值, 尤其在图像边缘和弱纹理区域的光流估计效果最优, 充分体现本文方法对于弱纹理区域光流估计的鲁棒性和边缘保护性能.
 | 图5 各方法在Middlebury测试集上的细节放大图Fig.5 Detail enlargement of different methods on Middlebury testing set |
为了验证本文方法在现实场景图像序列光流估计上的可靠性与鲁棒性, 分别采用UCF101数据库上的BaseballPitch、Basketball、BenchPress、Field-Ho-ckeyP、TableTennisShot、TaiChi、TennisSwing、YoYo8组运动视频图像集进行综合对比分析.
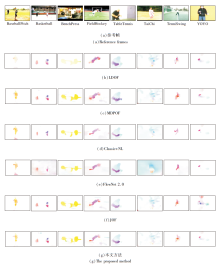
各方法在UCF101测试图像序列上的光流估计结果如图6所示.由图可看出, LDOF和Classic+NL在图像运动边界区域的光流估计均出现明显错误, 存在较多的光流异常值.FlowNet 2.0与PWC-Net这2种深度学习光流估计方法在图像中的人物区域均产生过度平滑现象, 导致图像与运动边缘不清晰.JOF由于采用图像相互结构引导滤波优化边缘光流估计, 导致光流估计结果不够平滑, 运动边界区域也存在部分光流异常值.
 | 图6 各方法在UCF101测试集上的光流估计结果Fig.6 Optical flow estimation results of different methods on UCF101 testing set |
本文方法光流估计整体效果较优, 尤其在图像与运动边界区域取得较准确的估计结果, 说明本文方法针对现实场景同样具有较高的光流估计精度与鲁棒性.
各方法在UCF101测试集上的PSNR、SM指标如表4所示.
| 表4 各方法在UCF101测试集上的指标值对比 Table 4 Index values of different methods on UCF101 testing set |
由表4可看出, 本文方法在8组测试集上的指标值最优, 说明本文方法针对现实场景图像序列具有较好的光流估计精度与鲁棒性.此外, 本文方法在BaseballPitch、Basketball、TaiChi、Tennis-Swing这些包含明显运动前景图像序列上的SM指标明显更优, 说明本文方法能有效提高图像前景和运动边界区域的光流计算精度与鲁棒性, 具有显著的边缘保护特性.
为了验证本文方法在大位移和复杂光照场景图像序列上的光流估计效果, 从UCF101数据库上分别选取大位移场景图像序列(BaseballPitch_02、Basketball_07、FieldHockey_20、YoYo_81)和复杂光照图像序列(BenchPress_08、TableTennis_02、TaiChi_04、TennisSwing_01)作为测试图像序列.
各方法在8组测试图像序列上的光流计算结果预测的第2帧如图7所示.
 | 图7 各方法在UCF101数据库大位移与复杂场景图像序列上预测的下一帧结果Fig.7 Results of next frame predicted by different methods with large displacement and complex scene image sequence on UCF101 database |
由图7可看出, 对于大位移运动测试图像序列, 利用本文方法估计光流预测的下一帧图像与真实下一帧更相似.
在BaseballPitch_02、FieldHockey_20、YoYo_81序列人物区域上, Classic+NL、LDOF、JOF、FlowNet 2.0存在明显信息丢失.PWC-Net在FiledHockey_20序列任务区域预测较准确, 但人物区域边缘存在明显的模糊现象.利用本文方法计算的光流结果预测的下一帧在人物区域获得较精准的预测, 这是因为本文方法使用归一化互相关匹配和金字塔分层优化策略, 可获得高精度的大位移运动光流, 为运动优化语义分割光流模型提供可靠的光流先验信息, 从光流中获取的运动信息更准确, 提升运动约束语义分割优化效果, 因此, 整体图像边缘结构更清晰.
BenchPress_08、TableTennis_02、TaiChi_04、TennisSwing_01序列由于包含分布不均匀的光照, 可被视作复杂光照场景图像序列.由图7可看出, 针对复杂光照场景, 利用LDOF和JOF估计光流结果预测的下一帧图像存在明显错误, 例如BenchPress_08序列窗户区域存在明显变形, 在TableTennis_02序列人物区域, 利用JOF估计光流预测的下一帧几乎丢失人物区域.利用本文方法和FlowNet 2.0估计光流结果预测效果整体优于LDOF、Classic+NL、JOF、PWC-Net.这是因为本文方法使用的归一化互相关光流数据项通过计算去均值归一化互相关块之间的匹配相似性, 提高模型抗光照变化性能, 并且光照对语义分割影响较小, 这有助于本文方法提高光流估计的精度和鲁棒性.
各方法在8组测试图像序列的PSNR、SM值如表5所示.由表可看出, 针对大位移运动测试图像序列, 本文方法的PSNR值最高, SM指标仅在Basket-Ball_07序列上低于Classic+NL、LDOF、JOF, 但总体误差精度最高.在复杂光照测试图像序列上, Flow-Net 2.0的PSNR、SM值取得最佳的误差精度, 而同为深度学习方法的PWC-Net精度最低, 说明Flow-Net 2.0对复杂光照场景效果更优.本文方法针对复杂光照场景估计精度仅低于FlowNet 2.0.同时, 本文方法在平均值上最优, 这进一步证实本文方法针对大位移和复杂光照场景具有较高的光流估计精度和鲁棒性, 针对边缘区域保护效果较优.
| 表5 各方法在UCF101数据库大位移与复杂场景图像序列上的指标值对比 Table 5 Index values of different methods with large displacement and complex scene image sequences on UCF101 database |
在Middlebury测试集上的平均耗时如下:Classic+NL为972 s, LDOF为122 s, JOF为657 s, FlowNet 2.0为0.091 s, PWC-Net为0.069 s, 本文方法为387 s.
受益于CNN在模型参数训练完成后具有实时计算的显著特点, FlowNet 2.0和PWC-Net耗时最短.但是, 该类方法必需大量标签数据训练神经网络模型参数, 导致现阶段仍难以直接应用于不包含光流真实值的现实场景光流估计任务.Classic+NL和JOF在图像金字塔分层细化计算过程中采用较多的金字塔层数, 提高光流估计的精度, 但导致耗时最长.LDOF的计算复杂度较低且不需要大量迭代运算, 耗时相对较少.由于本文方法在计算过程中采用的金字塔层数较少, 因此耗时小于Classic+NL和JOF.因为本文方法需要进行多次迭代优化求解, 耗时长于LDOF、FlowNet2.0、PWC-Net.
以Middlebury数据库上Grove2序列为例, 优化迭代次数对本文方法的影响如图8所示.由图8(a)可看出, 随着迭代次数的增加, AAE曲线呈现先降低再升高的趋势.在迭代次数为20时, 本文方法收敛, 误差最低.由(b)可看出, 随着迭代次数的增加, 本文方法耗时呈逐渐上升趋势.为了在获取高精度光流估计结果的同时尽可能降低耗时, 本文设置迭代优化次数为20.虽然本文方法的耗时较长, 但是本文方法的光流估计精度显著高于其它对比方法, 且光流估计结果具有边缘保护效果, 综合性能最优.
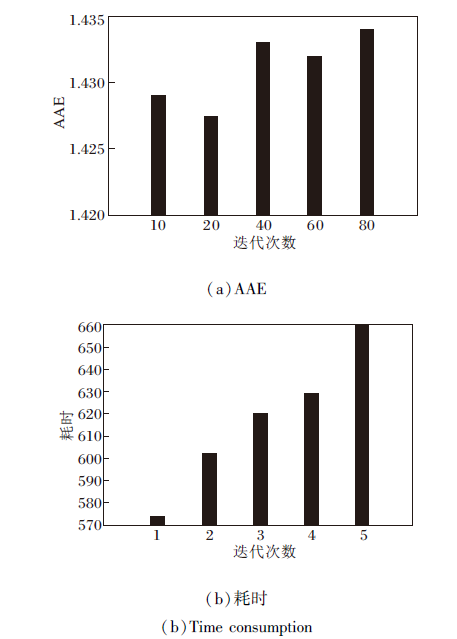 | 图8 迭代次数对本文方法性能的影响Fig.8 Effect of iterations on performance of the proposed method |
针对光照变化与大位移场景下图像序列光流计算的边缘模糊与过度分割问题, 本文提出基于运动优化语义分割的变分光流计算方法.首先构造归一化互相关变分光流计算模型, 提高光流计算的准确性与鲁棒性.然后设计运动优化语义分割光流计算方法, 分别估计图像前景运动目标区域和背景区域的光流, 并融合不同区域光流获得最终估计结果.在Middlebury、UCF101测试集上的对比实验表明, 本文方法能有效提高光照变化、弱纹理和大位移运动场景下光流估计的精度与鲁棒性, 同时具有边缘保护的特性.今后将考虑提高本文算法的计算效率, 使应用场景更丰富.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|